
基于深度学习的域适应方法综述
2022-06-16 02:32朱雅喃
数据采集与处理 2022年3期
田 青,朱雅喃,马 闯
(1.南京信息工程大学计算机与软件学院,南京 210044;2.南京信息工程大学数字取证教育部工程研究中心,南京 210044)
引 言
域适应(Domain adaptation,DA),主要解决源域与目标域之间分布不同的相似任务决策问题,通过将源域知识迁移到目标域中,解决目标域任务[1⁃8]。常规机器学习模型通常假定训练集(源域)和测试集(目标域)来自同一分布。一旦违反这一准则,由于源域和目标域分布存在差异,此时,源域上训练的分类器应用在目标域上的效果将大打折扣。然而,在实际问题中,以上假设通常难以满足,以致预测模型在目标域上很难达到预期效果。为应对以上跨域分布差异的机器学习问题,域适应[9]的学习范式被提出。
在域适应中,通常将有监督的训练域称为源域,半监督或无监督的训练域称为目标域。根据目标域标签数据,域适应分为半监督域适应、无监督域适应和其他域适应。基于域知识迁移层面,可将域适应分为3类:基于实例加权的域适应方法[1⁃2]、基于特征的域适应方法[3⁃6]以及基于模型的域适应方法[7⁃9]。具体而言,基于实例加权的域适应是通过调整源域样本和类间权重以减小源域与目标域之间分布差异的;基于特征的域适应则利用新的特征表示空间的方式来拉近域之间的特征分布距离;基于模型的域适应,对源域模型知识迁移利用,以实现领域之间的对齐。以上域适应方法划分如图1 所示。
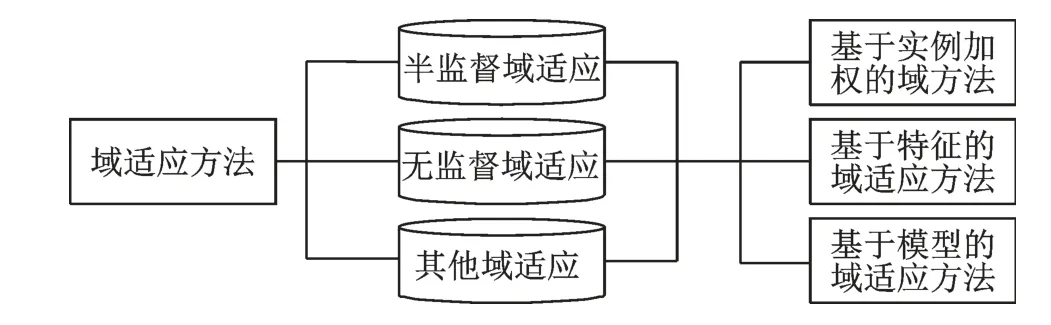
图1 域适应学习方法划分图Fig.1 Three categories of domain adaptation methodologies
近年,以GAN[10]为代表的深度对抗学习技术开始被用于域适应学习领域。根据是否采用对抗学习的建模机制,现有的深度域适应方法可归纳为非对抗域适应和对抗域适应两类。在大多情况下,对抗域适应方法取得了总体优于非对抗域适应方法的性能。基于对抗学习机制的对抗域适应模型通常主要包括跨域表征提取模块、领域判别器等部分,通过领域判别器与跨域表征提取模块之间的对抗学习,实现领域无偏(domain⁃invariant)的跨域表征,最终实现领域适应。目前,对抗域适应大多采用最小⁃最大(min⁃max)的分段交替优化方式实现模型参数的求解;而部分工作通过在模型中引入梯度反转层[11](Gra⁃dient reversl layer,GRL),进而采用梯度下降的方式实现模型求解。实际上,梯度反转层GRL 作为模型训练过程中的一种优化求解方式,与分段交替优化方式在本质上相同,都是为了实现领域无偏表征的对抗生成。尽管目前已有一些域适应研究综述论文[12⁃16],但鲜有系统性工作将对抗域适应方法作为单独分类进行分析总结。例如,Shao 等[12]从视觉分类应用的视角回顾了域适应研究;Day 等[13]对异构情景下域适应方法进行了总结。尽管以上工作[12⁃13]对域适应进一步发展和研究提供了借鉴意义,但并未将深度域适应方法作为回顾分析重点。除此之外,Csurka 等[14]从传统建模视角罗列了一些应用较为广泛的域适应研究工作,并结合分类损失、分布差异损失和对抗机制差异对深度域适应方法进行了划分;Wang 等[15]进一步从模型应用视角出发,对文献[14]进行了扩展和补充。虽然上述工作[12⁃13]涵盖了部分已有对抗域适应方法,但它们侧重从其他研究视角进行分析,未能对方法的对抗建模机制进行分类和分析。鉴于对抗学习在域适应研究中的逐渐普及,本文主要基于模型结构是否涉及对抗学习机制,将现有深度域适应方法划分为深度对抗域适应和深度非对抗域适应两大类,并逐类进行回顾和分析。
如图2 所示,本文着重对深度域适应方法进行回顾分析,根据建模机制将深度域适应方法分为对抗域适应和非对抗域适应两类。其中,非对抗域适应方法中包含基于差异度量的域适应、基于分布对齐的域适应和基于编码重构的域适应;对抗域适应方法包含基于标签空间的对抗域适应、基于数据增强的对抗域适应、基于距离度量的对抗域适应和基于其他机制的对抗域适应。本文主要贡献如下:首先,对域适应的背景、概念进行概括总结;其次,以是否生成对抗样本为划分标准,将深度域适应方法分为对抗域适应方法和非对抗域适应方法;然后,对域适应应用方向及常用的实验基准数据集进行归类和总结;最后,总结当前域适应方法研究现状,提出当前方法存在的不足以及未来可能的研究方向。
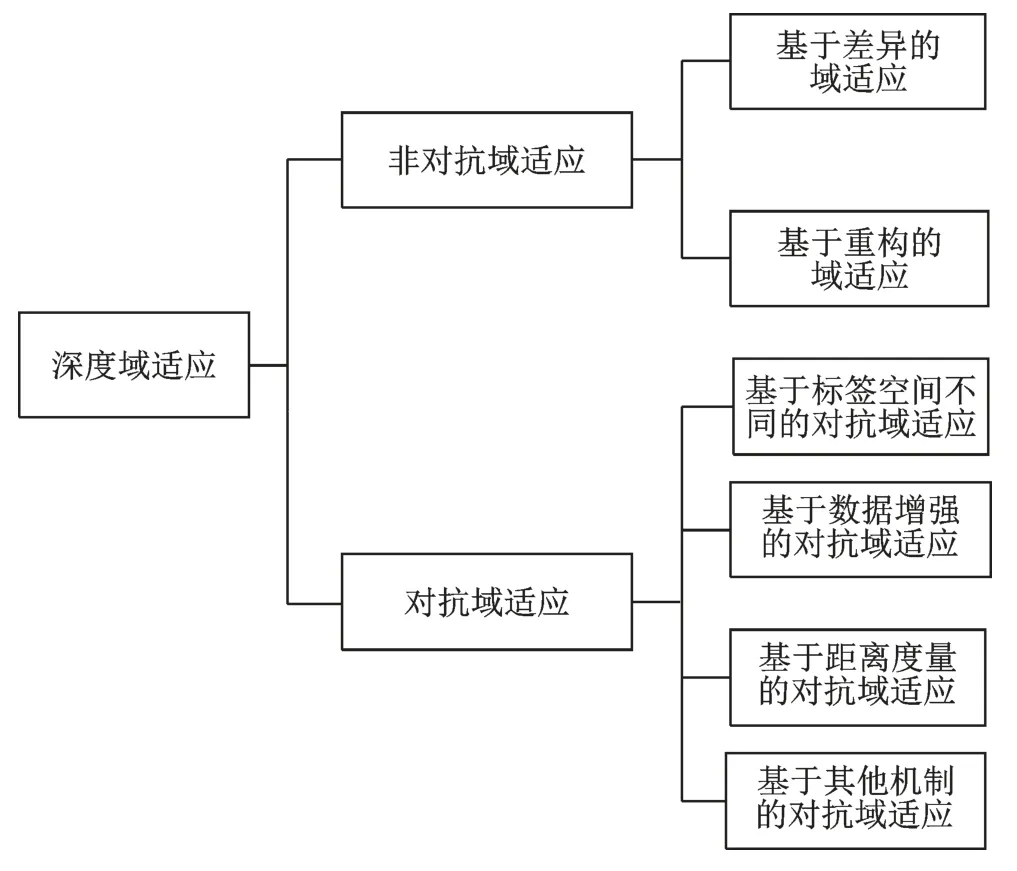
图2 深度域适应方法划分Fig.2 Deep domain adaptation and its categories
1 预备知识
1.1 域适应概念和符号定义
域适应方法中相关概念参照文献[15]定义如下。领域(Domain)[16⁃17]是学习的主体,领域由数据和生成数据的概率分布这两部分组成。通常情况下,D代表Domain,P代表概率分布。在域适应中,有两类基本领域,即源域(Source domain,Ds)和目标域(Target domain,Dt)。源域是领域知识已知的领域;目标域是待求解的任务领域。所谓域适应[18⁃20],即给定一个有标记的源域,和一个部分标记甚至无标记的目域任务。通常而言,假定源域和目标域特征空间相同(Xs=Xt),即源域和目标域数据的维度相同(ds=dt),但边缘分布或条件分布不同。为后文表述方便,在此对本文所涉及的主要变量和符号进行定义,如表1 所示。
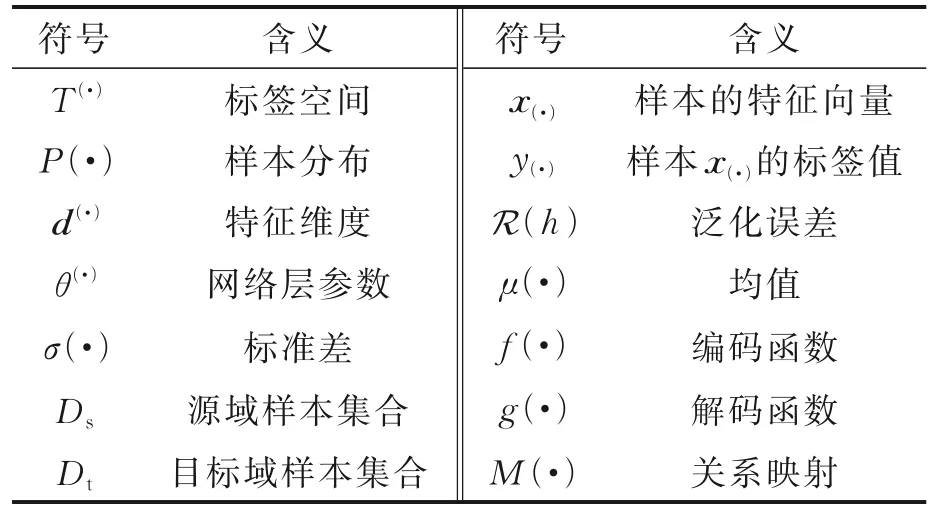
表1 变量和符号含义Table 1 Variables and definition of symbols
1.2 域适应场景划分
Pan 等[21]总结了不同数据集之间的差异导致领域之间的差异,即特征空间不同(Xs=Xt),或者标签空间不同(Ts≠Tt)。域适应有很多场景,不同场景对应不同的域适应方法,因此,根据是否有中间域连接,可将域适应方法分为一步域适应和多步域适应,如图3所示。根据领域差异(特征空间是否相同),可将域适应方法分为同构域适应和异构域适应。在每一类中,进一步将域适应划分为全监督域适应、半监督域适应和无监督域适应3 类方法。此外,根据领域之间的标签空间大小是否相同,域适应可被划分为闭集域适应(Closed set domain adaptation)[19]、部分域适应(Partial domain adaptation)[22]、开集域适应(Open set domain adaptation)[23]和通用域适应(Universal domain adaptation)[24]。鉴于现有的绝大部分域适应工作研究闭集场景下的域适应问题,因此本文主要对闭集域适应[25]相关问题和工作进行总结和回顾。
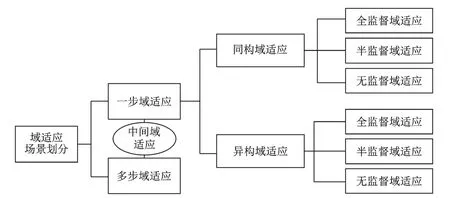
图3 域适应场景划分示意图Fig.3 Schematic diagram of different domain adaptation scenes
1.2.1 同构域适应
在同构域适应中,源域和目标域有相同特征空间,即样本实例中的特征维度相同(ds=dt),此时,源域数据集和目标域数据集的数据分布通常不同(P(Xs)≠P(Xt))。在域适应任务中,绝大多数情况下,源域样本被默认包含监督信息,即每个样本都有各自对应的标签值。极少数情况下会对源域样本是否含有数据标签进行讨论。因此本文所提出的以下分类方法中,默认所有源域样本包含标签信息,在这种情况下,本文进一步将域适应方法划分为以下3 类。
(1)全监督域适应
在全监督域适应中,源域提供大量有标签数据,尽管目标域的数据标签给定,但标记数量对于给定任务通常远远不够[26⁃27]。相较于半监督域适应和无监督域适应,全监督域适应研究工作相对较少。在全监督域适应方法中,一类典型方法是将同一类样本紧密映射到共同的潜在子空间中,同时将具有不同标签的样本分开。Saha 等[26]提出的最新研究方法,采用图嵌入方式,将域标签嵌入到惩罚图结构中。
(2)半监督域适应
在半监督域适应中,源域提供了大量有标签数据,目标域有充足的无标签数据和部分有标签数据[22,28⁃29]。具体而言,通过挖掘源域与目标域之间的相似关系,将可迁移知识从源域传递到目标域,解决目标域的分类任务。相较于无监督域适应,半监督域适应借助目标域上的少量标记信息进行域适应学习,通常能够在目标域上学得更具判别性的类别边界。因此,半监督域适应通常可获得优于无监督域适应的性能。
(3)无监督域适应
在无监督域适应中,源域数据提供大量有标签数据,目标域数据的标签缺失[30⁃32]。因此无监督域适应没有语义信息,需要大量目标域数据才能适应源域数据分布,无监督域适应的发展最初使用MMD(Maximum mean discrepancy)方法提取域不变特征[3]。随着深度网络的兴起,无监督域适应采用神经网络与MMD 结合的方式将分布对齐[30]。近几年,采用伪标签置信的方式或利用GAN 网络按类别对齐的方式也成为无监督域适应研究的主流方向[32]。
1.2.2 异构域适应
在异构域适应中,源域和目标域的特征空间[33⁃36]通常不同,即样本实例中的数据维度通常不匹配(ds≠dt)。相较于同构域适应,尽管异构域适应的研究难度更大,但异构场景在现实生活中更加普遍。如跨语言文本分类问题[37]和跨仪器医疗影像识别问题[38]等。与同构域适应相似,异构域适应也可以根据目标域样本的标记情况,被划分为监督域适应[32⁃36]、半监督域适应[35]以及无监督域适应[24]3 类情况。
1.2.3 多步域适应
在多步域适应中,知识传递通过一系列中间域实现。当源域和目标域有直接联系时,知识传递可以一步到位,通常称其为一步域适应。但实际情景中,当源域和目标域之间几乎没有重叠时,执行一步域适应方法可能导致负迁移。多步域适应大致可分为两类方法,第一类方法是中间域真实存在,如Tan等[39]提出传递迁移学习;更进一步,提出远领域迁移学习,其中源域为人脸数据集,目标域为飞机类别数据集。另一类方法是通过生成中间域作为过渡域,来解决源域和目标域之间的跨域分布差异,如Moon 等[40]提出求解无监督问题的多步骤框架,并提出一种计算平均目标子空间的新方法,将计算出的变换矩阵应用于下一个目标数据作为预处理步骤,使目标数据更接近源域。Cui 等[41]在生成器和判别器上均采用渐灭桥(Gradually vanishing bridge,GVB)机制,利用过渡的中间域降低整体传输难度,并减少域不变中其他域的特有特性影响。
一步域适应与多步域适应学习过程之间的差异如图4 所示。具体而言,多步域适应使用一系列中间域连接两个不相关的域,通过中间域执行一步域适应,中间域能够使源域和目标域之间距离更近。
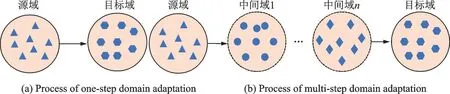
图4 一步域适应与多步域适应学习过程图Fig.4 Learning process of diagram one-step and multi-step domain adaptations
2 非对抗域适应方法
深度域适应是一种利用深度网络来提高域适应性能的方法。很多深度网络模型会开发自适应层完成源域和目标域的自适应,使源域和目标域数据更加接近,从而解决目标域任务,如图5 所示。深度网络中通用的网络损失定义为
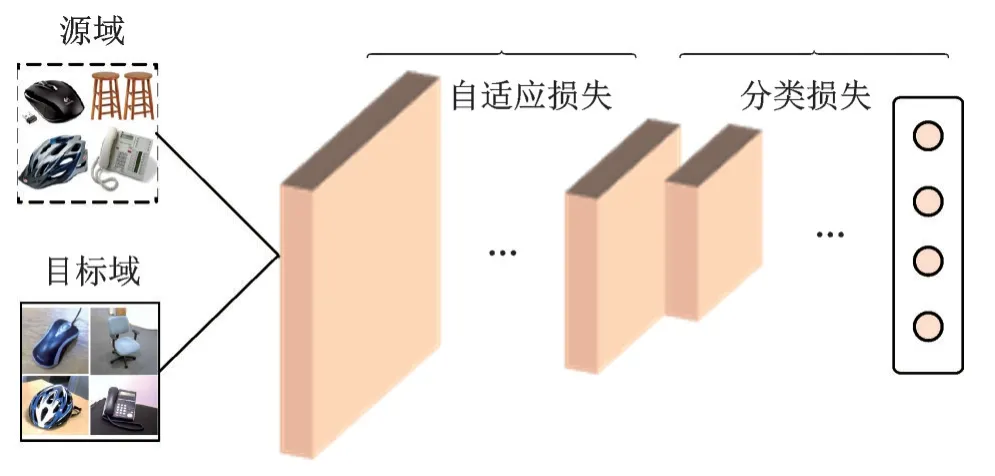
图5 深度网络中的通用损失Fig.5 Generic losses in deep networks
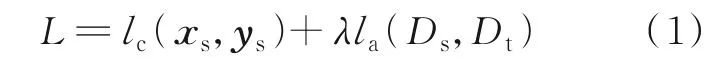
式中:L为网络全局损失,lc为网络的分类损失,la为网络自适应损失,Ds为源域数据集,Dt为目标域数据集,xs为源域样本,ys为源域数据集对应的标签,λ为权重参数。本部分将非对抗域适应方法进行划分和分析总结,主要分为基于差异度量的域适应、基于分布对齐的域适应和基于编码重构的域适应。
2.1 基于差异度量的域适应
在域适应中,目标域泛化误差可作为衡量目标域任务性能的标准,因此探究目标域的泛化误差是极其重要的。假定H 为再生核希尔伯特空间。给定源域S 和目标域T,则有∀h∈H 时
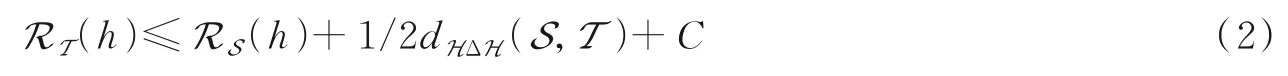
式中:RT(h)表示目标域的泛化误差,RS(h)表示源域的泛化误差,dHΔH(S,T)代表S 和T 两个域之间的分布差异。另外,C为最优联合泛化误差,通常被定义为

由式(2)可知,RS(h)可通过源域的监督信息最小化,因此降低目标域泛化误差上界的关键是缩减领域之间差异dHΔH(S,T)。根据差异度量准则的不同,缩减领域差异的方式主要基于图准则、基于标签准则和基于架构准则等方法。
2.1.1 图准则
基于图准则的域适应方法,将源域与目标域样本分别抽象为图结构。其中数据样本抽象为图结构中的顶点,样本之间的相似度关系,抽象为图结构中的边。因此源域与目标域数据集可被看作两个无向图。在此基础上,如果源域数据与目标域数据所抽象的图结构相似,则认为源域与目标域之间的差异足够小。基于以上原则,Mancini 等[42]提出了第一个基于图辅助的深度域适应框架,并将此方法应用在域适应的连续数据场景中。该项工作通过实例化由节点所组成的图,对源域与目标域之间的依赖关系进行建模,本项研究为该类方法在深度域适应方向的发展奠定了良好基础。此外,Ma 等[43]从样本关系的角度出发,采用图嵌入方法以保持不同领域样本的相似性和可辨别性。然后,在统一的目标下,优化矩匹配和几何对齐,从而学习一个子空间,以减少域间和域内的差异。另外,Morsing 等[44]也提出了双流体系结构的图嵌入域适应方法。在文中,作者设计了两个图模型,第一个图模型用来编码类内特征,使同一个类内的样本足够接近。第二个图模型用来维持类间的距离,使不同类之间的样本距离足够远。由于域适应的主要任务是找到源域和目标域的公共特征表示空间,这一过程可被视为特征降维。而图嵌入方式是在维持图固有结构的基础上,将图顶点映射成低维向量的过程。因此,可用图嵌入的方式实现源域和目标域样本降维,从而找到源域和目标域的公共特征表示空间。
上述方法,在知识迁移和适应的过程中充分地考虑了领域之间的结构,从而减轻了知识传递的难度。此外,图神经网络具有良好的性能,是一种基于深度学习的图信息处理方法,成为了广泛应用的图分析法。迄今为止,基于图准则的域适应方法并未和图神经网络相结合。因此在未来研究中,可考虑图神经网络与图准则相结合的域适应方法。
2.1.2 标签准则
在网络分类问题中,经常使用交叉熵损失,交叉熵衡量的是实际输出概率与期望输出概率之间的差距,即用来度量两个分布之间的差异。域适应中最基本的损失为分类损失,大多数域适应方法中的分类损失采用交叉熵损失,定义形式为
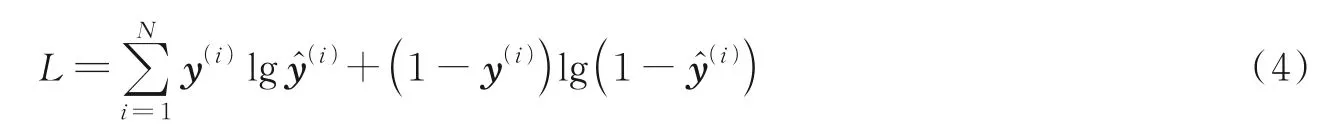
式中:y(i)为样本真实标签为预测标签。当y为0 时,式(4)变为,预测输出与真实输出相差越大时,对应的惩罚项值越大,并且成指数级增长,这是由log 函数本身特性所决定的。但是,由于交叉熵损失关注于正确预测标签概率的准确性,忽略了非正确标签的差异性,因此利用交叉熵损失学习到的特征较为松散。Morsing 等[44]将Softmax 输出变换为软标签输出,定义形式为

式中:Ci、Cn为对应的每一类的神经元输出;T可控制标签的软化程度,通常设为1,T值越大意味着标签的软化程度越高。相较于硬标签,软标签损失的不同之处在于更加注重类别之间的关系。在此启发下,Tzeng 等[45]首次将软标签应用到域适应分类中,以此缩减源域与目标域之间的条件概率分布。在此之后,Timnit 等[46]对软标签损失进行了改进,改进后的损失能够同时让属性级别和细粒度级别的损失达到最小。在实际问题中,目标域标签通常无法获得。因此Yan 等[47]提出利用伪标签为目标域样本进行分类。一般而言,域适应中分类的准确性与置信度相关,分类的置信度越高意味着分类的结果越准确。反之,置信度越低意味着分类的结果越不可靠。而置信度由熵值衡量,其表达式为

式中:H(为输出的熵值为非对抗域判别器输出;ln|Cs|为分类器的分类结果,熵值越高意味着分类的置信度越低,熵值越低意味着分类的置信度越高;wt(x)为目标域样本的可迁移性度量,是熵值和域判别输出的差与分类器分类结果的比值。虽然当前的域适应方法能够将源域丰富的标签信息转移到目标域任务中,但上述方法都基于源域标签信息不包含噪声信息这一假设。然而在现实情境下,源域的标签信息通常通过人工标注、众包收集等方式获取,不可避免地混杂错误的噪声标签。此外,目标域样本中也可能包含源域样本中不存在的无关类别标签。为应对以上问题,Yu 等[48]提出了双流卷积网络框架,该网络框架结构由一个生成器和两个具有不同决策边界的分类器组成,源域的标签决策函数由双向对称的KL 散度加和组成,目标域标签决策函数由KL 散度和熵值加和组成。该方法能够在检测源域样本噪声标签的同时,找到目标域中的无关类别。
综上,不同的分类损失形式有各自的优缺点,分类损失作为域适应损失中较为重要的一部分,应针对实际问题和场景进行选择。
2.1.3 架构准则
基于架构准则的域适应方法通常分为两种情况,第一种情况通过约束网络参数,利用正则项,确保源域与目标域之间的关联性。此类方法认为,源域与目标域数据分布存在高度相似性,因此源域网络与目标域网络的参数也应该具有相关性。Rozantsev 等[49]引入了双流体系结构,该结构模型中源域与目标域的对应层不共享但相关,具体如图6 所示。
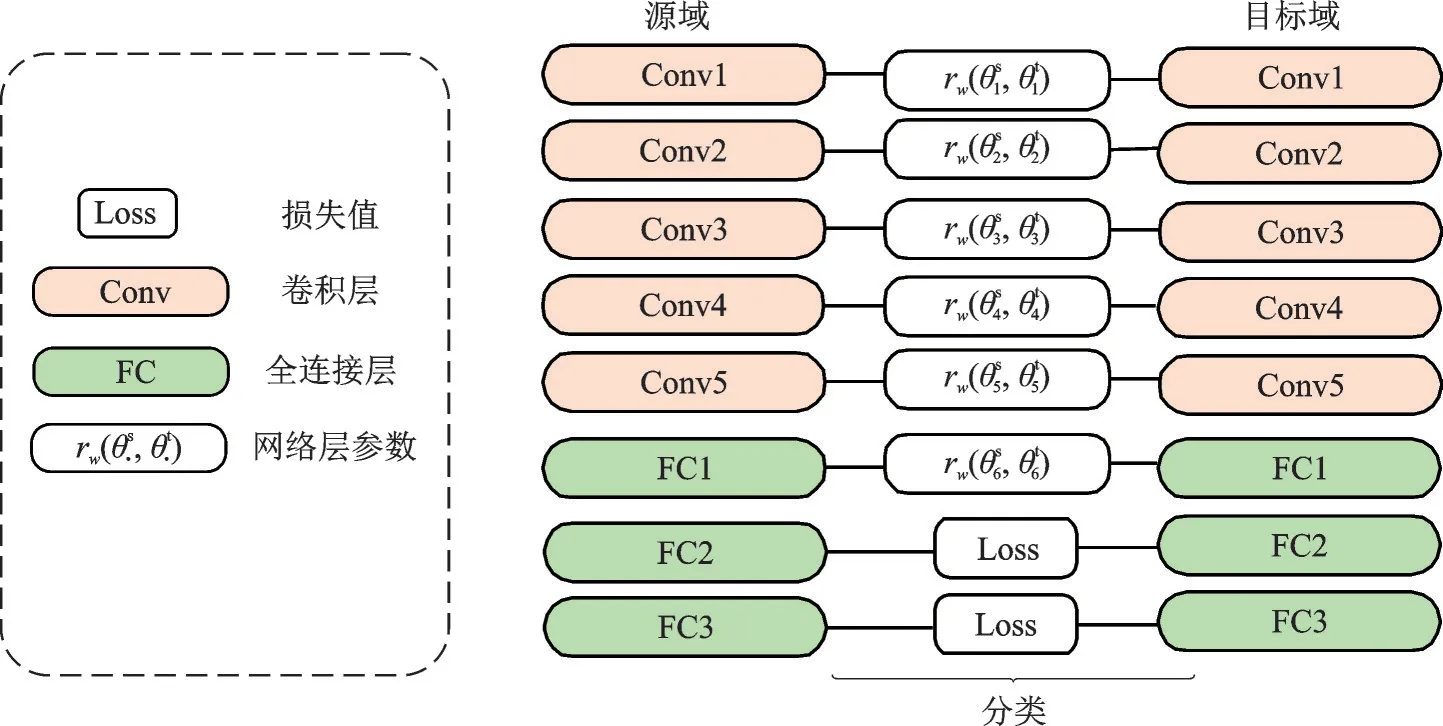
图6 基于正则项约束的双流体系网络Fig.6 Two-stream architecture based on regular term constraints
文献[50]中假设深度学习域适应方法不应该局限于学习领域不变性特征,而应该对域迁移部分进行显示建模。因此提出了权重正则项作为优化目标来缩减域之间差异,如式(7)所示。
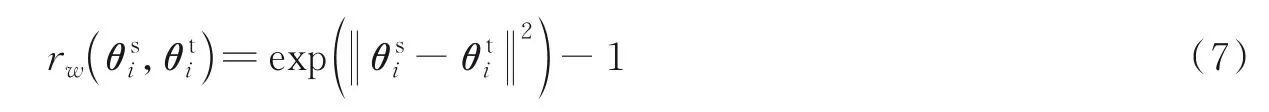
式中:为源域网络第i层参数,为目标域网络第i层参数。当源域网络和目标域网络参数之差的范数为0 时,指数形式值为1,此时达到理想情况下的最小值0,以此保证了两个网络之间的相关性。
第二种情况通过添加领域专属的批归一化层来缩减领域差异。Li 等[50]假定权重矩阵中蕴含类别相关知识,批正则层蕴含域相关知识,利用BN 层性质能够计算目标域均值和标准差,并将其与源域进行对齐,如式(8)所示。
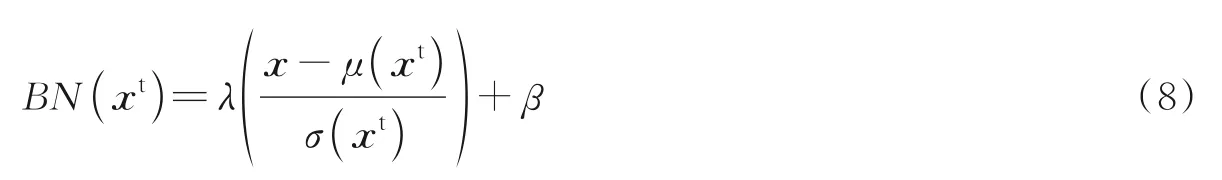
式中:λ和β为目标域所学参数,μ(xt)为目标域网络特征通道中的均值,σ(xt)为目标域网络特征通道中的标准差。式(8)中将样本值与样本均值做差后与其标准差做比值,能够保证网络层中所接收到的源域和目标域数据服从相似的分布。
总之,相较于其他方法,基于架构准则的域适应方法由最初的一个特征提取器变换为两个特征提取器,分别处理源域和目标域数据。由于源域和目标域数据分布之间存在相关性,因此两个特征提取器之间也应该存在一定的相关性。此类方法将数据之间的关系对应到模型层面,从而建立起两个领域之间的关系。
2.2 基于分布对齐的域适应
度量不仅是机器学习和统计学中常用的建模手段,更是域适应中常用的建模策略。度量的核心是衡量两个数据域之间的差异。具体而言,域适应中常用的分布差异度量方式包括KL(Kullback⁃leibler)散度、JS(Jensen⁃shannon)散度、沃瑟斯坦距离(Wasserstein distance)、希尔伯特施密特独立性系数、最大均值差异MMD(Maximum mean discrepancy)等。本文将其分别阐述如下:
KL(Kullback⁃Leibler)散度[51],又叫相对熵,本质上是两个概率分布P(X)和Q(X)之间的信息损失,KL 散度是非对称度量,如式(9)所示。
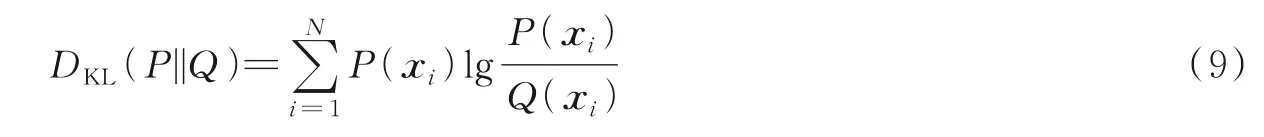
KL散度应用在域适应问题中存在的缺点为:当两个分布无重叠时,KL散度所得到的结果可能无意义。
JS(Jensen⁃shannon)散度[52]则是在KL 散度的基础上发展而来的,是基于KL 散度的变体。解决了KL 散度的非对称问题,是一种对称度量,如式(10)所示。
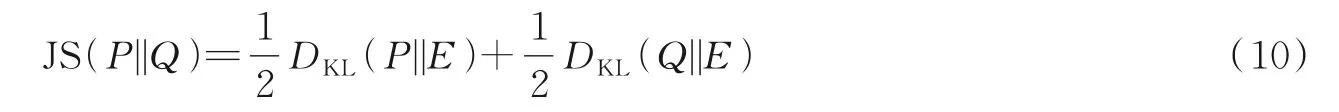
式中E=1/2(P+Q)。然而,JS 散度具有与KL 散度类似的缺点,即当分布P和Q距较远,完全无重叠时,JS 散度值为常数,导致学习过程中梯度消失。沃瑟斯坦距离(Wasserstein distance)[53]的定义如公式(11)所示。
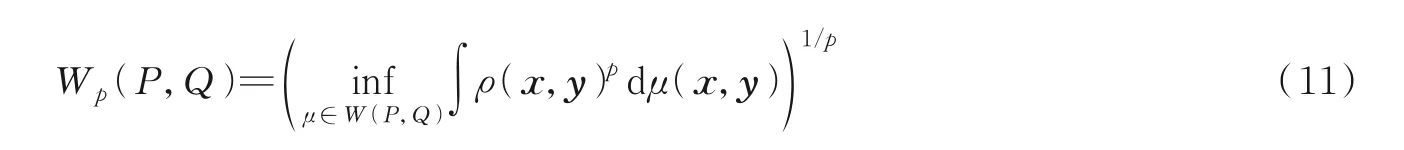
该距离定义在度量空间(E,ρ)上,其中ρ(x,y)表示集合E中两个实例x和y的距离函数,W(P,Q)表示集合E×E内所有的以P和Q为边缘分布的联合分布。沃瑟斯坦距离的求解是典型的线性规划问题,与传输矩阵中的各元素为线性关系,假设P(Xg)和Q(Xf)为边缘分布,则传输矩阵γ为两个分布的联合分布,对应的传输矩阵示意图如图7 所示。
图7 传输矩阵示意图Fig.7 Illustration of transfer matrix
当γ边缘化Xg和Xf时,对应的边缘分布变为
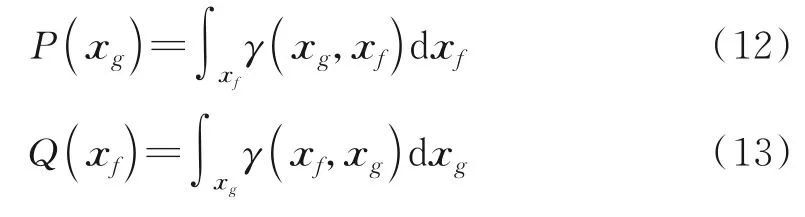
此时,利用γ矩阵所得的沃瑟斯坦距离变换为
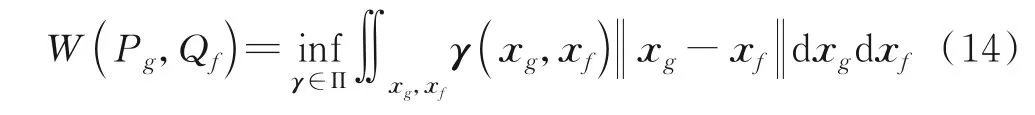
沃瑟斯坦距离,能够很自然地度量离散分布和连续分布之间的距离,并且能够在保持自身分布的几何形态特征基础上,将一个分布变换为另外一个分布尽管其能够解决KL 散度和JS 散度的缺陷,但沃瑟斯坦距离计算量庞大。
希尔伯特⁃施密特独立性系数[54]本身依赖于协方差而构建,是一种基于核的度量方法。此方法在再生核希尔伯特空间中定义了互协方差算子,然后从算子中推导出度量独立性的统计量,以此来验证两组数据的独立性,如式(15)所示。

式中:X、Y为数据的kernel 形式,H为中心矩阵。
MMD[55]度量再生核希尔伯特空间(RKHS)[56]中两个分布的距离,已被广泛应用在深度域适应中,如式(16)所示。
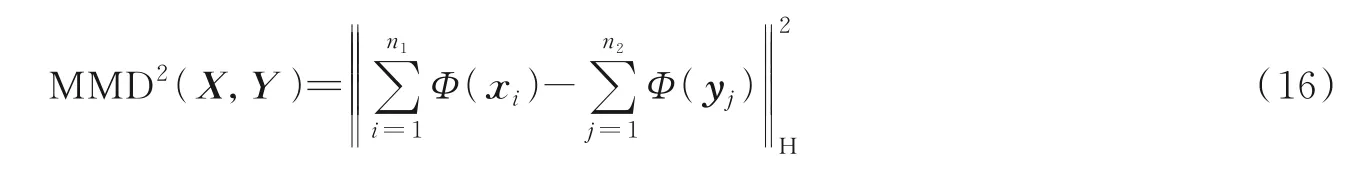
式中:Φ(·)代表特征空间映射,n1代表源域样本数量,n2代表目标域样本数量。MMD 变换过程如图8所示。
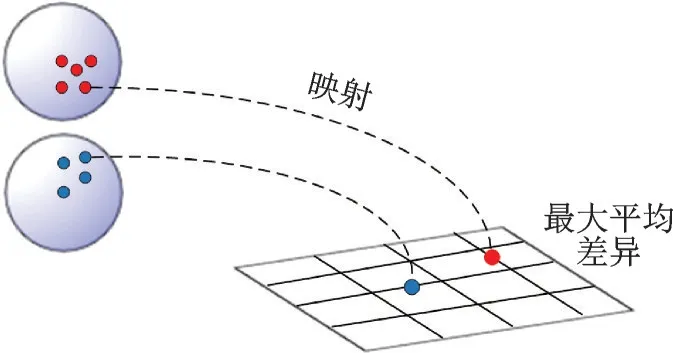
图8 MMD 距离Fig.8 MMD distance
上述度量标准和相关算法总结如表2 所示。

表2 常用度量标准和相关算法Table 2 Common metrics and related algorithms
2.2.1 边缘分布对齐
按照域分布对齐方式的不同,域适应方法大致分为边缘分布域适应、条件分布域适应和联合分布域适应(图9)。边缘分布域适应利用源域和目标域边缘分布概率距离,衡量两个域之间的差异,如式(17)所示。

图9 边缘分布对齐图Fig.9 Align map of edge distribution
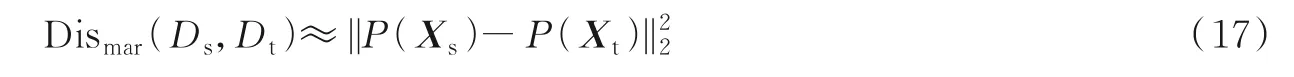
式中:Dismar(Ds,Dt)代表边缘分布差异度量,P(Xs)代表源域样本分布,P(Xt)代表目标域样本分布。
Ghifary 等[72]在早期提出DaNN(Domian adaptive neural networks)方法,DaNN 方法仅由两层组成,特征层和分类器层。作者衡量源域和目标域之间的损失的方法是在特征层后加入MMD 适配层。但由于DaNN 网络层数少,表征能力有限,因此无法有效解决域适应问题。后期很多研究工作都是在DaNN 方法基础上改进。例如,加深网络层次结构,改用VGG 或者AlexNet 等更深的网络结构。Tzeng 等[73]提出DDC(Deep domain confusion)方法训练源域和目标域的特征提取器,同时让两个网络共享参数,固定网络前7 层,并在高层中加入MMD 度量进行适配。
Long 等[74]提出的DAN(Deep adaptation networks)方法在DDC方法上加以改进,将原来的一层适配器改为3 层适配器,并且将度量改为MK⁃MMD(Multi Kernel⁃maximum mean discrepancy)。DAN 方法中添加了多个核以及多个自适应层,以缩减域间分布差异。但DAN 假设条件分布保持不变,这在实际应用中限制较大,且源域和目标域特征未必能通过DAN 有效对齐,因此,Long 等[30]提出RTN(Residual transfer networks)方法,在DAN 方法基础上加以改进。DAN 方法设计端到端的卷积神经网络,在原本接源域分类器的位置连接为残差网络结构,学习源域和目标域之间的差异。RTN 与DAN 的不同之处为,在RTN 方法中需要先融合特征再对特征使用MMD 惩罚。而DAN 方法中直接在自适应的多个特征层中使用多个MMD 惩罚。随后,Du 等[75]提出了最小化梯度偏差的方法,由于目标域样本缺少标签知识,文中通过基于聚类的自监督学习方式获得目标域的可靠伪标签,进而计算目标域梯度,让源域和目标域对齐效果更佳。
该类方法主要对源域和目标域的边缘概率分布进行对齐,仅考虑了全局特征变化,忽略了类内相似性,即未能考虑源域和目标域之间的条件分布概率差异。
2.2.2 条件分布对齐
条件分布域适应是用源域和目标域的条件分布概率来衡量两个域之间的差异,如式(18)所示。
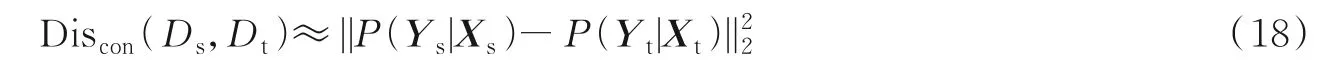
式中:Discon(Ds,Dt)代表条件分布差异度量,P(Ys|Xs)代表了源域样本的条件分布,P(Yt|Xt)代表了目标域样本的条件分布。
Saitod 等[76]提出非对称训练方法,缩减源域与目标域之间的条件分布差异。Wang 等[53]提出STL(Stratified transfer learning)方法,利用类内相似性施行类内迁移,达到更好的分类效果。Zhu等[77]提出深度子域适应网络,通过对齐特定激活层的相关子域来更新模型参数,进而使源域和目标域之间的条件分布对齐(图10)。
图10 条件分布对齐图Fig.10 Align map of conditional dis⁃tribution
此类方法虽然关注了源域和目标域之间的类内相似性,却忽略了全局特征变化。目前,单纯实现条件分布对齐的域适应方法较少,其通常与边缘分布对齐联合建模使用,以达到更高的域适应分类准确性。
2.2.3 联合分布对齐
联合分布域适应同时考虑源域和目标域的边缘分布概率和条件分布概率,以此来衡量两个域之间的差异,如式(19)所示。
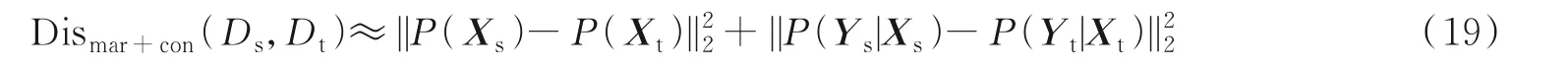
式中:Dismar+con(Ds,Dt)代表联合分布差异度量,不同于DDC、DAN、RTN 等边缘分布对齐的域适应方法,以及STL 等条件分布对齐的域适应方法。
Long 等[78]提出的联合自适应网络JAN(Joint adaptation networks)同时从边缘分布和条件分布对齐的角度进行域适应建模。JAN 基于联合最大平均差异(JMMD)准则,在深度网络中进行联合分布自适应。此外,Zhang 等[79]提出的DTN(Deep transfer network)方法,将网络分为共享特征抽取层和判别层。样本边缘分布和条件分布基于MMD 匹配,其中,共享特征提取层利用特征子空间,来对源域和目标域的数据进行边缘分布匹配,判别层利用分类器来对源域和目标域的数据进行条件分布匹配。马闯等[80]提出了一种双重加权的无监督域适应模型,首先通过目标域样本的适应性加权调整目标域样本权重,实现源域和目标域整体分布对齐,即边缘分布对齐。其次通过对源域类层面适应性加权调整源域类权重,实现源域和目标域的类分布对齐,即条件分布对齐。
这类方法不仅关注了全局的特征变化,还利用了源域和目标域的类内相似性,在对齐边缘概率分布的同时,也进行了领域之间的条件概率分布对齐(图11)。以上3 种域适应方法归类总结如表3所示。
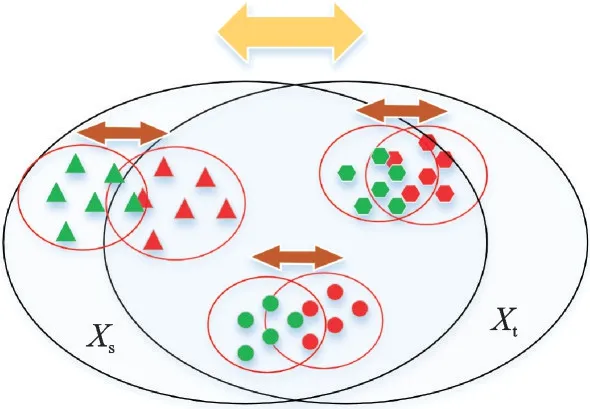
图11 联合分布对齐图Fig.11 Align map of joint distribution

表3 3 类分布对齐方式的域适应Table 3 Domain adaptation of three types of distri⁃bution alignment
2.3 基于编码重构的域适应
基本的自动编码器框架[90]为前馈神经网络,包括编码和解码过程,通过编码函数f(·)与解码函数g(·)分别进行表示(图12)。自动编码器首先对隐藏表示的输入进行编码,然后将隐藏表示解码回重建版本,如式(20)所示。
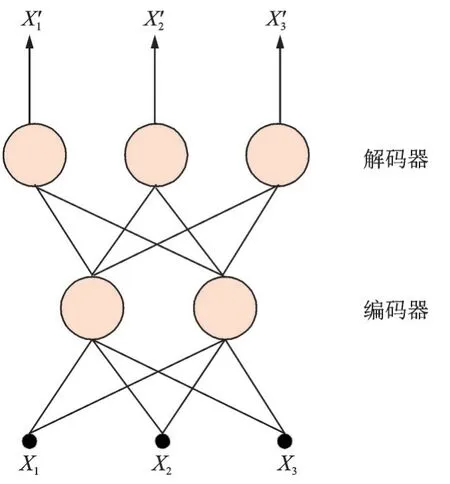
图12 自动编码器的编码与解码Fig.12 Encoding and decoding of the autoencoder

式中:x为输入的样本特征,z为隐含特征,为重构之后的输出特征。输入的样本特征可经过编码器学习到隐含特征,学习到的隐含特征可经过解码器重构到输出特征。
Vincent 等[91]提出基于叠加去噪自动编码器(Stacked denois⁃ing autoencoders,SDA)的高级表示方法,通过同一网络,重建来自不同域的数据,高级表示可以同时表示源域和目标域数据。因此,在源域的标记数据上训练的线性分类器可以对目标域数据进行预测。尽管SDA 在测试任务上取得了显著的结果,但其受计算成本高和特征维度高伸缩性差的制约。为了解决这些局限性,研究者们提出了边缘去噪自编码器(Marginalized denoising autoencoders,MSDA)[92],MSDA 用线性去噪器将噪声边缘化。用封闭形式计算参数,而且不需要随机梯度下降。MSDA 仅在20 行代码中即可实现,除此之外,MSDA 学到的表示与传统SDA 同样有效,可在基准任务中获得与传统SDA 几乎相同的精度,MSDA 在域适应中的应用也取得了显著成效。
重构域适应方法在此后得到了更深入的研究,Ghifary 等[93]提出一种新的基于深度学习的无监督域适应的目标识别算法。即通过设计深度重建分类网络(Deep reconstruction classification networks,DRCN)学习共享编码表示,为跨域对象识别提供有用信息。DRCN 是CNN 架构,它将两条管道与共享编码器结合,如图13 所示。
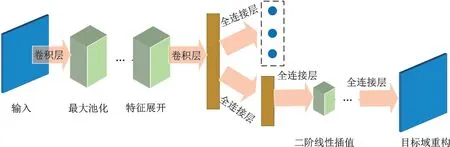
图13 深度重构分类网络框架Fig.13 Deep reconstruction of the classification network framework
在编码器提供表示后,第1 个管道(即CNN)用于具有源标签的监督分类。第2 个管道(即反卷积网络)对目标域数据的无监督重建过程进行优化。DRCN 为了将学习到的标签预测函数对目标域图像分类,其编码参数是共享的,而解码参数是分开的,以此将数据重建作为辅助任务以加强标签预测的准确性。
此外,域分离网络(Domain separation networks,DSNs)[94]对域表示的私有和共享组件进行建模。共享解码器通过学习私有和共享表示来重建输入样本,在共享表示上训练分类器。通过这种方式划分空间,共享表示不会受到特定于域的表示影响,可以获得更好的传输能力。模型经过训练,不仅能够在源域内执行目标任务,而且可以使用分区表示从两个域中重建图像。
Tsai 等[95]在分离网络和适应网络中加入混合对抗学习。文中指出,传统的域适应方法试图学习源域和目标域之间的共享表示,在没有提取源域和目标域个体信息的情况下进行分布匹配。该方法存在共享信息和个体信息混合的问题,极大限制了域适应性能。为了放松此约束,提取共享信息和个体信息至关重要。因此,该项研究通过新的域分离网络来获取共享信息和个体信息。在分离网络和自适应网络中,分别通过最小化分离损失的和最小化域偏差损失,对网络进行自适应训练。
Zhuang 等[96]认为,之前的大多数工作既没有显式缩小源域与目标域之间的差异,也没有在学习表示时编码标签信息。因此笔者提出了TLDA 方法(Transfer learning with deep autoencoders)。TLDA具有如下特点:(1)编码和解码权重在不同领域共享;(2)标签信息被编码。总之,基于编码重构的域适应方法是一种可抑制信息损失的无监督学习方法。该类方法通过共享编码器等方式学习跨域不变表示,并且通过源域和目标域之间的重建损失保持域私有表示。该类方法不仅可以降低信息损失,还可以将样本特征分解为域不变特征和域私有特征,从而减缓知识传递的难度。然而,该类方法通常因自编码器的表征能力有限导致其应用受限。
2.4 本节小结
本节对非对抗域适应方法进行了分类总结,按照实现域适应方式的不同,将其划分为基于差异度量的域适应、基于分布对齐的域适应和基于编码重构的域适应。一般而言,非对抗深度域适应方法通过深度神经网络,来减小源域与目标域的数据分布差异,进而实现域不变知识的跨域迁移和复用,并辅助目标域完成相关任务。但在实际应用中,尤其是医学图像处理上,域漂移问题仍然十分突出,因为医学放射影像(如CT 图和MRI 图等)与光学仪器拍摄的自然图像的成像方式截然不同,以致这些跨模态数据之间的分布差异巨大,非对抗域适应方法在跨模态数据中的表现效果通常不佳。
3 对抗域适应方法
对抗域适应受GAN 网络[10]的启发而近年逐渐兴起。GAN 网络最初由Goodfellow 等人提出,其目标是生成与训练集分布一致的数据,其中生成器负责生成样本试图混淆判别器,而鉴别器则试图区分样本的真实性,如图14 所示。
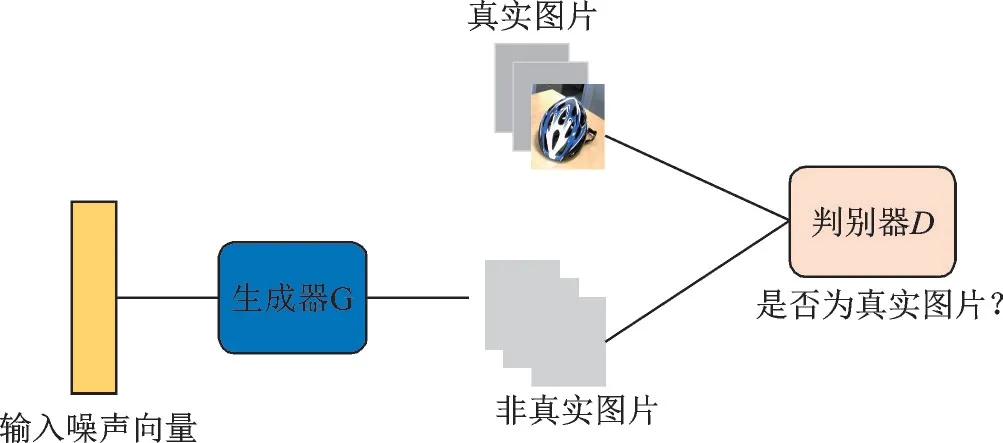
图14 GAN 网络模型Fig.14 Model of GAN
网络以对抗方式训练标签预测损失,优化G达到最小化损失的同时训练D最大限度地提高分配标签正确的概率,使模型最终达到纳什平衡点,GAN 的总体优化函数如式(21)所示。
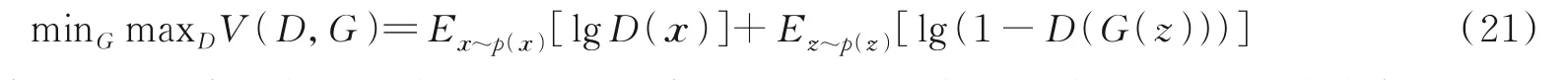
式中:x~p(x)代表x来自真实数据分布,而z~p(z)代表z来自生成数据分布。此后,研究者们相继提出了很多GAN 网络模型的变体。总体而言,分为基于结构优化的GAN 网络[97⁃103]和基于目标函数优化的GAN 网络[104⁃109]等,具体如图15 所示。GAN 网络模型的提出,使对抗学习方法成为域适应领域中常见方法之一。
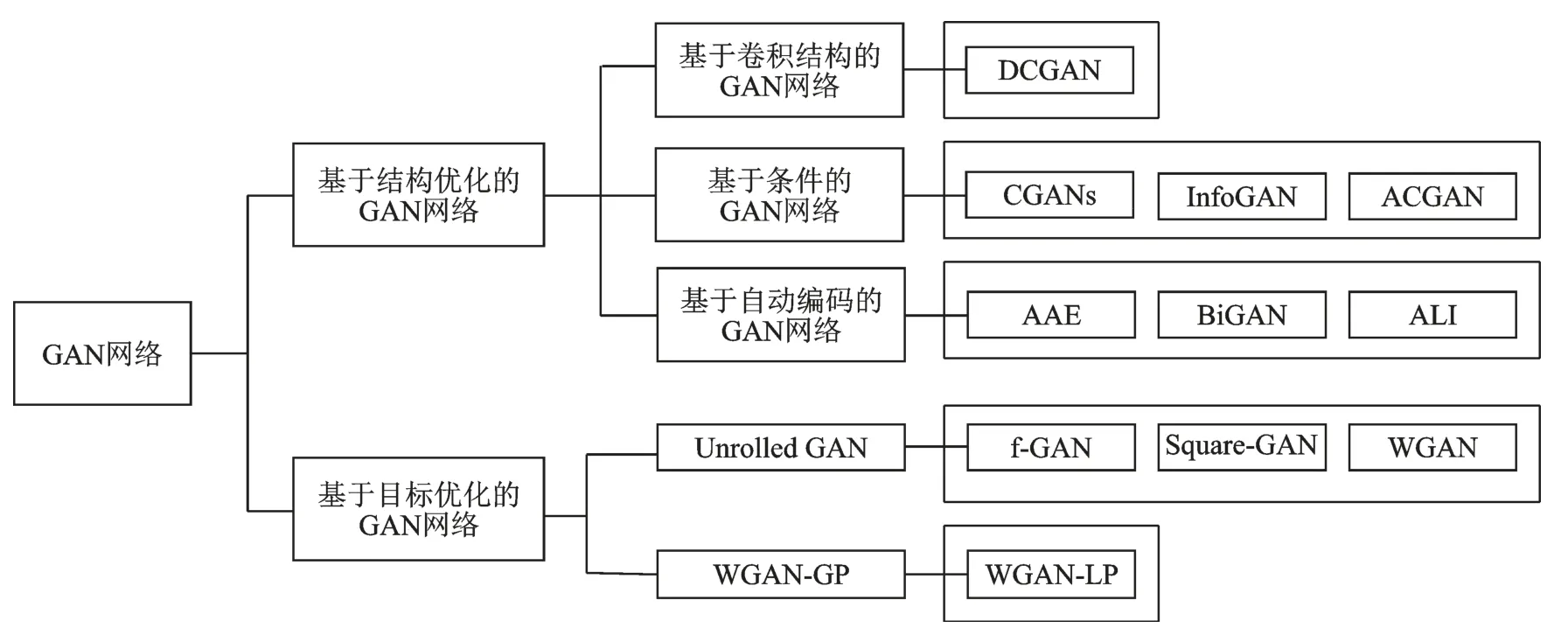
图15 GAN 网络不同的衍生模型Fig.15 Extended model from GAN
基于对抗学习的域适应方法将生成对抗网络的思想引入到域适应问题中,GAN 网络模型中的鉴别器试图准确地预测样本来自真实数据分布还是来自生成器。类似地,在域适应中可以设计鉴别器以区分源域分布和目标域分布。此时,生成器和判别器之间的博弈过程转换为特征提取与域判别之间的博弈过程。在域适应中,这一原则被用来确保网络不能区分源域和目标域样本。相较于非对抗域适应方法,对抗域适应方法能通过生成器与判别器之间的动态博弈过程更有效地提取域不变特征,并多数都取得了优于非对抗域适应方法的效果。
Tzeng 等[110]提出基于对抗性方法的统一框架,并根据是否使用生成器、使用何种类别损失函数或是否跨域共享权重总结了现有的方法。Ganin 等[11]首先将对抗学习应用到域适应问题当中,并且创建了DANN(Domain adversarial training of neural networks)网络,深度域适应的关键是从源域和目标域样本中学习域不变表示。从而使两个域的分布足够相似,即使在源域样本上进行训练,也可以直接用于目标域。因此,表示领域是否混淆是至关重要的转移知识,DANN 所提的通用对抗域适应表达如式(22)所示。
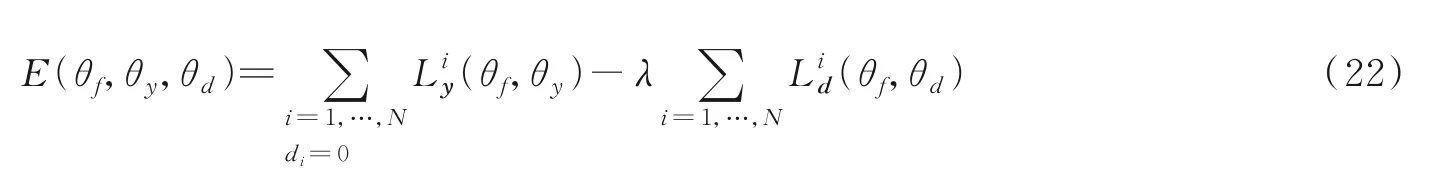
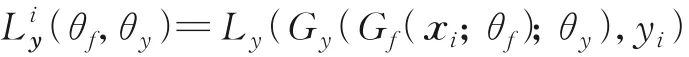
Tzeng 等[110]提出的对抗性判别域适应ADDA(Adversarial discriminative domain adaptation)方法通过迭代最小化3 个部分的损失函数来缩小源域和目标域之间的距离,如式(23)所示。
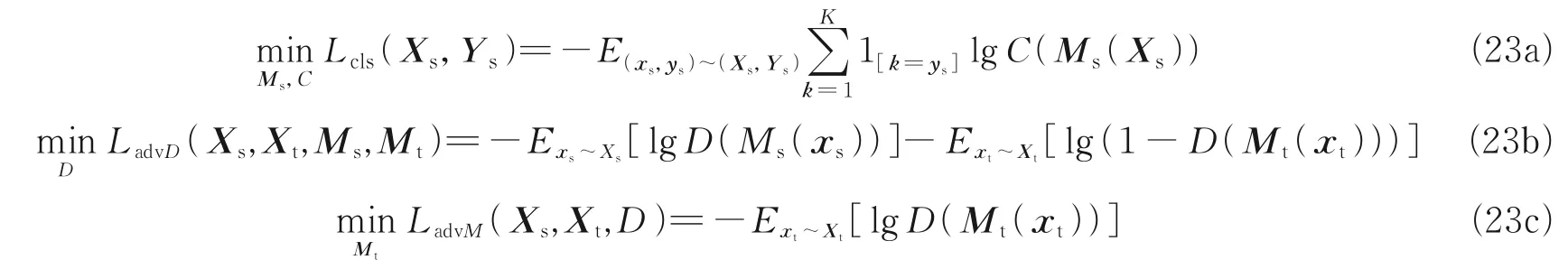
式中损失函数分为:源域经过映射后的分类损失Lcls;判别器进行域判别的判别损失LadvD;以及提取域不变特征损失LadvM。Ms为从源域数据中所学的映射,Mt为从目标域数据中所学的映射。相较于DANN 方法,ADDA 参数权重不共享,能够学习更多领域特有特征,从而更高效地缩减源域与目标域之间的差异。
DANN、ADDA 等方法的提出对对抗域适应方法的发展有着重要意义,此后,很多对抗域适应方法在此基础上加以改进。本文将对抗域适应方法进行分析总结,将其划分为基于标签空间的对抗域适应、基于数据增强的对抗域适应、基于距离度量的对抗域适应和基于其他机制对抗域适应,相关总结如表4 所示。

表4 四类对抗域适应建模策略Table 4 Four kinds of adaptive modeling strategies for adversarial domains
3.1 基于标签空间的对抗域适应
大数据时代,分类器和表示模型从现有大规模域转移到未知小规模域的情况普遍存在。因此,对抗域适应问题中存在不完全共享标签空间的情形。Cao 等[111]提出SAN(Selective adversarial net⁃works),引入标签空间不一致的对抗域适应方法,将共享标签空间这一假设放宽到:目标域标签空间是源域标签空间的一个子空间(图16)。
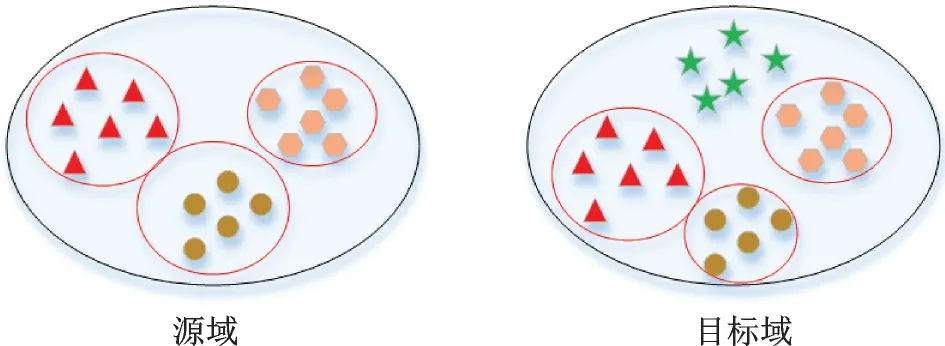
图16 标签空间不一致场景示意图Fig.16 Illustration of inconsistent tag space
在此方法之前,通常将整个源域与目标域匹配,在标签空间不同的场景下,此类方法容易产生负迁移。因此,SAN 通过筛选离群源类避免负传输,并且最大限度地匹配共享标签空间中的数据分布来促进正传输。针对标签空间的不同,Zhang 等[112]也设计了一种权值机制来减轻噪声样本和离群分类的影响,并嵌入多个对抗网络来实现域之间的各类别对齐。之后,Chen 等[113]提出了RTNet(Reinforced transfer network)网络结构,该项工作首次将强化学习引入到域适应问题中。文中提出,在标签空间不同的域适应问题中,大多数的方法通常为源域样本重新加权,进而选择与目标域相关的源域样本进行分布对齐。而RTNet 中利用了RDS(Reinforced data selector)网络结构对离群源域样本进行过滤,其中RDS 是基于Actor critic 算法的强化学习网络,用来筛选相关源域样本及过滤离群源域样本。
以上方法虽然将对抗机制引入到源域与目标域分布对齐工作中,但与目标域相关的源域样本的筛选工作仍然采用其他机制进行(如权值机制和强化学习机制)。未来,能否将对抗机制引入到相关源域样本的筛选工作中是值得关注的一个方向。
3.2 基于数据增强的对抗域适应
在深度对抗域适应中,基于数据增强的方法也得到研究者的关注[114],例如,在少数镜头学习场景中,由于缺乏数据,语义概率分布对齐和分离是困难的。因此,以CycleGAN[115]为代表的一类方法,通过最小化循环一致性损失,使得源域与目标域之间的数据能够相互转化(图17)。
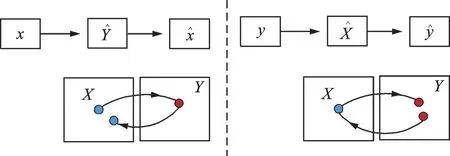
图17 循环一致性损失Fig.17 Loss of cycle⁃consistency
在深度学习中,图像空间中的数据增强是一种成熟的技术。Chen 等[116]提出像素级别的域适应方式,即利用CycleGAN 进行Image⁃to⁃Image 的图像增强。笔者认为,域之间进行图像转换时,预测任务应该保持一致,由此引入循环一致性损失。结果表明,相较于其他无监督域适应方法,该方法取得了更好的结果。尽管如此,但是特征空间的数据增强未能引起同等重视。为此,Wang 等[33]首次引入GAN网络模型在特征空间中进行数据扩充。他们通过GAN 训练的单一特征提取器强制域不变性。进而通过定义更复杂的极大极小博弈,在特征空间中进行数据增强,论文中通过利用CGAN 训练的特征生成器来实现特征空间的数据增强。其中,极小极大博弈针对特征层面进行,特征生成器允许生成符合所需类别的特征。因此CGAN 生成器能够学习类在特征空间中的分布,从而生成任意数量的标记特征向量。
最近,Na 等[117]通过对样本进行线性混合生成增广数据,并将增广数据作为中间域,输入到生成对抗网络中。通过在网络中进一步构建双向匹配、自惩罚和一致性正则化项约束来提升对抗建模机制的鲁棒性。结果表明,通过特征空间数据增强,可较好地提升无监督域适应的精度。
相较于其他方法,基于数据增强的对抗域适应方法通过扩充训练样本获得了更强的模型可解释性。该类方法可对稀疏数据进行扩充,有效解决因缺少数据而导致训练模型过拟合问题。而且通过比对生成样本与真实样本差异,该类方法也可及时感知领域之间的分布差异。
3.3 基于距离度量的对抗域适应
部分现有研究工作没有使用鉴别器对域标签进行分类,而是在距离度量方面进行研究探索。受Wasserstein⁃GAN[118]的启发,Shen 等[119]利用判别器估计源域样本与目标域样本之间的经验距离(Wasserstein distance),并对特征提取网络进行了优化,以对抗的方式将距离最小化。在对抗生成网络中,当域分类器能够有效区分目标表示和源表示时,网络就会出现梯度消失的问题。文中提出更为合理的解决方案,用Wasserstein distance 代替域差异度量,即使两个分布相距较远,也可以提供更稳定的梯度。最近,蔡德润等[120]通过在双向长短程网络中构建注意力机制,以此作为特征提取器提取复杂的时序数据,并在域对抗方法引入加性余弦间隔损失,来解决数据整体和类别之间的分布偏移问题。
总之,度量在域适应问题中尤为重要,成为衡量领域之间差异的主要方式。然而,距离准则的优劣,通常基于模型在目标域上的性能加以判断。对于何种距离度量方式对当前域适应问题最优以及相关机理,目前仍缺少相关的理论研究。因此,如何在对抗域适应中嵌入更有效的距离度量,仍是值得关注的一个研究方向。
3.4 基于其他机制的对抗域适应
Rahman 等[121]提出一种相关感知的对抗通用框架。该框架同时使用相关对齐和对抗学习来最小化源数据和目标数据特征差异。将相关对齐模块与对抗学习结合在一起,可以更有效地减少与未标记目标数据的领域差异,从而提高了模型的泛化能力。但是,丰富的领域特定特征给领域不变表示的学习带来了很大的挑战。在现有的解决方案中,领域差异被认为是直接最小化的[121],这在实践中很难达到理想效果。部分工作通过显式地对域不变和域特定部分建模来减轻传输困难,但显式构造的不利影响在于,所构造的域不变表示中保留了域特定特征。因此,Cui 等[124]在生成器和判别器上均采用渐灭桥(Gradually vanishing bridge,GVB)机制,实现了对抗域适应。GVB 不仅可以降低整体传输难度,还可以减少域不变中其他域的特有特性影响。Ahmed 等[125]提出,由于现实中很多应用对数据安全或隐私保护的要求,领域数据有时难以获取,如医院的患者数据以及公司的客户档案等。因此,笔者提出了一种基于隐私保护的对抗域适应建模机制,通过提高伪标签置信度,增大信息熵,来联合优化源域模型对应权重,以提高目标域任务的分类精度。
当前,对抗域适应研究沿着清晰的方向在发展,基于对抗的域适应方法将对抗机制完美引入到所需解决问题的特定情景中。除上述方法外,部分方法在对抗机制中加入渐灭桥原理,通过对抗机制生成中间域样本。此类方法在保持域不变特征的基础上模糊域私有特征,以减缓知识传递的难度。另一部分方法[126⁃127]采用对抗机制与注意力机制相结合的方式,选取样本图片中可迁移性强的部分进行学习。此类方法能够忽略图像中与目标任务无关的背景信息,最大程度地避免训练过程中的负迁移现象。综上所述,在未来,对抗域适应方法仍然有较大的发展空间和应用意义。
3.5 本节小结
本节对对抗域适应方法进行了分类总结,按照实现域适应方式的不同,将其划分为基于标签空间的对抗域适应、基于数据增强的对抗域适应、基于距离度量的对抗域适应和基于其他机制的对抗域适应。对抗域适应方法作为更具发展潜力的研究方向,拥有优于非对抗域适应方法的性能。究其原因,一方面相较于复杂的邻域间距离,对抗网络的设计相对简单,而且其提取域不变表征的能力更强。另一方面,对抗网络能够自适应实现源域和目标域之间的分布对齐,从而避免了人为的距离度量的设计。但是,受对抗网络收敛缓慢,对抗模型泛化能力不佳,容易出现模式崩塌等现象的影响,这主要是由于对抗网络模型中通常存在多个平衡态,不同平衡态之间的平衡点关联较弱所致。目前还缺少相关理论支撑推导模型的最优平衡点,这极易导致模型陷入局部最优,从而限制模型的性能。
4 域适应应用
域适应已广泛应用于各大领域,包括计算机视觉[122,128⁃139]、自然语言处理[140⁃146]和时间序列数据[147⁃152]。不同问题中利用域适应可以节省标记目标数据所需的人力时间。本文所描述的类似方法也可应用于领域泛化等相关问题。
(1)计算机视觉领域
现有的域适应方法大多面向计算机视觉任务,例如,将合成图像训练的模型适应于真实照片。在游戏行业中,游戏图像与真实场景之间存在领域差异,域适应成为解决该问题的主要手段。医学图像领域中,域适应也能将心脏核磁共振图转化为CT图[153⁃154]。此外,域适应方法也用于自主导航[122]、胸部X 射线分割[128](图18)、3D CT 扫描到X 射线分割[129]、目标检测[130⁃132]、行人重识别[133⁃139]等。
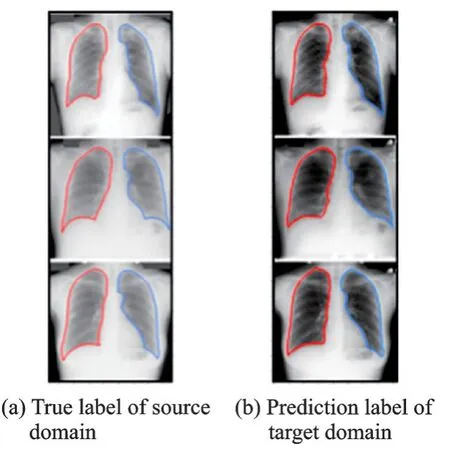
图18 胸部X 射线分割图Fig.18 X⁃ray segmentation of the chest
(2)自然语言处理领域
域适应还可用于自然语言处理问题,如情绪分析[140]、文本分类[140,142]、问题回答[143]、机器翻译[144⁃146]、词表征学习[155]以及关系提取[156]等。基于深度学习的域适应方法使得自然语言处理众多任务取得了重大进展。一方面,可以成功运用于分词、词性标注、成分分析、语义表示等任务;另一方面,可以提升问答系统、对话系统、阅读理解等应用系统的性能。
(3)时间序列数据领域
域适应在时间序列数据中应用广泛,既可用于学习提取不同年龄人口健康数据中的时间潜在关系[147],也可用于语音识别[148]、预测驾驶动作[149]、异常检测[150]等,其中,域适应在异常检测中的应用如图19 所示。
图19 域适应在异常检测中的应用Fig.19 Application of domain adaptation in anomaly detection
在领域泛化相关问题方法中,时间序列无线电数据被用于睡眠阶段分类[151],时间序列数据也可以结合预训练和微调等方式,解决源数据集与目标数据集标签空间不同的问题[152]。
(4)域泛化领域
域不变特征学习方法已经用于域泛化相关问题,即存在多个源域和一个未知目标域[157⁃158]。Ghi⁃fary 等[159]使用去噪自动编码器,利用重建方法提高物体识别的准确性。其中“噪声”是数据的不同视图(域)(例如,旋转、大小变化,或照明变化)和自动编码器试图重建在其他领域对象的相应视图。Carlucci等[160]在进行域映射的同时,提出了域适应和域泛化相结合的对抗性方法。由于域不变表示会与区分表示相竞争,Akuzawa 等[161]提出对抗特征学习与准确性约束(AFLAC)相结合的方法来找到不影响分类性能的域不变表示。
5 相关数据集与实验
相关数据集与实验结果分别如表5~8所示。

表5 实验所需数据集Table 5 Datasets required for experiments
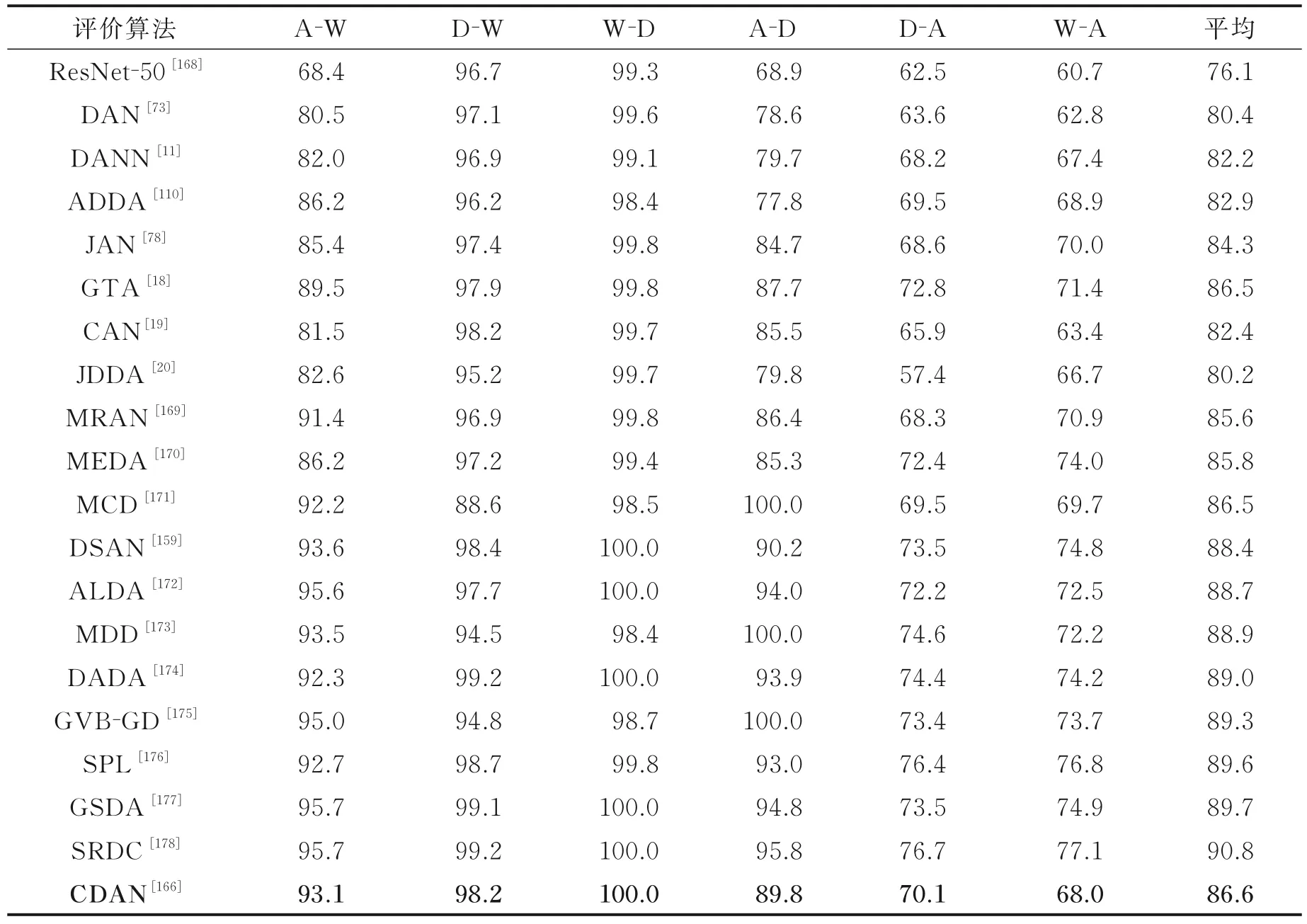
表6 Office31 数据集上的评价结果Table 6 Evaluation results on the Office31 dataset
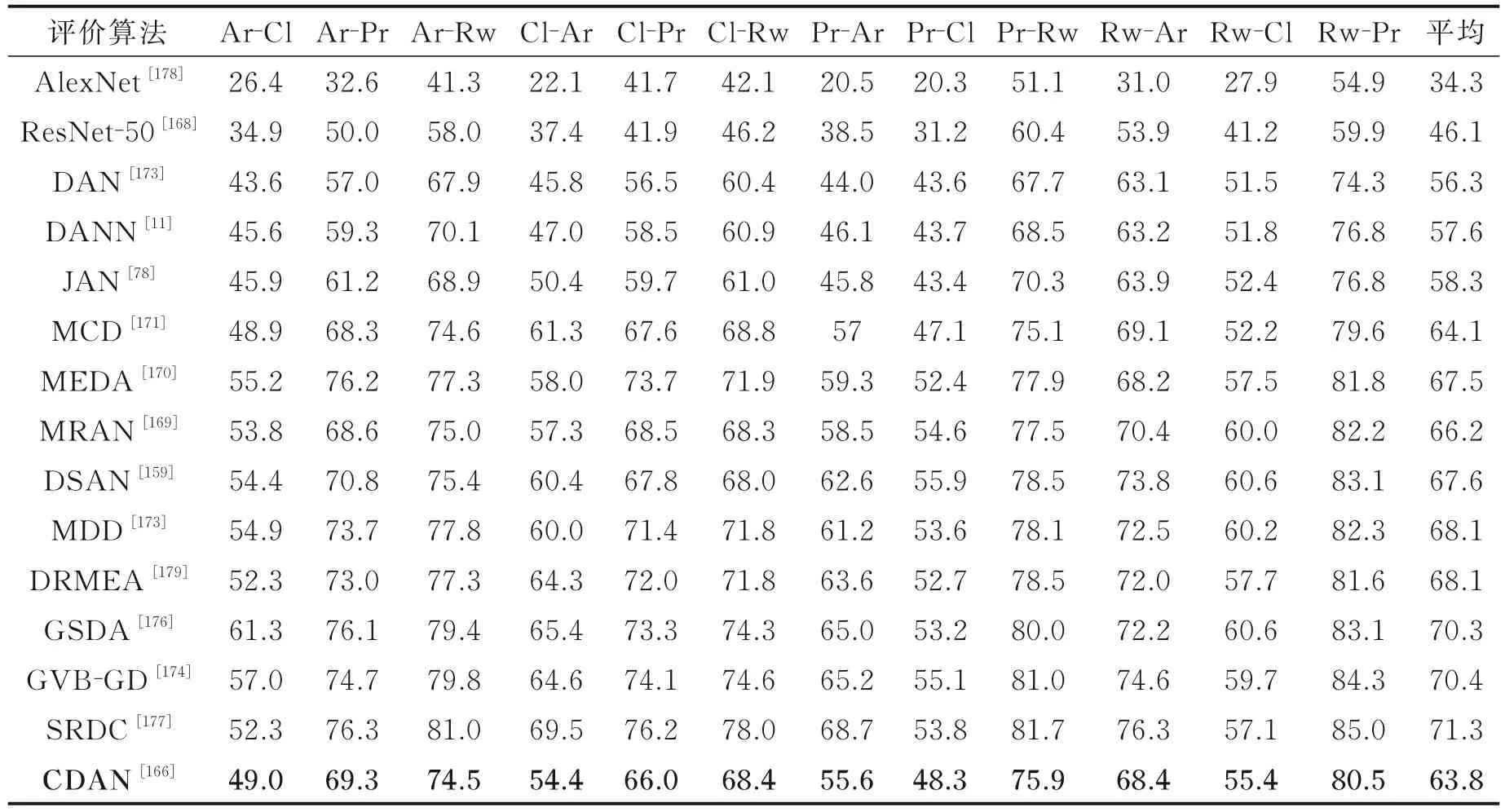
表7 Office⁃Home 数据集上的评价结果Table 7 Evaluation results on Office⁃Home dataset
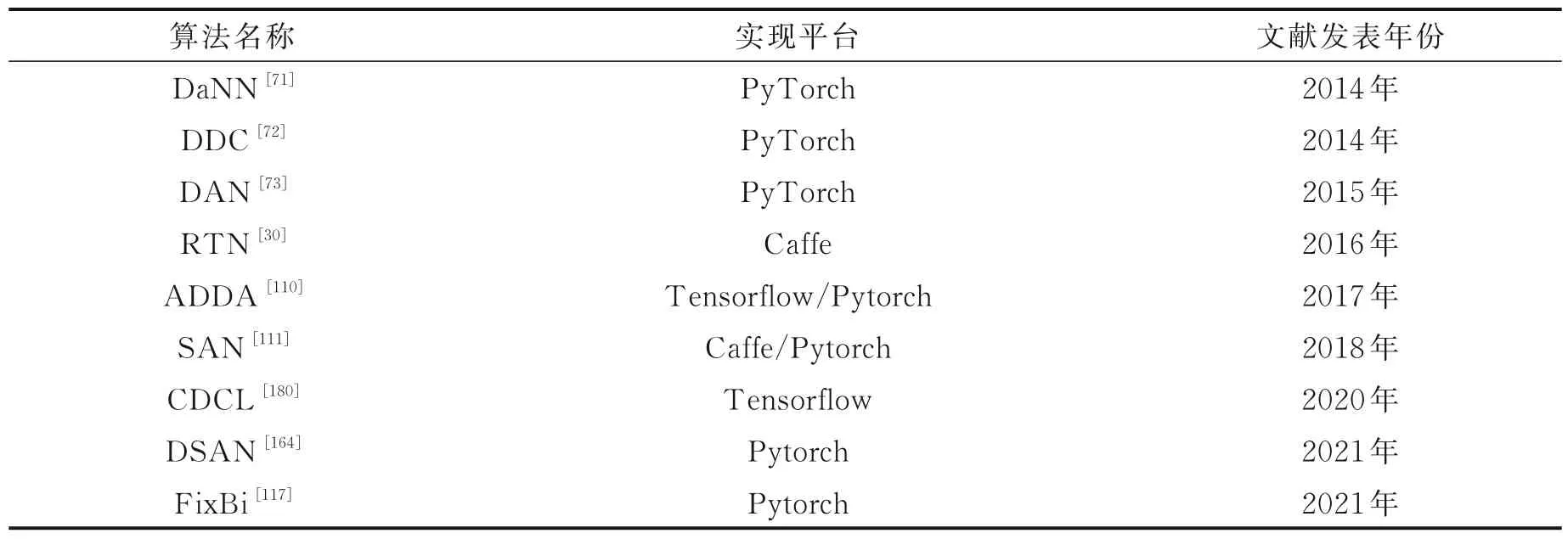
表8 深度域适应相关经典算法Table 8 Implementation of classical algorithms about deep domain adaptation
6 当前问题及未来研究方向
数据集的快速增长,为深度域适应发展提供了便捷,新方法层出不穷,实验结果更加精确。在此,本文展望未来的可研究方向,以进一步加强现有的工作。
(1)双向域适应
域适应的发展仍然面临更高难度挑战,例如,在域适应问题中,SVHN→MNIST 的准确率能够从70.7%提高到99.3%[181]。而对于MNIST→SVHN 的反向域适应,如果没有针对特定问题的超参数调优,准确率最高只能达到81.7%[182]。这表明反向域适应存在较大的难度,因此在未来的研究中,仍然需要加强对双向域适应问题的研究。
(2)超参数调优
反向验证和针对特定问题的匹配方法已经应用于超参数调优,这些方法并不需要目标标签。由于计算成本的增加[183]或反向验证精度与测试精度[184]不一致的问题存在,大多数方法并没有将反向验证广泛使用。Perone 等[183]针对特定问题提出了匹配领域之间像素强度的方法,然而这种方法不具有普遍性。因此,超参数调优方法应该被开发应用于更广泛的问题,目前,这仍然是一个值得研究的开放领域。
(3)结合改进的图像到图像的迁移方法
结合改进的图像到图像的迁移方法也被应用在域适应中。例如,由于区域差异较大,Bousmalis等[122]的PixelDA 方法难以直接应用。因此,类似于XGAN[123](图像到图像的转换,可以支持差异较大的域转换)方法被开发出来。此类方法允许域之间存在更实质性的差异,并且可以直接扩展到域适应问题中。同样,类似StarGAN[185]的图像到图像的转换方法也已经被扩展应用到多域适应问题中。
(4)数据集的局限性
在不同情况和特定任务下,可以获得不同的源域和目标域数据,然而,域适应中数据集相比于深度学习中通用数据集较小。Sankaranarayanan 等[186]注意到基于GAN 网络模型的域适应方法需要大量的训练数据,如果源域或目标域数据集太小,实验结果会变差。而且,目前大部分领域适应数据集为计算机视觉方向。Nidadavolu 等[187]认为,当前研究需要针对这种低资源情况进行调整。为了促进其他应用领域的研究,应该多创建其他领域相关数据集。
(5)异构数据挖掘
虽然深度域适应技术已被成功应用于许多实际应用中,如图像分类、风格转换、目标检测、人脸识别、语义分割和行人重识别等。但现有的算法大多集中于同构深度数据挖掘,即源域和目标域之间的特征空间是相同的。而这一假设在许多应用中并不成立,如图像域到文本域的迁移。我们希望在没有这种苛刻假设的情况下传递领域知识,更好地解决目标域任务。虽然目前已有异构域适应的相关研究被提出,但其实际效果并不佳,目前尚未有有效算法突破这一瓶颈。因此,异构深度数据挖掘在未来值得被进一步关注和研究。
(6)探索域边界
现有的深度域适应研究方法通常会明确给定分布已知的源域和目标域。但在实际情景中,如何准确定义分布未知的域边界对域适应建模至关重要。例如,在自动驾驶场景中,当前驾驶状态受多个因素影响,如天气、光照、路面状况和车速等,而驾驶状态会随着客观因素的影响连续发生变化。此时面临的首要问题是对域边界进行检测,以判断何种驾驶状态下需要对模型进行迁移。遗憾的是,目前域边界探索研究还相对薄弱,将来有待更深入的研究。
(7)最优纳什平衡点
基于对抗的域适应模型通过博弈的训练策略实现训练,领域生成器与域判别器之间需要达到最优纳什平衡点,以确保模型能够筛选和生成高质量样本[188]。但在实际场景中,生成对抗网络通常存在不同的平衡态,若模型训练未收敛到最优平衡点,则会导致模型学习不充分,即纳什平衡任务存在多个平衡点且多个平衡点之间关联性弱的问题。因此,如何寻找全部平衡点仍是目前学术界的公认难点之一,受该限制的影响,生成对抗机制在理论层面存在非最优平衡状态等诸多不利因素。遗憾的是,现有方法无法从理论证明角度出发推导模型的全局最优纳什平衡点,从而导致模型陷入局部平衡,限制模型实际表现。因此,这一方向仍然是未来面临的重要挑战。
7 结束语
针对基于深度学习的域适应问题,本文首先回顾了深度域适应近年来的研究现状,并依据是否涉及对抗训练机制,对现有相关工作进行了分析并将其分为非对抗域适应和对抗域适应两类。其次,当前现有的域适应方法在实际应用中仍然面临较大瓶颈,本文重点对深度域适应方法所面临的问题进行了总结,并指出未来可研究的方向。而部分域适应、开集域适应和通用域适应等相关方法,同样值得被深入探讨和研究。最后,希望本文工作能帮助读者了解该领域的研究现状,为读者相关研究提供借鉴。
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19
计算机技术与发展(2020年11期)2020-12-04
领导决策信息(2018年16期)2018-09-27
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
数学学习与研究(2017年3期)2017-03-09
青年文学家(2015年29期)2016-05-09
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
西南学林(2011年0期)2011-11-12
