
分布式供热管网中异常数据识别算法设计
2022-06-14 09:50薛贵军张红梅
计算机仿真 2022年5期
袁 丁,薛贵军,张红梅
(华北理工大学电气工程学院,河北唐山 063210)
1 引言
随着互联网技术和科学技术的迅猛发展,信息化已经成为我国供热行业发展和进步的焦点,其中数据采集和传输也成为供热系统不可或缺的一部分[1,2]。但是对于海量数据而言,处理方式仍旧停留在简单的统计阶段,无法使数据发挥出最大价值。供热数据深度挖掘的实现,不仅对数据的数量具有要求,同时数据质量也需要有所保证,因此,对供热管网数据进行异常辨识具有十分重要的意义[3]。
国内外相关专家给出了一些较好的研究成果,例如许春杰等人[4]在节点层级通过K-means算法对数据进行聚类,执行簇合并算法,同时使用基于KNN的异常簇检测方法进行局部节点检测,最终完成数据异常检测。冀汶莉等人[5]主要通过RDU算法对大部分数据进行下采样处理,将重复样本删除;剩余部分数据则通过SMOTE算法对少数异常数据进行过采样,合成新数据,降低数据集的不均衡性,同时采用优化后的数据集对RF分类算法进行优化,获取异常数据识别模型,通过模型实现数据识别。以上两种算法由于未能在实际操作过程中对数据进行降噪处理,导致最终获取的识别结果存在查全率和查准率下降以及运行时间增加等问题。为此,提出一种分布式供热管网运行数据异常在线辨识算法。仿真结果表明,所提算法能够有效减少运行时间,提升查全率和查准率。
2 数据异常在线辨识算法
2.1 分布式供热管网运行数据降噪
一般情况下,分布式供热管网在实际工作过程中,系统会受到周边环境和相关设备的影响。为了更好地克服这些干扰,需要对数据进行降噪处理。其中,数据是由过程数据和噪声数据构成,具体的计算公式如下所示
f(n)=x(n)+ε(n)
(1)
式中,ε(n)代表噪声数据;f(n)代表真实数据;x(n)代表过程数据。
为了更好完成数据降噪,以下使用基于贝叶斯的小波降噪方法对数据进行去噪,具体的去噪流程如图1所示:

图1 小波降噪流程图
其中,一簇动态离散小波基函数可以表示为
ψmk(t)=2-m/2ψ(2-mt-k)
(2)
式中,ψ(t)代表母小波;m代表伸缩系数;k代表平移系数。全部数据都能够划分为多尺度形式,具体计算式如下

(3)
式中,dy代表在尺度y处的小波系数;ay代表在粗略位置处的小波系数;dy(m,k)代表滤波矩阵;ay(L,k)代表数据矩阵;ψmk(t)和φmk(t)代表两个不同尺度的细节矩阵。
小波包在降噪的过程中,有两个重要因素对降噪起十分关键的作用:①选取哪种小包作为小波包分解的母小波;②明确小波包的分解水平。优先需要解决的问题为:通过训练集在小波簇中选取最符合条件的小波。针对各个候选小波基,随机选择一段过程测量数据作为训练集,主要通过小波分解的方式将其分解,分解为多个不同的等级。结合分解等级计算各个小波分解系数的平均值,然后进行统计分析。η代表候选小波描述的运行数据和测量数据两者之间的相似程度。η的取值越小,则说明候选小波越能够真实反映数据的变化情况。
当确定数据的小波分解级别后,通过香农熵准则划分为不同分解级别的性能指标。在数据处理的过程中,香农熵表示随机变量中的一种不确定变量。当熵值的取值越大,则说明其中含有的信息越多,同时成分也越复杂,数据降噪的难度也会相应地增加。
香农熵代表对任意一种信号进行无损压缩所包含的绝对限制,一个X值域为{x1,x2,…,xn}的随机变量的香农熵值H表示为
H(X)=E(I(X))
(4)
式中,E代表期望函数的取值大小;I(X)代表任意一个随机变量。假设p为X的概率密度函数,则香农熵对应的计算式为
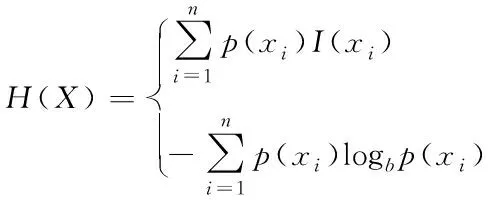
(5)
式中,p(xi)代表节点集合;I(xi)代表全部数据的平均取值。
为了在分布式供热管网运行数据异常在线辨识过程中,对数据进行有效降噪,修建图中的小波包分解树占据十分重要的地位。为了保留信号中的有效节点,需要对小波包树进行修剪,将冗余节点剔除。以下主要通过小波包树结构中的任意节点是否有效来进行信号降噪。白噪声的主要特点的平均值为0,标准差为1,所以通过各个节点的局部标准差来检测该节点的白噪声。
在第k个训练信号中的第n个节点局部方差能够表示为
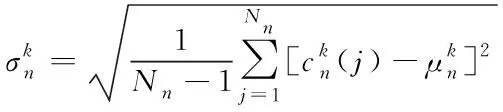
(6)

为了获取更加理想的去噪效果,在小波降噪中加入贝叶斯。通过应用双向优先注册获取最优小波数,针对原始小波包数中的各个节点,分别计算其标准差,同时将标准差按照从大到小的顺序进行排列。在训练集合中,第n个节点的全局标准差可以通过式(6)进行计算,即

(7)
上式中,μσn代表数据在训练过程中小波包分解中第n个节点局部标准差的平均取值;M代表训练集中的数据集总数。
在上述操作的基础上,主要选取最优树中的有效节点,同时在分解系数上增加阈值进行全面降噪。其中,阈值能够划分为两种类型,分别为软阈值和硬阈值,以下给出具体的定义:
1)软阈值
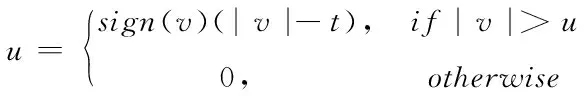
(8)
式中,t代表阈值大小;v代表小波系数的取值大小。
2)硬阈值:
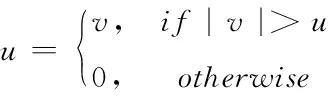
(9)
但是软硬阈值分别存在不同的弊端,为了有效避免两者的不足,以下主要使用非负garrote阈值,具体表达形式如下

(10)
当完成上述操作后,可针对分布式供热管网运行数据进行降噪处理:
1)将获取的数据分解到最优树中,通过相关决定参数对分解系数进行阈值处理。
2)针对最优树中保留节点的分解系数进行调整,最终达到信号重构的目的,完成数据降噪。
2.2 分布式供热管网运行数据异常在线辨识
利用图2给出分布式供热管网运行数据异常在线辨识的详细操作流程图。

图2 运行数据异常在线辨识流程图
对经过降噪处理的数据进行挖掘,为数据特征提取模型提供一定的数据基础,同时通过多数据流非线性特征重组方法,完成数据的布谷鸟搜索寻优,进而实现分布式供热管网运行数据异常在线辨识。
为了更好地实现数据异常辨识[6],通过统计信息处理方法进行信息统计,同时使用期望频繁项和概率频繁项相结合的方式,获取数据的挖掘信息,结合挖掘到的信息组建信息挖掘模型。利用宽平稳随机序列分析获取分布式供热管网运行异常数据的特征分布式调度函数,具体的表达形式如下

(11)
式中,xj(t)代表异常数据集中的平均信息熵取值;lj(t)代表异常数据集中的信息频谱特征向量,主要通过学习样本计算异常数据在第j个聚类中心的输出标签属性;N代表数据总量。
通过模糊关联规则调度方法进行统计特征分析,将全部分布式供热管网运行数据进行初始化处理,获取模糊聚类的中心点。其中,辨识数据对应的模糊隶属度函数能够表示为F(xi,Aj(L)),通过空间欠采样技术对数据的非线性特征进行重组,获取数据流融合的信息关联度,具体的表达形式为

(12)
式中,γi代表信息关联度;w代表聚类中心点总数;Ni(t)代表信号振荡频率;xi代表数据聚类中心;δN代表谱信息。
通过提取网络数据的信息熵,将获取的全部信息进行融合,即可获取对应采样节点的数据时间序列。
在上述分析的基础上,构建分布式供热管网运行数据异常在线辨识模型[7,8],通过模型获取多波束响应函数δk,同时将其转换为δik(t)
δik(t)=γiG(t)
(13)
上式中,G(t)代表数据安全等级。
选取少量的样本类别数据作为测试对象,对其进行特征提取,获取空间信息融合模型,如式(13)所示
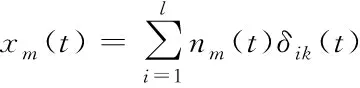
(14)
式中,xm(t)代表空间信息融合模型;nm代表测试对象数量。
在源域和目标域空间中,针对采集到的全部数据特征进行低纬度特征集组建,同时对分类任务进行特征筛选,获取多数据码元元素的期望支持度esup(D),同时获取模糊样本集。在满足约束条件的情况下,分类信息熵能够满足以下的约束条件
esup(D)=θ·xm(t)
(15)
通过模糊C均值聚类方法对数据中的异常信息进行自适应调节,利用四元组结构描述分布式供热管网运行数据的关联特征。设定Xij代表信息素强度;Pij代表输出优化训练的最优概率,通过谱聚类算法,获取模糊聚类迭代,具体的计算式为
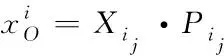
(16)
在数据特征提取模型的基础上,进行分布式供热管网运行数据异常在线辨识[9,10],同时引入布谷鸟搜索算法进行寻优。其中,数据进行特征提取的迭代式可以表示为
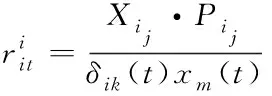
(17)
结合数据异常分布状态完成在线辨识,其中经过重组后的特征可以表示为
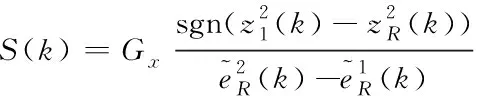
(18)

通过布谷鸟搜索算法,进行数据异常在线辨识自适应优化,获取最终的在线辨识结果

(19)
式中,S(k)代表系统参数。
3 仿真研究
为了验证所提分布式供热管网运行数据异常在线辨识算法的应用性能,需要进行仿真测试。将文献[4]方法和文献[5]方法作为对比方法,对比不同方法进行对比验证。
1)查全率/%
为了验证算法在实际应用的过程中,是否能够对全部数据进行辨识,将查全率作为测试指标,其中查全率取值越大,说明算法的应用效果越好,具体实验对比结果如图3所示。
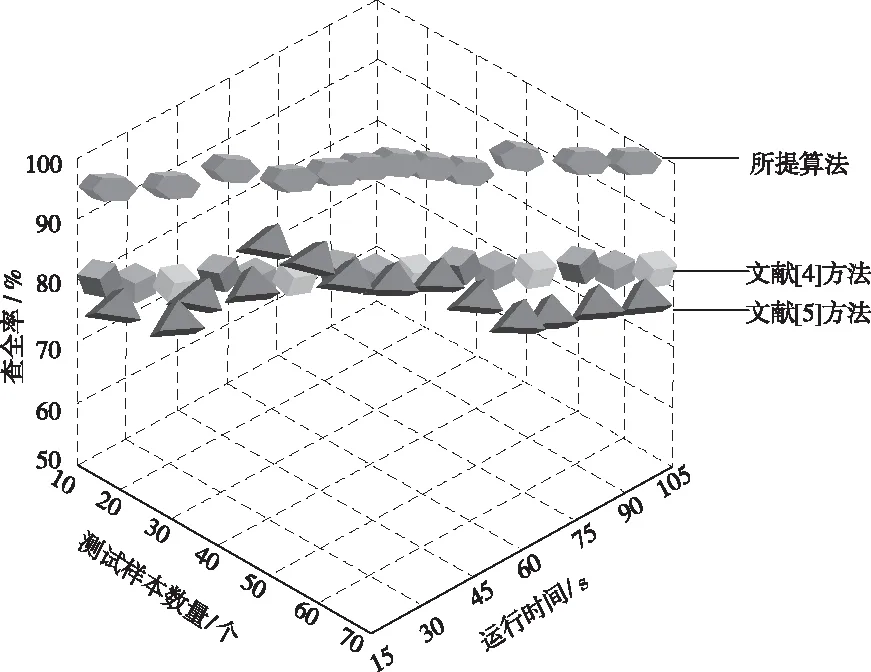
图3 不同方法的查全率对比结果
分析图3中的实验数据可知,当测试样本数量和运行时间开始增加时,各个方法的查全率均处于相对稳定的状态。但是相比另外两种方法,所提算法的查全率明显更高一些,充分说明所提算法的优越性。
2)查准率/%
为了验证辨识结果的准确性,实验选取查准率作为测试指标,其中查准率越高,则说明数据异常被准确辨识的概率就越大,具体实验结果如表1所示。

表1 不同方法的查准率对比
分析表1中实验数据可知,所提算法的查准率明显更高一些,主要是因为所提算法通过基于贝叶斯的小包降噪方法对数据进行去噪处理,全面剔除数据中的噪声,避免噪声对数据异常辨识产生的影响,全面提升了辨识结果的准确性。
3)运行时间/s
为了验证算法辨识速率的快慢,选取相同数量的样本进行数据异常在线辨识,其中用时越短,则说明辨识速率越快,具体实验结果如图4所示。
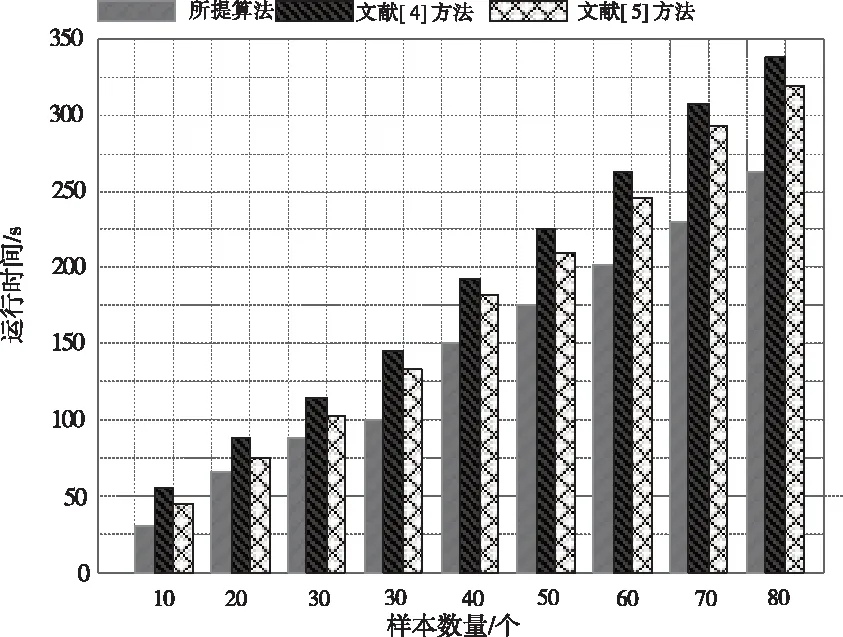
图4 不同方法的运行时间对比结果
分析图4中的实验数据可知,当测试样本数量开始持续增加,各个数据异常辨识方法的运行时间也开始呈明显的上升趋势,同时上升幅度较大。而所提方法则处于平稳上升的趋势。但是和另外两种方法相比,所提方法的运行时间明显低于另外两种方法,充分说明所提方法能够以较快的速度完成数据异常在线辨识。
4 结束语
由于传统数据异常在线辨识方法存在的弊端,提出一种分布式供热管网运行数据异常在线辨识算法。仿真结果表明,所提算法能够有效降低执行时间,提升查全率和查准率,获取满意的数据异常辨识结果。但是由于时间和精力有限,导致所提方法算法仍然存在不足,后续将对其进行进一步完善。
猜你喜欢
现代电子技术(2022年11期)2022-06-14
建材发展导向(2022年6期)2022-04-18
建材发展导向(2022年6期)2022-04-18
煤气与热力(2022年3期)2022-03-29
建材发展导向(2021年22期)2022-01-18
建材发展导向(2021年19期)2021-12-06
科技研究(2021年15期)2021-09-10
智能建筑与工程机械(2019年6期)2019-09-10
分析化学(2017年12期)2017-12-25
环境(2017年6期)2017-06-23
