
关键词最优路径查询的分段拓展算法
2022-06-16 05:24刘蒙蒙牛保宁
计算机工程 2022年6期
刘蒙蒙,牛保宁,杨 茸
(太原理工大学信息与计算机学院,山西晋中 030600)
0 概述
随着人们对旅游路线需求的多样化,路径查询不只是常见的最短路径查询,人们通常会综合考虑路径时间开销、路径覆盖的兴趣点等其他因素[1-3]。考虑如下的场景:当用户想要去某些地方旅游时,希望找到一条从指定地点出发,途经满足用户指定的兴趣点,最后到达终点的路径,该路径在满足游客的行程预算(以下称为代价阈值)的前提下,所用时间越短越好。
关键词最优路径查询[3-4](Keyword-aware Optimal Route query,KOR)是一种在满足关键词全覆盖、路径代价阈值约束下,路径时间开销最小的路径查询类型,常用于旅行规划。KOR 求解的途径是路径拓展,现有求解算法本质上都是广度优先搜索——搜索规模随搜索深度指数级增加。缩小搜索规模主要的优化策略有近似支配剪枝[3]、可行解目标值剪枝[3]、关键词顶点拓展[5]、全局优先拓展[3]和最小代价剪枝[6]。这些优化策略在搜索深度浅的情况下是有效的,但是在搜索路径长或搜索深度较深的情况下搜索规模仍然难以控制。因此,避免长路径拓展过程中搜索深度过深是解决这一问题的关键。
受人类在规划长路线时先选取必须要经过的数个重要地点,然后分别针对各段路径进行规划的启发,本文提出一种关键词最优路径查询的分段拓展算法(SE-KOR),SE-KOR 根据<关键词:顶点>的关键词倒排索引表,构建{起点→关键词顶点1→……→关键词顶点n→终点}的关键词顶点路径,将路径分割为以关键词顶点为边界点的多段路径,并分别拓展,降低搜索深度,以避免搜索规模爆炸的问题。最终将各段路径拼接成完整的路径。
1 相关工作
路径拓展算法分为启发式搜索和广度优先搜索。启发式搜索代表算法KDR[7]和Greedy[3]通过得分函数仅对关键词覆盖的顶点拓展,具有较高的执行效率,但返回结果本质上是关键词顶点的最优排序,不是具体路径。广度优先搜索代表算法KSRG[5]仅对关键词顶点拓展,具有较高的执行效率,但返回结果依旧是最优关键词顶点序列,在后续优化中,KSRG[6]利用Skyline 路径实现具体路径查询,但预处理工作获取Skyline 路径的时空开销巨大;KORL[6]利用树形索引将大图分而治之并在预处理中求取Skyline 路径,在拓展阶段需要对压缩图进行复原计算,产生大量中间拓展操作;OSScalling[3]、BucketBound[3]进行邻边拓展,在面临长路径搜索时,易出现搜索规模过大而耗时较长的问题。
在剪枝策略方面,现有策略主要有支配、近似支配、可行解目标值、全局优先拓展、关键词顶点拓展和最小代价剪枝。OSScalling[3]、BucketBound[3]运用支配、可行解目标值和全局优先拓展对中间路径剪枝。KSRG[5]提出关键词顶点拓展,跳过与关键词不相关的节点并利用近似支配剪枝。KORL[8]提出最小代价剪枝,剪去不满足代价阈值的中间路径,但现有剪枝策略不控制路径拓展方向。
除上述KOR 算法外,其他关键词的查询也得到广泛研究。基于关键词的最优位置查询[9-11]查找关键词全覆盖下距离各点最近的位置,空间组关键词查询[12-14]检索最接近查询位置且顶点间距离最短的关键词顶点序列。室内关键词感知路径规划[15-16]研究复杂室内场景下的关键词覆盖路径查询问题。多用户空间关键词[17-18]路线查询针对多用户查找关键词全覆盖、代价最小的路径,对多用户场景下的KOR 具有启发意义,但以上算法不适用于KOR问题。
为解决路径拓展不具体和长路径搜索耗时长的问题,本文提出关键词最优路径查询的分段拓展算法(SE-KOR),构建关键词顶点路径作为路径边界,将路径划分为多段分别拓展,并且采用局部代价阈值剪枝,保证路径拓展沿关键词顶点路径方向。本文算法的创新点如下:
1)针对广度优先搜索方式遍历顶点、查找兴趣点耗时长的问题,提出一种基于关键词倒排索引表构建关键词顶点路径的方法;以关键词顶点为边界点,把该路径分为多段并分段拓展,降低搜索深度,从而降低搜索规模,缩短执行时间。
2)针对现有剪枝策略不控制路径拓展方向的问题,本文提出局部代价剪枝,控制路径的走向沿着关键词顶点路径的方向拓展,并综合利用近似支配剪枝、可行解目标值剪枝和全局优先拓展,加速拓展过程。
2 KOR 及其求解框架
求解KOR 是一个NP-hard 问题[3],约束条件分别为关键词全覆盖、满足代价阈值以及目标值最优化。本节给出KOR 定义,介绍KOR 求解框架。
2.1 符号说明
为方便阅读,首先给出常用符号的说明,如表1所示。
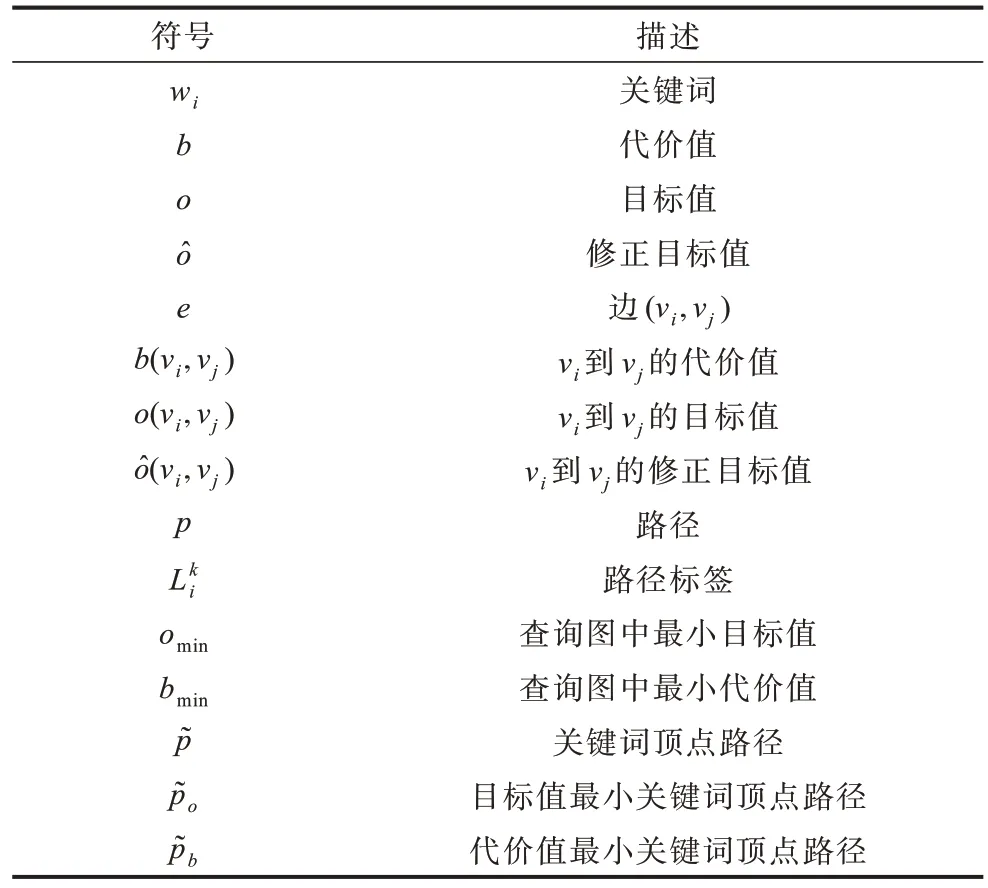
表1 符号说明表Table 1 Symbol description table
2.2 问题定义
关键词最优路径查询主要基于路网,路网可以抽象成如图1 所示的查询图。
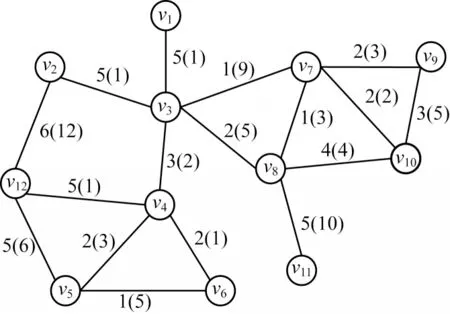
图1 查询图结构Fig.1 Query graph structure
定义1(查询图)[3]G=(V,E)由顶点集V和边集E构成。任意v∈V表示兴趣点,v的地理位置用经纬度表示,记为v.loc,v的关键词集合表示为v.φ={v.w1,v.w2,…}。连接邻接点vi和vj的路径(vi,vj)称为边,记为e,e∈E。每条边有两个属性:代价值b(vi,vj)和目标值o(vi,vj)。
如图1 所示,通常代价值表示边的长度,用括号外的数值表示;目标值表示经过边所需要的时间,用括号内的数值表示。表2 列出图1 中各顶点对应的关键词集合[5]。

表2 顶点关键词信息Table 2 Vertex keywords information
定义2(路径)p=(v0,v1,…,vn)表示一条从v0出发,经过v1,v2,…,vn-1,到达vn的路径,p覆盖的关键词表示为p.φ=。
根据定义2,路径p的代价值和目标值分别为:。
定义3(KOR)一个KOR 查询Q是一个四元组Q=(vs,vt,φ,Δ),vs、vt、φ和Δ 分别表示路径起点、终点、覆盖的关键词集合和代价阈值。用ps,t表示从vs到vt的路径集合,pcand表示满足关键词全覆盖和代价阈值的可行路径p的集合,即pcand={p|p∈ps,t∩p.φ⊇Q.φ∩b(p)≤Δ},则KOR的最优路径popt=。
2.3 KOR 求解框架
现有KOR 求解方法的核心是路径拓展,以降低路径拓展代价为目标,组合运用多种剪枝策略,预先计算剪枝时的代价值和目标值。KOR 的求解框架如图2 所示,包括预处理和路径拓展两部分。预处理部分预先计算路径拓展过程中用到的路网中任意两个顶点间的最小代价值和最小目标值,避免不同KOR 的重复计算;在路网更新时同步更新。路径拓展部分综合运用多种剪枝策略,尽可能地降低拓展代价。剪枝策略分为路径剪枝和可行解剪枝两方面。路径剪枝包括支配剪枝、目标修正的近似支配剪枝、全局优先拓展剪枝等。这些剪枝策略可以单独或组合运用,以低的代价得到可行解集合。然后利用可行解剪枝中的可行解目标值剪枝获取最优解。

图2 KOR 求解框架Fig.2 KOR solution framework
KOR 的求解过程主要是路径拓展的过程。为方便描述路径拓展过程,下面先给出路径标签和标签操作的定义。
定义4(路径标签)对任意从vs拓展至vi的路径p,在顶点vi处构建路径标签,4 个 参数分别代表路径p覆盖的关键词集合、修正目标值、目标值和代价值。路径标签简称标签。
定义5(标签操作)由顶点vi的标签向它的邻接顶点vj拓展生成新标签。新标签根据的当前顶点vi到顶点vj的o、b构建,满足以下条件:
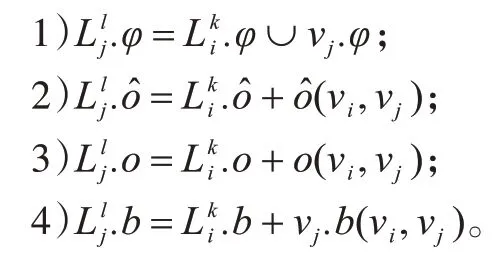
KOR 求解过程如下:
1)从起点开始邻边拓展,对于拓展到新的顶点,记录从起点到该顶点的一个标签,如中包括已经包含的关键词、修正目标值、o、b,并计算该标签的全局优先度,优先度越小,优先级别越高,然后入队。
2)根据全局优先拓展策略,选择优先级最高的路径标签出队,向下一个顶点拓展。
3)根据支配剪枝或者近似支配剪枝策略,判断当前路径是否被支配,若被支配则舍弃,继续下一轮拓展,否则入队。
4)如果当前路径满足关键词全覆盖和代价阈值,若此时可行解集合中为空,当前标签进入可行解集合,否则与现有可行解对比,保留目标值最小的可行解,即可行解目标值剪枝。
5)以此类推,直到优先队列中所有标签为空,返回一个目标值最小的可行解作为最优解。
两个部分相关定义及定理如下:
1)预处理
预处理阶段包括两部分:(1)利用Floyd[19]算法,计算查询图中任意两顶点间的最小代价值b(vi,vj)及最小代价值对应的目标值oσ(vi,vj)和最小目标值o(vi,vj)及最小目标值对应的代价值bτ(vi,vj),同时记录G=(V,E)中的最小代价值bmin和最小目标值omin,并保存在内存中;(2)关键词倒排索引[20]构建,将兴趣点的所有关键词信息{v.w1,v.w2,…}组合成非重合的关键词集合,构建关键词倒排索引表,记录关键词对应的兴趣点,如表3 所示。
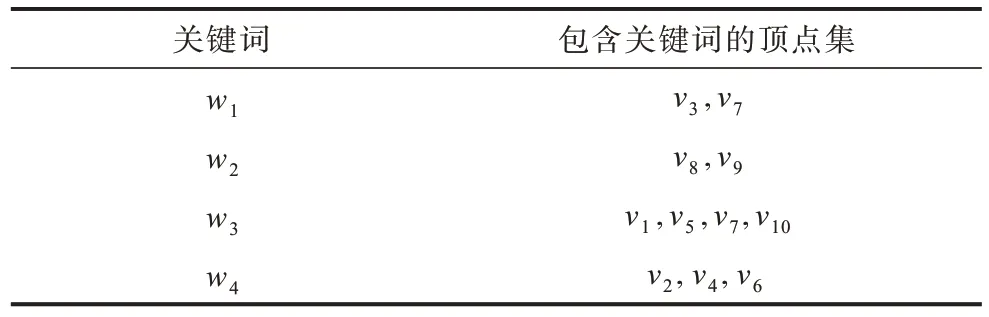
表3 关键词倒排索引表Table 3 Keyword inverted index table
2)路径拓展策略
本文算法基于上述算法框架,用到的拓展策略有目标修正的近似支配剪枝和全局优先拓展剪枝。
定义6(目标修正)给定查询图G=(V,E)和查询Q=(vs,vt,φ,Δ),已知标签,最小代价值bmin,最小目标值omin,其修正目标值为被称为修正比例,其中0<ε<1。
修正目标值用于近似支配剪枝。
定理1每个顶点最多存储标签的个数为[3]:
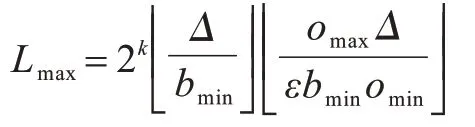
其中:k=|φ|为关键词个数。
证明首先给定k个查询关键词,最多有2k个关键词子集。其次给定代价阈值Δ,算法检查一条路经的边数不超过。其中,bmin为查询图G中最短边的代价值。因此,在G中路径的目标值以为界。综上,每个顶点最多存储的路径标签为Lmax=,其他具有相同目标值的标签都会被近似支配。
定理2经过目标修正获得的最优解pos目标值与实际最优解popt的目标值有如下关系:o(pos)≤·o(popt)[3]。
证明由定义6 可知,,0<θ<1,以下将、o(vi,vj)分别简称为和o。推导可知,,因此(e为p中的边),继而:
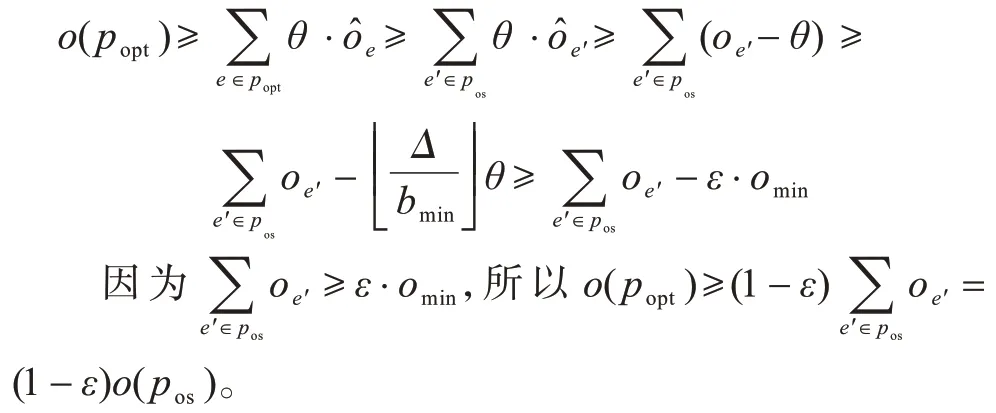
定义7(近似支配)假设给定一个稍大于1 的参数α(如α=1.1),路径pi、pj的起点和终点相同,若pj.φ⊆pi.φ且,则路径pj被pi近似支配,pj被剪枝。
定理3经过近似支配的最优解pdom的目标值与pos的目标值有如下关系:o(pdom)≤α·o(pos)[6]。
证明由定义7 可知,pj被pi近似支配时,被放大α倍,同理对于pdom和pos有关系:o(pdom)≤α·o(pos)。
定理4pdom的目标值与popt的目标值有如下关系:o(pdom)≤·o(popt)。
证明由定理3 可知,o(pdom)≤α·o(pos),联立定理2 可得o(pdom)≤α·o(pos)≤·o(popt)。
定义8(全局优先级)从vs到vt的最小目标值为o(vs,vt)。设置参量β(1<β<2),标签的全局优先度表示为,全局优先度越小,全局优先级越高。
3 SE-KOR 算法
SE-KOR 的核心思想是构建关键词顶点路径,将路径按照关键词顶点的次序分为多段并分段拓展。因此,本节重点介绍关键词顶点路径的构建和分段拓展的关键技术。
3.1 关键词顶点路径的构建
按照KOR 的求解框架,预处理阶段已经计算出查询图中任意两顶点间的b(vi,vj)、o(vi,vj),保证了任意两顶点之间都是可达的。因此,对于查询Q=(vs,vt,φ,Δ),在构建关键词顶点路径时,可以隐藏查询图G=(V,E)中没有被φ覆盖的顶点,保留起点、终点和φ覆盖的顶点,形成查询的关键词顶点查询图G′。针对G′进行拓展,获取满足关键词全覆盖和代价阈值的关键词顶点路径。
定义9(关键词顶点)给定查询Q=(vs,vt,φ,Δ),若关键词wi∈vm.φ,则称vm是包含关键词wi的一个顶点,简称关键词顶点。
定义10(关键词顶点路径)给定Q=(vs,vt,φ,Δ),φ={w1,w2,…,wn},从vs开始不断检查未覆盖的关键词,并向相应的顶点拓展,获得从vs扩展到vt的、满足关键词全覆盖和代价阈值的路径,不失一般性,记为,称为关键词顶点路径。
定理5给定任意可行路径,都存在一条关键词顶点路径与其一一对应。
证明可行路径指满足关键词全覆盖、代价阈值的路径,由定义10 可知,关键词顶点路径同样满足上述约束条件。
定义11(局部代价阈值)在构建过程中,每拓展至一个关键词顶点,记录到达当前节点的代价值,称为局部代价阈值。
1)针对查询图G=(V,E)和查询Q=(vs,vt,φ,Δ),隐藏没有被φ覆盖的顶点,保留起点、终点和φ覆盖的顶点,形成查询的关键词顶点查询图G′。在实现过程中,可以直接根据关键词倒排索引列表获取关键词顶点,形成查询图G′。
2)在G′上利用广度优先搜索,拓展满足关键词全覆盖和代价阈值的路径,记为关键词顶点路径。
下文用一个实例说明关键词顶点路径的构建过程。在如图3 所示的查询图中,颜色和形状(菱形和三角形)相同的顶点包含相同的关键词,虚线连接的是关键词顶点路径。
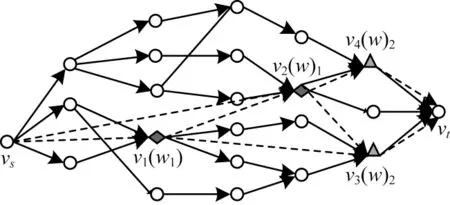
图3 关键词顶点路径示意图Fig.3 Schematic diagram of keyword vertex path

图4 关键词顶点路径构建示意图Fig.4 Schematic diagram of keyword vertex path constructio
1)在vs处构建初始标签。
2)从起点开始向所有关键词顶点拓展,构建从vs到关键词顶点的标签,并计算全局优先度后入队。
3)选取全局优先级最高的标签出队,这里假设v1顶点处的出队,此时已经包含关键词w1,向尚未包含的关键词w2覆盖的顶点v3、v4拓展构建标签,并判断新标签是否满足代价阈值和近似支配条件,若满足则入队,否则被删除。
4)继续选取优先级别最高的标签拓展,重复过程3),直至拓展至终点vt,选取满足关键词全覆盖、代价阈值和目标值最小的标签记为。
拓展结果体现在如图5 所示的G′中,v2、v4是在构建时被舍弃的关键词顶点。
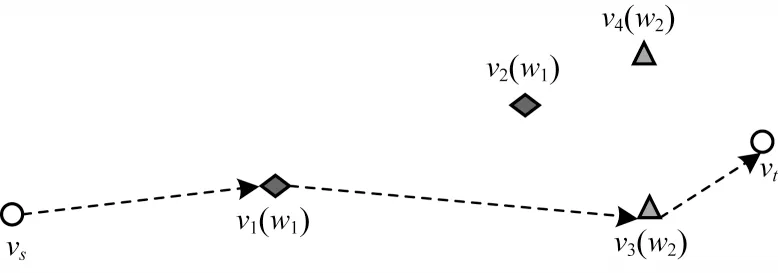
图5 关键词顶点路径示例Fig.5 Keyword vertex path example
3.2 分段拓展和拓展方向的控制
分段拓展补充起点到关键词顶点、关键词顶点之间以及关键词顶点到终点之间的路径,如图5 中vs→v1、v1→v3、v1→vt的路径。
对每一分段采用广度优先搜索,根据局部代价阈值、可行解目标值的约束分别对其进行拓展。在关键词顶点路径的基础上拓展,搜索规模缩减至仅与关键词顶点路径中相关的顶点的局部图,很大程度上降低了路径查询中搜索的规模。
在分段拓展过程中的一个问题是:需要避免分段之间的交叉,即控制拓展方向避免分段之间的交叉。一种解决方案是:利用已经求出的局部代价阈值,进行局部代价阈值剪枝,约束每一段路径的代价值,从而达到控制路径方向,避免分段路径的交叉。
在对每个分段拓展时,将代价阈值约束条件替换为局部代价阈值。如图6 所示,在拓展分段vs→v1时,判断从vs经过白色顶点到v1的上下两条路径p1、p2的代价值b(p1)、b(p2)是否小于等于v1处的局部代价阈值,若是则入队,否则被舍弃。如此,路径拓展方向朝向违背的方向时,会被即时剪枝,避免各分段路径的交叉,控制拓展方向。
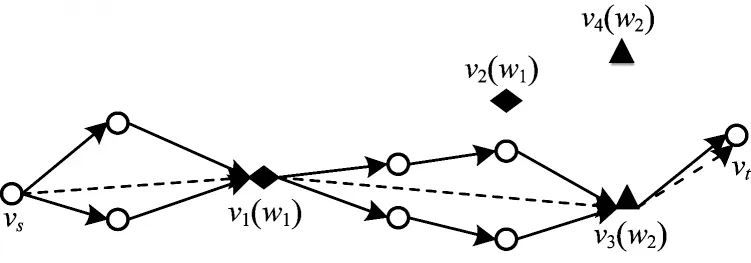
图6 分段拓展示意图Fig.6 Schematic diagram of segmented expansion
3.3 查询近似度分析
现有算法通过邻边拓展求取途径关键词顶点,且满足代价阈值时点与点之间的最短路径,将其划分为子问题可以看作是以关键词顶点为界的每一段路径的拼接。本质上邻边拓展方法是边拓展边判断一个顶点是否为关键词顶点。由定理5 可知,任意一条可行路径与一条关键词顶点路径一一对应。而SE-KOR 根据关键词倒排索引表直接获取关键词顶点,并依据预处理求取目标值最小关键词顶点路径以及代价值最小关键词顶点路径作为路径分段依据,进行分段拓展,大幅减小了搜索规模。因此,SE-KOR 算法具有可行性。
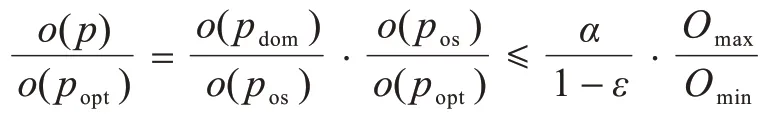
由上式可知,使用SE-KOR 算法返回的与最优解误差在最坏情况下不超过,α是一个稍大于1 的数值,在可控范围内。
3.4 算法描述
SE-KOR 算法由计算关键词顶点路径的comKeywordVertexPath()函数和分段拓展的主程序两部分组成。
SE-KOR 算法主程序如下:



运行示例:给出Q={v1,v10,


下面分析算法的时间和空间复杂度:
1)时间复杂度

2)空间复杂度
在分段拓展过程中,将路径划分为s+1(s+1≥1)段路径。假设整条路径需要遍历n(n≤|V|)个节点,当路径被划分为s+1 段时,则每段路径平均遍历个节点,因此每个顶点标签个数的上界为,则s+1段路径共需维护个标签,空间复杂度为。
4 实验结果与分析
上文已经给出SE-KOR 的实现过程和算法步骤,本节通过实验验证SE-KOR 在执行时间上的优越性,并对执行时间与近似度进行分析。
4.1 实验设定
实验设计如下:
1)实验环境与数据集
实验环境:win10,运行在Intel®CoreTMi7-8550U处理器和16 GB 内存上。算法使用Java 在IntelliJ IDEA 上实现。数据从公开的路网数据集中下载,并随机生成关键词信息。数据集信息如表4 所示。

表4 不同规模数据查询Table 4 Data query of different scales
2)实验设计
由于KORL 的预处理阶段与SE-KOR 的预处理有所不同,且面向大规模数据集,Greedy、KSRG 没有实现具体路径的查找,因此仅与OSScalling、BucketBound 算法对比。针对关键词个数、代价阈值、查询图规模等查询因素,设置实验1~实验3,取平均查询时间和平均近似度为评价标准。
实验1关键词个数不同时算法的执行时间
控制数据集和代价阈值不变,改变关键词个数。查询图为G3,代价阈值为40 km,关键词个数为2、4、6、8,分别对3 个算法进行测试,随机提交5 个查询,取平均执行时间和平均近似度。
实验2代价阈值不同时算法执行时间
控制数据集和关键词个数不变,改变代价阈值。查询图为G3,关键词个数是4,代价阈值为45 km、55 km、65 km、75 km、85 km,分别对3 个算法进行测试,随机提交5 个查询,取平均执行时间和平均近似度。
实验3查询图规模不同时算法的执行时间
控制关键词个数和代价阈值不变,改变查询图规模。代价阈值为55 km,关键词个数为6,分别对3 个算法进行测试,随机提交5 个查询,取平均执行时间和平均近似度。
4.2 实验结果
本节分别给出3 个查询因素下SE-KOR 的执行时间和近似度的实验结果,并加以分析。
4.2.1 不同查询因素下算法的执行时间
不同查询因素下算法的执行时间主要有以下3 种:
1)不同关键词个数下算法的执行时间实验1 结果如图7 所示,随着关键词个数的增长,SE-KOR 的执行时间明显短于对比算法,当关键词个数为2 时,SE-KOR 执行时间至少缩短8.0%。OSScalling 是邻边拓展,当关键词个数增加时,搜索规模也随之增加。虽然BucketBound 将优先级队列划分为多个bucket,但邻边拓展的本质没变。而SE-KOR 将路径划分为多段,有效降低搜索规模,缩短了执行时间。

图7 不同关键词个数下算法的执行时间Fig.7 Execution time of algorithm under different keyword numbers
2)不同代价阈值下算法的执行时间
实验2 结果如图8 所示,当代价阈值增大时,查询时间呈先增长后稳定的趋势,且SE-KOR 的执行时间较BucketBound 至少缩短61.0%。针对另外两种算法,当代价阈值持续增加时,最优解不会发生变化,查询时间由高趋于稳定。而SE-KOR 的查询时间与构建关键词顶点路径有关,因此查询时间的峰值点与另外两种算法有所不同,但走向基本一致。
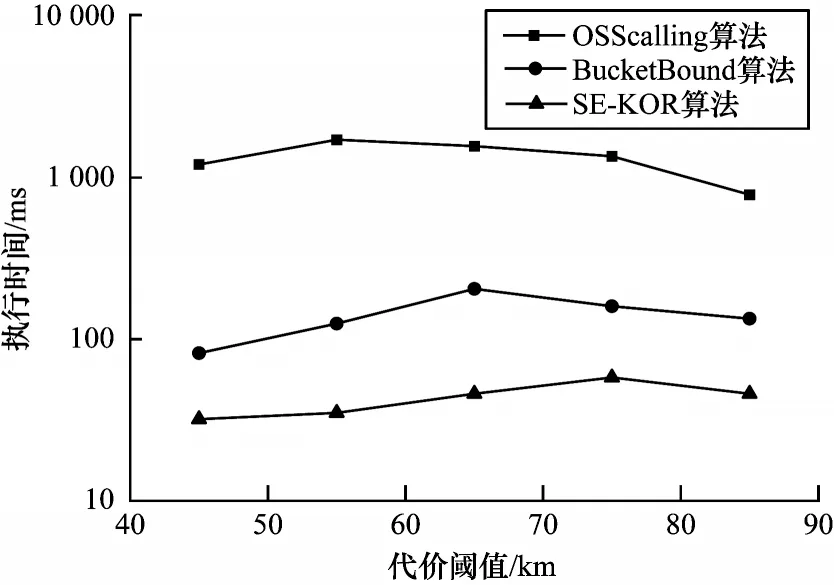
图8 不同代价阈值下算法的执行时间Fig.8 Execution time of algorithm under different cost thresholds
3)不同查询图规模下算法的执行时间
实验3 结果如图9 所示,随着查询图规模的增大,SE-KOR 的查询时间较另外两种算法缓慢增长,且SE-KOR 执行时间至少缩短57.7%。随着查询图规模不断增大,另外两种算法因大量中间拓展操作,造成搜索规模越来越大。而SE-KOR 将路径划分为多段拓展,能有效避免拓展过程中产生的大量拓展操作,从而显著缩短执行时间。

图9 不同查询图规模下算法的执行时间Fig.9 Execution time of algorithm under different query graph scales
4.2.2 不同查询因素下的近似度分析
不同查询因素下的近似度分析主要有以下2 种:
1)不同关键词个数下的近似度分析
实验1 的近似度曲线如图10 所示,在不同关键词个数下,SE-KOR 的近似度与另外两种算法相差无几,甚至会出现优于BucketBound 的情况。而OSScalling、BucketBound 求的近似解在实际最优解处波动。
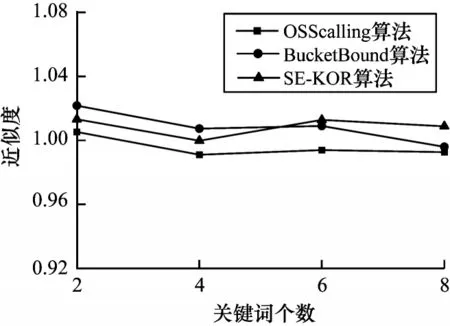
图10 不同关键词个数下算法的近似度Fig.10 Approximation of algorithm under different keyword numbers
2)不同代价阈值下的近似度分析
实验2 的近似度曲线如图11 所示,在不同代价阈值的约束下,SE-KOR 的近似度趋于稳定,而另外两种算法的近似度有所浮动。这是因为代价阈值越大,前期构建路径边界时越容易找到目标值最小关键词顶点路径。而另外两种算法依旧是逐步筛选中间路径,直到找到近似最优解,因此会有波动。
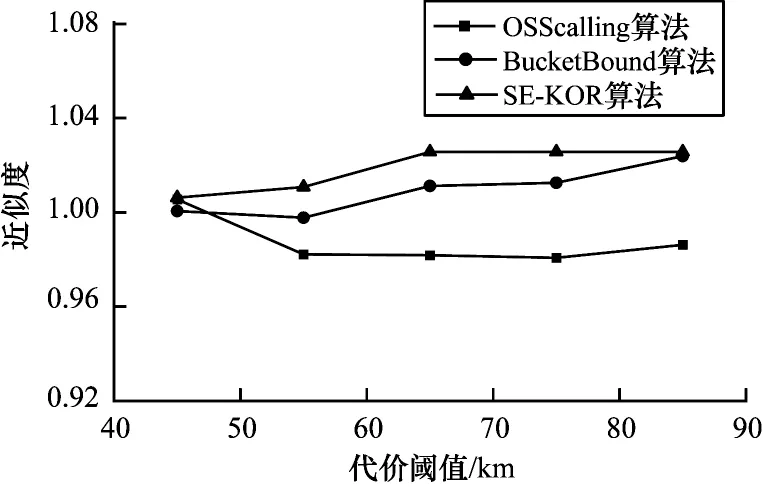
图11 不同代价阈值下算法的近似度Fig.11 Approximation of algorithm under different cost thresholds
5 结束语
针对现有KOR 算法在搜索长路径时执行时间较长的问题,提出SE-KOR 算法将路径划分为多段并分别拓展。SE-KOR 算法根据关键词倒排索引列表对关键词顶点拓展,获得目标值最小关键词顶点路径以及代价值最小关键词顶点路径,以此为依据,将路径以关键词顶点为边界节点,把路径划分为多个分段。在分段拓展中采用局部代价阈值以及综合运用近似支配、可行解目标值剪枝、全局优先拓展等剪枝策略加速拓展。实验结果表明,SE-KOR 算法能够显著缩短执行时间,且不损失精度。下一步将对现有单源[21-23和全源[24-26]最短路径进行研究,提出合适拓展策略降低各个分段路径的关联度,并行拓展每个分段路径,最终将各分段路径拼接,形成完整的路径。
猜你喜欢
保健医苑(2022年5期)2022-06-10
成都信息工程大学学报(2021年6期)2021-02-12
电子产品世界(2021年6期)2021-02-10
电子产品世界(2021年5期)2021-02-09
计算机应用(2020年5期)2020-06-07
海峡姐妹(2017年12期)2018-01-31
语文世界(初中版)(2017年5期)2017-06-22
作文与考试·初中版(2017年12期)2017-04-19
天津诗人(2017年2期)2017-03-16
大陆桥视野·下(2017年1期)2017-03-09
