
基于改进XGBoost算法的硬盘故障预测
2022-06-14 10:07陈守贤
计算机仿真 2022年5期
陈守贤,陈 梅,李 晖
(贵州大学计算机科学与技术学院,贵州贵阳550025)
1 引言
硬盘是现代数据中心的重要组成部分,在大型存储系统中能否提供稳定可靠的数据访问能力,直接影响到整个存储系统的可靠性[1]。根据微软公司过去对数据中心发生的硬盘故障统计[2],硬盘发生的故障占所有故障的78%,内存占比3%,RAID卡占比3%,其它故障占比16%,由此可知硬盘故障是影响存储系统可靠性的主要因素。目前,提高存储系统可靠性的机制分为被动容错和主动容错[3]。被动容错是当硬盘发生故障时,通过对数据进行备份或纠删码的方式来保障数据的安全性。被动容错方式存在的缺点,需要备份大量数据,增加数据中心的运营负担以及数据在备份时如果用户请求会存在一定的响应延迟。主动容错方式则是使用硬盘的SMART技术[4]来预测硬盘故障。SMART全称“Self-Monitoring, Analysis and Reporting Technology”,即“自我检测、分析和报告技术”,它可以监控单个硬盘的内部属性,并为每个指标设定阈值,在任何属性超过阈值时发出警报。目前,几乎所有硬盘制造商都支持SMART技术。然而,据估计,在0.1%误报率(FAR)[5]下,阈值算法只能达到3%~10%故障检出率(FDR)。研究表明,基于简单的SMART属性值不能够准确的预测硬盘故障。使用机器学习方法基于大量硬盘数据,通过对硬盘SMART属性数据进行分析,挖掘硬盘内部数据蕴含的规律,实现硬盘故障预测,达到及时处理硬盘故障,提高了存储系统的可靠性。在构造硬盘故障预测模型过程中,存在硬盘正负样本比例不平衡。如何在正负样本不平衡情况下识别出更多的故障硬盘,这是需要重点关注和解决的问题。
为了对硬盘故障预测,研究人员提出了许多基于SMART属性的统计方法和机器学习方法。Zhu等[6]基于原始的SMART属性及其变化率采用神经网络和支持向量机模型预测硬盘故障。Wang等[7]提出了一种基于马氏距离和广义似然比检验的硬盘故障预测两步参数化方法,得到了FAR为0,FDR为67%。Chaves等[8]利用贝叶斯网络方法预测了超过40000 SATA硬盘的SMART数据的故障,结果表明均值和方差分别比基准模型增加了28.3%和17.6%。Xu等[9]使用基于回归树预测磁盘故障算法,在BackBlaze数据集上实现了30%~40%的FDR,而FAR保持在0.1%。李新鹏等[10]针对不平衡样本数据采取数据级方法基于自适应加权Bagging-GBDT算法对磁盘故障进行预测,对少数类样本的召回率提高了9.46%。Zhang等[11]提出了一种基于分层扰动的硬盘健康度预测对抗训练方法,降低了硬盘误报率,提高了故障检测率的精度。Shen等[12]采用基于k-means聚类的欠采样方法来解决硬盘数据不平衡问题,使用循环神经网络对硬盘进行故障预测,减少了计算开销,提高了预测模型的FDR。
总之,为了提高模型预测精度,针对硬盘正负样本数目不平衡的分类问题,本文提出了一种基于改进的XGBoost算法用于硬盘故障预测。通过对算法损失函数的改进,使得改进的函数能够适应类别不平衡问题,以及通过减少易分类样本的权重,使模型在训练时更专注于难分类的样本,最后使用信息增益比率进行特征选择,提高对硬盘故障预测的精度。为验证模型的有效性,本文使用公开的硬盘数据集进行实验分析。
2 相关原理及技术
2.1 XGBoost算法
XGBoost是基于GBDT算法的改进[13],与GBDT相比,XGBoost在目标函数中增加一个正则项来提升算法的泛化效果,同时使用二阶泰勒展开式逼近损失函数来优化目标。XGBoost算法的预测精度受模型的偏差和方差影响,损失函数代表了模型的偏差,为了使模型的方差较小,在目标函数中加入正则化项,从而防止模型过拟合。所以XGBoost算法的目标函数由损失函数l和控制模型复杂度的正则化项Ω组成,即
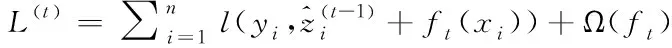
(1)

为了优化目标函数,对式(1)二阶泰勒展开得
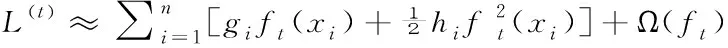
(2)
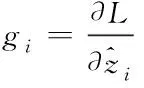
其中,gi,hi分别为损失函数的一阶导数和二阶导数。
定义模型的复杂度Ω,则展开式为
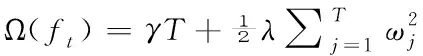
(3)
其中,T为节点数,ωj为叶子节点j的权重,γ和λ为正则化系数。
2.2 特性选择
在设计分类模型时,一个最重要的环节就是特征选择,面对许多特征,如何选取有利于模型分类的特征。本文使用基于信息增益比率的方法对硬盘特征进行选择。
2.2.1 信息熵
在介绍信息增益比率之前,首先引入信息熵(Information Entropy)的概念[14]。信息熵是为了度量信息的不确定性程度,熵的值越小,代表信息所含信息量越大。为了选取有利于硬盘故障预测相关的特征,使用信息熵来判断所选特征的信息量。设X表示硬盘数据基于某个目标的划分,则X的信息熵公式为

(4)
其中,pi表示数据集中第i个类别标签的频率,设硬盘数据X按特征A进行划分,若特征A有n个分支,则特征A的信息熵公式为:
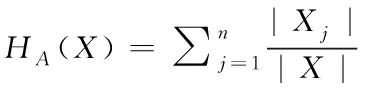
(5)
2.2.2 信息增益比率
为了更好的表示信息量,引入信息增益(Information Gain)的概念。对于特征A,其信息增益的计算公式为
gain(A)=H(X)-HA(X)
(6)
如果每条样本的特征A都不相同时,gain(A)的值就会很高。因此,使用信息增益比率(Information Gain Ratio)来防止这种情况的发生。对于特征A,分裂信息的公式为

(7)
信息增益比率由信息增益与分裂信息的比值表示,即

(8)
如果特征A的取值有很多,则SplitInfo(X)的值就会变得很大,导致最终的增益比率下降。但是SplitInfo(X)也有可能为0的情况,所以,在分母上添加一个分裂信息的平均值,即

(9)
3 XGBoost算法损失函数的改进
XGBoost是一个高效、灵活的算法,针对不同的问题可以使用不同的损失函数,并且它提供了自定义损失函数的接口,只需要在目标函数优化过程中,自定义损失函数满足二阶可导即可。XGBoost算法对于二分类问题通常使用交叉熵损失函数。其形式如下
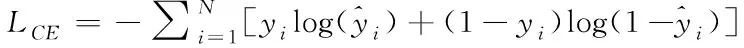
(10)
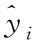
为了解决硬盘类别不平衡问题,对交叉熵损失函数进行改进。具体做法是给正负样本加上权重,由于负样本出现的频次高,就降低负样本的权重,正样本数量少,就相对提高正样本的权重。公式如下
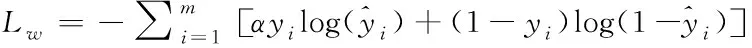
(11)
其中,α表示“不平衡参数”,通过设定α值来控制硬盘正负样本对总的损失的共享权重,用于平衡训练正负样本集。
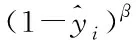

(12)
其中,β用于区分训练样本难易程度,其范围β∈[0,+∞),β取值越大则越重视难度。即专注于比较困难的样本,使用该损失函数度量难分类和易分类样本对总的损失的贡献。当α=1,β=0时,该函数为交叉熵损失函数。
通过设置系数以适应不平衡数据集,改良损失函数使得其更加关注分类错误的样本。
4 基于改进XGBoost算法的硬盘故障预测
使用硬盘SMART数据基于改进的XGBoost算法对硬盘进行故障预测,其流程见图1。
硬盘故障预测步骤总结如下:
1) 采集硬盘SMART数据和类别标签构成原始数据集;
2) 对原始数据集预处理并使用信息增益比率方法进行特征选择;
3) 为了避免特征值之间的差异对模型性能的影响,对数据进行归一化处理;
4) 将预处理后的数据样本分为训练集和测试集;
5) 使用训练集构建改进的XGBoost模型,通过网格交叉验证方式优化参数α,β,使得最优参数值既能适应不平衡样本,同时使模型更专注于难分类的样本;
6) 使用测试集对优化模型进行预测,结合硬盘原始类别与预测结果得到模型分类准确率。

图1 XGBoost硬盘故障预测流程图
5 实验分析
5.1 数据集来源
本文使用两个数据集均来自企业级真实环境下的公开数据集[15],数据集Dataset1是从某企业数据中心采集的SMART数据,共有23395块硬盘数据,其中包含正常硬盘22962块以及故障硬盘433块。Dataset1中硬盘数据的采集频率为一小时一次,该数据集保存硬盘故障前20天的SMART数据样本,正常硬盘将保存连续7天的SMART数据样本。数据集Dataset2来自Blackbalze公司官网公布的ST4000DM000型号的希捷硬盘SMART数据。该数据集共有35320块硬盘,其中包含正常硬盘34256块以及故障硬盘1064块。Dataset2中硬盘的采集频率为一天一次,该数据集保存正常硬盘和故障硬盘前10天的SMART数据。
5.2 数据预处理和特征选择
Dataset2的SMART数据共采集23条特征属性,其中包含一些SMART数据没有变化的属性和缺失值较为严重的属性。本文在数据预处理时将缺失值较严重的属性和没有变化的属性从数据集中删除。对于缺失值不是很严重的SMART属性使用硬盘的前一时间点的值进行填充。由于各SMART特征之间的值对硬盘的故障预测可能存在冗余,从而影响模型的预测性能,因此对各SMART特征进行相关性分析,将各特征值之间具有强相关性的冗余特征进行删除。为了方便与Dataset1数据集进行比较,使用基于信息增益比率的特征选择方法筛选出排名靠前的12个特征作为本文硬盘故障预测的输入特征。表1展示了这12个特征及信息增益比率。
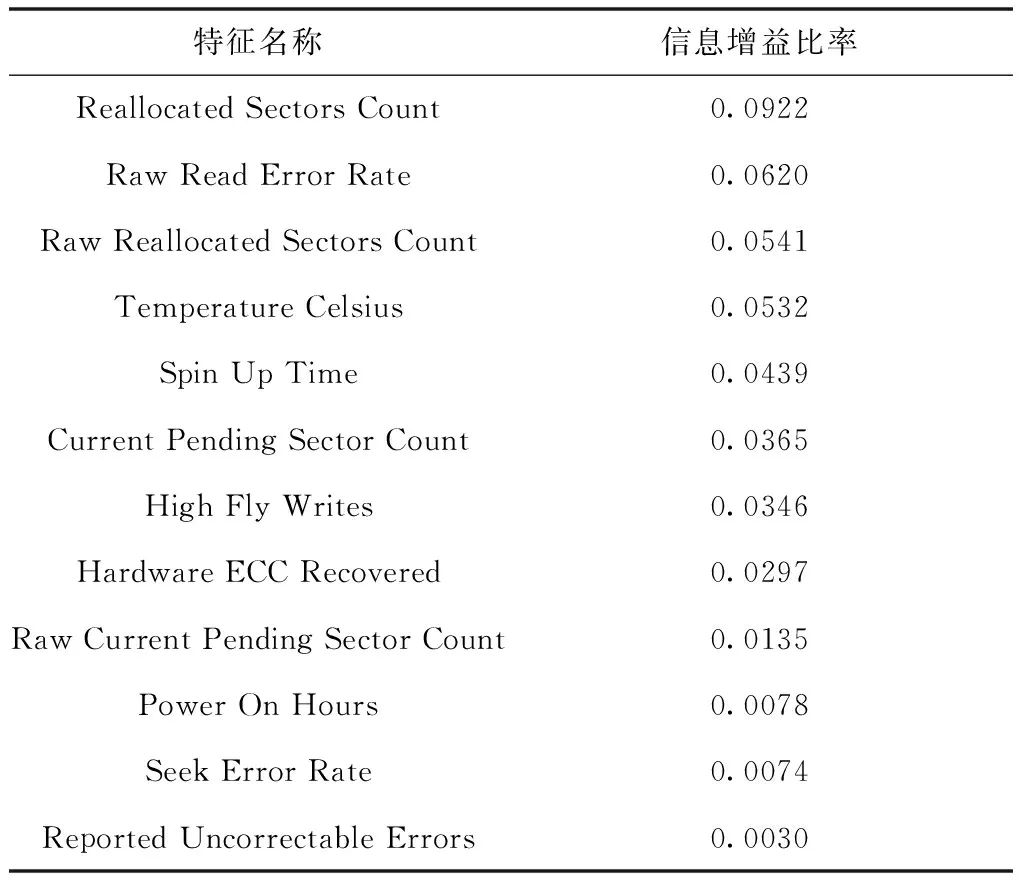
表1 Datasets2特征选择
以上特征中,有的特征取值范围较大,有的特征取值范围较小,为了避免特征之间的差异对模型性能的影响,对特征值进行归一化处理,即
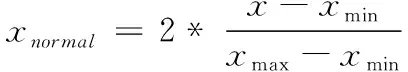
(13)
其中,x表示采集的原始特征值,xmax表示采集该特征的最大值,xmin表示采集该特征的最小值,xnormal表示归一化后的特征值。通过特征归一化之后,12个特征值的范围被映射到[-1,1]之间。
5.3 价指标
为了评估硬盘故障预测的性能,使用准确率(Accuarcy)、故障检测率(FDR)、故障误报率(FAR)、F1-Score、ROC曲线、AUC值等评价指标。该评价指标由混淆矩阵计算得出,见表2。
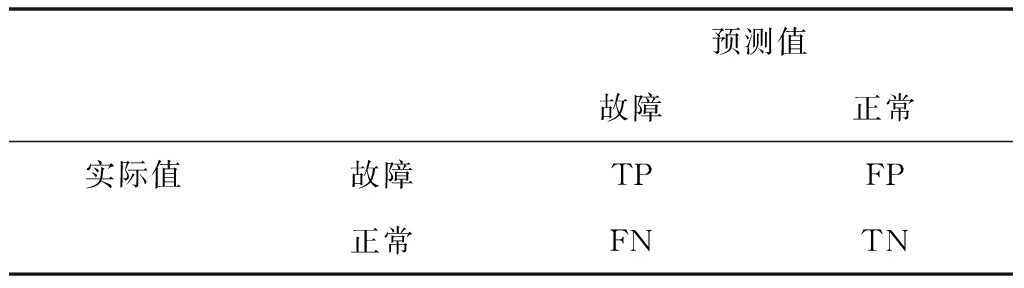
表2 混淆矩阵
1) 准确率(Accuarcy):
5) ROC曲线:使用ROC曲线评估故障预测模型的性能。该曲线的评判标准是曲线越靠近对角线的左上角,模型分类效果越好。AUC值则表示ROC曲线下的面积。
5.4 结果分析
使用数据集Dataset1和Dataset2验证本文改进的XGBoost模型预测硬盘故障精度。将改进XGBoost模型与XGBoost模型、随机森林、支持向量机、朴素贝叶斯针对准确率、故障检测率、故障误报率、F1-Score、ROC曲线、AUC值指标进行比较。
Dataset1对不同模型的硬盘故障预测的Accuarcy、FDR、FAR、F1-Score的结果见表3。ROC曲线和AUC值见图2。
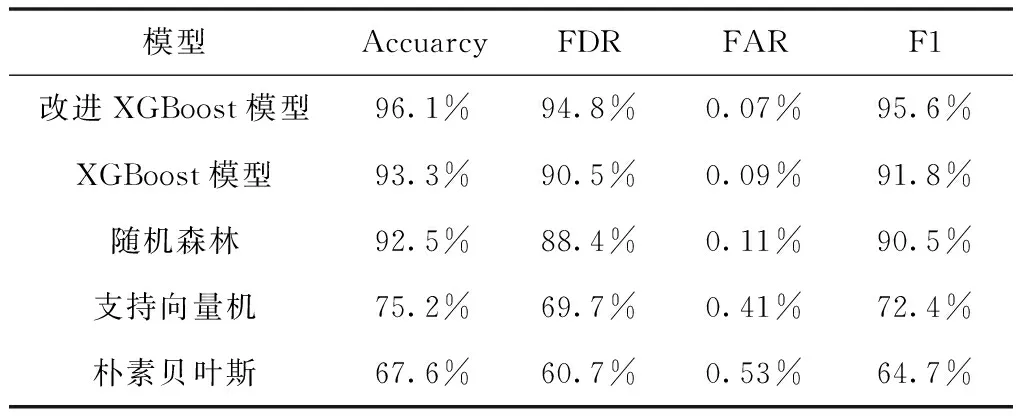
表3 Dataset1不同模型硬盘预测性能比较

图2 Dataset1不同检测模型的ROC曲线及AUC值对比
数据集Dataset2对不同模型的硬盘故障预测的Accuarcy、FDR、FAR、F1-Score的结果见表4。ROC曲线和AUC值见图3。
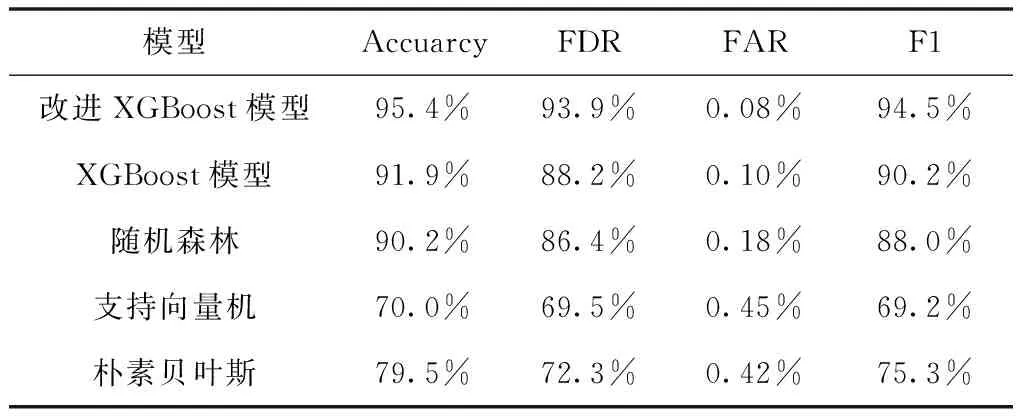
表4 Dataset2不同模型硬盘预测性能比较

图3 Dataset2不同检测模型的ROC曲线及AUC值对比
由表3和表4知,以随机森林和XGBoost算法为代表的集成学习算法比单个模型的预测精度高,XGBoost模型在硬盘故障预测中比随机森林预测精度高,通过对XGBoost模型损失函数的改进能够进一步的提高模型的预测精度,使用两个公开硬盘数据集验证了改进的XGBoost模型预测精度以及鲁棒性。图2、图3直观的展示了两个数据集在硬盘故障预测算法的有效性。
6 结束语
针对硬盘故障预测中样本类别不平衡以及传统算法对于不平衡样本易出现故障预测准确率较低的问题,本文提出了一种改进的XGBoost算法。使得改进之后的算法既解决了正负样本不平衡问题,同时使模型更专注于少数类别训练比较困难的样本,并使用信息增益比率方法对硬盘的SMART数据进行特征选择,提高模型的预测性能。通过两个公开的真实数据集进行实验,验证了改进的XGBoost模型不仅能够提升硬盘故障预测的精度,同时具有一定的泛化能力。
猜你喜欢
心理学报(2022年10期)2022-10-12
消费电子(2022年6期)2022-08-25
电子产品世界(2021年8期)2021-01-16
布达拉(2018年5期)2018-05-14
西江文艺(2017年15期)2017-09-10
数学学习与研究(2017年3期)2017-03-09
计算技术与自动化(2014年1期)2014-12-12
中学生数理化·七年级数学人教版(2014年6期)2014-09-18
微型计算机(2009年13期)2009-12-11
