
基于标签相关性的K 近邻多标签学习
2022-06-16 05:24韩京宇
计算机工程 2022年6期
钱 龙,赵 静,韩京宇,毛 毅
(南京邮电大学 计算机学院,南京 210023)
0 概述
多标签学习广泛存在于真实世界中。在文档分类问题[1-3]中,每篇文档可能隶属于多个预定义的主题,如“经济”与“文化”;在场景分类[4]问题中,每个场景图片可能属于多个语义类别,如“海滩”和“城市”;在ECG 心电异常检测[5]问题中,每个病人可能同时具有多种心脏疾病,如“完全性左束支阻滞”“前壁心肌梗死”以及“下壁心肌梗死”。对于上述多标签学习问题,训练集中的每条样本对应一组标签,学习系统通过对训练集进行学习从而完成对未知样本标签集的预测。
如果限定每个样本只对应一个标签,那么传统的二分类以及多分类问题均可看作多标签学习问题的特例。相较二分类以及多分类问题,多标签学习的难点在于随着标签数量的增加,待预测的标签组合数量呈指数级增长[6],从而导致分类器的计算成本过高,例如,一个具有20 个标签的数据集,每条样本对应的标签组合一共有220种,且各个标签组合对应的训练样本数不平衡[7],会进一步增加学习的难度。在解决此类问题时,一种直观的做法是将其转换为多个独立的二分类问题来求解[8],其中,每个二分类问题对应一个可能的标签。然而,此种做法忽略了样本标签间的相关性[9-11],因此,其泛化性能往往并不理想。例如,在ECG 心电异常检测问题中[5],如果已知一个病人具有下壁心肌梗死疾病,则该病人具有前壁心肌梗死疾病的可能性将大于完全性左束支阻滞疾病[5]。因此,有效利用标签间的相关性是解决多标签学习问题的关键。
根据多标签学习中考虑的标签关联程度,可以将现有方法分为一阶策略、二阶策略和高阶策略3 类[12]:一阶策略是将每个标签看成是独立不相关的,不考虑标签间的相关性;二阶策略利用了标签成对的关联信息;高阶策略考虑每个标签对其他标签的影响。LP 算法[13]将多标签问题转换为多分类问题,虽然其考虑了标签间的相关性,但标签组合的爆炸提高了算法的复杂度。TSOUMAKAS 等[14]提出Random k-Labelsets 算法,该算法将集成学习与LP算法[13]相结合,将原始的标签集分成若干子标签集,使用LP 技术训练相应的分类器,但是,该算法对于标签子集的选择是随机的,没有充分利用标签集间的相关性。READ 等[15]提出了分类器链(Classifier Chain,CC)算法,该算法将先预测出的标签作为后续待预测标签的输入特征,CC 算法虽然考虑到了标签间的相关性,但其结果依赖于标签预测的顺序,前面预测的标签误差会传递到后面的标签中,如果前面的标签误差较大,将会导致算法整体分类性能不佳。YANG 等[16]提出深度森林的多标签学习(Multilabel Learning with Deep Forest,MLDF)算法,MLDF算法通过设计多层结构来学习标签之间的相关性,使得深度森林模型适用于多标签分类场景。
本文提出一种双模态、阈值自调节的多标签学习K 近邻算法,该算法的核心思想是根据标签相关性的双模态来构建预测模型,其中,一种模态是某些标签和其他标签具有多阶相关性,另一种模态是某些标签和其他标签是独立的。使用Fp_growth[17]算法挖掘标签集的频繁项,明确数据集本身固有的标签高阶关系,然后基于本文算法为高阶标签关系建模,评估样本标签集合是每一种频繁项的可能性,如果标签高阶关系模型不能预测出样本的标签集合,说明该样本具有的标签间相关性并不强,则使用一阶策略完成该样本标签集的预测。在此基础上,提出一种阈值自学习算法,该算法采用通用的Beta 分布[18]描述阈值分布,基于每个频繁项和标签在原始特征空间上选择出对应的特征子空间,针对特征子空间中的每条样本,根据相应的评分模型获取相应的概率,用于更新Beta 分布的参数α和β,使得阈值更加准确地拟合样本分布,从而提高模型的预测性能。
1 问题描述与解决方案
1.1 问题描述
设D={(xi,Yi)|1≤i≤m}(xi∈X,Yi⊂Y)为给定的多标签数据集,其中,X=Rd表示d维的样本空间,Y={l1,l2,…,lq}表示所有可能的标签,q是标签数量,xi是第i条训练样本实例,Yi∈Y为样本xi对应的标签集。
本文目的是基于标签相关性的双模态分别构建2 个分类器:
1)第一个分类器是h1(x),该分类器输出一个实值函数f:X×P→R,对于给定样本x及频繁项Pj(1≤j≤k),分类器h1(x)输出的函数值量化样本x与频繁项Pj相关性得分的大小,频繁项由Fp_growth[17]算法挖掘得到,P={P1,P2,…,Pk}为频繁项集,k为频繁项个数。分类器h1(·)可由f(·,·)求得:
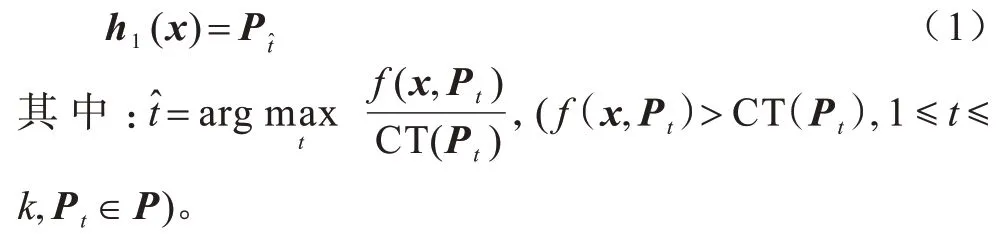
其中:CT(Pt)是频繁项Pt对应的阈值,本文称为关联阈值。
2)第二个分类器是h2(x),该分类器输出一个实值函数g:X×Y→R,对于给定样本x和标签lj(1≤j≤q),分类器h2(x)输出的函数值可以量化样本x与标签lj相关性得分的大小。分类器h2(·)可由g(·,·)求得:
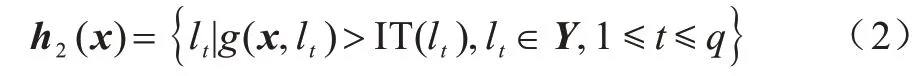
其中:IT(lt)是标签lt对应的阈值,本文称为独立阈值。
当频繁项相关性得分大于对应的关联阈值且该频繁项得分是所有频繁项中的最大值时,样本的标签集就是该频繁项。当通过多标签分类器h1(x)预测样本的标签为空集时,说明样本的标签集并不在频繁项集中,验证了样本标签间的相关性并不大,此时再使用分类器h2(x)预测样本的标签集,从而兼顾标签间多种可能的相关性。
定义1(特征子空间)在多标签任务中,给定标签lj(1≤j≤q)和频繁项Pj(1 ≤j≤k),可以在原始样本空间中获得对应的特征子空间:
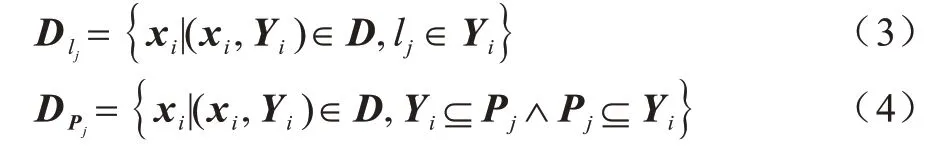
定义2(频繁项)给定一个标签组合ls(ls⊂Y)和最小支持度θ(1<θ≤|D|),如果标签组合ls在数据集D中出现的频数大于等于最小支持度θ,则该标签组合ls就是一个频繁项Pj(1≤j≤k)。
1.2 解决方案框架
本文提出一种基于标签相关性的多标签学习K 近邻算法,其架构如图1 所示。首先,使用频繁项挖掘算法Fp_growth[17]挖掘给定数据集的频繁项集;然后,为频繁项相关性得分和标签相关性得分建模,基于这2 种评分模型使用阈值自学习算法为每一个频繁项和标签学习对应的关联阈值和独立阈值。至此,多标签学习分类模型构建完毕,最终使用预测算法完成测试样本预测。
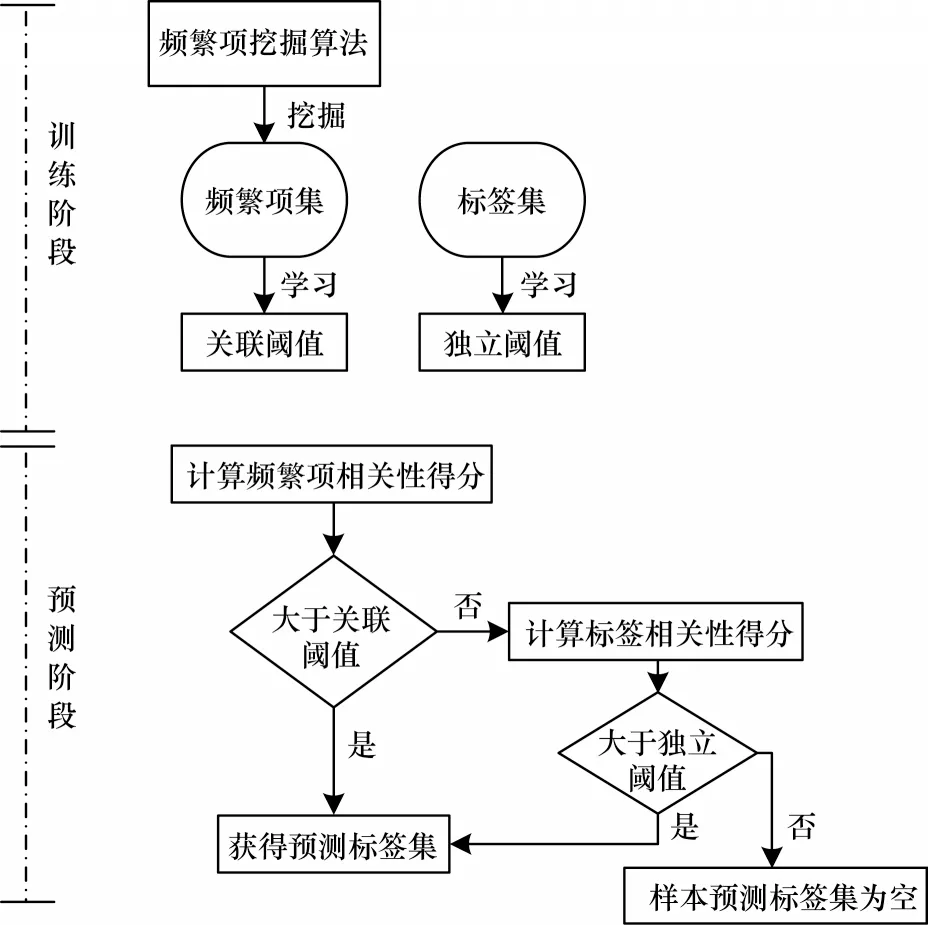
图1 本文算法结构框架Fig.1 The structure framework of this algorithm
2 训练与预测
2.1 相关性得分建模
本文对标签高阶关系和单标签分别进行建模,建模方法与ML-kNN 算法[19]相比,ML-kNN 算法将标签与其他标签之间看作是相互独立的,实现了单标签的建模与模型求解,忽略了标签之间的相关性,本文在ML-kNN 单标签建模算法的基础上,实现高阶标签关系建模与模型求解,兼顾了标签间多种可能的相关性。
标签高阶关系通常以频繁项的形式呈现,对频繁项相关性得分进行建模,形式化表示为:
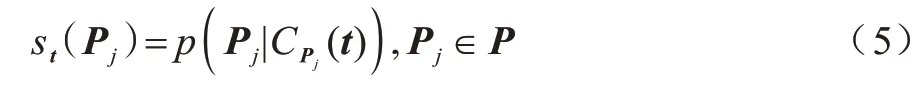
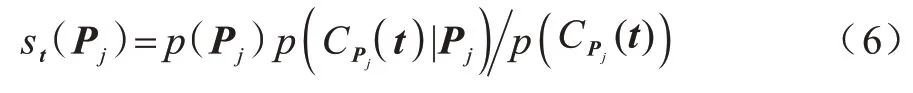
其中:p(Pj)是频繁项Pj的先验概率;表示在样本t的标签集是频繁项Pj的条件下,样本t的k 近邻样本中恰有个样本的标签集是频繁项Pj的概率。
st(Pj)计算过程如算法1 所示。
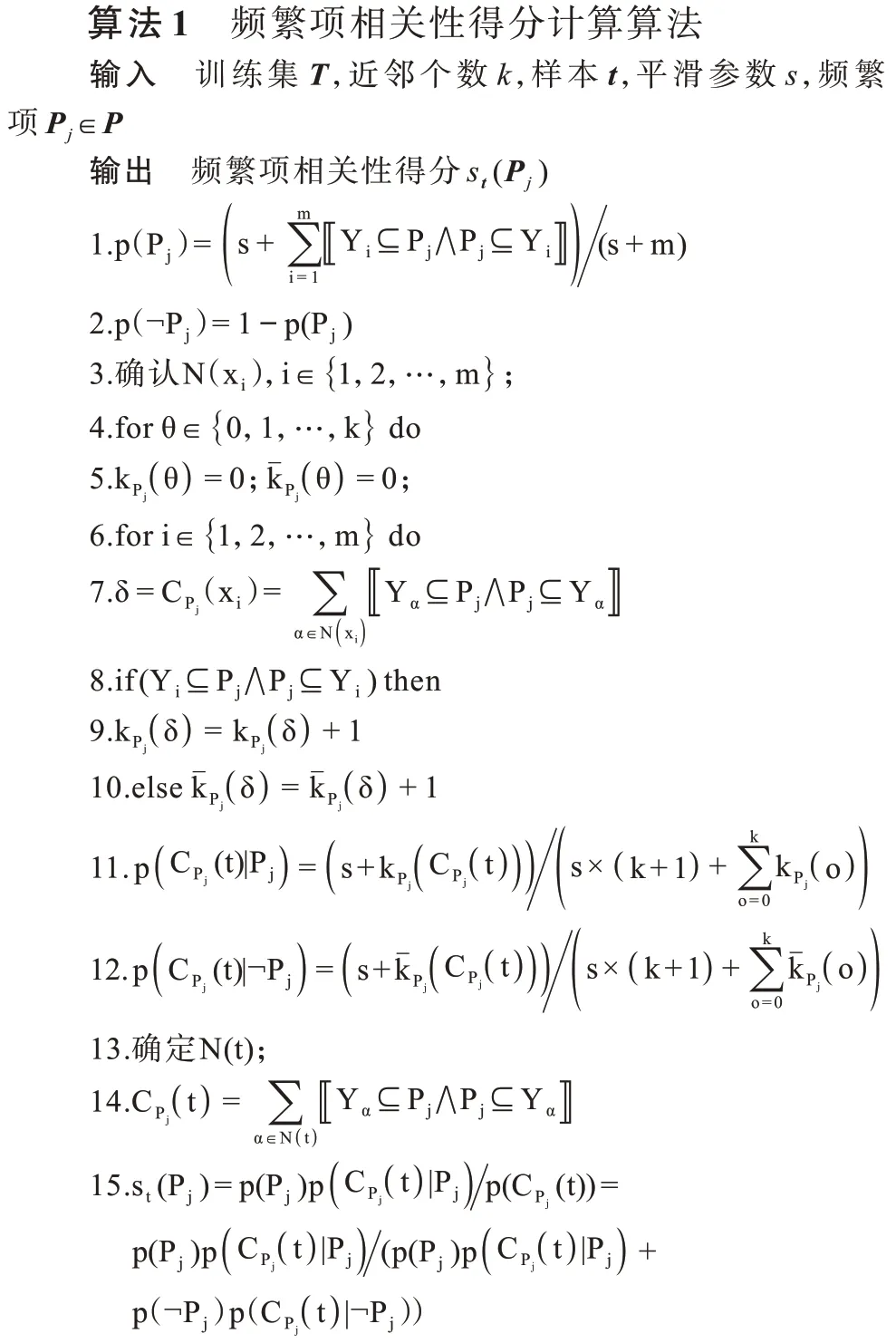
对标签相关性得分进行建模,形式化表示为:
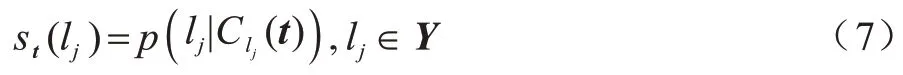
使用贝叶斯准则,式(7)可以重写为:
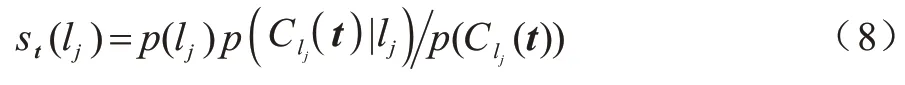
st(lj)的计算过程见文献[19]。以上2 种评分模型求解算法的时间复杂度类似,以算法1 的时间复杂度为例进行分析,该算法是对标签高阶关系建模以评估样本标签集是该频繁项的可能性,核心步骤是计算先验p(Pj)和似然,这2 个概率的计算都是基于训练集T中样本数的统计而进行的,需要遍历整个训练集T,因此,该算法的时间复杂度为O(N)。
2.2 阈值自学习算法
对于某个样本t,通过上述相关性得分建模算法,便可得到模型对各个频繁项的相关性得分以及模型对各个标签的相关性得分。在多标签分类中,每个实例对应的标签数是不同的,大多数情况下采取的做法是设置全局阈值,将标签相关性得分大于全局阈值的标签筛选出来。本文采取一种更加灵活的方法,为每个频繁项自动地学习得到适用于样本特征的关联阈值,为每个标签自动地学习得到适用于样本特征的独立阈值。关联阈值记为:
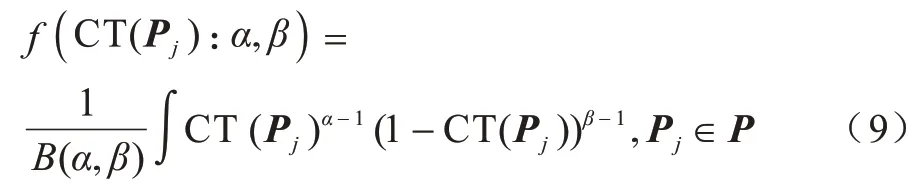
本文采用通用的Beta 分布来描述关联阈值CT(Pj)(Pj∈P,CT(Pj)∈[0,1])的阈值分布。Beta 分布的参数α和β可以基于可用样本通过贝叶斯推断估计出。f(CT(Pj):α,β)是关联阈值服从的Beta 分布的密度函数,α和β决定了密度函数的形状。本文利用关联阈值自学习算法求解关联阈值CT(Pj),关联阈值自学习算法描述如下:

独立阈值自学习算法描述如下:


值得注意的是,以上提到的2 种阈值自学习算法都是增量式学习算法,当有新的训练样本时,可以基于已有的阈值直接进行更新,而无需重新学习。
例1假设一个频繁项P1,在训练集中有3 个样本t1、t2、t3的标签集是该频繁项,对t1、t2、t3计算频繁项相关性得分,分别为,假设频繁项P1的关联阈值Beta 分布的初始参数为α0=1,β0=1,则Beta 分布参数的更新如下:
α1=1+100×0.28=29,β1=1+100×0.72=73
α2=29+100×0.25=54,β2=73+100×0.75=148
α3=54+100×0.44=98,β3=148+100×0.56=204
最终,频繁项P1的关联阈值为:
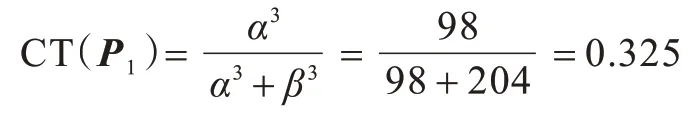
2.3 预测算法
预测的思路是首先基于标签高阶关系模型,评估样本标签集合属于每一种频繁项的可能性,如果标签高阶关系模型不能预测出样本的标签集合,说明该样本具有的标签间相关性并不强,则将问题转换为多个独立的二分类问题进行解决,从而兼顾标签间多种可能的相关性。预测算法描述如下:


3 实验结果与分析
3.1 实验数据集
为了验证本文算法的有效性,选取来自Mulan Library[21]库中的2 组经典多标签数据集进行实验,多标签数据集对应的名称、领域、样本数、特征数、标签空间中标签数等详细信息如表1 所示。

表1 多标签数据集统计信息Table 1 Multi-label dataset statistics
Emotions[22]数据集包含593 个标注了情感的歌曲样本,每个样本由72 个特征描述,即8 个韵律特征和64 个音色特征。每个样本对应6 个情感标签,每个标签代表一个基于模型的歌曲情感聚类。
Scene[23]数据集包含2 407 个自然场景的图片样本,每个样本由294 个特征描述,对应一个294 维的特征向量,具体的属性向量生成过程可参见文献[23],标签空间是6 种可能的自然场景。
3.2 实验设置
实验设置具体如下:
1)实验平台。实验中所有代码都由Python 编写,模型基于sklearn 搭建。设备系统为Windows10,配备NVIDIA GEFORCE GTX 950M 显卡,内存为16 GB。
2)数据预处理。本文算法对样本进行预测需要找出样本在训练集上相似度最高的k个样本,基于这k个样本的标签集预测测试样本的标签组合。为了度量样本之间的相似性,本文采用样本间的欧氏距离作为样本相似性的度量标准,为了消除特征之间的量纲影响,对数据特征进行归一化处理。
3)评价指标。本文算法可以直接预测出测试样本的标签集,因此,基于多标签排序[24]的评价指标并不适用于本文算法,考虑到本文算法的特殊性,从多标签分类层面对预测结果进行评估,采用Precision(P)、Recall(R)、F1-Measure(F1)[25]作为算法性能的评价指标。Precision、Recall 的计算依赖于分类结果的混淆矩阵,F1-Measure 的计算又是基于Precision、Recall。分类结果的混淆矩阵如表2 所示。

表2 分类结果的混淆矩阵Table 2 Confusion matrix of classification results
各评价指标的计算公式如下:
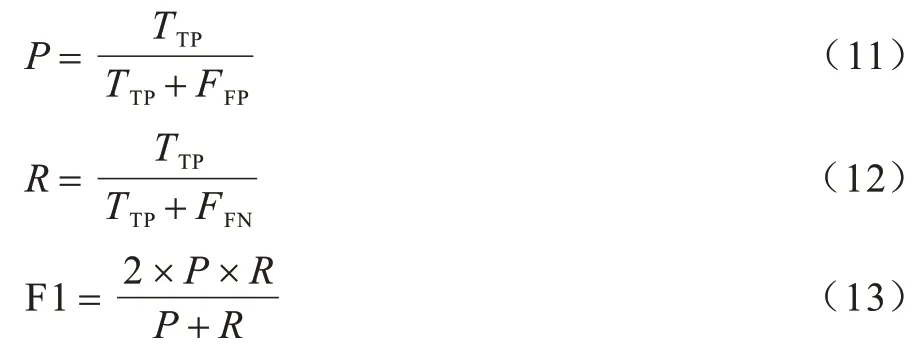
P指标用于衡量预测出的正样本中确实是正样本的比率,R指标用于衡量正样本中有多少比例被预测出,F1 是P和R的调和平均,用于衡量算法在整体上的性能效果。
3.3 结果分析
3.3.1 本文算法与各基准方法性能比较
各方法在实验数据集上的性能比较结果如表3、表4 所示。从表3、表4 可以看出,本文算法在2 个数据集上的F1 指标都取得了最优值,在Emotions 数据集上,本文算法的F1 比CC、LP、RAKEL、MLDF 分别提高1.4、5.8、1.4、6.6 个百分点,在Scene 数据集上,本文算法的F1 相比CC、LP 分别提升1.3 和8.4 个百分点。相较其他基准方法对标签高阶关系建模,本文算法通过数据挖掘来明确数据集本身固有的高阶标签关系并进行建模,其考虑标签间真实存在的相关性,因此,取得了较好的分类性能。
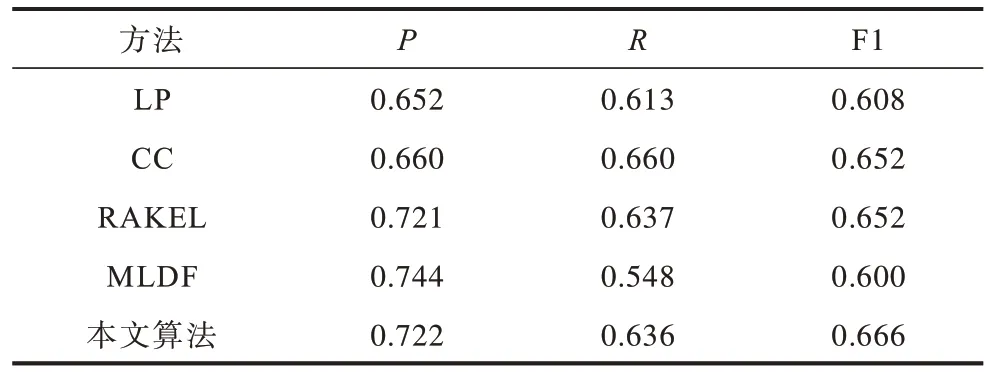
表3 多标签学习方法在Emotions 数据集上的性能比较Table 3 Performance comparison of multi-label learning methods on Emotions dataset
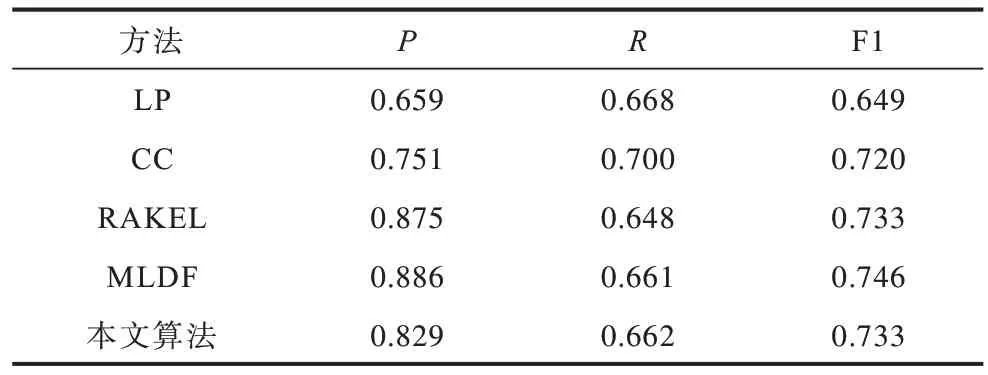
表4 多标签学习方法在Scene 数据集上的性能比较Table 4 Performance comparison of multi-label learning methods on Scene dataset
3.3.2 关联阈值和独立阈值的有效性分析
为了验证关联阈值CT和独立阈值IT的有效性,本文采用3 种策略分别进行实验:
1)只使用关联阈值对测试样本进行预测。
2)只使用独立阈值对测试样本进行预测。
3)结合2 个阈值对测试样本进行预测。
3 种策略的判别能力如表5、表6 所示。由表5、表6 可以看出,策略3 的分类性能优于策略1 和策略2。对比2 组实验数据不难发现,在Emotions 数据集上,只使用关联阈值就可以取得较好的分类性能,在Scene 数据集上,只使用关联阈值则分类性能不理想。在Emotions 数据集上,从策略1 到策略3 分类性能提升不是很明显,但是在Scene 数据集上,从策略1到策略3 的分类性能提升效果非常显著。
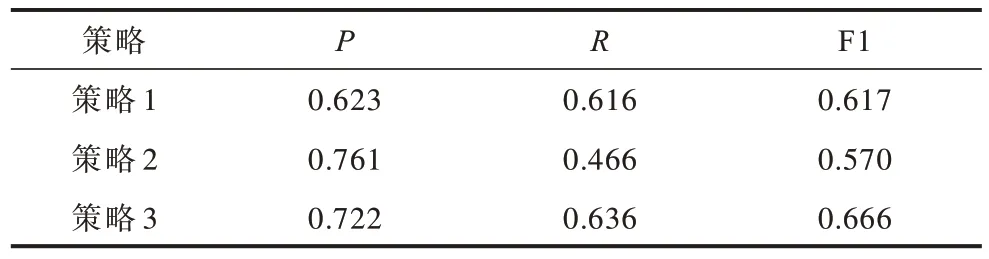
表5 不同策略在Emotions 数据集上的性能比较Table 5 Performance comparison of different strategies on Emotions dataset
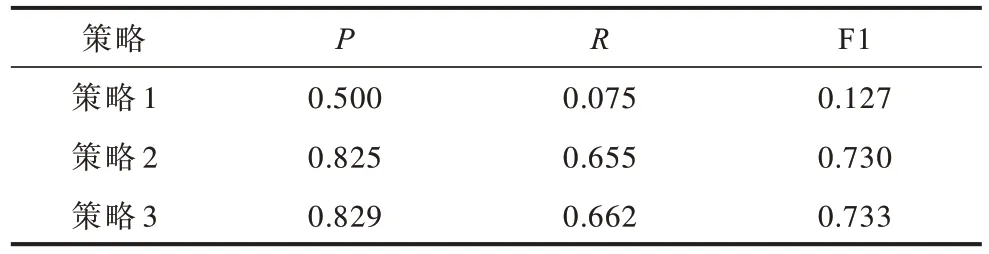
表6 不同策略在Scene 数据集上的性能比较Table 6 Performance comparison of different strategies on Scene dataset
出现上述2 种情况,最主要的原因是2 组数据集标签间相关性的强弱不同。具体来说,Emotions 数据集上因为标签间的相关性很强,测试样本的标签集总是以频繁项的形式呈现,因此,通过关联阈值预测就可以将绝大部分的测试样本标签集确定,剩余的样本需借助独立阈值去获取样本的标签集,即从策略1 到策略3 分类效果的性能提升不是很明显,验证了本文对标签高阶关系建模的有效性。在Scene数据集上,由于标签间的相关性较弱,存在挖掘出的频繁项不能覆盖所有标签的情况,通过使用关联阈值进行预测,该标签的分类指标必然为0,将大幅影响整体分类效果。在实际的预测过程中,只有很少部分的测试样本标签集是频繁项,值得注意的是,在数据集上虽然挖掘出频繁项,但一种标签组合是否属于频繁项由它在数据集上出现的频数以及设置的阈值参数共同决定,在Scene 数据集上,频繁项的个数很少,通过本文算法验证了Scene 数据集标签间的相关性较弱,对于测试样本,大部分都采用策略2 完成标签集的获取,因此,从策略1 到策略3 分类效果有了很大的提升。
4 结束语
已有多标签学习算法大多将多标签学习问题转化为多个独立的二分类问题,以对每个标签进行单独求解,该过程通常忽略了标签间的相关性。本文提出一种基于标签相关性的多标签学习K 近邻算法,该算法充分挖掘标签间的相关性,对标签高阶关系进行建模,基于标签高阶关系模型分析样本的标签集合,如果标签高阶关系模型不能预测出样本的标签集合,说明该样本标签间的相关性并不强,此时使用一阶策略完成该样本标签集的预测工作,从而消除仅依靠单阶或多阶模型进行预测时存在的弊端。在2 个经典数据集上的实验结果表明,该算法具有较高的F1-Measure 值,其能取得较好的分类效果。下一步将在确定对应于每个频繁项或标签的近邻样本时,采用不同大小的近邻参数K,从近邻样本中提取出更为有效的信息来辅助分类过程,从而提高本文算法的分类性能。
猜你喜欢
四川大学学报(自然科学版)(2021年6期)2021-12-27
计算机系统应用(2021年2期)2021-02-23
计算机应用(2020年12期)2020-12-31
哈尔滨轴承(2020年1期)2020-11-03
电子技术与软件工程(2019年18期)2019-11-18
北京航空航天大学学报(2019年9期)2019-10-26
福建基础教育研究(2019年7期)2019-05-28
电子技术与软件工程(2017年14期)2017-09-08
北京航空航天大学学报(2016年7期)2016-11-16
文苑(2015年9期)2015-09-10
