
基于支持向量机的风电机组故障预测
2022-06-14 10:03李森娟岳大为王秋富
计算机仿真 2022年5期
李森娟,张 萍,岳大为,王秋富
(河北工业大学人工智能与数据科学学院,天津 300130)
1 引言
风电机组通常地处气候恶劣的海上、丘陵等地区,受到地理位置、天气、时间等多种因素的限制,其定期维护和故障检修的成本较高,约占整个风电行业生产总值的10%~15%,而海上风电机组更是达到了20%~35%[1-3]。为了使风能成为更经济的能源来源,需要最大限度地提高风电场的经济效益,对于风电场来说降低运行和维护成本是至关重要的。风电场SCADA系统实现对运行设备的监视、数据采集以及报警等功能,了解机组的运行状态,及时发现故障并提前对相关故障进行处理,从而提高运营效率,降低运维成本[4-5]。
利用振动信号对风电机组进行故障预测时主要针对风电机组中的发电机、齿轮箱、塔筒等机械传动与支撑部件,通过振动特征量的时频域分析方法可以获取相关部件的劣化程度[6]。同样考虑到风电机组在运行过程中受到风速、温度、机械等不确定性因素的影响,风电机组的振动特征容易受到各种噪声的干扰,近年来,利用SCADA数据进行风电机组的故障预测研究越来越多。文献[7]对SCADA数据预处理(4分位法剔除异常数据等),对齿轮箱特征因素进行相关性分析,利用统计过程控制原理(Statistical Process Control,SPC)分析残差,最终对齿轮箱的异常状态进行预测。但是,此模型在风电机组齿轮箱正常工作状态下才具有较高的预测精度,而且没有推广到整机的状态评估。文献[8]采用基于互信息的动态特征矩阵描述风电机组的动态特性,通过加权k近邻同时考虑动态特征矩阵中的特征贡献率与累计互信息的影响,利用动态阈值计算降低运行状态突变造成的误报。但是所提方法只是对变桨系统能够准确进行故障信息的检测。文献[9]根据风力发电机正常运行时采集的SCADA数据,利用非线性状态估计技术(Nonlinear State Eatimation Technique,NSET)建立了齿轮箱振动、发电机振动和主轴承振动三种振动模型,帮助检测早期故障。文献[10]基于模糊粗糙集理论建立变桨系统特征参数约简的数学模型,再利用实际运行数据训练经粒子群优化的支持向量机,从而获得高精度诊断模型,对变桨角度故障进行诊断实验。在这些故障诊断和预测模型研究中,仅以风电机组主要部件作为研究对象,并没有对整机进行分析。综上所述,本文选取关键特征参数建立故障诊断模型,进而对风电机组进行故障预测具有重要意义。
2 基于网格搜索的支持向量机算法
2.1 SVM模型
SVM是一类线性分类器,通过构造分隔超平面,将样本数据分为两个类别[11]。对于线性不可分的样本数据,SVM通过将原始数据映射到更高的维度,从而使其线性可分。假设样本数据表示如下
(x1,y1),(x2,y2),…,(xi,yi)
xi∈Rn,yi∈{-1,1}
i=1,2,…,l
(1)
式中:xi和yi分别为样本空间向量和类别标志;R为训练样本总数;n为样本空间维数。分类超平面为w·x+b=0,如图1所示,其中R1和R2分别为x的第一维和第二维的取值;w为最优超平面的法向量;b为偏置。
以线性可分的情况为例进行分析,将最优超平面的求解问题转化为约束优化问题,见式(2)
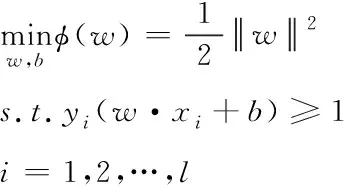
(2)
对式(2)进行求解,把构建最优超平面的问题转化为对偶二次规划问题,结果见式(3)。

s.t.0≤ai≤C
ai≥0;i=1,2,…
(3)
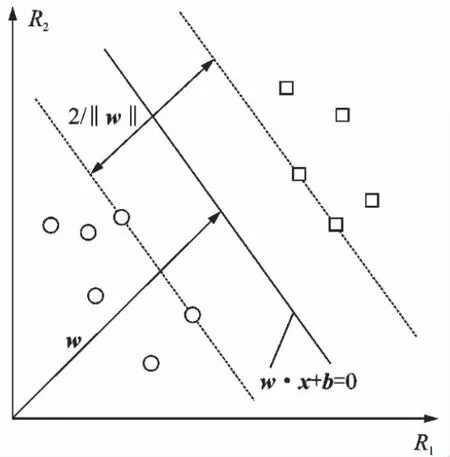
图1 最佳超平面
最终的最优分类面函数表示为
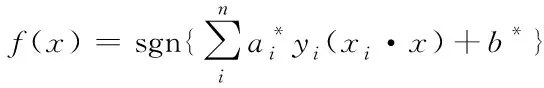
(4)
2.2 K折交叉验证
模型的参数选择是影响模型应用效果的重要因素,为了避免模型过拟合从而提高模型对于测试集数据的预测精度,也就是模型的泛化能力,因此,常用K折交叉验证(K-fold Cross Validation)方法评价模型的泛化能力。K折交叉验证方法将数据集等比例划分成K份,以其中K-1份数据训练,剩余一份数据验证得到精度指标,如此训练K次并取各次指标的平均值作为交叉验证模型的指标[12]。
2.3 网格搜索算法
网格搜索也叫穷举搜索,即遍历整个训练数据集。该方法通过遍历给定的参数组合对所需训练的模型进行优化[13-14]。使用网格搜索算法寻找模型最佳参数可以防止模型过拟合或欠拟合。网格搜索算法在实际应用的过程中一般需要配合分类算法进行使用,目的是对分类算法的参数进行寻优。
3 数据处理
3.1 数据描述
风电场SCADA系统能对风电机组功能进行现场或远程控制,并通过收集数据,对风电机组的运行情况进行分析和报告。文中的数据来自一台3MW的直驱式风电机组,从风电机组SCADA系统采集到三个独立的数据集:“运行”数据、“状态”数据和“警告”数据,包含从2014年5月至2015年4月,共11个月的数据,每隔十分钟采集一次。
1)运行数据:风电机组控制系统监控许多瞬时参数、功率特性、电气设备中的各种电流和电压、以及发电机轴承和转子等部件的温度。采集这些数据10分钟的平均值、最小值和最大值,将其存储在具有相应时间戳的SCADA系统中,部分数据如表1所示。该数据用于训练分类器,并根据过滤器进行标记,初始运行数据包含大约45000个数据点。

表1 10min运行数据
2)状态数据:风电机组有许多正常运行状态。当风电机组处于异常或故障运行时,也有大量的状态。这些都是由状态信息记录,包含在“状态”数据中。状态数据被分成两个不同的组:Wind Energy Conversion(WEC)状态数据和Remote Terminal Unit(RTU)状态数据。WEC状态数据对应于与风电机组本身直接相关的状态信息,而RTU状态数据对应于与电网连接点处的功率控制数据,即有功和无功功率设定点。每次WEC或RTU状态改变时,都会生成一个新的带时间戳的状态信息。因此,直到产生下一个状态信息前,认为风电机组在一个状态下运行。每个风电机组状态都有与之相关的“主状态”和“子状态”代码。WEC状态信息部分数据示例如表2所示。RTU状态数据几乎只处理有功或无功功率设定值。
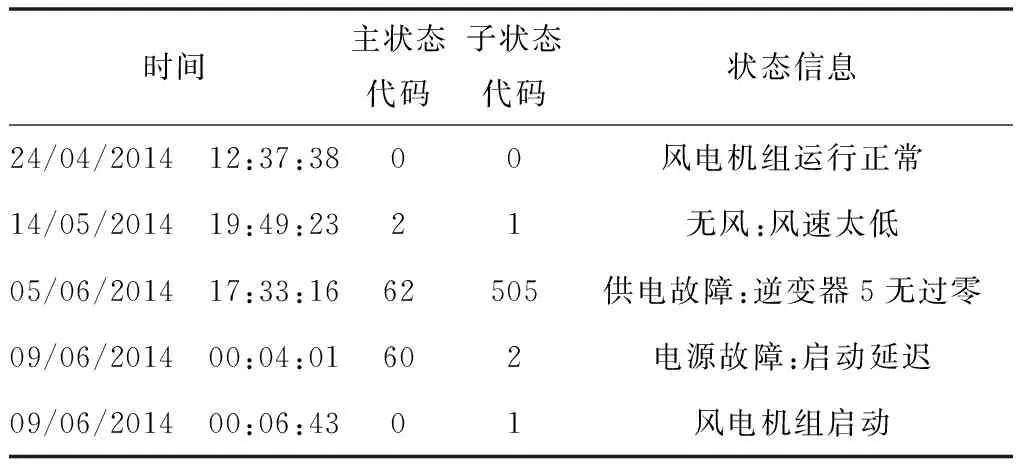
表2 WEC状态数据
3)警告数据:风电机组上的“警告”数据大多对应于风电机组的一般信息,通常与风电机组运行或安全没有直接关系,如表3所示。这些“警告”信息以与状态信息相同的方式标记时间戳。有时,警告信息对应于风电机组上潜在的发展中的故障;如果警告持续一定的时间,并且没有被风电机组操作员或控制系统清除,就会产生故障并且生成新的状态信息。因此,在分析中可以忽略警告消息,因为信息是由状态信息捕获的。
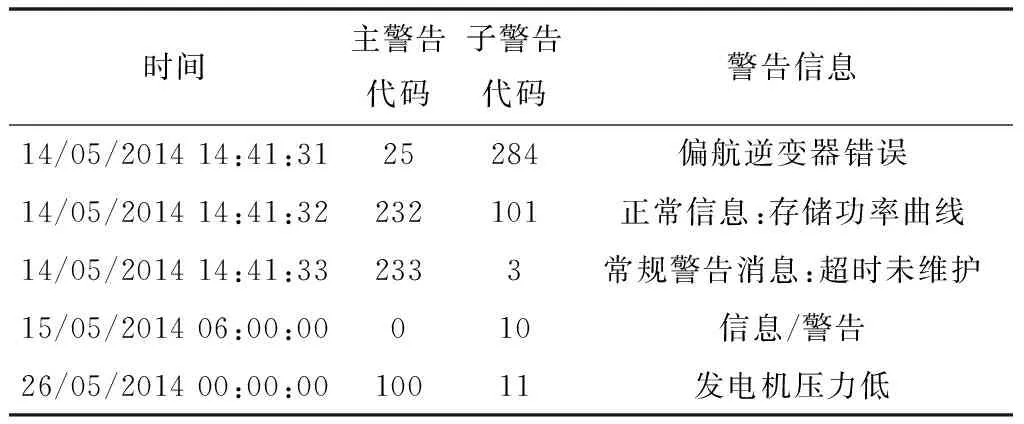
表3 WEC警告数据
3.2 数据标签
为了准确地训练分类器,正确地标记数据是很重要的。在文中,使用三个类型的分类:故障/无故障:样本被分类为故障或无故障;故障诊断:样本被分类为特定故障或无故障;以及故障预测,也就是在故障发生前一小时将数据分类为特定故障。这是通过将初始运行数据分成标记的“无故障”、“所有故障”、“特定故障”和“故障预测”数据集来实现的。接下来解释了标记数据的过程。
无故障数据集:对于三个类型的分类,需要一个通用的“无故障”数据集,包括标明的无故障操作。为了实现这一点,对完整的10分钟操作数据进行筛选。首先,选择对应于标明操作的WEC状态代码,这些代码是“0 : 0——运行中的风电机组”、“2 : 1——风速过低”和“3 : 12——风速过高”。接下来,过滤掉与功率输出被削减的RTU状态相对应的所有操作数据。此时,仅留下一个状态,“0 : 0——RTU正在运行”。最后,过滤掉对应于单个特定警告消息的数据(主警告代码“230——功率限制(10h)”)。经过以上三个阶段的筛选,无故障数据包含大约28000个点的10分钟运行数据。

图2 功率曲线
风电机组的功率和风速之间理想的关系如图2所示,显示了在轮毂高度风速的风电机组功率输出。为了验证“无故障”数据集中仅包括风电机组处于正常运行时的数据,绘制了过滤数据的功率曲线,以检查其是否符合标准形状,如图3所示,利用文献[15]所述的一种滤除功率曲线异常的算法标示正常操作的估计界限之外的数据点。图中所有数据点显示了在不进行任何过滤之前从操作数据产生的功率曲线,红色的点是算法标记为异常的点,大约有4000个这样的点。黑色的点显示了筛选的无故障数据集,经过三步筛选过程后,仍然有大约400个点,算法将其识别为异常。由于这些数据在整个无故障数据集中所占的比例不到1%,而且在实际中,风电机组数据总是包含噪声,因此决定将这些数据包含在无故障数据中。

图3 标记的功率曲线
所有故障数据集:为了对故障/无故障数据进行分类,还需要生成一组标记的故障数据。为此,列出了经常发生的故障,对于这些故障,选择了带有与故障对应的代码的状态信息。接下来,使用风电机组状态开始之前600秒和结束之后600秒的时间戳来对应相关的10分钟运行数据。表4总结了包括的故障,其中,故障频率指的是每个故障的具体实例,而不是与其相关联的运行数据的数据点的数量。电缆故障指的是风电机组的供电电缆故障,励磁故障指的是发电机励磁系统的故障,电源故障指的是风电机组的供电电源故障,冷却故障指的是风电机组的空气循环和内部温度循环故障,发电机故障指的是发电机温度过高。
特定故障数据集:对于特定故障与所有故障使用相同的方法,但这次对表4中的每个故障代码使用单一状态代码。同样,每个故障状态开始之前600秒和结束之后600秒的时间戳用于对应相应的10分钟运行数据。
故障预测数据集:为了预测特定的故障,故障分类的时间戳被扩展到不同的时间段,分别取自特定故障前的10、20、30、60、120和360分钟。这意味着导致特定故障的运行数据点也包含在该故障类别中。

表4 常见故障
4 实验结果与分析
数据集被随机打乱,分成训练集和测试集,其中80%用于训练,其余20%用于测试。因为原始操作数据集有60多个要素,所以仅选择了30个特定要素的子集用于训练。分析数据发现许多原始特征对应于风电机组上损坏的传感器,例如,它们包含结冰或明显不正确的值。然后,选择最相关的剩余特征进行训练。这些特征的一个子集,对应于风电机组中逆变器柜上的12个温度传感器,都具有非常相似的读数。因此,决定将这些数据合并,并使用12个逆变器温度的平均值和标准差,最终使用29个特征训练支持向量机。因为一些特征,例如功率输出具有从0到几千的巨大范围,而其它特征,例如温度,范围仅仅从0到几十,因此对所有数据都进行归一化处理,如式(5)所示
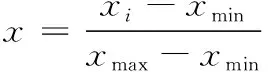
(5)
其中,xmin为样本数据的最小值,xmax为样本数据的最大值。
对用于训练每个SVM的多个超参数进行参数网格搜索,以找到产生最佳结果的超参数。然后使用10折交叉验证对这些超参数进行验证。用于交叉验证的评分标准是召回率的平均值。搜索的超参数是C:对损失值的惩罚系数,即相对误差的宽容度;γ:定义了一个单独的训练例子以及使用的核有多大的影响。四种核函数分别是简单线性核、径向基(高斯)核、多项式核、Sigmoid核。参数选择如表5所示。

表5 网格搜索中的超参数
原始数据严重失衡——无故障样本比故障类样本多一百多个,因此,使用SMOTE算法来减轻数据不平衡的影响。
模型的预测准确率一直是用来评估模型性能优劣的一种量化指标,而在文章中,风电机组的故障数据远远少于其健康数据,仅以预测准确率作为模型优劣的评判标准可能使得评估结果存在一定偏差。因此,文章使用混淆矩阵作为评判指标来衡量模型的预测效果。混淆矩阵是一个简单的方阵,用于展示分类器的预测结果——真正、真负、假正、假负的数量。对于类别数量不均衡的分类问题来说,文中采用准确率(Accuracy)、召回率(Recall)和F1 score作为性能指标。F1 score为精确率(Precision)和召回率的调和平均值。
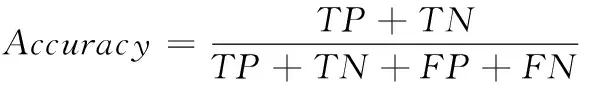
(6)
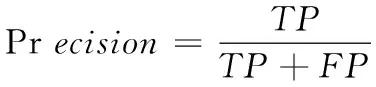
(7)

(8)

(9)
式中,TP是真正性(即正确预测的故障样本)的数量,FP是假正性,FN是假负性(即错误标记为无故障的故障样本),TN是真负性。P代表Precision,R代表Recall。F1 score的取值范围从0到1,1代表模型的输出最好,0代表模型的输出结果最差。
在表6中可以看到平衡训练集情况下的超参数搜索的结果。
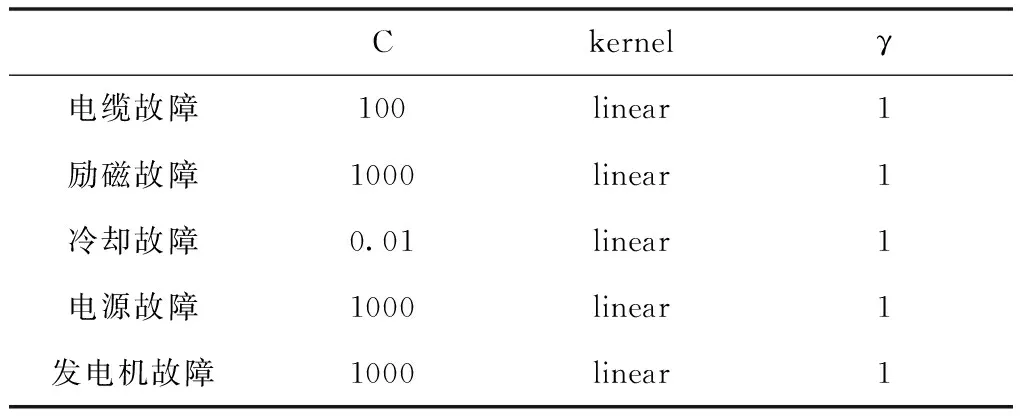
表6 网格搜索中的超参数
当在平衡集上训练数据时,得到的混淆矩阵如图4所示,图中颜色的深浅代表了各个区域分布数量的多少。由混淆矩阵得到的结果可以计算得到表7,对所有故障集预测在准确率和召回率方面的性能相当高(分别为85%和95%)。高召回率意味着很少有遗漏的故障实例。然而,SVM精确率比较低,因此,F1不是很高。

图4 混淆矩阵结果
对于在平衡集上训练的特定故障集的预测,结果类似于所有故障集情况,除了在冷却故障上显示出非常差的全面性能。预测发电机故障显示出最好的结果,精确率为87%,远高于其它任何一项,召回率为100%,准确率为99%,以及0.93的F1 score。在很大程度上,精确率和召回率之间的权衡与故障/无故障集是一样的。然而,在发电机故障的预测中看到了非常好的性能。

表7 模型的评估报告
当特定故障前的时间段从10分钟延长到1小时时,在准确率和召回率方面仍显示出良好的结果,结果见表8。
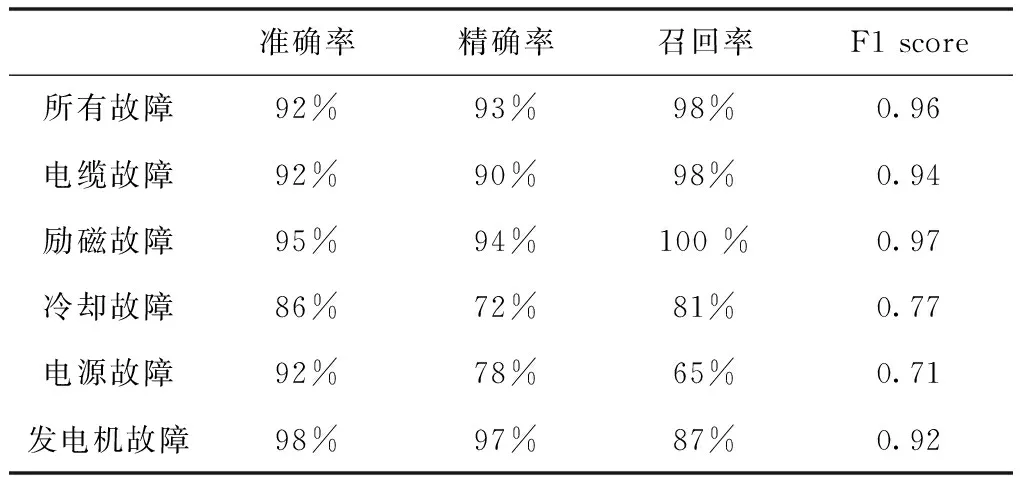
表8 模型的评估报告
5 结论
文中考虑算法筛选特征导致解释性差的特点,从风电机组特性出发,最终选择29个特征,对故障进行三个类型的分类:区分故障/无故障运行,对特定故障进行分类,以及提前一小时预测特定故障,通过对SVM模型进行优化,得到一个效果更好的模型并选择合适的评价指标对得到的模型进行评估。结果表明,一小时的预测结果在各个数据集上显示出良好的结果,通过实时传输风电机组SCADA数据,能够实现故障的在线监测,并及时安排维修人员排故,避免非计划维修,在一定程度上实现风电机组的视情维修。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
电子乐园·下旬刊(2022年5期)2022-05-13
中国核电(2021年3期)2021-08-13
科学导报(2020年50期)2020-09-09
海峡姐妹(2020年8期)2020-08-25
领导文萃(2019年8期)2019-04-19
伙伴(2018年7期)2018-05-14
读友·少年文学(清雅版)(2018年12期)2018-04-04
能源(2014年10期)2014-10-30
中学生数理化·八年级物理人教版(2014年2期)2014-04-02
