
基于杰卡德相似系数的OPAC用户检索行为研究
2022-06-09 05:34:46高洪臻
图书馆研究与工作 2022年6期
高洪臻
(潍坊市图书馆 山东潍坊 261061)
1 引言
OPAC(Online Public Access Catalog,联机公共目录检索)系统是互联网时代图书馆与用户互动的终端系统,为用户获取图书馆资源提供方便快捷的网络渠道,是新时代图书馆知识共享、开放阅读、馆藏资源管理与服务的重要窗口。图书馆新媒体服务环境下,OPAC检索平台已成为用户与图书馆馆藏资源衔接的重要纽带之一,如何充分借助OPAC检索系统深入挖掘用户对馆藏资源的需求,成为图书馆阅读服务工作的重要研究方向[1]。
用户访问OPAC网页时,网页服务器会根据用户检索字段记录检索日志,检索日志信息包括用户查询的书籍名称、作者、关键词等,这些信息可体现用户的实际需求和潜在需求,是除文献借阅量指标外揭示用户需求最直接的信息。借助数据挖掘中文处理算法,挖掘其检索日志间的关系,深入探究图书馆馆藏资源与用户需求的关联,通过数据分析有助于创新阅读服务工作,提升图书馆馆藏资源建设水平和文献流通率,让图书馆知识共享、阅读服务工作更贴近用户需求。
2 相关技术简介
2.1 文本预处理技术
OPAC检索日志中存储了用户检索的关键词信息,关键词信息多以中文字、词形式存储,部分用户借助OPAC查询时输入的仅仅是关键词,并非准确的书籍信息,故需对OPAC检索日志进行挖掘分析。处理这些关键词短文本语言需要借助数据挖掘中文处理算法,对日志关键词做分词、停用词处理、词频计算等预处理,经过预处理后的词语组才可进入数据挖掘相似度计算方法,从而展示OPAC检索平台中用户留下的资源期望信息。
OPAC检索日志中的原始信息经预处理后的词汇数据组,需进行词汇数据的相似度计算,根据数据组中的数据元在整个文档信息中出现的频率与前后词语关系,计算词语相似度,并根据相似度大小划分类别,得到数据处理后的相关信息组,展示词语间的关联。
2.2 Jaccard相似系数
数据挖掘中数据向量的相似度计算方法主要有夹角余弦法、皮尔逊相关系数法、杰卡德(Jaccard)系数法等[2]。其中Jaccard系数法以乘积方式为主,增大特征项对极性判定的作用,去掉分母中向量相同的部分进而提高向量相似程度的辨识度,因此Jaccard系数法常用来计算不完全相同的两个数据向量间的相似程度,而文本数据向量间的相近性较强,适用于Jaccard系数法进行相似度计算与辨别。
基于共现词次数的Jaccard系数法主要根据两个句子中出现相同部分的多少来判定,共现词相同部分越多其相似度越高,Jaccard相似系数的计算公式如公式1所示:
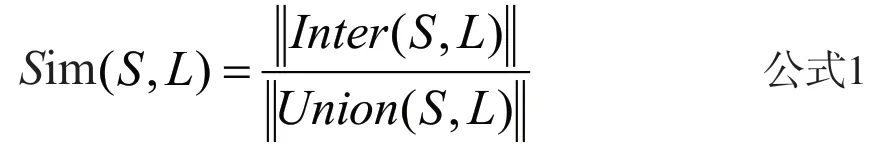
其中Inter(S, L)表示句子S、L的数据组词汇交集,Union(S, L)表示句子S、L的词汇并集[3]。OPAC检索日志中词语字符一般较短,因此Jaccard系数法可满足日志信息中文本信息的相似度计算,从而分析用户查询信息间的关系,挖掘用户阅读需求。
2.3 OPAC用户检索行为分析方法及原理
OPAC检索日志中含有用户需求的查询信息,查询信息以条目形式存储于文档中,由词语、句子的形式存储。OPAC用户检索行为分析主要以Jaccard系数为基础,分析查询条目信息中词语、句子间的吻合度,以计算得到的Jaccard相似度划分类别,相似度越高则代表查询信息条目中相近的信息越多,关联信息分析价值越高。OPAC用户检索行为分析方法的具体步骤为:
(1)给定OPAC检索日志文档X,文档中包含n条OPAC查询条目信息,其数据集表示为,{X1,X2,X3,...Xn,}数据Xi(1≤i≤n)表示由词语、句子组成的第i条查询信息,若查询条目信息中仅包含词语,则将词语看待为句子表示。首先对数据集{X1,X2,X3,...Xn,}进行文本预处理,包括数据Xi(1≤i≤n)的分词、停用词处理、词频计算等,经预处理后的数据集由数组X关键词信息组成{YX1,YX2,YX3,...YXn},其中数据YXi(1≤i≤n)表示文本预处理后数据集X中第i个元素对应的预处理数据信息。
(2)文本向量化操作。{YX1,YX2,YX3,...YXn}数据组选用Word2Vec文本向量化方法生成对应的数据化文本向量V(YX) ={V(YX1),V(YX2),...V(YXn)},V(YX)数组中每个元素代表一个查询条目对应关键词的向量化信息。
(3)计算文本向量数组中数据的Jaccard相似度。Jaccard相似系数的计算公式生成V(YX)数组元素间信息的Jaccard相似度Sim(V(YXi),V(YXj))(1≤i,j≤n)。
(4)设置阈值r和类别数w,根据得到的元素Jaccard相似度Sim(V(YXi),V(YXj))划分数据类别。首先将Sim(V(YXi),V(YXj))同阈值r比较,高于阈值的两个向量元素则代表对应的句子间交集大,低于阈值的则代表相似度低,按照句子相似度高低,对交集大的句子进行类别划分。由于可视化工具展示的局限性,需设定类别数w划分句子。
根据划分后的类别,展示句子间的相关性,分析句子间关联。
3 基于Jaccard系数的OPAC平台下用户检索行为分析
本文以潍坊市图书馆为例,对其2018—2020年间的OPAC检索信息日志数据进行分析,根据每年OPAC检索信息日志数据的分布特点,选取搜索量大于一定数值的关键词进行处理分析。例如2019年潍坊市图书馆OPAC检索平台日志数据共11万条,去除检索次数小于20次的关键词,选取2 523条检索数据进行分析,缩小处理数据的样本数,提高处理结果的准确性和代表性。针对潍坊市图书馆每年OPAC检索信息数据组,实验前首先对数据预处理以规范实验数据,包括分词、停用词处理、词频计算、数据标记等,然后将实验数据进行Jaccard系数下的相似度计算,设定阈值r为0.6,类别w根据可视化工具展示效果分别设定为20—30之间,通过文本处理工具对处理结果进行可视化展示,进而分析实验结果[4-5]。
3.1 基于词汇网络图的用户检索行为分析
本文选取潍坊市图书馆2018—2020年OPAC检索日志进行实验分析,以检索日志中检索条目组成的数据组{X1,X2,X3,...Xn,}为实验数据进行Jaccard系数下的相似度计算,通过文本处理工具KH Coder 3 Folder进行词汇网络图的可视化处理。图1展示了2020年OPAC检索关键词按词频大小及Jaccard相似系数计算后所生成的词汇网络图,图中圆圈越大代表关键词在数据组中出现的次数越多。
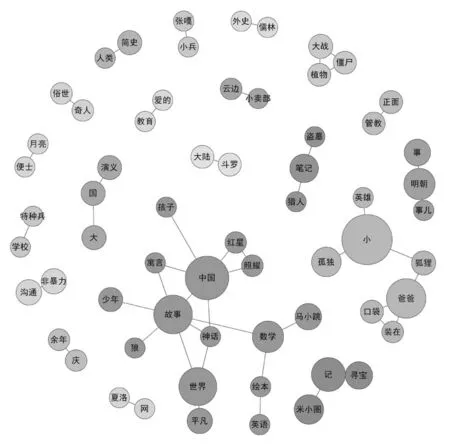
图1 潍坊市图书馆2020年OPAC检索热门词汇网络图
由于Jaccard相似系数是以词汇在句子和整个文本中出现的频率为依据计算词的相似度,因此大部分词语仅在同一文本中出现,词频较高的词语其相似度高,例如“儒林”“外史”;“月亮”“便士”等,这些词语被划分后,可明显看出《庆余年》《斗罗大陆》等书已成为2020年OPAC平台检索的热搜书籍。而不同文本句出现相同关键词且词频较高时,则在网络图中会将其链接,划分为相似集群,例如“猎人”“笔记”“盗墓”;“大”“国”“演义”等,分别以“笔记”“国”为纽带将不同的书籍信息链接。依据OPAC平台检索词汇信息,本文在处理时将长文本处理中部分无意义但在OPAC平台检索词数据分析中具有一定代表性意义的词汇保留,例如“大”“小”等词汇在长文本处理中一般视作停用词被删除,而本文在做OPAC平台检索词处理时,“大”“小”词分别代表着《斗罗大陆》《植物大战僵尸》《大江大河》《乔家大院》《米小圈》《小王子》《马小跳》《小淘气尼古拉》等书籍信息,在OPAC平台检索词汇分析中具有一定的意义,因此本文保留了类似词汇。整个词汇网络图展示了OPAC检索中高频词汇及高频词汇间的交集关系,以关键词为纽带将词汇链接,借助词汇网络图,可以分析用户每年对馆藏资源的需求以及趋向。
词汇网络图借助词频及相似系数,展现高词频和高关联度的词汇,高词频展示了书籍的受欢迎度,而高关联词汇则挖掘了不同书籍的相同信息,并突出用户喜爱程度。图1中关联网最大且词频最高的网络子图是由“中国”“故事”“童话”等词语组成,每个词会根据其所在的句子及出现的频率关联对应的词组。本文以“故事”一词为例,展示其关联的数据信息(见图2)。

图2 以“故事”一词为主线的OPAC检索数据(部分)
OPAC检索数据中,“故事”一词关联包括小说、童话、绘本等不同类别的书籍信息,例如《中国民间故事》《红色少年的故事》《数学故事》《雷锋的故事》等书籍信息;“少年”一词关联《牧羊少年》《红色少年》《少年特战队》等书籍信息;“爸爸”一词关联《口袋里的爸爸》《大头儿子和小头爸爸》《我爸爸》《了不起的狐狸爸爸》等书籍信息。主线关键词的存在链接了相关热门搜索书籍,书籍受众人群较多、主题内容丰富,但以相同的主线关联在子网络中,因此图书馆可根据其关联结果在加大馆藏资源建设的同时创新阅读推广工作,借助数据分析结果提高文献资源阅读量和用户参与度。
3.2 不同年份的用户检索行为比较
以Jaccard相似系数为基础研究OPAC检索数据得到的词汇网络图,可得到用户搜索热词及相关书籍信息子网络,而依据经典数据挖掘实例“啤酒与尿布”分析思想,OPAC检索数据中词频相同或相近的词所代表的书籍也隐含着其对应的关系。图1中,“正面、管教”“儒林、外史”“云边、小卖部”等关键词的词频相近;“大”“国”“演义”等关键词的词频相近。这些词频相近词汇分别代表着不同的书籍信息,依据其词频大小关系可进行书籍相关展示与借阅推荐等工作,从隐含词汇信息中挖掘阅读服务工作的亮点和创新点。
根据相同年份的不同词频信息可挖掘当年OPAC检索信息热点和关联关系,而借助不同年份的不同检索信息,则可分析用户馆藏资源需求的变化,并预测今后用户需求,为图书馆阅读服务工作的开展提供依据。图3、图4分别为潍坊市图书馆2018年、2019年OPAC检索热门词汇网络图。
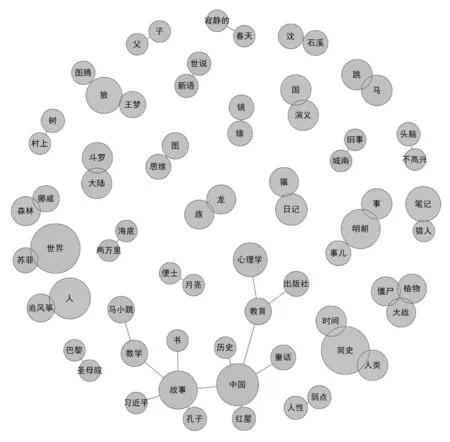
图3 潍坊市图书馆2018年OPAC检索热门词汇网络图

图4 潍坊市图书馆2019年OPAC检索热门词汇网络图
分析潍坊市图书馆2018—2020年OPAC检索热门词汇网络图,可知每年搜索关键词的变化。与2018年相比,2019年新增“爸爸”“友情”“豆豆”“爱的”“葵花”“定律”等倾向于情感、教育等方向的书籍信息词;与2019年相比,2020年新增“特种兵”“非暴力”“米小圈”“余年”“正面管教”等爱国、热剧等方向的书籍信息。每年的OPAC热门关键词会根据当年国家发展、教育话题和影视剧等发生改变,因此可根据当年不同发展情况,提前预测用户需要的热门馆藏图书,提高用户阅读兴趣和图书借阅量。
4 OPAC检索行为分析下公共图书馆阅读服务工作创新
基于Jaccard相似系数分析OPAC检索关键词,可从词频和词汇关联关系展开检索关键词的分析,根据分析结果研究图书馆阅读服务工作的创新和发展。根据用户检索关键词分析用户对馆藏资源的需求,从而开展馆藏资源采购新方法;根据用户检索书籍信息间的关系,包括关键词关联书籍信息、词频概率大小相同类别书籍信息,分析用户需求的书籍间的关系,更新馆藏资源布局,以用户需求书籍信息为基础,建设用户趋向馆藏资源空间;根据用户需求书籍方向、用户阅读需求等,分析用户阅读兴趣和方向,进而创新阅读推广工作,提升阅读推广服务新理念。本文分别从馆藏资源采购、馆藏资源布局、阅读推广服务三方面分析工作创新点和发展方向。
4.1 馆藏资源采购新方法
OPAC检索数据涵盖了用户所需馆藏信息关键词,包括馆内已有馆藏及馆内未采购书籍,根据检索数据信息可分析用户潜在的馆藏需求信息,从词频大小、查询时间研究图书馆馆藏资源采购新方法[6-7]。
(1)依据OPAC检索数据中词频较高的关键词信息,采购馆藏资源。OPAC检索关键词中,词频较高的关键词所代表的书籍可直接揭示大部分用户需求,根据关键词查询次数,依次补充馆藏副本和新增馆藏书籍是馆藏资源采购的新路径,具有较高的数据参考依据,可以有效提高用户借阅需求的满足率。
(2)挖掘OPAC检索词频偏低的关键词信息,补充、丰富馆藏资源。词频较低的关键词并不代表可以忽略,这些信息中包含部分用户的阅读需求,若馆内无此类馆藏资源,表示馆藏资源涵盖范围有待补充,此类书籍需要借助OPAC检索数据中词频较低的关键词挖掘发现,根据关键词信息对应的书籍发掘需要采购的图书,从而补充、丰富馆藏资源。
(3)根据OPAC用户检索行为指向图书信息,深入挖掘关键数据信息,包括书籍简介、作者、出版社、类别等,借助关联规则、聚类算法等智能分析方法,关联相关信息规则,例如分析书籍简介关键词、作者相关度等信息,寻找与查询图书相关的书籍,进而拓展用户需求的阅读范围,建设个性化服务馆藏资源。
(4)OPAC检索关键词往往代表着某一类图书,根据检索信息内容,查询馆内馆藏资源丰富度,若此类馆藏资源较少,则应查询同类书籍及对应的潜在发展性书籍信息,根据一个关键词指引的类别,运用发散思维扩展信息渠道,提升关键词代表性类别书籍,从而提升馆藏需求列表,以增强馆藏亮点及潜在书籍为趋向建设馆藏资源。
4.2 馆藏资源新布局
基于Jaccard相似系数分析的OPAC检索热门词汇网络从词汇大小、关联关系展示,根据OPAC检索数据的多角度分析,从检索热门排行、关联信息挖掘、数据比对分析的角度创新图书馆馆藏资源布局。
(1)汇集用户需求量大的图书,建立热门书籍专架。根据一段时间内OPAC检索关键词词频大小,筛选较高词频词汇对应的书籍,并根据书籍自身特征建立热门书架,满足用户对热门书籍的阅读需求,同时通过专架吸引更多的用户借阅这些热门图书。
(2)挖掘OPAC检索关联书籍,搭建相关主题区域。分析OPAC检索热门词汇网络中的子网络,以主线词汇对应的相关书籍为基础,设立主题书架。例如潍坊市图书馆2019年OPAC检索热门词汇网络中“故事”一词,其对应的图书可设置故事专题书架,汇集对应的热门图书,提高图书馆馆藏资源建设的创新性和个性化。
(3)分析OPAC检索同频率词汇,推荐同热度书籍。借助经典数据挖掘实例“啤酒与尿布”分析思想,将词频大小相近的图书邻近排放,设置相关类别同类图书推荐或相关主题推荐,方便用户寻找,从而提高图书馆阅读服务力度[8]。
(4)设置书籍联动馆藏区,实现高需求量图书带动低需求量图书提高借阅量。以OPAC检索词汇中高频检索关键词代表图书为主,搜寻相关低频检索关键词代表图书,并设置联动书架,以主题相关、作者相关等线索,吸引用户借阅图书,提高图书馆借阅量。
4.3 阅读服务工作新方向
图书馆阅读服务要根据实际工作的需求,以互联网时代新技术为平台,创新阅读服务工作方向、提升阅读服务意识、拓展阅读服务路径。
(1)融合新时代下互联网新技术,分析OPAC用户检索行为下的潜在需求,预测后期用户需求走向,以智能算法为支撑,为图书馆阅读服务工作提供新路径和新方向。
(2)实现印刷型图书与电子图书的统一检索与推送服务,推荐用户所需热门印刷型图书和关联性电子图书,扩大图书馆阅读服务覆盖面,充分发挥线上图书馆的作用,实现电子图书推送服务,打破传统印刷型图书副本数量的限制,充分满足用户阅读需求。
(3)以OPAC检索关联词汇为基础,打造专题阅读活动,包括线上专题阅读服务、主题图书互推互认等专题性活动,并开展以主线词汇为主题的活动,涵盖范围广、关联书籍种类多样化,从而提升图书馆阅读服务范围及创新性。
5 结语
基于Jaccard相似系数开展OPAC检索平台下用户关键词词汇的分析,并以词汇网络的形式展现,从词汇词频和相似关联词汇入手,分析热门关键词间的关系,根据不同角度的大数据分析可以获取用户的阅读需求方向,根据数据分析的结果可以指导图书馆资源建设和图书馆阅读服务创新工作的发展,为用户提供精准化阅读服务,从而有效提升图书馆馆藏资源利用率、用户参与度及满意度。Jaccard相似系数既可以应用于图书馆OPAC检索行为分析,也可以应用于图书馆网站用户检索行为分析、数字图书馆用户行为分析,同时可将这一功能开发、整合到智慧图书馆大数据统计分析系统中,通过智能化手段为图书馆服务提供决策参考。
猜你喜欢
现代装饰(2022年6期)2022-12-17 01:07:32
公民与法治(2022年10期)2022-10-12 07:46:48
园林科技(2021年3期)2022-01-19 03:17:48
艺术品鉴(2019年11期)2019-12-27 09:06:18
经济技术协作信息(2018年28期)2018-11-22 05:26:22
大观(书画家)(2018年6期)2018-07-08 00:43:26
新产经(2018年6期)2018-07-04 00:39:24
公民与法治(2016年22期)2016-05-17 04:20:32
读者·校园版(2015年7期)2015-05-14 13:11:40
深圳大学学报(理工版)(2015年5期)2015-02-28 16:22:05
