
结合l1/2范数与显著性约束的背景减除
2022-06-16 05:25张国庭陈利霞周泽锋
计算机工程 2022年6期
张国庭,陈利霞,2,周泽锋
(1.桂林电子科技大学数学与计算科学学院,广西桂林 541004;2.桂林电子科技大学广西高校数据分析与计算重点实验室,广西桂林 541004)
0 概述
近年来,视频运动目标检测作为计算机视觉和数字图像处理领域的热点研究方向[1-3],广泛应用于智能监控、交通管制、机器智能、医疗诊断等任务。背景减除[4]是将视频中感兴趣的目标提取出来并去除不感兴趣的背景。常用的背景减除模型主要包括基于概率建模的高斯混合模型(Gaussian Mixture Model,GMM)和鲁棒主成分分析(Robust Principal Component Analysis,RPCA)模型[5]。GMM 模型由STAUFFER 等[6]于1999 年提出,通过期望最大化(Expectation Maximization,EM)算法来确定像素颜色分布的时间以及每个分布的参数。虽然GMM 可以处理背景光线的细微变化,但如果用于参数学习的初始视频帧有噪声,训练后的模型将会受噪声影响。为了提高GMM 的性能,学者们试图通过提出不同的学习方法或修改算法的适应性使该模型对噪声更具鲁棒性[7-9]。RPCA[5]模型利用矩阵的核范数约束低秩部分,通过l1范数约束稀疏部分。由于该模型简单且求解高效,因此被广泛应用于运动目标检测任务,但是RPCA 模型的前提假设是背景静止或几乎静止,而现实世界中的背景往往是变化的。针对此问题,CAO 等[10]提出全变分正则化的RPCA模型,利用运动目标的空间连续性和时间连续性,抑制了动态背景的干扰,但对缓慢运动的目标检测效果较差。针对动态背景或噪声干扰问题,EBADI等[11]提出利用动态树结构的稀疏矩阵建模前景,从而加强前景的稀疏性。CHEN 等[12]在前景建模中引入l1/1/2范数,充分描述了视频的时空相关性,增强了前景的稀疏性。虽然这些模型取得了一定的效果,但处理复杂场景视频的效果仍有待提升,而且当目标移动缓慢时,检测出来的前景出现较多空洞现象。本文提出一种结合l1/2范数和显著性约束的前景检测模型。利用l1/2范数产生更稀疏的解,减少动态背景对前景的干扰。通过显著性约束对视频序列的每一帧进行低秩稀疏分解,有效识别移动缓慢的物体,缓解前景的空洞现象。
1 RPCA 模型
假定给出的视频图像序列包含T帧,将所有帧向量化为列向量得到矩阵。检测运动目标可以通过求解如式(1)所示的RPCA 模型来获取低秩背景矩阵X1∈Rm×n×T(m、n分别表示图像的高度和宽度)以及稀疏前景X2∈Rm×n×T:

其中:||X1||*表示矩阵X1的核范数;||X2||1表示矩阵X2的l1范数;λ是一个正的权衡参数。在强动态背景下,RPCA 检测结果中前景出现大量误判像素,检测性能较差。由于现实世界中视频的背景复杂多变,因此可将式(1)扩展如下:
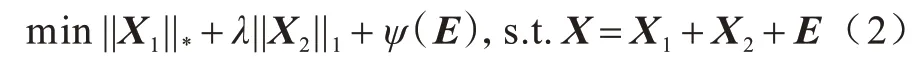
其中:ψ(E)为干扰信号,通常可用‖E‖F/2 来表示,E为噪声矩阵,用于表示动态背景产生的随机变化。
2 模型建立
一方面,传统的背景减除模型在检测移动缓慢的物体时,容易出现空洞现象,导致检测精度下降。由于前景具有显著性,而显著性约束[13-14]能将静止图像的前景检测出来,因此引入显著性有助于检测移动缓慢的目标。另一方面,传统模型多数利用l1范数约束稀疏部分的矩阵,而lq(q∈(0,1))正则化比l1正则化能生成更稀疏的解。通过对所有lq正则化的研究表明,对于q∈[1/2,1),q越小,解越稀疏,但是对于q∈(0,1/2],解的性能没有明显下降,但求解的复杂程度远高于l1/2范数的求解[15]。基于以上两方面,本文引入l1/2范数和显著性约束,提出一种新的背景减除模型,具体如下:

3 模型求解
基于交替方向乘子法,式(3)的增广拉格朗日函数表示如下:

其中:[·]:i是矩阵的第i列;mat(·)表示把向量转化成矩阵,使得mat(vec(Li))≡L i;μ是惩罚参数;是拉格朗日乘子。为求解式(4),利用交替方向乘子法对其进行变量分离并转换为6 个问题进行求解。在迭代初始化时,令,迭代次数k=0。

该问题有闭型解,可通过奇异值阈值化(Singular Value Thresholding,SVT)[16]求解:

其中:Y=USV*;Sτ=sign(S)×max(|S|-τ,0),τ=。
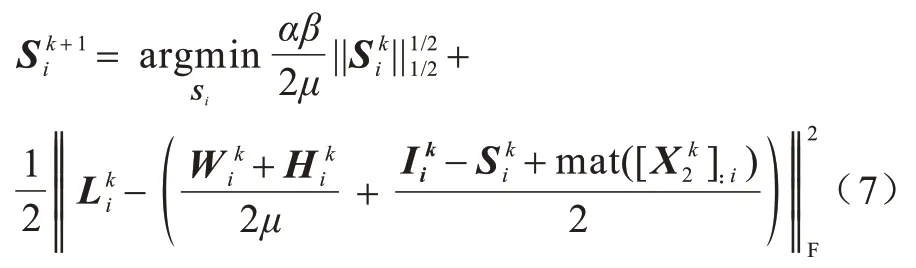
该问题可通过半阈值化算子[15]求解:
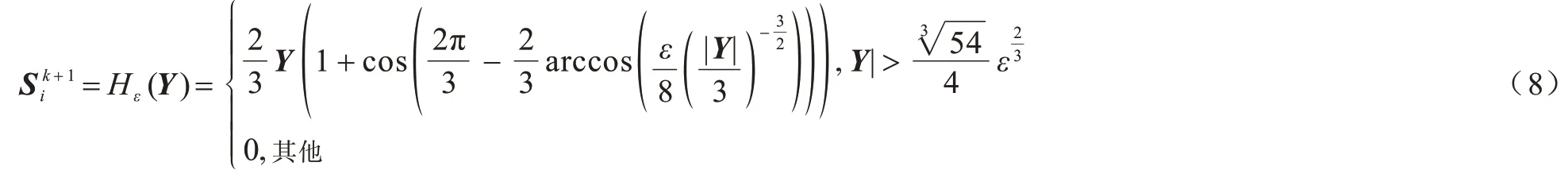
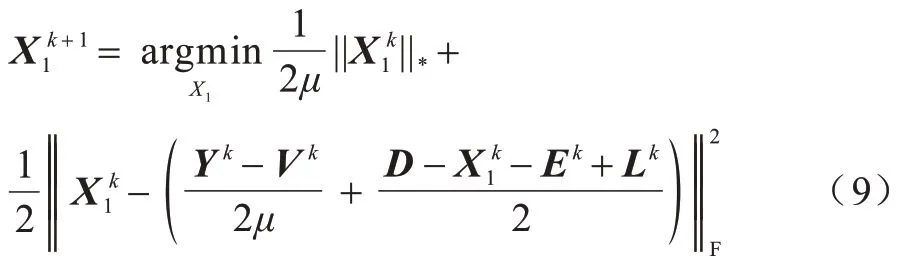
该问题可由SVT 求解,方法与子问题1 类似。

该问题可通过半阈值化算子来求解,方法与子问题2 类似。
5)固定其他变量,利用式(11)更新Ek+1:

6)更新拉格朗日乘子和惩罚参数:

重复求解以上问题直至满足以下迭代收敛条件:

4 实验结果与分析
为验证本文模型的性能,实验从CD.net-2014[17]测试数据集中选取Boulevard 和Traffic(相机抖动)、CopyMachine 和Backdoor(移动缓慢)、Fountain021和Boats(动态背景)、Sating 和SnowFall(恶劣天气)8 组128×128×128 的视频集进行测试,并在相同条件下 与l1/1/2-RPCA[12]、KBR-RPCA[18]、HoRPCA[19]、FRMC[20]、TRPCA[21]、IALM-RPCA[22]模型从主观和客观两方面进行比较。所有实验的运行环境为Matlab 2019a,Intel Core i5-6500 处理器,8 GB 内存,Win10 64 位操作系统。实验设置参数λ=0.8、α==0.01、ρ=1.1。实验视频集如图1 所示。

图1 实验视频集Fig.1 Experimental video sets
为准确地评估本文模型的性能,采用查全率(recall)、查准率(precision)和调和平均值(Fmeasure)来评估前景检测的效果。recall 和precision的定义分别如下:

其中:ttp表示检测出的正确的前景像素点;ffn表示错检为背景的前景像素点;ffp表示错检为前景的背景像素点。
采用F-measure 来综合判断提取效果。F-measure的定义如下:

4.1 主观分析
图2 给出了相机抖动视频集、移动缓慢视频集、动态背景视频集和恶劣天气视频集的视觉效果。

图2 不同模型下视频集的视觉效果对比Fig.2 Comparison of visual effects of video sets under different algorithms
对于相机抖动视频集:FRMC、KBR-RPCA、l1/1/2-RPCA、TRPCA 提取的前景精度较差,运动目标中存在较严重的空洞现象;HoRPCA、IALM-RPCA 提取的运动目标的精度较高,但这两种模型把部分背景也检测为运动目标;本文模型在去除背景干扰的同时,提取的运动目标精度也较高,整体取得最佳的检测效果。
对于移动缓慢视频集:FRMC、KBR-RPCA、TRPCA 提取的运动目标缺乏完整性;HoRPCA 和l1/1/2-RPCA 把部分背景误判为前景目标;IALMRPCA 和本文模型提取的前景对象都较为完整,检测精度明显高于其他4 种模型,但本文模型具有最高的F-measure 值。
对于动态背景视频集,FRMC、KBR-RPCA、TRPCA检测前景的精度较差,运动目标较为模糊;HoRPCA、l1/1/2-RPCA、IALM-RPCA 提取的前景目标均比较清晰和完整,但与本文模型相比,这3 种模型受动态背景影响的干扰较大,把过多的背景误判为运动目标;本文模型在去除动态背景干扰的同时,提取的运动目标精度也较高,整体上取得最佳的检测效果。
对于恶劣天气视频集:FRMC、KBR-RPCA、TRPCA、HoRPCA、l1/1/2-RPCA 提取的前景对象中空洞过大,丢失大量的前景信息;IALM-RPCA 比其他5 种模型提取的运动目标完整,不存在严重的空洞问题,但也把部分背景误判为前景;本文模型与其他模型相比,提取前景的精度较高,同时对背景的误判较少,整体取得最佳的检测效果。
4.2 客观分析
将本文模型和其他6 种模型进行比较,评价指标值如表1 所示,其中,加粗数据代表最优值,加下划线数据代表次优值。从表1 可以看出,虽然其他模型的recall 值和precision 值有比本文模型高的情况,但本文的recall 值和precision 值在此情况下基本也处于次优状态,而且本文模型的F-measure 值均高于其他模型。以上说明了本文模型在抑制动态背景产生的噪声以及目标提取的完整度和精确度方面的综合效果较好。

表1 不同模型下的客观评价指标数据对比Table 1 Data comparison of objective evaluation index under different models
将本文模型与其他6 种模型进行实验对比,选取视频集Skating 中12 个代表帧,每个相隔8 帧,计算各个代表帧的F-measure、precision 和recall 值,得出的相关指标曲线如图3 所示。由图3 可以看出,本文模型的F-measure、precision 和recall 值基本每帧都高于其他6 种模型,相比于l1/1/2-RPCA 背景减除模型的平均查全率、查准率和调和平均值分别提升了9、14 和10 个百分点。从图3(a)、图3(c)可以看出,本文模型的F-measure 和recall 值均高于其他模型,因此本文模型的综合检测效果最好。从图3(b)可以看出,本文模型只有个别帧的precision 值低于其他模型,而多数帧的查准率都是处于最优的。
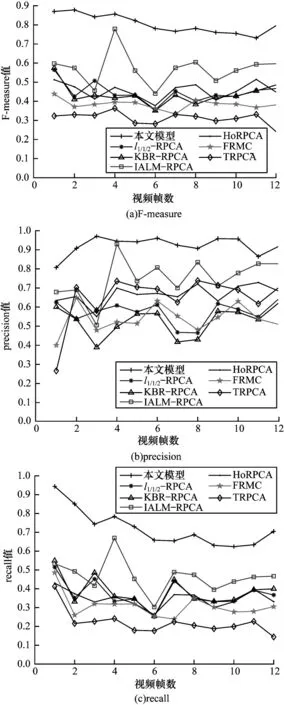
图3 不同模型下的客观评价指标曲线对比Fig.3 Curve comparison of objective evaluation index under different models
表2 给出了本文模型和其他6 种模型的视频集平均每帧的运行时间对比结果。从表2 可以看出,本文模型在运行时间方面优于KBR-RPCA、IALMRPCA、FRMC、TPRCA 模型,但低于HoRPCA 和l1/1/2-RPCA 模型,说明本文模型在计算方面较为耗时,但与运行速度较快的对比模型差距不大,能满足视频监控的实时性要求。

表2 不同模型下的运行时间对比Table 2 Comparison of running time under different models s
采用视频集Skating 作为实验视频集,研究参数变化对实验结果的影响,如图4 所示。从图4(a)中可看出,参数λ在0.08 处F-measure 取得最大值,因此选取λ=0.08 作为最优参数值。从图4(b)中可看出,参数β在0.02 处F-measure 值取得最大值,结合参数变化对其他视频集的影响,因此选取β=0.01 作为最优参数值。从图4(c)可以看出,当参数α在[0.01,0.1]时对实验结果几乎没有影响,因此选取α=≈0.09 作为最优参数值。
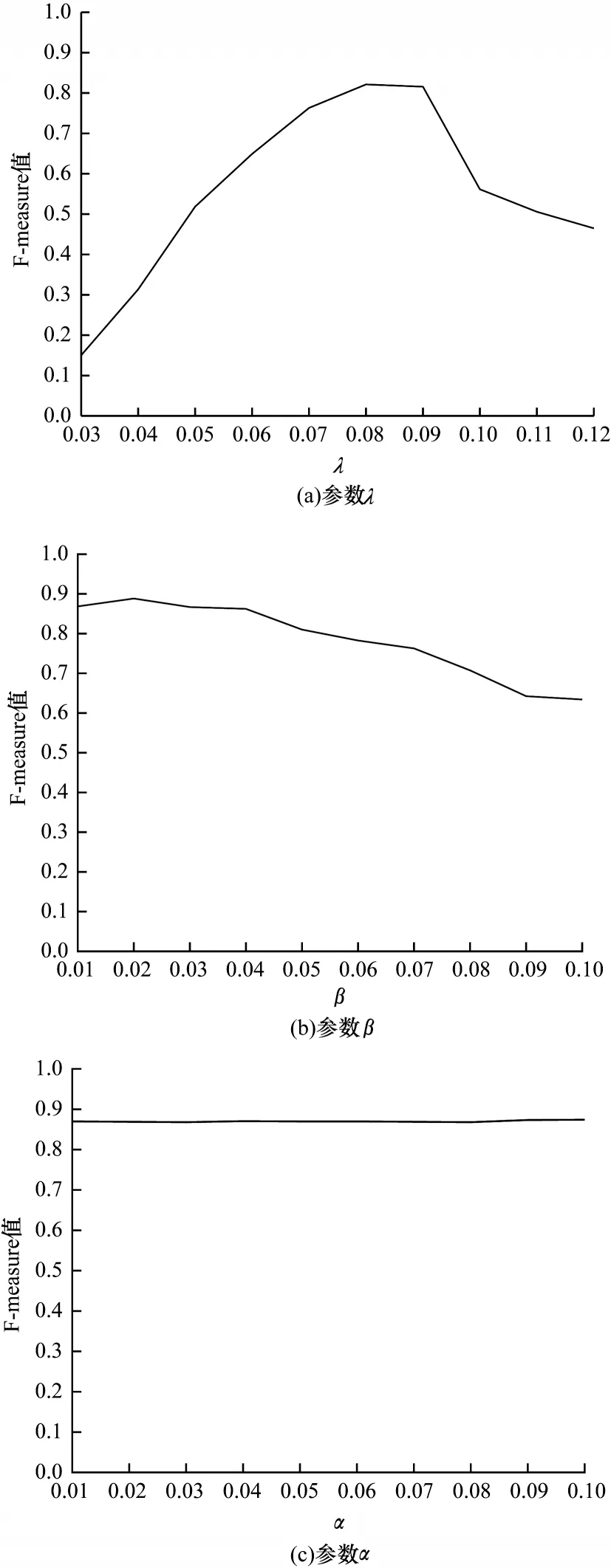
图4 F-measure 随参数取值的变化Fig.4 F-measure changing with parameters value
5 结束语
本文提出一种结合l1/2范数和显著性约束的背景减除模型。以RPCA 理论为基础,使用l1/2范数替代l1范数对视频前景作稀疏约束,减少由动态背景造成的干扰,提高前景检测的精确度。利用显著性约束对每一帧图像进行低秩稀疏分解,识别移动缓慢的物体,缓解了前景的空洞现象。实验结果表明,与主流模型相比,本文模型能有效去除动态背景对前景的干扰,且检测移动缓慢目标的效果较好,显著提高了移动目标检测精度。但当背景颜色和前景颜色相近时,本文模型容易出现误判的情况,因此后续将结合视频序列的颜色信息,进一步提升背景减除模型的检测精度和适用性。
猜你喜欢
山东第一医科大学(山东省医学科学院)学报(2022年7期)2023-01-05
波谱学杂志(2022年1期)2022-03-15
建材发展导向(2021年6期)2021-06-09
今日农业(2020年17期)2020-12-15
中国人兽共患病学报(2020年11期)2020-12-08
安阳工学院学报(2020年4期)2020-09-11
中国外汇(2019年11期)2019-08-27
小型微型计算机系统(2019年4期)2019-05-05
电子制作(2019年24期)2019-02-23
中国校外教育(下旬)(2017年8期)2017-10-30
