
基于信息熵的局部二值模式手指静脉识别
2022-06-14 10:28:28黄艳国杨训根周满国
科学技术与工程 2022年14期
黄艳国, 杨训根, 周满国
(江西理工大学电气工程与自动化学院, 赣州 341000)
基于生物特征的身份识别技术越来越普及,各类产品渐渐融入日常生活。类似指纹[1-2]、人脸[3-5]等识别系统被广泛用于手机的解锁与支付软件当中。而身份识别产品的关键技术是基于人的生物特征,如指纹、人脸、虹膜[6]、掌纹[7]和静脉等。手指静脉作为人的生物特征之一,近年来也有许多的研究方法被提出,并取得了良好的识别效果。相对于一些基于深度学习的卷积神经网络[8]方法,传统特征因其所需数据少、对硬件要求低、能够达到较高识别率等特点,在实际应用上具备一定的优势。
关键点的匹配是手指静脉识别的有效手段,Meng等[9]结合感兴趣区域与细节匹配,提出了基于区域的检测方法,通过计算Hessian矩阵作为细节点特征,对于细节点的匹配采用邻域匹配以减少计算量,取得了较好的识别率,但相应地增加了匹配时间。Jin等[10]提出的基于二值图像的算法,对感兴趣区域提取特征点,利用梯度直方图将特征点矢量化描述,有效缩小了图像视野,为静脉采集装置的小型化提供思路,但算法的识别率仍有较大的提升空间。局部二值模式(local binary patterns, LBP)特征被成功运用于目标检测与跟踪[11]任务中,在手指静脉识别方面也有许多研究。刘超等[12]在LBP算子的基础上,根据图像的分块包含的信息量,通过逐步迭代的方式得出分块图像的权值,有效提升了算法的识别率,但求取权值系数过程计算量大、耗费时间过长,降低了算法的时效性。而胡娜等[13]提出双向主成分分析(principal component analysis,PCA)降维,对分块图像特征进行行和列的双向降维,相对于传统LBP算法,有效提升了识别率,同样降低了识别速度。稀疏表示模型也是静脉识别的一类有效方法,Lei等[14]在稀疏表示模型中引入欧氏距离计算距离熵,有效抑制了图像的噪声干扰,相比于原有的模型,有效降低了等错误率,但相较于传统特征算子,识别率还需要进一步提升。
基于以上分析,LBP算子在静脉识别上具备优良的性能,在LBP算子的基础上,现通过局部平均的方式加强LBP算子的纹理表达能力,然后结合信息熵[15]作为加权系数得出熵值加权的局部二值模式(entropy weighted local binary patterns,ELBP)特征。而对于原始图像提取感兴趣区域[16],消除手指周围区域的干扰。同时,为提升算法的识别率与识别速度,采用主成分分析(PCA)将特征维数降低,最后使用欧式距离与曼哈顿距离计算相似性,对比验证本文方法的有效性。
1 基本原理
1.1 感兴趣区域(region of interest, ROI)提取
手指区域的提取,去除了许多手指未覆盖的干扰区域,有利于提升算法的识别率。首先将原图像转化为灰度图,对灰度图做边缘滤波[17]处理,如图1(b)所示。从图1(b)中可以看出,边缘算子能够很好地凸显手指的边缘部分。然后通过简单阈值分割凸显手指边缘,为方便手指区域的提取,其中全局阈值设为100,像素小于100时为0,大于或等于100时为1,得到二值图像如图1(c)所示。
由图1(c)可知,受检测器的影响,图像左右两边的手指边缘被包含,为准确提取手指区域,将二值图像分为上下两部分,如图1(d)所示。分别求出每部分的最密集边缘,即为对应的边界,根据求得的边界坐标,可得出原图的候选区域,如图1(e)所示。最后得到的候选区域如图1(f)所示,从图1(f)中可以看出,此方法能够较完整地保留了待测手指的完整性,有效地去除了冗余区域。
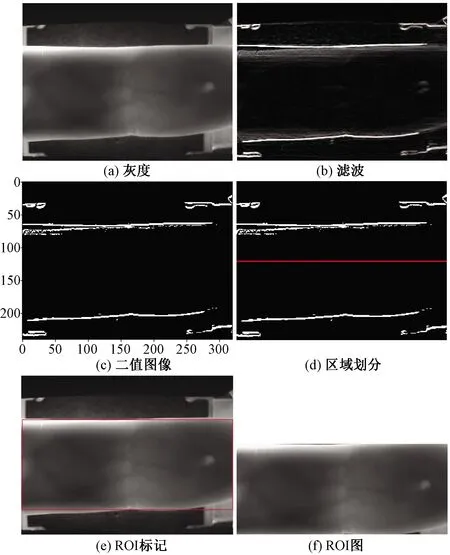
图1 ROI提取示意图Fig.1 ROI extraction process
1.2 ELBP特征
LBP作为经典的纹理特征,在图像识别与目标检测中得到了广泛的应用。其主要是通过像素与邻域像素的大小比较,并用0和1表示比较结果,然后将一系列0与1组合为一个二进制数,之后转化为十进制数即为中心像素的LBP值,最后通过直方图统计,得出图像的LBP特征。像素LBP值转换公式为
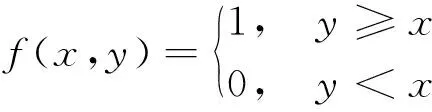
(1)
li=f(c,ni)
(2)

(3)
式中:f(x,y)为比较函数;c为中心像素点;ni为邻域像素点;li为邻域像素比较结果;i为像素对应编号;L为求得的LBP值。
为提升LBP算子的识别性能,通过计算邻域像素的均值,使LBP算子包含邻域像素之间的大小信息,同时与中心像素比较取更大值作为新的中心像素,计算公式为

(4)
nc=max(c,mean)
(5)
式中:N为邻域像素个数;mean为均值;nc为新的中心像素。
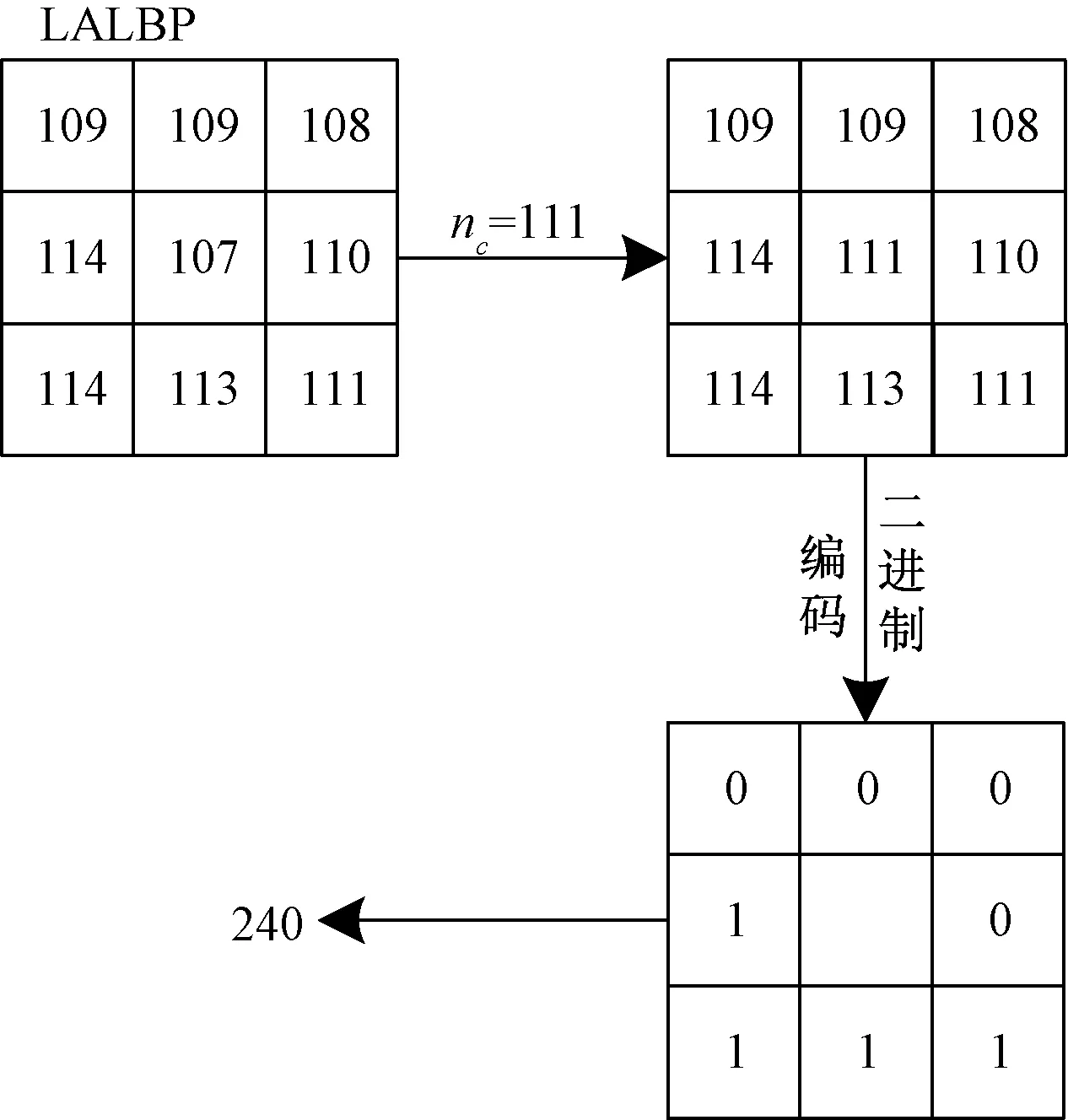
图2 LALBP编码原理Fig.2 LALBP coding principle
将求得nc代入式(2)和式(3)中可得LALBP值,计算过程如图2所示。将原图像转化为LALBP图后,使用梯度直方图统计可得256维的特征描述子,即图像的LALBP特征。
1.3 信息熵加权的ELBP特征
信息熵是香农在1948年根据热力学中的热熵[18]提出的,其描述的是信息源的不确定度。当信息源的不确定性越高,信息熵越大,其包含的信息量越大。利用信息熵表述图像的分块信息量,根据信息熵的大小分配权值,可提高重要特征密集区域的表达,提升识别率,信息熵与权值的计算公式为
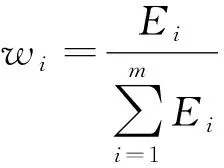
(6)
式(6)中:P为像素级数大小为k时在图像中出现的概率;E为信息熵;wi为块i的权值系数;Ei为块i的信息熵值;m为分块数。
将原图划分为8块,对于每个分块分别求LALBP特征并计算信息熵大小,将信息熵作为对应块的LALBP特征的系数,得到ELBP的直方统计图,最后将各块的特征归一化后级联得到图像的ELBP特征,提取流程如图3所示。
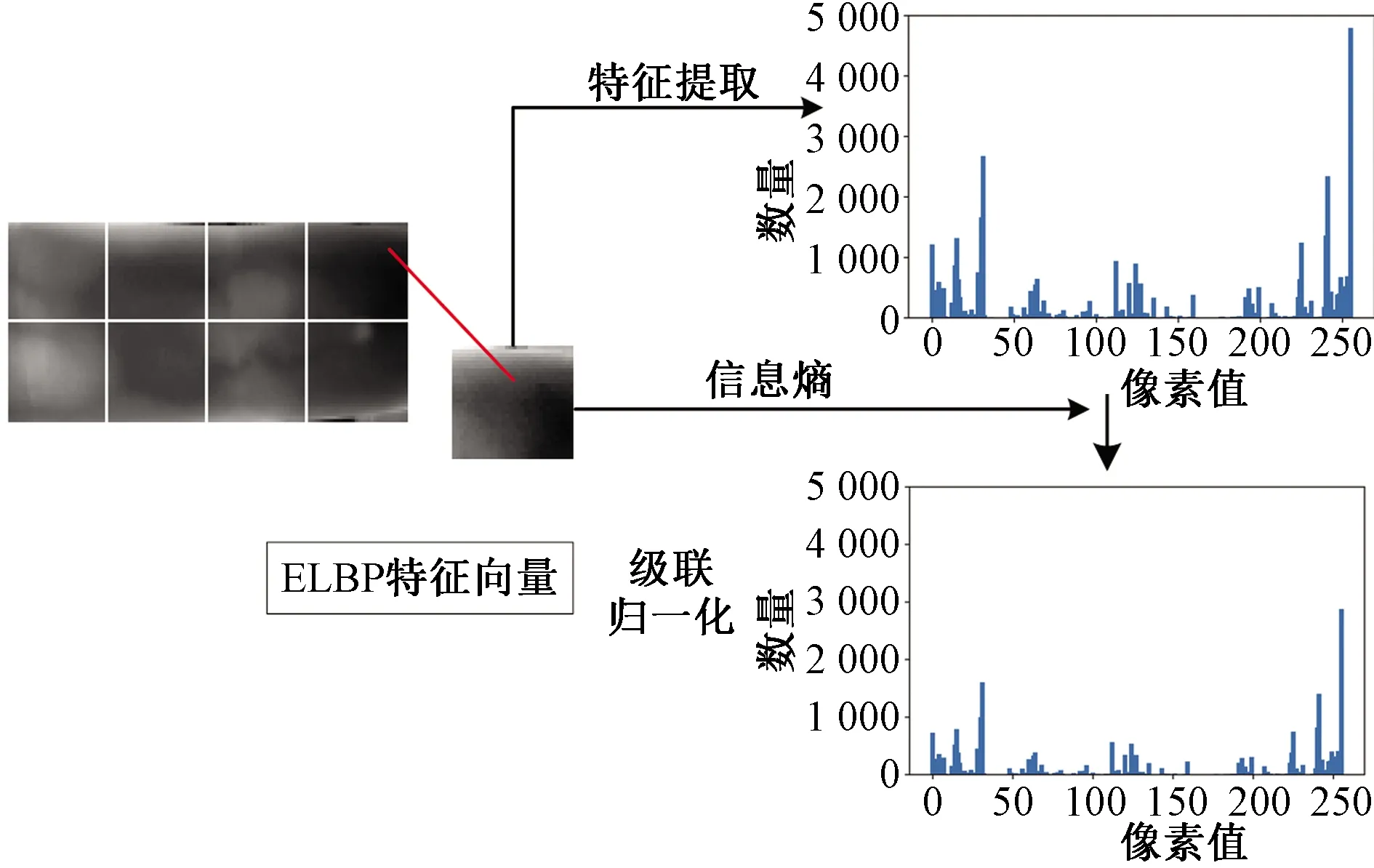
图3 ELBP特征提取示意图Fig.3 ELBP feature extraction diagram
2 基于ELBP的静脉图像识别
静脉图像的识别主要包括训练和识别两部分,训练过程将提取每幅图像的特征算子储存到训练库中,识别过程需要对提取的特征与训练库进行匹配比较,识别出待测图像属于训练库中的哪一类,流程图如图4所示。
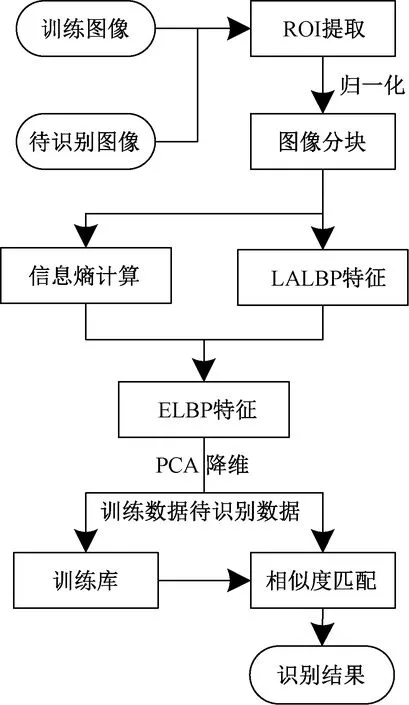
图4 识别算法流程图Fig.4 Flow chart of recognition algorithm
首先提取原图像的ROI区域并归一化至64×128大小,得到相同大小的特征提取图像;然后根据归一化后图像的尺寸,将图像分为m大小相同的子块,分别对子块图像提取LALBP特征,之后通过式(4)和式(5)得到对应块的信息熵与加权系数,将系数与对应块的特征相乘后级联,得到熵值加权的ELBP特征;最后利用向量距离计算方法欧氏距离、曼哈顿距离等作为相似度计算公式,计算待识别图像与训练库中所有样本的相似度,采用最近邻分类方式得出相似度最大的样本类,待测图像的识别结果即为对应的类。
分别采用欧氏距离以及曼哈顿距离作为对比分类器,对于每一个待识别样本,提取特征后分别与训练库中的样本特征求特征向量的距离,距离最小的训练样本对应的类型即分别为匹配类型。欧氏距离与曼哈顿距离计算公式分别为

(7)
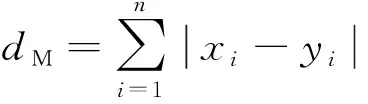
(8)
式中:xi为训练库的特征因子;yi为待识别特征因子;n为特征维数;dE为欧氏距离计算结果;dM为曼哈顿距离计算结果。
3 实验结果及分析
采用的数据集为SDUMLA数据库与天津市智能实验室采集指静脉图像数据库。SDUMLA数据库分别采集了106人,有636种手指类型,图像大小为320×240。天津数据库则采集了66根不同手指,每类15幅图像,图像为尺寸为80×170。
3.1 基于SDUMLA数据库分析
在SDUMLA数据库中分别选取1、2、3、4、5幅图像为训练样本数,组建5个不同的训练库,通过PCA降维,得到在不同训练样本数下,ELBP特征维数与识别率的关系,结果如图5所示。
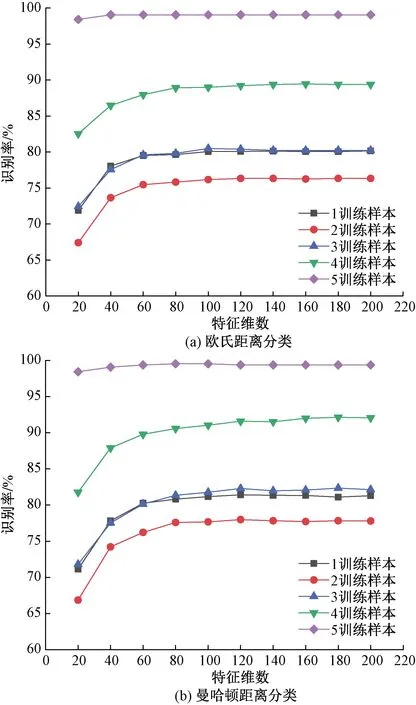
图5 特征维数对比Fig.5 Feature dimension comparison
对比图5中两种分类方式可以看出,ELBP的主要特征只有80维,维数上升到80之后,识别率处于稳定状态,并且特征维数对识别率的影响在不同分类器上变化趋势一致。同时,随着样本数量的增加,识别率越稳定,所需的特征维数越低。由图5可知,当训练样本数为5时,特征维数为40时识别率便基本不变。基于匹配时间与识别率的综合考虑,选取80作为维数降低后特征的长度较为合适,既提升了识别率又兼顾了训练样本数量的变化,同时能够极大程度缩短匹配时间。
欧氏距离与曼哈顿距离同样作为向量距离的计算方法,但作为识别系统的分类器性能上有很大的差异,一个优良的分类器能够有效地提升识别系统的识别率,LBP、HOG、LBP-PCA与本文方法在不同分类方式下的识别率与识别时间如表1所示。
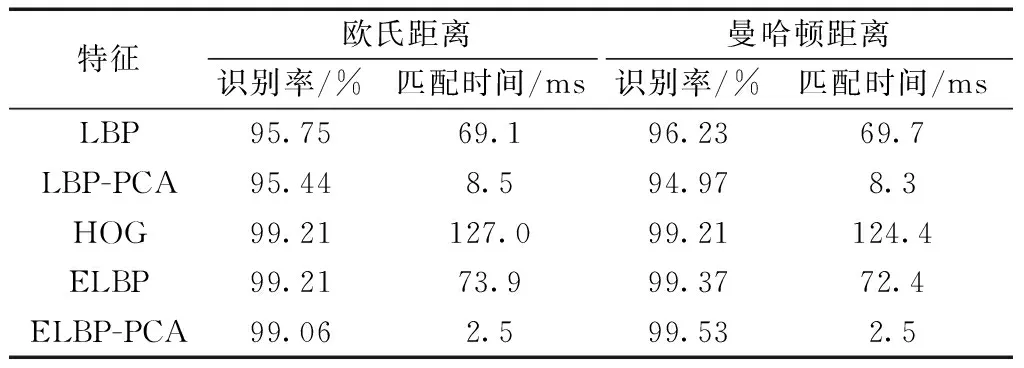
表1 两种分类器性能对比
从表1可以看出,在识别率方面,LBP、ELBP和ELBP-PCA特征采用曼哈顿距离计算相似度的识别率更高,相对于欧氏距离分别提升了0.48%、0.16%和0.47%,HOG特征保持不变,而LBP-PCA降低了0.47%;在时间方面,两种计算方式并无明显差异,因此本文所选特征算子更适合采用曼哈顿距离作为相似度计算的方法。同时对比几种特征算子的结果可以发现,HOG特征虽然识别率达到了99.21%,但匹配时间过长;LBP-PCA识别时间为8.3 ms,满足一般识别要求,但识别率仅为94.97%,相对于其他方法偏低;而本文方法识别率最高,达到了99.53%,同时匹配时间最低为2.5 ms,因此本文方法在识别率与匹配时间上相对其他方法具有一定的优势。
利用维数选取的5个数据库,对比分析LBP、HOG、LBP-PCA与本文算法识别率、识别时间与样本个数的关系,其中,识别率与训练样本个数关系如图6所示。
从图6中可以看出,训练样本个数为2时,识别率达到了低谷,但低谷并不是特征算子导致。因此针对此数据集,样本数为2时效果最差,同时样本数为5时,相较于1、2、3、4,识别率有明显的提升,所以样本数量的增加能够有效提升识别率。对比图6(a)和图6(b),可以看出,不同的分类方式下,识别率会有一定的变化,但本文提出的ELBP-PCA特征,在两种距离计算方法下,识别率均高于其他特征,在不同训练样本个数下均有一定的优势。
3.2 基于天津静脉数据库分析
由以上实验分析可知,本文算法在SDUMLA数据库中的识别率最高为99.53%,高于其他对比特征,同时表明了本文算法的高性能。为证明本文算法的通用性,而不是针对某一数据集有较好的性能,将本文算法与LBP、HOG和LBP-PCA等特征在天津数据库上进一步对比分析。
天津静脉数据库样本中,每种类型包含15个样本,可分别选取1、3、5、7、9个训练样本数构建5个训练库,分析各算法在天津数据库上的识别率与训练样本个数的关系。在不同训练样本个数的情况下,得出不同特征的识别率,同时也可反映出本文方法在天津静脉数据库上的性能,得出的各类方法所能取得的最高识别率。同样采用两种不同的距离计算方式构建分类器,计算不同训练样本下的识别率,对比结果如表2所示。
由表2可知,各类特征在此数据集上的识别率均在94%以上,表明纹理和梯度特征在静脉识别中有较好的性能。比较样本个数与识别率的关系可知,天津数据库的最佳样本数个数应在3~5,过多的样本反而会降低识别率。其中利用欧式距离分类,训练样本个数为3时,ELBP的识别率达到最大值99.74%,高于LBP的97.53%,与HOG持平;而使用曼哈顿距离分类时,训练样本个数为5时,识别率达到99.84%,高于LBP、HOG的98.75%、99.74%,表明ELBP特征在不同的数据集上仍有很好的识别性能。
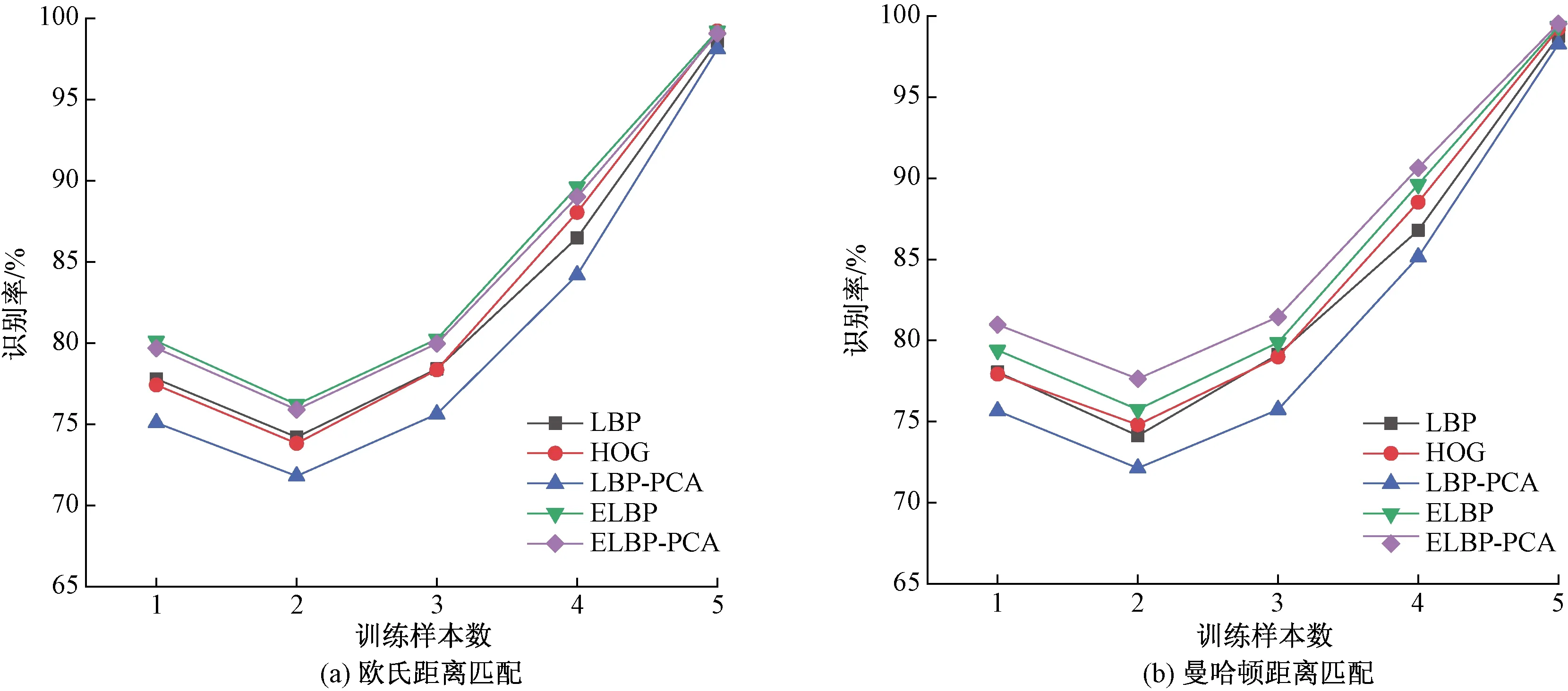
图6 训练样本数对比Fig.6 Comparison of the number of training samples

表2 不同训练样本个数下的识别率
4 结论
结合信息熵与改进型LBP算子提出了信息熵加权的ELBP算子,整体上突出图像部分信息丰富区域的表达,对于单个LBP算子通过引入邻域像素间的关系加强了LBP算子的识别性能,并通过PCA降维,消除冗余特征,提升了图像的识别率与匹配速度。实验结果表明,本文算法能够有效提升识别率,在两个数据集上最高识别率分别达到99.53%、99.84%,相对于单一的LBP、HOG算法,具有更高的识别性能,并且在识别时间上同样具有一定的优势。同时经过实验验证,本文算法与曼哈顿距离结合识别性能更好。
猜你喜欢
军民两用技术与产品(2022年1期)2022-06-01 06:28:50
计算机工程(2020年3期)2020-03-19 12:24:50
科技创新与应用(2020年6期)2020-02-29 10:39:27
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
中国交通信息化(2018年3期)2018-06-13 03:27:58
电子测试(2017年12期)2017-12-18 06:35:48
雷达学报(2017年6期)2017-03-26 07:52:58
北京理工大学学报(2016年6期)2016-11-22 11:17:22
电视技术(2016年9期)2016-10-17 09:13:41
系统工程与电子技术(2016年7期)2016-08-21 13:59:00
