
面向图像目标识别的轻量化卷积神经网络
2022-06-16 05:25史宝岱李宇环
计算机工程 2022年6期
史宝岱,张 秦,李 瑶,李宇环
(空军工程大学 研究生学院,西安 710051)
0 概述
自深度学习[1]的概念被提出以来,图像分类领域迎来了重要的发展时期。深度学习方法有很多,包括自动编码器[2]、置信网络[3]、卷积神经网络[4],其中卷积神经网络在目前深度学习算法中占有重要地位。为了提高识别准确率,通常会使神经网络的结构更复杂、层数更深,如文献[5]提出的ALexNet 模型,含有61M 的参数量;文献[6]提出的ResNet50 模型,参数量达到了25M。但在现实生活中计算资源往往有限,载体趋向小型化、可移动,因此文献[7]提出的计算速度更快且保有相当准确率的神经网络更具实用性。
轻量化神经网络越来越为人们所重视,常见的做法是提出新的网络结构或者压缩现有的网络。Google提出面向嵌入式设备的小型轻量化网络MobileNets 系列,其中MobileNetV1[8]用深度可分离卷积替代了传统卷积,令每一个通道都包含了全部信息,达到模型压缩的目的。MobileNetV2[9]引入倒残差和线性瓶颈结构,进一步优化了网络;MobileNet V3[10]先利用文献[11]中的Mnasnet 进行粗略的搜索,再利用感知算法NetAdapt[12]进行搜索微调,在减少模型延时的同时保持了原有的精度水平。同样,文献[13]提出利用深度可分离卷积替换InceptionV3[14]的卷积操作,将通道相关性和空间相关性分开进行了处理,得到Xception 模型。此外,旷视科技提出可用于移动设备的ShuffleNet系列,其中ShuffleNetV1[15]引入了逐点群卷积和通道混洗,大幅减少了1×1 卷积操作的数量。文献[16]对现有网络进行了对比实验,得出4 条准则,进而改进得到ShuffleNetV2,该模型给算力有限的嵌入场景提供了一个高效的架构。
参数压缩的途径有模型蒸馏、低秩分解、网络剪裁、量化等。其中,模型蒸馏即知识蒸馏,将教师网络的经验迁移学习到学生网络中。TIAN 等[17]指出基础的知识蒸馏只适用于输出为类别的情况,并不适合跨模态蒸馏。网络裁剪的基本做法是剪除模型中不重要的部分,同时弱化对模型精度的损失,例如文献[18]提出一种利用偏置参数进行网络裁剪的方法,文献[19]提出一种基于灰色关联算法的剪枝方法。
移动式平台在生活中大量存在,但这些平台的存储能力有限,这就要求设计者在保持准确度的前提下,尽量降低网络模型的计算量。目前提出的网络在目标分类上也取得了较好的成果,但网络参数量和复杂度依然较高。
本文提出一种轻量化的卷积神经网络ConcatNet,通过采用特征拼接的方式,将深度可分离卷积、通道注意力和通道混洗有机地结合在一起,在保持一定准确率的同时,大幅降低参数量和计算复杂度。
1 相关工作
1.1 深度可分离卷积
与传统卷积相比,深度可分离卷积将通道域和空间域分开处理,可以在牺牲少量精确度的前提下,大幅降低模型所需的计算量和参数量,加快模型的处理速度。深度可分离卷积包括深度卷积Depthwise 和逐点卷积2 个结构,如图1 所示。
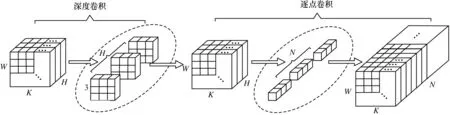
图1 深度可分离卷积结构Fig.1 Structure of depthwise separable convolution
在二维平面进行深度卷积操作,将单个卷积核应用到每个通道上,样本输入大小设为W×K×H,其中:W为图像高度;K为图像宽度;H为图像通道数。这里选用3×3×1 的卷积核,经过H个卷积操作后,得到H个W×K特征图。逐点卷积类似于普通卷积,可以对通道数进行调整。卷积核大小设为1×1×3,数量设为N,则最终得到W×K×N大小的特征图。
相对应的计算量为:
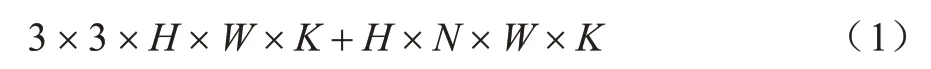
标准卷积对应的计算量为:

将深度可分离卷积和普通卷积的计算量相比,得到比值如下:
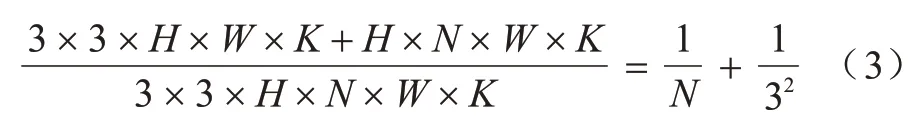
由上述公式可知,当卷积核大小为3×3 时,深度可分离卷积可以将参数量减少到普通卷积的1/9 左右,极大地增加了网络的运算速度,因此本文在构建模型时均采用深度可分离卷积。
1.2 通道混洗
通道混洗由ZHANG 等[15]提出,用于解决不同组之间信息不流通的问题。本文从特征图入手,将来自不同支路的特征图用concat 函数组合在一起,但拼接得到的特征只能在通道进行相加,信息流通不畅。虽然可以采用1×1 卷积混合通道间信息,但是会带来参数量大幅增加的问题。然而,通道混洗可以在不增加计算量和参数量的前提下,完成通道间的信息混合,增强分类效果,示意图如图2 所示。图2(a)是分组卷积后没有经过通道混洗的情况,各通道信息之间没有信息交换,因此无法保证最终分类的效果。图2(b)是在分组卷积之后加入了通道混洗,将分组后特征图均匀打乱并重新排列。本文利用通道混洗操作整合了支路信息,提升了模型运算的效率。
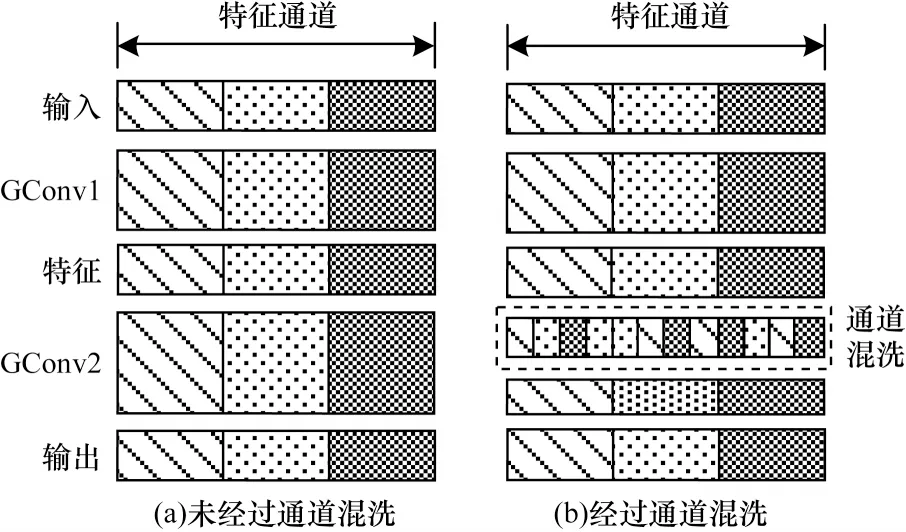
图2 通道混洗示意图Fig.2 Schematic diagram of channel shuffle
1.3 通道注意力
在计算机视觉领域,添加注意力机制已经成为提高模型性能的常用手段,文献[20]总结了注意力机制在自然语言处理、图像识别、语音识别等领域的应用现状。软性注意力是神经网络中的常用方式,主要分为通道注意力和空间注意力2 种,可以根据特征的重要程度生成对应的权重,从而合理分配算力。文献[21]提出挤压和激励网络,将ImageNet 数据集的Top-5 error 降到了2.251%,主要贡献是提出了通道注意力的一种实现方式,先利用全局平均池化将特征图压缩成一个实数,然后将这个实数输入到由2 个全连接层组成的小网络里,输出值是每个特征图对应的权重,最后将这个权重和原特征值相乘,从而让通道权重分配更加准确。
但仅采用全局平均池化获取特征图的信息并不够准确,因为一旦遇到正负激活值相抵的情况,特征图就会变模糊,进而造成信息丢失。为降低信息的损失,本文同时采用全局平均池化和全局随机池化提取中间特征图的信息,其中全局平均池化可以较好地保留背景信息,而全局随机池化按概率值选取特征,具有较强的泛化性,两者相结合可以减少信息的丢失。本文首先由2 种池化操作将输入特征图F分别压缩成2 个实数向量,令两者相加取平均值;接着,借鉴文献[22]提出的超轻量级通道注意力网络(Efficient Channel Attention Net,ECA-Net),并利用自适应一维卷积替代全连接层,完成局部的跨信道交互,如此只会增加很少的参数量。剩余的过程与ECA-Net 网络类似,最终得到了通道的权重,也避免了特征维度的降低,有助于提高准确率,详情可以参考文献[12]。M(F)的计算公式如式(4)所示:

其中:M(F)为经过通道注意力模块之后,输出的特征;σ代表sigmod 操作;CK代表卷积操作;K代表卷积核大小。本文在构建网络模型时加入了通道注意力模块,提升模型的信息提取能力。
2 网络构建
要想完成卷积神经网络的轻量化,就要用较简单的方式实现网络效率的最大化。本文提出的ConcatNet主要采用特征拼接的方式实现,ConcatNet的具体结构如图3所示,其中a、b、c分别1为3个支路的权值系数。
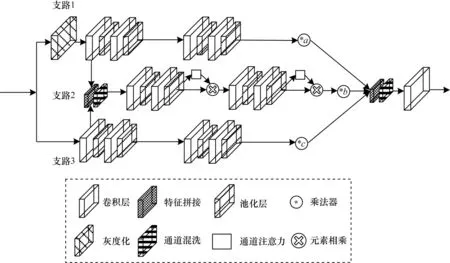
图3 ConcatNet 结构Fig.3 Structure of ConcatNet
相比于灰度图,彩色图像的颜色分布较复杂,传递的信息更丰富,含有的数据量更大,但处理的时间和难度也随之增大。而灰度图数据量小,便于处理,虽然缺失了一定的颜色等级,但从其亮度等级上看,与彩色图一致,两者各有利弊。为丰富特征输入的维度,本文将输入图像分为两路:1 支路转换为灰度图输入,3 支路直接输入,维持其彩色图特征,两路分开并行处理,经过一个卷积层后,将输出特征图拼接起来,构成2 支路,特征拼接利用concat 函数完成,但concat 函数只能完成通道数的叠加,并不能完成2 个支路信息的整合,因此采用通道混洗处理拼接之后的特征图。
图3 中1、2、3 支路用于特征提取的卷积层均由4 个3×3 卷积层构成,不同的是卷积核个数,这里卷积层的数量由实验得出,具体见下文。1 支路卷积核的个数分别是32、32、64 和128,2 支路卷积核的个数分别是96、192、384 和384,3 支路卷积核的个数分别是64、64、128 和256,在支路前3 个卷积层后添加一个最大池化用于去除冗余信息,在第4 个卷积层后添加一个全局平均池化用来代替全连接层,将特征图降成一维。为降低网络的参数量,完成网络的轻量化,本文采用深度可分离卷积。
为增强支路的特征提取能力,将有限的算力用在重要的特征上,考虑到卷积操作本身包含了空间注意力,拟在每条支路上加入2 个改进后的通道注意力模块,抑制通道域的无用信息,通过实验得出每条支路均加入2 个通道注意力模块效果最好。具体实验如下:首先,把3 条支路的输出值用concat 函数拼接起来并组合特征,将3 路通道进行叠加,加入通道注意力模块,在将拼接特征输入之前进行筛选,将有用支路的特征放大;之后,利用通道混洗加强通道间的信息流动;最后,采用1×1 卷积层代替全连接层进行分类,以避免破坏图像的空间结构,而且输入图像的尺寸不会受到限制,至此模型构建完毕。
3 实验与结果分析
3.1 数据集
本文首先在文献[23]总结公布的CIFAR-10、CIFAR-100这2个数据集上初步评测模型的效果,这2个数据集在图像分类领域中比较常用,而且两者较适用于训练轻量化神经网络,CIFAR-10 和CIFAR-100 数据集均含有60 000 张32×32 像素的图片,其中50 000 张用于训练,10 000 张用于测试,不同的是前者有10 个类别,而后者为100 个类别。因此CIFAR-100 数据集用于训练的图像就少于CIFAR-10 数据集,准确率也较低。之后,在大型的彩色光学数据集ImageNet 上测试模型效果,ImageNet 数据集共128 张,分为1 000 个类别,现已成为图像领域的标准数据集。
3.2 训练细节
将图像随机进行左右旋转以增加样本数量,为便于处理,将图像进行归一化。硬件:显卡为RTX2060,4 GB 独显,CPU 为i7-10750H,运行内存为16 GB。软件采用GPU 版本的tensorflow 1.14.0框架,python 3.1。采用步数作为迭代指标,而不用epoch,总步数设置为30 000,每一步训练的批量大小设置为64。初始学习率设为0.003,每过10 000 步,学习率降为上一次学习率的0.3 倍,采用随机梯度下降法,动量设置为0.9。为全面衡量算法性能的好坏,本文对算法模型的准确度、参数量、计算复杂度等参数进行分析。
3.3 支路卷积层对算法效果的影响
模型主要依靠支路的卷积层提取图像特征,除了卷积核的数量,3 条支路的卷积设置也相同。本实验在不插入通道模块的前提下完成,且支路末端的乘法器权值均设为1,依次将卷积块的数量设置为3、4、5,选用的数据集为CIFAR-10,实验结果如表1所示。
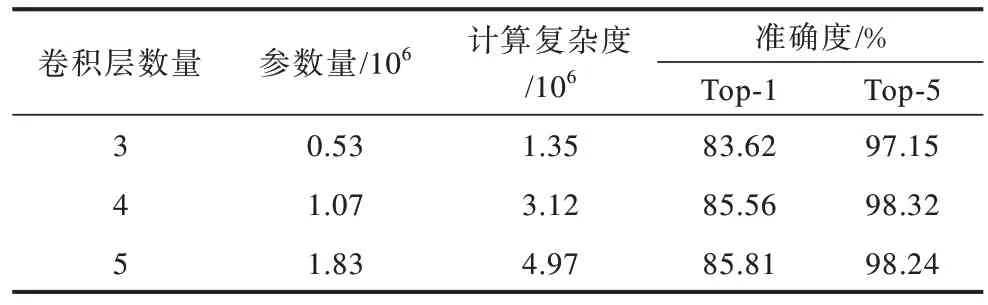
表1 支路卷积层的数量对比Table 1 Comparison of the number of branch convolution layers
由表1 可知,算法参数量和计算复杂度均随着卷积层的增加而增加,Top-1 和Top-5 精度大体也遵循此趋势,当卷积层数分别为4、5 时,两者精度相当,几乎没有提升,但参数量却增加了70%,计算复杂度增加了1.85×106,因此,本文选择在支路上设置4 个卷积层。
3.4 通道模块对算法效果的影响
要想在完成网络轻量化的同时保持精确度,通道注意力就显得尤为重要,其插入位置和插入的数量均需经过实验验证。本文在支路上设置2 个通道注意力模块,每条支路的卷积块数量定为4,支路末端权重均设为1,现在需要对放置通道模块的支路进行仿真对比,结果如表2 所示。
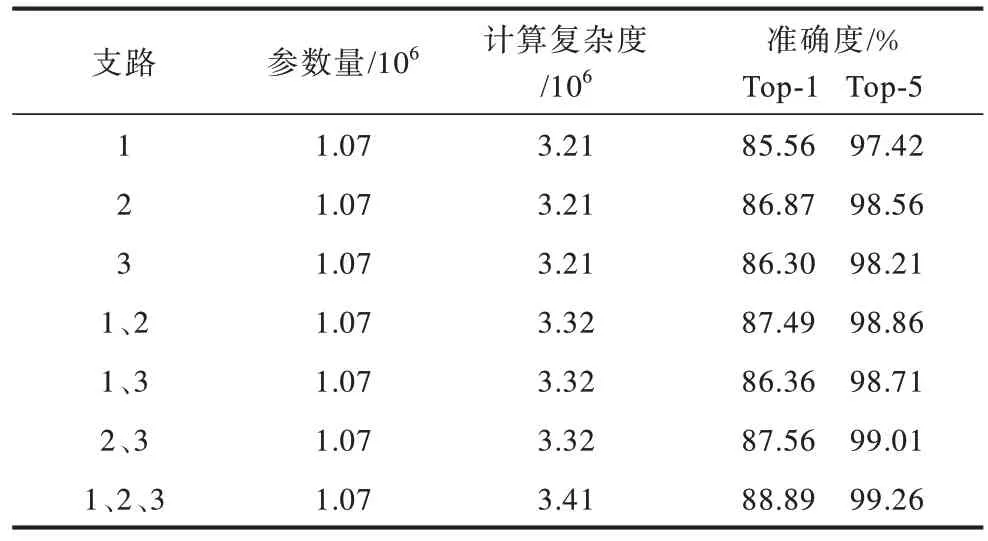
表2 通道注意力模块实验Table 2 Channel attention module experiment
由表2 可知,由于插入的通道模块只有一维卷积操作,因此无论在几个支路加入通道模块,参数量都几乎不会增加,但模型的复杂度会随着插入模块数量的增加而增加。当3 个支路均插入通道模块时,复杂度也只有3.41×106,不算高,但模型的准确率却达到实验最高值,所以本文选择在每条支路上均插入通道注意力模块。
3.5 迭代步数
本文用步数代替迭代周期,所以选择一个合适的步数尤为重要。本文先后将步数设置为20 000、25 000、30 000、35 000、40 000,把CIFAR-10 数据集Top-1 精度作为指标,实验结果如表3 所示。

表3 迭代步数实验Table 3 Iterative steps experiment
由表3 可知,当步数为30 000 时,识别率为88.89%,而当步数再增加时,网络发生了过拟合,识别率逐渐下降,因此本文将步数设置为30 000。
本文提出的ConcatNet 网络和其他轻量级网络在CIFAR-10数据集上的实验结果对比如表4所示。由表4可知,ConcatNet的Top-1 精度比MoblileNet1/2 的Top-1精度低1.27 个百分点,但Top-5 精度提高了0.12%,识别率相似,但参数量比MobileNetV2 减少了51.4%,计算复杂度比MobileNetV2 减少了44.8%,大幅降低了对计算平台的要求。
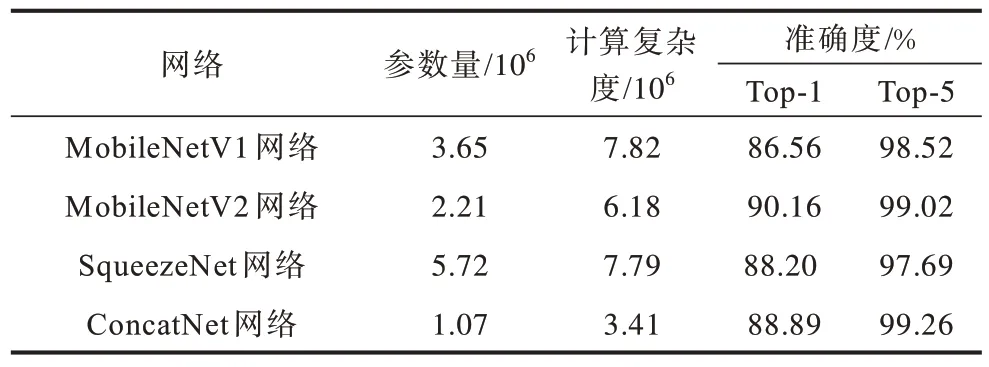
表4 轻量级网络在CIFAR-10 数据集上的对比Table 4 Comparison of lightweight networks on the CIFAR-10 data set
3.6 CIFAR-100 数据集上的实验结果
ConcatNet 模型在CIFAR-10 数据集上表现较好,但CIFAR-100 数据集比前者多了90 个类别,虽然超参数设置一样,但识别难度较大,其识别结果如表5 所示。由表5 可知,与MobileNetV2 相比,本文模型Top-1 和Top-5 的精度均要低1~2 个百分点,总体来说准确度相当,但参数量和计算复杂度均要低50%左右,在轻量化上更为先进。
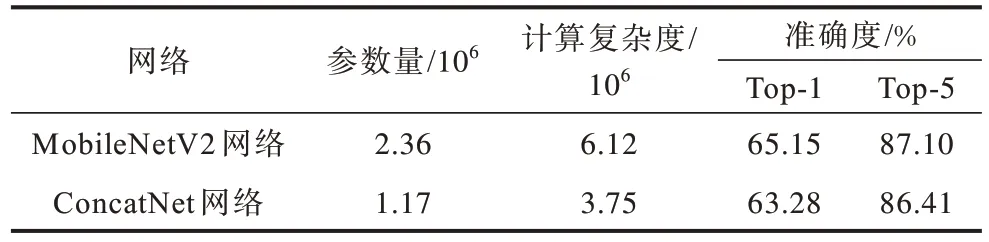
表5 轻量级网络在CIFAR-100 数据集上的对比Table 5 Comparison on the lightweight network CIFAR-100 data set
3.7 ImageNet 数据集上的实验结果
将实验批量大小设置为96,步数设置为50 000,其他超参数保持不变,将本文模型与MobileNetV2模型进行比较,实验结果如表6 所示,这两个网络的精度相近,但本文网络的参数量降低了43.52%,计算复杂度降低了39.73%。
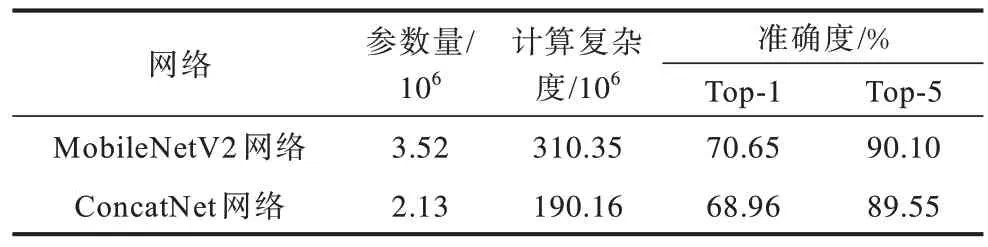
表6 轻量级网络在ImageNet 数据集上的对比Table 6 Comparison on the lightweight network ImageNet data set
4 结束语
本文提出一种轻量化的图像识别网络,利用特征拼接、通道混洗等方法构建3 条支路,并在支路卷积上采用深度可分离卷积。在输出阶段,采用先筛选再混洗的方式,从而在保持网络轻量化的同时,保证模型精度不降低。实验结果表明,与当前先进的轻量化卷积神经网络MobileNetV2 相比,本文网络在保持精确度相当的情况下,将网络参数量和复杂度降低了约50%。但实际应用环境较复杂,下一步将推进网络的轻量化研究,引入高效且轻量的注意力机制,增强该网络的泛化性、鲁棒性。
猜你喜欢
西安石油大学学报(自然科学版)(2022年5期)2022-10-08
小雪花·成长指南(2022年1期)2022-04-09
精密成形工程(2022年2期)2022-02-22
甘肃教育(2020年22期)2020-04-13
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
电机与控制学报(2018年9期)2018-05-14
科技与创新(2017年7期)2017-05-13
第二课堂(课外活动版)(2016年2期)2016-10-21
汽车维修技师(2016年11期)2016-05-05
