
基于近似Q-学习算法的数据驱动控制仿真
2022-06-14 10:06于子航王改云
计算机仿真 2022年5期
于子航,王改云
(桂林电子科技大学花江校区电子工程与自动化学院,广西 桂林 541000)
1 引言
数据驱动控制是智能控制的一种形式,是智能领域的一个研究分支,最早起源于计算机科学领域。其中包含数据驱动思想与数据驱动控制两方面。数据驱动思想是利用受控系统现有数据实现系统数据的预报、调度、监控和决策等功能。数据驱动控制指的是在控制器设计过程中,不包含受控系统的数学模型,简单来说就是从数据直接到控制器的设计理论方法。传统的受控系统包含受控对象和控制器两部分,受控对象设计有四种方法,分别为:有精准的机理模型;有不精准的机理模型;机理模型过于复杂,非线性较强,阶数较高;无机理模型。控制器分为基于有机理模型和无机理模型两种。
随着研究深入,现阶段数据控制方法取得了巨大发展,并且产生了如自适应控制、最优控制、系统辨识等领域分支。例如,在智能车辆领域,许德智等人[1]提出了一种智能车辆自动超车系统的数据驱动路径跟踪约束控制,该方法在设计控制器的过程中,设计了一种抗饱和补偿器来解决控制输入受变换范围和速率限制问题,系统的控制仅使用自动超车系统数据,使控制性能不受车辆模型信息的影响,最后通过与PID(Proportional Integral Derivative)控制作仿真对比实验证明该方法能够较好地实现自动超车的路径跟踪,且误差较小,但是由于该方法需要处理数据较多,导致响应时间较长;在矿物浮选领域,姜艺等人[2]提出了一种数据驱动的浮选过程运行反馈解耦控制方法,该方法首先以矿浆液位和流量为输入,精矿品位为输出建立非线性运行模型,以未建模前的一拍可测特点为基础,设计出包含了PID控制器和反馈解耦控制器等为一体的数据控制方案,经过仿真结果表明,该方法具有一定的可行性,但是由于需要依赖的模型过多,导致控制结果还存在一定误差。
虽然数据驱动在多个领域取得了巨大成就,但是现阶段大多数的控制理论成果仍然对被控系统精准的数学模型过于依赖并且存在未建模动态等问题。然而在实际操作过程中,控制系统的参数和方程形式通常为未知的,进一步导致了受控系统的数学模型建立较为困难。因此,本文提出了一种基于近似Q-学习算法的数据驱动控制仿真,Q-学习是重要的强化学习方法之一,是一种不依赖环境模型的学习手段,主要通过经历的动作序列来完成最优动作学习。本文以Q-学习算法作为控制器结构,同时使用递推方式解决被控模型未知,致使优化算法不能继续使用的问题,最后通过对被控对象的伪偏导函数进行评估,完成数据驱动控制。在仿真中,将本文方法与传统方法的控制结果进行比较,结果表明本文方法的误差较小,具有一定的可行性。
2 近似Q-学习算法下数据驱动控制研究
2.1 近似Q-学习算法分析
智能学习的过程中,由于训练数据中不包含〈s,a〉训练样例,直接对函数π*:S→A进行学习较为困难,因此,可将立即回报序列r〈s,a〉,i=0,1,2…作为替代样例。给定训练信息以后,整个学习的过程是以状态和动作的数值评估函数为基础的,并且最终通过该评估函数实现最优策略的构建。假设要学习的评估函数为V*,当V*(s1)>V*(s2)时,则认为状态s1优于s2。在状态s下的最优动作为立即回报r(s,a)加上V*值时a的最大动作,即
π*(s)=arg max[r(s,a)+γV*(δ(s,a))]
(1)
Q-学习算法[3]作为智能学习中的分支,是一种无模型学习,该学习过程采用增量学习的马尔可夫决策的变化形式,其主要依据是学习各个状态-动作对的评价值Q(s,a)。Q(s,a)为从状态s开始到执行动作a的过程中累计获得的回报值。将Q(s,a)值定义为最大的折算累积回报值,也就是说Q的值是从状态s开始执行到动作a后,立即回报值遵循最优策略值,用γ对其进行折算,则该最优值数学表达式可表示为
Q(s,a)=r(s,a)+γV*(δ(s,a))
(2)
若Q(s,a)为状态s上最优动作,则a的值应最大化,将式(2)代入式(1)中,则可得出
π*(s)=arg maxQ(s,a)
(3)
从式(3)中可以看出,当智能学习Q函数在缺少函数r和函数δ的相关知识时,仍可以选择出最优动作,由此可以证明在学习的过程中,只需关注状态Q的局部值重复,就能够获得全局最优的动作序列,这意味着不需要进行前瞻搜索和明确从该动作中获得的状态即可选择出最优动作。在时间轴上的立即回报序列上估计训练值,可通过下式完成

(4)
用式(4)改写式(2),结果如下
Q(s,a)=r(s,a)+γmaxQ(δ(s,a),a′)
(5)
本文采用新状态s′的当前值精化前一状态s的评价值(s,a),在估计出在极限的条件下收敛到实际Q函数时,系统能够被建模成确定性的马尔可夫决策[4]过程,并且学习过程中各个动作的选择可被每个状态、动作对无限访问。当系统为非确定情况时,回报函数r(s,a)与动作函数δ(s,a)会存在概率输出,在这种情况下,函数r(s,a)和δ(s,a)可以被看作为基于状态s和动作a的输出概率分布,定义π为所有状态中能够使Vπ(s)最大化的最优策略,则Q(s,a)又可以表示为
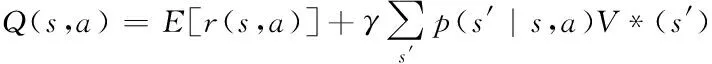
(6)
式(6)中,p(s′|s,a)表示状态s运行动作a时会产生下一状态s′的概率,将Q重新定义为递归形式,其数学表达式可以表示为

(7)
确定性的推导训练法则不能在非确定性条件下进行收敛,因此对确定性规则进行修改,使其采用当前值和修正后估计衰减值的加权平均,修改后的规则可作如下表示
Q(s,a)←Q(s,a)+α[r+γmaxQ(s′,a′)-Q(s,a)]
(8)
式(8)中,α表示学习率。Q值函数的学习是通过迭代完成的,经过一次迭代后就会更新一个Q(s,a),经过一系列迭代后,当每一个数值不再发生较为明显的变化时,即可认为Q值函数收敛,学习结束。学习与环境交互过程如图1所示。
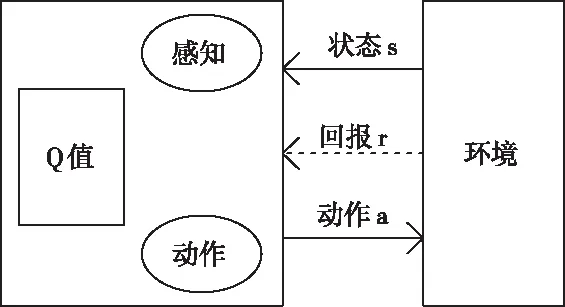
图1 学习与环境交互过程模型
2.2 数据驱动控制
以Q-学习算法为基础算法构建数据驱动控制[5]模型,其结构如图2所示。
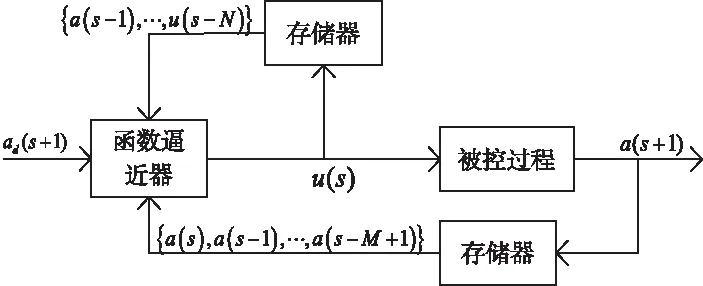
图2 基于Q-学习的控制方法
控制器为函数逼近器[6],虽然为固定结构,但是相关参数可调,如果控制器为近似Q-学习结构,则学习层的状态s和动作a是根据实际要求选定好的,而当前Q值和修正后估计衰减值的加权平均[7]就是控制器的参数θ。当Q-学习算法输入的是当前时刻固定状态的控制量和输出量[8],即下一个状态的期望输出值,则控制器的输入量数学表达式如式(9),输出量可用u(s)来表示
a(s),a(s-1),…,a(s-M+1),
u(s-1),u(s-2),…,u(s-N),ad(s+1)
(9)
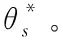
Js(θk)=E[a(θk,s+1)-ad(s+1)2]
(10)
由于被控系统的模型是未知,致使优化算法不能继续使用,因此本文利用递推式(11)来解决此问题。

(11)
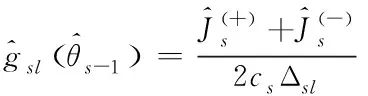
(12)
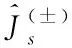
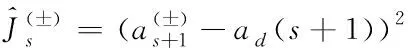
(13)

为使数据驱动控制响应时间更快,将受控系统的当前工作点处使用等价线性模型替代非线性离散系统[10],并且通过被控对象提供的数据对模型中的伪偏导函数进行评估。非线性离散系统一般可以表示为
y(k+1)=f(y(k),…,y(k-ny),u(k),…,u(k-nu))
(14)
式(14)中,y(k)表示k时刻被控系统的输出数据,u(k)表示k时刻被控系统输入数据;ny、nu表示系统未知阶数;f(·)表示未知线性函数。假设系统满足|Δy(k+1)≤b|Δu(k)||,则式(14)可以等价表示为线性化模型如式(15),且伪偏导函数是有解的。
y(k+1)=y(k)+φT(k)Δu(k)
(15)
式(15)中,φ(k)=[φ1(k)…φL(k)]T表示伪梯度向量,Δu(k)=[Δu(k)…Δ(k-G+1)]T,G表示线性水平常数,将传统的非线性模型改为上述线性化方法后,在控制的过程中完全不依赖受控系统的数学模型和先验知识。线性化后模型结构较为简单,需要确定参数变少,从而使响应时间变短。
最后使用最小化加权预测误差准则函数[11-12],可得如下数据控制方案
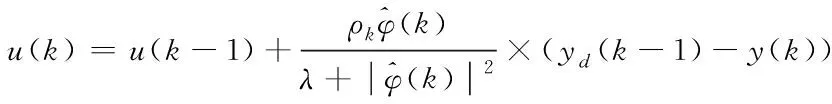
(16)
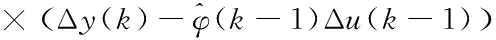
(17)
式中,ρk、ηk分别表示步长序列。控制器结构如图3所示。
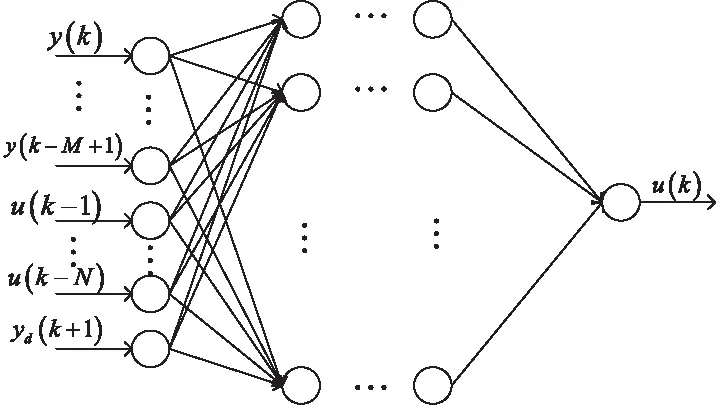
图3 控制器结构图
3 仿真研究
为验证基于近似Q-学习算法的数据驱动控制方法的有效性,引入典型的线性系统,并对其跟踪控制问题进行仿真,并与文献[1]、文献[2]方法作仿真对比。引入的线性系统数学表达式如下
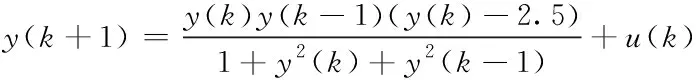
(18)
分别使用本文方法和文献[1]方法对引入系统进行了50次独立控制实验,并且对输出的误差Err进行了评估。

(19)
式(18)中,b表示运行步数。给定被控系统幅值为1的方波输入控制信号,在系统单次运行后,本文的跟踪结果如图4所示,文献[1]方法、文献[2]方法的跟踪结果分别如图5、图6所示。
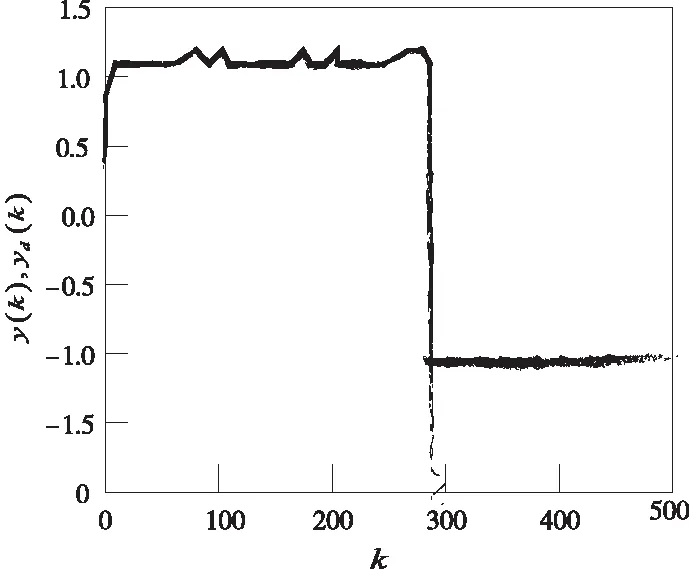
图4 本文方法对系统的跟踪控制结果

图5 文献[1]方法跟踪控制结果

图6 文献[6]方法跟踪控制结果
从图4、5、6中可以看出,文献[1]、文献[2]方法在计算每步运行控制信号的过程中,会存在扰动的问题,并且由于该方法控制器选取不当对系统的稳定性产生了影响,从而导致在控制跟踪的过程中出现异常尖峰的问题,而本文方法由于不依赖被控系统的数学模型,且用线性动态模型替代非线性模型,减少了参数的计算量,从而得到准确度更高的控制结果。
同时统计三种控制算法50次试验的平均输出误差和响应时间,其结果如表1所示。

表1 实验结果误差对比
从表1的误差结果可以看出,与文献[1]、文献[2]方法相比,本文的跟踪误差更小,响应时间更短。
通过以上仿真比较证明本文方法的结果准确度要优于传统方法,进一步证明了本文基于近似Q-学习算法的数据驱动控制的有效性,具有一定的实际应用价值。
4 结论
本文方法的控制律不依赖受控系统的数学模型结构,仅利用Q-学习算法的迭代学习,在实际操作过程中,又仅有一个伪偏导数作为在线调整参数,使系统的计算量较小,响应时间较短,在一定程度上解决了未建模动态的问题。仿真条件下证明了本文方法获得的控制结果误差较小,具有一定的可行性。
本文提出数据驱动控制方法采用以近似Q-学习算法为结构的控制器,Q-学习算法最终获得的值可能不是最优,如何根据受控系统特性精准的在从学习状态开始到执行动作的过程中获得最优回报值,是下一步需要改善的问题。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
中国自行车(2022年3期)2022-06-30
英语文摘(2022年4期)2022-06-05
汽车实用技术(2022年7期)2022-04-20
当代陕西(2019年8期)2019-05-09
领导文萃(2019年8期)2019-04-19
网络空间安全(2019年8期)2019-03-18
读友·少年文学(清雅版)(2018年12期)2018-04-04
电脑爱好者(2015年3期)2015-09-10
中学生数理化·八年级物理人教版(2014年2期)2014-04-02
