
基于深度学习的责任审计系统研究
2022-06-09 05:45:12史红刚
自动化技术与应用 2022年5期
史红刚
(西安医学院,陕西 西安 710021)
1 引言
随着信息技术的发展,审计智能化促进了行业的发展、机制的改革。以政府机构为例,文件形式更多的是以政策,活动以及其他有关审核和归档需求结果,这些结果文件需要在线发布,在发布之前,应该要求每个文档都经过编辑阶段,以检查是否存在单词的拼写错误或拼写错误或信息不完整。但是通过人工审核方式往往无法按照最新的规范格式、文字编辑要求进行修改,因此需要一种能够自动工作以协助编辑团队工作的文档责任审计系统,以便可以检测文档中是否存在键入错误。
责任审计系统设计的目的是提高和修订检测结果的质量,并利用和开发与适合使系统工作的方法有关知识。业界重点使用贝叶斯规则概率方法检测和纠正文书写错误,关于文字书写错误和更正的研究数量仍然很少,并且该方法的使用仍然限于少数简单方法。在单词非单词错误的检测和纠正研究中,研究结果证明了使用字典查找的检测方法以及其他几种比较方法,结果表明,“相似度法”比“正反字典法”具有更好的准确性,准确度分别为98.55%和97.59%[1]。
基于以上几个背景问题,针对语言文献的研究方法很少而且太简单,因此本文提出一种使用流深度学习来构建一个智能的责任审计系统来审核政府机构文件,可以帮助和支持智能治理,同时在IR(Information Retrieval)和NLP(Natural Language Processing)领域中增加应用场景[2]。
2 系统设计
2.1 智能治理和文件审计
智能治理是指通过采用最新的信息技术开发实现责任审计,政府机构中的文件审核与如何使用计算机技术自动评估任何形式的文本文件有关,主要针对以下现状。
1)对将要或已经存储在数据库中的政府机构文件进行自动评估,以提供拼写错误百分比。
2)自动评估将要或已经存储在数据库中的政府机构文件,以提供文件质量分类的结果,例如,根据以下标准,评级为1—3(not very good、very good class、very good level),处理文本文档时使用的规则[3-5]。
3)对将要或已经存储在数据库中的政府机构文件进行自动评估,以提供与政府机构外部其他文件相似度百分比。
4)对将要或已经存储在数据库中的政府机构文件进行自动评估,以提供与成为参考文件的模板(法律规则,标准格式等)的适用性百分比结果。
2.2 系统设计
责任审计系统采用Matlab 作为审计模型进行计算,采用Django作为系统框架,Django是使用Python语言框架之一。Django 可用于满足一般应用程序的需求,例如处理用户身份验证,内容管理,RSS等;同时Django还注重安全性,例如,保护应用程序免受SQL注入、跨站点脚本编写、跨站点请求伪造和点击劫持的影响。Django在界面方面也使用户可以自由确定所需的设计[6-9]。
本责任审计系统基于流深度学习(Stream Deep Learning,SDL)模型,以准确性值的形式获得过程评估值,将卷积神经网络(Convolution Neural Network,CNN)的基于极限学习机(Extreme Learning Machine,ELM)的简化深度学习(SDL-ELM)和Extreme Learning Machines 的训练速度与利用Matlab、后端(Python Django)和前端(PHP)Web App相结合。如图1所示,SDL-ELM结构由一个输入层,一个输出层和几个隐藏层组成,这些隐藏层被安排为单个单元的卷积层,然后是汇聚层。卷积和汇聚层的数量取决于情况的复杂性,卷积层由几个特征组组成,汇聚层由几个特征组的记录组成。以下是针对分类过程的流深度学习的详细步骤:
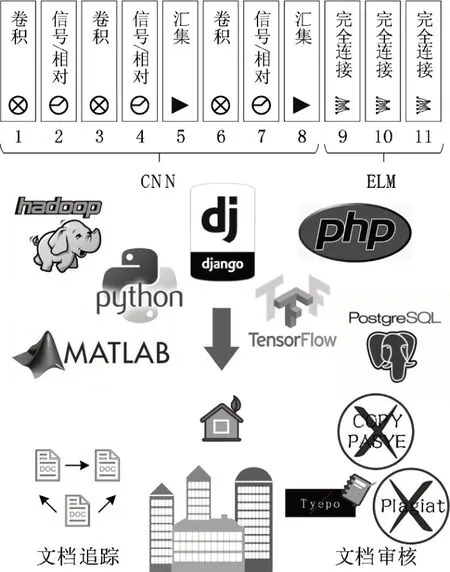
图1 SDL-ELM组成结构
(1)通过组合卷积,信号/相对,汇聚和完全连接过程,在“责任设计系统”中创建一个文件夹。
(2)确定参数值:
a.用于特征值的标准化过程。
b.用于卷积过程。设置:如使用三种类型的过滤器:第一(conv11):平均过滤器,第二(conv12):最大过滤器,以及第三(conv13):std 过滤器,std(标准偏差)。numFilter=3;占填充量的百分比(k),滤波器矩阵的大小(k×k),例如k=3;
c.汇聚过程。
(3)执行学习过程
a.预处理,伪代码如下:

[numData,…numFeature,target,norm]=FnPreProses('datatrainClassify',…mac,mic,mao,mio);1.Load training data,get numData and numFeature.2.Create“image matrix”for each initial data(only the feature value is taken)from the dataset,which is using Repmat technique.3.Normalization of all“image matrix”data.norm{i}=(((a{i}-mic)./(mac-mic))*(mao-mio))+mio;in which a{i} is each i-th data matrix element,and norm {i} defines it as a matrix with a size [numFeature x numFeature]
b.使用CNN进行特征抽象,伪代码如下:

1.卷积初始化.hC=FnConvDL(norm,numData,k);if k=3,then expand the edge norm image matrix(padding)with zero value as much as pad size=(k-1)/2=(3-1)/2=1,where k is an odd number≥3,and f(i,j)represents the data value.The equation of filter 1st:平均过滤器images/BZ_72_1411_1762_1927_1857.pngThe equation of filter 2nd:最大过滤器images/BZ_72_1411_1942_1983_2019.pngThe equation of filter 3rd:std过滤器images/BZ_72_1411_2104_2057_2191.png2.信号/相对hA=FnSigDL(hC,numFilter,numData);3.卷积hC=FnConvInDL(hA,numData,k,numFilter);4.信号/相对hA=FnSigDL(hC,numFilter,numData);5.汇聚hP=FnPoolDL(hA,windows_size,numFilter,numData);6.卷积hC=FnConvInDL(hP,numData,k,numFilter);7.信号/相对hA=FnSigDL(hC,numFilter,numData);8.汇聚jika ukuran(hA{i}{j})=[2 x 2],maka set windows_size=1 hP=FnPoolDL(hA,windows_size,numFilter,numData);
c.完全连接到ELM,伪代码如下:

9.完全连接1st.E.g.,num_neuron_hidden_layer=5;[hFC11,W11,Bias11,Beta11]=FnELMtrainClassify(hP,target,...num_neuron_hidden_layer,numData,numFilter);10.完全连接2nd.Eg,num_neuron_hidden_layer=7;[hFC12,W12,Bias12,Beta12]=FnELMtrainClassify(hP,target,...num_neuron_hidden_layer,numData,numFilter);11.完全连接3rd Eg,num_neuron_hidden_layer=4;[hFC13,W13,Bias13,Beta13]=FnELMtrainClassify(hP,target,...num_neuron_hidden_layer,numData,numFilter);
(4)执行测试过程

a.卷积初始化,伪代码如下:[numData2,...numFeature2,target2,norm2]=FnPreProses('datatestClassify',...mac,mic,mao,mio);b.使用CNN进行特征抽象,伪代码如下:1.卷积初始化hC2=FnConvDL(norm2,numData2,k);2.信号/相对hA2=FnSigDL(hC2,numFilter,numData2);3.卷积hC2=FnConvInDL(hA2,numData2,k,numFilter);4.信号/相对hA2=FnSigDL(hC2,numFilter,numData2);5.汇聚hP2=FnPoolDL(hA2,windows_size,numFilter,num-Data2);6.卷积hC2=FnConvInDL(hP2,numData2,k,numFilter);7.信号/相对hA2=FnSigDL(hC2,numFilter,numData2);8.汇聚if size(hA2{i}{j})=[2 x 2],then set windows_size=1 hP2=FnPoolDL(hA2,windows_size,numFilter,num-Data2);c.完全连接到ELM,伪代码如下:9.完全连接1st[Accuracy1,classPredict1,Ytest_predict1]=...FnELMtestClassify(hP2,target2,W11,Bias11,Beta11,numData2,numFilter);

10.完全连接2nd[Accuracy2,classPredict2,Ytest_predict2]=...F images/BZ_73_1435_420_1631_531.pnglassify(hP2,target2,...W12,Bias12,Beta12,numData2,numFilter);11.完全连接3rd[Accuracy3,classPredict3,Ytest_predict3]=...FnELMtestClassify(hP2,target2,...W13,Bias13,Beta13,numData2,numFilter);
2.3 实验
图2中的测试结果表明,与测试数据相比,使用的训练数据越多,准确性越好。这是因为系统可以从训练数据中学习更多知识。相反,如果训练数据越来越小,则系统将无法识别数据中存在的模式,因此从训练过程中获得的知识仍不是完全最优的。但是有时会有一些特殊情况,即即使训练数据少于测试数据,但仍可以提供更好的准确性结果。

图2 实验结果图
当已知测试数据是一定数量并且训练数据的质量也很好时,有必要寻找应该使用多少训练数据。因此,有必要在已知测试数据为一定数量时寻找应该使用多少训练数据。
3 结束语
本文研究了一种基于深度学习的责任审计系统,通过以政府机构文档为研究背景,以提升文档责任审核的高效性,文中以伪代码的形式对深度学习过程进行了描述,并且以过程执行过方式(卷积初始化—使用CNN 进行特征抽取—完全连接到ELM),表明流深度学习可以并且准备好很好地用于开发责任审计系统以支持智能治理。
猜你喜欢
中国新闻周刊(2021年26期)2021-07-27 04:02:12
动漫星空(2018年11期)2018-10-26 02:24:02
动漫星空(2018年2期)2018-10-26 02:11:00
动漫星空(2018年9期)2018-10-26 01:16:48
动漫星空(2018年5期)2018-10-26 01:15:02
电子测试(2018年9期)2018-06-26 06:45:56
趣味(语文)(2018年2期)2018-05-26 09:17:55
信息安全研究(2016年4期)2016-12-01 06:06:54
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
自动化博览(2014年6期)2014-02-28 22:32:20
