
融合空间偏好和语义的个体活动识别方法
2022-06-08 09:10郭茂祖陈加栋赵玲玲
国防科技大学学报 2022年3期
郭茂祖,陈加栋,张 彬,赵玲玲,李 阳
(1. 北京建筑大学 电气与信息工程学院, 北京 100044; 2. 哈尔滨工业大学 计算机科学与技术学院, 黑龙江 哈尔滨 150001)
移动网络的普及与移动终端设备的性能提升促进了基于位置的社交网络(location-based social-networks , LBSNs)快速发展[1]。社交网络用户通过文字、图片、评分等形式分享日常动态,而社交关系、时空轨迹、活动出行等信息隐含在用户上传信息中。因此,基于社交网络中用户信息的挖掘能够获取用户的出行和活动的模式与偏好等特征,为用户画像、目的地推荐及出行规划[2-5]、个性化产品广告投放等实际应用提供支持。同时,其也有助于进一步了解城市范围内的群体行为模式,对城市规划[6-8]、资源配置优化、异常检测等领域具有重要价值。
在地理信息系统中,兴趣点(point of interest, POI)的地标用于标示某一地点所代表的设施、景点、地标等场所,包含地点对应的名称、类别、经纬度、海拔等信息。在用户通过社交媒体记录分享自身活动时,其上传的地点名称及兴趣信息能够使对应位置构成POI。由于社交签到数据包含了签到时间、POI等信息,其隐含的信息能够描述用户在签到时进行的目的性活动所属类别,即活动语义信息。社交媒体包含的大量签到与活动数据,为挖掘用户活动偏好、识别活动语义提供了基础。
在活动语义识别任务中,当前研究聚焦于挖掘时间信息中的活动行为的周期性和趋势性特征,对空间经纬度信息的使用主要在于计算签到点与周围POI之间的距离,作为POI推荐依据[3,9],或利用用户对访问点的历史信息进行统计获得访问频率,用于个体活动行为偏好分析[10]。数据中所包含的签到地点的名称文本信息对于活动语义的识别同样具有重要意义,并且其在一定程度上可以直接反映活动语义。许多现有研究采用潜在狄利克雷分配(latent Dirichlet allocation, LDA)主题模型来对POI名称进行提取,通过生成的主题分布对个体进行活动行为识别,或进行旅游景点推荐[3-4]等;另有研究采用聚类[2]的方法对POI进行分析,从而为用户推荐兴趣点。
活动语义识别的难点不仅体现在不同个体在同一地点的活动语义差别,同时也体现在不同场所经纬度、高度信息相似所造成的识别困难。现有活动语义识别研究对时间信息中的周期性和趋势性特征考虑较为充分,但并未结合用户的活动空间偏好特点和POI语义信息。
针对上述问题,本文提出了一种基于空间偏好和POI语义的个体活动语义识别方法,通过签到数据中的时间信息、空间信息和POI文本信息对个体活动语义进行识别。将活动语义识别视为多分类问题,通过特征工程挖掘时间、空间、文本信息中的关键特征,构建反映群体和个体偏好的时空联合特征向量,并采用极限梯度提升(extreme gradient boosting,XGBoost)算法建立分类器,对特征进行编码并构建活动语义识别模型。
1 相关工作
个体的活动行为在时间和空间中通常具有较强的规律性,分析时空数据能够实现用户的活动类别识别,对于城市规划、交通规划、针对个体兴趣偏好的推荐系统有着重要的价值。
用户的时空轨迹或签到数据在个体的活动偏好和推荐领域存在许多研究应用。Zhu等[2]设计了一种个性化的旅游景点推荐算法,向用户推荐旅游景点。通过基于密度的聚类算法(density-based spatial clustering of applications with noise,DBSCAN)对空间地理数据进行聚类,获得旅游景点POI对应签到数据,再通过主题提取模型LDA分别为用户及区域生成潜在主题分布,并与用户的社交关系数据相结合,构建模型获取个体用户对应不同活动语义的得分。之后将模型与旅游景点的位置、评分相结合,对旅游景点进行排名,实现对用户的景点推荐。Qiao等[3]通过学习用户与POI的潜在表示形式,将地理位置信息、用户关系信息和时间信息进行综合,提出联合表示学习框架,将上述因素纳入计算得出各个POI间的转移概率,完成POI的推荐和社交链接的预测。Cao等[4]采用了基于社交网络的矩阵分解框架,根据用户与地区POI的交互数据分析其活动偏好,采用频谱聚类对POI进行聚类,结合地理信息为用户推荐POI。在用户活动行为的建模中,挖掘相似用户的活动行为,对建模用户个体的活动偏好和移动模式有重要作用。Rizwan等[10]通过核密度估计(kernel density estimation,KDE)方法帮助观察分析活动行为和目的地的稀疏分布,以及识别活动事件的精细密度,并使用标准偏差椭圆(standard deviational ellipse,SDE)方法分析签到行为的空间分布区域。研究结果表明男性和女性在活动行为偏好上有很大区别,活动时间选择上也有不同。Araújo等[11]将随机森林模型和马尔可夫模型结合构建一个集成学习器,用于预测用户的下一活动位置。
基于社交位置的社交网络数据存在很多问题,比如数据稀疏、数据量低、可信度差、缺乏权威认可、隐私问题等。Martí等[12]分析了LBSN数据的主要问题,并提供了相关使用方法。Kim等[13]采用模拟用户数据解决上述问题,方法以大量社交网络数据为基础构建框架,结合人类实际生活行为模式生成模拟用户数据,提取模拟用户的时间、空间、社交关系信息。文献[14]通过类似方法构建了地理模拟系统,生成人群需求模拟数据进行研究。
Zhong等[15]挖掘用户移动位置和时间的上下文相关性,分析用户移动模式,获取兴趣偏好。通过位置信息对用户活动相似性进行建模,将用户频繁活动的区域视为兴趣中心,提出多中心聚类算法衡量用户的相似性。Wang等[16]提出基于图嵌入的半监督学习框架为位置场所注释,挖掘场所位置相关性和访问相同地点的用户相似性。Zhang等[17]将时空特征和活动轨迹的额外活动信息相融合,用以解决在轨迹补全问题中的不足。Shi等[18]在人流流动性研究中,关注人类在移动中的时空特性和移动动机,探讨活动轨迹研究中活动目的对移动的影响。
社交媒体数据能够辅助决策城市规划和城市资源配置,以数据来驱动规划和发展。González等[5]挖掘个体时空活动轨迹,不完全重合的活动轨迹遵循简单的可复制模式。出行方式的固有相似性影响到城市规划、城市资源配置以及流行病的预防和响应。Van Weerdenburg等[6]基于休闲活动和旅游类数据,对比三种有监督多标签机器学习方法,探究这些理论在城市休闲和旅游业研究以及相关城市政策和规划中的潜力,为城市休闲和旅游研究提供了新视角。Cai等[7]通过人类活动的时空模式,提取城市空间动态语义,并揭示了北京城市动态的五个小时模式、四个每日模式和六个空间模式。Huang等[8]通过市民与交通系统的互动解决交通拥堵,利用社交媒体数据分析城市交通和城市动态,探索人类活动对日常交通拥堵影响。
个体社会活动行为与个体社会关系网络有重要关系。基于此,Pan等[19]提出发现社交关系中有影响力的朋友算法,通过签到数据中的用户语义信息计算不同用户之间的影响。Papangelis等[20]将地理区域中的地域性概念用于理解个体的空间活动和社交行为。这种地域性特点会影响到个体与个体间的交互以及他们所处的环境。本文受个体活动语义识别研究[2-4,10,15]启发,针对个体数据中隐含的兴趣偏好对识别准确率的影响进行了探究。为获取用户空间访问偏好,文献[2,4,15]采用聚类方法由地理信息提取热点访问区域,但基于聚类方法获取的空间偏好区域[2]可能将不属于热点区域的边缘点包含到聚类簇中,对识别效果造成不利影响。本文基于用户对各区域的访问频数进行统计,提出了更加直观的个体空间访问偏好表征方法。
为了利用签到点名称来挖掘文本信息,文献[2]采用LDA聚类对热点区域内的旅游景点进行主题生成,从而获取用户的潜在访问主题偏好以及各区域的潜在主题分布。在个体活动语义识别任务中,不同个体在同一地点可以拥有不同的活动语义,而聚类所得的空间区域潜在主题分布固定,不利于活动语义识别。本文通过词向量嵌入模型BERT(bidirectional encoder representations from transformers)将签到地点名称转换为带有语义的向量,由于包含语义的特征向量和活动语义间不存在固定对应关系,在活动语义识别准确性上能够获得更好的表现。
2 个体活动的时空联合特征表示
本文在进行个体活动语义识别过程中同时考虑了时间、空间以及POI名称文本中潜在的语义信息,将活动语义识别作为一个多分类问题处理。在访问时间特征方面,提取签到时间特征,以表示活动行为的时间周期性和趋势性。
空间特征方面,由于用户在不同访问位置的访问频率差异反映了一定的偏好,因此,本文提出基于访问热度的群体和个体的空间偏好特征。空间偏好带有群体性和个体性两个层面:群体偏好的产生表现为签到数据空间中存在若干热点访问区域,这些热点访问区域往往关联典型的活动类型,如旅游胜地、热门餐厅等;个体偏好则是针对个体签到数据而言,由于用户的出行习惯或工作要求,也可能出现热点访问区域,且个体在这些区域倾向于进行相同的活动。
POI语义方面,采用BERT模型提取POI名称隐含的语义信息。综合上述三个维度提取的特征构建联合特征向量,使用XGBoost算法建立分类器。整体的活动语义识别模型框架如图1所示。
2.1 空间偏好特征表示
不同个体具有不同的出行和活动习惯偏好,在签到行为数据的空间分布上也有所反映,具体表现为个体或群体对不同子区域的访问频率差异,并随签到行为进行逐渐形成用户个体和群体的热点访问区域。由于个体在特定空间区域的活动类别与其日常习惯偏好存在紧密联系,相关空间特征的挖掘对个体活动识别具有重要的意义。本文基于用户签到数据对不同子空间的访问频率提出空间偏好的估计方法,分别对个体、群体的空间偏好进行了度量,并获取相应的空间热点访问区域,作为签到行为的空间特征表示个体的潜在活动模式。
2.2 用户空间偏好的度量方法
本文采用基于子空间访问频率统计的度量方法,分别提取用户个体、群体的热点访问区域及相应访问量作为空间偏好特征,具体提取方法描述如下。
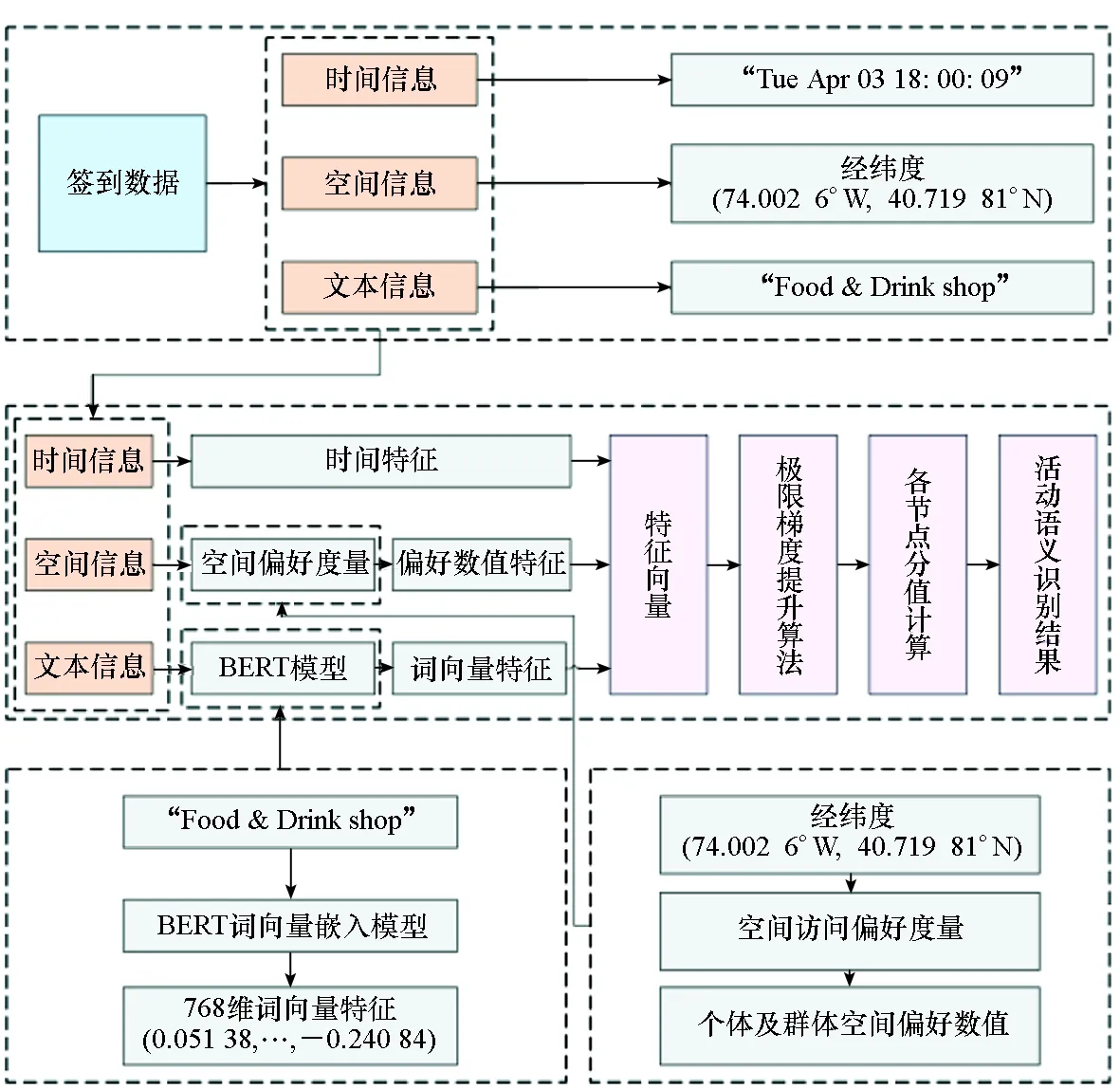
图1 基于空间偏好和POI语义的活动语义识别框架Fig.1 Activity semantic recognition framework based on spatial preference and POI semantic
1)首先定义子空间区域的经纬度阈值ε,将签到数据集空间范围S划分为网格子区域Si,子空间起始经度a0、纬度b0分别取签到点分布范围的经纬坐标下界:
(1)
将用户签到空间位置坐标集合表示为L,第i条数据的签到点经纬度位置表示为li。
L={l1,l2, …,ln}
(2)
li=(ai,bi)
(3)
2)采用如下方法估计某个区域的空间偏好:首先统计L中所有签到点坐标,获取落在子区域Si内的签到位置坐标及个数ni,构成子区域签到点数量集合N。然后分别计算子区域内任意点li作为质心Ci时的均方误差E,选取计算所得均方误差最小的签到点作为该子区域质心:
(4)
(5)
3)考虑到签到点有可能落在划分子区域边缘上,两类边缘点分别类似于图2的A、B两点,对两类点分别计算坐标与邻近各子区域质心的欧式距离di,即对A点类型,计算di(i= 1, 3);对B点类型,计算di(i= 1, 2, 3, 4)。取最小di对应的子区域作为边缘点所属:
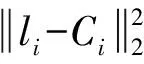
(6)
图2展示了签到数据在空间中的分布,每条横线表示纬度,竖线表示经度。通过上述方法将整个签到空间划分为一个个的签到子区域,各个子区域中的一个点就表示有一次签到行为发生于此空间内,模拟了签到点在签到空间内的分布情况。
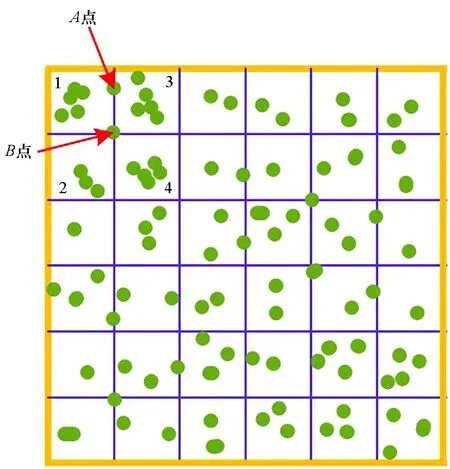
图2 签到点空间分布示意Fig.2 Schematic diagram of check-in points
图3和图4分别展示了Foursquare纽约市公开数据集的群体、个体签到记录空间分布,并显示了通过本文空间偏好度量方法获取的特征值。特征值越大,表示个体或群体对该子区域的访问偏好程度越高。
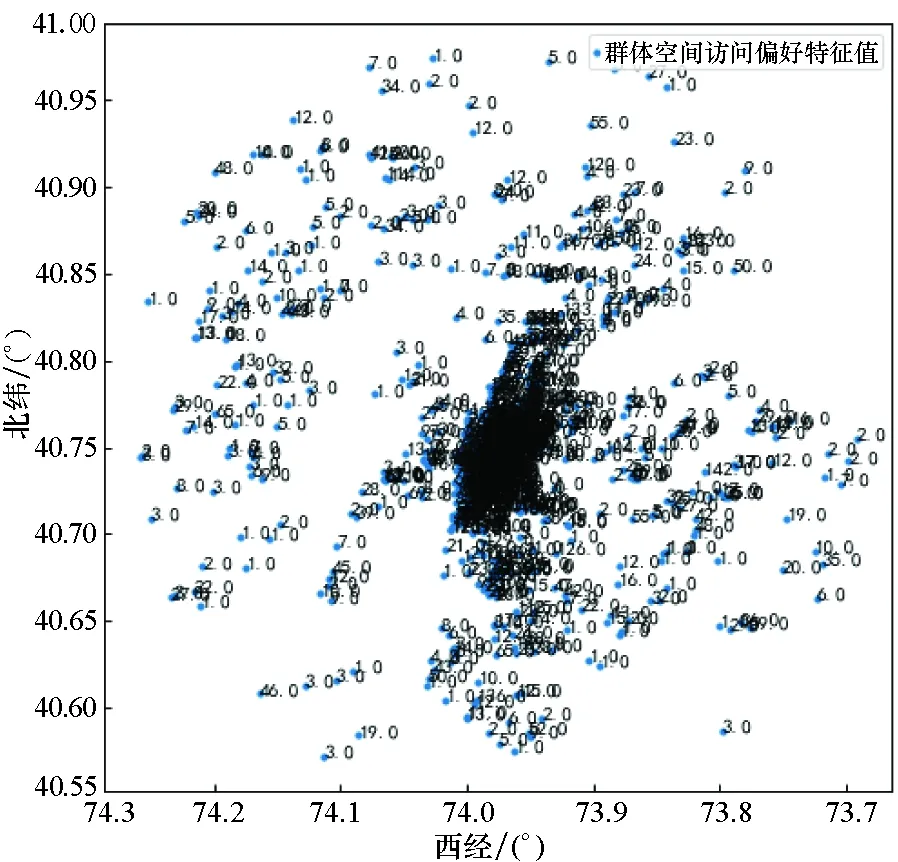
图3 群体空间访问分布及偏好特征Fig.3 Group spatial preference and numerical feature

图4 1号用户的空间访问分布及偏好特征Fig.4 Spatial preference feature of the No.1 user
2.3 POI语义信息提取
用户在签到时刻进行的活动往往与其所在位置的类别、功能具有紧密的联系,签到地点信息对个体活动的识别具有重要意义。因此,本文通过提取签到点POI名称中的文本信息特征,获取其隐含的活动语义信息。
词嵌入方法在自然语言处理领域得到了广泛的应用,通过将词语映射到一个数学空间里,能够获取文本对应的反映其特点的向量表征。本文使用自然语言处理中的BERT模型将签到地点名称转换为带有语义的词向量。
BERT模型以Transformer模型架构为基础,能够在左右两侧上下文的联合条件下,从无标注的文本中预训练出词的深层双向表征。
本文方法使用谷歌公司提供的Uncased BERT-Base模型对签到地点名称进行词嵌入,将文本信息映射至特征空间,以获取对应的词向量特征。变换流程如图5所示,具体详细如下:
1)基于个体用户签到数据,获取签到POI名称文本序列{P1,P2,…,Pn},分别对位置名称Pi进行词嵌入、位置编码、片段编码得到对应的向量表示X。
2)将X输入自注意力层,计算其对应的Query矩阵、Key矩阵、Value矩阵:
Qi=X·WQ
(7)
Ki=X·WK
(8)
Vi=X·WV
(9)
其中,WQ、WK、WV分别代表对应权重矩阵。
3)计算得分,即Qi与Ki的点积,通过softmax函数对结果进行归一化处理,并乘以Vi矩阵得到注意力矩阵Zi:
(10)
4)由于多头注意力机制,需要将多个Zi矩阵相连,并与权重矩阵WO进行点乘,Z即为对应文本的向量表征:
Z=Concat(Z1,Z2,…,Zm)·WO
(11)
5)将结果Z保存为对应的嵌入结果,并循环执行完成所有文本到向量的转换,对序列中其他POI名称文本循环此过程,获取全部POI文本对应的向量表征。
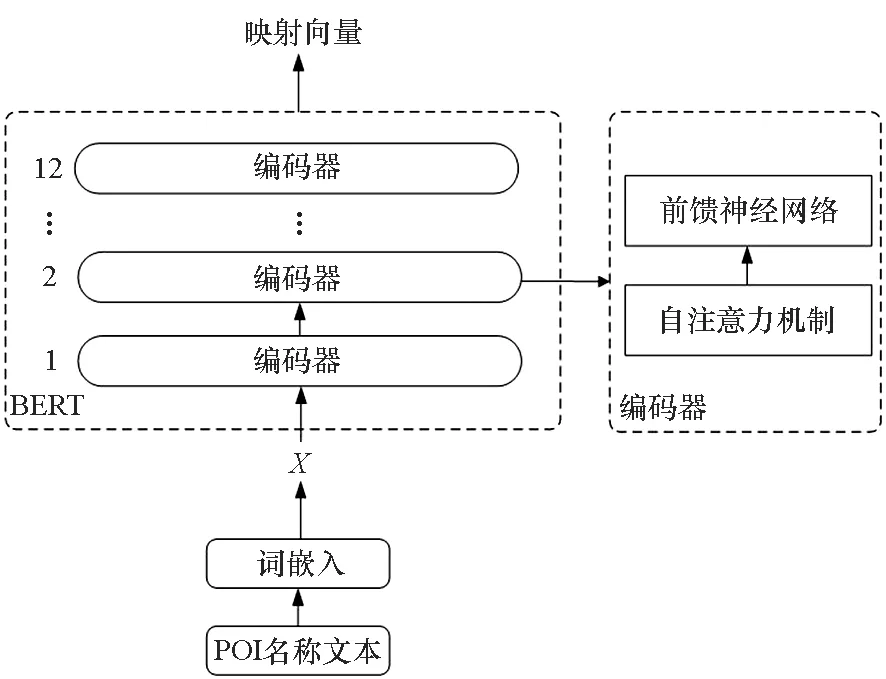
图5 BERT模型流程Fig.5 Flow chart of BERT model
3 活动语义识别算法
本文将活动语义识别作为一个多分类任务进行处理,提取了时间、空间、文本三个维度的特征,组合成特征向量,采用XGBoost模型作为分类器,构建一种融合多特征的活动识别(multi-feature activities recognition,MFAR)算法模型。模型的输入包括签到数据的用户ID、签到地点空间经纬度坐标、签到时间戳、签到地点POI名称。算法从时间信息中提取月、日、星期、工作日、签到时刻,并计算签到点的空间访问偏好程度;文本上对于签到地点名称,利用BERT模型对其进行编码,将字符信息转换为具有文本语义的向量。组合三个维度中的所有特征构成特征向量,利用XGBoost模型完成活动语义识别,MFAR算法具体流程如算法1所示。

算法1 MFAR算法

4 实验与结果
MFAR的主要任务是识别LBSN用户在签到位置的活动语义,实验采用Foursquare社交平台公开签到数据集来验证本文方法的有效性,选用的数据集中包括来自纽约的227 428条及东京的573 703条用户签到数据。每条签到记录主要包含匿名的用户ID、签到位置ID、位置所属类别ID、签到位置名称、经纬度坐标、UTC时差、世界标准时间。
具体活动语义的标签类别及描述如表1所示,数据集包含12种活动语义标签,描述了用户在签到地点的活动语义,例如:对于一条记录了某用户在健身房锻炼的签到数据,其POI名称为“Gym/Fitness Center”,对应活动语义标签为“Sports”。

表1 活动语义类别及描述
XGBoost算法中决策树数量d与最大深度k的超参数对模型性能影响较大。经参数调优,本文将模型学习率设置为0.3,决策树数量为1 000,树的深度为6。
此外,本文采用控制变量思想分别调整不同参数值,计算不同实验设置下模型多分类结果的准确率Sacc、精确率Spre、召回率Srec、F1值SF1。为避免实验结果偶然性的影响,在对比实验中采用十折交叉验证,取评价指标平均值进行对比。同时,采用混淆矩阵进一步获取模型对不同活动类别的识别情况,并对主要误识别原因进行分析。四种主要评价标准计算公式如下:
(12)
(13)
(14)
(15)
根据模型对样本的分类结果与其实际类别的匹配情况,TP、TN分别代表模型分类正确的正例与反例样本,即真正例与真反例;FP、FN分别代表分类错误的正例与反例样本,即假正例与假反例。
本文围绕空间偏好特征、POI文本特征和分类器进行了一系列对比实验,并对模型性能进行对比分析,以证明MFAR提取特征的有效性与分类器的性能。
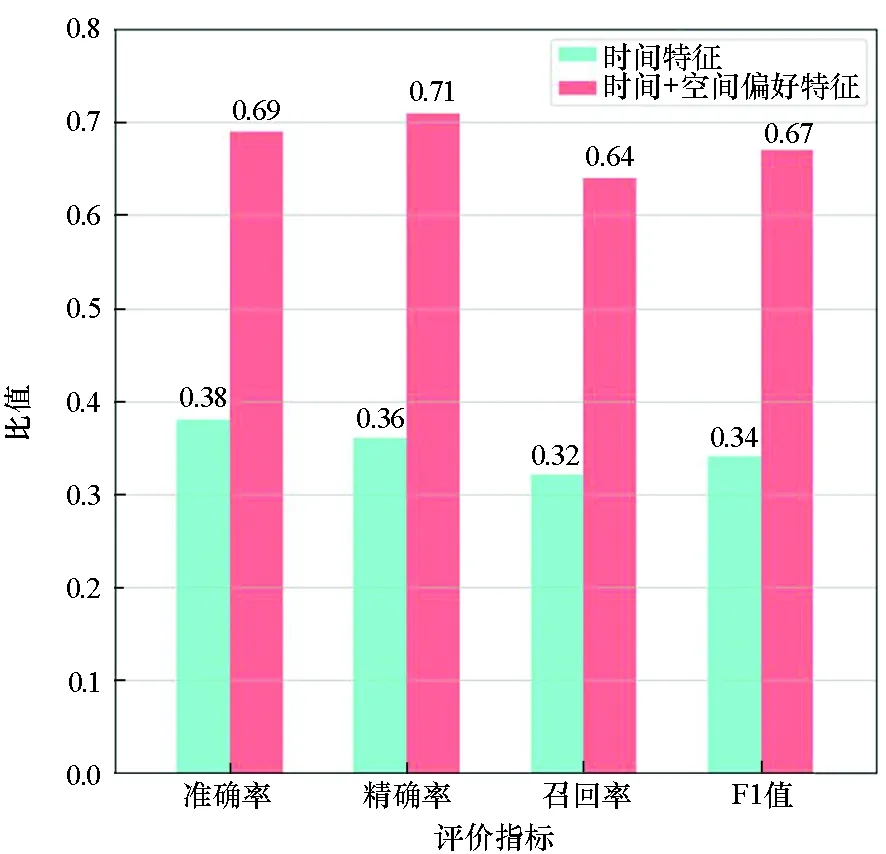
图6 关于空间偏好特征的模型性能对比Fig.6 Comparison of the model performance in view of spatial preference features
图6展示了引入空间偏好特征对模型性能产生的影响,对比了仅采用时间特征以及同时采用时间与空间偏好特征训练所得分类器的性能指标。对比实验结果,相比较于单一的时间特征,空间特征的引入为模型的活动语义识别性能带来了明显提升。空间访问频率反映了群体和个体的空间访问偏好,由于在群体访问所形成的热点区域(如知名餐厅、名胜古迹等)中大多数个体所进行的活动行为相同,多数个体用户在相应位置进行的活动行为具有较高相重合度。个体访问数据形成的热点访问区域同样会反映个体活动的空间访问习惯偏好,在签到数据中常体现为个体在进行特定活动时多次重复访问某一地点。实验结果证明,空间访问偏好特征对活动语义识别有重要作用。
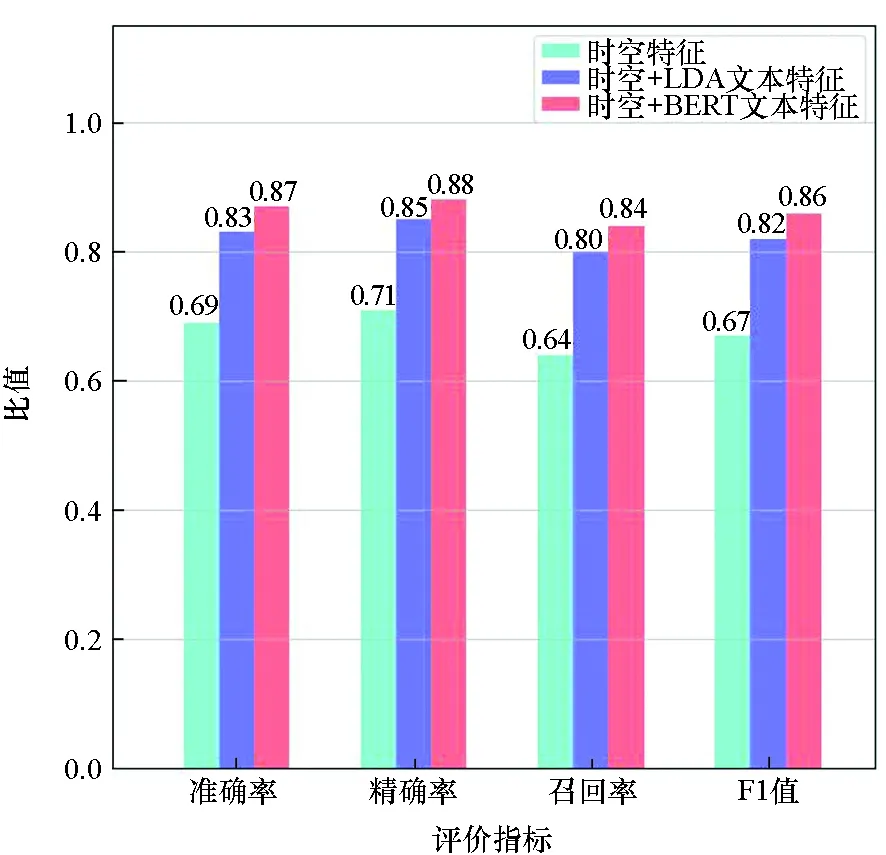
图7 关于文本特征提取的模型性能对比Fig.7 Comparison of model performance in view oftext feature extraction
图7展示了文本特征对模型性能的影响,对比了仅采用时空特征、分别采用LDA主题模型与BERT模型进行词向量嵌入的模型性能,三种特征选取方式分别对应三种不同颜色柱状图。对比时间空间相结合的特征,在加入了文本作为识别特征后,识别准确率又有了较高的提升。在活动语义识别中文本特征是一个重要的特征,活动点的名称与个体在活动点进行的活动行为有重要联系。对于文本特征,本文通过两种不同的思路来挖掘:①LDA主题模型,从词到主题的分布来对文本进行向量的表征;②BERT模型,从词的语义来进行向量表征。在通过LDA模型进行词向量的转换时,首先以所有签到点的名称进行训练生成主题,之后对所有签到地点名称进行主题归属预测,得到主题归属预测向量,完成词到向量的编码。BERT模型将签到地点经过一个12层的编码器结构来完成语义表征。图7的实验验证了基于BERT的语义表征优于基于LDA的主题表征。在活动语义识别中,同一地点的活动行为不尽相同,LDA主题模型对文本以主题语义的形式进行词向量表征,但主题语义并不等同于活动语义。BERT模型对文本以自然语言语义的形式进行词向量表征,相同字符在不同语境中存在不同含义,而主题则更加确定,所以对于相同地点的不同活动行为经由BERT模型转化来的向量有着更好的表达效果,因此该模型更有利于活动语义识别。
将MFAR算法与只采用时间、空间、文本单一特征进行训练得到的识别准确率进行对比。其中,单一采用时间特征所得准确率为0.38,空间特征准确率为0.48,文本特征准确率为0.78,MFAR算法准确率为0.87,结果显示MFAR算法表现优于其中任一种特征。此外,为探究算法中各特征的作用,基于单一特征的识别准确率定义了特征重要性度量,计算方法如式(16)~(17)所示。
(16)
Stotal=Sspa+Stem+Stex
(17)
其中,Ii代表不同特征类别的重要度分值,Stem、Sspa、Stex分别表示基于时间、空间、文本特征单独训练所得模型的准确率,SMFAR表示同时采用三种特征的MFAR算法模型准确率。
根据式(16)进行计算,时间特征重要度为0.20,在三种特征中最低;空间特征重要度为0.26,略高于时间特征;文本特征重要度最高,为0.41。根据上述结果,签到位置文本信息在活动识别中发挥了更重要的作用。进行打卡签到时用户更倾向于记录新颖活动,对日常生活频繁活动记录较少,整个打卡签到行为随机性大,导致时间信息中周期性和序列性行为较难挖掘,因此单一时间维度特征识别效果较差。空间偏好信息相比较于时间信息识别较好的原因是,对于空间中的热点访问区域,多数个体在这些地区都进行相同的活动行为。签到地点名称文本反映了签到地点的固有属性,这些固有属性决定了当前地点能够提供何种活动行为,因此识别效果最好。
如图8所示,实验对比了XGBoost分类器、基于随机森林的分类器、K近邻分类算法以及支持向量机在采用相同特征前提下的模型性能,结果表明MFAR采用的XGBoost分类器的各项性能指标均显著优于其他分类器。
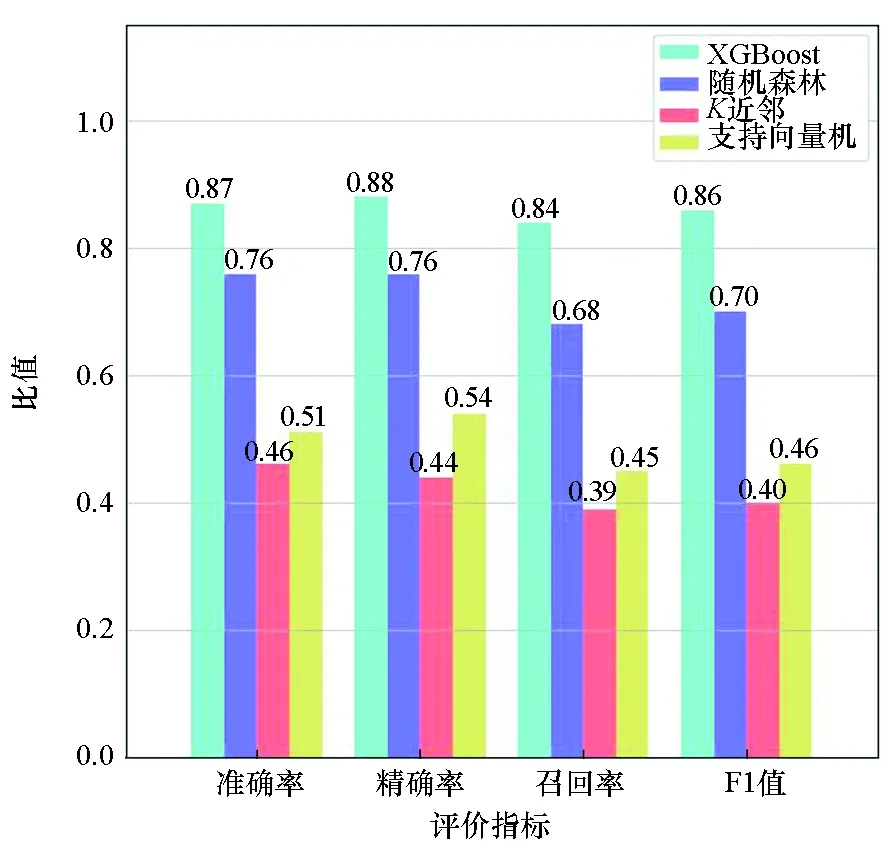
图8 采用不同分类器的模型性能对比Fig.8 Comparison of model performance with different classifiers
图9为活动语义识别模型的混淆矩阵,混淆矩阵展示了算法对不同活动语义的预测情况,其中横轴代表MFAR算法根据签到数据特征所得的活动语义预测值,纵轴代表该签到数据包含的活动语义真实值,位于矩阵对角线上的数字代表活动语义预测值与真实值相符的签到数据样本数量。例如:在活动语义真实值为Shopping的样本中,有7 972条签到数据预测正确,其余预测值与真实值不符,其中273条被预测为Entertainment;在对活动语义真实值为Entertainment样本的预测结果中,有250条被预测为Shopping。
观察混淆矩阵不难发现,模型对Education、Medical、Service等活动类别识别较为准确,此类标签在数据集中通常对应具有特殊性的签到地点,例如教学楼、诊所、药店、政府大楼、银行等。由于活动语义、签到地点间的关联性及地点本身的特殊性,通过POI名称文本隐含的语义信息即可实现一定程度的活动判断,并结合签到时空特征进一步提升识别准确性。同时,模型在Entertainment类、Restaurant类和Shopping类活动样本间出现了较多误识别情况。通过观察数据集相关样本,能够发现出现误识别的活动类别间存在时空重叠,即用户进行几种活动的时间、空间信息相似度较高。另外,Entertainment类活动语义范围广泛且模糊,部分样本的时空特征与Restaurant类、Shopping类活动并不存在明显界线,相关活动类别的区分主要根据签到地点名称文本进行,在文本信息不足以体现区别时易造成混淆。
为了进一步验证模型性能,将MFAR算法与位置感知Dirichlet分配(location-aware latent Dirichlet allocation, LLDA)算法[2]、相似用户模式 (similar user pattern, SUP)算法[21]和多层感知机(multi-layer perception, MLP)基线模型进行对比,通过评价指标及十折交叉验证标准差衡量算法的个体活动识别性能。其中SUP算法对相似位置进行分类,获取用户偏好相似度及用户间签到活动的关联,引入了名为相似用户模式的位置特征,通过多个分类器对位置语义标签进行识别。实验采用SUP算法提取用户特征,并结合其他特征识别个体活动。LLDA算法采用DBSCAN算法对空间位置进行聚类,并结合LDA主题生成模型获取区域及潜在活动的主题分布,建立用户兴趣评分模型,将最高分值对应活动类别作为用户活动语义。此外,作为基线对比实验,本文采用MLP构建分类器模型,各隐藏层之间全连接并在各神经元添加ReLU激活函数,将联合特征向量输入模型,最终由softmax层输出属于不同类别的概率,取概率最大类别作为分类结果。
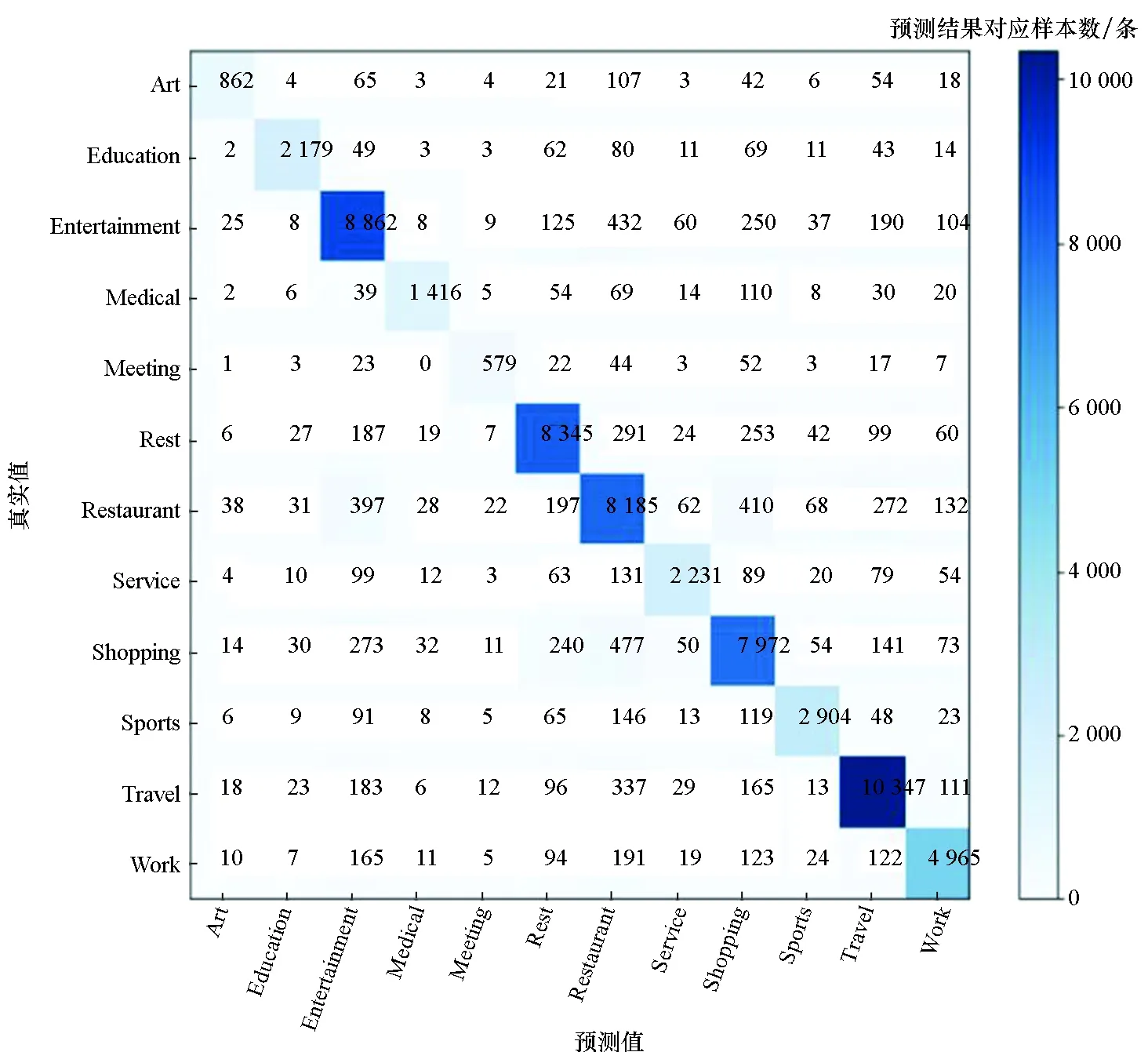
图9 MFAR算法识别混淆矩阵Fig.9 Identify confusion matrix of MFAR
对比实验结果如表2所示,MFAR算法在识别准确率上相比较于SUP算法提高了42个百分点,相较于LLDA算法提高了11个百分点,在和MLP基线模型的对比中准确率也提升了4个百分点。
基于Foursquare东京数据集的活动语义识别算法对比实验结果如表3所示,在该数据集上,本文MFAR算法的识别准确率相较于SUP算法提高了43个百分点,相较于LLDA算法提高了10个百分点,与MLP基线算法实验结果相比,准确率提升了26个百分点。
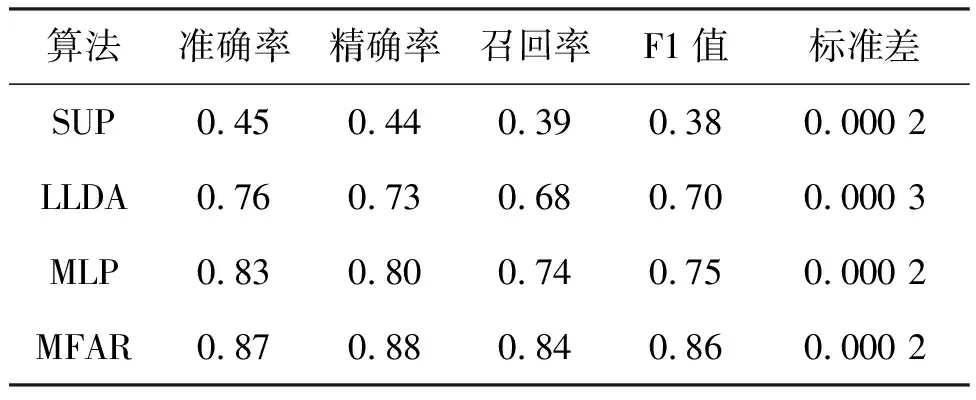
表2 纽约市数据集的活动语义识别算法对比结果Tab.2 Comparison of several activity semantics recognition algorithms on New York City dataset

表3 东京数据集的活动语义识别算法对比结果
对比两数据集实验结果能够发现,本文算法及LLDA的准确率在表3所示实验中有明显提升,推测为东京数据集数据量较纽约市数据集更大,使得本文模型的训练更为充分。而SUP算法性能不佳的可能原因在于稀疏签到数据集不易获取活动及用户的相似性。此外,对比结果也表明在个体活动语义表达上,MFAR提取的文本及空间特征优于LLDA挖掘的空间信息与潜在活动主体分布。
综合上述实验结果,本文提出的MFAR算法在基于Foursquare数据集的个体用户活动识别任务中具有更好的表现。
5 结论
本文提出了一种结合空间偏好和POI语义信息的个体活动语义识别算法。重点研究了空间访问偏好和POI语义对个体活动语义识别的影响,并且通过实验对比验证了这两个特征在活动语义识别中的作用,与其他算法的对比也证明了本文算法的性能优势。本文在特征挖掘中还存在一些不足,对空间信息的挖掘中主要通过区域访问频率来反映个体对空间区域的偏好,缺少对群体空间访问偏好与个体空间访问偏好之间的联系的挖掘,因此,未来工作中将就社交网络关系等群体与个体活动的潜在关联进一步融合到特征表示中进行研究,提高模型的活动识别能力。
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
北京航空航天大学学报(2022年8期)2022-08-31
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
劳动保护(2019年7期)2019-08-27
当代陕西(2019年10期)2019-06-03
福建基础教育研究(2019年11期)2019-05-28
长江学术(2016年4期)2016-03-11
中学科技(2015年1期)2015-04-28
人间(2015年21期)2015-03-11
长江学术(2015年1期)2015-02-27
