
领域对齐对抗的无监督跨领域文本情感分析算法
2022-06-09 14:57:42贾熹滨胡永利
计算机研究与发展 2022年6期
贾熹滨 曾 檬 米 庆 胡永利
1(北京工业大学信息学部 北京 100124) 2(多媒体与智能软件技术北京市重点实验室(北京工业大学) 北京 100124) 3(北京人工智能研究院(北京工业大学) 北京 100124)
随着互联网的迅速发展和社交媒体平台的快速普及,包含个人情感倾向的文本评论数据大量产生,文本情感分析技术(sentiment analysis)应运而生.该技术采用有监督学习的方式,利用标定样本训练文本情感分类模型,实现了对评论数据情感倾向的自动判别[1].目前文本情感分析技术被广泛地应用在舆情监测[2]、智能客服[3]、社交网络情感分析[4]等实际业务场景中,该技术实现了对舆情信息的及时把控和商业价值的有效挖掘.然而全新的产业领域层出不穷,未标定的文本数据日益剧增,为一个新领域重新标定大量的训练数据并学习全新的情感分类模型无疑费时费力.
因此,学术界提出了领域自适应(domain adap-tation)方法[5]以减轻数据标定的负担.领域自适应是迁移学习(transfer learning)的一条分支,其目标是利用标定的源领域数据训练一个分类性能良好的源领域模型,并将该模型迁移到少量标定甚至无标定的目标领域数据[6],以完成跨领域情感分析任务.
然而,源领域模型无法直接迁移到目标领域,其原因在于跨领域文本数据在包含部分公共信息的同时,也具有大量的领域专有信息.该专有信息将导致领域偏移问题(domain shift),使源领域模型无法拟合目标领域数据.例如2个领域都共享“好”“不错”“质量不佳”等通用型描述词,在跨领域情感分析任务中,这类词汇有助于挖掘领域不变信息.但是各领域也存在专有的描述词汇,如在书籍评论中,通常采用“生动”“不易理解”“有趣”等描述词汇.在电子产品评价中,通常采用“便携”“顺滑”“性能卓越”等领域专有描述词,这些词汇导致了跨领域文本数据的分布差异.
因此,为了解决跨领域情感分析任务中的领域偏移问题,研究者提出了2类解决方案:1)提取领域不变特征,其中包括基于特征选择[7-9]和基于领域对抗学习的领域自适应算法[10-11];2)减小领域专有特征差异,包括基于分布自适应[12-15]和基于子空间学习的领域自适应算法[16-21].目前主要采取一种解决方案缓解领域偏移问题.然而实际上跨领域文本数据同时包含领域不变信息和领域专有信息,且2种信息的占比不定.因此本文拟在提取领域不变特征的同时,减少领域专有特征差异,以提升现有跨领域情感分析算法的迁移性能和分类性能.
为此,本文提出了一种领域对齐对抗的无监督跨领域文本情感分析算法(domain alignment adversarial unsupervised cross-domain text sentiment analysis algorithm, DAA).该算法以渐进式的迁移策略学习跨领域知识,依次构建了特征提取模块、领域对齐模块和领域对抗模块.首先经由特征提取模块将源领域和目标领域数据映射到公共的子空间,再将源领域和目标领域特征输入领域对齐模块和领域对抗模块.在领域对齐模块中,本文基于对跨领域文本数据差异度量完备性和计算复杂性的考虑,引入了中心矩差异构建领域一致性约束以减小领域专有信息差异.其次,在领域对抗模块中,本文基于领域对抗学习的领域自适应算法,构造了领域判别器和梯度反转层(gradient reversal layer, GRL)[10],通过领域对抗学习的方式使领域判别器无法判别数据的领域类别,以提取领域不变特征.最后,本文通过协同优化的训练方式,使网络在提取领域不变特征的同时,减小领域专有特征差异.
本文的主要贡献有3个方面:
1) 提出了一种领域对齐对抗的无监督跨领域文本情感分析算法.该算法通过渐进式的迁移策略实现了领域知识的迁移,即在底层特征提取层共享参数,以完成底层文本特征到公共语义空间的映射,并进一步在高维语义空间通过领域对齐模块和领域对抗模块协同优化的方式,迭代地减小领域差异.
2) 考虑到跨领域文本数据同时包含领域不变特征和领域专有特征的特点,本文分别在领域对齐模块和领域对抗模块,构造领域一致性约束和领域不变性约束.并在训练过程中通过协同优化的训练方式优化这2种约束,以提升跨领域文本情感分析算法的迁移性能.
3) 为了证明本算法在跨领域文本情感分析任务中的分类性能和迁移性能,本研究在2个标准的亚马逊跨领域情感分类数据集上进行了24组实验,包含12组区分积极、消极情感的2分类实验和12组区分积极、中性、消极情感的3分类实验.实验结果显示,本算法在24组跨域情感分类任务中的平均分类准确率都超过了最先进的模型.其次为了进一步验证本算法的迁移性能,本研究分别从定量分析和定性分析2个角度,分析迁移前后的Proxy A-distance和特征分布图.实验结果显示即使当2个领域存在较大的领域差异时,本算法依然展现出显著的迁移性能.
1 相关研究工作
目前,领域自适应算法主要被划归为4类:基于特征选择、基于领域对抗学习、基于数据分布对齐和基于子空间学习的领域自适应算法.前2种方法从提取领域不变特征的角度进行迁移,后2种方法通过减小领域专有特征差异的方式进行迁移.
1.1 基于特征选择的领域自适应算法
在早期工作中,大多数研究者主要采用基于特征选择的领域自适应算法,通过学习源领域和目标领域的公共特征的方式减小领域差异.
结构对应学习(structural correspondence learning, SCL)[7]是较早被提出的跨领域文本情感分析算法,该算法通过奇异值分解的计算过程,预测在领域间频繁出现且表现相似的枢纽特征(pivot features),以建立不同领域间特征的对应关系.Blitzer等人[8]进一步对SCL进行改进,通过源领域标签出现的频率和互信息预测枢纽特征.Pan等人[9]提出的谱特征对齐算法(spectral feature alignment, SFA)构建了领域专有特征的二分图,并基于图谱理论的谱聚类算法,将连接到共有领域无关特征的领域专有特征映射到公共特征子空间中.Bollegala等人[22]通过挖掘领域间共性的情感表达方式创建情绪敏感词库,以获取不同领域间单词的相关性,并采用该词库在2分类器中扩展特征向量表示训练模型.Bollegala等人[5]通过挖掘源领域标定信息、领域间公共特征的分布式属性、领域间无标定样本的局部几何信息,构造词嵌入表示模型,以学习源领域和目标领域间的枢纽特征.Xi等人[23]提出的基于类别注意力网络与卷积神经网络的模型(category attention network and convolutional neural network based model, CAN-CNN)将类别注意力网络作为核心模块,使网络关注有助于分类器判别的类别特征,以提取源领域和目标领域的可迁移特征.Zhang等人[24]提出的分层注意力生成对抗网络(hierarchical attention generative adversarial networks, HAGAN)通过分层注意力机制,自动提取枢纽特征与非枢纽特征.
综上,基于特征选择的领域自适应算法的关键在于学习领域不变特征,因此该类算法适合源领域和目标领域包含较多公共特征的迁移任务.
1.2 基于领域对抗学习的领域自适应算法
随着生成对抗网络(generative adversarial net-work, GAN)的提出,基于领域对抗学习的领域自适应算法受到了研究者们的广泛关注.
Ganin等人[10]提出的领域对抗神经网络(domain-adversarial neural networks, DANN)将生成对抗思想应用于迁移学习领域.该研究提出的领域对抗算法直接构造了领域判别器,并在反向传播过程中配合梯度翻转层,令该判别器无法判定样本的领域来源,以提取领域不变特征.Tzeng等人[11]提出的对抗判别领域自适应算法(adversarial discriminative domain adaptation, ADDA),利用领域判别器判别样本领域来源的同时,在固定源领域特征提取器的基础上,为目标领域额外训练特征提取器,以保证2个领域提取到相似的特征.
随后,研究者们在DANN和ADDA的基础上进行改进.Sankaranarayanan等人[25]在领域分类分支下同时构建了生成器与判别器,通过源领域和目标领域样本生成伪样本,并将真实样本和伪样本同时输入判别器,并采用对抗学习的训练方式提取领域不变特征.Volpi等人[26]以加噪的方式增强特征表示,使训练过程更鲁棒,并且令源领域和目标领域共用一个特征提取器,以提取领域不变特征.Long等人[27]提出的CDANs(conditional domain adversarial networks)通过计算特征与预测标签概率向量的互协方差以提升分类器的判别性.Saito等人[28]使用2个独立的分类器,通过迭代地最大最小化2个分类器的判别矛盾区域,间接优化领域的决策边界.Lee等人[29]提出DTA(drop to adapt)以正则化的思想,针对卷积层和全连接层设计了2种dropout机制,使决策边界穿过目标领域的低密度区域,以提升迁移模型的泛化性能.Zhang等人[30]提出的SymNets(domain-symmetric networks)将源领域类别分类器和目标领域类别分类器拼接成联合的分类器,在预测标签类别的同时对预测结果加和,隐性地构建领域判别器.针对源领域标签空间是目标领域标签空间的子集时,直接将源领域分类器迁移到目标领域可能会出现负迁移的问题,Zhang等人[31]提出的选择对抗网络(selective adversarial network, SAN)构造了2个领域判别器:第1个判别器为相关的源领域样本赋予权重,第2个判别器将源领域加权数据和目标领域数据作为特征判别器的输入.不同于Zhang等人[30]提出的为样本加权的操作,Cao等人[32]提出的SAN(selective adversarial network)设计了实例级别和类别级别的2种判别器加权机制,从而同时减弱甚至消除不相关样本和不相关类别的影响.
还有研究者结合各个领域自适应算法的优势,提出了融合多种迁移策略的领域对抗学习算法.Qu等人[33]提出的对抗类别对齐网络(adversarial category alignment network, ACAN),在衡量跨领域数据底层特征边缘分布差异的同时,最大化2个领域同类别特征的平均绝对差值,并在优化生成器时最小化平均绝对差值,进而增强领域间的类别一致性.Cao等人[34]提出的对称对抗迁移网络(symmetric adver-sarial transfer network, SATNet)为源领域和目标领域分别构造分类器,并通过优化类别级和领域级的对齐损失,增强类别级领域不变特征的学习.
综上,领域对抗学习适用于源领域和目标领域有大量领域公共特征的情况,其优势在于简洁的迁移过程,只需采用对抗学习的方式优化领域判别器,即可提取领域不变特征.
1.3 基于数据分布对齐的领域自适应算法
当源领域和目标领域仅包含部分公共特征,而领域专有特征表示较为显著时,一般采用基于数据分布对齐的领域自适应算法.具体划分为基于边缘分布对齐、基于条件分布对齐和基于联合分布对齐的领域自适应算法.
当假设2个领域的边缘分布差异较大时,通常采用基于边缘分布对齐的领域自适应算法.Pan等人[12]提出的TCA(transfer component analysis)在再生核希尔伯特空间下利用最大均值差异(maximum mean discrepancy, MMD)度量跨领域数据的边缘分布差异.Gretton等人[13]在文献[12]研究的基础上提出多核MMD(multi-kernel maximum mean discrepancy, MK-MMD),通过构造多核加权的MMD提升单核的表征能力.Long等人[14]在深度网络中构建多层MK-MMD的领域差异度量约束,增强特定任务层中特征的迁移能力.Zellinger等人[15]提出中心矩差异(central moment discrepancy, CMD)通过显性地刻画领域间的高阶中心矩差异,度量领域间的边缘分布差异.
基于条件分布对齐的领域自适应算法通常假设领域间的条件分布概率存在一定差异.Gong等人[35]在协变量分布和目标领域条件分布都发生变化的情况下,通过学习领域间条件概率中保持不变的条件转移成分(conditional transferable components),实现源领域到目标领域的迁移.Xie等人[36]通过对齐标定源领域数据的中心和包含伪标签的目标领域中心的方法,学习迁移任务中的语义信息,以减小同类但不同领域特征的差异.传统的无监督领域自适应方法通过对齐领域分布差异的方式进行迁移,但是这种方式破坏了目标领域数据判别性的内在结构.因此为了保持目标领域数据内在的判别性,Wang等人[37]提出了基于结构预测的伪标签选择算法(structured prediction based selective pseudo-labeling),该算法将预测结果可信的目标领域标签作为下一轮迭代中特征对齐网络的输入,进而对齐特征的条件概率分布.类似地,Tang等人[38]提出的SRDC(structurally regularized deep clustering)基于判别性聚类的深度网络,利用KL散度(Kullback-Leibler divergence)最小化目标领域预测标签分布和引入辅助标签分布之间的距离,以目标领域数据的分布推测目标领域伪标签,并依靠源领域数据的真实标签形成辅助分布,通过联合网络训练策略,保证目标领域内在的判别性.Zhu等人[39]针对全局领域迁移难以学习特征结构的问题,提出了局部最大化均值差异(local maximum mean discrepancy, LMMD).该距离度量函数根据样本所属类别,在度量领域经验分布核均值嵌入的希尔伯特施密特范数(Hilbert-Schmidt norm)的同时,根据预测标签的概率向量为源领域和目标领域样本赋予权重,并对齐领域间相关子领域的数据分布.
假设领域间联合概率分布存在一定差异时,通常采用基于联合分布对齐的领域自适应算法,即综合考虑边缘分布对齐与条件分布对齐.Long等人[40]提出了基于联合分布对齐的迁移算法(joint distri-bution adaptation, JDA),该算法参考了Pan等人[12]提出的TCA,构建了针对边缘分布对齐的损失函数,计算目标领域的伪标签,并利用贝叶斯公式逼近条件概率以实现条件分布自适应,最后经过多轮的迭代获取精度较高的伪标签,间接提升领域迁移性能.Tahmoresnezhad等人[41]在减小边缘分布和条件分布的同时,构造了类内距与类间距约束,以提升源领域分类器向目标领域数据迁移的拟合能力.由于不同的特定任务层各侧重于不同的数据分布对齐,Long等人[42]提出的JAN(joint adaptation networks)基于联合最大均值差异策略(joint maximum mean discrepancy, JMMD),通过对齐多层的联合分布差异,实现领域知识的迁移.
1.4 基于子空间学习的领域自适应算法
基于子空间学习的算法将源领域和目标领域从2个不同的子空间,经由映射矩阵投影到全局的公共子空间,并进行领域重构.对于基于线性函数映射的子空间学习算法,Fernando等人[21]提出的SA(subspace alignment)直接为源领域计算线性变换,令投影后的源领域数据的概率分布近似目标领域数据.Sun等人[18]提出的CORAL(corelation alignment)通过学习二阶特征变换,对齐源领域和目标领域的二阶协方差矩阵信息.除了上述线性的函数映射外,还有研究者采用非线性映射实现样本到特征子空间的投影.Glorot等人[16]所提出的堆叠降噪自编码器(stacked denoising auto-encoders, SDA),通过构建非线性编码器学习映射矩阵.Chen等人[17]提出的边缘堆叠降噪自编码器(marginalized stacked denoising auto-encoders, mSDA)在SDA的基础上进行改进,以闭式求解代替随机梯度下降进行参数的更新.Aljundi等人[19]提出的基于标记的子空间对齐方法从2个领域中选择标记以最大化领域重叠信息,并利用高斯核投影将源领域和目标领域样本映射到公共子空间,以学习新的领域特征表示.Bousmalis等人[20]提出的领域分离网络(domain separation network, DSN)通过最小化源领域和目标领域之间的相似性损失和约束重建损失,获取领域不变特征,同时利用正交约束将私有和共享的表示分量分开以获取领域专有特征.Bermúdez-Chacón等人[43]提出的多分支网络(multibranch networks)通过加权组合操作集成多条分支,自动地为各领域构建描述领域性质的特征提取网络结构,并将经过多分支网络提取的源领域和目标领域特征输入领域判别器,以提取领域不变特征.
总之,经由子空间投影后,在源领域数据分布与目标领域数据分布相互匹配的全局子空间下,源领域分类器对目标领域数据具有更好的分类性能.
1.5 本文研究动机
跨领域文本情感分类任务具有2个显著特征:
1) 不同语义层次的特征具有不同程度的领域差异,具体反映在低层特征的领域差异集中在文本特征表示上,而高层特征的差异体现在更为抽象的语义信息中.因此,多层渐进式的迁移策略有助于促进跨领域文本情感分类任务中的知识迁移过程.
2) 在实际的跨领域情感分析任务中,数据同时包含领域专有信息和领域不变信息,且2种信息的占比难以确定,因此考虑到迁移模型泛化性,探究领域一致性约束和领域不变性约束的协同优化方法对知识迁移的影响,同样是跨领域文本情感分类任务中的研究重点之一.
因此,基于跨领域文本情感分类任务中的2个特点,本研究结合文献[10,15]的优势,提出一种领域对齐对抗的无监督跨领域文本情感分析算法.
2 领域对齐对抗的无监督跨领域文本情感分析算法
本节主要介绍领域对齐对抗的无监督跨领域文本情感分析算法DAA.
2.1 基本定义
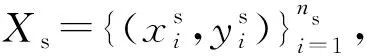

(1)
本文提出了一种协同优化的领域自适应算法以最小化领域差异损失.该算法由2部分组成:1)通过领域对抗学习的方式提取领域不变特征;2)通过基于数据分布对齐的领域自适应算法计算领域间的分布差异.
目前,基于数据分布对齐的领域自适应算法通常采用KL散度[44]、MMD[12]及MK-MMD[13]等标准分布度量函数计算领域差异.但是KL散度仅仅在一阶矩下度量概率分布差异,而MMD及其变体MK-MMD尽管匹配了多阶矩的加权和,但是仍然需要相对较为复杂的核函数计算过程.相比之下,中心矩差异CMD[15]通过显性地刻画领域间的高阶中心矩差异,包括方差、偏度、峰态等,弥补了KL散度、MMD和MK-MMD这3个标准分布度量函数的不足.
定义2.中心矩差异.设X和Y为有界的随机样本,数据分布分别为p和q,其区间为[a,b]N,中心矩差异为

(2)
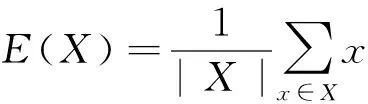
(3)
2.2 算法架构细节
本算法以渐进式的迁移策略,实现了跨领域文本数据的领域知识迁移.网络结构如图1所示,网络主要由3部分组成,包括特征提取模块、领域对齐模块和领域对抗模块.其中特征提取模块将2个领域的样本xs和xt映射到全局子空间,实现了底层文本特征的对齐.其次将底层特征分别输入领域对齐模块和领域对抗模块,并通过协同优化的领域自适应算法,在高层语义空间进一步迁移领域知识.在领域对齐层中,首先在多层高维语义层,通过CMD度量源领域和目标领域的领域差异,提取领域可迁移特征.并将源领域样本特征输入标签预测器,保证迁移模型的分类性能.此外本算法构建了与领域对齐模块平行的领域对抗模块,该模块构造了梯度反转层,并后接领域判别器,通过网络的迭代训练,令领域判别器无法判别数据的领域来源,以提取领域不变特征.
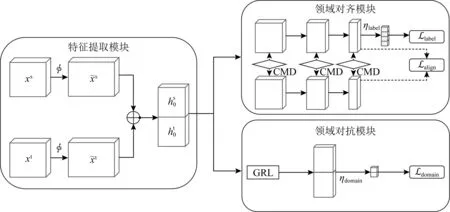
Fig. 1 The network structure of DAA图1 DAA网络结构图
在特征提取模块中,源领域和目标领域向量共享映射函数φ,2个领域的数据同时被映射到公共子空间下:
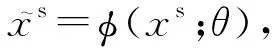
(4)
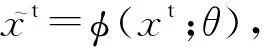
(5)
其中xs和xt分别代表源领域和目标领域的原始样

其次,令映射后的跨领域数据特征经过全连接层,采用非线性激活函数获得底层特征,并拼接源领域和目标领域底层特征,方便领域对抗模块的处理.计算过程为:
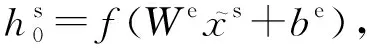
(6)
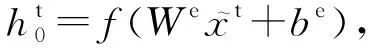
(7)

(8)
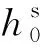
经由底层特征初步的特征映射后,本文构建了领域对齐模块,实现多重语义层中领域专有信息在高层语义空间的数据分布对齐.本文引入了CMD在各层高层语义层构建领域对齐损失,通过最小化该损失项,可减小2个领域的高阶分布差异.领域分布一致性约束为:
(9)

(10)
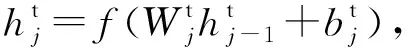
(11)
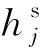
同时为保证分类器的判别性,本文还在领域对齐模块构建了源领域情感分类器,分类器的输入是源领域特征和源领域情感极性标签:
(12)
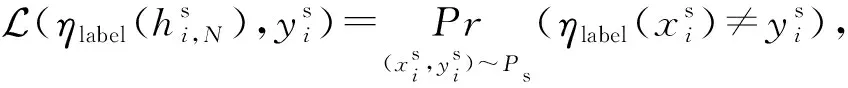
(13)

除了领域对齐模块外,本文还设计了一个具有领域不变性约束的领域对抗模块,用于提取领域不变性特征.领域判别器为2分类器,判别输入样本所属领域,即来自源领域还是目标领域.并且为了提取领域不变特征,还需在分类器之前构建梯度反转层,在反向传播时将梯度乘以负标量以逆转梯度,在模型的迭代训练中学习领域不变特征.领域对抗损失为:
(14)

(15)
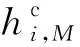
2.3 算法优化过程

(16)
其中,α和β为损失项权重.
本文所提出的领域对齐对抗的无监督跨领域文本情感分析算法DAA完成了源领域情感分类器到无标定目标领域的迁移任务,算法优化过程如算法1所示:
算法1.领域对齐对抗的无监督跨领域文本情感分析算法.
输出:经优化后的网络{φ,We,be,Ws,bs,ηlabel}.
② 初始化网络参数包括We,be,Ws,bs,Wt,bt;/*特征提取模块*/
③ 将源领域和目标领域样本映射到公共子空间,如式(4)(5);
④ 获取底层特征表示,如式(6)(7);
⑤ 拼接源领域和目标领域底层特征,如式(8);
⑥ while损失未收敛do /*领域对齐模块*/
⑦ forj←0到N:
⑧ 提取高层特征,如式(10)(11);
⑨ end for
⑩ 计算领域对齐损失,如式(9);
3 实验设计
3.1 数据集
为了验证领域对齐对抗的无监督跨领域文本情感分析算法DAA的可行性与有效性,本文在2个公开的亚马逊评论数据集上进行实验,包括积极和消极情感的2分类评论数据集,以及包含积极、中性、消极情感的3分类评论数据集.
第1个数据集是Blitzer等人[8]公开的早期2分类亚马逊评论数据集,如表1所示,包括书籍B(books)、光盘D(DVD)、电子产品E(electronics)和厨房用具K(kitchen)这4个领域,每个领域包含2 000个训练样本和3 000~6 000个测试样本.情感标签来源于顾客给出的评价星级,若产品获得4星或5星,则标签被设置为1,代表积极情感,否则其标签被设置为0,表示消极情感.本研究在该数据集上划分出12个跨领域任务,即B→D,B→E,B→K,D→B,D→E,D→K,E→B,E→D,E→K,K→B,K→D,K→E.
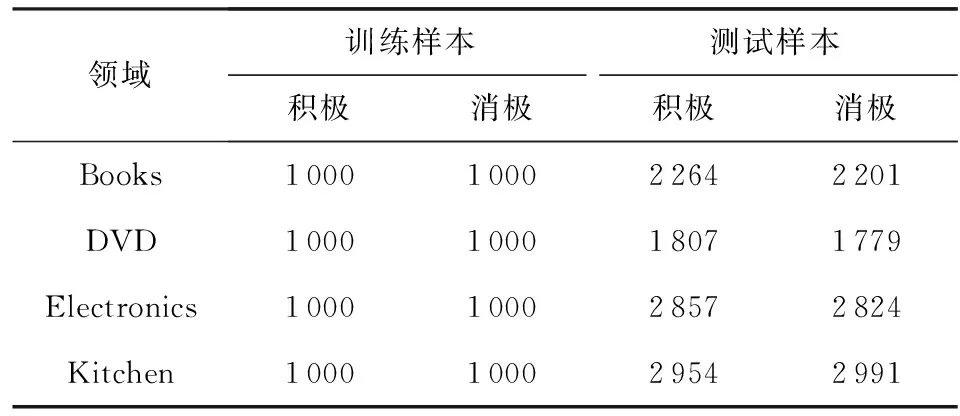
Table 1 Profile of Two-category Amazon Review Dataset表1 2分类亚马逊评论数据集
最新的亚马逊评论数据集如表2所示,该数据集由McAuley等人[45]公开.该数据集包括积极情感、中性情感和消极情感3个类别,包含书籍BK(books)、电子产品E(electronics)、美容产品BT(beauty)、音乐M(music)这4个领域,每个领域分别包含2 000个样本.本文将每个领域中的1 600个样本用于训练,剩余400个样本用于测试.尽管该数据集与Blitzer等人[8]公开的数据集在领域上看似有所重叠,但由于数据收集时间不同,同类领域样本分布也具有本质上的差异.同样在该数据集中,本研究将其划分为12个跨领域任务,即BK→E,BK→BT,BK→M,E→BK,E→BT,E→M,BT→BK,BT→E,BT→M,M→BK,M→E,M→BT.

Table 2 Profile of Three-category Amazon Review Dataset表2 3分类亚马逊评论数据集
3.2 对比方法
为了验证算法的有效性,本文所提出的DAA与1个基线方法、4类面向跨领域文本情感分类任务的无监督领域自适应算法中的代表性方法以及最先进的方法(state of the art, SOTA)进行对比.基线方法为SO(source-only),即不采用任何迁移算法的分类结果.4类迁移学习算法包括:
1) 基于特征选择的领域自适应算法.该类算法通过选择源领域和目标领域公共特征的方式,实现领域知识的迁移.代表算法包括SCL[7]和SFA[9],跨领域文本情感分类任务中的SOTA为HAGAN算法[24].
2) 基于领域对抗学习的领域自适应算法.该算法通过构建领域判别器并最大化领域判别器损失,实现领域不变特征的提取.DANN[10]是该类算法中通过构建梯度反转层和领域判别器实现领域对抗学习的代表性算法.ACAN[33]和SATNet[34]是以领域对抗学习方式为主、融合多种领域自适应策略的代表性算法,其中SATNet是该类算法中的SOTA.为达成最公平的比较,本实验复现DANN时,同样采用mSDA提取底层特征,并在领域对抗模型中构造1层全连接层.
3) 基于数据分布对齐的领域自适应算法.该类算法的核心在于对齐源领域和目标领域的数据分布,代表算法包括DAN[14],其中CMD是现有跨领域文本数据距离度量算法中的SOTA,为了达成最公平的比较,本实验中将CMD的中心矩阶数设置为3.
4) 基于子空间学习的领域自适应算法.该类算法将源领域和目标领域映射到公共的子空间,代表算法包括mSDA[17]和DSN[20],其中mSDA是基于离散特征输入的领域自适应算法中的SOTA,为达成最公平的比较,本实验中将mSDA输入向量的维度同样设置为30 000维,堆叠层数设置为5.
3.3 最优超参设定及其设定策略
实验采用针对迁移学习任务的反转交叉验证方法(reverse cross-validation criteria)实现模型调优,该方法过程有4步:
1) 将标定的源领域样本S和未标定的目标领域样本T按照10折交叉验证的方式划分,得到源领域训练集S′、目标领域训练集T′、源领域验证集Sv,目标领域验证集Tv;
2) 采用源领域训练集S′和目标领域训练集T′训练情感分类器η,并在源领域验证集Sv上进行模型验证和早停机制;
3) 基于上一步训练的模型,获得带标签的目标领域样本{(x,η(x))}x∈T′,并将标定的目标领域和无标签的源领域样本S′分别作为源领域和目标领域输入,训练获得反转分类器ηr,同时在带标签的目标领域验证集{(x,η(x))}x∈Tv中进行模型验证和早停机制;
4) 在源领域验证集上采用反转分类器ηr进行验证,并计算反转验证损失RSv(ηr).
这4个步骤不断重复,直至获得最低的反转验证损失,此时得到最优的迁移模型.经上述反转交叉验证方法可获得最优超参设置.在特征提取模块中,全连接层的神经元个数为48.在领域对齐模块中,采用2层全连接层,神经元个数分别为32和16.在领域对抗模块中,采用1层全连接层,神经元个数为48.中心矩阶数为3,学习率为10-3,根据迁移任务的不同,损失项权重α和β分别取自[0.1,1]中的9个数.
4 实验结果分析
4.1 分类准确率结果
表3给出本算法在跨领域2分类评论数据集的分类准确率,并与3.2节中给出的4类领域自适应算法进行对比.由表3所示,本算法DAA相比SO高出6%,证明算法具备基本的迁移能力.其次,与基于特征选择的领域自适应算法SCL,SFA和该类算法中的SOTA算法HAGAN相比,DAA在12个2分类跨领域文本情感分类任务中的平均准确率分别高出了5.1%,4.6%,1.1%.与基于数据分布对齐的领域自适应算法DAN,CMD的对比结果显示,DAA的平均准确率相比2种算法高出2.8%和2.2%.证明本文提出的DAA的领域对齐损失和领域对抗损失的联合优化有助于促进跨领域文本数据的知识迁移.同样地,DAA在12个任务中的准确率均高于基于子空间学习的领域自适应算法mSDA,在大多数的任务中高于DSN,其中在B→K和D→B任务中比DSN,DAA低0.4%,0.3%.在K→E任务中,DSN比DAA高出0.6%,其原因在于DSN中私有编码器和共享编码器的协作有助于提取良好的特征表示.与只采用领域对抗学习算法的DANN相比,本算法的平均准确率高出1.4%.而相比于融合多种领域自适应算法的ACAN和SATNet,本算法分别提高了0.6%和0.4%.

Table 3 Accuracy of Twelve Two-category Cross-domain Text Sentiment Analysis Tasks表3 12个2分类跨领域文本情感分析任务的准确率 %
表该分类任务的最优值.
由表3的实验结果表明本文提出的DAA在12个2分类子任务上的平均准确率相对近年所提出的ACAN和SATNet有一定提升,特别是在子任务B→E,D→K和E→K上均有较大幅度的提升.其中本算法DAA在B→E任务上分别提升了1.2%和3.2%,在D→K任务上分别提升了7%和7.4%,在E→K任务上相比ACAN提升了4.9%.分析对比11种算法,本文所提出的DAA的网络结构、迁移约束项和算法优化过程更简洁.首先对于网络结构,本算法对源领域和目标领域都采用单个统一的领域判别器,而ACAN和SATNet为源领域和目标领域分别构建了2个分类器.其次对于迁移约束项,本文以领域对抗学习和边缘分布对齐的思想构建了2个约束,而ACAN融合边缘分布对齐、条件对抗、生成器正则化的思想构建了3个约束项.最后对于算法的优化过程,ACAN和SATNet都采用最大化最小化的2步式对抗生成训练方式,而本算法以构建领域反转层的方式,采用更简洁的协同优化方式统一训练特征提取模块和2个迁移模块,单步协同训练相对2步式训练,更有利于避免局部最优,获得优化训练结果.因此通过表3的实验结果证明了本算法DAA对跨领域情感分析模型的优化和跨领域数据分类性能的提升.
此外由表3数据可见,基于特征选择的算法SCL和SFA的准确率相比其他领域自适应算法准确率更低.其原因在于该算法的优势是提取领域间共享的全局特征,然而当源领域和目标领域差异较大时,很难找到所需的全局共享特征,进而导致在没有对齐领域的情况下算法分类性能的下降.
表4显示了12个3分类跨领域情感分析子任务的实验结果.在该实验中,相比积极和消极情感,中性情感极性在特征表现上不太明显,因此本文考虑选择一种特征提取性能更优的特征编码器.本实验分别采用mSDA和单层text-CNN(text convolutional neural networks),进一步探讨特征提取器的选择对迁移效果的影响.其中,mSDA的输入是经过词袋模型(bag of words)处理所得的词频矩阵,mSDA[17]采用闭式求解,因此相比于传统的神经网络,该算法计算速度更快.而单层的text-CNN由Kim[46]提出,该网络的输入是词向量矩阵,本文通过Mikolov等人[47]提出的词嵌入模型获得词向量表示.
在表4中,DAA(CNN)表示使用text-CNN的DAA, DAA(mSDA)表示采用mSDA编码器提取特征的DAA.实验结果表明,不论是DAA(CNN)或是DAA(mSDA),都在所有子任务中高于其他的对比算法.因此该实验结果进一步证明,同时对齐特定领域特征和提取领域不变特征在跨领域情感分类任务中的必要性和有效性.
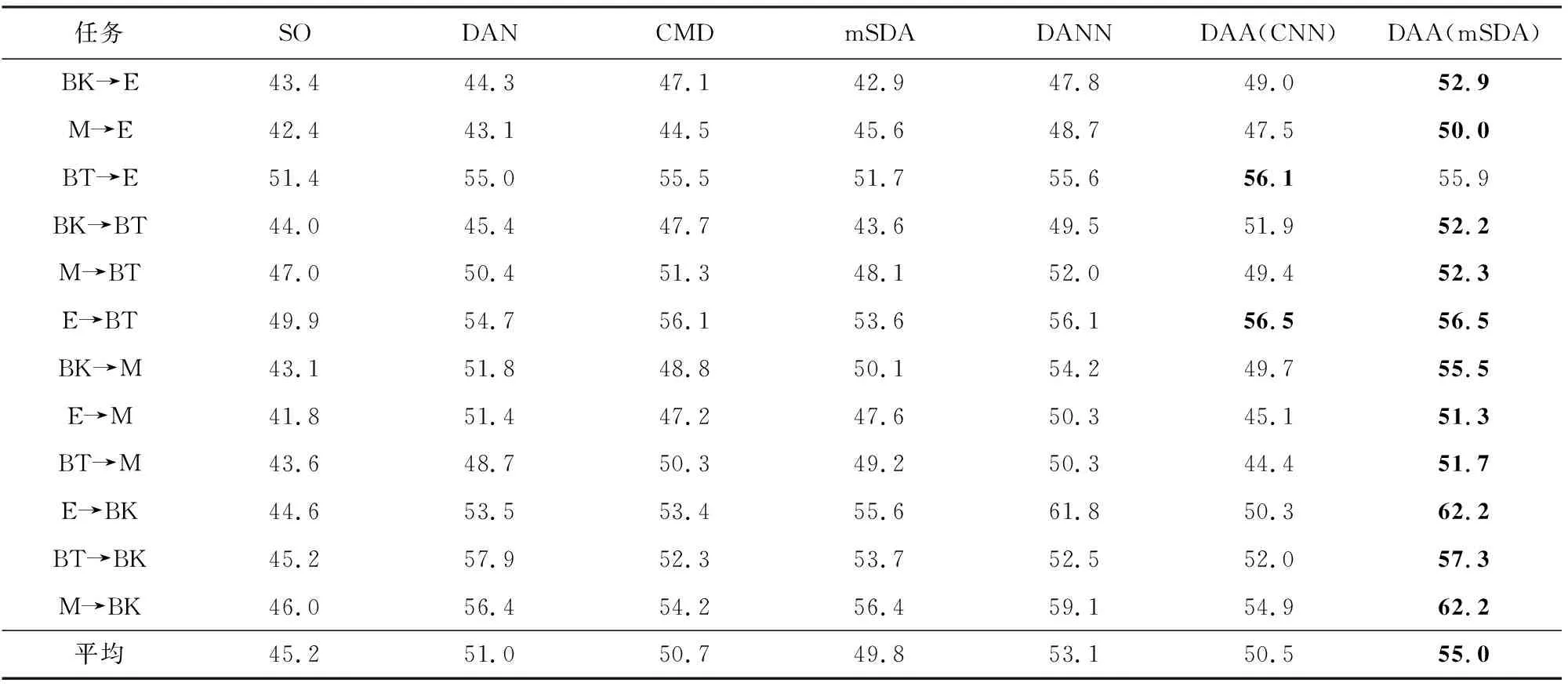
Table 4 Accuracy of Twelve Three-category Cross-domain Text Sentiment Analysis Tasks表4 12个3分类跨领域文本情感分析任务的准确率 %
而对于特征提取器的选择对迁移效果的影响,由表4数据可知,DAA(mSDA)在12个子任务上的平均准确率比DAA(CNN)高4.5%,而DAA(CNN)只在跨领域任务BT→E上比DAA(mSDA)稍高一些.经分析后得出子空间映射能力会对分类性能造成影响.其原因在于,mSDA将输入映射为底层特征表示前,为输入添加了噪声.并通过边缘化降噪自编码器,以增强去噪变换的计算过程,增强特征的鲁棒性表达.然而在DAA(CNN)中,底层特征通过卷积网络提取获得,而在卷积网络中,良好的特征表示很大程度上取决于训练数据的多样性.相比之下,CNN面向新数据的鲁棒性相对较差,进而导致特征提取效果不佳,而领域自适应算法又建立在特征提取的基础之上,导致后续的迁移效果不佳.故本文经实验结果推断后得出,在跨领域情感分类任务中,特征提取器的选择和领域自适应算法的优化缺一不可.
另外,结合表3和表4进一步分析发现,领域类型相似的迁移任务的分类准确率在每种领域自适应算法下,都具有相对较高的准确率.而不同类型的领域迁移任务,即使采取了对应的迁移策略,分类准确率也相对较低.例如,如表3所示,在2分类跨领域情感分析子任务中,厨房用具K和电子产品E都属于工具类商品,书籍B属于娱乐文化类商品.实验结果显示,E→K在SO上的准确率高于其他的迁移任务,并且经过迁移后,对于任意迁移学习算法中的E→K任务,准确率都远远高于其余11个迁移任务.因此通过实验结果可以推断出,E和K属于同一类商品,故领域差异更小、迁移过程更容易.然而属于不同类型的迁移任务K→B在SO和各类迁移学习算法中的准确率都相对较低.同理,对于表4中3分类跨领域情感分析子任务,E和BT都属于日常生活用品,M属于休闲用品.E→BT任务同样表现出更高的准确率,而BT→M不论在SO抑或在其他的迁移学习算法中,准确率都相对较低.由此推断出,各领域间的原始领域差异对跨领域情感分类任务迁移性能的影响,即领域差异越大,跨领域情感分类任务迁移难度越大,准确率相对越低.然而该结论是相对主观的推测,还需要客观的领域差异度量结果加以验证.因此4.2和4.3节将给出定量和定性的迁移性能结果,进一步证明本算法的有效性以及上述推论的可靠性.
4.2 迁移性能分析结果
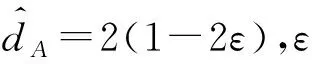
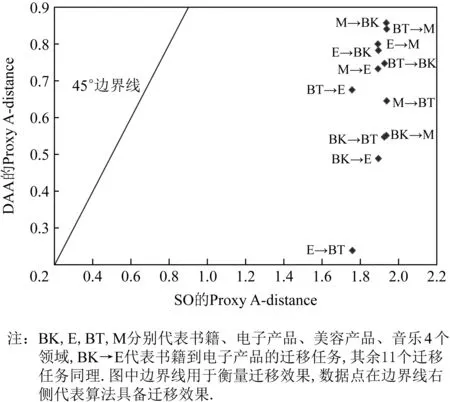
Fig. 3 Proxy A-distanceon SO and DAA in 12 three- category cross-domain text sentiment analysis tasks图312个3分类跨领域文本情感分析任务中SO与 DAA的Proxy A-distance
由图2和图3实验结果所示,所有任务的数据点皆处于边界线右侧,且离边界线偏移程度较大,因而证明了DAA算法具备良好的迁移性能.
此外,表5和表6给出数据点的具体数值和领域差异减小值(discrepancy reduction values),以进一步从定量的角度验证算法的迁移性能,若领域差异减小值为0,则说明算法的无迁移效果,反之领域差异减小值越大,则迁移效果越好.

Table 5 Proxy A-distance and Discrepancy Reduction Valuesof SO and DAA in 12 Two-category Cross-domainText Sentiment Analysis Tasks表5 12个2分类跨领域文本情感分析任务中SO与DAA的Proxy A-distance和领域差异减小值
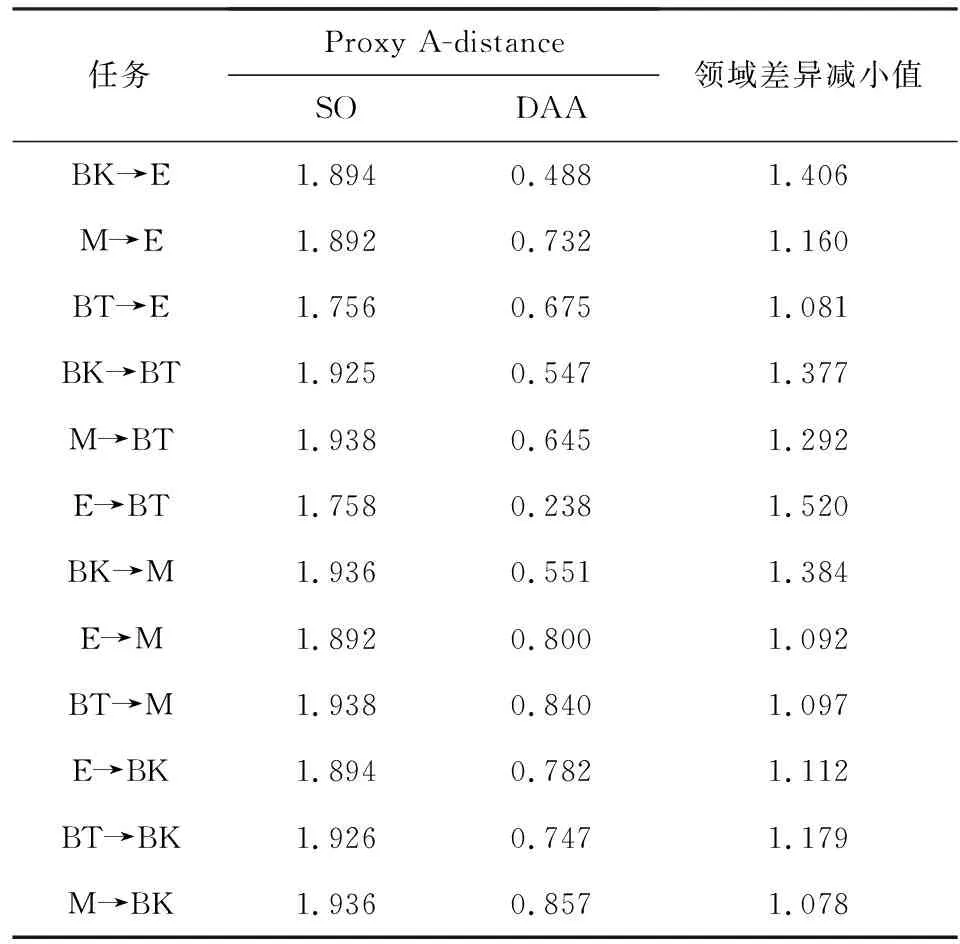
Table 6 Proxy A-distance and Discrepancy Reduction Valuesof SO and DAA in 12 Three-category Cross-domainText Sentiment Analysis Tasks表6 12个3分类跨领域文本情感分析任务中SO与DAA的Proxy A-distance和领域差异减小值
如表5和表6所示,即使对于领域差异较大的任务,DAA依然表现出了良好的迁移性能,如表5数据所示,在SO上领域差异较大的B→E任务,经过DAA的迁移后,领域差异减少了1.070.同样如表6所示,即使在源领域和目标领域属于不同的类别、原始领域差异较大的任务BK→E中,领域差异在经过协同优化的领域自适应算法后,也有显著降低.因此,经过图2、图3和表5、表6的定量迁移实验结果进一步证明,本文提出算法具备良好的迁移性能,可以有效地减小领域差异.
另外结合4.1节中,各领域间的原始领域差异对跨领域情感分类任务迁移性能影响的推断,此处基于领域差异度量结果,对推断给出了更客观的验证结果.在表5中,本研究发现属于同一领域类别、领域差异较小的E→K任务的Proxy A-distance在SO和DAA上低于其他跨领域任务,相反,属于不同领域类别的K→B在所有任务的SO中取得了最大值.相应地,在表6中,E→BT的Proxy A-distance在所有任务的SO中为最小值,而BT→M为最大值.说明属于同一类型的E和BT,领域差异较小,而属于不同类型的BT和M的领域差异较大.因此,根据表5和表6的实验结果得出,原始领域差异会对迁移性能产生一定影响.
4.3 特征分布可视化结果
本实验绘制特征分布图,从定性的角度分析DAA的迁移性能,如图4和图5所示.
图4为2分类跨领域情感分类任务的特征分布图.其中红色点和蓝色点分别代表源领域和目标领域的积极情感类别数据,黄色点和绿色点分别代表源领域和目标领域的消极情感类别数据.M1代表特征提取模块,M2代表领域对齐模块,M3代表领域对抗模块.每一行分别代表2分类的跨领域情感分类任务B→K,D→E和K→D.

Fig. 4 The feature distribution maps on two-category cross-domain text sentiment analysis tasks图4 2分类跨领域文本情感分析任务的特征分布图

Fig. 5 The feature distribution maps on three-category cross-domain text sentiment analysis tasks图5 3分类跨领域文本情感分析任务的特征分布图
图4(d)(h)(l)代表只采用特征提取模块的特征分布情况,可见不同领域同类别的数据拟合效果不佳,且无明显的分类边界.图4(c)(g)(k)代表采用特征提取模块和领域对齐模块的特征分布情况,相比图4(d)(h)(l),其分类效果有明显改善,但是仍然有部分点被错分.图4(b)(f)(j)代表采用特征提取模块和领域对抗模块的特征分布情况,可以看出分类效果较图4(d)(h)(l)有明显改善,但是领域间同类数据分布呈块状,拟合效果不佳.图4(a)(e)(i)为融合DAA三个模块的特征分布情况,该情况下迁移效果最佳,领域间同类数据均匀拟合,且类别之间有明显的分类边界.由此推断本研究提出的领域对齐对抗算法面向2分类跨领域情感分类任务,具备较好的迁移性能和分类性能图5为3分类跨领域情感分类任务的特征分布图.其中红色点和蓝色点分别代表源领域和目标领域的积极情感类别数据,黄色点和绿色点分别代表源领域和目标领域的消极情感类别数据,紫红色点和青色点代表源领域和目标领域的中性情感类别数据.M1,M2,M3所对应的模块与图4相同.每一行分别代表3分类的跨领域情感分类任务E→BT,BK→M,E→BK.
由图5(d)(h)(l)可看出,只采用特征提取模块而无迁移机制的情况下,数据点分布散乱,无分类边界,分类效果和迁移效果不佳.图5(c)(g)(k)和图5(b)(f)(j)中,特征分布较为混乱.而图5(a)(e)(i)相比之下呈现较为明显的分类边界,且同类数据点的拟合程度有所改善.由此证明DAA在3分类跨领域情感分类任务中,同样具备有效的分类性能和迁移性能.
5 总 结
面向无监督领域自适应任务,本研究提出了领域对齐对抗的无监督跨领域文本情感分析算法DAA.该算法充分利用实际跨领域文本数据同时包含领域特定信息和领域不变信息的本征特点,以渐进式的迁移策略,逐层减小不同语义层的领域差异.并在高层特征提取层以协同优化的领域自适应算法,分别在领域对齐模块和领域对抗模块,构造领域一致性约束和领域不变性约束.经由2个约束在训练过程中迭代地协同优化,实现跨领域文本数据的领域知识迁移.
本研究在24个跨领域文本情感分析任务上验证了算法的有效性.对比实验结果显示,本算法有效提升了现有无监督跨领域文本情感分析算法的准确率.并结合领域差异度量的定量实验和特征可视化的定性实验,进一步证明算法的分类性能和迁移性能.此外,本文还对实验结果进行更为细致的分析,深入探讨原始领域差异和特征提取器的选择,对跨领域文本情感分析算法的影响.
本文针对无监督跨领域文本情感分析任务进行了相关的研究和探讨.但是在实际应用场景中,跨领域文本情感分析任务还面临着各种各样的挑战,如各领域的语言不同导致数据分布差异过大,领域间各类别数据不平衡导致源领域分类器向某一类别的数据偏移的问题.因此未来的研究工作将进一步考虑如何设计子空间映射能力更强的跨语言特征提取器,以及如何从类别标签语义信息的角度对齐领域差异,以解决跨领域数据类别不平衡问题.
作者贡献声明:贾熹滨提出研究问题和思路,提出实验改进建议和论文修改思路;曾檬完善算法设计及实验验证,撰写论文;米庆参与实验改进和论文修订;胡永利提出实验方案及实验改进建议.
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
青年生活(2019年23期)2019-09-10 12:55:43
当代陕西(2019年10期)2019-06-03 10:12:04
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
中共南宁市委党校学报(2015年4期)2015-02-28 11:48:10
河南科技(2014年23期)2014-02-27 14:19:15
