
基于FPGA的人体行为识别系统的设计
2022-06-11 02:55吴宇航何军
南京信息工程大学学报 2022年3期
吴宇航 何军
0 引言
人体行为识别(Human Activity Recognition,HAR)[1]是人工智能和模式识别[2]的重点研究方向之一,广泛应用于智能家居[3]、老人护理[4]和轨迹追踪[5]等领域.当前基于人体行为识别的研究方法主要分为基于计算机视觉[6]和基于可穿戴传感器[7]两大类.基于计算机视觉的研究方法是通过外部设备采集的图像、视频等信息进行检测识别,该方法存在功耗高、可持续性差、无法应用于非固定场景等不足.基于可穿戴传感器的研究方法是通过收集智能移动设备上的传感器数据实现行为识别[8],虽然相比于前一种解决方案,该方法使用便捷、抗干扰能力强,可以应对不同的使用场景,但推断计算过程大多基于云端或者CPU,功耗高、延时大.而FPGA以其强大的并行计算能力、灵活的可配置性和超低功耗,是边缘端理想的计算平台.
可穿戴传感器采集的大多为序列数据,当前,主要以基于循环神经网络(RNN)[9]和卷积神经网络(CNN)的模型对序列数据进行预测和识别.虽然基于RNN的识别模型的精度略高于基于CNN的模型精度,但是RNN模型的循环性质和数据依赖特性,使得该模型的运算难以在硬件上实现高度并行化,从而导致在边缘端硬件平台计算效率低,而CNN的优势在于可以实现更高的并行度,计算性能高,适合部署在FPGA上,因此本文选用基于CNN的模型作为系统的识别模型.
目前已经有许多研究人员开展关于使用FPGA 实现CNN加速的研究[10-11].文献[12-13]使用了流水线和循环展开等方法优化卷积计算过程;文献[14]提出了参数化架构设计并在卷积运算中四个维度方向实现了并行化计算;文献[15]提出了层间计算融合的模式以减少片内外的数据传输带来的时间消耗;文献[16]设计出基于CPU-FPGA的软硬件协同系统来加速CNN网络计算.上述方法通过提高计算单元的利用率、提升卷积计算并行度和优化系统与内存之间数据传输等途径,实现加速器计算性能的提升.本文使用直接内存读取(Direct Memory Access,DMA)进行高速数据传输,同时使用定点化[17-18]、多通道并行和流水线等方法提升计算效率,最后在PYNQ框架下进行软硬件协同处理并输出识别结果.实验结果表明,在识别准确率达到91.80%的情况下,系统的计算性能高于CPU,功耗仅为CPU的1/10,能耗比相对于GPU提升了91%.
1 HAR-CNN模型的搭建和训练
1.1 HAR-CNN模型的搭建与训练
人体行为识别模型如图1所示.HAR-CNN识别模型由1个输入层、4个卷积层、2个池化层、2个全连接层和1个Softmax层组成,Softmax层用于输出识别结果.选用RELU作为激活函数引入非线性.表1给出了各级卷积层和全连接层的权重参数个数以及各层的计算次数.从表1中可知模型中绝大部分计算都集中于卷积层,因此对于卷积计算的加速很有必要.
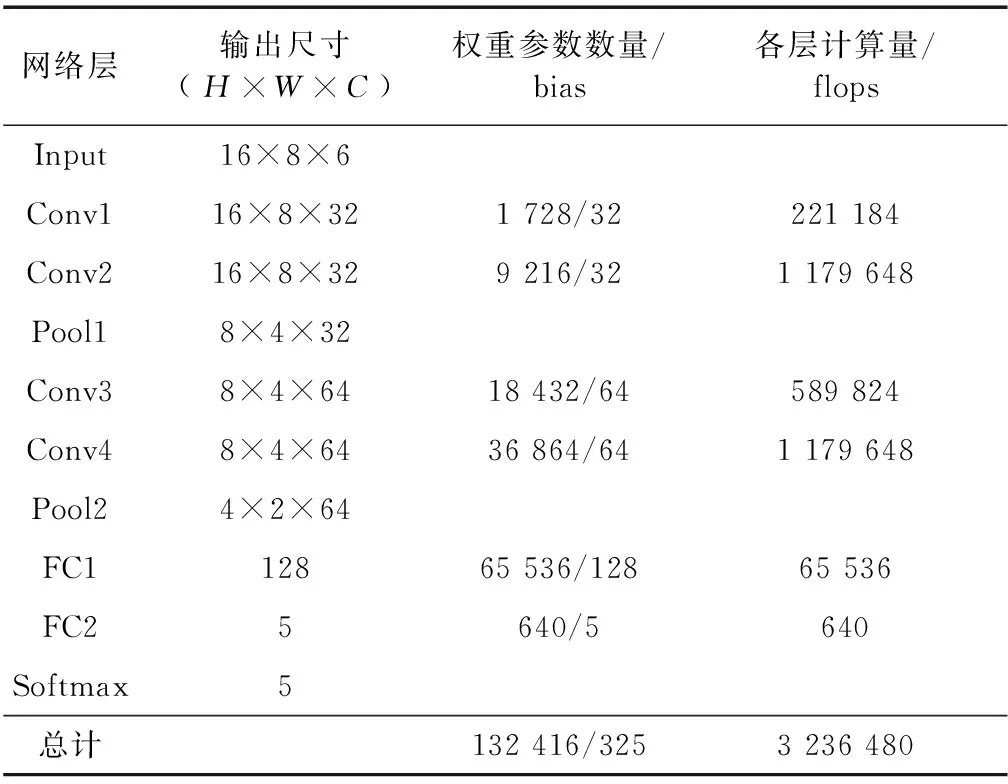
表1 各级参数量
1.2 定点化处理
通常,在CPU或是GPU上训练的模型参数类型均为浮点数,而FPGA仅支持定点数计算,因此本文首先对权重数据和特征数据进行定点化处理:一方面使用低精度的定点数(16 bit、8 bit)来取代浮点数,模型准确率的下降可以控制在预期范围之内;另一方面,定点数计算会节约大量的BRAM存储资源和DSP计算资源,减少数据的传输时间从而提升计算效率.
卷积计算的核心是乘累加操作,假设输入数据为一个单通道的二维矩阵,卷积核尺寸为3×3,则第2层中第i行第j列的特征值可以用式(1)计算:
fi,j=b+w00pi-1,j-1+w01pi-1,j+w02pi-1,j+1+
w10pi,j-1+w11pi,j+w12pi,j+1+w20pi+1,j-1+
w21pi+1,j+w22pi+1,j+1.
(1)
权重W和偏置项b是已知的,可以计算得出每一层特征图和权重参数的最大值(hx)和最小值(hn),取h=max(|hx|,|hn|),取整数点位为大于以2为底,h的对数的最小整数加1,其中第1位为符号位.假设权重参数的最大值和最小值分别为7.8、-8.1,则h为8.1,大于以2为底,h的对数的最小整数为4,加上一位符号位,整数点位数为第5位.取n位定点数取代32位浮点数计算,n减去整数点数为小数点数位,浮点数剩余(32-n)的位数由四舍五入法舍去.
由于不同卷积层的权重参数处于动态范围,故本文采用动态指数量化的方式对每层权重参数进行定点化.每个网络层的输入特征矩阵参数、输出特征矩阵参数和权重参数分别根据上文方法确定整数位和小数位.
卷积计算采用定点化后的CNN模型,对每层的输入特征矩阵和权重参数进行乘累加操作,计算结果根据每层的量化尺度进行量化,然后进行下一层的运算,以此延续完成整个卷积计算过程.
由于使用DMA搬运的数据位宽必须为8的整数倍,考虑到模型识别精度和定点资源消耗的情况,选用8 bit、16 bit和32 bit的数据位宽作为模型运算的数据精度,并对比不同数据位宽的模型精度和计算性能.
2 HAR-CNN硬件设计
2.1 系统架构
人体行为识别软硬件协同加速系统整体框架如图2所示,整个系统设计由采集并制作数据集、模型训练及优化、IP核设计、FPGA验证以及终端显示等模块组成.模型开发阶段,对识别模型进行训练和优化,并将量化后的权重参数和传感器数据存入SD卡.模型验证阶段,首先设计出卷积和池化IP核,并采取流水线和并行化处理等方法进行加速计算,最后在PYNQ框架中的PS(Processing System)端使用高级语言映射CNN模型,对输入的传感器数据进行识别.
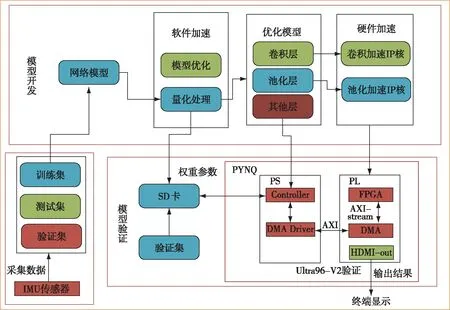
图2 软硬件协同加速系统设计框图Fig.2 System architecture of hardware & software co-acceleration
传感器采集到的数据首先传入PS端数据预处理模块,经过降噪、标准化处理后将数据传入PL(Programmable Logic)端硬件加速模块,PS端 CPU负责根据模型运算的过程分别调用卷积核和池化核进行计算.经过模型计算后的识别结果通过HDMI-out接口输出到终端显示.
2.2 硬件设计
CNN加速器的运行架构如图3所示.卷积模块和池化模块分别负责运算模型中的卷积计算和池化计算.PS端的CPU控制端负责控制调用计算模块并配置计算参数.DMA模块负责数据在内部存储器和外部双倍速率同步动态随机存储器(Double Data Rate,DDR)之间的传输.CPU通过控制信号调用卷积模块和池化模块再进行不同的排列组合可以实现不同网络的卷积神经网络模型.本文设计的IP核都是复用的,通过对计算参数的配置,可以支持不同尺寸、不同模式下的卷积运算.卷积启动信号启动卷积计算之后,此时特征图数据和权重数据存入到片上存储中,经过卷积和RELU计算后,将计算结果通过DMA传回外部存储器.池化启动信号负责将经过卷积和RELU计算后的特征信号进行池化计算,计算结果最终存入外部空间.
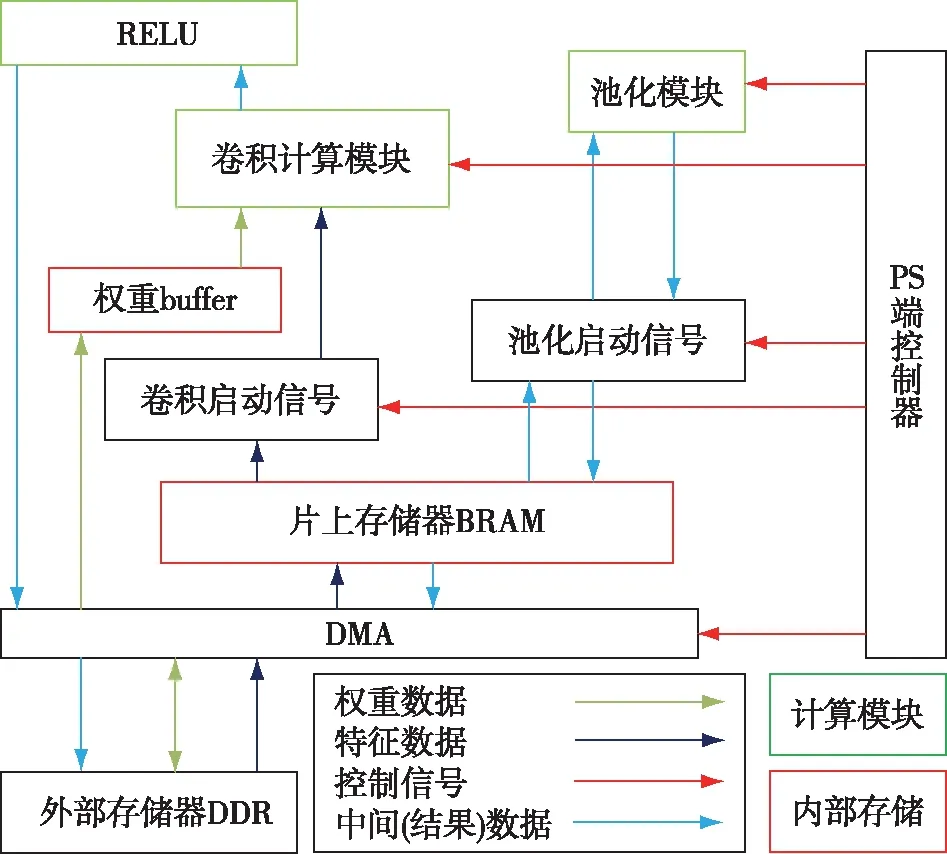
图3 加速计算架构Fig.3 Accelerator’s computing architecture
加速计算架构的运算流程如下:
1)PYNQ框架下,CPU在外部存储器DDR上开辟空间,将量化后的权重参数从SD卡存入到FPGA中的DDR中.
2)PS端CPU启动加速器之后,首先通过S-AXI接口将计算参数和控制信号写入随机存取存储器RAM中,然后DMA将特征数据搬运到片上BRAM中,将权重数据搬运到权重buffer.
3)卷积运算模块得到指令后,同时获取权重数据和特征图数据,并且进行卷积和RELU计算,计算后的结果存入片上BRAM中,最后通过DMA存入DDR中.
4)池化运算模块得到指令后,将经过卷积模块计算后的特征图数据根据CPU配置的池化参数进行计算,将计算中间数据存入BRAM中,将最终结果直接通过DMA传入到DDR中.
5)根据模型设计,重复执行上述3)和4),直到完成整个推断过程,将最终的识别结果通过HDMI输出到终端显示.
2.3 卷积加速设计
卷积运算模块如图4所示.受限于硬件资源,本文使用HLS设计了2个处理单元(PE),并使用Dataflow约束条件使2个PE模块并行计算.PE模块主要负责卷积的乘加运算,并将计算结果储存到BRAM中.
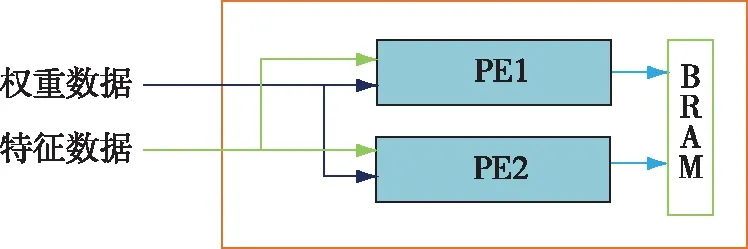
图4 卷积运算模块Fig.4 Convolution operation module
PE模块核心计算单元的设计如图5所示,PE模块内部都开辟了缓存用来存储权重数据,模块内具体的计算流程如下:取N个对应的位宽为16 bit的特征数据和权重参数,将对应的N个数据相乘,再将相乘的N个结果累加.
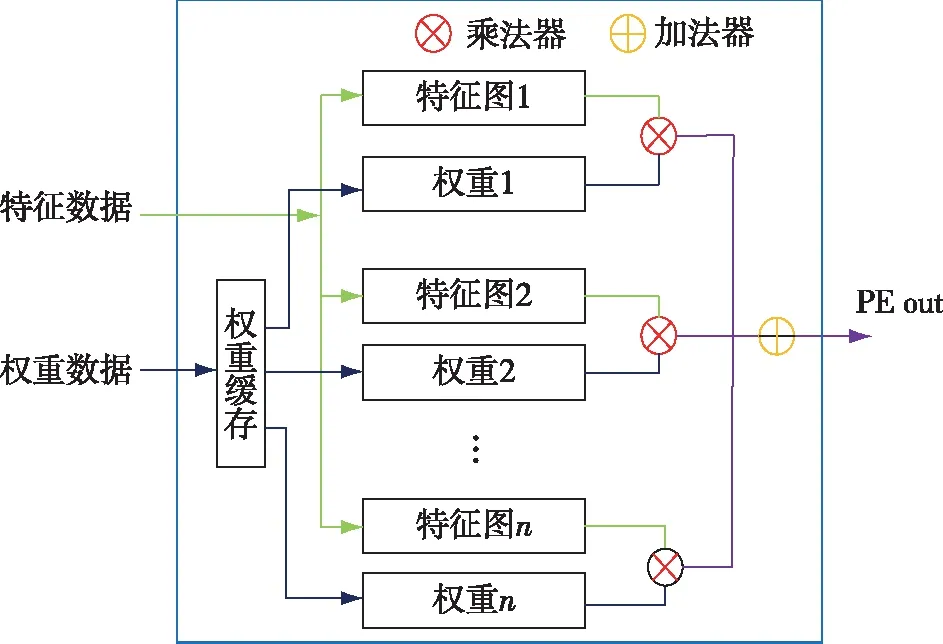
图5 PE模块核心计算单元Fig.5 PE module core computing unit
2.4 卷积并行计算
卷积计算是CNN模型中最大的计算部分,为了提升卷积计算的运算效率,本设计采取了多channel和多filter并行的方法进行加速计算.具体过程如图6所示.图6中输入特征图尺寸为Hin×Win,卷积核尺寸为Kx×Ky,输入通道为CHin,卷积核个数为K,N为通道并行度.
多channel并行是将特征图和每个权重数据沿着输入方向切成多个子块,每个子块的输入通道维度均为N,分别从特征图子块和权重子块中取出N个对应的数据进行计算.多filter并行是将输入权重和多个卷积核同时进行计算.图6为子块进行卷积运算的流程,具体的计算流程如下:
1)如图6a所示,2个PE单元同时取出特征图和2个卷积核的N个通道方向上的第1个数据,将分别取出的对应数据相乘,然后在通道方向上累加,输出结果.
2)如图6b所示,PE模块中的权重不变,滑动特征图,使得权重N个通道上第1个数据与部分特征图数据相乘并在通道方向上累加.
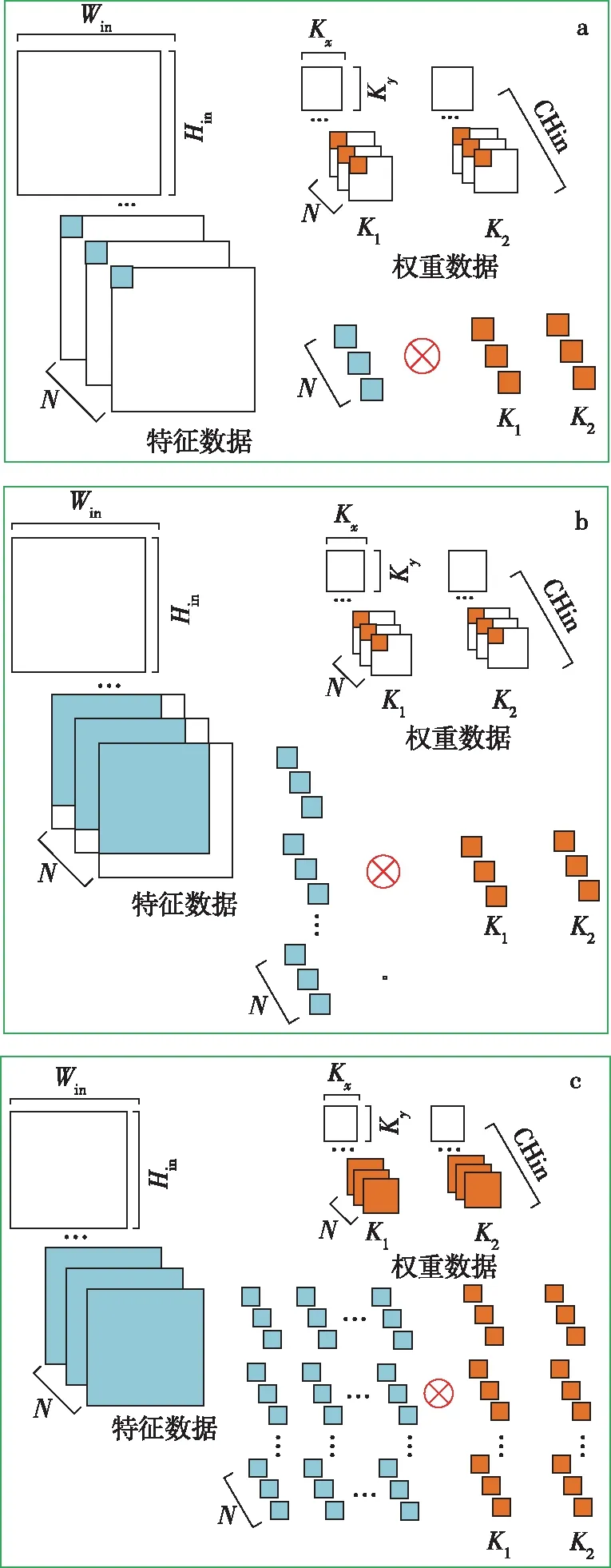
图6 卷积计算流程Fig.6 Convolution operation process
3)如图6c所示,改变PE中的权重数据,使得计算可以覆盖子块的全部特征数据和权重数据,得到N个通道上3×3卷积核所有数据与整幅特征图计算中,完成与3×3卷积核9个权重数据相对应的特征图相乘并在通道方向累加的结果.
4)沿通道方向取出下一个N通道子块重复上述计算,将最终得到的结果累加输出特征图.
为了验证卷积加速设计的有效性,选取N分别为16、32、64时进行多通道加速设计,并与未加速的设计进行比较.本文选取数据位宽为16 bit,尺寸为32×32×64输入特征数据和尺寸为64×3×3×64的权重数据进行卷积计算,加速对比如表2所示.表2中的实验都进行了定点化和流水线优化,但对比实验未进行多channel并行和多filter并行设计加速.实验结果表明,最优设计(本设计)的计算性能是未进行多channel并行和多filter并行加速设计的95.46倍.
为了验证量化设计对计算性能加速的有效性,选取数据位宽分别为8 bit、16 bit和32 bit,在PE=2,N=32的条件下进行卷积加速设计.选取和表2尺寸相同的特征数据和权重数据进行卷积计算,加速对比如表3所示.实验结果表明,数据位宽为8 bit、16 bit量化设计的计算性能分别是数据位宽为32 bit的1.38倍和1.21倍.

表2 不同卷积加速方案的性能对比
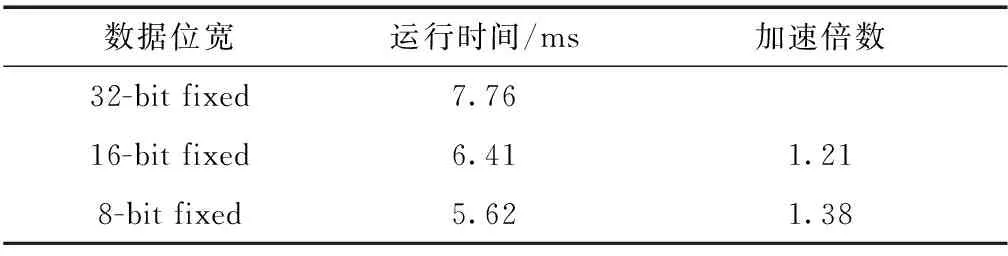
表3 不同数据位宽的卷积性能对比
2.5 池化加速设计
最大值池化计算如图7所示.将特征图沿着长度和宽度分成多个n×n的子块,在每个子块内取最大值,输出的特征图的长度和宽度分别为原特征图长度和宽度的1/n.

图7 最大值池化计算Fig.7 Maxpooling calculation
如图8所示,为了提升池化模块的计算效率,本文设计了横向池化和纵向池化两个子函数,并利用流水线并行计算得到输出结果,同时对每个子函数进行多通道并行加速.
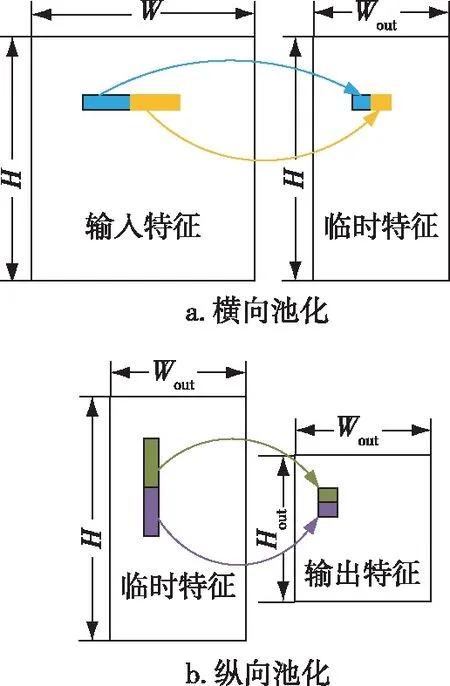
图8 池化流程Fig.8 Pooling flowchart
假设对输入特征数据进行n×n的最大值池化,步长也为n,其具体计算流程如下:
1)如图8a所示,输入特征进入横向池化模块,第1个数据寄存在寄存器中,与后续输入的n-1个数据相互比较,将最大值存在寄存器中.以输入的n个数据为一组,反复执行上述的操作,得到横向池化的结果,此时的中间数据高不变,宽度为原先宽度的1/n.
2)如图8b所示,首先将中间特征输入的前Wout个数据存入buffer中,后面输入的n-1组Wout个数据与第1组数据在对应的位置上相互比较得到最大值,输出结果.以输入的n组Wout个数据为一组,反复执行上述的操作,得到纵向池化的结果,此时输出特征的高度、宽度均分别为原先高度和宽度的1/n.
为了验证池化加速设计的有效性,选取尺寸为100×100×64输入特征数据进行最大值池化运算,在N=16的条件下进行多通道加速设计,同时应用定点化和流水线优化加速.不同的是方案1使用的传统的设计方案,方案2使用的是横向池化和纵向池化并行加速的设计方案.加速对比结果如表4所示,本文设计为传统的方案计算性能的1.91倍.
为了验证量化设计对池化计算性能加速的有效性,选取数据位宽为8 bit、16 bit和32 bit使用方案2进行卷积加速设计.选取和表4尺寸相同的特征数据和权重数据进行卷积计算,加速对比如表5所示.

表4 不同池化加速方案的性能对比

表5 不同数据位宽的池化性能对比
实验结果表明,数据位宽为8 bit、16 bit量化设计的计算性能分别是数据位宽为32 bit的1.22倍和1.12倍.
2.6 系统实现
CPU通过不断调用卷积和池化两个子函数对输入特征进行卷积计算和池化计算,最终在FPGA上搭建行为识别的CNN网络结构.利用时分复用技术,节省硬件资源开销,时分复用结构如图9所示.当人体行为数据传输到神经网络之后,卷积层L1、L2、L3、L4、L5和L6由卷积核计算,池化层分别为P1和P2,由池化核进行最大值池化计算. 另外,全连接层也使用卷积核进行计算.
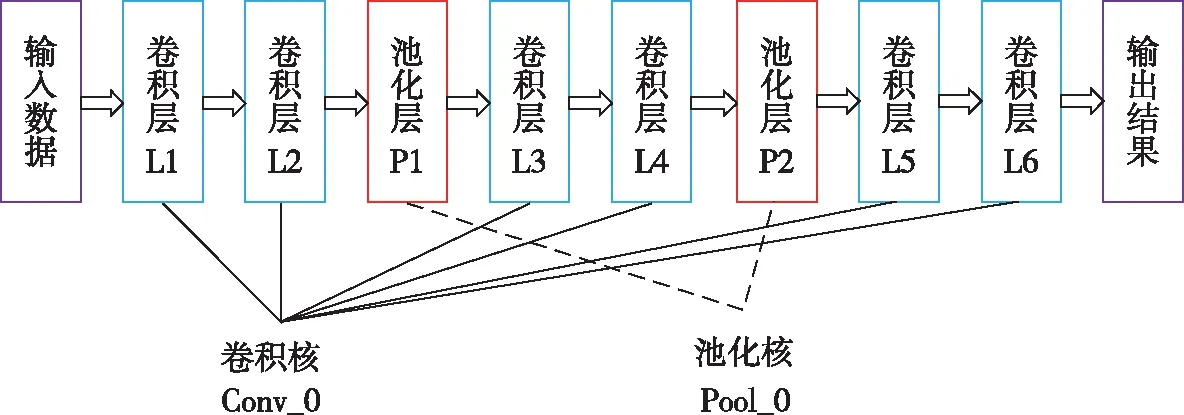
图9 时分复用技术Fig.9 Time division multiplexing technology
3 实验以及结果分析
3.1 数据集
本文使用UCI_HAR数据集和自制HAR数据集进行实验.UCI_HAR数据集可在https:∥ucihar-data-analysis.readthedocs.io/en/latest/处进行下载,自建HAR数据集可在https:∥github.com/nuisyaya/HAR_Dataset处下载,也可向本文通信作者(jhe@nuist.edu.cn)申请使用.
1)UCI_HAR数据集:为了验证模型对传感器数据进行识别的有效性,本文使用已公开的UCI_HAR 标准数据集进行验证.该数据集包括12个日常活动,即3个静态活动(站立、坐、躺)、3个动态活动(步行、上楼、下楼)和3个静态活动的转换(站坐、坐站、站躺、躺站、坐躺、躺坐).这些数据由三星智能手机记录,该智能手机使用嵌入式加速度计和陀螺仪,以50 Hz的恒定速度收集三轴线性加速度和三轴角速度.采集者利用录制视频手动标记数据,然后随机分为两组,选用70%作为训练集,30%作为测试集.应用噪声滤波器对传感器数据进行预处理之后,在2.56 s和50%重叠的固定宽度滑动窗口中采样(窗口宽度为128).如表6所示,利用这个数据集的6个活动,包括3个静态活动和3个动态活动进行实验,每条传感器数据的尺寸为128×6.

表6 UCI_HAR 数据集
2)自制HAR数据集:选取SparkFun公司的惯性测量单元(Inertial Measurement Unit,IMU)传感器采集人体行为数据制作数据集.传感器实物图如图10所示.采集的数据包括陀螺仪测量的X、Y、Z三轴的角速度,加速度计测量的X、Y、Z三轴的加速度,共6个输入通道,设置采样率为50 Hz,要求10个志愿者分别采集两组行为,共计20组,每组行为包括行走、上楼梯、下楼梯、跑步和跳跃,分别对应标签0到4.然后在2.56 s和50%重叠的固定宽度滑动窗口中采样,每条样本包括128个采样点,每条数据尺寸为128×6.表7展示5种行为样本个数统计结果.自制的HAR数据集按照7比3的比例划分为训练集和测试集.在测试集选取500个样本存入SD卡中用于FPGA端验证.

表7 各行为样本数据统计

图10 IMU传感器实物Fig.10 Picture of IMU sensor
由于传感器在数据采集过程中会由于志愿者的主观能动性产生额外的动作,使原始数据中夹杂背景噪声,因此本文在数据预处理阶段使用中值滤波对数据进行降噪处理.
模型开发阶段,使用TensorFlow深度学习框架
进行网络训练,设置学习率为0.000 1,使用Adam优化器进行优化,使用如图1所示的CNN模型架构对传统的UCI_HAR数据集和自制的数据集进行训练优化.如图11所示,本文设计的模型在传统UCI数据集上准确率为91.23%,验证了模型的可靠性.在自制的HAR数据集上准确率达到93.61%.
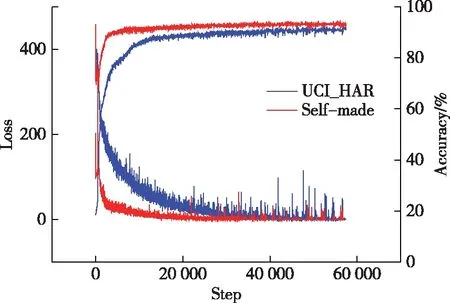
图11 模型性能曲线Fig.11 Model performance curve
3.2 实验环境
本文使用Xilinx公司的Vivado HLS进行开发.FPGA选用的是Avnet公司的Ultra96-V2,工作频率为200 MHz.实验数据类型为16位定点数.CPU采用主频为3 GHz的i7-9700处理器,GPU采用英伟达公司的GTX1080Ti显卡.
3.3 实验结果
随机选取每种行为各100条数据存入SD卡,用于验证部署在FPGA端系统的准确率.如表8所示,选取量化后数据位宽为8 bit、16 bit和32 bit的模型在FPGA端进行模型精度的验证,经过500次迭代,数据位宽为8 bit、16 bit和32 bit的模型验证准确率分别为84.40%、91.80%和93.20%.数据量化导致的精度损失,模型精度均低于软件平台准确率93.61%.考虑到资源消耗和模型精度的情况,最终选用16 bit的数据位宽作为模型运算的数据精度,同时也将其他两种精度的模型部署在FPGA上用于测试计算性能和功耗.

表8 不同数据位宽模型准确率对比
本文选取数据位宽为16 bit,N分别为16、32、64三个通道并行参数进行架构设计.FPGA硬件资源消耗如表9所示.
FPGA的资源占用率如图12所示.在数据位宽为16 bit,N分别为16、32、64的条件下,BRAM的资源占用率均为80%,DSP资源占用率分别为39%、47%和60%,触发器(Flip-Flop,FF)的占用率分别为40%、58%和78%,查找表(Look-Up-Table,LUT)占用率分别为53%、70%和99%.
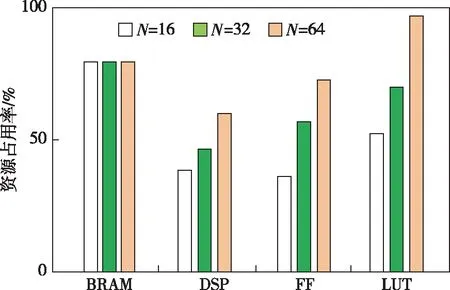
图12 FPGA资源占用率Fig.12 FPGA resource utilization
表10中列举了不同计算平台的计算性能和功耗的对比.不同设计方案之间功耗对比可由各方案的迭代一次平均耗时与功耗的乘积的倒数相除获得.从表10中可以看出,本文设计的数据位宽为16 bit、通道并行参数N=64的人体识别系统识别速度高于CPU,而功耗仅为CPU的1/10,能耗比是GPU的1.91倍.除此之外,本文还设计数据位宽为8 bit和32 bit的模型并部署在FPGA上,数据位宽为8 bit、通道并行参数N=64的系统识别速度是CPU的1.34倍,能耗比是GPU的3.02倍.实验结果表明,使用FPGA作为边缘计算平台搭建人体行为识别系统,达到了低功耗、低延时的设计要求.
4 结束语
本文设计了基于FPGA和CNN的人体行为快速识别系统.通过数据定点化,并行处理数据和流水线等方法提升计算速度.使用UCI_HAR数据集和自制的HAR数据集进行了实验,并与CPU和GPU在计算性能和功耗方面进行对比,实验结果表明,本设计在识别准确率达到91.80%的情况下,计算速度优于CPU,能耗比相比于GPU提升91%,达到了低功耗、低延时的设计要求,验证了FPGA作为边缘计算平台进行人体行为系统识别的可行性和优越性.在未来工作中,我们将进一步优化该系统,例如增加人体行为种类、识别不同行为之间的切换和改进神经网络模型等.
猜你喜欢
科学技术与工程(2023年3期)2023-03-15
计算机应用(2022年9期)2022-09-25
航空维修与工程(2022年3期)2022-04-28
软件导刊(2022年3期)2022-03-25
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
计算机技术与发展(2019年1期)2019-01-21
北京航空航天大学学报(2018年1期)2018-04-20
导航定位与授时(2017年5期)2017-09-20
