
面向图像数据的对抗样本检测与防御技术综述
2022-06-09 14:34:28杨奎武魏江宏宁原隆
计算机研究与发展 2022年6期
张 田 杨奎武 魏江宏 刘 扬 宁原隆
(战略支援部队信息工程大学 郑州 450001)
深度神经网络(deep neural network, DNN)能处理复杂的科学问题,已成功应用于目标跟踪与检测[1]、文字处理[2]、语音处理[3]、图像识别[4]等领域.近期研究发现,DNN模型很容易受到对抗样本的攻击,将对抗样本输入高准确率的DNN模型后,模型的准确率会明显降低[5].
目前,对抗样本的研究主要分为2方面:1)对抗样本生成技术;2)对抗样本检测与防御技术.由于对抗样本生成技术的对抗攻击会对DNN模型造成负面影响,尤其在医疗[6]、运输[7]等信息敏感领域,因此,对抗样本的检测与防御技术成为目前DNN安全的研究热点[8].
本文重点关注对抗样本检测与防御技术,描述其演进过程,并从特征学习、分布统计、输入解离、对抗训练、知识迁移和降噪等6个方面对检测与防御技术进行汇总归纳,分析对比每类技术的性能、优缺点,使读者对对抗样本的检测与防御机制有直观的了解.
鉴于当前对抗样本的研究大多选择图像数据作为输入样本,本文的讨论也集中于图像处理领域.
1 对抗样本概述
1.1 对抗样本的产生
对抗样本是指在原始数据集中的样本中通过有目的地添加少量的扰动信息,使得基于DNN模型的系统出现误判的样本[5].
理论上,输入空间的某个邻域可以从不同的角度表征同一个对象,即输入空间的某邻域内的数据应有相同的输入标签和统计分布.

Fig. 1 Fast adversarial example generation on GoogLeNet图1 GoogLeNet中快速对抗样本生成
对抗样本的发现否定了这一推测.Szegedy等人[5]发现,被神经网络正确分类的原始样本添加了微小扰动后,神经网络对其的分类准确率显著下降.
图1左图为Goodfellow等人[9]在ImageNet数据集上训练了GoogLeNet模型,中间图为快速生成的对抗扰动,右图为添加扰动后的对抗样本,原模型将图像x以置信度57.7%判定为“熊猫”,在加入微小扰动后,模型以置信度99.3%将其判定为“长臂猿”.
1.2 对抗样本的成因
对抗样本的成因主要有4种假说:盲区假说、线性假说、决策面假说、流形假说[8].
Szegedy等人[5]提出对抗样本处于数据分布的低概率区域,即盲区.不能覆盖盲区的训练数据所训练的模型泛化性不高,因而产生对抗样本.
Goodfellow等人[9]考虑权重向量与对抗样本之间的关系:
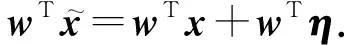
(1)
他们认为对抗样本的成因是神经网络的高维线性[9],对抗扰动使得激活函数增加wTη,这意味着w的维度越大,激活函数越有可能被微小的扰动所误导.
Moosavi-Dezfooli等人[10]提出了决策面假说.在研究通用对抗扰动(即:可应用于所有输入样本的对抗扰动)时,他们发现:分类器的高维决策边界之间存在几何关系.即存在一个低维子空间,包含大多数自然图像决策边界的法向量.因此,在该子空间内的对抗扰动可以干扰大多数输入样本的分类.
流形假说是指对抗样本偏离正常的数据流形[11].前面提到的3类成因假说主要应用于对抗样本生成,而流形假说则更多地应用于对抗样本检测,如MagNet[12]的检测器就基于此类成因假设.
现阶段,神经网络和数据的高度复杂性使得深度学习模型不可解释,因此不同的假说具有不同的侧重点,没有达成数理层面的统一认识.理论的不完善在一定程度上限制了对抗样本检测与防御技术的发展,现有的检测与防御技术只能被动地针对生成技术而改进,但没有从根源解决问题.
2 对抗样本生成技术
图2展示了对抗样本生成技术演进.对抗样本生成技术可分为黑盒攻击和白盒攻击2类,目前白盒攻击的成果更多,但以对抗样本的迁移性为基础的黑盒攻击更具有实际意义.白盒攻击中,基于梯度的算法为经典算法,随着神经网络的广泛应用,又出现了基于对抗式生成网络(generative adversarial network, GAN)、针对语义图像分割、对象检测模型等生成技术.
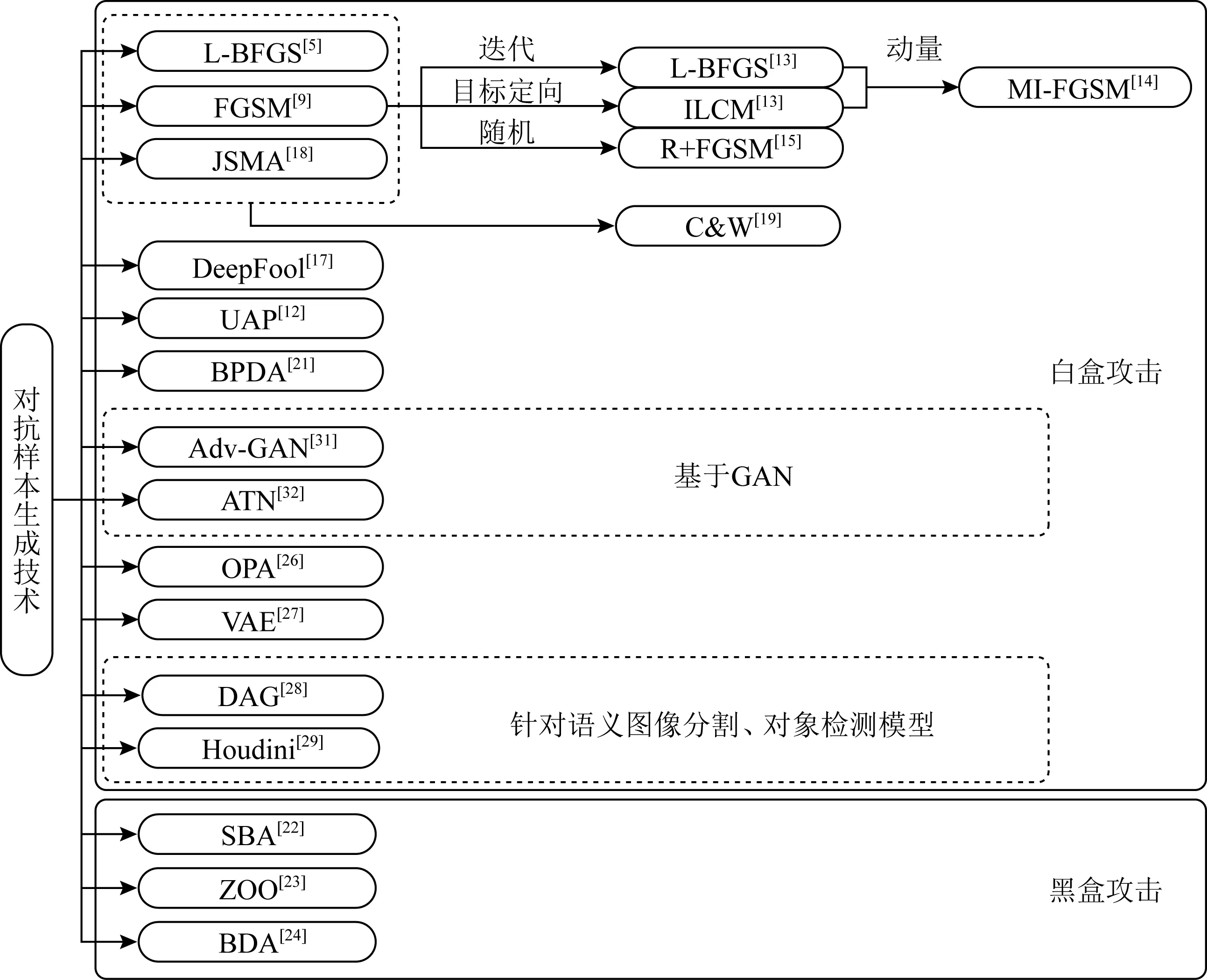
Fig. 2 The evolution of generating adversarial examples图2 对抗样本生成技术演进
2.1 受限内存下的BFGS算法
Szegedy等人[5]提出对抗样本概念的同时提出首个对抗样本生成技术:受限内存下的BFGS(limited memory Broyden-Fletcher-Goldfarb-Shanno, L-BFGS)算法,在减小内存占用的条件下使用BFGS算法求解.
L-BFGS算法的最终目标是在输入空间的边界内找到感知上最小的输入扰动以生成对抗样本,通过箱约束优化问题求解对抗扰动r:
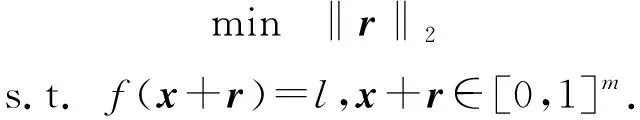
(2)
在实际应用中,作为最早的生成技术,L-BFGS已成功应用于AlexNet等经典神经网络.但L-BFGS算法对对抗扰动的分布没有深入分析,因此无法将网络得以很好地推广.
2.2 快速梯度符号法(fast gradient sign method, FGSM)

FGSM的优点在于快速性,在使用线性激活函数和决策函数时总能找到有效的对抗样本.
但FGSM生成的对抗样本只是1阶近似最优解,而不是最优解.且FGSM的阈值ε是由人为选择的,在使用非线性决策函数时,FGSM的效用将降低.

Fig. 3 Effect of FGSM with nonlinear decision function图3 选择非线性决策函数的FGSM效果
基于FGSM又提出了很多衍生方法:
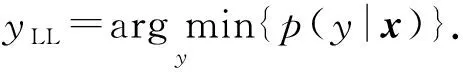
2) 引入随机性.R+FGSM(random initialized FGSM)[15]方法在生成对抗扰动之前对样本进行了单步随机步长变换操作,此方法有助于绕过依赖于梯度掩蔽的防御.投影梯度下降(projected gradient descent, PGD)方法[16]与R+FGSM同样在生成对抗扰动之前引入了单步随机变换,不同之处在于PGD使用多步迭代生成对抗扰动.
2.3 深度欺骗算法(DeepFool)
DeepFool攻击是一种针对FGSM在非线性模型中出现的问题而提出的方法,具有更强的适应性.
受二进制线性分类器启发,Moosavi-Dezfooli等人[17]使用点到决策边界的距离来最小化扰动.图4表示一个4分类问题,图中的3条线分别对应前3类的参数超平面与第4类相交得到的参数超平面,样本x0属于第4类.通过计算x0与每个决策边界的距离确定最小扰动.
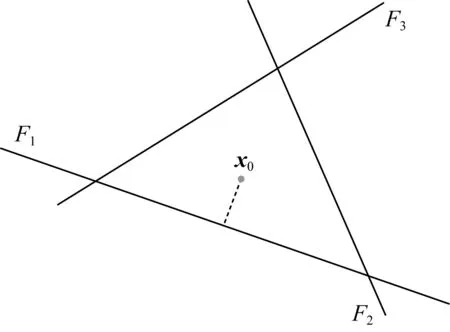
Fig. 4 Diagram of DeepFool of four-category classification图4 4分类问题DeepFool方法示意
进一步将线性分类器推广到非线性分类器,将围绕x0的各类别决策边界线性化,通过迭代移动x0至决策边界,直至样本被分类器错误分类.
DeepFool攻击解决了FGSM需要人工设置合理阈值ε的问题,最优化扰动,适应性更强,DeepFool已成功攻击各类模型,如LeNet,GoogLeNet等.在性能上,MNIST和CIFAR10模型上DeepFool算法所产生的扰动是FGSM所产生的扰动的1/5,计算速度达到L-BFGS的30倍,是目前防御方法常对抗的攻击模型之一.
2.4 雅克比显著图攻击(Jacobian-based saliency map attack, JSMA)
受计算机视觉领域的显著图启发:输入的不同特征对输出的影响程度不同,Papernot等人[18]提出JSMA方法[18]生成对抗样本.FGSM[9]和DeepFool[17]生成的是非定向对抗样本,JSMA[18]以特征对输出结果的影响程度为依据,可增强指定类型的特征以达到生成定向对抗样本的目的.
JSMA[18]通过计算前向导数生成对抗性显著图.与FGSM[9]和DeepFool[17]对损失函数的求导操作不同,前向导数是神经网络输出层的每个输出对输入的每一个特征的偏导数,对抗性显著图则体现了输入的不同特征对输出的影响程度.
原始算法中,使用softmax作为显著性度量,考虑到使用不同的显著性度量,Carlini和Wagner[19]提出了使用对数梯度代替softmax属性,也能够成功找到对抗样本.
JSMA需要设置特定的目标类别,而这种选择会影响攻击的速度和质量,因此目标类别的选择与计算性能的提升是应用JSMA算法时需要解决的问题.
2.5 Carlini & Wagner攻击(C&W)
Carlini和Wagner[19]针对Hinton等人[20]提出的防御蒸馏网络提出C&W攻击方法.C&W方法按攻击目标类别分为3类:随机目标、最易攻击的类别、最难攻击的类别,并通过限制l∞,l2,l0范数优化扰动.
C&W攻击的目标函数为
(3)
与前期的对抗样本生成技术不同的是,C&W将扰动最小化和损失函数最大化这2个优化问题结合为一个目标函数.
Carlini和Wagner[19]提出了6种f函数,并衡量了相应的模型效果.各种对比实验结果显示:使用式(5)中的函数性能更好.
基于l2范数的攻击,在给定输入x、选定目标t的情况下,寻找w满足:

(4)
其中,f定义为
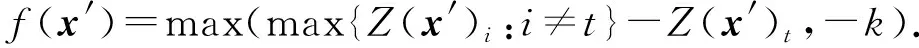
(5)
由于l0距离度量具有不可微性,不适用于梯度下降法,因此C&W攻击通过迭代寻找对分类输出无大影响的像素点实现优化.
l∞范数函数并不全可微分,无穷阶范数是由最大量决定,因此对应的梯度下降只会影响最大改变量的像素点,结果模型很容易陷入次优解.
解决陷入次优解的思想在于并非只惩罚最大点,而是设置一个阈值表征大点,惩罚所有大点.
C&W攻击在攻击防御蒸馏网络时有着很高的成功率,也是现有防御模型常用来测试的攻击方法.
2.6 后向微分近似攻击(backward pass differentiable approximation, BPDA)
Athalye等人[21]针对基于混淆梯度的降噪方法提出的BPDA方法.在给定训练器f的情况下,增加一个预处理器g(x),g(x)满足g(x)≈x,基于这一性质,将其导数近似为恒等式的导数:
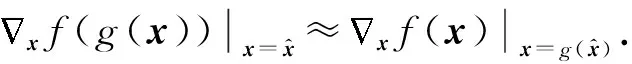
(6)
文献[21]针对ICLR 2018会议发表的7种基于混淆梯度的防御模型,使用BPDA方法完全攻击6种、部分攻击1种.BPDA的出现证明目前大部分基于梯度掩蔽的防御模型都有脆弱性,如何构造具有高鲁棒性的防御网络依旧是一个值得研究的问题.
2.7 其他生成技术
基于对抗样本的可迁移性的对抗样本生成技术,可以实现黑盒攻击.这类技术主要有:替代黑盒攻击(substitute blackbox attack, SBA)[22]、零阶优化(zeroth order optimization, ZOO)[23]、边界攻击(boundary attack, BDA)[24]等.
考虑到对抗样本的普遍适用性,生成与输入无关的通用扰动,实现跨类别的扰动迁移,这类技术有:通用对抗性扰动(universal adversarial pertur-bation, UAP)[12]、无数据UAP[25].考虑到扰动最小化的技术有单像素攻击(one-pixel attack, OPA)[26].
对抗攻击目标不是分类器而是生成模型的技术有:变分自动编码器(variational autoencoder, VAE)攻击[27]等.
针对语义图像分割和对象检测模型的攻击有:密集攻击者生成(dense adversary generation, DAG)[28]、Houdini攻击[29]等.
结合GAN的生成技术有:对抗转化网络ATN[30],Adv-GAN[31]等.
3 对抗样本检测与防御技术
对抗样本检测与防御技术分为检测与防御2部分,检测技术可以分为特征学习、分布统计、输入解离这3类,防御技术可以分为对抗训练、知识迁移、降噪这3类,如图5所示:
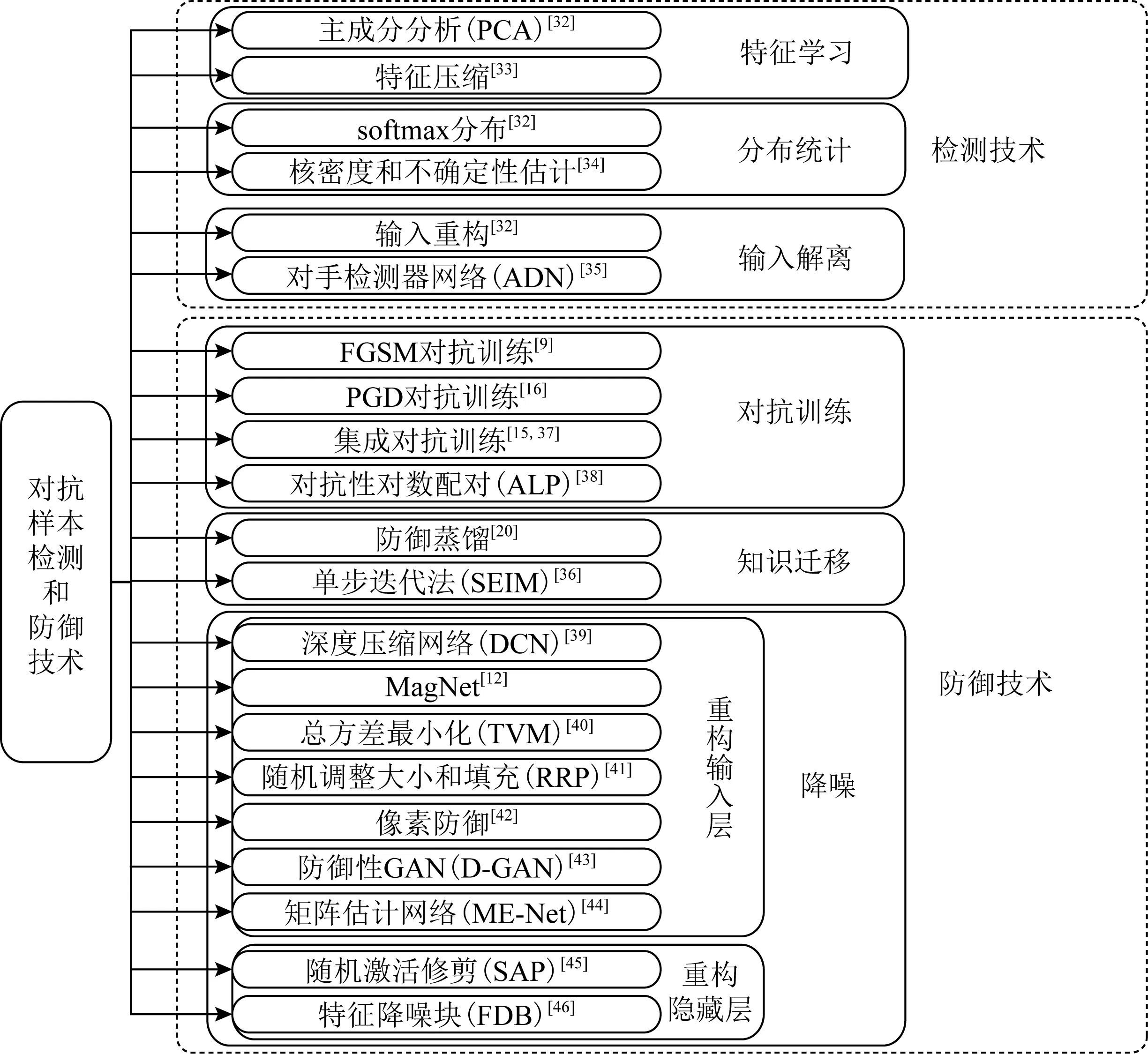
Fig. 5 Generalization of detecting and defense technology of adversarial examples图5 对抗样本检测与防御技术总览
检测技术从早期的探索对抗样本与原始样本的特征或数字特征之间的区别,到近期的与防御技术相结合,通过解离输入将输入的某个特征或某部分作为检测器的输入,从而检测出对抗样本.
最早的防御技术是对抗训练,但对抗训练依赖于训练数据集,所以会产生过拟合问题,可以通过知识迁移提升模型泛化能力.降噪是近期热门的防御技术,但降噪依赖于梯度掩蔽,这一问题尚未得到解决.
3.1 特征学习
特征学习主要用于对抗样本检测,这种方法基于对抗样本与原始样本的不同特征,通过降维将高维的复杂数据转化为低维数据,从而降低检测难度.
1) 主成分分析(principal components analysis, PCA)[32].PCA通过对信息量较少的维度进行特征学习,加上白化操作降低数据的冗余性.实验发现,对抗样本会异常强调PCA中排名较低的主要成分,因此可以通过PCA成分来检测对抗样本是否存在.这种方法可用于检测MNIST,CIFAR10和Tiny-ImageNet上的FGSM[9]和BIM[13]对抗样本,但前提是攻击者不了解该防御措施,否则就可以绕过检测.
2) 特征压缩[33].Xu等人[33]认为输入的特征维数越大,产生的攻击面越大,因此可以通过压缩特征来检测对抗样本.类似于PCA[32]方法,特征压缩的目的是从输入中删除不必要的特征.特征压缩方法独立于其他防御模型,且特征压缩不是完全可靠的防御手段,因此和其他防御技术结合使用性能更好.
3.2 分布统计
分布统计的核心思想是利用对抗样本与原始样本的不同数字特征,通过检测输入是否符合原始样本的分布,从而判断输入是否具有对抗性.
1) softmax分布[32].许多分布外样本与分布内样本具有不同的softmax输出向量,因此通过检测对抗样本的softmax分布,可以检测图像是否具有对抗性.不足之处在于此方法仅适用于输入对抗样本即停止的特定攻击,且预测置信度较低.在种类过多的数据集上(如ImageNet),softmax概率并不十分准确.
2) 核密度和不确定性估计.Feinman等人[34]基于对抗样本不存在于非对抗性数据流形内部的假设提出了2种执行对抗性检测的方法:内核密度和贝叶斯不确定性估计.内核密度通过密度估计值KDE(x)是否小于阈值来判断输入x是否具有对抗性.贝叶斯不确定性估计在检测过程中通过Dropout执行随机遍历,从而量化网络的不确定性.
3.3 输入解离
输入解离是一种检测与防御相结合的方式,核心思想是通过分解输入,将其的某个特征或某部分作为检测器的输入,从而检测出对抗样本.
1) 输入重构[32].最早提出通过重构输入并进行分析来检测对抗样本这一想法的是Hendrycks等人[32].方法通过创建一个检测器网络完成检测,该检测器网络将输入重构,将样本的对数和置信度分别作为输入,输出为对抗性输入的概率.其训练数据包含对抗样本和原始样本.在MNIST数据集上,该方法可以检测FGSM和BIM攻击.但在白盒设置下,攻击者仍能找到对抗样本.
2) 对手检测器网络[35].Metzen等人[35]使用一个检测器子网络(adversary detection network, ADN)来增强DNN.ADN是一个二进制网络,将分类器隐藏层的某层输出作为输入,从而区分原始样本和对抗样本.作者在CIFAR10和ImageNet的10类子集中通过ADN训练DNN,成功训练出高精度检测对抗扰动的检测器网络.为了使检测器能够适应未来的攻击,作者在ADN中加入生成对抗样本的过程.在CIFAR10和ImageNet的10类子集中进行评估,该方法对FGSM[9],DeepFool[17],BIM[13]攻击有效,但检测C&W攻击[19]时有较高的错误率.
3.4 对抗训练
对抗训练法的核心思想在于将对抗样本加入模型训练集,从而提升模型的鲁棒性.不同对抗训练之间的差异主要在于生成训练数据的方式,因此产生数据集依赖,可以通过知识迁移技术提升模型的泛化能力.
1) FGSM对抗训练.FGSM对抗训练[9]是最早的对抗样本防御技术,核心思想是将对抗样本加入训练集训练分类器,从而提高模型的准确性.Goodfellow等人[9]在提出FGSM方法的同时,提出将对抗样本作为输入训练分类器,即最早的FGSM对抗训练.对抗训练是在模型中引入正则化:
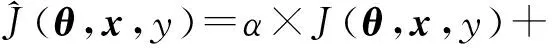
(7)
这类防御技术对训练数据具有依赖性,因此对未训练过的数据类型仍有很高的误分类率.例如:单步FGSM对抗样本[9]训练出的模型无法抵抗BIM[13]对抗样本的攻击.近期有研究提出单步迭代法(single-step epoch-iterative method, SEIM)[36],通过知识迁移的方式来提升模型的泛化能力.
2) PGD对抗训练.PGD对抗训练[16]的提出针对有最大损失化函数的对抗样本,通过对此类对抗样本的优化,使损失函数达到最小化.
PGD类似BIM[13],通过多次小步迭代产生对抗样本,不同之处在于PGD多了一层扰动的随机处理,并且在迭代次数上远远多于BIM.
PGD对抗训练的目标函数是:
(8)
随机处理和迭代次数的增加,使得PGD对抗训练的性能优于BIM[14],在较弱的黑盒攻击下,PGD对抗训练使得网络在MNIST和CIFAR10数据集上的准确率分别超过95%和64%.
3) 集成对抗训练.多个弱防御的简单集成并不能形成强防御,因这一发现,Tramèr等人[15]提出集成对抗训练,模型对黑盒攻击产生了极大的防御性.集成对抗训练使用标准风险最小化的对抗样本:
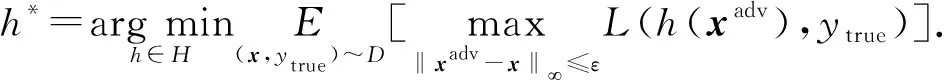
(9)
集成对抗训练是通过从其他模型传递来的扰动来增强训练数据的技术.这样训练的原因在于文献[15]的作者从直觉上认为,作为对抗样本在模型之间的传递,在外部模型上制作的扰动是对式(9)中最大化问题的良好近似[37].集成对抗训练对黑盒攻击有较强的鲁棒性,是目前最有效的对抗训练方法之一.
4) 对抗性对数配对(adversarial logit paring, ALP).ALP[38]鼓励对抗性和非对抗性输入对之间的对数近似.ALP引入正则化方法,对由PGD攻击生成的原始样本和对抗样本的对数差异进行惩罚.对数配对有2种策略:对抗对数配对ALP和干净对数配对(clean logit paring, CLP).ALP使用原始样本和对抗样本作为输入对,CLP则使用不同类别的原始样本.ALP以PGD对抗训练为基础,但足够多步的PGD迭代会导致ALP对抗训练性能下降,而单独使用CLP则会导致对抗性增强.
3.5 知识迁移
知识迁移是一种能提升网络泛化能力的技术,通过训练数据集以外的样本来平滑训练过程中学到的模型.最早运用这种技术的是Hinton等人[20]提出的防御蒸馏网络[21],近期提出的SEIM方法[37]也用到了这一技术.
1) 防御蒸馏.Hinton等人[20]提出的防御蒸馏是一种将知识从深度神经网络集成到单个神经网络的防御方法.为了降低模型对数据的依赖性,提升泛化能力,防御蒸馏首先按照正常的方式训练分类网络,然后用从初始网络中学到的概率向量训练另外一个完全相同架构的蒸馏网络,如图6所示:
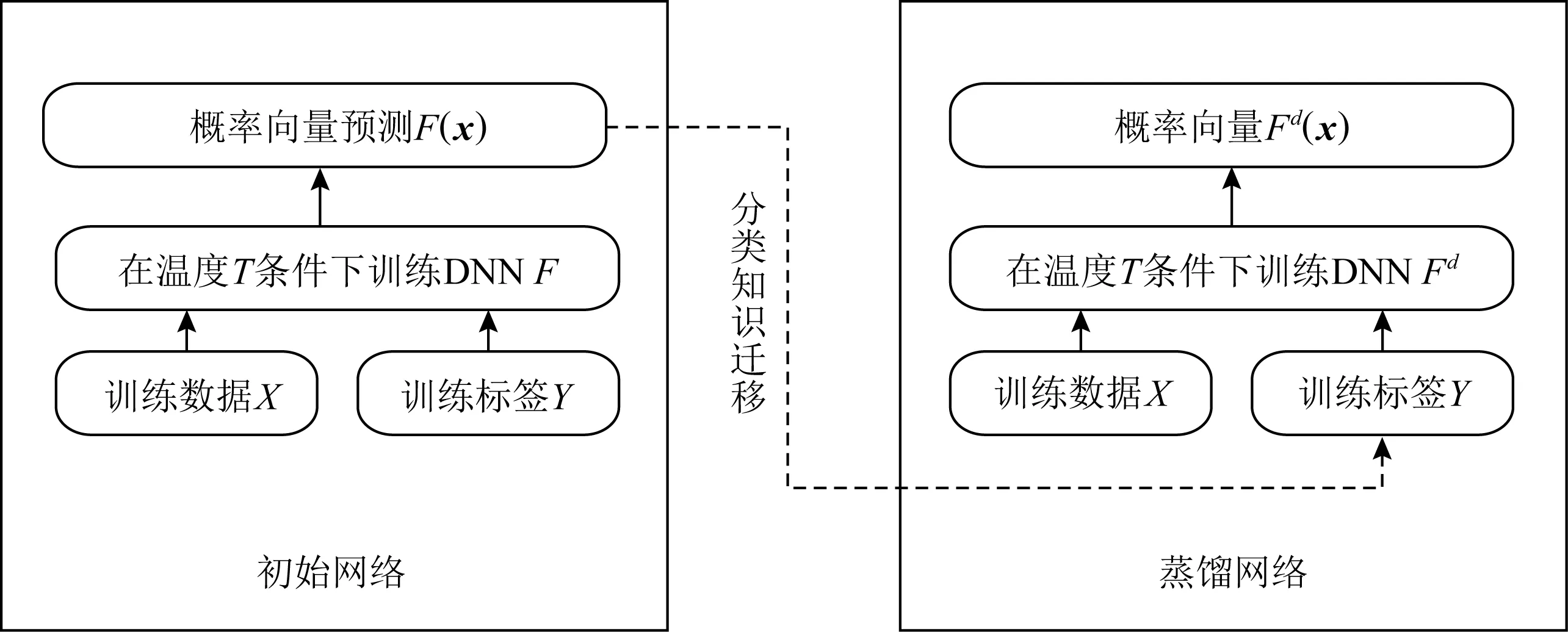
Fig. 6 The mechanism of defending distillation图6 防御蒸馏工作机制
防御蒸馏在输出层使用改进的函数Softmax训练初始网络,其中温度T为超参数:
(10)
作为早期的防御方法,防御蒸馏使用知识迁移的方法降低DNN的维数,在保持原始DNN准确率的同时,能够将MNIST数据集上对抗样本致错的成功率降到0.5%,CIFAR10数据集上降到5%,提升了网络的泛化能力和防御对抗性干扰的能力,但是后续出现的C&W攻击可以完全攻击防御蒸馏网络.
2) 单步迭代法.SEIM[36]为了解决对抗训练对数据集的依赖性问题,利用连续的训练回合来模拟多步迭代方法产生对抗样本的过程.
如图7、图8所示,多步迭代生成对抗样本时,每一回合中对抗样本生成器的输入均为原始样本;而在SEIM的中间回合中,上一轮生成的对抗样本将作为下一轮的输入.

Fig. 7 Single-step or iterative adversarial training图7 单步或迭代对抗训练
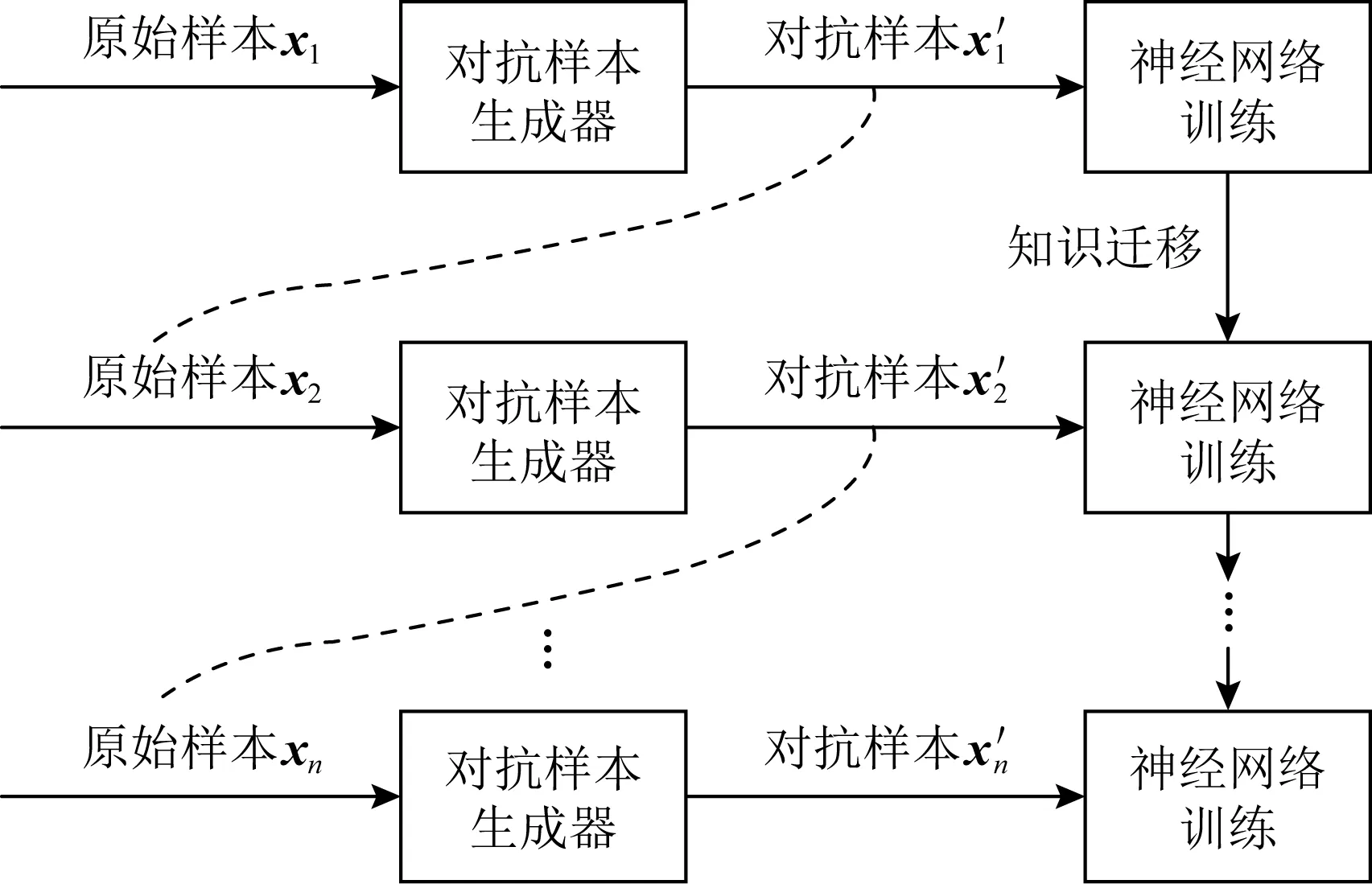
Fig. 8 Single-step epoch-iterative adversarial training图8 SEIM对抗训练
SEIM通过知识迁移提高模型的泛化能力,防御性优于现有的单步迭代式对抗训练.
3.6 降 噪
降噪的核心思想是:通过对对抗样本施加变换,破坏添加的噪声,从而消除扰动的影响,提高分类器的准确性.根据神经网络的结构,降噪法可以2次细分为输入层降噪和隐藏层降噪2类,但无论是哪种降噪方法,都依赖于梯度掩蔽,这也意味着目前基于降噪技术的防御方法对BPDA等攻击方式都显示出脆弱性.
输入层降噪的思想是在输入层对样本进行转换操作,常见的有图片裁剪或缩放、位深度缩减、JPEG压缩、总方差最小化等.
1) 深度压缩网络(deep contractive network, DCN)[39].通过破坏附加噪声并使用降噪自动编码器(denoising autoencoder, DAE)对输入进行预处理以去除对抗样本的影响.
实验结果表明DAE可以消除大量的对抗扰动,但当DAE和原始DNN堆叠,网络会受到新的对抗样本的攻击.基于此,文献[39]的作者提出了深度压缩网络DCN,模型重新构建端到端训练程序,包括受压缩自动编码器(contractive autoencoder, CAE)启发的平滑度损失.
DCN方法是最早的防御方法之一,Gu等人[39]实验评估了针对L-BFGS的防御策略,攻击者仍然能够找到使DCN误分类的对抗样本,但与攻击原始模型相比,攻击DCN的代价更大.
2) MagNet[12].类似于ADN[35]检测,MagNet由2部分组成:检测器和重整器,如图9所示,两者都经过训练以构造原始样本.
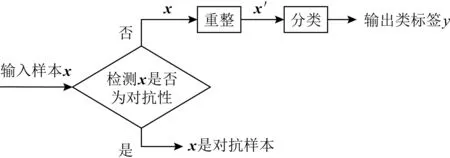
Fig. 9 The mechanism of MagNet图9 MagNet工作机制
检测器按照误差阈值,通过测量重建误差来检测对抗样本.重整器是在正常样本上训练得到一个自动编码器,无论是原始样本还是对抗样本输入,自动编码器都能将其输出为一个原始样本近似的样本.
MagNet在抵御黑盒攻击方面非常有效,但在白盒攻击中,因攻击者也了解检测器和重整器的参数,其防御性降低.
3) 总方差最小化(total variance minimization, TVM)[40].TVM通过引入随机性使图像不可微,使攻击者难以计算梯度.TVM的图像转换操作是从输入中随机选择像素并执行迭代优化来查找颜色与随机选择的像素一致的图像.目标函数为

(11)
TVM对FGSM[9],DeepFool[17],C&W[19]攻击具有鲁棒性,但因为要解决每个输入的优化问题,因此模型的运行速度变慢.
4) 随机调整大小和填充(random resizing and padding, RRP).RRP[41]最大可能引入了随机性,通过2层(调整层和填充层)随机操作破坏梯度.
对于所有的输入,RRP在调整层生成若干个随机大小的图片,再在填充层对这些图片进行随机像素填充并随机返回几个填充后的图像.填充后的图像,被随机选择一个进入CNN分类器.RRP对各种白盒攻击有良好的防御性,且当随机调整大小和填充的空间足够大时,将大大提高攻击者的计算成本.但RRP依赖于梯度掩蔽,能够被BPDA等方法攻破.
5) 像素防御[42].通过模拟原始样本的分布,将所有输入映射成原始样本的分布再输入分类器.这类似于MagNet思想,不同在于像素防御单个模型同时充当检测器和重整器.像素防御算法的关键在于εdefend设置.εdefend控制的是样本转换的阈值,定义为

(12)
像素防御与其他防御方法最大的不同在于可以控制样本转换的损失值,一定程度上提升了性能.
6) 防御性GAN(defense-GAN, D-GAN)[43].D-GAN利用GAN学习原始样本的分布,将输入样本映射成满足原始样本分布的近似样本,再将处理后的样本输入到分类器进行分类,如图10所示:
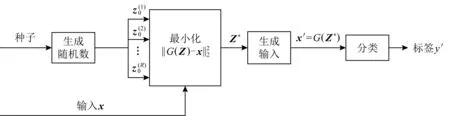
Fig. 10 The mechanism of D-GAN图10 D-GAN工作机制
D-GAN可以用来检测与防御对抗样本,相比MagNet和对抗训练能更稳定.但是,D-GAN的鲁棒性依赖于GAN的性能,使用未训练和调整的GAN,因此D-GAN的性能将降低.
7) 矩阵估计网络(matrix estimation-net, ME-Net)[44].ME-Net也应用了随机性提高梯度掩蔽效率.ME-Net基于矩阵估计,使用随机删除像素和矩阵估计重构2个步骤对图像进行预处理.ME-Net破坏扰动的对抗结构,同时增强了原始图像的全局结构.ME-Net对黑盒攻击和白盒攻击都有很强的防御性,且在一定程度上可以规避BPDA的攻击,同时还可以跟其他模型相结合进一步提升模型鲁棒性.
输入层降噪是对整个图像的转换,隐藏层降噪是对某个隐藏层或某个神经元结点进行操作.
8) 随机激活修剪(stochastic activation pruning, SAP)[45].SAP通过随机丢弃激活值破坏梯度,使基于梯度的攻击失效.SAP类似于Dropout,不同的是,SAP的丢弃概率由激活值大小决定,且SAP重新调整了幸存结点的大小.
SAP与其他降噪方法一样,也显示出了对梯度掩蔽的依赖性,因此,SAP对BPDA等攻击方式没有足够的鲁棒性.
9) 特征降噪块(feature denoising block, FDB)[46].对特征图进行降噪处理,去噪块对输入特征降噪处理,由1×1的卷积层处理,然后通过残差连接添加到块的输入中,如图11所示:
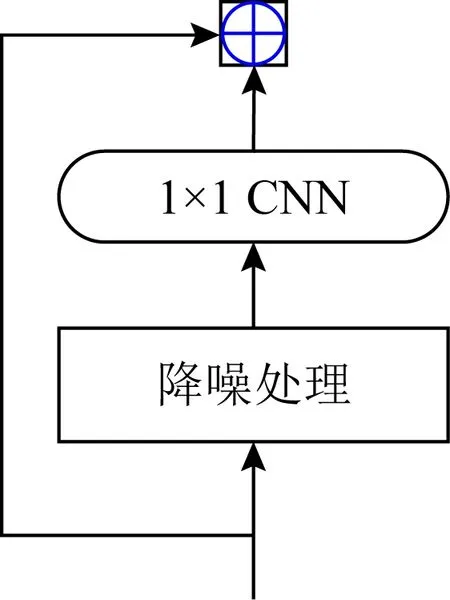
Fig. 11 The mechanism of FDB图11 FDB工作机制
与SAP[45]相比,FDB[46]的关注点不在单个激活值,而在不同的特征块.这在理解对抗样本的特性时或许更有实际意义,也能够避免因零激活值引起的梯度爆炸问题.
10) 综合分析(analysis by synthesis, ABS)[47].ABS既运用了对抗训练的方法,又运用了降噪技术.类似于D-GAN[43]学习样本分布的思想,ABS需要学习所有类别的分布,从而将所有输入都重整映射为符合分布的输出.
ABS方法的主要工具是变分编码器,为每个类别设置一个VAE,对类别的样本分布进行建模.给定一个C类的数据集,通过梯度下降,使得标签y的对数似然下限最大化[47]:
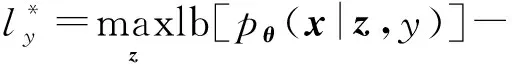
(13)
二进制ABS不能应用于非灰度图像,且每个类别都需要一个VAE近似分布,这使得其在非灰度图像或分类复杂的数据集上应用受限.
4 对抗样本检测与防御技术评价
目前,检测技术的研究因在数理层面对对抗样本缺乏共识而受限.除softmax分布[32]检测法以外,目前检测技术的主要测试样本是FGSM[9]或BIM[13]对抗样本,softmax分布仅适用于输入对抗样本后立即停止的特定攻击.如表1所示,特征压缩[33]的检测范围更广,但当攻击者完全了解检测机制时,可以绕过特征压缩的检测.
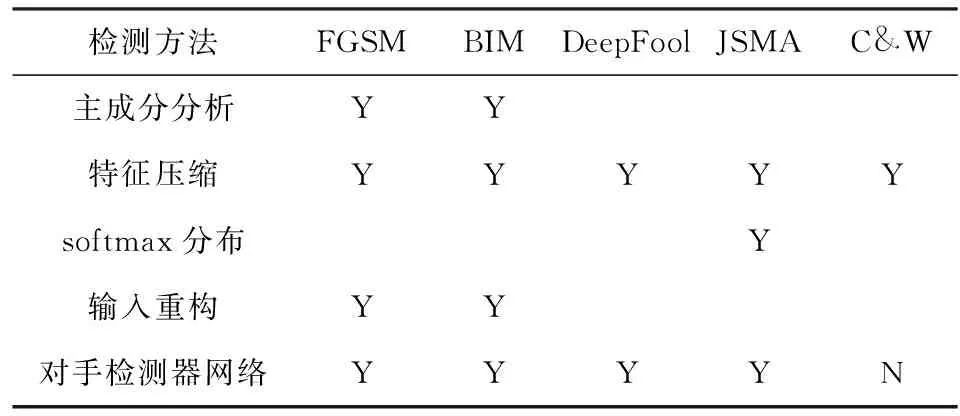
Table 1 The Estimation on Detecting Technology表1 检测技术效果评价
特征学习类的检测技术,如PCA、特征压缩等,使得攻击者只能利用某些主要成分、特征进行攻击,一定程度上限制了攻击.
但这类技术的性能还有待提升.首先,特征的限制并不是越少越好.以PCA为例,将攻击者限制于第1个主成分上的检测是无效的[48].其次,特征学习也不能完全抵御白盒攻击.在测试了26个不同主成分设置的模型后,Carlini等人[48]发现不使用PCA的原始模型比使用了PCA的模型展现出更好的鲁棒性.
相比于主动地提升模型的鲁棒性,对抗样本检测技术的应用有利于提升模型的精度.无论是特征学习还是分布统计类的检测技术,都关注于数据本身,这在一定程度上限制了其防御效果.因此,这2类检测技术的难点在于如何在攻击者知道有检测机制的条件下进行对抗样本检测.考虑到这种情况,检测与防御手段的结合成为新的趋势.
相比检测技术,防御技术的研究更广泛.目前的防御技术主要启发于提升神经网络鲁棒性的2个角度,如图12所示.
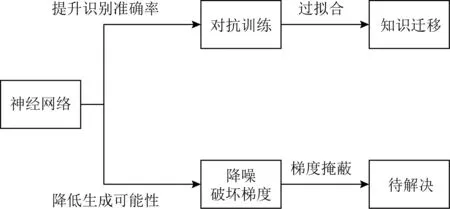
Fig. 12 The evolution of adversarial example defense图12 对抗样本防御技术的演进
1) 提升模型准确率.最直接的想法是将对抗样本作为训练数据训练模型,提升准确率.
对抗训练[9,15-16]中,模型的防御能力与训练数据集有关,通过扩大数据集规模、增加训练数据种类能够提升模型的鲁棒性.
但这会产生过拟合,提升泛化能力成为模型优化的关键问题.实验证明,结合知识迁移,能够缓解模型数据集依赖问题,提高模型泛化能力[15].集成对抗训练作为目前最为有效的对抗训练手段之一,相比其他对抗训练方法,集成对抗训练的泛化能力更强.这是因为集成对抗训练运用了知识迁移技术,集成对抗训练所选择的扰动是由其他模型迁移而来.
2) 降低攻击成功率.鉴于现有攻击大多依赖于梯度,最直接的降低攻击成功率的策略是通过降噪破坏梯度.但这也带来了防御模型依赖于梯度掩蔽这一尚未解决的问题.表2展示了经典的防御技术的防御效果.

Table 2 The Estimation of Defending Technology表2 防御技术效果评价
随机性在防御模型中的应用广泛.在对抗训练中,PGD对抗训练[16]增加了迭代次数并引入一层随机性,其最好的MNIST模型可以实现89%以上的准确性,甚至可以抵抗白盒的迭代对抗攻击.在较弱的黑盒攻击下,MNIST和CIFAR10网络的准确率分别超过95%和64%.在降噪类防御中,RRP[41],ME-Net[44],SAP[45]都使用了随机性,从结果来看,对输入层降噪能够抵抗的攻击范围更广.
结合检测技术来看,处理特征的模型比处理激活值的模型鲁棒性更好,在应用中也更有实际意义.
表3展示了不同检测与防御类别的比较.检测方法更偏向于数据驱动,在攻击者了解检测机制的条件下,能够通过对数据的处理绕过检测.因此,检测、防御相结合的方式是研究趋势.防御方法围绕提升模型准确率和降低攻击成功率这2方面展开,在防御中降低数据依赖性、提升模型泛化能力以及提升对高强度攻击的抵抗性依旧是亟待解决的问题.

Table 3 Comparison of Different Types of Detecting and Defending Technologies表3 不同检测与防御技术的比较
5 总结与展望
本文介绍了对抗样本生成攻击技术、检测与防御技术,生成攻击倾向于黑盒攻击的研究,是因为黑盒攻击更具有现实意义.
相比生成技术,检测与防御技术具有滞后性,因此防御方法往往会受到特定的攻击.早期生成技术基于梯度,现有的防御技术基于梯度掩蔽,而BPDA等引入近似性的生成技术则能够攻击基于梯度掩蔽的防御技术.
鉴于检测与防御技术的滞后性,目前研究的难点在于:首先是提升自适应性,现有的防御方法大都针对已有的攻击,不能保证对未知攻击的鲁棒性.其次是扩大防御范围,现有的防御方法无法防御多种类型的攻击.
针对这个难点,有研究将其他现有的算法用来进行对抗攻击和防御,例如:强化学习[49]或元学习[50]等.还有研究通过研究神经网络的特性来探寻对抗样本的成因与防御[51-52].例如:Geirhos等人[51]发现卷积神经网络强调纹理特征,增加形状权重能够改善模型的鲁棒性.Zhang等人[52]的工作进一步表明,对抗训练模型更强调形状特征或边缘特征而非纹理特征.
本文重点关注了图像领域的对抗样本检测与防御技术,但对抗样本在文字、语音等领域也存在,这也是未来可能的研究方向.
作者贡献声明:张田负责相关文献资料的收集、分析和论文初稿的撰写;杨奎武提出综述思路并指导论文撰写与修改;魏江宏针对研究现状讨论提出修改意见并指导修改;刘扬和宁原隆负责图表整理与论文校对.
猜你喜欢
数学物理学报(2022年4期)2022-08-22 04:06:36
数学物理学报(2021年6期)2021-12-21 06:24:38
应用数学(2020年2期)2020-06-24 06:02:50
数学物理学报(2019年4期)2019-10-10 02:38:56
数学年刊A辑(中文版)(2018年2期)2019-01-08 01:59:52
电子测试(2018年1期)2018-04-18 11:52:35
贵州师范学院学报(2016年3期)2016-12-01 03:53:52
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
电源技术(2015年11期)2015-08-22 08:50:38
