
基于IMU辅助的快速相机重定位方法研究
2022-06-14 09:49杨伟力罗达灿陈朝猛于阳阳
计算机仿真 2022年5期
杨伟力,罗达灿,陈朝猛,于阳阳
(贵州民族大学,贵州 贵阳 550025)
1 引言
相机重定位是在三维环境中利用二维图像快速、准确地估计六自由度相机位姿,该任务往往作为同步定位与地图重建[1],增强现实[2],自主导航[3]等任务的子模块。在传统相机重定位中,三维场景通过SfM(Structure from Motion)、视觉里程计或者地图重建算法获得,查询帧图像需与整个三维场景模型进行匹配,建立2D-3D候选匹配关系,这些候选2D-3D匹配列表在RANSAC循环中利用PnP (Perspective-n-point)算法进行几何验证剔除异常点,对通过几何验证的2D-3D匹配再利用PnP估计相机位姿[4,5]。但在大场景中,计算量则会指数级增长,导致无法满足实时应用,特别对于敏捷型机器人或无人机需要快速实现定位,提升机动性。
将视觉传感器和惯性传感器结合是近几年里程计和同步定位与地图重建的研究前沿,现有视觉惯性里程计中,常采用基于手工特征的滤波器[6]和非线性优化[7]实现二维图像和惯性姿态信息的融合。IMU中的加速度和陀螺姿态数据的采样率可高达100Hz,使其更加适合于快速移动的敏捷型机器人定位。然而消费级IMU传感器存在漂移、噪声、轴偏差等,导致测量姿态存在误差,简单特征融合会得到可信度较低的位姿状态[8],为此现有方法将视觉信息和惯性信息进行融合得到更精确地机器人姿态[9,10]。
最近几年,深度神经网络(Deep Neural Network, DNN)在相机重定位[11]和视觉惯性里程计[12]上表现出极具竞争力的精度和鲁棒性。深度神经网络能够提取高层次特征表示,而无需对传感器显式地建立数学模型,这种数据驱动型模型更加鲁棒,且在高端图像处理器中前向推理速度比传统方法更快速,更适合于实时应用。
本文设计一种基于IMU辅助的快速相机重定位算法,结合IMU信息快速地从单帧RGB场景图像预测六自由度相机姿态。
2 基于IMU辅助的快速相机重定位方法
现有高精度相机重定位方法主要基于DSAC++[13],其设计了可微RANSAC策略(Differentiable SAmple Consensus),实现端到端训练相机位姿估计网络。但如果网络初始化存在偏差则导致参数搜索空间范围扩大,不仅需要较大网络模型回归位姿,导致其前向推理速度较慢,而且往往只获得局部最优解无法获得高精度的相机姿态。为此,本文在DSAC++基础之上,结合IMU姿态数据缩小了参数搜索空间,因此只需轻量级网络估计相机位姿,从而加速相机姿态估计速度。
2.1 DSAC++
DSAC++[13]及其早期版本DSAC[14]采用两个CNNs的端到端场景坐标回归器,其关键在于将传统RANSAC可微分化以实现网络端到端训练。DSAC采用两个CNN分别去预测场景坐标和评估每个像素对应姿态的可靠度分数,场景坐标预测网络输入从原图像截取的小块,输出为该小块中心像素对应的三维坐标,从而形成稠密估计。但截取图像块的方式使得场景坐标预测速度较慢,因此在DSAC++中利用FCN[15](Fully Convolutional Network)作为场景坐标预测模型,直接回归像素对应的三维坐标。特别是DSAC++采用无监督式的重投影误差损失训练网络而无需场景坐标真实值作为监督。DSAC++的训练采用三阶段训练策略,首先在使用PnP求解器获得的场景坐标下已给出的2D-3D匹配对上采样一组位姿对场景坐标预测模型进行初始化;其次优化由三维点至二维图像平面的残差之和构成的重投影损失;最后利用一种概率式内点计数对位姿假设进行评估以此实现可微RANSAC。然而,如果初始化网络的相近场景坐标与真实值偏差较大则会降低定位精度[16],为此,将IMU姿态信息融合至场景坐标预测模型,而无需初始化步骤,提升定位精度,同时辅助姿态信息的使用缩小了网络参数搜索空间,因此只需较小的网络模型即可达到好的位姿估计结果。
2.2 IMU惯性编码器
IMU可测量加速度和陀螺姿态信息,输出的惯性数据流具有较强的时域特征,频率相比图像数据更高,一般约100Hz,更适合于快速移动情况下的机器人位姿估计,但IMU测量存在偏差且易受噪声影响,因此常使用统计滤波进行状态估计,如扩展卡尔马滤波(EKF),无轨卡尔马滤波(UKF)或者粒子滤波等。本文提出利用长短期记忆模型(long short-term memory, LSTM)直接从惯性序列数据提取高层次特征表达,将高层次特征嵌入至场景坐标预测网络。直接使用LSTM估计姿态精度并不太高,但不会突然产生高度错误的输出,而滤波器方法会在某些数据帧产生较大误差[17]。因此,IMU姿态的高层次特征更适合作为一组辅助特征与DSAC++中的场景坐标预测网络进行特征融合,缩小模型参数搜索空间,促进丰富的图像特征获得高精度位姿。
2.3 相机重定位网络
所提出一种基于IMU辅助的快速相机重定位方法网络框架如图1所示。对图像传感器和IMU惯性传感器进行标定,同时对输出数据序列时间对齐。在训练和测试过程中,每输入t时刻采集的图像,则将t-1至t时刻之间的IMU惯性姿态数据输入由LSTM组成的惯性编码器中。惯性编码器由具有128位隐藏状态的三层双向长短期记忆模块(Bi-directional LSTM)构成,惯性编码器提取高层次位姿特征aI
aI=fintertial(xI)
(1)
其中fintertial(·)是具有高度非线性特征表达能力的LSTM编码器,xI为IMU数据序列。
输入二维图像的分辨率为640×480,进入DSAC++中的场景坐标预测FCN网络,最终产生80×60个点的稠密场景坐标预测。FCN是一种经典网络结构,在像素级分类任务(如语义分割、光流估计等) 具有良好表现,因此在像素级三维坐标估计任务上也能达到较好的结果。

图1 基于IMU辅助的快速相机重定位方法网络框架
记FCN前端编码器提取的高层次特征为aV
aV=fcamera(I)
(2)
对提取的高层次IMU特征aI和图像特征aV采用融合函数g(·)进行特征融合得到融合特征z
z=g(aV,aI)
(3)
这里,采用直接拼接的方式进行特征融合
gdirect(aV,aI)=[aV;aI]
(4)
其中[aV;aI]表示将aV和aI进行拼接操作。该场景坐标预测由FCN构成,目的是回归像素对应的三维坐标值,从而建立二维图像与三维场景空间的2D-3D匹配关系。
在DSAC++中场景坐标预测网络初始化要求较为严格,往往利用RGB-D相机获得精度较高的场景深度来初始化。如果初始化精度较低则使得网络陷入局部最优,定位精度急剧降低。因此在DSAC++中FCN采用11层深度的大网络预测场景坐标,扩大网络参数搜索空间同时增强了网络表达能力。但由于自然场景多样化,而数据集中场景较为单一,深层次网络容易使重定位网络过拟合,难以适应新的自然场景。此外,一个环境可能存在多个相同结构和特征的区域,如窗户、座椅等,只用初始场景初始化的网络从多种可能中挑选,增加六维相机姿态预测出错的概率。IMU高层次特征的引入,能缩小场景坐标预测网络所需的参数搜索空间,因此只需要轻量化网络即可得到较高精度的场景坐标值。实验中,将FCN后10层卷积层替换为4层可分离卷积层,网络层数的降低自然提升前向推理速度,同时轻量化网络具有更好的泛化能力,更能适应新的自然场景。同时由于每一帧图像都有时间对齐的IMU数据序列进行辅助,因此对于存在多个相同结构和特征的区域,也能给正确的估计姿态。
场景坐标预测后,随机挑选一个场景坐标子集构建一个相机姿态假设池{hi,i=1…N},每一个假设hi由可微RANSAC策略依据全局一致性指标(重投影误差)给出一个可信度分数s(hi),该可信度分数转换为一种概率值P表示,基于最佳概率选择最佳的相机姿态hi。该可微RANSAC策略采用一种简单且可微的柔性内点计数策略实现为假设打分。对相机姿态假设hi及对应像素j的重投影误差为

(5)
其中C是相机内参矩阵,pj是该设定相机姿态下图像平面坐标系下的像素坐标值。在齐次坐标下,进行透射投影后作差计算重投影误差,计算该误差的模。内点计算利用阶跃函数实现
∑j1(τ-rj(hj,w))
(6)
其中1(·)为阶跃函数,τ为内点阈值。由于阶跃函数不可导,使用sigmoid函数替换阶跃函数,因此最终柔性内点计数策略为

(7)
其中超参β调节sigmoid函数的柔性程度。最终假设的选择依据softmax分布P(j;w,a)进行
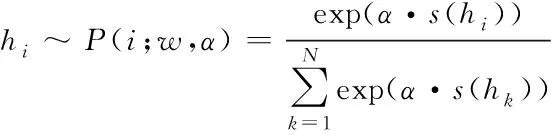
(8)
其中超参α是固定分布尺度的参数,其通过限制或加强得分较低对得分较高的假设的影响调节在端到端训练中网络参数的梯度流动。由于不同环境下内点分数幅度波动较大,为保证分数在有效范围内进而保证端到端训练更加稳定和易于收敛,利用信息熵策略自适应地调节分布的尺度,对该softmax输出概率采用自适应调节超参α:

(9)

相机重定位最终获得的位姿是一个姿态假设hi,其由相机的三维位移t和欧拉角表示的方向矩阵R构成
hi=[R|t]
(10)
姿态hi相对世界坐标原点定义,世界坐标可旋转任意全局参考帧,实验中选取三维场景所有相机位置的平均中心位置。
3 实验结果与分析
实验采用数据集Cambridge Landmarks dataset和7 Scenes dataset,Cambridge Landmarks dataset使用智能手机拍摄室外场景视频,并用SfM算法标注位姿。该数据集具有行人、车辆、光照变化、天气变化等难度较高的场景。7 Scenes dataset是使用Kinect V1拍摄的一组室内场景数据集,包括7个办公室场景,每个场景在一间房内拍摄,该数据集包括许多无纹理场景。图2中为两个数据集中随机抽取的示例图片,由图可见两个数据集有光照变化、遮挡、动态物体、天气变化等多种改变环境表观的因素,使相机重定位任务具有较大挑战性和代表性。

图2 数据集中随机抽取的示例图片
所有实验均在一块Nvidia 1080 Ti上运行,网络框架使用Pytorch实现。超参初始为0.1,设置为0.5,内点阈值设置为10个像素。使用ADAM进行优化,学习率设置为10-6。
表1为在两个数据集下的不同场景测试得到的相机位姿估计的中值误差,在两个数据集上,均得到了与DSAC++极具竞争力的性能。在7Scenes数据集中获得更好的实验效果,特别是在角度误差上明显比DSAC++的误差要小,这是因为7Scenes数据集在室内场景拍摄,存在较多无纹理区域,因此图像信息提供的位姿估计能力相对较弱,此时,IMU姿态信息对位姿的贡献得到明显体现,如在Stairs场景中,DSAC++位置误差和角度误差分别是0.29m和5.1°,在本文的重定位网络中位置误差降低为0.21m,角度误差则大大降低为原来的一半。可见,本文的重定位网络对于无纹理或弱纹理场景具有良好的位姿精度。在Cambridge Landmarks数据集中部分场景也获得了较好结果。Cambridge Landmarks在室外拍摄,室外自然场景纹理更加丰富,图像信息就能够获得较好的位姿估计。

表2 平均位姿估计时间表
本文提出的重定位网络,将原来场景坐标预测的11层FCN网络替换为4层可分离卷积构成的轻量化网络模型,使得网络前向推理速度更快。在位姿估计速度测试实验中,将不同场景的测试数据均分别送入网络,最后计算所有测试数据的前向推理时间的平均值,由表2可见,原始DSAC++前向推理时间需要485.07ms,这虽然满足大部分机器人定位需要,但是对机动性要求较高的敏捷型机器人而言,无法满足实时用。而本文提出的网络平均前向推理时间只需13.53ms,缩小了30多倍。显然本文提出的重定位网络在敏捷型机器人的应用上具有更高的优势。
4 结束语
本文提出一种基于IMU辅助的快速相机重定位方法,利用LSTM提取IMU姿态数据的高层次特征,与DSAC++中场景坐标预测网络进行特征融合,缩小网络参数搜索空间,从而利用轻量化的浅层网络即可实现快速且高精度的相机位姿估计。所提方法在较多无纹理区域的场景图像中,重定位精度仍然存在波动较大,主要是因为IMU姿态数据中噪声的影响。在接下来的工作中,将设计如何在本框架中集成可端到端训练的IMU去噪模块,提升IMU姿态信息的精度,从而在有较多无纹理场景下也能获得更高的重定位精度。
猜你喜欢
中国科技纵横(2020年13期)2020-12-11
现代信息科技(2020年22期)2020-06-24
当代陕西(2019年18期)2019-10-17
山东工业技术(2019年16期)2019-07-19
智富时代(2018年5期)2018-07-18
智富时代(2018年5期)2018-07-18
中学生数理化·七年级数学人教版(2016年6期)2016-05-14
诗选刊(2015年4期)2015-10-26
海峡科学(2013年3期)2013-10-21
数学大世界·小学低年级辅导版(2010年4期)2010-03-25
