
基于粒子群优化-BP神经网络-马尔科夫链的地面能见度观测资料质量控制
2022-06-14 08:22殷利平刘宵瑜盛绍学温华洋邱康俊
科学技术与工程 2022年13期
殷利平, 刘宵瑜, 盛绍学, 温华洋, 邱康俊
(1.南京信息工程大学自动化学院, 南京 210044; 2. 南京信息工程大学江苏省大气环境与装备技术协同创新中心, 南京 210044; 3. 安徽省气象信息中心, 合肥 230031)
目前自动气象站对大气能见度要素的观测多采用散射式能见度仪采样,但是在日常工作中能见度仪采样的数据出错率比较高,故障一般由如下几种情况造成:能见度仪的镜头前或两个镜头之间有异物堵塞,如蜘蛛结网、小鸟做窝;在一些施工区、省道县道等公路,由车辆扬起的灰沙、粉尘可能导致能见度采样区内颗粒物变化不定;恶劣天气下,由于局部地区的风速、风向变化比较大且快,导致树叶、杂物被吹起恰好位于能见度仪的采样区内;雨雪天气、积雪和天气寒冷凝结的冰霜也可能使能见度仪镜头表面受污染严重,导致能见度数据不准确。高质量的实时能见度气象数据是短时气象预报、实时路况分析和大气环境质量评估的重要依据,所以对能见度气象观测数据进行质量控制具有重要意义[1-4]。
目前大多数地区对地面单站观测数据的质量控制使用的仍是传统质量控制方法,即为将格式检查、范围检查、极值检查以及内部一致性检查相结合的综合检查法[5-9],针对传统质控算法的不足,闽锦钟等[10]结合江苏、安徽多区域站资料提出二次迭代的时间、空间一致性检查的综合判别质量控制法,提高对可疑观测资料的判别精度;叶小岭等[11]在气温与相对湿度之间的耦合关系上,用基因表达式编程(gene expression programming,GEP)算法对逐时的地面气温资料进行单站的质量控制,该方法能够在时间维度对气象资料进行有效的质量控制,上述两种算法本质还是传统质控算法的延续,对数据的处理不够快。为了有效提高数据处理能力,况华等[12]提出一种基于双向长短期记忆神经网络的异常数据检测方法,建立时序预测模型,通过对比预测值和实际值的误差检测异常值,该方法检测过程相对简单,所以处理数据速度较快,但是该方法应用范围有限;国外学者也提出了一系列关于气象数据质量控制的方法,其中最具代表性的是Hubbard教授团队[13]提出的空间回归检验法(spatial regression test, SRT),该方法利用邻近站观测值计算目标站的空间回归预测值,通过目标值是否在预测置信区间之内来判定数据是否可疑,该方法应用广泛,但是对地形复杂度高的地区,性能不够理想。
为了进一步提高对气象数据的处理能力,获得高质量的地面能见度观测资料,现基于基准数据训练反向传播(back propagation, BP)神经网络,运用粒子群优化(particle swarm optimization, PSO)算法来优化BP神经网络中的权值阈值,结合马尔科夫链(Markov chain, MC)理论对神经网络的估计值进行修正,从而提出一种适合单站单要素的质量控制方法,即PSO-BP-MC质量控制方法,并将其应用到地面能见度观测资料中,以期对能见度观测资料中的存疑数据识别精度高,且具有地区和气候适应性强的特点。
1 实验数据预处理
气象数据全部来自安徽气象局历年来汇总的气象站观测资料。如图1所示,安徽地形复杂多样,不同地形气候不一,因此所得到的观测数据差值较大。考虑到地形因素对模型质量控制效果的影响,以高山、山谷、平原、水源地地形作为特征,分别选取黄山站(高山地形)、山南溪谷站(山谷地形)、灵璧站(平原地形)和白泽湖站(水源地地形)的历史数据进行试验,这些监测站区域分布如图2所示。
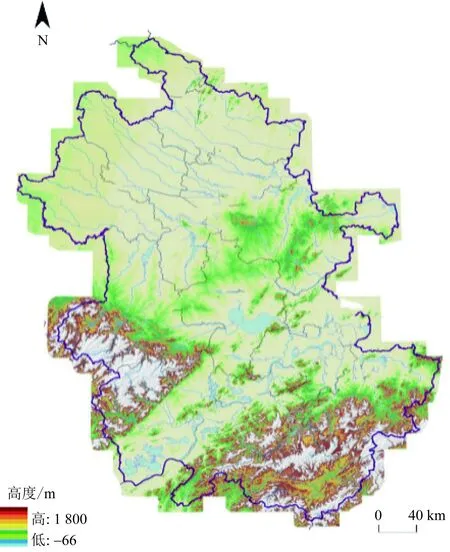
图1 安徽省地形图Fig.1 Topographic map of Anhui Province

图2 安徽省各区域小型气象站分布Fig.2 Distribution map of meteorological stations in Anhui Province
为了保证数据的时效性,对于每种地形观测站点,从2017—2019年安徽气象局记录的数据当中选取较为完整的能见度小时时序数据,并将其作为基准资料,这些基准数据均经过了一般的质量控制流程,已经剔除了明显的粗大误差,能正确地反映当时观测的能见度数值。为了测试质量控制方法的有效性,一般需人为地向被检站的基准资料中添加人工误差,以真实反映实际情况下观测数据的出错率。可将被检站的基准资料中的部分数据置换为随机误差数据,置换率一般不超过5%。将基准资料添加人工误差后得到的数据称为实验数据,该实验数据A可通过公式给出,即
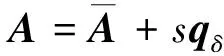
(1)
2 PSO-BP-MC能见度数据预估模型
2.1 神经网络建模
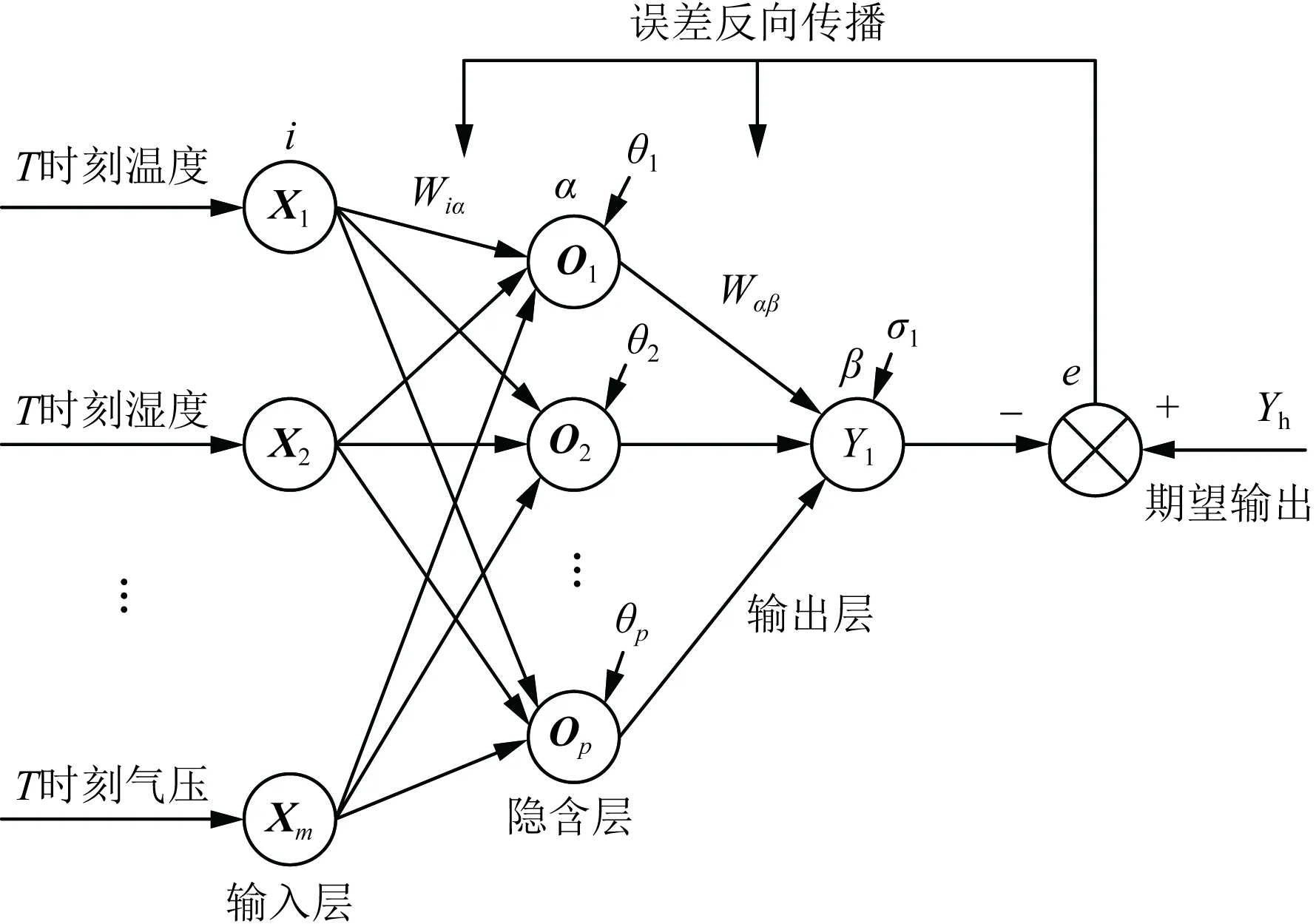
Wiα(i=1,2,…,m; α=1,2,…,p)为输入层到隐含层的权值;Wαβ(α=1,2,…,p; β=1)为隐含层到输出层的权值;Op为隐含层输出;θα(α=1,2,…,p)为隐含层的阈值;σ1为输出层阈值;Yh为期望输出;e为神经网络期望输出与实际输出的误差图3 BP神经网络能见度预估的结构图Fig.3 Structure diagram of BP neural network for visibility prediction
BP算法在优化时采用阶梯搜索法,易陷入局部最小点。考虑PSO算法具有较强的全局收敛能力,并能以较大概率求得全局最优解[14],在2.2节将粒子群算法的全局搜索和BP神经网络的局部搜索相结合,以此优化BP神经网络的权阈值,进而提高网络的训练收敛速度。
2.2 BP神经网络的权阈值优化
采用粒子群算法优化BP神经网络,通过跟踪个体粒子极值和全体粒子极值来获得BP神经网络最佳的初始权值和阈值,加快BP神经网络收敛速度,进而提高BP神经网络预估性能。对于粒子群优化算法,每个粒子的向量维度需包含BP网络全部的权阈值总个数,因此,每个粒子的维度D为
D=DinDh+DhDout+Dh+Dout
(2)
式(2)中:Din、Dh、Dout分别为输入层、隐含层和输出层的节点个数。对于能见度数据预估模型,输入层有m个节点,隐含层有p个节点,输出层节点数为1,所以维度为D=mp+2p+1。PSO优化算法由J个D维粒子组成群落x=(x1,x2,…,xJ)T,第i个粒子的信息包括粒子位置xi=(xi1,xi2,…,xiD)T和粒子速度vi=(vi1,vi2,…,viD)T,i=1,2,…,J。用gi=(gi1,gi2,…,giD)T表示其个体极值,即第i个粒子在迭代过程中得到其最优适应度时所在的位置,Qg=(Q1,Q2,…,QD)T表示种群全局的极值,即全体粒子在迭代过程中取得最优适应度时所在的位置[15]。在每一次迭代过程中,逐步地向当前所寻到的最优粒子的位置靠近,并更新粒子的速度和位移,其更新模型为

(3)
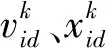

(4)
2.3 MC模型修正
为了进一步提高能见度预测的精度,依据若干历史时刻的残差情况对预测时刻的残差情况进行预测并修正,利用马尔科夫链模型修正能见度预估值,其算法具体步骤如下。

步骤2建立状态转移概率矩阵。由误差状态Ei转为误差状态Ej的马尔科夫转移概率Pij为
Pij=P(ΔEi→ΔEj)=aij/ai
(5)
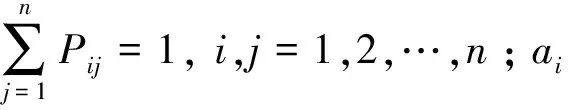

(6)
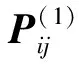
步骤3预测值修正。取预测的误差状态区间中点作为预测值的估计误差,则预测值的修正值为

(7)
式(7)中:Δup、Δdown分别为预测的相对误差所处状态区间的上下区间值;h(x)为2.2节中根据PSO-BP神经网络得到的预测值。
步骤4对后续时序数据残差修正。若前一时刻通过能见度数据质量检测,则将前一时间预测值与实际值的残差加入原序列中重新构置一步状态转移矩阵,重复步骤3、步骤4。
3 能见度数据质量控制法
PSO-BP-MC单站质量控制法的主要思想是:首先通过BP网络将历史观测资料中除能见度以外的其他气象要素数据用于BP网络学习,利用粒子群算法全局性搜索的特点,寻找合适的神经网络阈值和网络初始连接权值;然后进行新一轮BP神经网络训练,提高局部收敛速度和系统预测的准确性;再对学习网络输入下一时刻(或多个时刻)所观测要素的时间序列,基于经过训练的BP神经网络模型输出此时对应的能见度估计值;最后结合MC模型修正PSO-BP神经网络模型估计值。总的来说,PSO-BP-MC能见度质量控制方法的流程图如图4所示。
若被检站该时刻的观测值是由非气象因素造成的,观测值与估计值之间的差值一定会高于平均水平,即可认为该时刻的观测值可疑,需进行可疑性标记[16-17]。基于PSO-BP-MC的能见度数据质量控制方法的具体流程可总结如下。
步骤1首先取待检站的位置信息及被检站被检时刻前20 d长为480 h的历史逐时观测数据,然后进行归一化处理构成BP网络的样本集,其中样本集中前2/3的时序数据作为训练样本集,后1/3的时序数据作为测试样本集。
步骤2根据训练、测试样本集,运用PSO优化的BP模型进行训练学习,结合残差修正模型,得到当前最佳质量控制模型。
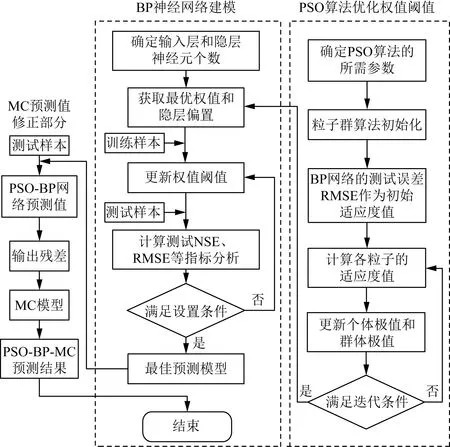
纳什系数(Nash-Sutcliffe efficiency coefficient,NSE);均方根误差(root mean squared error,RMSE)图4 PSO-BP-MC能见度质量控制方法的流程图Fig.4 Flow chart of PSO-BP-MC visibility quality control method
步骤3根据步骤2的最佳质量控制模型计算被检站当前时刻的能见度预测值Vest(t)。
步骤4记f为质量控制参数,其取值需根据不同地区、不同气候等条件而定,将会讨论f对能见度数据检验效果的影响;S为目标站能见度序列Vobs(t)的标准差。将被检站当前能见度的观测值Vobs(t)与预估值Vest(t)进行比较,并判断式(8)是否成立,即
|Vobs(t)-Vest(t)|≤fS
(8)
若式(8)成立,则认为Vobs(t)正确;反之,则认为Vobs(t)可疑,需要对该观测数据进行可疑性标记。
步骤5重复步骤1~步骤4,对被检站下一时刻的能见度观测值进行检验。
4 方法可靠性分析及检验结果评估
为了检验PSO-BP-MC质量控制法的适用性,运用该方法对4个站点2017—2019年地面能见度观测资料进行质量控制,该质量控制分两步进行:①根据被检站的观测资料建立模型,得到被检站对应时刻的能见度预估值;②计算模型对人为误差的检错率,其中检错率定义为实际识别的误差个数占插入误差个数的百分比。
将被检站的观测值与预估值进行比较,若两者差值超过一定标准,即认为数据可疑,其中预估值的精度直接关系到检错率的高低。对比这两个步骤的指标,以此评估PSO-BP-MC质量控制方法。
4.1 模型预估精度评估
模型的预估精度可以用纳什效率系数(NSE, 其量值记为ηNSE)和均方根误差(RMSE,其量值记为ηRMSE)来评估,其中ηNSE的值介于0 ~1,如果数值越接近1,则模型的预估精度越高,ηNSE和ηRMSE计算公式分别为

(9)

(10)


图5 黄山站2017—2019年能见度数值预估指数曲线对比图Fig.5 The visibility numerical prediction index curve of Huangshan station from 2017 to 2019
从图5中可以看出,基于PSO-BP-MC模型的NSE指数大部分在0.9以上,且RMSE指数比较平稳,整体的预估误差值较小,从图5的两种预估指数曲线对比可知,相较于SRT方法,POS-BP-MC方法对黄山站的能见度观测数据的预估精度更高。
4.2 检验结果及分析
基于PSO-BP-MC模型的质量控制错误有如下两类,错误Ⅰ是将原本正确的数据标定为错误;错误Ⅱ是将原本错误的数据标定为正确,其对立的状态就是将错误的数据认定为错误,即在数据的质量控制中能将错误的数据检出。在实际使用质量控制方法时,为得到最佳的质量控制效果,应同时考虑这两类错误,即在保证控制效果的前提下,使两类错误发生率尽量低。选择两类错误值之差最小时的f值作为最佳质量控制参数。
运用PSO-BP-MC方法和SRT方法对不同地形代表站2019年1月施加随机误差后的能见度观测资料进行试验,得到各站点不同质控参数下的两类错误率如图6、图7所示。由图6可以看出,随着质控参数f值的增大,模型认为正确观测值的置信区间也在扩大,则“拒真”错误在降低,但“纳伪”错误在增加,两类错误发生的数值差最小时对应的检错率为最佳质量控制参数下的检错率,也称为最佳检错率。
为了检验PSO-BP-MC质量控制法,运用此方法对施加人为误差的黄山站、山南溪谷站、灵璧站和白泽湖站四站2017—2019年逐时能见度数据进行检查,四站不同年份的年平均检错率结果如表1所示。将PSO-BP-MC质量控制方法的检验结果与SRT方法对比,运用SRT方法对以上数据作检错率分析,结果如表1所示。
从表1中的数据可以看出,运用PSO-BP-MC方法得到的最佳f值为1~2,由该质量控制方法计算出的不同地区下的年平均最佳f值相较于SRT方法更小。在保证检出率大致相同的前提条件下,f值越小代表着预估值与目标值越接近,说明该方法预估拟合的能力比SRT方法更为突出。灵璧站与白泽湖站f值相差不大,说明两地形因素对能见度的影响相似,而黄山站和山南溪谷站的f值相较大,是由于高山和山谷的海拔原因造成的,气温、气压、湿度与海拔关系密切,这些气象因素对能见度的相关性大且复杂,海拔高的地方温度低、湿度大,容易形成团雾,降低能见度,而气温高、湿度小的天气可以大大增加可见度距离。由于地形原因,能见度变化不易准确预测,本文模型对高山预测拟合效果不及平原等地区,所以以较大的f值来降低“拒真”错误。总的来说,运用PSO-BP-MC质量控制法对四站的年平均检错率均在80%以上,与SRT方法相比,本文的质量控制方法对存疑的能见度数值识别率更高,且四组地形代表站的检错率相差不大,说明该方法对不同地区的能见度数值监测稳定性更优。
为了进一步验证PSO-BP-MC质量控制法的可行性,选用安徽省气象中心2020年春季未经过质量控制的初始观测数据进行方法试验,其中不同地形区域的台站,选择不同地形代表站的年平均最佳f值作为质控参数,若实测值在正常值的参考区间之外,则认定该时刻数据为可疑数据,需要进行数据可疑性标记。
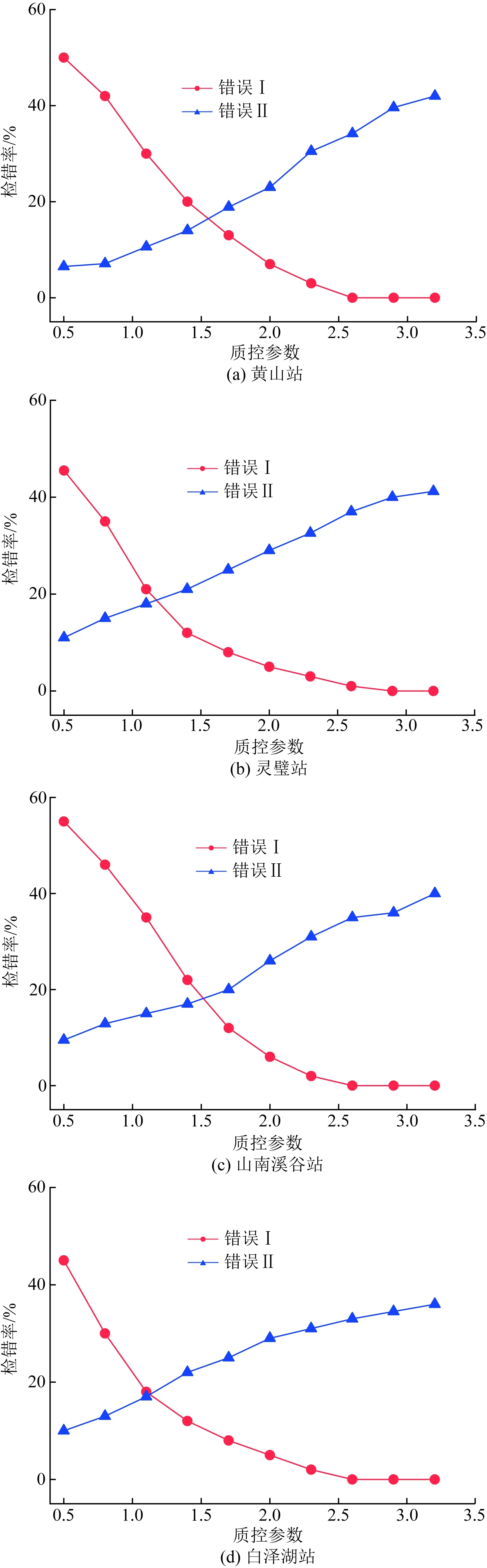
图6 PSO-BP-MC方法在各站不同质控参数下的两类错误率曲线 Fig.6 Two types of error curves of PSO-BP-MC method under different f of each station
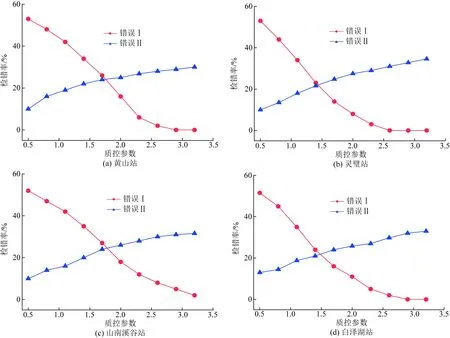
图7 SRT方法在各站不同质控参数下的两类错误率曲线Fig.7 Two types of error curves of SRT method under different f of each station
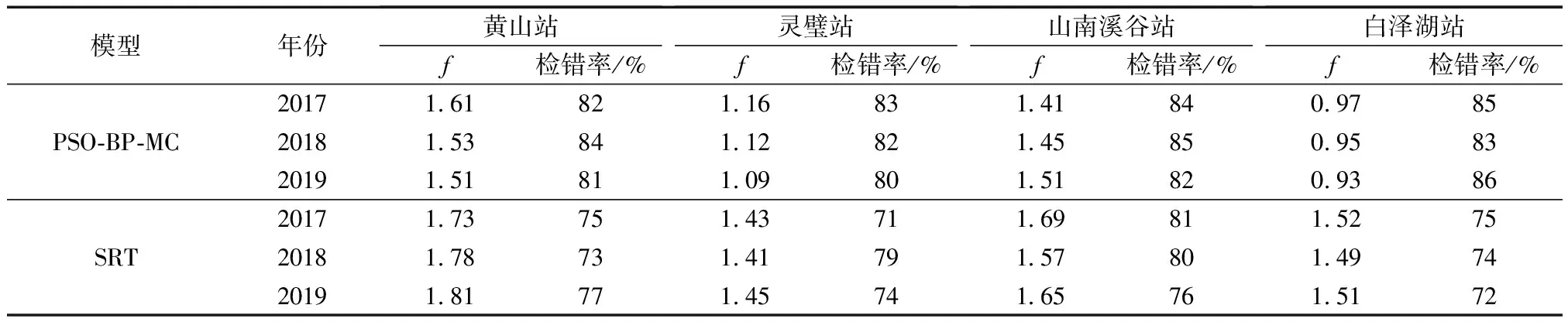
表1 四站不同年份的年平均最佳f值及对应的检错率Table 1 The annual average f number and corresponding error detection rates in different years
对全省各站点2020年春季的能见度观测数据运用PSO-BP-MC方法进行数据质量检测,各站点能见度观测数据中存疑数据的检出率占比如图8所示,可以看出,2020年春季安徽省各站能见度要素的存疑数据均在8%以下,因此大多数站点能见度观测数据的错误率很小,都在可接受范围之内。但也有例外,例如太和县站点连续3个月的能见度可疑数据检出率占比都高于平均值,经后期人工维护得知,春季恶劣天气导致该气象站点部分传感器发生故障,使得该站点上传至信息中心的观测数据异常。利用异常数据得到的能见度拟合值就会与实际无错误的能见度值相差较大,从而在质量控制过程中“拒真”错误增加,导致该站点的能见度可疑数据检出率过高。
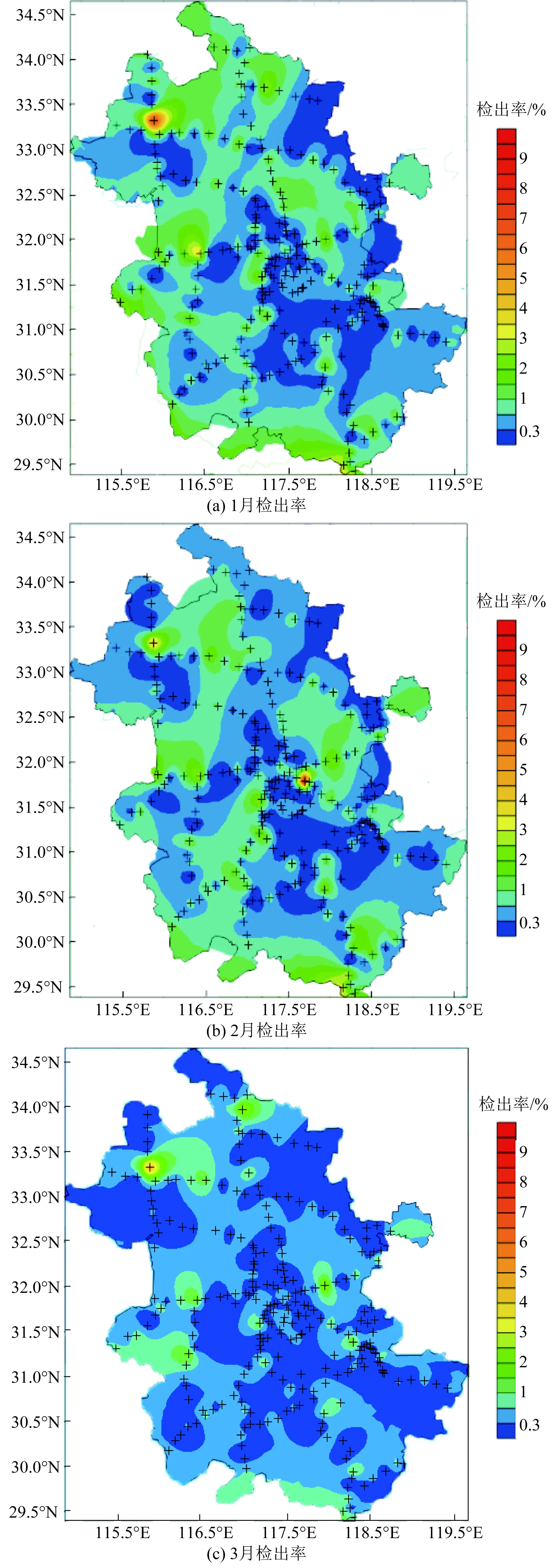
图8 2020年安徽省各站春季能见度可疑数据检出率占比图Fig.8 Percentage of visibility error data in the spring of 2020 in Anhui Province
5 结论
为解决自动气象站能见度要素观测数据错误率高的问题,首先从能见度时间序列的随机特性出发,结合粒子群算法优化、BP神经网络和马尔科夫链,对黄山站多年地面能见度时间序列进行预估,然后对添加人工误差的历史数据进行检错率分析,寻找最佳质量控制参数。实验结果表明,PSO-BP-MC模型具有较好的预估拟合性能,且该方法在不同地区、不同年份下的检错率均较高。在各地形代表站年平均最佳质量控制参数的大致区间已知的情况下,运用该方法对安徽省各台站的初始观测数据进行能见度要素数据的质量控制,可以很准确地获取各站点能见度观测数据错误率信息,实现对能见度观测数据的质量监测。
猜你喜欢
矿山安全信息(2022年22期)2022-11-24
昆明医科大学学报(2022年1期)2022-02-28
气象水文海洋仪器(2021年4期)2021-12-11
天津科技(2021年4期)2021-05-13
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
浙江工业大学学报(2017年5期)2018-01-22
电子制作(2017年24期)2017-02-02
中国交通信息化(2016年6期)2016-06-06
中国交通信息化(2015年4期)2015-06-06
