
基于对抗深度学习的物联网安全检测方法
2022-06-15 09:06胡声秋李友国高渊吴玲丽
电子设计工程 2022年11期
胡声秋,李友国,高渊,吴玲丽
(中国移动通信集团重庆有限公司,重庆 401121)
近年来,深度学习技术在网络安全领域得到了快速应用[1-3],例如入侵检测[4]、恶意软件分析[5]、垃圾邮件过滤[6]和网络钓鱼检测[7]等。基于深度学习的网络入侵检测技术得到了快速演进,使得一些传统入侵检测系统无法实现的应用也能在深度学习领域成功进行验证[8-9]。然而,深度学习的高度非线性特性限制了开发人员对其进行解释,存在潜在的网络安全隐患。许多工作也验证了深度学习在处理对抗操作方面的脆弱性[10-12]。例如,对抗样本可以通过稍微改变网络输入数据来混淆深度学习模型[13-16]。为了确保基于深度学习的安全系统的防御能力,该研究针对物联网环境设计的基于深度学习的网络入侵检测系统Kitsune 的安全性问题,从两个角度来进行评估:1)物联网视角:抵御恶意网络攻击的能力。2)对抗机器学习视角:处理对抗样本的鲁棒性,在执行对抗样本攻击时将KitNet 与Kitsune 解耦开来,从归一化的特征空间来评估KitNet 的安全性。同时,将传统的手工固定阈值进行回归模型学习,通过后处理变换转变为自适应阈值。最终,利用弹性网络进行对抗样本生成和网络入侵检测优化,在尽可能小的输入扰动下,实现混淆入侵检测系统的分类。
1 网络评估
1.1 Kitsune概述
如图1 所示,Kitsune 是由数据包捕获器、数据包解析器、特征提取器、特征映射器和异常检测器组成。数据包捕获器和数据包解析器是网络入侵检测系统的标准组件,它们转发解析后的数据包和元信息(例如传输信道、网络抖动、捕获时间等)。然后,特征提取器生成一个包含100 多个统计信息的特征向量,这些统计信息定义了数据包和活动通道的当前状态。特征映射器将这些特征聚类成子集,然后输入到异常检测器中,异常检测器包含深度学习模型KitNet。

图1 Kitsune的框架流程图
Kitsune 是专门针对物联网环境部署在网络交换机上的轻型入侵检测系统。它通过使用无监督的在线学习方法来实现,该方法允许动态更新,以响应目标网络节点的流量。该方法在训练阶段假设所有的实时传输都是合理的,从而学习正常的数据分布。在测试阶段,它解析传入的数据,通过判断是否遵循所学到的正常分布来进行异常检测。
1.2 KitNet
KitNet 由集成层和输出层组成。集成层包含多个自动编码器,每个自动编码器处理一组由特征映射器提供的输入。然后,这些自动编码器的输出分数经过归一化后送入到输出层中的一个聚合自动编码器,其输出分数用于评估网络流量数据的安全性。
自动编码器是KitNet 的基本组成部件,它将输入编码成隐层表示,然后从该表示解码恢复到相同的输入维度。KitNet 中的自动编码器经过训练后,能够正确编码正常网络流量的相关属性。KitNet使用均方根误差(Root Mean Square Error,RMSE)函数作为每个自动编码器的性能标准。每个自动编码器模块产生的分数由下式给出:
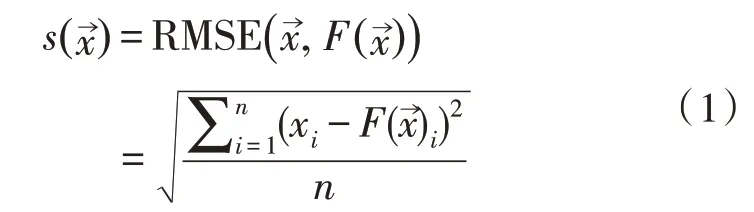
其中,n是输入数量,是自动编码器,为输出的分数。
正则化器是Kitsune 的另一个组件,它在聚合自动编码器之前运行,用以实现分数的归一化操作,使得最小最大值范围线性缩放到0 和1 之间:
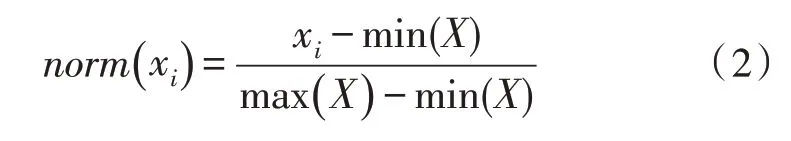
X为训练过程中所有样本的第i个元素组成的集合。
1.3 异常检测
KitNet 的主要输出是由聚合自动编码器产生的RMSE 分数,而不是像常规深度学习分类器那样的概率规律。Kitsune 只有当S≥φβ时才会触发警报(认定为异常发生),其中φ是训练期间记录的分数最高值,β是一个常数,且β≥1,以确保所有的训练数据都服从正态分布。
2 实 验
2.1 实现对抗性机器学习
为了实现对抗性机器学习,将Kitsune的原始C++版本在TensorFlow 框架中进行实现。测试和评估流程与C++实现保持一致。然后,利用Cleverhans[17](一个对抗性机器学习库),来生成不同的对抗性样本。使用了与文献[18]中相同的Mirai 数据集进行对比实验。
2.2 改进归一化的特征空间
通过在KitNet 的输出端添加一个额外的变换层,将分类机制引入到模型中,如式(3)所示:

这使得深度学习模型基于阈值T产生分类结果。当T=φβ时,即与原始KitNet 等价,将模型从回归器转换为分类器。
针对深度学习模型的对抗样本,在执行攻击时将KitNet 与Kitsune 解耦开来。在对Kitsune 的现实攻击中,攻击者必须绕过特征提取器,以便在KitNet的输入上引起扰动。然而,通过对特征提取器原理的理解,攻击者可以通过构造的数据包来生成所需的特征。因此,在进行对抗性评估时,着重从归一化的特征空间来评估KitNet 的安全性。
3 物联网视角的安全性评估
为了客观衡量基于深度学习的网络安全检测系统的防御能力,应该从传统网络安全和对抗机器学习两个方面分别进行评估。在网络入侵检测领域,区分恶意网络流量和正常流量的能力是主要的性能指标。
Kitsune 的开发人员针对各种网络中的一系列攻击对检测系统进行了评估,发现Kitsune 的准确性高度依赖于阈值T的选取。该值定义了决策边界,是模型部署时的重要超参之一。为了观察阈值T如何影响对抗性机器学习中的扰动,进而评估其性能,考虑了以下两个指标:
1)假阳性率(False Positive,FP):被错误分类为恶意攻击的百分比。
2)假阴性率(False Negative,FN):被错误分类为正常的恶意输入百分比。
一方面,误报率反映了网络的可靠性。另一方面,漏报率则反映了入侵检测系统的有效性。因此,在理想情况下,两种指标都应尽可能最小化。在Kitsune 的设置中,阈值T对假阳性率和假阴性率进行了权衡。
在该分析中,对阈值T的可能取值范围(0~20)进行了研究。当T=20 时,漏报率为100%。图2(a)绘制了阈值T对误报率和漏报率以及入侵检测系统成功率的影响性分析。图2(b)则为检测系统的精度-召回曲线(ROC 曲线)。
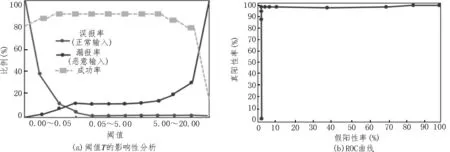
图2 阈值T的影响性分析及ROC曲线
从图中可以观察到,假阳性率和假阴性率在阈值中间范围内几乎保持不变。在阈值范围的两端,两个指标呈现出此消彼长的趋势。最后,当T<7 时,成功率也基本上没有变化,这是因为异常检测数据集通常是长尾分布的,且大多属于正常类别。综上,发现0.05~1 之间的取值范围是比较合适的。图2(b)中的ROC 曲线则证明了Kitsune 在Mirai 数据集上的有效性。
4 对抗视角的安全性评估
4.1 对抗样本生成方法
智能和自适应的攻击者通常会利用机器学习模型的弱点,通过使用对抗样本生成等技术来攻击基于深度学习的网络入侵检测系统。对抗机器学习主要有两个攻击目标,即完整性攻击和可用性攻击。完整性攻击是通过生成逃避检测的恶意流量从而产生假阴性样本,而可用性攻击则是通过伪装正常流量(看起来像恶意流量),产生假阳性样本。然而,无论是哪种对抗样本,都要求在尽可能小的输入扰动下实现混淆入侵检测系统的分类。
执行这些攻击的另一个问题是网络数据不同于图像,图像通常用于传统的对抗性机器学习。图像域中的对抗样本是指那些被人类看起来相同但被模型感知为不同的图像。Lp范数可以用来量化两幅图像之间的距离,因此可以直接用作度量指标。然而,在网络安全中,攻击的定义通常是抽象的。
一种可能的方式是在模型抽取的特征层面进行差异性度量。具体来说,使用原始输入和产生的扰动输入在特征空间上进行Lp范数的距离计算。此时,L0范数表示对提取特征的少量扰动。
正如许多不同领域的生成对抗样本方法一样,该研究着重针对网络安全领域对具有不同范数距离度量指标的对抗样本效果进行了实验对比,来评估KitNet 与如下几种方法的鲁棒性。
1)快速梯度符号法。该方法在L∞范数上进行优化,即减少任何输入特征上的最大扰动,在与梯度相反的方向上对x→的每个元素进行单步处理[15]。
2)雅可比显著图方法。这种攻击通过迭代的方式计算显著图,然后对特征进行最大程度的扰动,并最小 化L0范数[16]。
3)Carlini 和Wagner(C&W)。基于C&W 的对抗框架,可以最小化L0、L2或L∞距离度量[14]。文中利用L2范数,通过迭代的方式来减少向量之间的欧氏距离。
4)弹性网络方法。弹性网络攻击限制了整个输入空间的绝对扰动,即L1范数。弹性网络方法通过使用带有L1正则化器的迭代L2攻击,来生成对抗样本[17]。
4.2 实验结果
完整性攻击是在阈值为1.0 的正常输入上执行的。实验结果如表1 所示。为了比较不同算法,测量了所有的Lp范数指标。每次攻击都是在数据集中随机选取的1 000 个正常样本上进行的。

表1 作用在KitNet上的完整性攻击
可用性攻击也使用相同的阈值。随机选择1 000个输出分数最接近阈值的输入向量,结果如表2 所示。需要注意的是,由于正则化器只在正常输入上进行训练,许多恶意攻击将在0~1 范围之外进行规范化。

表2 作用在KitNet上的可用性攻击
4.3 实验结果分析
通过比较表1 和表2 可以看出,KitNet 在处理不同算法产生的完整性攻击的性能表现一般要比可用性攻击好。例如,对抗样本很少在快速梯度符号法和雅可比显著图的可用性攻击中生成。此外,可用性攻击产生的干扰都比完整性攻击大。造成这种问题的一个潜在原因是正常和恶意输入数据之间的不相交性,这种不相交性源于规范化输入的裁剪操作以及更接近正常输入数据的边界判定(即阈值T)。
在这4 种方法中,KitNet 在快速梯度符号法和雅可比显著图的表现比C&W 和弹性网络方法的攻击还要差。特别是在可用性攻击中,这些方法所产生攻击的成功率非常低。这是因为更先进的迭代C&W 和弹性网络方法能够搜索比快速梯度符号法和雅可比显著图更大的对抗空间。
弹性网络方法基于L1范数进行优化的,但是它所生成的对抗样本的其他范数也很小,产生的L0扰动甚至比雅可比显著图方法(基于L0优化)产生的更好。如上所述,L0范数是网络安全设置中这4 个Lp范数中最合适的,因为它意味着最小程度地改变从网络流量中所提取的特征。因此,弹性网络方法只需要非常小的扰动,就可以针对Kitsune 产生混淆检测系统的对抗样本。
上述攻击是通过对每种方法的参数进行自适应步长随机搜索而产生的。实际上,攻击者可能会使用这种方法来确定攻击算法的效果。然后,利用更鲁棒的优化算法(如贝叶斯或梯度下降优化)与攻击算法来产生更好的结果。
4.4 弹性网络优化
由于弹性网络方法生成的对抗样本在上述实验中被证实是最有效的,故接着在Kitsune 设置中优化弹性网络攻击方法。具体来说,使用的是一种简单的梯度下降优化器来最小化目标函数,如式(4):

弹性网络算法还有其他几个超参数,包括学习速率、最大梯度下降步长数和目标置信度。这些参数分别设置为0.05、1 000 和0。弹性网络算法中包含的优化方案通过改变参数c来产生最优的结果。
参数c是以减少两个Lp正则化项为代价,从而确定对抗性错误分类目标的贡献。因此,理论上c的最佳值是达到所需成功率的同时保持尽可能小的值。评估了当β=1 时,c值变化对成功率和L1范数的影响,并绘制了曲线,如图3 所示。从图中发现c=450 时是最佳值,它以相对较小的扰动达到100%的成功率。

图3 参数c对成功率和L1 范数的影响
另一方面,β的选择也会显著影响Lp范数。现在通过改变c=450 时的参数β来分别优化弹性网络方法产生的扰动。实验结果如表3 所示。可以发现,当β逐渐增大到一定程度后,成功率将随着β的增加而下降。

表3 不同β值下所产生的扰动
综上可以发现,对抗式机器学习无疑是基于深度学习的网络入侵检测系统的潜在威胁。因此,当入侵检测向深度学习领域发展时,同时在传统网络安全指标和对抗机器学习领域评估其安全性是至关重要的。
5 结束语
该文验证了基于深度学习的网络安全检测系统在处理来自对抗机器学习领域的恶意攻击时的脆弱性。因为该漏洞普遍存在于现有的基于深度学习的检测系统中,即使该模型在对正常和恶意网络流量进行分类时达到了很高的成功率,研究人员也必须采取措施来提升深度学习模型在对抗攻击中的安全性,以确保网络入侵检测系统的鲁棒性。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
波谱学杂志(2022年1期)2022-03-15
北京航空航天大学学报(2021年7期)2021-08-13
科学技术创新(2021年5期)2021-03-17
安阳工学院学报(2020年4期)2020-09-11
——编码器
演艺科技(2020年7期)2020-08-13
空间科学学报(2020年6期)2020-07-21
中国惯性技术学报(2019年3期)2019-10-15
中国惯性技术学报(2019年6期)2019-03-04
中国校外教育(下旬)(2017年8期)2017-10-30
