
基于PCA-SOA-ELM 的空调系统负荷预测
2022-06-07 01:21:00闫秀英李忆言杜伊帆闫秀联
分布式能源 2022年2期
闫秀英,李忆言,杜伊帆,闫秀联
(西安建筑科技大学建筑设备科学与工程学院,陕西省 西安市 710055)
0 引言
“碳达峰、碳中和”目标下,建筑领域节能减排任务艰巨。据国家能源局发布的统计数据,2021年全国发电装机容量约23.8亿kW,同比增长7.9%[1]。空调负荷的高峰期与电力负荷高峰期呈现正相关关系,尤其在夏季高峰时期,陕西省空调最大制冷负荷占总负荷的比值高达35.9%[2],因此也成为了一种潜力很大的需求响应资源,对其采取能耗削减措施可以进一步推动建筑“碳达峰、碳中和”[3]。空调系统需求响应的峰值负荷预测可以为系统优化控制策略提供理论依据,提前制定最佳运行策略,提高系统的需求响应潜力[4]。因此,研究空调系统需求响应时段负荷的特点以及影响因素,构建负荷预测模型,进行准确的峰值负荷预测是空调系统需求响应控制策略是否节能和稳定运行的关键。
负荷预测方法通常分线性方法和非线性方法。线性方法如参数回归分析[5]、相似工况预测[6]、时间序列[7]、指数平滑法[8]等。其中,多元线性回归法需要充分考虑各个影响因素的特点,分析影响因素对空调能耗的影响程度,且对历史数据依赖性较强,需大量时间进行数据修正。相似工况预测构建的模型依赖于历史数据,如果未来预测日和历史日相似度比较低,预测结果将会产生较大的偏差。时间序列法只适合中短期预测,当外界因素发生变化时,预测结果有时不符合实际规律。空调负荷有很大的随机性和波动性,线性方法不能处理空调负荷与影响因素之间这种非线性关系,而人工智能算法凭借着强大的非线性映射能力,逐渐被应用于空调负荷预测,提高预测的准确性。非线性方法包含人工神经网络[9]、支持向量机[10],以及极限学习机(extreme learning machine,ELM)[11]等智能算法。
近年来,基于ELM 的方法由于其更快的训练速度以及更强的处理大量样本、高维数据的能力,预测效果显著,备受研究人员青睐[12-13],国内外开展了一系列的研究。有学者提出,利用蝙蝠算法对ELM 的隐含层节点个数进行优化,可以解决ELM在预测阶段出现的不稳定问题,但此方法仅针对单一量控制,无法顾及到权值与阈值[14];另有学者提出利用改良遗传算法对ELM 的权值和阈值进行优化,但此方法存在算法过于繁琐的缺点[15]。更有研究利用多目标粒子群算法优化ELM 参数,然而这种方法易陷入局部最优而导致参数优化不佳,从而对ELM 的稳定性产生不良影响[16]。对于ELM 负荷预测时的特征选择,利用核主成分分析法对外部气象因素进行优选[17],但在历史负荷特征进行选择的方面并未能做出最优选择;利用最大交互信息系数[18]可以得到较好的特征选择结果,但经过筛选的特征中仍含有大量无效信息。
针对预测过程中利用随机数作为初始参数以及未准确选择合适的特征导致ELM 的稳定性产生较大的波动这一问题,提出一种基于主成分分析(principal component analysis,PCA)和海鸥算法(seagull optimization algorithm,SOA)优化ELM的空调负荷预测方法,从而提高预测网络的稳定性与准确性。首先,对于所采集办公建筑各参数之间相互影响的问题,采用PCA 对数据进行降维,降低数据规模的同时对空调负荷影响因素进行特征提取;其次,进行ELM 空调系统负荷预测模型建立,且利用SOA 迭代寻优ELM 的输入权值矩阵和隐含层阈值,去除原参数选取的强随机性对模型泛化能力和预测性能的影响,最后,建立基于PCA-SOAELM 的空调系统需求响应时段负荷预测模型,仿真对比分析模型性能。
1 优化方法
1.1 极限学习机
ELM 是一种单隐层神经网络[11],其输入权值矩阵、隐含层偏置是随机设置的,且在训练中无需调整。其在保证网络训练参数少、学习速度快、泛化能力强以及建模精度高等优势的同时,避免了由于梯度下降算法产生的诸多缺陷,目前已广泛应用于负荷预测[19]、故障诊断[20]、图像处理[21]、人脸辨别等领域。
1.1.1 基本原理
设输入变量xi=[xi1,xi2,…,xin]T∈Rn,输出变量yi=[yi1,yi2,…,yim]T∈Rm。假定ELM网络有n 个输入神经元,L 个隐含层神经元,m 个输出层神经元,其网络结构如图1所示,数学表达为:
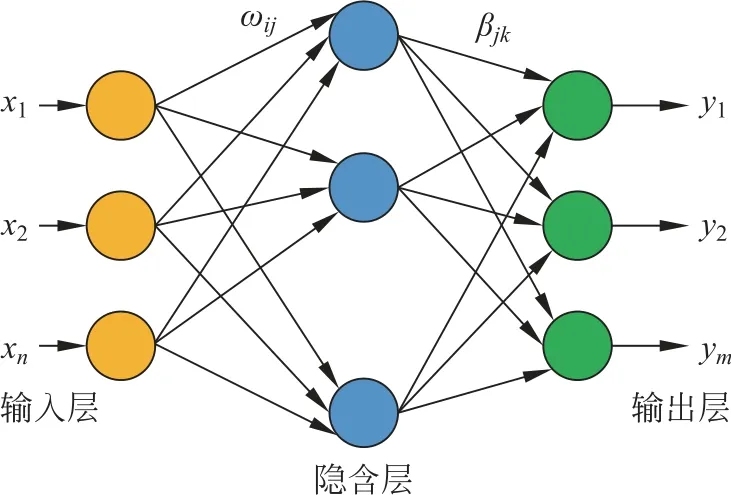
图1 网络结构示意图Fig.1 Network structure diagram

式中:g(ωi,xi,bi)为ELM 网络激活函数;ωi=[ωi1,ωi2,…,ωin]T∈Rn为ELM 网络输入权值;βi=[βi1,βi2,…,βin]T∈Rn为ELM 网络输出权值;bi=[bi1,bi2,…,bin]T∈Rn为ELM 网络隐含层阈值。式(1)矩阵表达式:

式中:T′为网络输出的转置矩阵;H 为网络的隐含层输出矩阵。
由式(3)方程组的最小二乘解求隐含层与输出层间的连接权值β:

其解为:

式中:H+为隐含层输出矩阵H 的Moore-Penrose广义逆。
1.1.2 ELM 算法流程
ELM 算法流程为:
(1) 确定隐含层神经元个数,随机设定输入层与隐含层间的连接权值ω 和隐含层神经元的偏置数b。
(2) 选择一个无限可微的函数作为隐含层神经元的激活函数,进而并计算隐含层输出矩阵H。
ELM 常用的激活函数分别为:
Sigmoid函数
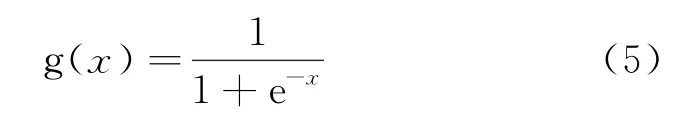
Sine函数

Hardlim 函数
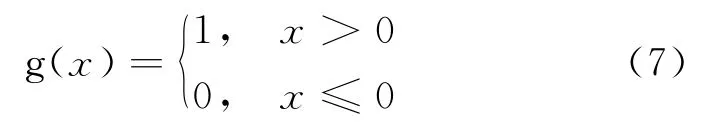
1.2 海鸥优化算法
2019年,学者Gaurav Dhiman[22]提出SOA,对海鸥各种行为方式进行模拟。该算法相较于其他算法,调整参数较少、寻优精度高、收敛效果好,具有明显优势,其搜索的全面性与优越性得到广泛认可。因此利用SOA 优化ELM 的ω 和b,可以避免原参数选取的强随机性对模型泛化能力和预测性能的影响,从而得到预测模型最优参数配置。
1.3 主成分分析
对多维变量进行降维,一般考虑PCA 对数据的特征矩阵进行矩阵分解与压缩,将n 维特征变量映射到m 维变量(n>m),m 维变量则被称为主成分[23]。
2 SOA-ELM 模型
2.1 SOA-ELM 预测模型构建
ELM 的预测性能往往与随机生成的输入权值矩阵ω 和隐含层阈值b 有很大关联,为尽可能消除随机选取参数对模型泛化能力和预测性能的影响,利用SOA 算法对ωj和bj进行迭代寻优,进而建立SOA-ELM 预测模型,模型流程如图2所示。
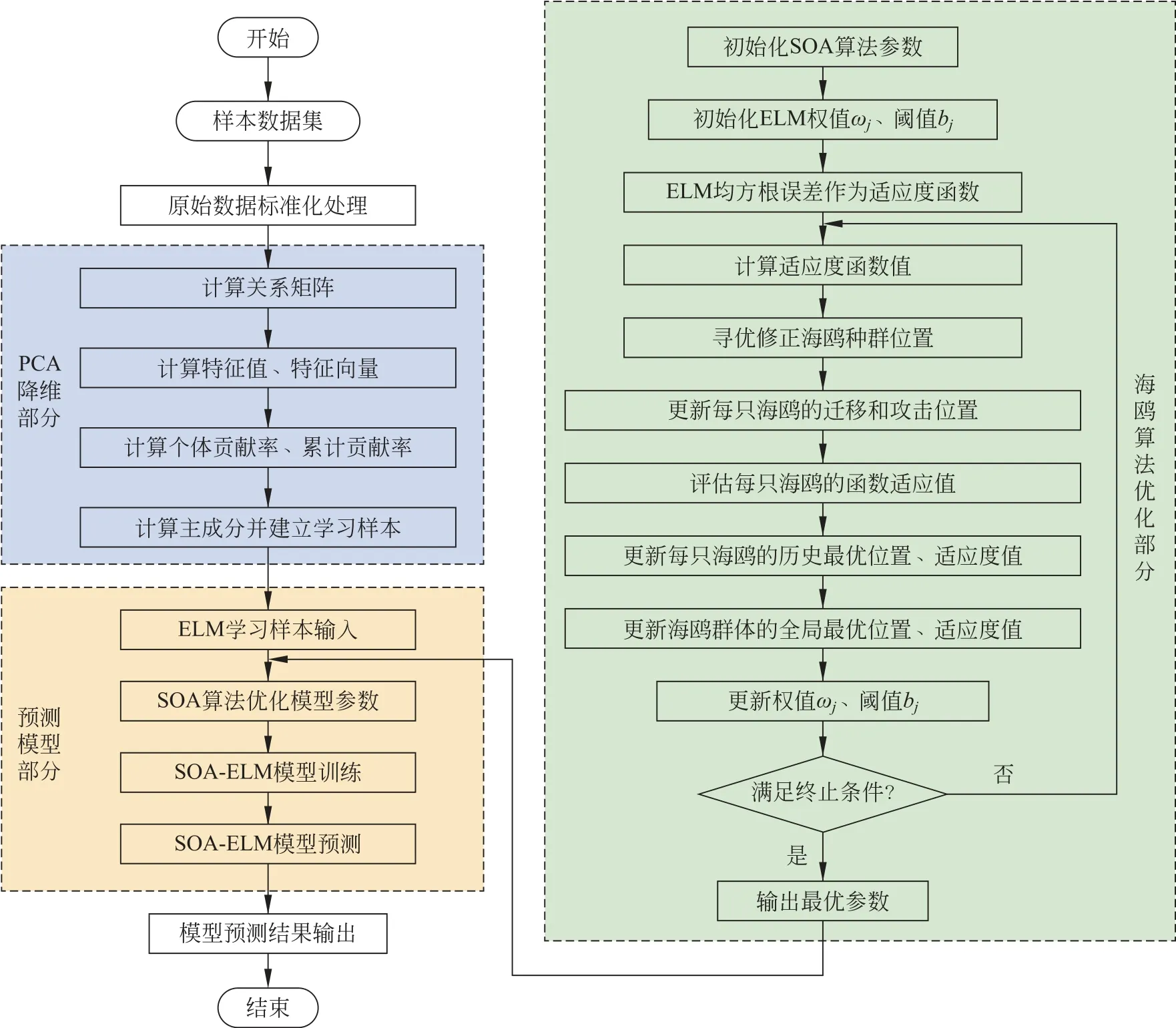
图2 SOA-ELM 模型负荷预测流程图Fig.2 SOA-ELM model load forecast flow chart
首先,对样本进行预处理,并设置SOA 中的初始化参数,即海鸥群体规模、搜索空间常数、种群位置的上下界及最大迭代次数;其次,以均方根误差函数为适应度函数,计算每个海鸥的初始适应度值并排序,其中适应度函数值最优者为当前最优位置,即海鸥领导者;当前迭代次数未达到最大迭代次数时,对海鸥群领导者与追随者进行位置更新,同时计算位置更新后每一个体的适应度函数值,并依据数值优劣进一步更新最优种群位置,满足终止条件时,输出最优的ωj和bj;最后,将SOA 寻优得到最优的ωj和bj赋予ELM 模型,得出相关负荷预测结果。
2.2 预测模型评价指标
为了验证SOA-ELM 空调负荷预测模型的预测效果,取均方根误差(root mean square error,RMSE)eRMSE,平均绝对百分比误差(mean absolute percentage error,MAPE)eMAPE和决定系数R2这3个指标对模型性能进行评价。其计算公式如下:

3 实例分析
以某高层综合办公楼为研究对象,对其2021年7月每天08:00—22:00采集的实时数据展开分析,数据采样步长为1 h,样本数为740,在建立预测模型时,将其中四分之三作为训练集,四分之一作为测试集,来验证所建负荷预测模型的准确度。所研究的空调系统设备参数如表1所示。本文实际共采集了8组数据,分别为T 时刻冷负荷、T-1时刻室外干球温度、相对湿度、T-1时刻冷负荷、风速、T 时刻室外干球温度、T-1时刻太阳辐射值与温度设置值。
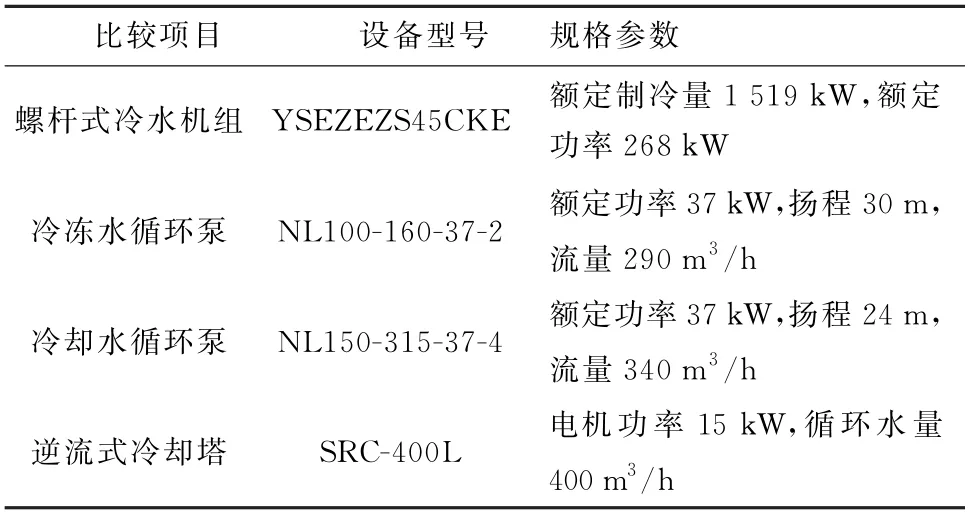
表1 冷源系统设备参数Table 1 Cold source system equipment parameters
3.1 特征指标提取
不考虑空调内部因素对负荷造成的影响,只考虑空气温度、空气湿度、风速等气象因素。
表2为特征提取初选指标后计算得到的因素特征值与贡献率,由表2可知,提取的前6种主成分即可解释98.00%的信息,其特征解释率为42.49%、20.21%、14.82%、9.83%、7.74%、2.82%,故将前6项作为影响空调负荷的决定性指标。
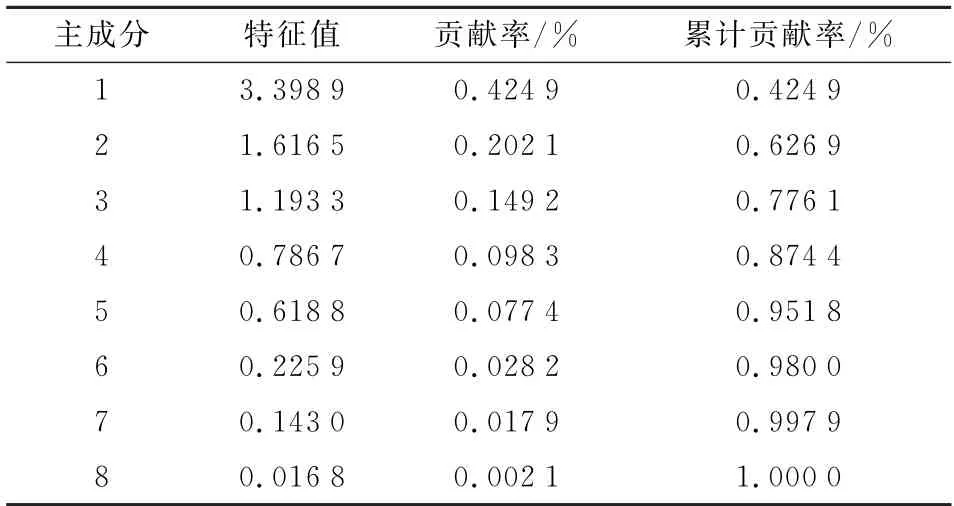
表2 特征变量提取Table 2 Feature variable extraction
利用Origin软件绘制累计方差贡献度占比图,如图3所示,曲线以降维后保留的特征个数为横坐标,新特征矩阵可解释方差贡献率为纵坐标。
根据图3 贡献度占比图分析结果,最终选择T-1时刻冷负荷、太阳辐射、T-1 时刻室外干球温度、T 时刻室外干球温度、室内温度值和相对湿度作为模型输入。

图3 贡献度占比图Fig.3 Contribution ratio chart
3.2 参数设置
ELM 学习性能也依赖激励函数和隐含层节点数的优选。依据遍历法对所有可能的取值依次进行仿真寻优,得出最佳的隐含层节点数为95,如图4 所示。仿真比较各个激励函数的泛化性能指标,结果见表3。由表3知,网络复杂情况一致时,Sigmoid性能指标最优,训练时间最短。因此ELM 的激活函数选定Sigmoid函数。由图4可知,隐含层节点数为95时,函数数值最小,收敛性能较好。
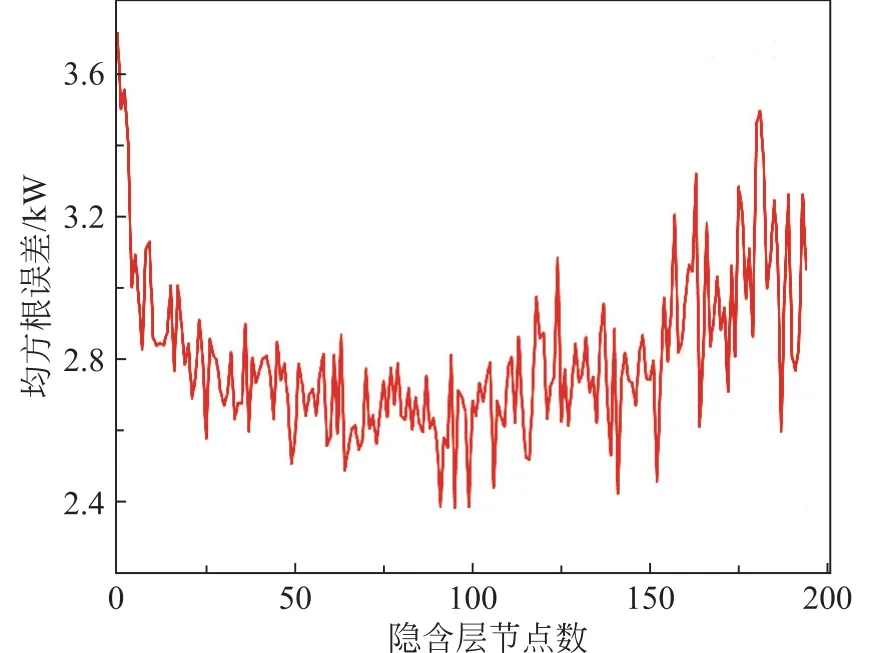
图4 隐含层节点选取Fig.4 Hidden layer node selection
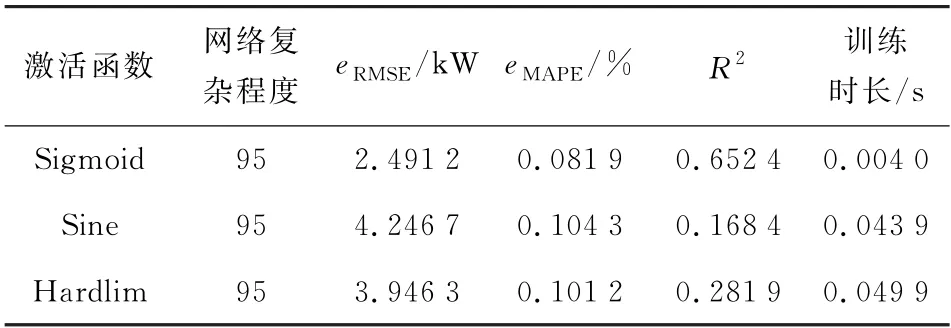
表3 ELM 激活函数的性能比较对比Table 3 Performance comparison and comparison of ELM activation functions
3.3 空调负荷预测结果分析
SOA 初始化设置为:总样本量20、最大迭代次数为200、fc=2、u=1、v=1、搜索空间上下限分别为1和-1。
利用SOA优化ELM 的ωj和bj,SOA-ELM 的寻优过程共迭代200次,适应度收敛曲线如图5所示。
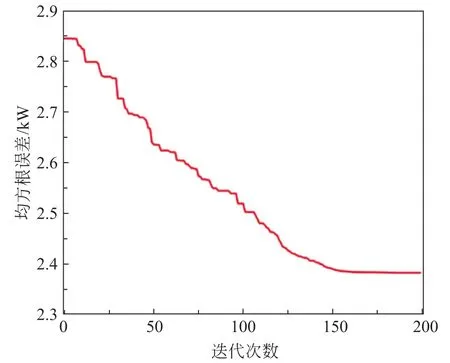
图5 适应度收敛曲线Fig.5 Fitness convergence curve
采用均方根误差作为迭代时的适应度函数,经迭代150次后,均方根误差数值稳定在2.38,适应度曲线收敛并获得最优适应度值,表明在此参数集下SOA-ELM 算法收敛性能良好。此时可获取最优的ELM 负荷预测模型ωj和bj,最终建立SOAELM 空调系统需求响应时段负荷预测模型。
为深入评价预测效果,采用性能评价指标分别对预测模型进行评价,结果见表4。
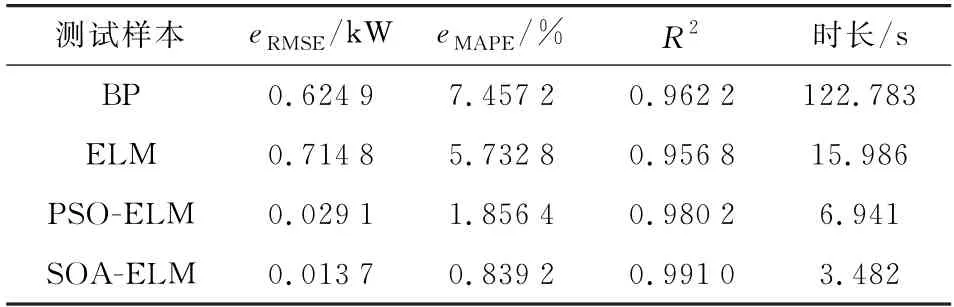
表4 模型性能评价指标对比Table 4 Model performance evaluation index comparison
由表4可知:相比较于BP、ELM、PSO-ELM 这3种模型,SOA-ELM 模型的均方根误差分别降低了0.008 2、0.011 6、0.002 1,平均绝对百分比误差分别降低了7.494 8%、5.162 9%、1.011 9%;预测时长相较于BP、ELM、PSO-ELM 也分别降低了119.301、12.504、3.459;且SOA-ELM 的R2高达0.991 0,相较于其他模型数值最趋近于1。证明了SOA-ELM 泛化能力更强、预测精度更高、预测时长更短,具有更高的可靠性,可应用于空调系统需求响应时段的负荷预测。
图6为预测结果,其中,图6(a)为预测误差对比图,图6(b)为预测值对比图。由图6(a)可知,对数据进行PCA 降维处理后,BP、ELM、PSO-ELM、SOA-ELM 平均绝对误差分别为1.27%、1.06%、0.79%、0.33%,SOA-ELM 模型预测误差相较于其他模型的预测误差更优,说明PCA-SOA-ELM 模型预测准确度提升较大,预测效果更佳。由图6(b)所描述的4种模型预测值与真实值的对比可得,SOAELM 预测模型的预测值相比较于BP、ELM、PSOELM 模型都越接近真实值,拟合情况更优越,预测效果更明显。
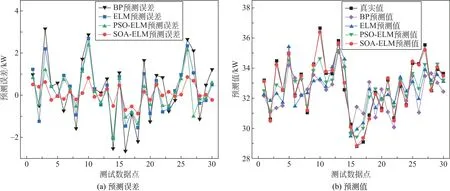
图6 预测结果分析Fig.6 Analysis of forecast results
表5列出了4种模型测试集实际值与预测值的对比,其中包括预测输出值对比与绝对误差对比2部分。
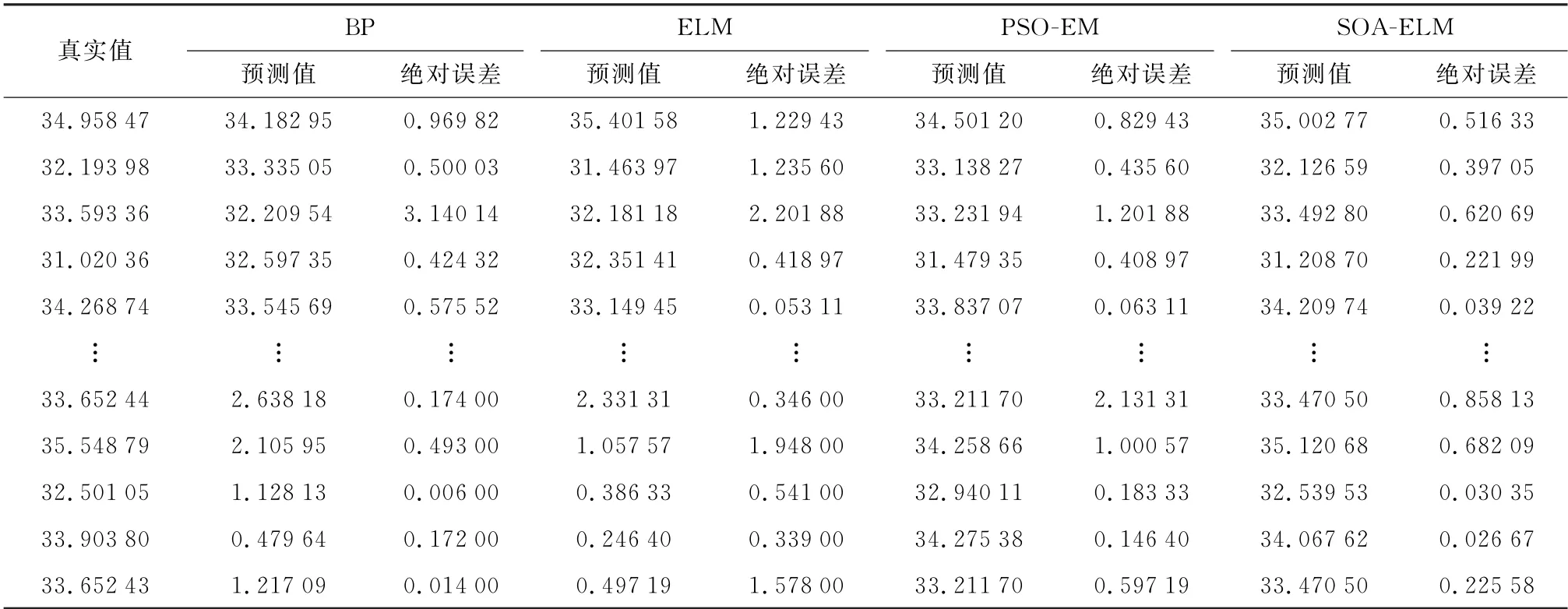
表5 空调负荷实际值与预测值对比Table 5 Comparison between actual and predicted air conditioning load kW
4 结论
将某高层建筑综合办公楼宇作为研究对象,提出了一种基于PCA 和SOA 优化ELM 的空调系统需求响应时段负荷预测方法,根据仿真试验得出以下结论:
1) 针对所采集参数之间相互影响的问题,采用PCA 对数据进行降维,消除数据耦合,降低数据规模的同时对空调负荷影响因素进行特征提取。经主成分分析特征提取后得到包含98.00%原信息的6项主成分,说明PCA 具有很好的降维和特征提取能力。
2) 利用SOA 优化ELM 的ωj和bj,显著提高了模型的预测性能,其预测结果的均方根误差为0.013 7,平均绝对百分比误差为0.839 2%,决定系数为0.991 0,训练时长为3.482 s,均优于BP、ELM、PSO-ELM 的预测结果,证明了SOA-ELM具有更佳的泛化性能和预测精度。
猜你喜欢
计算机仿真(2022年8期)2022-09-28 09:53:02
成都信息工程大学学报(2022年3期)2022-07-21 09:35:04
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
小学阅读指南·低年级版(2017年5期)2017-05-18 11:18:41
自动化学报(2017年7期)2017-04-18 13:41:02
汽车维护与修理(2016年10期)2016-07-10 08:17:41
中国塑料(2016年11期)2016-04-16 05:26:02
汽车维护与修理(2015年7期)2015-02-28 12:18:16
教育与职业(2014年16期)2014-01-19 01:24:36
舰船电子工程(2010年1期)2010-04-26 05:06:48
