
基于GIS 和历史卫星影像的城市建筑大数据识别
2022-06-06 14:46:22邓章陈毅兴
湖南大学学报(自然科学版) 2022年5期
邓章,陈毅兴,2†
(1.湖南大学土木工程学院,湖南长沙 410082;2.建筑安全与节能教育部重点实验室(湖南大学),湖南长沙 410082)
随着城镇化进程加快,建筑能耗总量不断上升,建筑成为第三“能耗大户”[1],因此建筑节能对城市的可持续发展尤为关键.建筑能耗模拟可用于评价节能技术措施[2].城市尺度的建筑群能耗模拟是国际城市能源研究领域的一个新兴方向,可以更好地评估新区能源规划和旧区节能改造等技术方案,从而推动节能减排目标的实施.由于缺乏每栋建筑的详细数据,在城市建筑群能耗模拟中,围护结构和空调系统等参数一般根据典型建筑进行假定,而建筑类型及建造年代是典型建筑参考的主要依据[3].
目前获取数据最直接的方法是利用政府机构公开的数据平台,绝大部分的研究中都采用这种方式.欧美一些大城市的数据平台存储了大量城市建筑信息,如建筑轮廓、楼层数、建筑类型和建造年代等数据[4-5],可用于建筑群能耗模拟.公开数据平台节省了大量收集数据的时间,但受限于特定的城市.另一种直接的方法是实地调研[6].当调研的范围扩大至城市级别,是极其耗时耗力的.
当较难获取直接的数据时,可运用相关的数据来间接推断建筑类型及年代.对于建筑分类,首先可以利用多种数据进行识别.Wang 等人[7]使用建筑轮廓和城市电子地图信息点(POI)数据,运用逻辑回归的监督学习算法识别出南京市2 275 栋商业建筑.Niu 等人[8]使用微信定位数据、出租车GPS 轨迹及POI等数据,运用空间聚类算法推断广州天河区各建筑功能.Deng 等人[9]提出了基于POI 和区域边界轮廓等地理信息系统(GIS)数据,运用分类和无监督学习聚类的方法,识别出长沙市区68 966 个建筑轮廓中69%的建筑类型.对于未识别的21 538 个建筑轮廓,其大部分为老旧住宅建筑,只含建筑轮廓面积和楼层数等几何信息.仅已知建筑几何信息时,Hecht等人[10]基于建筑轮廓数据的几何特征,运用随机森林的监督学习算法,主要将住宅建筑分为11 种类型,非住宅建筑分为工业和商业建筑.Lu 等人[11]基于建筑轮廓的面积、周长和高度,周边80 m内其他建筑信息和周边道路、停车场、植被的信息,运用决策树和随机森林等四种监督学习算法,将建筑分为单户住宅、多户住宅和非住宅建筑,四种算法中准确率最高为76.1%.
对于建造年代,Biljecki等人[12]基于3D建筑模型(CityGML)的建筑类型、高度、邻近建筑数量及体积等9 种属性,运用随机森林的监督学习算法推测建筑年代.Tooke等[13]和Rosser等[14]均基于遥感数据的建筑轮廓面积、周长、屋顶倾斜度及体积等二维和三维属性,运用随机森林算法分别推测3 282栋和2 553栋住宅的建筑年代.监督学习需要大量已知的样本进行训练,更适用于城市内的街区尺度.Zirak 等[15]根据建筑年代普查数据随建筑类型和供热面积的分布,指定对应建筑的年代.Schwanebeck 等[16]根据土地普查数据获取住宅地块内的建筑年代.然而这些普查数据有时较难获得.Li等[17]和Zeppelzauer 等[18]运用卷积神经网络的深度学习算法提取街景图像特征,对不同时期的特征进行分类从而推断独户住宅的年代.近些年来,遥感影像(航空等影像)被广泛用于提取建筑物信息[19].Deng 等人[9]通过人工对比历史卫星影像数据,获取243 栋建筑年代信息.相比于街景图像受限于地理位置,航空影像成图范围小,卫星影像对整个城市具有更全面的覆盖,因此历史影像的自动对比对于大规模运用是省时省力的.
综上所述,一种基于有限和公开数据来识别建筑类型和年代的方法将具有更好的适用性.本文基于长沙市区未识别的21 538 个建筑轮廓的几何特征,运用监督式分类学习算法识别建筑类型.本文同时利用基于深度学习的图像识别算法,自动提取历史卫星影像的建筑轮廓,检测建筑物变化,用于推断长沙市区大量建筑的建造年代.
1 研究方法
1.1 基本信息
本文的研究区域为长沙市.在建筑类型识别方面,先前的研究通过城市地图信息点POI 和区域边界轮廓数据已成功识别出长沙市区68 966 个建筑轮廓中69%的建筑类型.图1展示了21 538个没有POI和区域边界轮廓数据的建筑轮廓在长沙市五区的分布及示例,数据来源于2017 年.其中18 933 个建筑轮廓包含地上楼层数信息,6 层及以下建筑占比为91%.卫星影像是指卫星拍摄的真实地理面貌,可用来检测地面上建筑、道路等信息.通过历史卫星影像的对比,可观测地理信息的变化.目前谷歌地球免费支持查看和下载高精度的历史影像,因此根据时间轴获取长沙市五区2005—2014年的影像数据.
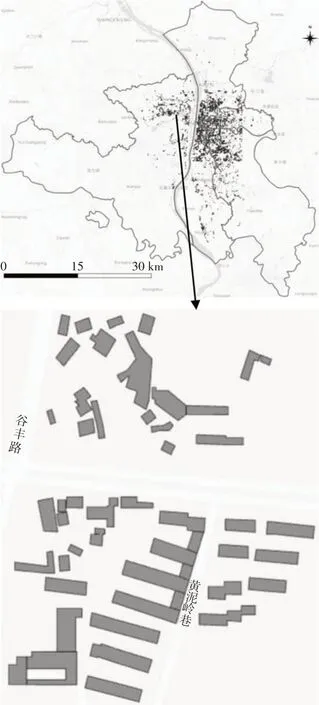
图1 长沙市五区建筑轮廓及示例Fig.1 Building footprints in five districts of Changsha
1.2 建筑类型分类
图2 所示为建筑类型分类的流程图.第一步是通过分析建筑轮廓和楼层数据来获取每栋建筑的特征参数,包括地上楼层数、轮廓面积、轮廓周长、近似矩形短边宽度、近似矩形长宽比、近似矩形系数.首先,地上楼层数的信息大部分来自GIS 数据库,对于2 605 个缺少楼层信息的建筑,利用百度街景手动补全.然后,利用地理信息系统软件QGIS 计算获得每个建筑轮廓的面积和周长.建筑轮廓的形状与建筑类型有较大关系,但是建筑轮廓的信息很难直接使用轮廓的坐标点进行分析,因此需要引入其他参数来反映轮廓的形状特点,如住宅建筑大多为长条形.本文就此提出了近似矩形的概念,当对轮廓进行旋转操作后,每个旋转角度都对应一个矩形框包围轮廓各边界点.选取面积最小的矩形框作为轮廓的近似矩形,如图2 所示.轮廓面积与最小矩形面积的比值定义为近似矩形系数,系数越接近1,表示轮廓形状越近似于矩形.同时近似矩形的长宽比和短边宽度也能描述形状特征,因此增加了近似矩形短边宽度、近似矩形长宽比和近似矩形系数3个特征参数.
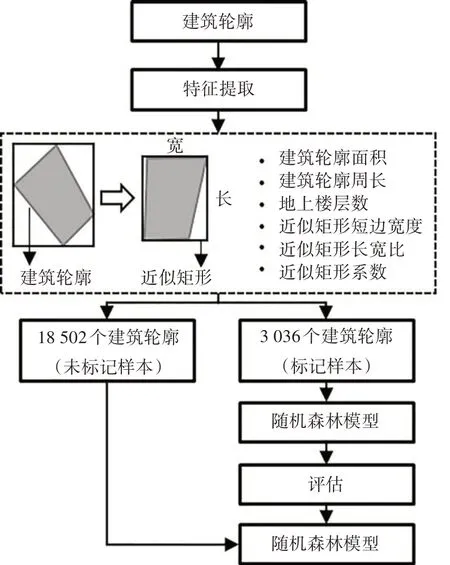
图2 建筑分类流程图Fig.2 Workflow of building type identification
第二步是根据百度街景对3 036 个建筑轮廓的实际建筑类型进行标记.通过卫星图发现建筑轮廓中绝大部分为老旧住宅建筑,由于当时没有小区边界的概念而未被识别.其他类型的建筑由于数量较少,进一步细分后将没有足够的数据进行监督学习训练,因此本文将建筑轮廓的类型分为低层住宅、公寓式住宅和其他类型.标记得到低层住宅845 个,公寓式住宅1 547个,其他类型644个.图3所示为各类建筑轮廓的特征参数分布.从图3 可看出低层住宅和公寓式住宅具有不同的特点,如绝大部分低层住宅的轮廓面积、轮廓周长小于公寓式住宅,低层住宅地上楼层数的中位数为2,而公寓式住宅地上楼层数的中位数为6.后续的随机森林分类模型学习分析各类特征参数的特点,从而识别出不同类型.
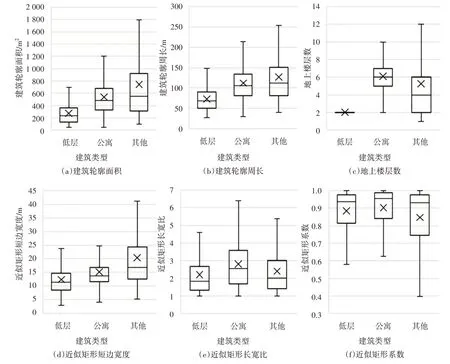
图3 标记的3 036个建筑轮廓特征参数分布Fig.3 Characteristic parameter distribution of 3 036 labeled building footprints
本文采用了随机森林的分类模型,将6 个参数作为模型输入,建筑类型作为模型输出.随机森林是一个包含多个决策树的分类器,决策树是机器学习中一种常用的分类方法,基于if-then-else规则,根据待分类项中相应的特征属性值判断进入相应的分支,直至到达叶子节点,得到分类结果,从而形成一个树状结构.随机森林是用随机的方式生成多个互不关联的决策树,各自独立地学习和预测,最后统计多个决策树投票结果来决定最终结果,因此优于任何一个单分类器的分类结果.本文决策树的数量取值为100,最大深度为10.之后采用k折交叉验证法,评估训练后模型的性能,避免模型出现过拟合.k折交叉验证是指将数据集等比例划分成k份,以其中的1 份作为测试数据,其他的k-1 份数据作为训练数据,随机重复验证k次,k通常取10.最后将训练完成的模型用于18 502个建筑轮廓的分类.
1.3 建造识别
由于卫星影像是可见光成像,极易受气候条件影响,存在云层遮挡和光线不同等问题,因此筛选出高质量成像且光影效果较为接近的影像,分别是2005 年、2008 年、2012 年和2014 年,地面分辨率为0.53 m,图像格式为tiff 格式.图4 所示为建筑建造年代识别示意图.两个不同年代的卫星影像作为输入,通过卷积神经网络方法实现图像分割,分别识别和生成建筑物轮廓矢量数据.由于每次卫星拍摄影像时角度不同,导致不同的影像中建筑物存在一定的偏移,因此利用QGIS 的相交分析工具,考虑两建筑相交重叠部分超过50%,判断为同一建筑,然后检测出变化的建筑,从而确定它们的建造年代为2013—2014年.

图4 建造年代识别示意图Fig.4 Workflow of built year identification
卷积神经网络(CNN)是一种包含卷积计算且具有深度结构的神经网络,属于深度学习的范畴,在图像识别中得到广泛应用.相比于传统的神经网络需要读取整幅图像,CNN能够有效地将大数据量的图像降维成小数据量,且同时保留图片特征.典型的CNN 由卷积层、池化层和全连接层3个部分构成.卷积层通过卷积核(过滤器)的过滤提取出图片中局部的特征;池化层用于继续降低数据维度,可大大减少运算量;全连接层与传统神经网络结构类似,用来输出结果.目前CNN有FCN、U-Net等多种代表算法用于图像语义分割,Mask R-CNN算法用于实例分割.语义分割是指为图像中的每个像素打上类别标签,而实例分割是目标检测和语义分割的结合,能区分同类中的不同实例.影像中识别出建筑物并提取轮廓,属于实例分割的范围,因此本文选取Mask R-CNN算法.
Mask R-CNN 算法属于监督学习,需要用标记的样本对模型进行训练,我们选取了2014 年影像中的一个区域,运用已有的1 602 个建筑轮廓矢量数据作为标记数据,包含多种不同形状,但不包括建筑的阴影,如图5 所示.由于卫星在拍摄影像时存在一定的倾斜角度,导致GIS 数据与影像存在偏差,如图6(a)所示,神经网络对这种类型的噪声较为敏感,为了提高标记数据的质量,对建筑轮廓进行了相应的平移调整,如图6(b)所示.然后将影像通过滑动窗口切片成256×256 像素尺寸,并且考虑切片边缘的重叠,再使用旋转、缩放、平移等数据增强方法来增加有限的数量集,确保模型的识别精度和泛化能力,获得2 145 个地图瓦片图片作为数据集.之后选用Python 和PyTorch 深度学习框架对模型进行训练和调参.数据集按9∶1 划分为训练集和验证集,模型的骨干网络(backbone)选取ResNet50,训练轮数(ep⁃ochs)选取20,并且在学习曲线中自动提取最佳学习率.最后基于训练好的模型输入不同年代的影像进行预测生成相应的建筑轮廓.

图5 标记的建筑轮廓和影像Fig.5 Labeled building footprints and imagery

图6 建筑轮廓和影像对齐调整Fig.6 Alignment and adjustment of building footprints and imagery alignment
2 结果分析
2.1 建筑分类结果
随机森林模型中采用C4.5 算法,以信息增益率为准则选择属性.图7 展示了各特征参数重要度,可见楼层数对建筑分类最为重要,其次是近似矩形短边宽度,轮廓周长的影响最小.采用混淆矩阵对各个类型的识别效果进行评估,如表1 所示,其中对角线上的值表示正确分类的样本.10 折交叉验证后结果显示,整体准确率为81.7%,与文献[11]中用面积、周长等基本属性分类得到的76.1%准确率相比,该方法得到了有效提升.准确率表示预测正确的结果占总样本的百分比.除了准确率外,还采用精确率和召回率评估不同类型的识别效果.精确率表示所有被预测为某类的样本中实际为该类样本的概率,召回率表示实际为该类样本中被预测正确的概率.由表1 可看出,低层和公寓式住宅召回率都在98%左右,表示可以很好地被推断正确.但低层和公寓式住宅精确率在80%左右,是由于其他类型中包含零售商店和饭店等类型,在几何特征上与低层住宅相似,其他类型中包含学校和行政楼等类型,在几何特征上与公寓式住宅相似,因此它们中有一部分被错误地推断为其他类型.

图7 各特征参数重要度Fig.7 Importance of each characteristic parameter
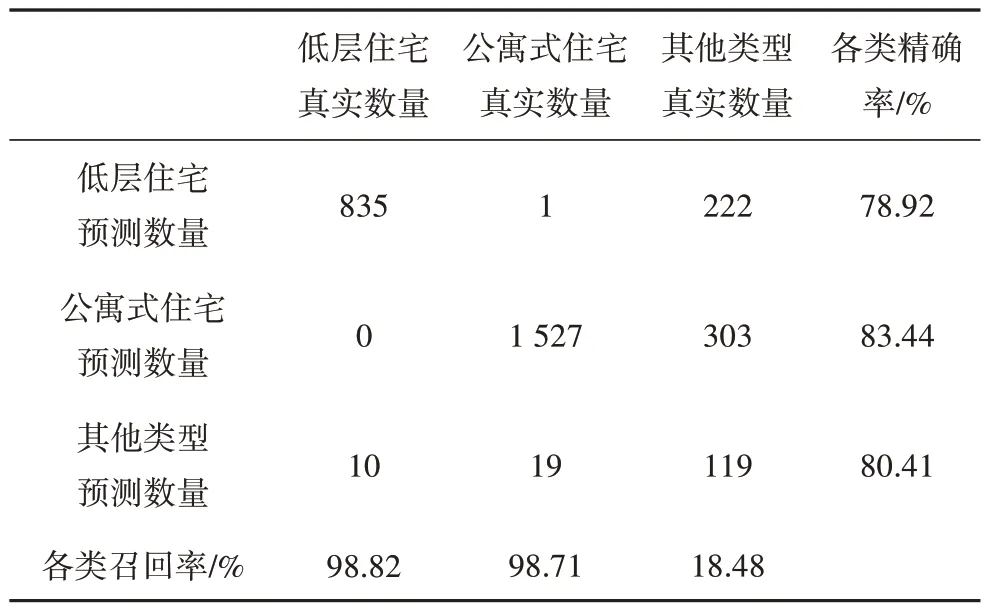
表1 随机森林模型分类结果Tab.1 The result of random forest model
将训练好的模型用于预测剩下的18 502 栋建筑类型,结果见表2.数量最多的为低层住宅,共有10 428 栋,以1~3 层为主,较为密集地分布在区域内.公寓式住宅共有5 686 栋,以5~6 层为主,住宅群分布较为均匀.其他类型共有2 388 栋,分布较为分散.

表2 建筑类型预测结果Tab.2 The prediction result of building type
2.2 建造年代识别结果
Mask R-CNN 模型一般选用平均精确度(aver⁃age precision)作为评价指标,平均精确度是对精确率-召回率曲线上的精确率求均值.结果显示平均精确度为80%,对于相互有间隔的建筑能较好地识别,而对密集分布的低层建筑识别较弱.本文选取长沙市中心范围为4.17 km×4.33 km 的区域作为研究区域,将训练完成的模型应用于该区域进行建筑物识别和提取.图8 展示了2014 年、2012 年、2008 年和2005 年四个年代的示例.从图8 可以明显看出每栋建筑随不同年代的变化.

图8 各年代建筑轮廓提取示例Fig.8 The example of building footprints extraction in different ages
根据已有的2017 年建筑矢量数据,依次与各个年代提取的建筑轮廓进行交集计算,将建造年代分为2015—2017 年、2013—2014 年、2009—2012 年、2005—2008 年、2005 年之前等五个阶段,结果如表3所示.在7 900 个建筑轮廓中,5 077 栋(64%)建筑的建造年代在2005 年之前,符合中心城区早期开发建设的情况.

表3 建造年代分布Tab.3 The distribution of built year
3 结论
本文提出了基于GIS 和历史卫星影像数据识别城市建筑类型和建造年代的方法.运用随机森林的监督学习方法,将建筑类型分为低层住宅、公寓式住宅和其他类型.利用卷积神经网络的深度学习方法进行历史卫星影像识别,成功提取各个年代建筑轮廓,然后相交分析推断出建筑年代.主要结论如下:
1)建筑类型识别方面,针对长沙市区21 538 个建筑轮廓(不含POI 和区域边界轮廓信息),提出近似矩形的概念,新增近似矩形短边宽度、近似矩形长宽比、近似矩形系数作为特征参数反映轮廓形状特征.分析显示,楼层数和近似矩形短边宽度是影响分类最为重要的两个特征参数.训练结果显示,分类模型的整体准确率为81.7%.在用于预测的18 502个建筑轮廓中,成功识别出10 428 栋低层住宅、5 686 栋公寓式住宅.
2)建造年代识别方面,训练结果显示,建筑轮廓提取模型的平均精确度为80%.将其应用于长沙市中心区域7 900 个建筑轮廓,交集计算推断出5 077个建筑的建造年代为2005年之前,1 606个建筑的建造年代为2005—2014年,1 217个建筑的建造年代为2015—2017年.
猜你喜欢
课堂内外·小学版(低年级)(2023年6期)2023-04-29 00:44:03
现代装饰(2021年4期)2021-11-02 07:08:22
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:36
学生天地(2020年30期)2020-06-01 02:25:50
现代装饰(2020年3期)2020-04-13 12:54:20
现代装饰(2020年2期)2020-03-03 13:37:40
制造技术与机床(2019年11期)2019-12-04 05:50:54
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:03:44
中学生数理化·八年级数学人教版(2017年4期)2017-07-08 13:04:56
计算机工程(2015年4期)2015-07-05 08:27:39
