
基于特征扩展的微博短文本流热点话题检测方法
2022-06-16 02:32李艳红谢梦娜王素格李德玉
数据采集与处理 2022年3期
李艳红,谢梦娜,王素格,李德玉
(1.山西大学计算机与信息技术学院,太原 030006;2.山西大学计算智能与中文信息处理教育部重点实验室,太原 030006)
引 言
社交网络和互联网的飞速发展使微博变为用户捕获信息的主要平台。根据新浪微博官方数据显示,2020 年第一季度微博每月的活跃用户高达5.5 亿,每天活跃用户高达2.41 亿。微博作为一种舆情的聚焦工具,民众共享的信息或谈论主题在网络中广泛传播,使得微博的爆发力和破坏性更加强烈,从而产生巨大的社会影响。因此及时发现微博短文本流中的热点话题,有助于了解公众情绪和舆论,为话题推荐和政府决策提供依据。由于微博短文本流具有文本内容短小、特征稀疏以及话题不断变化的特点,因此如何从中实时发现热点话题是一项值得深入研究的课题。
网络上两种主要的热点话题检测方法分别以文本为中心[1]和以突发特征为中心[2]。以文本为中心检测热点话题是首先对文本聚类,然后分析各类簇的突发情况,判定有突发状态的类簇为热点话题。此类方法一般基于潜在狄利克雷分布(Latent Dirichlet allocation,LDA)主题模型[3]或者改进后的LDA主题模型[4]。例如,Kiejin[5]首先使用N⁃gram 算法来构建多个词语,精确地捕获一个句子的含义,然后通过LDA 主题模型实现话题的初步检测。Mehrotra 等[6]提出优先考虑博文内容而非改进主题模型,即在文本预处理时对博文进行多方案聚合。文献[5,6]提供的各类方法前提都得保证数据是静态的,但在实际情况中,数据通常是在线文本流形式,而非静态数据。Wang 等[7]首次提出了一种新的主题模型,即多属性狄利克雷分布(Multi attribute LDA,MA⁃LDA),该模型把微博的时间特性和哈希标签结合到LDA 主题模型中。周先琳[8]对微博文本预处理后,创建动态标签⁃潜在狄利克雷分布(Labeled⁃LDA,L⁃LDA)模型检测热点话题。由于利用主题模型进行参数估计比较耗时,因此很难满足实时检测热点话题。以特征为中心的方法指的是通过特征词的速度、动量等来判定突发状态,对有突发特征的微博文本进行聚类,从而确定热点话题。如Fung 等[9]利用时间信息以及单词分布情况确定突发特征词;李汉才等[10]融合时序性和波动性计算话题热度;万越等[11]提出使用影响力因子,并结合热度因子修正动量模型确定突发特征;郑斐然等[12]根据突然高频出现在微博中的特征词的速度变化情况确定突发词;蔡莹等[13]结合词语权重定义突发状态,进而检测热点话题。由于以特征为中心的方法通过突发特征确定热点话题,因此省去了训练数据计算参数的时间。
为了解决短文本特征稀疏问题,目前有两类短文本扩展方法:基于外部资源扩展[14]和基于内部资源扩展[15]。基于外部资源扩展是指使用外部语料库(如:维基百科、Probase 等)对短文本扩展。比如Cheng 等[16]利用维基百科语料库获取丰富的信息进行短文本扩展;Li 等[17]提出从Probase 中提取概念和共现术语,并对词语进行消歧,从而扩展微博短文本特征,用于微博文本的分类研究;Duan 等[18]提出用特征向量代替词来训练一个巨大的外部资料库,弥补了短文本的特征稀疏问题。基于内部资源扩展是指利用短文本自身的上下文关系,构建基于文本内容的词集实现短文本的扩展。如Paulo 等[19]提出利用词共现和词向量在原始文档中创建一个大的伪文档从而进行特征扩展;张萌[20]利用微博文本所带链接内容丰富短文本特征,利用主题模型发现热点话题。与利用外部资源扩展方法相比,基于自身资源的扩展方法在相似特征选取上具有优势,并且基于外部资源扩展的边界难以确定,引入的知识太笼统,会带来一些无关词从而使得特征扩展质量不高。考虑到一般情况下一条微博会包含多条评论文本,评论者针对该条微博文本表达观点和评价,因此本文选用微博评论文本作为扩展语料,并利用突发特征来检测热点话题。对于热点话题的检测,已有研究人员做了大量相关工作,但仍存在以下问题:(1)在微博短文本利用评论文本进行特征扩展时,没有考虑评论文本的用户影响力(如用户活跃度、粉丝数等),在筛选特征词时忽略了评论文本中的特征词与微博文本中的特征词的相关性;(2)在定义突发特征时,没有考虑微博文本强度(如点赞数、评论数等)对突发程度的影响。
基于上述问题,本文提出一种基于特征扩展的微博短文本流热点话题检测方法。根据用户活跃度、粉丝数等计算评论用户影响力,结合评论文本的点赞数筛选出高质量评论文本;使用词共现和词频⁃逆文档频率(Term frequency⁃inverse document frequency,TF⁃IDF)方法提取评论文本中的特征词,对微博文本进行特征扩展;提出利用点赞数、评论数计算微博文本强度,并作为计算词对速度的参数,进而确定突发词对;利用突发词对速度确定突发词对窗口,合并交叉、重叠、相邻的突发词对窗口得到热点话题窗口;最后通过采用吉布斯采样狄利克雷多项式混合模型(Gibbs sampling Dirichlet multinomi⁃al mixture model,GSDMM)[21]对热点话题窗口中的微博文本聚类,分析得到的每个类簇中特征词的重要度,提取重要度高的特征词来表示热点话题的主题结构。
1 问题形式化定义及符号说明
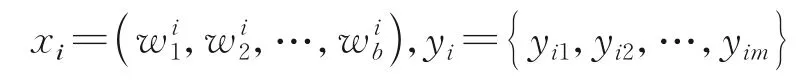
话题检测框架的主要符号及其说明如表1所示。

表1 话题检测框架主要符号Table 1 Main notations of topic detection framework
2 基于评论文本的特征扩展和突发特征定义
2.1 特征扩展定义
表2 给出了一条微博短文本及其对应的评论文本。从表2 可发现,微博文本“有病的人找不到床位”中并没有提到任何和医保相关的内容,但是通过其评论文本可知这条微博文本是在抨击医保乱象。由此可知,可以利用微博评论对微博进行特征扩展。

表2 微博文本及其评论文本Table 2 Microblog text and its comment text
为了解决微博短文本特征稀疏问题,使用微博评论文本作为扩展语料。由于微博评论文本的质量参差不齐,为了得到高质量的扩展特征,首先基于评论文本的强度来对评论文本进行筛选,然后根据词共现度和词区分度从筛选出的评论文本中抽取特征词用于微博短文本的特征扩展。
下面首先给出评论文本强度定义。
定义1评论文本强度cts 表示该条文本参考价值,可以通过发表评论用户的影响力以及评论文本对应的点赞数定义,即
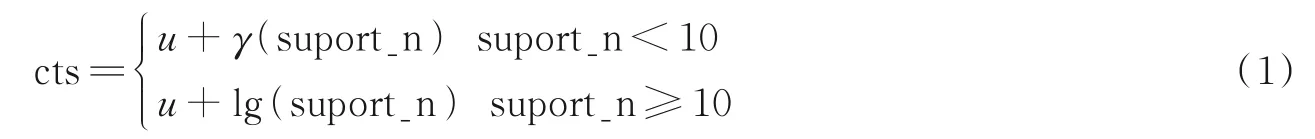
式中:suport_n 表示点赞数,u表示用户影响力。u的计算式为

式中:fan_n 表示粉丝数,follow_n 表示关注数,sum 表示一条微博文本对应的所有评论用户的粉丝数,level(0 ≤level ≤1)为微博官方通过用户的活跃度、用户信誉值等综合考虑所得的一个用户信用值,γ为调节参数(0 <γ<1)。
为了从评论文本中提取特征词,给出词共现度和词区分度的定义。
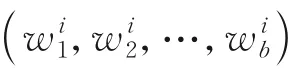

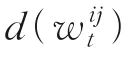
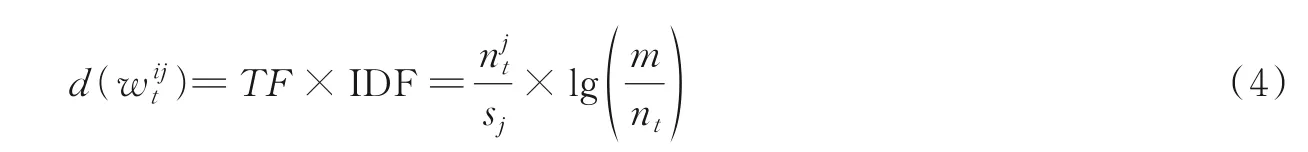
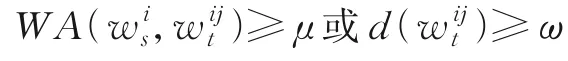

表3 微博文本扩展示例Table 3 Microblog text extension examples
2.2 突发特征定义
微博短文本流中主要分布两类话题,即热点话题和一般话题。直观上,热点话题区别于一般话题的特征是:(1)出现热点话题时,微博文本流中涌现出大量的相关微博,而一般话题微博文本的出现较为平稳;(2)出现热点话题时,微博话题讨论量呈上升趋势,在短时间内微博文本点赞数、转发数以及评论数显著增加,而一般话题没有这一特征。热点话题微博与一般话题微博示例分别如表4 和表5所示。
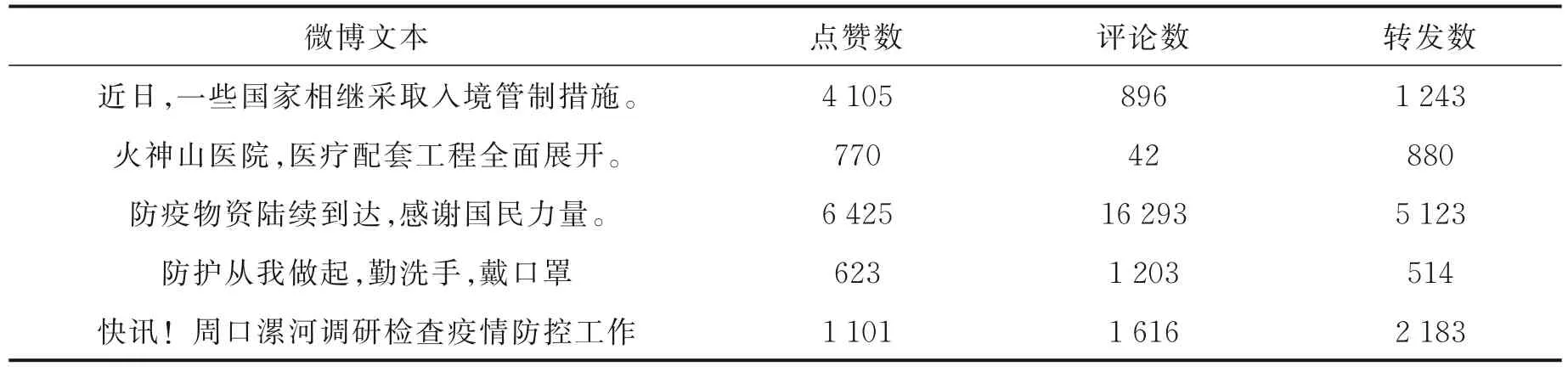
表4 热点话题微博博示例Table 4 Examples of hot topics microblog

表5 一般话题微博示例Table 5 Examples of general topics microblog
基于上述现象,提出在使用词对加速度定义突发特征时,应考虑微博文本强度(点赞数、评论数和转发数)的不同。
定义4微博文本强度ts的大小是由评论数、点赞数和转发数确定的,定义为
式中:u表示用户影响力,comment_n、suport_n 和transmit_n 分别表示评论数、点赞数和转发数。
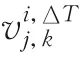

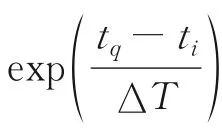
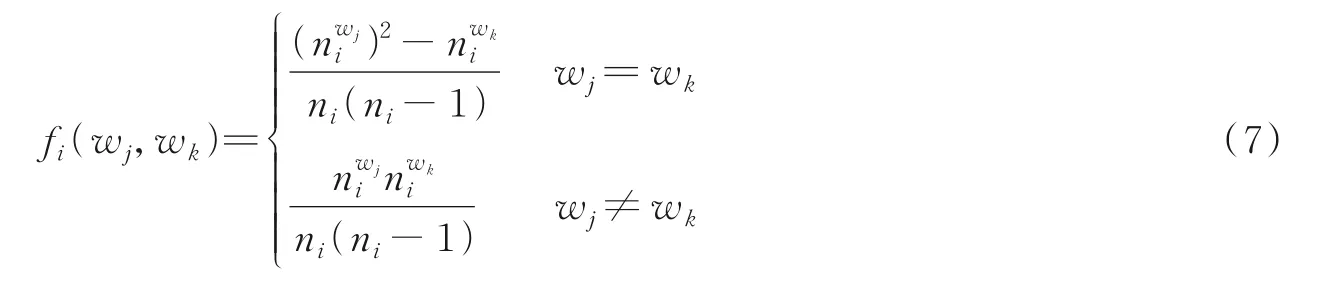
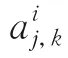

式中ΔT1<ΔT2。
定义7当词对加速度aj,k≥α,则称(wj,wk)为突发词对,α表示词对加速度阈值。
微博文本流中的突发词对速度可以反应热点话题的热度,所以可根据其确定突发词对窗口。
定义8突发词对窗口BWW 定义为
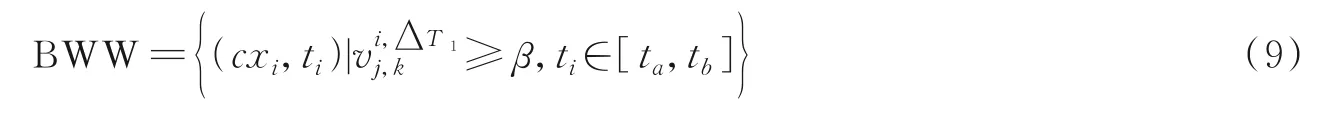
通过对微博文本流中热点话题的分析,可发现在连续时间区间内出现的微博文本一般属于同一个热点话题。此外,还发现在一个时间区间内的多个突发词对窗口往往是交叉、重叠或者相邻的,所以可通过突发词对窗口来确定热点话题窗口。
定义9将n个交叉、重叠或相邻的突发词对窗口BWW1、BWW2、…、BWWn合并,定义为热点话题窗口W,可表示为

3 基于特征扩展的热点话题检测
3.1 热点话题检测框架
本文提出的热点话题检测框架主要分为3 个模块:微博短文本特征扩展、突发特征识别、热点话题窗口的确定和热点话题的主题结构,如图1 所示。
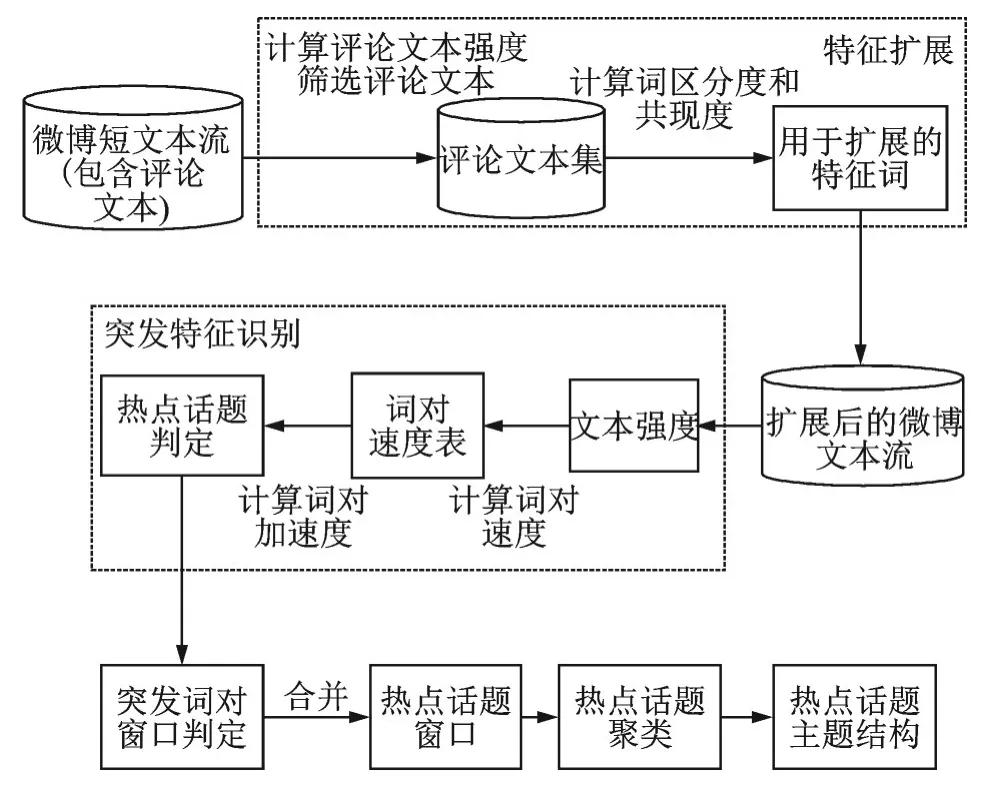
图1 基于特征扩展的热点话题检测框架Fig.1 Framework of hot topic detection based on feature extension
(1)微博短文本特征扩展:首先基于评论文本的强度(粉丝数、关注数和点赞数)筛选评论文本;然后利用词共现与TF⁃IDF 抽取评论文本中的特征词用来扩展微博文本。
(2)突发特征识别:通过文本强度给词对速度加权,从而计算词对加速度,并将其作为突发特征。当新到达微博时,计算微博中词对的频率、速度和加速度。当词对加速度大于阈值时,判定产生热点话题。
(3)热点话题窗口的确定和热点话题的主题结构表示:当词对加速度大于阈值时得到突发词对,通过突发词对的速度来判定突发词对窗口,合并满足条件的突发词对窗口进而确定热点话题窗口。利用GSDMM 算法对热点话题窗口中的微博文本聚类,得到热点话题的主题结构。此聚类方法能够较好地处理高维、稀疏的短文本。
3.2 基于特征扩展的热点话题检测算法
根据图1 所示的特征扩展热点话题检测框架,提出了一种基于特征扩展的热点话题检测算法(Fea⁃ture extension based hot topic detection,FE⁃HTD),如算法1 所示。
算法1基于特征扩展的热点话题检测算法
输入:微博文本流D,时间片ΔT1和ΔT2,文本强度阈值k,词对加速度阈值α,词共现度阈值μ,词区分度阈值ω,突发词对速度阈值β,窗口合并个数阈值n。
输出:热点话题主题结构。
①对ti时刻出现的所有微博文本和对应的评论文本,计算文本强度,当评论文本强度cts ≥λ时,将该条评论文本作为扩展语料。
②计算所有微博文本中特征词与所对应的评论文本中的特征词的词共现度以及词区分度

⑥根据定义8 判断交叉、重叠或相邻的突发词对窗口个数,当大于n时,合并窗口从而得到热点话题窗口W。
⑦利用GSDMM 算法对热点话题窗口W中的微博文本聚类,获取热点话题主题。
4 实验结果及分析
4.1 实验数据
面向微博文本流的热点话题检测无标准数据集,文中实验数据通过新浪微博(www.weibo.com)平台获取。采集了2020 年1 月中旬、2020 年6 月中旬以及2020 年12 月中旬3 个时间段的微博短文本流作为测试数据集,共获取微博短文本33 万余条,具体如表6 所示。
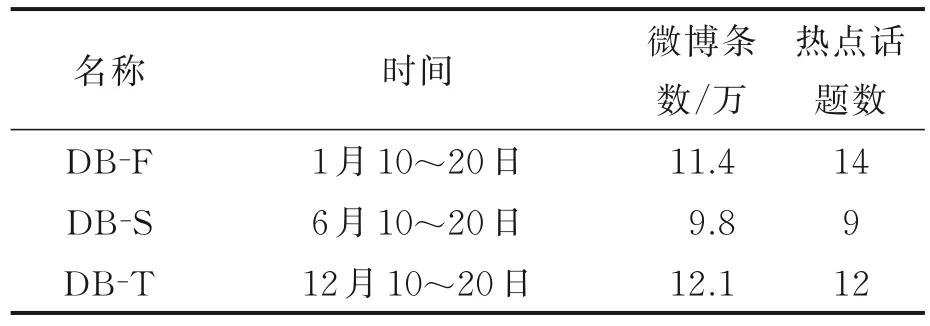
表6 测试数据集表示Table 6 Representation of test data sets
首先对获取到的微博数据进行处理,保留微博的发布时间、内容信息、评论信息、点赞数、评论数、转发数、粉丝数以及关注数;然后对微博和评论信息进行分词、去除停用词以及删除噪声(如URL 链接等);最终得到32 万条微博短文本及其相应的评论文本,经过对微博文本进行人工标注,共得到热点话题35 个。
4.2 FE⁃HTD 算法的准确率、召回率、F1值
通过准确率P、召回率R、F1值来判断算法性能,其计算公式分别为

式中:RHT 指算法正确检测的热点话题数量;ST 指算法检测出的热点话题数量;LT 指人工标注的热点话题数量。
算法FE⁃HTD 的参数取值:词区分度阈值ω=0.35,评论文本强度阈值λ=1.6,词对加速度阈值α=0.15,词共现度阈值μ=0.20,突发词对速度阈值β=3.0,ΔT1=15 min,ΔT2=30 min,突发词对窗口的合并阈值n=4。由分析采集到的数据可发现,一些用户的粉丝数很大但是关注数很小;一些用户的粉丝数接近于关注数;粉丝数与关注数比值最小为0.47,最大为23 314。为缩小该范围,并使得用户影响力在合理区间,设定调节参数γ(0 <γ<1)。实验中将γ取0.1。
为了验证微博短文本流特征扩展对热点话题发现的作用,将本文提出的FE⁃HTD 方法与不经过特征扩展而直接进行热点话题检测的HTD 方法进行对比实验,结果如表7 所示。
从表7 可知,对微博文本进行特征扩展以后,可以检测到一些仅利用微博文本发现不了的热点话题。因为特征扩展可以丰富微博短文本信息,比如由微博短文本“我最爱的综艺没有之一”可以得到的特征为“最爱,综艺”,利用评论信息进行特征扩展以后成为“最爱,综艺,偶像,练习生”,可知该微博文本与话题“偶像练习生开播一周年”相关,从而提高了热点话题的识别率。
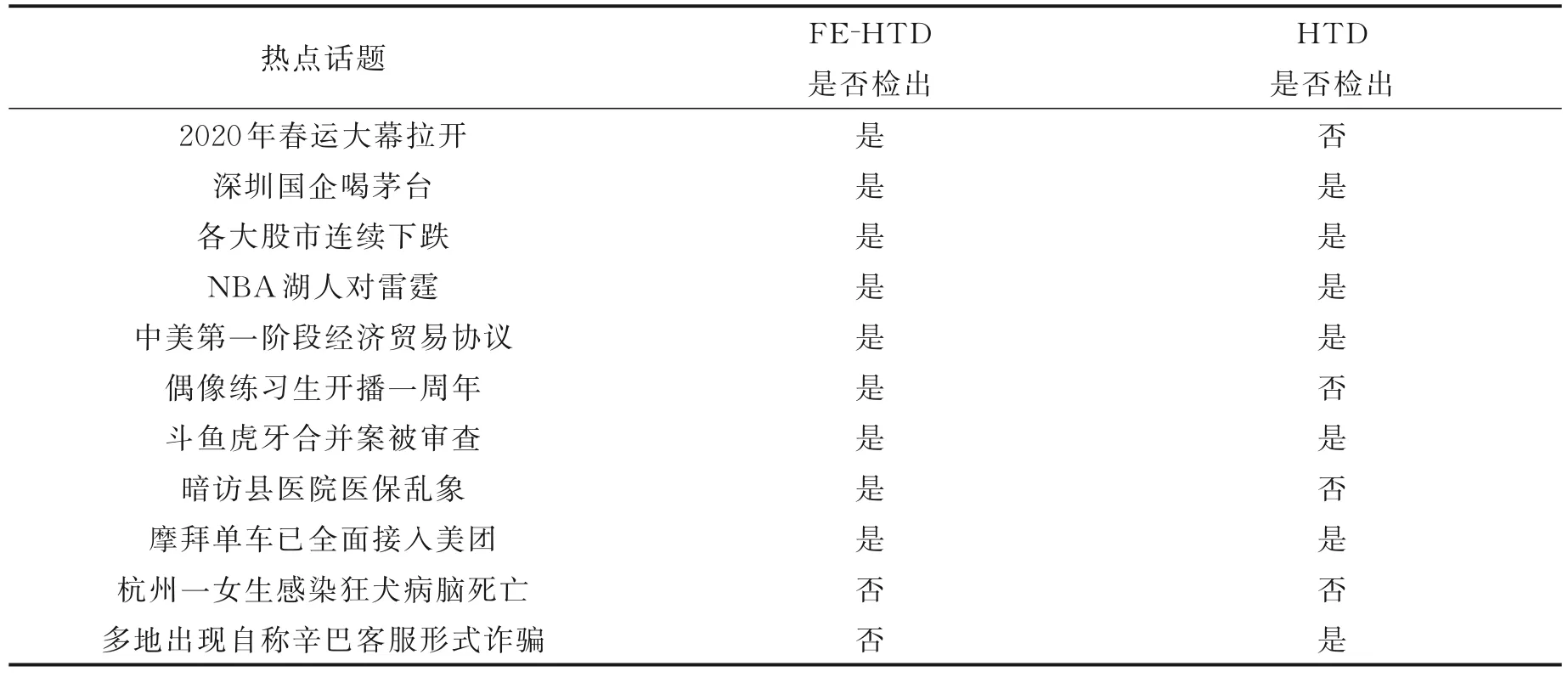
表7 部分话题检出情况Table 7 Detection of some topics
为了验证本文所提出的FE⁃HTD 算法的性能,将其与其他3 种算法进行了比较。第1 种算法为上文提到的HTD;第2 种为BW⁃TD[25],该算法基于定长滑动窗口,将词频的变化作为突发特征,通过聚类得到突发话题;第3 种算法为T⁃TD[26],该算法利用词共现对文本进行扩展,并使用LDA 模型检测突发话题。图2 为4 种算法在数据集DB⁃F、DB⁃S 和DB⁃T 上热点话题检测的P、R、F1值的对比结果。由图2 可知,在3 个实验数据集上,本文所提FE⁃HTD 算法的P、R、F1值均高于对比算法。其原因在于BW⁃TD 算法采用定长滑动窗口,通过实验数据可知,有的话题持续时间仅有47 min,将时间窗口设置为3 h,窗口可能会将话题切分开,导致特征词频变化率未达到阈值造成话题漏检,从而热点话题检测查准率降低;算法HTD 未考虑特征扩展,算法T⁃TD 虽对文本进行特征扩展,但是在扩展的特征词质量上没有做筛选,因此导致扩展质量不高,话题检测准确度低。本文所提算法优于对比算法的主要原因在于,在特征扩展时考虑了文本强度,在检测突发特征时不但考虑了词对加速度,还考虑了微博文本点赞数、评论数、转发数以及发表微博文本用户的影响力。
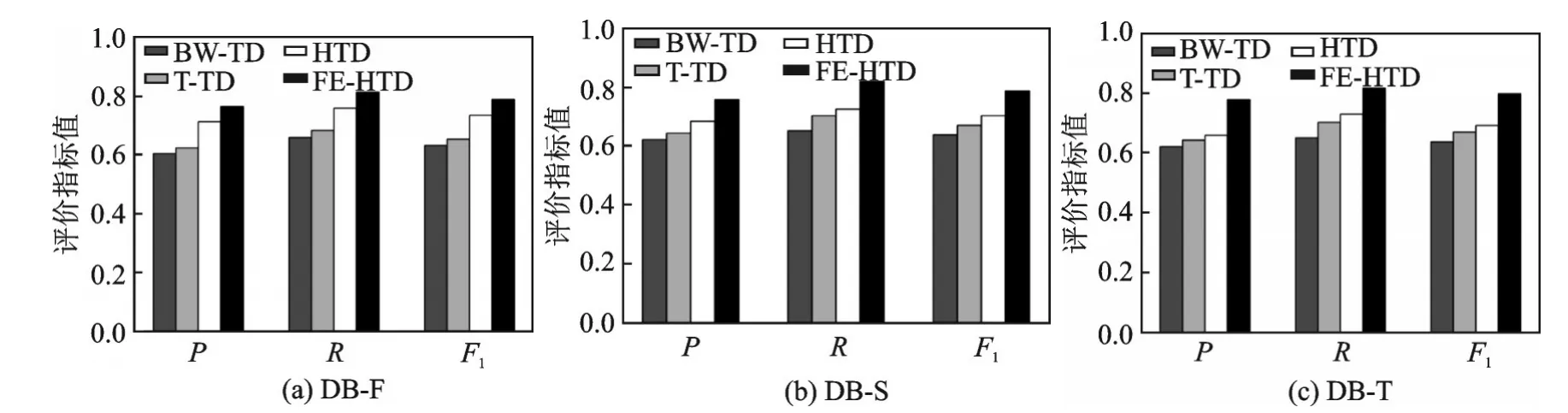
图2 4 种检测算法在不同数据集上的P、R、F1值对比Fig.2 Comparison of P,R and F1 values of four detection algorithms on different data sets
4.3 FE⁃HTD 算法时效性
为了检测本文所提算法的时效性,将FE⁃HTD 与做了特征扩展的T⁃TD 算法和未经特征扩展的BW⁃TD 算法作对比实验。在表8 中列举了3 个热点话题的检出时间,热点话题1~3 出现相关微博的时间分别为(12:37:53、13:09:03、13:41:27)。
由表8 可知,本文提出的FE⁃HTD 算法和T⁃TD 算法相比较,FE⁃HTD 算法提前30 min 检测出热点话题。这主要是因为本文算法基于动态窗口,对微博文本实时计算特征词对加速度和词对速度,并在突发特征定义时利用文本强度为特征词对加权,当词对加速度大于阈值时则认为存在热点话题。比如实验中微博文本“万众一心,众志成城”经过特征扩展以后变成“万众一心,众志成城,新冠,疫情,隔离,医护”,可以发现特征词对(新冠、疫情)出现在原始微博中,导致特征词对速度变大,从而快速检出热点话题。T⁃TD 算法根据词共现选取评论,随后利用主题模型输出话题,最后聚类判断话题簇的突发状态,主题模型参数估计比较耗时,并且该算法采用定长窗口,只有当一个窗口结束后才进行词频分析,因此导致检测出热点话题的时间滞后。本文算法与对比算法BW⁃TD 相比检出时间较为接近,平均滞后5 min,主要是因为本文在话题检测前做了特征扩展。若不考虑特征扩展所需时间,对比算法BW⁃TD 检出热点话题的时间滞后。

表8 话题检测时效性描述Table 8 Effectiveness description of topic detection
4.4 特征扩展的热点话题主题结构
为了得到热点话题的主题结构,本文利用GSDMM 算法对热点话题窗口中的微博文本进行聚类。表9 列举了3 个热点话题对应不同算法检出特征词的情况。分析“司机救婴儿闯红灯家属拒绝作证”这一热点话题,FE⁃HTD 算法检出5 个突发词对,聚类分析热点话题窗口中的微博文本,得到主题结构:(1)司机闯红灯家属拒绝作证;(2)建议家属拉入征信系统。可以看出对比算法仅有少量的突发词检出,而本文算法可检出较多突发词对,所以主题结构比较丰富。
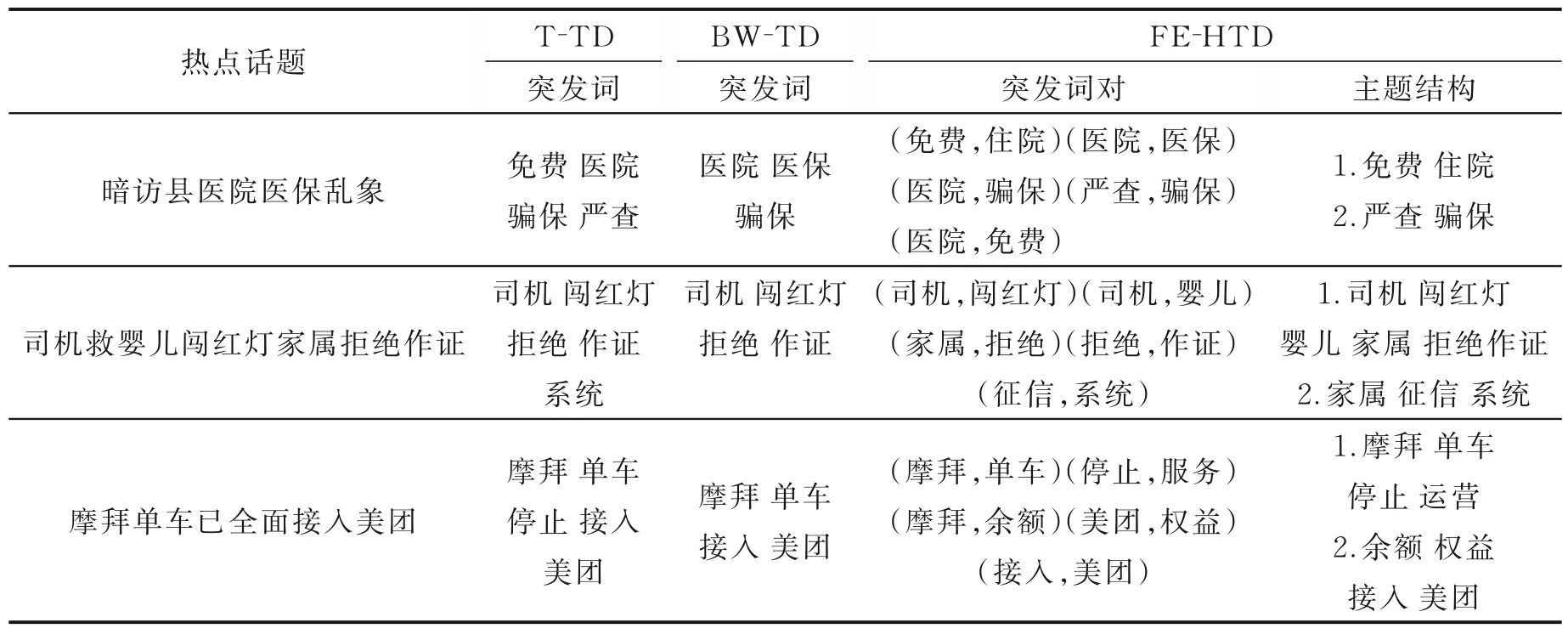
表9 热点话题主题结构Table 9 Theme structure of hot topics
4.5 参数μ 对算法P、R、F1值的影响
为分析词共现度阈值μ对所提FE⁃HTD 算法的P、R、F1值的影响,分别在DB⁃F、DB⁃S、DB⁃T 数据集上进行了实验。本文在0.15~0.25 之间取不同的共现度阈值μ进行实验,结果如表10 所示。
由表10 可知,随着μ值的增大,算法的召回率下降。这是因为μ值的增大导致得到的特征词有限,一些可以用作特征扩展的词被过滤掉,使得算法召回率变小。通过上述实验数据可知,当μ为0.20 时,算法准确率达76.4%,召回率达78.7%,实验结果最优。
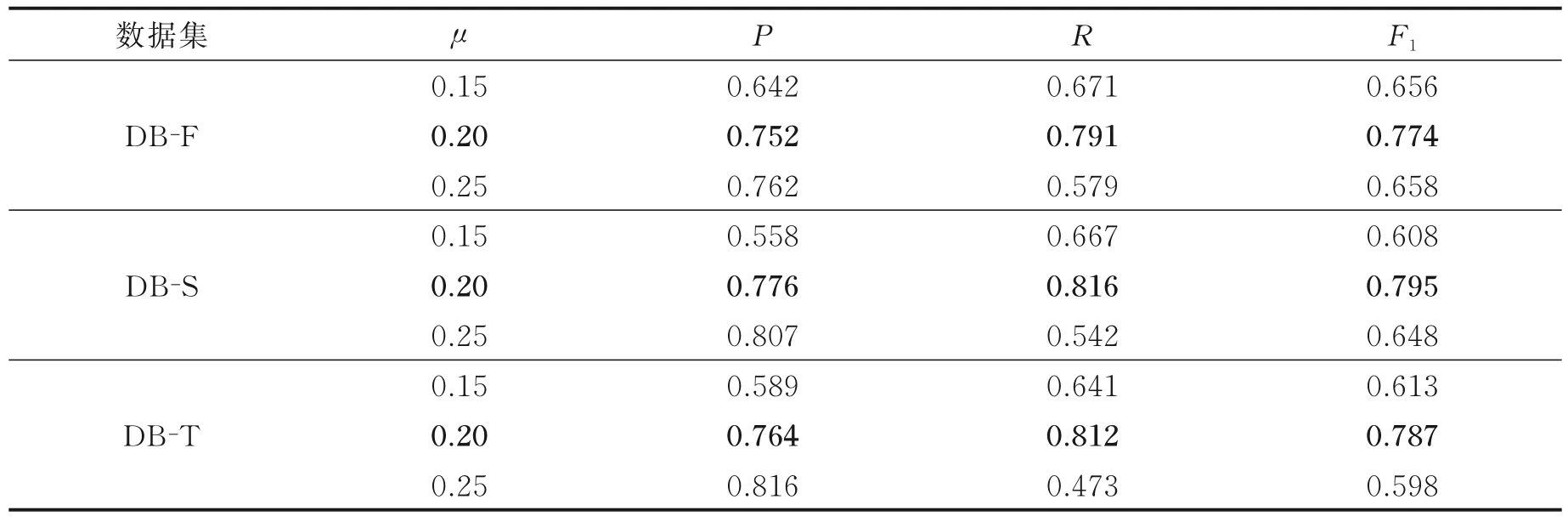
表10 不同μ 值对算法的P,R,F1值的影响Table 10 Influence of different values of μ on P,R and F1 values of the algorithm
5 结束语
本文利用微博文本、评论文本和用户信息提出了一种基于特征扩展的微博短文本流热点话题检测方法。首先基于文本强度筛选评论文本,计算词共现度和词区分度提取特征词,通过文本强度和词对加速度定义突发特征,然后根据突发词对的速度确定可变长的热点话题窗口范围,最后聚类得到窗口中热点话题的主题结构。基于新浪微博平台采集的真实数据,将所提算法与对比算法进行实验,验证了所提算法的有效性和准确性。本文所提方法可以用于微博短文本流的热点话题发现,对社交网络中信息推荐和舆情监控等具有支撑作用。
猜你喜欢
作文大王·低年级(2022年3期)2022-03-19
计算机系统应用(2021年9期)2021-10-11
现代信息科技(2020年18期)2020-02-22
计算机技术与发展(2018年8期)2018-08-21
动漫界·幼教365(大班)(2018年6期)2018-05-14
小学生作文·小学低年级适用(2018年12期)2018-04-11
计算机应用与软件(2018年1期)2018-02-27
网络空间安全(2016年3期)2016-06-15
校园英语·下旬(2016年2期)2016-03-18
中国有色金属(2014年23期)2014-03-13
