
一种基于L2正则化迁移学习的变负载工况条件下故障诊断方法
2022-06-11 07:29:14宋旭东朱大杰杨杰丛郁洋
大连交通大学学报 2022年2期
宋旭东,朱大杰,杨杰,丛郁洋
(大连交通大学 计算机与通信工程学院,辽宁 大连 116028)
目前研究人员已经开始使用深度学习方法进行机械设备故障诊断[1].深度学习解决了传统故障诊断方法存在的问题,它能直接从源域数据中提取有价值的特征,不需要再过度依赖专家对故障数据处理的经验.但是,利用常规的深度学习进行故障诊断需要满足一些前提条件,首先就是要对源数据做一个比较复杂的数据预处理,其次就是训练网络模型需要大量的故障数据.但是在变负载工况条件下,故障数据获取困难,导致故障诊断模型准确率不高、存在过拟合以及泛化能力较弱等问题.近几年,基于迁移学习的故障诊断受到了学术界的青睐,它可以将之前学习到的知识运用到当前任务当中,以此来实现对目标数据的分类.迁移学习可以不要求源域数据与目标域数据是独立同分布的,它可以减少在新任务中对所要处理的数据进行重新打标签所带来的时间以及其他经济成本.赵宇凯等将VGG16卷积神经网络和迁移学习相结合,保留了网络的低层权重,并用目标域数据对高层权重进行微调,提出了一种新的故障诊断方法[2];吴定会等将一维卷积神经网络和双向门限单元进行结合,提出了一种新的迁移学习方法[3];Wang等提出了一种基于ResNet的迁移学习方法[4];Han等将数据增强运用于卷积神经网络,提出一种新的迁移学习方法[5];胡明武提出了一种基于K近邻算法的变负载轴承故障诊断模型[6];刘布宇运用卷积神经网络进行变负载下轴承故障诊断[7].现有的基于深度学习的迁移学习方法虽然能够实现变工况下的轴承故障诊断,但是过拟合现象仍未得到很好解决,从而导致模型的泛化能力不高.
本文通过L2正则化迁移学习抑制模型过拟合,引入长短期记忆网络(Long Short-Term Memory, LSTM)进行故障诊断模型训练,最后利用少量目标域数据进行模型参数微调,最终构建基于L2正则化迁移学习的变负载工况下故障诊断模型.
1 相关技术
1.1 L2正则化迁移学习
正则化迁移学习是用来提高模型准确率,抑制过拟合,增强模型泛化能力,实现模型迁移的一种机器学习方法[8].L2正则化策略通过向目标函数添加如下正则项:
(1)
其中,w为权重参数.通过式(1)可知,L2正则化为各个权重参数的平方和.
相对其他正则化方法,L2正则化不会忽略特征,L2正则化通过对权重收缩来抑制权重过大,能获取带有更小参数的更简单的模型,所以本文选择L2正则化.
1.2 长短期记忆网络
现有深度学习方法主要包括:循环神经网络、卷积神经网络和深度置信网络.循环神经网络有着更为精细的信息传递机制,LSTM作为循环神经网络最为典型的一种网络结构,能够有效地解决大量数据长时间的依赖问题和数据序列过长导致的梯度爆炸问题,因此本文选择LSTM网络.
长短期记忆网络结构如图1所示.

图1 长短期记忆网络结构图
长短期记忆网络前向计算方法如下:

2 变工况条件下的故障诊断方法
通过引入L2正则化来达到变负载工况条件下的故障模型参数迁移,并通过采用长短期记忆网络进行故障诊断模型训练.
变工况条件下的故障诊断方法如图2所示,给出了基于L2正则化迁移学习和长短期记忆网络的变负载工况条件下的故障诊断流程,具体包括三个阶段:①模型预训练,对应流程图左侧进行的训练;②模型参数迁移;③目标域模型训练,对应流程图右侧进行的训练.

图2 变负载工况下故障诊断流程
引入L2正则化项后的故障诊断模型的目标函数可定义如下:
(8)
基于L2正则化迁移学习能够较好地抑制过拟合,具有较高的泛化能力,可通过研究正则化后目标函数的梯度观察L2正则化的表现.
目标函数对应的梯度为:
(9)
权重更新公式如下:
(10)
化简之后为:
(11)
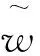
模型预训练阶段可通过在源域中加入少量目标域的数据,对模型进行长短期记忆网络预训练,之后将训练好的模型参数迁移到目标域中,目标域模型训练阶段可利用少量目标域数据,利用长短期记忆网络对模型参数进行微调,最终构建具有一定泛化能力的故障诊断模型,模型诊断结果通过Softmax进行故障分类,Softmax公式如下:
(12)
式中,yk代表第K个神经元的输出,共有n个神经元,zi代表第i个神经元的输入信号.
3 模型实验验证
本文采用美国凯斯西储大学(CWRU)的滚动轴承数据集进行实验,实验平台主要由一个1.5 kW的电动机、一个扭矩传感器/译码器、一个功率测试计以及电子控制器等设备组成.CWRU将加工过的故障轴承重新装入测试电机中,分别在0、1、2和3 HP(HP是负载的单位,即马力)的电机负载工况工作条件下记录振动加速度信号数据.
本文所用的源域数据和目标域数据均为CWRU的滚动轴承数据集,故障数据集是在采样频率为12 kHz的驱动端处产生,源域数据和目标域数据来自不同的负载,源域数据为1 HP的数据样本集,目标域数据为2 HP的数据样本集,故障的位置分为外圈故障、内圈故障以及滚动体故障,故障的直径为0.177 8、0.355 6以及0.533 4 mm.在预训练阶段,总的训练样本个数为7 000,其中源域数据样本个数为6 000, 目 标 域 样 本 个 数 为
1 000.每个样本数据点为864.
本文实验是基于Python语言,采用以TensorFlow为后端的Keras库实现,计算机硬件基本配置为i7-8750H处理器,8 GB内存,Windows系统.
3.1 L2正则化前后模型对比实验
对比引入L2正则化迁移学习前后的长短期记忆网络故障诊断模型,观察模型实验结果,实验结果如图3所示.
(a) 未加入L2正则化迁移学习
从图中可以看出,加入L2正则化迁移学习后的长短期记忆网络故障诊断模型和不加入正则化的诊断模型相比训练数据的识别精度和测试数据
的识别精度差距缩小了,而且通过增加训练次数,加入正则化后的模型在测试数据上的准确率也要高于未加入正则化的模型.通过以上实验说明加入L2正则化后过拟合受到了抑制,模型的泛化能力得到了提升.
3.2 不同抑制过拟合方法对比实验
将本文所用的L2正则化方法与其他抑制过拟合方法进行对比,实验结果如表1所示.
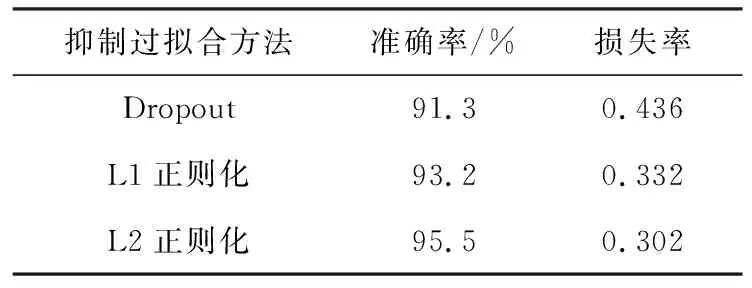
表1 不同抑制过拟合方法实验对比结果
通过表1 可知,本文运用L2正则化进行迁移学习轴承故障诊断的准确率和损失率要好于其他两种抑制过拟合的方法.
表1评价指标中的准确率是分类正确的样本数量与整组样本数量的比值,公式如下所示:
(13)
式中,n是分类正确的样本数量,N是整组样本数量.
损失率评价指标采用小批量交叉熵误差损失函数,公式如下所示:
(14)
式中,M是小批量数据的个数,pmi是正确解标签,代表的是监督数据,表示第m个数据中的第i个元素的值,ymi是神经网络的输出.
3.3 不同模型对比实验
将加入L2正则化的长短期记忆网络故障诊断模型(L2正则化LSTM)与常规深度学习模型,包括长短期记忆网络(LSTM)、门控循环单元(GRU)以及双向长短期记忆网络(Bi-LSTM)进行迁移学习模型故障诊断准确率的对比,源域数据为1 HP,目标域数据为2 HP,实验结果如表2所示.

表2 不同模型的迁移学习准确率对比结果
对于加入L2正则化的LSTM,模型的泛化能力得到了提高,过拟合得到了抑制,进而提高了模型准确率,而其他3个模型泛化能力不高且易发生过拟合,在变负载工况条件下,训练数据的识别精度和测试数据的识别精度差距会放大,所以准确率不如本文所提出的方法高.
同时,将本文所提出的诊断方法与文献[6]中的深度迁移学习的变工况下滚动轴承故障诊断方法进行对比,文献[6]中的12种变工况的诊断方法中准确率最高为92.9%,低于本文所提出方法的准确率;文献[7]中运用卷积神经网络进行变工况下的轴承故障诊断,迁移之后的准确率为81%左右,要远远低于本文所提出的方法,进一步验证了本文方法的有效性.
另外,针对不同数量的目标域样本进行模型对比实验,利用本文所提出的加入L2正则化迁移学习的长短期记忆网络故障诊断模型与前面提到的三种常规深度学习故障诊断模型进行实验对比,观察不同目标样本数下的准确率,实验结果如图4所示.

图4 不同目标样本数下的实验对比
由图4可知,在不同目标样本数下利用上述四种网络模型进行迁移学习轴承故障诊断的准确率整体呈上升趋势,并且本文所提出的加入L2正则化迁移学习的长短期记忆网络故障诊断模型的准确率要明显高于其他三种,进一步验证了本文所提方法的有效性.
4 结论
本文通过引入L2正则化来抑制模型过拟合、提升模型的泛化能力,进而实现模型参数迁移目的.针对变负载工况条件下的故障诊断应用需求,提出的一种基于L2正则化迁移学习的故障诊断方法,通过模型实验验证了所提出的方法对变负载工况条件下的故障诊断具有较高的准确性,具有较好的抑制过拟合和模型泛化能力.提出的方法能够很好地应用于机械设备故障数据量少、故障数据难以获取等实际应用场景,提出的方法具有一定实际意义和应用价值.
猜你喜欢
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
数学年刊A辑(中文版)(2019年1期)2019-01-31 02:35:44
数学杂志(2018年5期)2018-09-19 08:13:48
中国交通信息化(2018年5期)2018-08-21 03:37:40
重庆工商大学学报(自然科学版)(2015年10期)2015-12-28 07:43:58
数学年刊A辑(中文版)(2014年5期)2014-11-01 05:43:38
振动、测试与诊断(2014年5期)2014-03-01 01:14:21
机械与电子(2014年1期)2014-02-28 02:07:31
