
重水堆控制计算机二进制程序反汇编研究
2022-06-06 08:11陆乾杰吴海燕
仪器仪表用户 2022年6期
陆乾杰,赵 心,钱 锐,吴海燕
(中核核电运行管理有限公司 维修五处,浙江 海盐 314300)
0 引言
重水堆核电站采用电站控制计算机(Digital Control Computer,以下简称DCC)进行全厂集中控制,负责反应堆反应性控制、主回路压力和装量控制、蒸发器压力和液位控制等,是整个核电站的控制中枢。国内唯一的秦山三期重水堆电站控制系统由加拿大原子能公司设计,硬件采用SSCI 890(S)系列计算机[1]。该系列计算机为16 位8MHz 集成电路数字机,操作系统(V70 Omnitask Real-time Executive,VORTEX)和核心控制程序均采用SSCI V70 指令集,系统中所有程序均以二进制代码形式运行。虽然大部分程序均有其对应的未编译源码,但是系统中仍然存在大量没有源码的二进制程序,例如系统引导程序、系统测试程序等。对于这些二进制程序进行逻辑功能分析是非常困难和复杂的,因此本文将通过反汇编的方法对二进制程序进行反编译研究,将二进制代码转化成便于理解和阅读的汇编代码。

图1 反编译的解决思路Fig.1 Disassembly pipeline diagram
1 问题的提出和解决思路
1.1 问题提出
在DCC 系统备份和恢复过程中,DCC 程序均以COR 文件类型进行存储。COR 文件是二进制代码,无法直接打开和阅读。而在DCC 的缺陷分析和国产化研究中,出现了对于DCC 二进制程序反汇编的需求,主要来源于以下几个方面:
1)当系统出现异常时,需要对备份出来的数据进行检查和代码分析,通过回溯其代码执行的过程来定位缺陷的位置。
2)在变更或者参数修改时,可能需要查看历史备份数据COR 文件中对应的数值。
3)在执行系统测试时,可能会出现一些无法意料的报错,就需要对测试程序的逻辑进行分析,而现存所有的测试程序均以二进制码的形式存储,无法直接进行分析。
4)在Processor 处理器板卡国产化时,需要对其引导程序进行分析,而引导程序只有二进制码,无法进行分析。
基于以上需求,本文需要对DCC 系统的二进制码进行反汇编研究,只要能将二进制码COR 文件转变成具有可阅读性的文本,以上问题就能迎刃而解。
1.2 解决思路
完成对于二进制程序COR 文件的反汇编工作,首先要对SSCI V70 指令集数据格式进行分析,根据其格式标准对COR 文件格式的分析,将COR 文件中二进制数据从文件中取出来,并且以八进制的形式进行展现。
其次要对SSCI V70 指令集和寻址方式进行分析,对各类指令进行分类,提取特征,根据总结出来的特征完成对于单条指令的反汇编。
最后在完成单条指令反汇编的基础上,对整个程序进行整体反汇编,主要解决整体反汇编中出现的数据区和指令区无法识别的问题,最终形成具有可阅读性的文本。
2 COR数据可视化
2.1 指令数据格式分析
SSCI V70 指令集是16 位指令集,所有的数据和命令仅包含16 位。数据的BIT0-14 表示数值,BIT15 为符号位S,符号位S 为0 表示正数,符号位S 为1 表示负数。在DCC 中负数的数值使用补码表示。地址的BIT15 为指针位I,若指针位I 为1 表示这个地址为指针,实际地址为BIT0-14 地址所指向空间的数值。
2.2 COR文件转化
当程序直接读取COR 文件只能得到字节流数据,如图2。

图2 COR文件字格式图Fig.2 COR Type file in origin format
根据对SSCI V70 指令集数据格式的分析,所有数据均是16 位数据,因此可以将COR 文件转化为16 位数据为单元的数据列表。由于读取的值为8 位/字节,因此可以做如下转换:
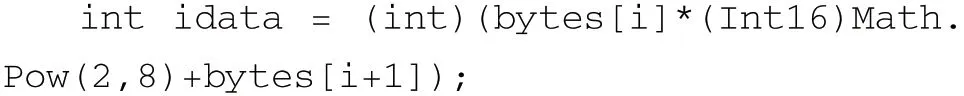
bytes 为读入字节流,idata 为转化后16 位数据。
在对COR 文件进行转化后发现COR 的前128 字节为描述信息,其中包括了COR 的程序名、程序位置、程序长度等信息。因此实际代码数据从128 字节开始进行转化,INIT 程序转化后用八进制显示如图3。

图3 COR文件八进制格式图Fig.3 COR Type file recording in octal
将COR 文件转化为16 位数据为单元的数据列表后可以对程序内容进行反汇编。
3 单条指令反编译
3.1 指令类型和寻址方式分析
所有的指令可分为单字指令和双字指令,单字指令指的是有16 位二进制数据组成的指令,双字指令是有两个16 位二进制数据组合而成的指令。
对于DCC 指令集共有10 类指令[2],分别为,存取指令(Load/store)、算术指令(Arithmetic)、逻辑指令(Logic)、位移指令(Shift/Rotation)、寄存器指令(Register Transfort / Modification)、跳转指令(Jump)、调用指令(Jump-and-mark)、执行指令(Execution)、控制指令(Control)、IO 指令(Input/Output)。
一般一条单字指令都由操作码(OP CODE)、寻址方式(M)和操作数(A)构成。操作码指示这条指令的作用和功能,寻址方式表示指令要操作的数据存放形式,与操作数配合可以在内存空间或者寄存器中找到需要操作的数据。
3.2 指令统计分类
对于编译器而言,明确了操作码、操作数和寻址方式后就可以根据以上规则转化为二进制码。但是据上文所述对于不同指令而言其操作数、操纵码、寻址方式在16 位或者32 位指令空间中的位置不同,反编译器无法根据二进制码直接应用规则来将二进制码反编译。
便于反编译器的执行,通过对Varian-70 所有指令共176 种进行统计后,根据指令BIT12-15、BIT9-11和BIT6-8 的值将指令分为38 小类:

表1 指令集分类表Table 1 Instruction types summary
3.3 具体实现
根据以上分类,可以通过指令前7 位的数值定位到指令类型和指令功能,然后根据后9 位(单字)或者后9+16 位(双字)提供的信息完成具体操作,举例如下:
不带数据单字举例:005002,其前四位为0,中三位为5,根据分类属于单字寄存器指令,进一步得知后9 位中前3 位为0 表示寄存器间数据转换,中3 位为0 表示数据清零,后3 位为2 表示B 寄存器,因此005002 反汇编为“TZB”。
带数据单字举例:020612,其前四位为2,中三位为0,根据分类属于直接单字取指令(B 寄存器),进一步得知后9 位表示直接寻址的地址,因此020612 反汇编为“LDB 612”。
双字举例:006010,030300,第一个字中前四位为0,中三位为6,根据分类属于双字存取指令,进一步得知后9 位表示数据取到A 寄存器,第二个字为取值地址,因此006010,030300 反汇编为“LDA 030300”。
通过以上方法可以完成单条指令的反汇编,并且根据类型分类可以获知下个字的类型。
4 整体反汇编
反汇编算法可以分为静态扫描算法和动态扫描算法。静态扫描算法是对目标程序从头到尾进行扫描,直接将所遇到的二进制码全部翻译为对应的汇编指令,缺点在于无法区分程序段中的数据区。动态扫描算法是模拟程序运行来区分指令和数据,但是缺点在于动态扫描时需要处理间接调用和多层调用问题,且编译的覆盖面低于静态扫描算法[3]。
对于静态扫描算法,最大的问题在于解决指令和数据的区分。对DCC 源码分析发现,DCC 的数据区一般处于程序开头或者结尾,且大规模出现,很少出现少量数据与指令混杂在一起的情况。因此采用静态扫描的反编译算法较为合适,同时本文根据DCC 源码特征采用动态标记和卷积标记两种策略来解决数据与指令无法区分的问题。
4.1 动态标记
小规模出现的数据区往往会被上下文通过单指令直接索引的方式调用,因此在第一次静态扫描时,当扫描到单指令直接索引的指令时将索引的地址进行标注为数据区,进行动态标记。当第二次扫描时不进行反编译,仅仅对标记为数据区的数据转为数据显示。例如:

当第一次扫描时,会将数据反编译为:

由于第一次扫描时会将023411 地址标记为数据,因此第二次扫描后为:

第一次静态扫描时对于无法反编译的数据(未在指令集)标记为数据,同时针对字符串编译一般经过反编译后会出现大量单字节操作指令,例如下文所示(取自AACKN程序示例):
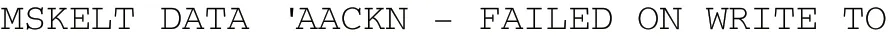

通过对大量连续出现如上指令的片段数据标记为数据区。
4.2 卷积过滤
由于大块数据区的数据可能正好可以被反汇编,因此当第一次静态扫描后会出现零零散散的指令分布在数据区内。卷积在离散数学中的意义是对当前数据和卷积核进行加权求和,这样可以将当前数据与周围数据信息融合,再经过一层滤波就可以将零散分布在大块数据区的指令去除,实现大块数据区的识别。
卷积公式如下:x 表示输入序列,h 表示卷积核,y 表示输出结果,N 为数据长度(f 长度+h 长度-1)。
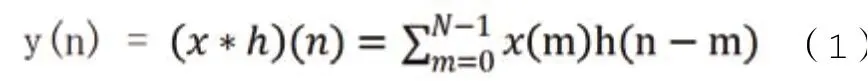
经过第一次静态反编译标记和动态标记后代码标记区可以用一个一维矩阵矩阵形式表示x[n],其中n 表示数据数量,若为数据类型则为1,若为指令则为0。
以SGL 程序的30077-30125 的数据段为例,数组x表示标记区数据,1 表示为数据,0 表示为指令:

以python 语言为例使用一个[1,1,1,1,1]的卷积核h 与x 做卷积运算:

得到结果y 如下:
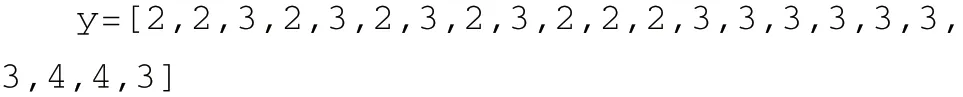
再经过>1 的滤波器后得到数组z:
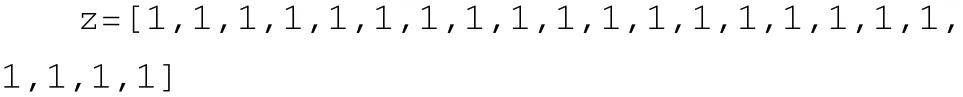
由此可以看到通过卷积滤波之后夹杂在数据区的指令均被过滤,这是由于卷积时卷积核会将当前数据周围信息也包含进来,通过滤波后指令类型就消失了,就能能到完整的数据区。

图4 反编译器程序逻辑图Fig.4 Disassembly compiler logic diagram
4.3 具体实现
反汇编器整体实现的流程如下:
1)从COR 文件中读取二进制数据,并且将二进制数据转化成八进制数据,放入数据数组中。
2)第一遍静态反编译,对单个数据依次进行反编译,同时对于单指令直接索引和无法反编译的数据进行动态标记,标记于对应的标记数组中。
3)第二遍循环,使用卷积核对标记数组进行卷积运算,得到新的标记数组。
4)第三遍循环,对于标记数组中大于某值的数据均转为数据类型显示。
5)最后,将所有显示数据输出到文本中,完成反编译过程。
5 问题的解决
通过以上的研究,完成了对于反编译器的代码编写,实际以DCC 备份SGL.COR 运行结果如下,左侧为原编译过程中产生的标记文件,右侧为COR 文件反编译的结果片段:
由于反编译后数据缺少交叉编译时的符号,因此指令后面仍保持数据显示。

图5 反编译对比Fig.5 Disassembly result comparing with source code
对于以上结果,当系统出现异常时,就可以通过反编译后文本回溯执行过程来定位缺陷的位置,同时对历史备份数据COR 文件进行反汇编后可以快捷地查看相应的参数数值。
对于测试程序和引导程序,可以直接在Virtual Console 机上加载程序完毕后,通过“C”命令对其内存数据进行显示和保存。通过这种方法可以直接得到八进制码,无需进行COR 数据的转化。最后通过反编译,可以得到可阅读的文本进行逻辑分析,为国产化研究和测试程序执行流程的研究解决了数据无法直接阅读的难题。
6 结束语
本文通过对DCC 指令集的数据格式的分析,根据16位数据中关键位信息将指令分为了39 小类。根据分类,可以通过指令前7 位的数值定位到指令类型和指令功能,然后根据后9 位(单字)或者后9+16 位(双字)提供的信息完成单条指令的反汇编操作。结合DCC 代码特点,采用静态编译的方式进行反编译,使用动态标记和卷积过滤的方法区分了数据区和指令,解决了静态编译中数据指令无法区分的缺点,完成了整体二进制数据的反编译工作。反编译后数据虽然缺少交叉编译时的符号,但是已经具备了可读性。通过本文的方法可以将未知的二进制码反汇编为具有可读性的汇编代码,有利于重水堆控制计算机的缺陷查找和系统学习。
猜你喜欢
中等数学(2021年8期)2021-11-22
云南画报(2021年8期)2021-11-13
北京航空航天大学学报(2021年6期)2021-07-20
成都体育学院学报(2021年1期)2021-07-16
中学生数理化·七年级数学人教版(2020年4期)2020-08-10
学校教育研究(2020年11期)2020-06-08
数学大王·低年级(2019年10期)2019-11-25
航空科学技术(2019年2期)2019-09-10
阅读(低年级)(2019年4期)2019-05-20
科技与创新(2019年2期)2019-02-14
