
多源数据驱动的高速公路服务区运营状态评价
2022-06-14 10:29:54罗二娟刘文辉原国华赵一翰赵建东
科学技术与工程 2022年14期
罗二娟, 刘文辉, 原国华, 赵一翰, 赵建东*
(1.山西省交通新技术发展有限公司, 太原 030012; 2.北京交通大学交通运输学院, 北京 100044)
服务区作为高速公路的窗口,是其不可或缺的重要部分。良好的高速公路服务区服务能力及运营状态不仅可以提高公众出行效率与满意度,还可以传递出当地风土人情文化、拉动当地消费水平。
现有高速公路服务区运营状态研究主要分为信息监测、数据处理以及能力评价三方面。在信息监测方面,张海燕[1]用车位探测器和车位显示灯进行停车位管理,并连接区域引导信息屏和入口信息显示屏显示服务区当前使用信息,使车辆到达服务区前了解停车等信息;黄豪等[2]对服务区气象、人流、车流、路况等信息全面感知,并进行建模和大数据分析。在数据处理方面,邵奇可等[3]运用出入停车场的车辆信息及车位占用情况汇总,通过全球广域网端(world wide web,WEB)和手机软件(application,APP)方式发布,使用户能在互联网设备上获取信息;田佳[4]根据服务区实时车辆驶出与驶入基础数据、服务区高清卡口系统视频识别数据、各项服务设施效率等建立高速公路服务区运行指数模型,其中高清卡口系统能识别车牌号、车型并记录车辆通过时间和车辆信息。卞军[5]在对服务区大数据进行深入整合后,实现了服务区运营管理、资源分配、车流量预测、路况信息匹配、人流预测、市场营销等多方关联应用。在能力评价方面,张海峰等[6]结合天津市高速公路服务区特征,探索研究了区域性高速公路绿色服务区评价指标体系;王殊[7]建立多个服务区横向评价指标体系,通过逼近理想解排序方法模型(technique for order preference by similarity to an ideal solution,TOPSIS)和距离综合评价法,依据指标数值大小对多个服务区服务水平进行高低排序。
综上分析可知,目前中外对于高速公路服务区的服务运营状态并没有一个标准的评价体系[8],大多数只是依靠车流,人流等单一数据判断。因此,本文融合车流、客流、经营数据流等多源数据,制定服务区运营状态指标体系[9],划分服务区营运状态等级,评估预判服务区的运营状态,为服务区智能运营提供信息支撑[10]。
1 数据处理
1.1 原始数据获取
图1所示为山西盂县服务区信息化建设项目,包括卡口、车位管理、收银稽查、安防监控、智慧厕所5个系统,在服务区布设了多种智能摄像设备,采用先进的图像识别算法和技术,实现服务区车辆信息采集、车辆流量监测和统计、客流检测及管理等功能,为服务区的经营管理提供信息服务。

图1 盂县服务区信息化系统拓扑结构图Fig.1 Topology of information system in Yuxian service area
各系统可获取数据有:①卡口系统:服务区出入口抓拍摄像机,能获取车辆车牌、车型、归属地、进出时间,进而计算出车型比例、归属地比例、单车停留时间;②车位管理系统:利用安防监控视频,采用图像识别算法,分区域识别剩余车位数量;③安防监控系统:服务区综合楼各出入口的双目客流摄像机,获取进出各门口的客流数据,可得到时段、天的客流曲线;④收银稽查系统:可获取每个档口的收银数据、每笔订单的交易清单以及交易场景录像数据;⑤厕所数据;布设蹲位检测器、厕位指示灯,在终端实时展示厕位使用情况;通过客流检测单元、环境采集单元,获取厕所人流量、温湿度、臭味浓度数据。
将所采集数据进行分类。如表1所示,包括车流数据、客流数据以及经营现金流3个不同种类数据。所有数据均为每15 min统计一次。
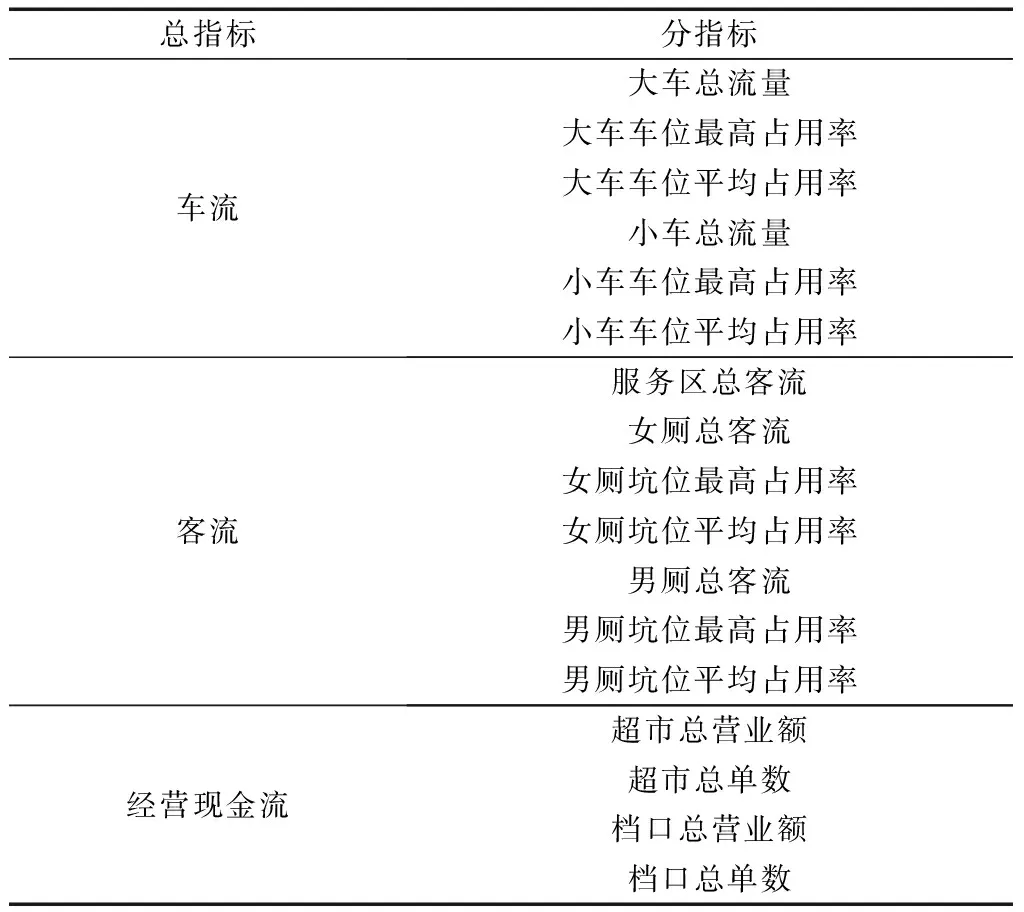
表1 盂县高速公路服务区多源数据Table 1 Multi-source data of Yuxian expressway service area
1.2 异常数据处理
因采集数据为原始数据,存在数据异常现象,故需对数据进行处理及分析。异常数据类型分为缺失数据及噪声数据。
1.2.1 缺失数据处理
数据缺失主要是由于数据传输、采集、存储等过程中人为或系统误差等因素导致,一般如果数据缺失项较多,导致数据完整性下降明显,则应对该数据作删除处理。例如,因服务器关闭而导致数据大量缺失,则将这些数据进行删除处理。此外,如图2中标黄部分所示的个别数据缺失现象,采用历史均值法进行填充,即用前后一周同一天同一时刻的平均值填充。
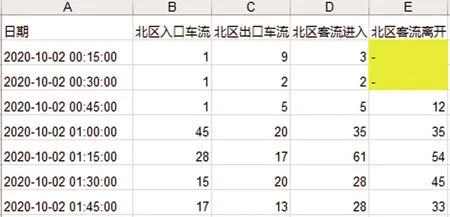
图2 缺失数据Fig.2 Missing data
1.2.2 噪声数据处理
噪声数据定义为数据表内由于一些系统随机偏差或错误产生的和其他数据不一致的部分数据。分析发现有两类数据可能属于噪声数据,一类是在客流高峰时期,突然出现前后15 min内客流变化极大、该时段客流出入为0或者接近于0的数据,取三天南区客流进入数据,如图3(a)所示,高峰时段,前后两段时间客流较大,但中间出现客流量为0现象,取某一周时间数据验证,如图3(b)所示,发现均存在该现象,故判定该数据为噪声数据。
另一类是在客流或车流低峰时期,突然出现前后15 min变化极大,车流或客流量较大的值,通过箱型图观察数据范围,筛选出噪声数据。如图4所示,数据的最小值为0,最大值为311。上下四分位数分别为19和68,将距离上下四分位数1.5倍四分位距的数据,认为是噪声数据,如图5(a)中红色点所示。将异常数据用前一天同一时刻和后一天同一时刻的数据平均值进行填充,结果如图5(b)所示。
采用历史均值法对噪声数据进行数据填充修复。最终数据处理前后对比如图6所示,图6中蓝色的线表示未处理前的数据,橙色的线是第一次处理后的数据,绿色的线是处理完成的数据。可以发现,处理后图线趋势变得更平稳。

图3 客流量统计图Fig.3 Statistical diagram of passenger flow
图4 客流量箱型图Fig.4 Box chart of passenger flow

图5 数据处理前后图Fig.5 Before and after data processing
图6 异常数据处理前后对比Fig.6 Comparison of abnormal data before and after processing
1.3 数据特征分析
(1)车流分析。车流分析过程中,先取某一天车流初步总结规律,再取多天车流,验证规律[11]。发现服务区的南北区入口、出口车流规律大致相同,在中午和下午时间段,车流量较大,且出口车流量峰值总体在对应入口车流量峰值时刻之后,在一周中,休息日和工作日的车流量无明显差别。
车流出现这种规律可能原因是:11:00左右私家车主进入服务区用餐、休息;在下午时段,可能有部分车主长途驾驶后,进入服务区短暂休息。
(2)客流分析。客流分析过程中,先取某一天客流初步总结规律,再取多天客流,验证规律。因南北区客流规律相近,故以北区出入客流为例进行分析,可以发现,随着时间增长,北区客流呈先迅速增长、到达峰值后逐渐下降的趋势;此外,北区进入客流在12:00左右到达高峰值,离开人数在17:00左右到达峰值。
以周的角度进行分析,选取8月19日至9月23日客流数据,发现随着时间推移,从8月19日至9月2日,客流人数逐渐减少,可能原因可能是8月19日前后为大学生新生开学季,但这几周变化不明显;9月2日人数最少;9月2日至9月23日,后面周三比前面周三人数明显增多,估计其原因主要是时间上逐渐接近国庆。
2 基于K-means聚类算法的分级评价
K-means算法[12]在聚类过程中其收敛速度较快。当结果簇是密集的,而簇与簇之间区别明显时, 效果较好,而本文数据正是具有这种特点,较为适合K-means聚类算法,除此之外,该算法的K值可预先设定,可更灵活地设置数据的类别数,从而更好地进行分类。故选择K-means算法对服务区运营状态进行分级评价研究。
2.1 K-means聚类算法
2.1.1 算法理论
K-means聚类算法主要思想是:首先确定K个初始的中心点,即确定数据的分类数,之后将每个数据按照距离分配到离其最近的簇中心点所代表的簇中,直至所有的数据都被分配完毕,再根据一个簇内的所有数据重新计算该类簇的中心点(取平均值),然后再迭代的进行分配点和更新类簇中心点的步骤,直至类簇中心点的变化很小,或者达到指定的迭代次数,其基本原理如下:
对于K-means,首先定义一个数据样本集合Ω,包含了n个对象,其中每个对象都具有d个维度的属性,如式(1)所示。K-means算法的目标是将n个对象依据对象间的相似性聚集到指定的K个类簇中,每个对象属于且仅属于一个其到类簇中心距离最小的类簇中。
Ω={xi|xi=(xi1,xi2,…,xid)},i=1,2,…,n
(1)
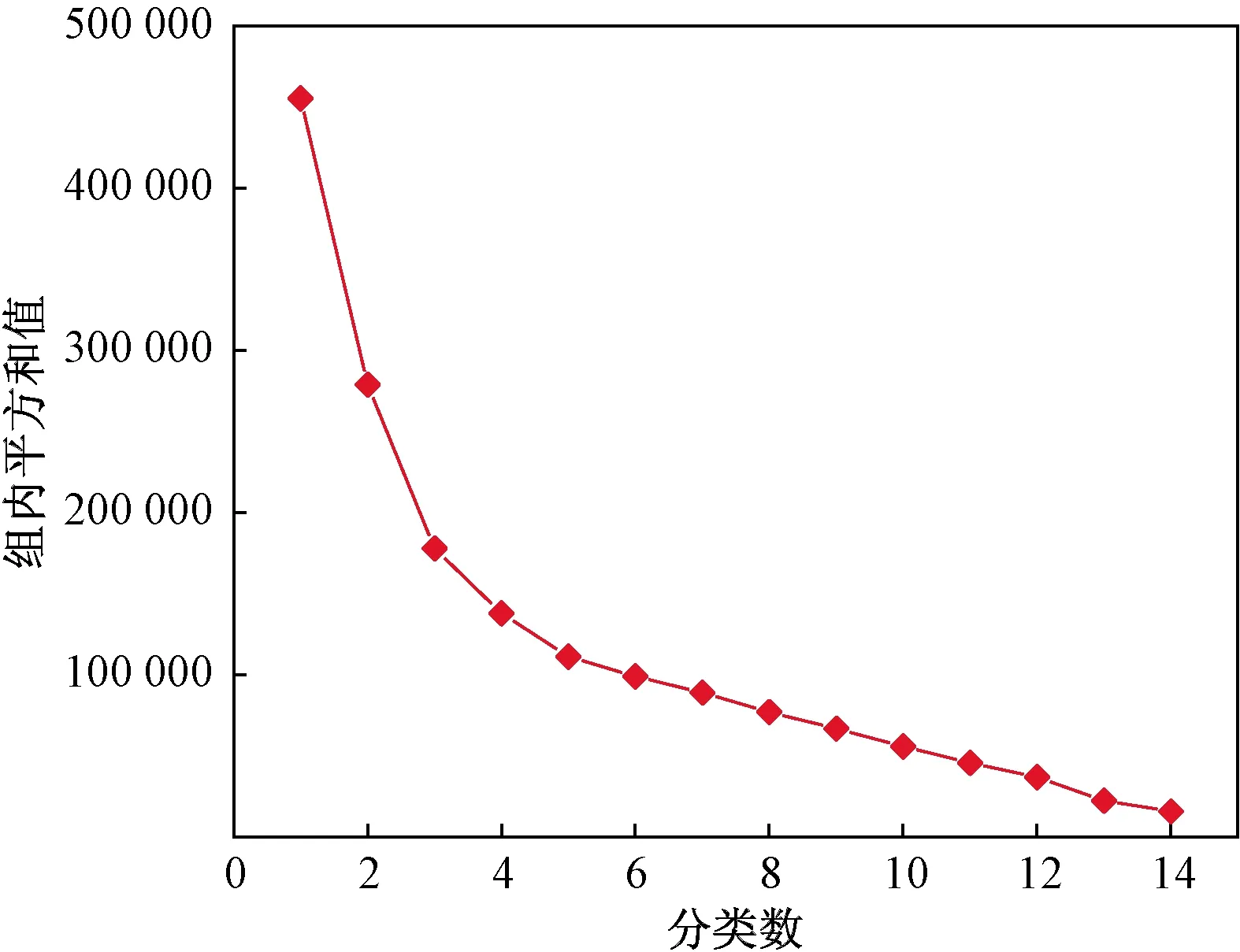
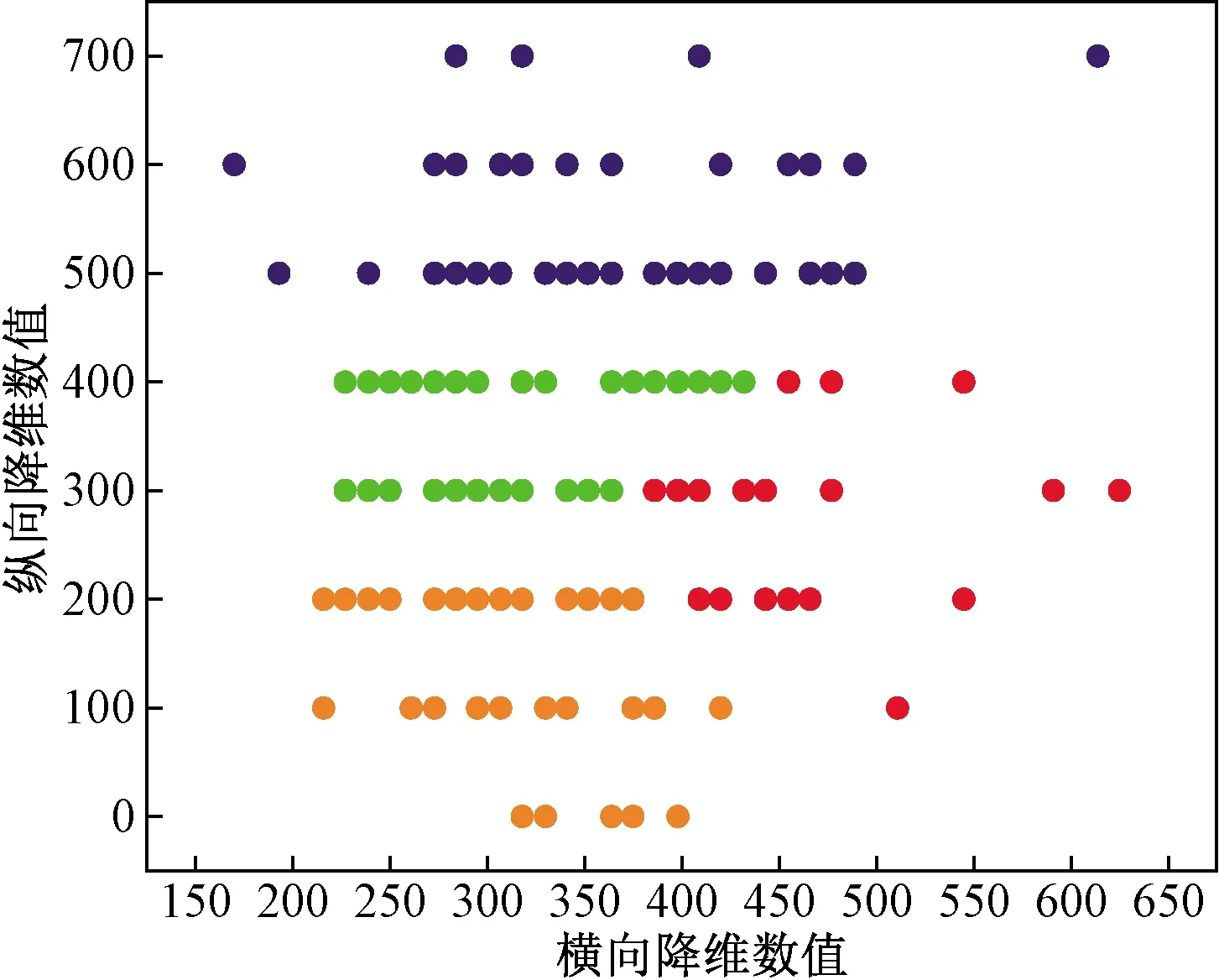
再初始化K(1 C={cj|cj=(cj1,cj2,…,cjd)},j=1,2,…,K (2) 式(2)中:Cj为第j个聚类中心;Cjd为第j个聚类中心的第d个属性。 然后计算每一个对象到每一个聚类中心的欧氏距离,即 (3) 式(3)中:Xi为第i个对象;Xid为第i个对象的第d个属性。 依次比较每一个对象到每一个聚类中心的距离,将对象分配到距离最近的聚类中心的类簇中,得到K个类簇。 2.1.2 算法流程 K-means聚类算法具体流程如图7所示。 图7 K-means聚类算法流程Fig.7 K-means clustering algorithm flow 2.2.1 数据选择 由于K-means算法需要不断迭代来确定数据类别,因此需要大量数据提高其分类准确度。以15 min为周期的数据进行分类研究。 2.2.2K值确定 合理地确定K值和K个初始类簇中心点对于聚类效果的好坏有很大的影响[13]。在统计学中,组内平方和(sum of squares for error,SSE),表示每个水平或组的各样本数据与其组均值的误差平方和,反映每个样本各观测值的离散情况,又称误差平方和或残差平方和。故采用SSE对K值进行选取,计算公式如式(4)所示。当SSE图像出现拐点时,该点对应的K即为最佳。 (4) 式(4)中:Ci为第i个簇;p为Ci的样本点;mi为Ci的质心;SSE为所有样本的聚类误差,代表了聚类效果的好坏。 将数据输入计算得到SSE图像,如图8所示。可以看出,该图像的拐点出现在3~4。因此,理论上可以将服务等级分为3类或4类。 图8 SSE图像Fig.8 SSE image 若是选择将服务等级分为3类,根据后续程序计算输出结果,可以得出其分类效果并不理想。因此最后决定将服务等级分为4类。 2.2.3 降维处理 因原始数据集是高维数据,难以将聚类效果用图表现出来,故需要对其进行降维处理,再可视化。使用T分布式随机相邻嵌入(T-stochastic neighbor embedding,TSNE)算法将原始高维数据进行降维处理。随机近邻嵌入是由SNE (stochastic neighbor embedding,TSNE)衍生出的一种算法,SNE将高维和低维中的样本分布都看作高斯分布,而TSNE将低维中的坐标当作T分布,这样可以让距离大的簇之间的距离拉大,从而解决SNE所产生的拥挤问题。TSNE原理如下。 高维空间中的两数据点的相似性采用联合概率Pij度量: (5) 低维空间中的两个数据点的相似性采用联合概率qij度量: (6) 为使得高维空间点映射到低维空间后,尽可能保持一样分布,采用KL(Kullback-Leibler divergence)距离进行衡量。KL距离损失函数为 (7) 梯度的计算公式为 (8) 以盂县高速公路服务区3月15日—3月21日的一周数据为例。选取盂县高速公路服务区该日期内午高峰时段(11:00—14:00数据)以15 min为跨度的84组数据,每组数据包括车流情况、客流情况、经营现金流情况。 程序聚类结果如图9所示,数据横纵坐标越大,即离原点越远,代表着该数据所表示的服务区越拥挤,运营状态越差;反之数据横纵坐标越小,即离原点越近,代表服务区运营状态越好。 所评价的3月15日—3月21日一周内每日午高峰时段高速公路服务区运营状态类别数统计如图10所示,类别0~3分别代表该时段运营状态为最好、一般、较差以及最差。 从图10中可知,3月20日以及3月21日数据的0、1类别较多,而2、3类别较少,判断这两天午高峰时段服务区运营状态较高;而16日、17日的2、3,数据类别较多,0、1类别较少,判断这两日午高峰时段服务区运营状态较差。 图9 聚类结果Fig.9 Clustering results 图10 分类结果(周)Fig.10 Classification result (one week) 选取3月19日,以15 min为一个周期的96组数据,每组数据包括车流、客流、经营现金流,与2.2节评价过程一致。程序聚类结果如图11所示,同样可以看出聚类效果较好。 从图12可知,3月19日类别为0的数据多集中于凌晨时段及23:00以后,该时段服务区较为空旷,运营状态最好。类别为1的数据多集中于凌晨时段,8:00之前以及夜间晚高峰之后,该时段车流量较少,服务区可提供较好服务能力。类别为2的数据多集中于非高峰时段,该时段服务区服务能力一般。类别为3的数据多数集中于高峰时段,该时段服务区人车拥挤,服务区运营状态较差。 图11 聚类结果Fig.11 Clustering results 图12 分类结果(日)Fig.12 Classification result(one day) 研究发现,K-means聚类算法对服务区运营状态分级评价的判断结果为:在一周中,3月20日运营状态最好,而3月17日运营状态最差。在一天各时段运营状态分级评价的研究过程中K-means聚类算法的判断为:凌晨以及白天较早时间段内服务区的运营状态最好,而在高峰时段以及下午时段服务区较为拥挤,运营状态较差。 相比于算法,K-means聚类具有如下优缺点:计算机迭代速度很快,并且收敛速度快,适合处理大量数据。且可以任意设定K值,使数据被分成指定的K类。但其并不适合处理较少量的数据,如果数据量较少,其分类结果可能每次迭代都不同,并且极易受异常数据的干扰,使其计算结果受到较大影响。除此之外,虽然理论上可任意设定K值,但如果设定不合理,数据聚类效果将不会理想。而本文以15 min为周期,收集车流、客流以及经营现金流等大量数据,数据量达到计算精度要求,且根据SSE来进行K值选取,分析SSE图像拐点,选定K为4,此时评价结果较为理想。 利用山西省盂县服务区监测系统的多源异构数据,从车流情况、客流情况以及服务区经营现金流情况三个角度综合考虑,使用K-means聚类算法对高速公路服务区数据进行分级评价。得出如下结论。 (1)针对本文研究对象山西省盂县高速公路服务区的原始数据建立一套数据清洗规则,有效识别出了缺失数据与噪声数据,并且做了相应的数据删减和增补,并初步识别了车流、客流规律,逻辑正确且符合实际情况。 (2)以15 min时间粒度整理了一天96个原始数据,从一周同一时段及一天各时段两个角度出发,运用K-means聚类算法进行分类,综合分析评判了服务区运营状态实时变化情况。验证了夜间车辆少服务能力强,高峰时段运营状态较差的现象。 (3)综合评判了K-means聚类算法的特点优劣以及适用范围。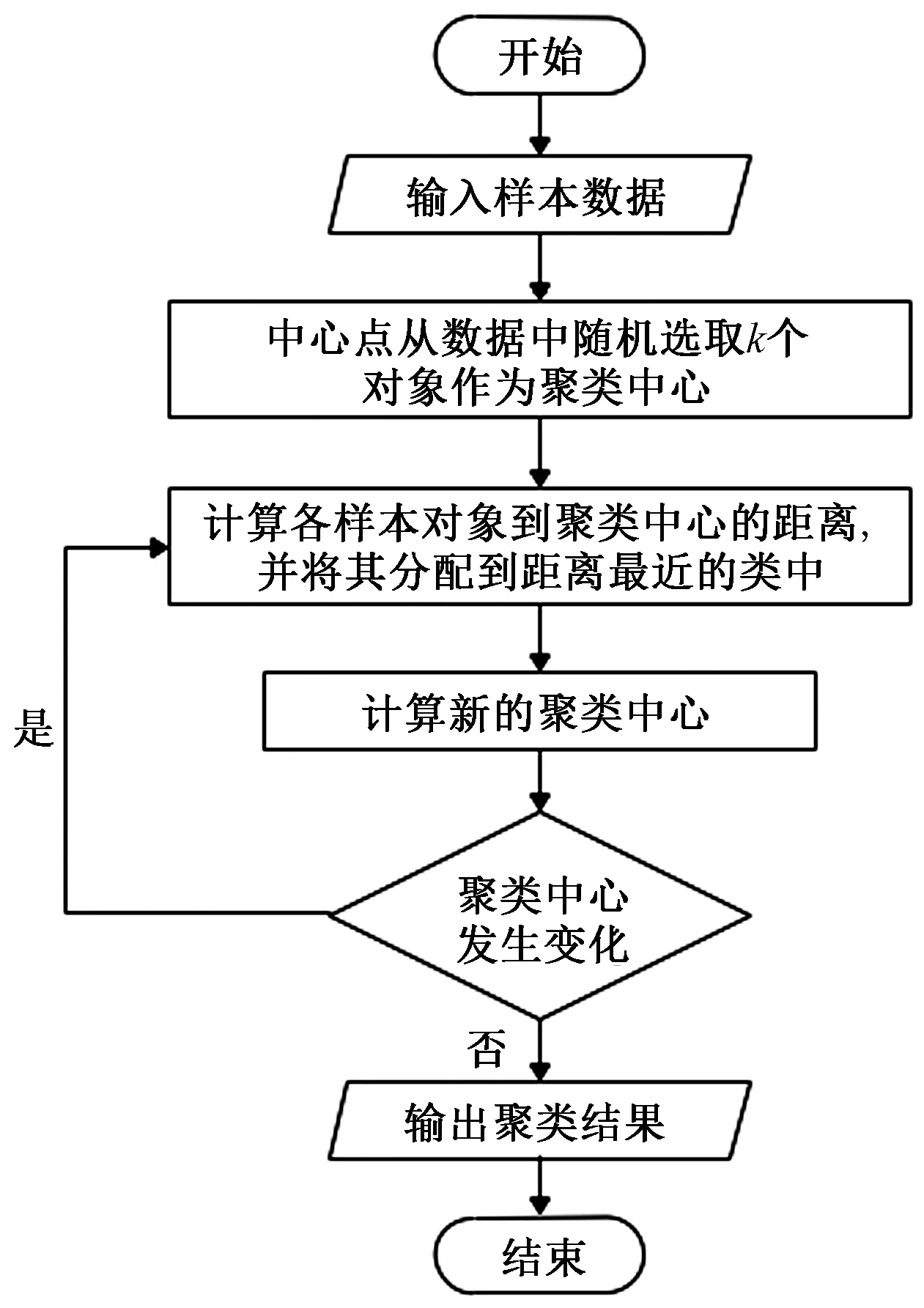
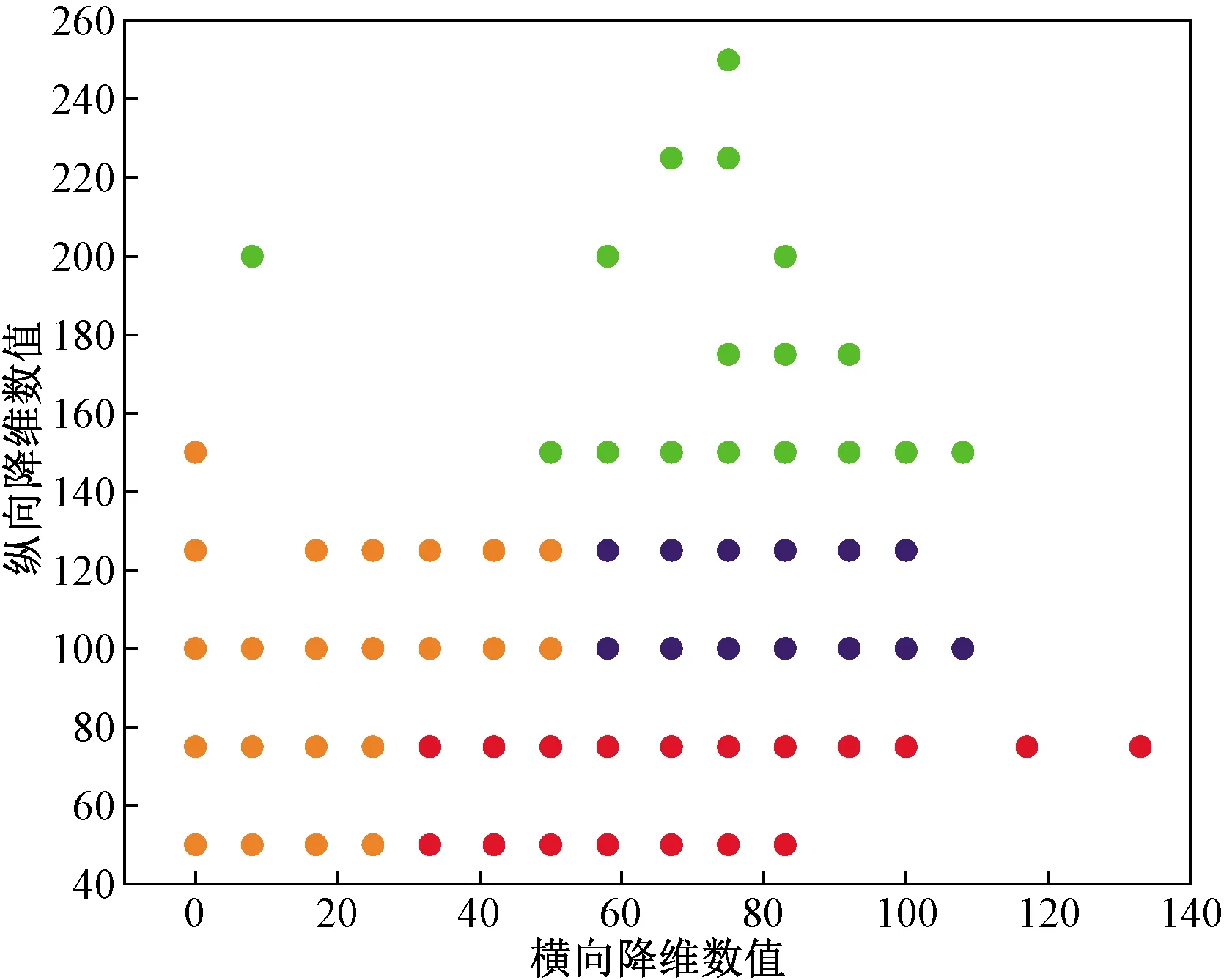
2.2 评价过程
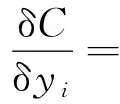
2.3 一周同一时段运营状态分级评价
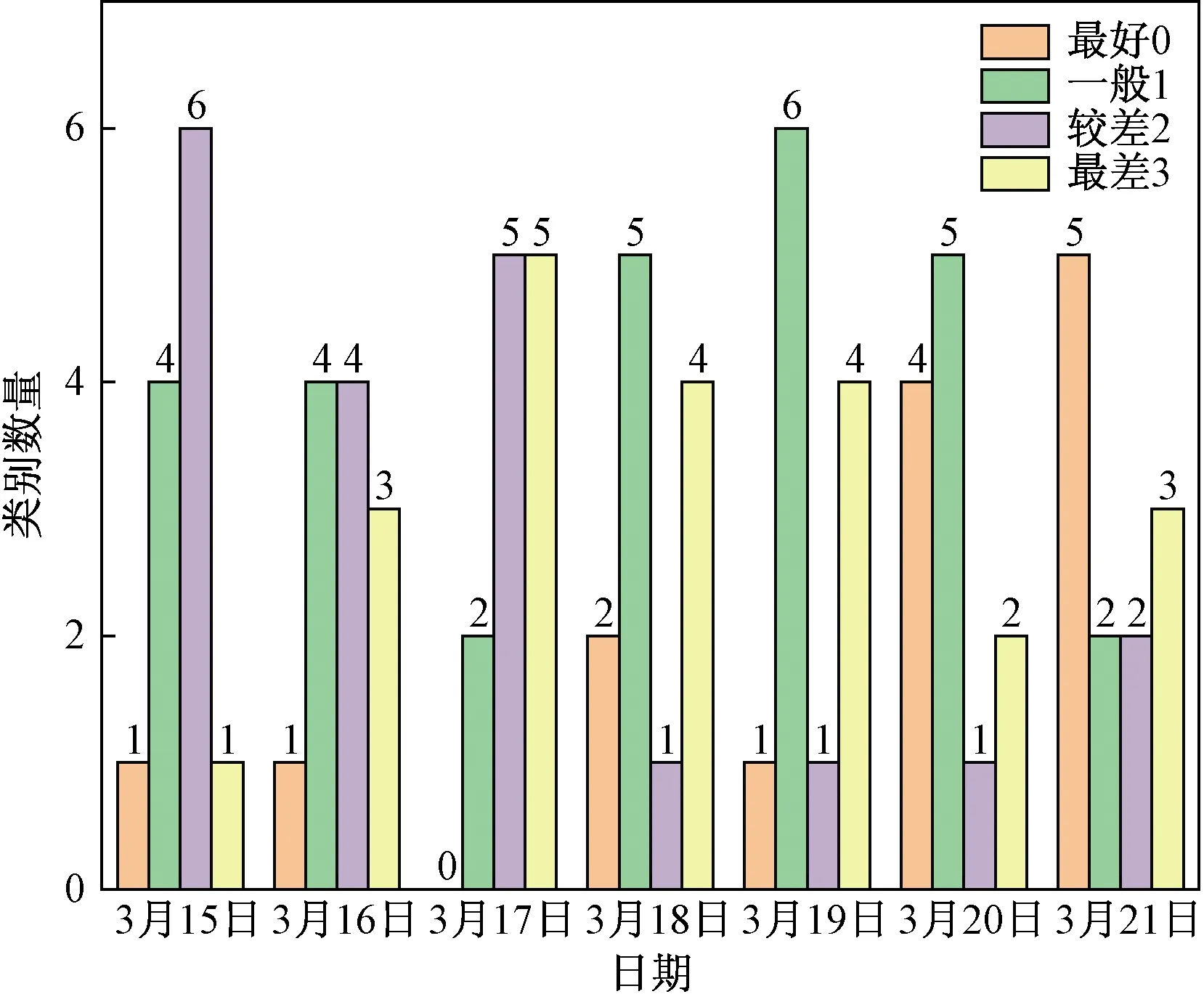
2.4 一天各时段运营状态分级评价
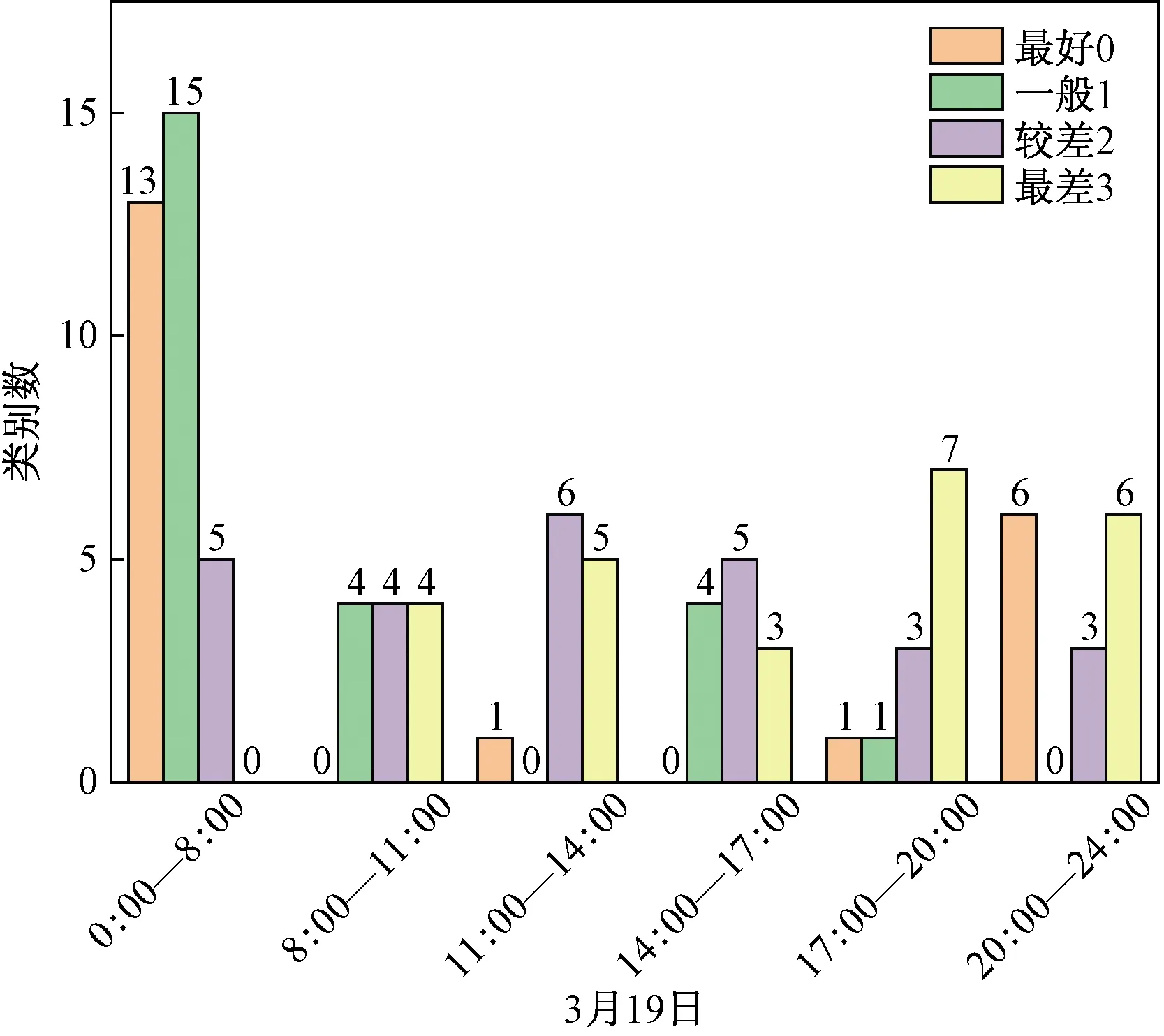
3 评价方法分析
4 结论
猜你喜欢
中国交通信息化(2023年1期)2023-03-18 02:01:40
工会博览(2022年33期)2023-01-12 08:52:32
环球时报(2022-12-12)2022-12-12 17:14:03
中国交通信息化(2020年4期)2021-01-14 01:30:40
扬子江(2019年3期)2019-05-24 14:23:10
中国公路(2017年5期)2017-06-01 12:10:10
浙江大学学报(工学版)(2016年9期)2016-06-05 09:20:55
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27 06:31:37
数学教学通讯·初中版(2015年5期)2015-06-17 15:33:29
中央民族大学学报(自然科学版)(2015年2期)2015-06-09 08:45:20
