
基于BiLSTM-CapsNet混合模型的社交文本情感分析
2022-06-09 07:46:56叶慧雯王子民张秀文赵子涵杨玉东
南京理工大学学报 2022年2期
季 陈,叶慧雯,王子民,张秀文,赵子涵,杨玉东,2
(1.南京工业大学 计算机科学与技术学院,江苏 南京 211816;2.淮阴工学院 电子信息工程学院,江苏 淮安 223003)
随着互联网信息技术的快速发展,微信、QQ、微博等社交媒体用户数以亿计,通过社交媒体可以发表心情、感想和对各类事件的看法等,其内容包括新闻资讯、热点事件、产品评论、娱乐八卦等众多方面,能够直观地反映用户的情感倾向[1]。近年来,文本情感分析在政府舆情监控、企业管理决策、个人情绪管理等方面发挥着重要作用。
随着情感分析技术方法、算法和资源的不断发展,现有的研究基于不同的监督环境产生了3种主要的方法[2]。基于情感词典[3]的方法:郗亚辉[4]通过词语和词语之间有情感的交互和上下文的约束等联系扩展情感词典以提高文本分析的准确率;Xu等[5]利用不同情感词之间的上下级关系对情感词典进行扩充达到提高准确率的目的。基于机器学习的方法:Pang等[6]首次在针对电影评论的情感分析中使用支持向量机(Support vector machine,SVM)进行情感二分类,将电影评论文本分为了积极与消极两类;李婷婷等[7]利用文本的词性、情感程度等,构造出了不同的特征,提出了SVM和条件随机场相结合的分类模型,提高了文本分类的准确率;针对情感词在不同的上下文语境中具有不同含义的问题,Cai等[8]在一种三层情感词典的基础上将SVM和梯度提升决策树(Gradient boosting decision tree,GBDT)结合形成情感分析混合模型,有效提高了文本情感分析的效果。基于深度学习的方法:Kim等[9]最先开始使用卷积神经网络(Convolutional neural network,CNN),用不同的卷积核对文本不同位置的局部语义进行特征提取,改善了文本分类的效果,但CNN中的池化操作会带来信息的丢失问题;杨玉娟等[10]在word2vec的基础上引入了术语频率-逆文档频率算法形成词向量,同时在长短期记忆网络(Long short-term memory,LSTM)模型中加入了注意力机制,提高了文本分析的准确率。
综合以上3种文本情感分析方法,基于情感词典方法依赖人工构建情感词典,基于机器学习的方法依赖人工构建文本特征,实时性较差。基于深度学习的方法相比于情感词典方法和机器学习方法,可以从经计算机处理过的文本词汇中自动提取语义特征[11],实时性较强,但是文本的上下文信息和位置语义信息无法依靠单一的神经网络模型进行提取。
胶囊网络(Capsule network,CapsNet)模型是在卷积神经网络模型的基础上进行的改进,用动态路由代替了CNN中的池化操作,解决了池化操作带来的信息丢失问题,能很好地提取情感词在全文的位置语义信息;双向长短期记忆网络(Bi-directional long short-term memory,BiLSTM)模型由两个方向相反的LSTM模型上下叠加构成,单独的LSTM模型只能获取文本单向的上文或下文信息,本文利用BiLSTM代替LSTM可以更好地捕捉文本双向的语义依赖。
综上,针对现有文本情感分析方法实时性不强,不能同时提取文本上下文信息和局部语义特征等问题,本文提出一种改进胶囊网络的BiLSTMCapsNet混合模型进行文本情感分析,这一模型由BiLSTM模型和CapsNet模型组成混合模型,既能利用BiLSTM模型可提取文本上下文信息的优势,又能利用CapsNet模型可提取文本位置语义信息的优势,可以很好地提高文本情感分析的效果。
1 BiLSTM-CapsNet混合模型的建立
BiLSTM-CapsNet混合模型主要分为4步:文本预处理、文本建模、特征提取和情感分类。文本预处理的目的是去除噪声,只保留具有语义特征的词语;文本建模就是将文本数据转化为可以由计算机处理的数值型数据的过程;特征提取使用CapsNet提取局部语义特征,再使用BiLSTM提取上下文特征信息。情感分类采用softmax分类器进行分类。基于BiLSTM-CapsNet混合模型的文本情感分类如图1所示。

图1 基于BiLSTM-CapsNet混合模型的文本情感分类
1.1 数据预处理
文本数据不仅包含了具有语义特征的词汇还包含了一些影响分类效果的噪声特征,数据预处理的目的在于去除噪声,保留具有语义特征的词汇。数据预处理操作步骤如下所示:
(1)过滤掉文本中的标点符号和特殊字符;(2)使用Jieba等分词工具进行分词,若是英文这步操作省略;
(3)文本数据中含有各种没有具体语义的停用词,将会影响到分类效果,使用哈工大停用词表去除噪声数据;
(4)文本中的标签也需要进行处理,将文本型的标签数据转化成计算机能够识别的数值型数据。
1.2 文本建模
社交文本数据是高度非结构化的数据,需要将其转换成结构化的数值型数据进行处理。本文选用了word2vec工具,word2vec将每个词映射到一个高维向量中,训练所得的向量可以表示词对词之间的关系。word2vec主要依赖其自带的框架结构将不可计算的非结构化的文本词汇转化成可计算的结构化的高维实数向量。
1.3 局部语义特征提取
胶囊网络模型用于文本分类结构图如图2所示,主要分为4个部分:卷积层、主胶囊层、卷积胶囊层和全连接胶囊层。第一部分是一个标准的卷积层,通过多个不同的卷积核在句子的不同位置提取特征。第二部分为主胶囊层,该层是将卷积操作中的标量输出替换为矢量输出,从而保留了文本的单词顺序和语义信息。第三部分为卷积胶囊层,在这一层中,胶囊通过与变换矩阵相乘来计算子胶囊与父胶囊的关系,然后根据路由协议计算上层胶囊层。第四部分是全连接胶囊层,胶囊乘上变换矩阵,然后按照路由协议生成最终的胶囊及其对每个类的概率。其中Flatten函数用在卷积层到全连接层的过渡,把多维的输入一维化。本文采用了胶囊网络的前3层进行文本局部语义特征的提取。

图2 胶囊网络用于文本分类模型结构图
假设数据集文本中的一个词为w(i),经过word2vec工具转化为词向量V(w(i))),则词向量矩阵Sij={V(w(1)),V(w(2)),…,V(w(n))}。胶囊网络在卷积层中用滤波器对词向量矩阵Sij进行卷积操作达到文本局部语义特征提取的作用,计算方法如式(1)所示

式中:b0为偏置项,Wα为卷积运算操作的滤波器,X i:j+K1-1表示滤波器每次移动的单词窗口为X i至X i+K1-1,f()为非线性激活函数ReLU,若有B个滤波器,即α=1,2,…,B,则mα i表示胶囊网络提取的文本局部语义特征。
1.4 上下文信息提取
LSTM模型适用于处理和预测时间序列中时间间隔和延迟相对较长的事件,提出的目的主要是为了解决循环神经网络结构中存在的梯度消失或者梯度爆炸问题,是一种特殊的循环神经网络,但是LSTM建模存在一个问题,无法编码从后向前的文本信息。BiLSTM模型是由两个方向相反的LSTM模型上下叠加构成,可以更好地捕捉双向的语义依赖,在更细粒度的文本分类过程中,BiLSTM模型有更好的表现。BiLSTM模型结构如图3所示。

图3 BiLSTM用于文本分类模型结构图
如图3所示,w(i)表示文本中的词汇,V(w(i))表示经word2vec转化的词向量,词向量拼接形成了词向量矩阵Sij,其中Sij={V(w(1)),V(w(2)),…,V(w(n))},然后利用BiLSTM模型进行上下文信息提取,得到BiLSTM的输出h n,计算方法如式(2)所示

1.5 混合模型
基于BiLSTM-CapsNet混合模型的文本情感特征提取流程图如图4所示。
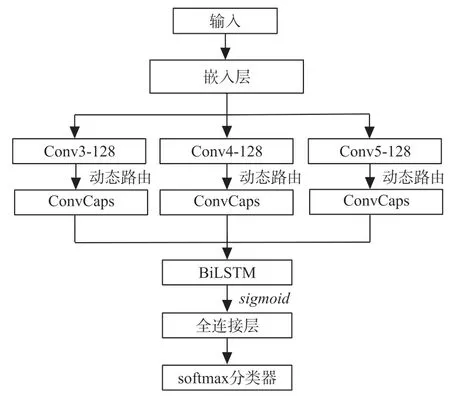
图4 文本情感特征提取流程图
输入层将文本数据集进行预处理后,通过word2vec将文本中的词汇转化成词向量,设置词向量维度为100,然后通过嵌入层将文本词向量进行拼接,形成文档词向量矩阵,如式(3)所示

式中:w(n)表示词语,V(w(n))表示词向量,Sij表示词向量矩阵,⊕表示拼接操作。
局部语义特征提取是由胶囊网络的一层卷积层和两层胶囊层组成,以嵌入层的词向量矩阵Sij作为输入,采用大小为3×100,4×100,5×100的滤波器各128个进行卷积运算,通过卷积操作来提取各个位置的局部特征

式中:Oij表示Conv层的输出。使用动态路由操作代替池化操作,再进行两次胶囊层的特征提取。

式中:gij表示CapsNet的输出,同时作为BiLSTM的输入。隐藏层大小设置为128,sigmoid作为激活函数,从BiLSTM模型的两个方向输入序列,通过隐藏层提取文本的上下文信息,如式(6)所示

式中:gijt表示在t时刻的文档矩阵,hijt表示在t时刻BiLSTM的输出,再使用CapsNet的全连接层进行连接,最后通过softmax函数进行文本情感分类,如式(7)所示

式中:b i为偏置项,Wi表示全连接层到输出层的权重系数,dijt表示t时刻全连接层的输出向量。
2 试验与结果
2.1 试验数据集
当前文本情感分析的主要任务可分为词级别情感分析,句子/文档级情感分析和目标级情感分析3类,本文主要研究是基于句子/文档级的情感分析。从粒度上划分,情感分析又可以分为粗粒度和细粒度。粗粒度的情感分析就是对文本的正负极性进行分类,而细粒度的情感分析可以根据要求的不同分成多类,本文的细粒度情感分析试验把情感分成了7类,分别是0:生气(anger)、1:厌恶(disgust)、2:伤心(sandness)、3:喜欢(like)、4:害怕(fear)、5:惊喜(surprise)、6:开心(happiness)。本文试验采用了两组数据集,一组做细粒度情感分析,另一组做粗粒度情感分析。
细粒度情感分析试验数据集采用的是NLPCC2014微博情绪识别数据集,截取其中部分如表1所示。粗粒度情感分析试验数据集为产品评论数据集,截取其中部分如表2所示。

表1 NLPCC2014微博情绪识别数据集样例

表2 产品评论数据集部分样例
试验采用了Python作为算法的实现语言,词向量分别取200维,文本长度取固定长度100,选用Adam作为优化函数,具体设置如表3所示。

表3 模型参数设置
为验证本文提出的BiLSTM-CapsNet混合模型的情感分析性能,两组试验分别对比了6组模型,其中包括CNN模型、BiLSTM模型、CapsNet模型、CNN+CapsNet模型、CNN+BiLSTM模型和本文提出的BiLSTM-CapsNet模型。从准确率、精确率、召回率和F1值4个评价标准进行比较。
2.2 评价标准
文本情感分类常用的评价指标有精确率(Precision)、召回率(Recall)和F1值。
精确率定义如式(8)

式中:TP为正样本判断为正样本的数量即正样本判断正确的数量,FP为正样本判断为负样本的数量即正样本判断错误的数量。
召回率定义如式(9)

式中:FN为负样本判断为正样本的数量即负样本判断错误的数量。
F1值是精确率和召回率的调和平均值,定义如式(10)

2.3 细粒度情感分类试验
细粒度情感分析试验采用了NLPCC2014微博情绪识别数据集,试验结果如表4所示。
由表4可知,在细粒度情感分析试验中,本文文本情感分析算法模型在召回率和综合评价指标F1值方面,相较于单一的CNN、BiLSTM、CapsNet模型和混合的CNN+BiLSTM、CNN+CapsNet模型都达到了最好的结果。在准确率方面,本文文本情感分析算法模型优于单一的BiLSTM、CapsNet模型和混合的CNN+BiLSTM、CNN+CapsNet模型,与单一的CNN模型准确率相当。

表4 细粒度情感分析试验结果
2.4 粗粒度情感分析试验
粗粒度情感分析试验采用了评论数据集,试验结果如表5所示。

表5 粗粒度情感分析试验结果
由表5可知在粗粒度情感分析试验中,本文文本情感分析算法模型在准确率、召回率和综合评价指标F1值方面,相较于单一的CNN、BiLSTM、CapsNet模型和混合的CNN+BiLSTM、CNN+CapsNet模型,都达到了最好的结果。
3 结束语
本文结合BiLSTM模型和CapsNet模型各自优势构成的BiLSTM-CapsNet混合模型,既能同时利用BiLSTM和CapsNet特征提取的优势,又能很好地理解待处理文本的语义。通过细粒度情感分析和粗粒度情感分析两组试验,分别对比了6种模型,验证了本文提出的模型在细粒度和粗粒度情感分析试验中都具有较明显的优势,能够更好地完成文本情感分析的任务。
本文提出的BiLSTM-CapsNet混合模型在试验中使用的训练时间资源都高于单一的CNN、BiLSTM和CapsNet模型,与同类的CNN+BiLSTM、CNN+CapsNet混合模型相当,所以如何使用更少的时间资源进一步提高本文模型文本情感分析的准确率是下一步的工作目标。
猜你喜欢
红外技术(2022年11期)2022-11-25 03:20:40
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
高技术通讯(2021年1期)2021-03-29 02:29:24
开放教育研究(2020年2期)2020-03-31 01:54:14
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
电脑与电信(2018年11期)2018-02-16 05:41:32
信息安全研究(2016年3期)2016-12-01 06:06:41
现代语文(2016年21期)2016-05-25 13:13:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
