
油料储运工控系统业务安全数据集研究
2022-06-02 10:22李晓明任琳琳王汝墨刘家译李忠林刘学君万园春
信息安全研究 2022年6期
李晓明 任琳琳 王汝墨 刘家译 李忠林 刘学君 沙 芸 万园春
1(中国航空油料集团有限公司 北京 100088)2(民航智慧能源工程技术研究中心 北京 100088)3(北京石油化工学院信息工程学院 北京 102617)4(中国电子科技集团公司第三十研究所 成都 610041)
1 背景及现状研究
工业控制系统广泛应用于电力、石油石化、交通、水利、钢铁、先进制造等重要基础设施,独立、隔离的传统工控系统迎来了工业互联网时代,工控系统的安全是重中之重.而工控系统安全中,业务安全是网络安全和生产安全的统一抓手,业务安全性能越来越成为研究人员的关注焦点.同时,工控安全领域的震网病毒等案例表明[1],在工业互联网时代,针对工控系统业务安全的防护必须向智能化发展:例如,李晓明等人[2]通过强化学习的特征提取方法进行识别异常检测;使用机器学习、深度神经网络等预测模型可以有效对工控系统的未来状态进行预测.
针对预测模型的防护目标,可以分为网络层面和业务层面(工控工艺流程层面),不论哪个层面都需要相应的数据集辅助训练.当前以DoS攻击等手段构造的用于网络层面异常检测的数据集研究已经取得一些成果:Tavallaee等人[3]完善并发布了NSL-KDD数据集模拟真实网络,采用合理的训练集与测试集样本数量,足以负担起不同研究工作的任务要求;Los Alamos国家实验室发布的Multi-Source Cyber Security Events数据集[4]涵盖了58天的全面企业网络完全数据集.针对业务领域的数据集仅有新加坡科技大学网络安全研究中心水厂系统数据集[5](简称新加坡水厂数据集)和密西西比州立大学SCADA实验室天然气管道数据集[6](简称密西西比数据集)2个模拟入侵者对底层设备攻击的数据集.
训练一个智能且高效的预测模型需要的数据量十分庞大,且数据的质量直接影响模型的最终效果;目前来看,在工控系统的网络层面已经存在大量的数据集用于学习,足以训练出针对网络层面防护的优秀模型;但聚焦业务流程的工控数据集还处于稀缺状态.
在数据集的构建方法上,完整的数据集不但需要正样本也需要负样本(即攻击样本),正负样本应同源且负样本需要达到一定比例,以实现良好的模型训练效果.然而真实的工控系统无法大量生成数据集所需的负样本.
数据集的构建分为仿真系统采集正负样本和算法生成数据2种方式.
目前许多研究团队使用算法进行数据生成方法的研究:Zhou等人[7-8]提出了基于双判别模型及关联分组的工控系统负样本生成方法;电子信息系统复杂电磁环境效应国家重点实验室的黄琼男等人[9]对各类GAN网络进行数据生成有详尽论述;邹振婉等人[10]也针对GAN网络的生成进行了详细研究.使用算法进行数据生成的缺陷是训练模型时需要完整真实的数据集.
半实物仿真平台的应用也是工业控制领域的研究热点:密西西比大学的关键设施保护中心使用HMI、远程中断、PLC、传感器、执行器等设备构建的控制系统主要针对天然气传输管道进行仿真,并采集整理出一套具有丰富底层特征数据的天然气数据集;诺维萨德大学[11]的SlaCana等人设计了一套基于施耐德PLC的趋于供热变电站仿真模型,对关键组件三通阀用于不同温度水流混合进行研究;新加坡科技大学网络安全研究中心使用了包括2个高架水箱、6个消防水箱、2个原水水箱和1个回水水箱的水分配(WADI)试验台;山东大学李冰等人[12]基于RTDS以及OpenFAST打造了一套风能转换的仿真系统,提出了一种新的OpenFAST粘合代码以保证系统流程更新过程中的稳定性;浙江大学的郑飞飞等人[13]对污水处理流程进行了仿真系统构建,主要研究了历史观测点用水量与污水处理系统流入量之间的传递系数K值的确定,并通过该系数计算仿真系统内各个处理节点流入水量.
只有密西西比大学和新加坡科技大学网络安全研究中心2个研究团队使用仿真系统采集并发布了涵盖底层特征的工控系统公开数据集.密西西比数据集与新加坡水厂数据集虽然涵盖了对底层数据以及业务流程的攻击,但并未全面地从业务后果影响的角度构造大量导致业务流程失控的底层攻击.
本文的研究采用真实的攻击数据采集方式,针对业务场景设计了丰富的攻击类型,依据业务属性分类,对工控系统中最关键的修改值,从业务后果影响的角度进行攻击类型设计,着重对业务流程的数据进行采集,弱化了网络层面的攻击.
当前,急缺面向业务层面的工控系统数据集,对于一个完整的储运系统,涵盖了传输管线与储存油库,其特点是点位众多、控制复杂、流程丰富,任何一个业务流程的异常都会给整个系统带来严重的后果,所以为了保障业务流程正常运行,需要聚焦业务异常各种情况,使用反映实际系统的半实物仿真系统,构建有针对性的业务数据集.
2 数据集构建
本文基于实际油料储运工控系统业务过程搭建了一个半实物仿真沙盘配合SCADA系统的平台,使用此平台构建业务数据集.该仿真平台具有如下优势:还原了真实业务场景下油料储运的整个过程,且用户界面操作简单易用.此外,该平台使用PLC自动采集数据,保证数据的完整性以及准确性.该平台还具有可扩展性,可进行后续的改造以满足不同的业务场景,填补了国内油料储运业务实验设备的空白,为未来的研究工作打下基础,依托该平台可以持续进行油料储运业务相关实验研究.
2.1 半实物仿真平台
半实物仿真平台模拟实现油料储运业务过程.该平台由实体沙盘模块、数据采集与控制模块、人机接口模块3部分组成.
实体沙盘模块由储水罐、液位传感器、温度传感器、阀门、水泵等实体进行搭建,其实物如图1所示.数据采集与控制模块使用PLC实现对实体沙盘各部件进行控制.人机接口模块使用WINCC搭建一套仿真控制系统并实现图形界面.系统界面如图2所示.

图1 实体沙盘模块实物展示
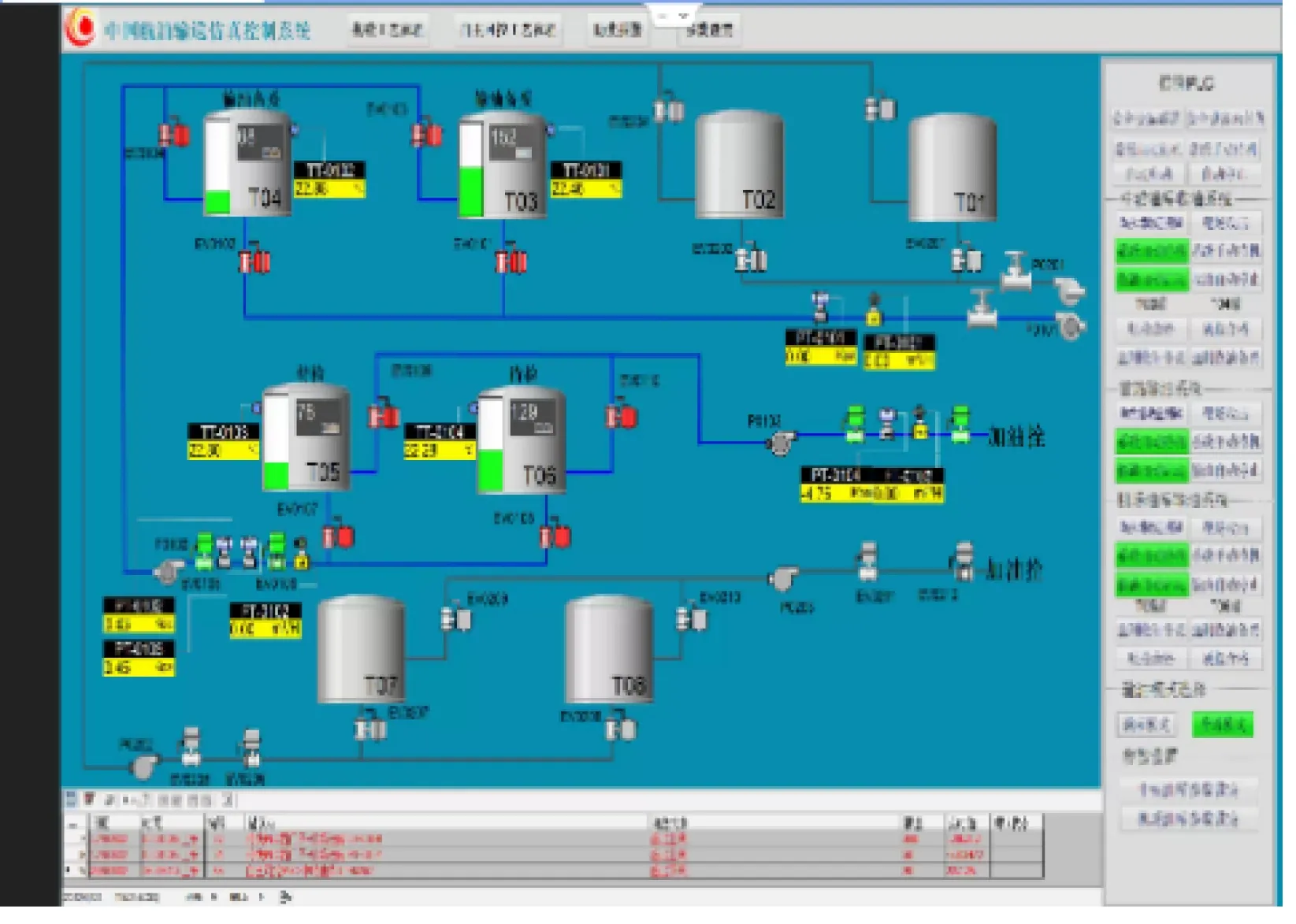
图2 人机接口模块仿真控制系统界面
2.2 数据采集过程
数据采集过程如下:按照业务流程手动操作仿真系统正常运行,获取正常数据.基于系统状态向系统发起攻击,采集负例样本.
每次攻击持续时间在1 min到2 h不等.在采集过程中遵循以下原则:每个采集时间段开始时让系统正常运行10~15 min;发生系统攻击后针对不同攻击造成的影响效果等待2 min至2 h后再进行系统的复原;采集过程中模拟工控现场产生重大事故的攻击类型,力图使该类攻击数据在数据集中占比更大;设定每0.5 s记录1次仿真平台的数据.在每轮次运行后,限定时间间隔从系统中提取系统数据与时间轴.
上述原则是对实际业务场景进行分析后制定的,其目的在于尽可能拟合实际业务场景的数据变化曲线,使数据更具有研究应用的价值.
2.3 攻击类型设计
对半实物仿真平台的攻击使用真实的黑客攻击,攻击方式如下:首先抓取仿真系统与PLC之间通信的网络数据包,其次解析网络包中的内容,最后根据解析出的控制字段以及数据段进行劫持攻击、篡改参数攻击以及篡改控制命令攻击.
根据油料储运实际业务流程中可能出现的工控事故情况,针对半实物仿真平台中传感器分类设计了13类攻击(其中共分为22种攻击方式),其目的是为了模拟真实环境下的严重工控事故,每一大类攻击都对应着业务流程中某一环节可能产生的重大事故,例如引起虚假报警会导致当前业务流程中断,篡改量程上下限等攻击会使油罐发生泄漏事故造成严重后果;本文所设计的攻击较好地反映了业务流程运行时可能面临的问题.攻击类型的具体说明如表1所示:

表1 13类(22种)攻击类型说明
3 数据集比较
对采集到的数据集进行脱敏处理、缺失值处理、分表拼接集成、数据标注等处理工作后,构建了一套包含370 685条标注样本、119列特征的油料储运工控系统业务安全数据集(简称油料储运数据集).在所有样本中,正样本占比60.15%,负样本占比39.85%.不同种类攻击数据条数以及所占的比重如表2所示;油料储运数据集与密西西比数据集、新加坡水厂数据集(2019-11)的规模对比如表3所示.
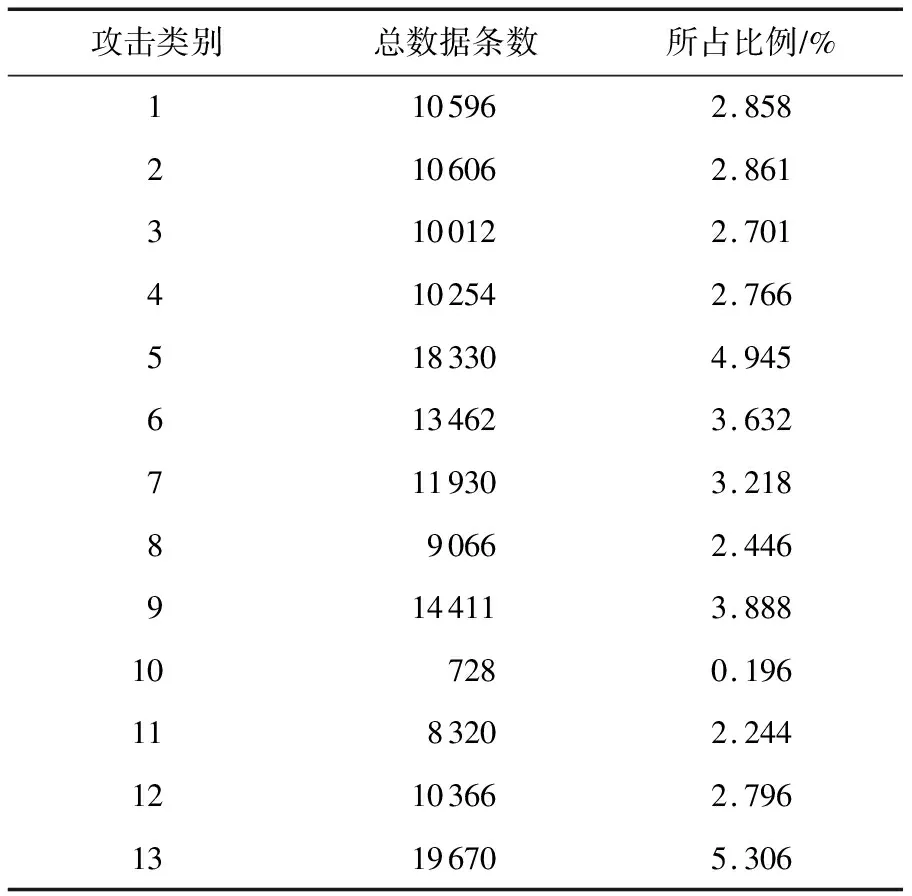
表2 负样本数据统计(13类攻击)
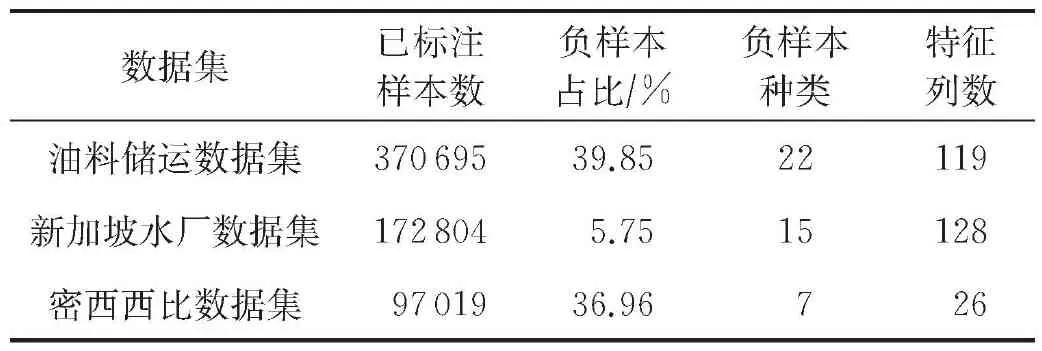
表3 数据集信息对比
从表3可以看出本文构建的油料储运数据集已标注样本数排在首位,共有370 695条已标注样本,同时负样本的占比也处于首位,达到39.85%,即包含147 721条已标注负样本.在攻击类型上,新加坡水厂数据集包含15种负样本,这15种生成负样本的攻击同本文相同,也是基于工控事故造成的后果来进行设计的.油料储运数据集的13大类攻击产生了22种负样本,相较于新加坡水厂数据集细化了攻击的种类,产生了更多不同的负样本且考虑了攻击的隐秘性,如在篡改关键参数的同时一并篡改报警值.密西西比数据集包含7种攻击负样本,大部分属于网络攻击产生的负样本.在特征列数上,新加坡水厂数据集居于首位,包含有128列特征,油料储运数据集位于第二,包含119列特征,密西西比数据集包含26列特征;油料储运数据集的特征列几乎全部由业务流程数据特征组成,对于业务异常和业务流程的反映最为明确.
4 数据集实验
相同业务的工控系统通常有多个现场,但现场之间的点位数量不同,甚至工控系统品牌也不同.即使是同一业务的工控系统不同现场也难以采用同一个异常检测算法.异常检测算法的迁移能力是应用的关键.迁移能力固然与算法有关,也与数据集相关.如果某数据集中能够学习到该工控系统的核心业务逻辑,会对提高异常检测算法的迁移能力有所帮助.
研究团队为了验证油料储运数据集的学习能力,使用了Tradaboost[14],TCA[15],JDA[16],CORAL[17],BDA[18]这5种算法,对油料储运数据集、密西西比数据集以及新加坡水厂数据集进行了双向迁移实验.
实验从油料储运数据集、密西西比数据集、新加坡数据集中选取了1 100条左右的样本进行实验.由于以上迁移学习算法皆需要源域数据集与目标域数据集的特征列数相同,因此选取了仿真系统中同一油罐的特征列形成单个油罐数据集19列,选取新加坡水厂数据集中1个水罐进行水分配的特征列形成单个水罐数据集19列,使用上述方法抽取数据,并以此进行油料储运数据集和新加坡水厂数据集之间的迁移算法实验.由于密西西比数据集特征数量较少,其业务相关特征列无法和油料储运数据集的单个油罐19列特征相匹配,因此采用随机选取的方式从密西西比数据集中构造单个业务数据集,进行油料储运数据集和密西西比数据集的迁移算法实验.
油料储运数据集和新加坡水厂数据集的迁移实验、油料储运数据集和密西西比数据集迁移实验的预测正确率结果如表4所示:
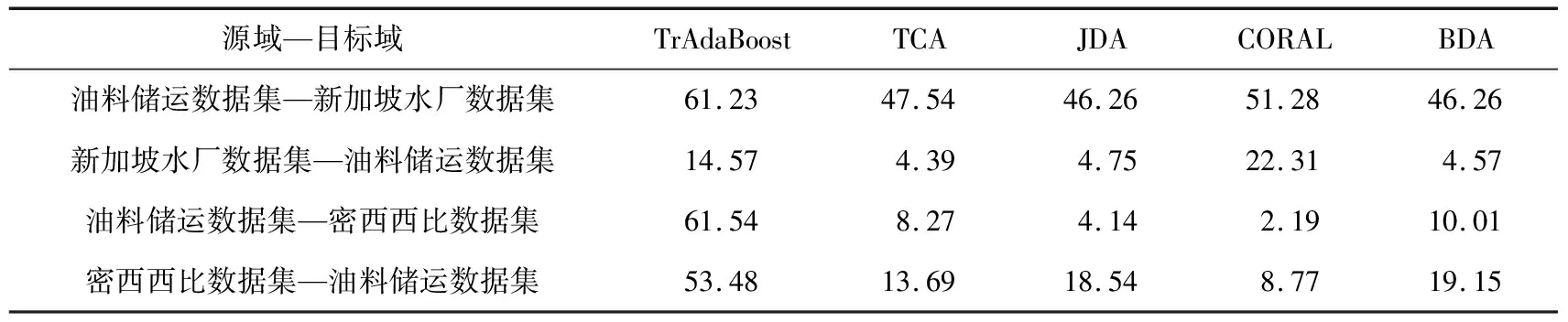
表4 油料储运数据集与2个公开数据集的迁移实验的正确率 %
由表4可以看出,从油料储运数据集迁移到新加坡水厂数据集的正确率要高于新加坡水厂数据集迁移到油料储运数据集的正确率.原因在于油料储运数据集的攻击类型更全面,迁移到新加坡水厂数据集时,涵盖了新加坡水厂的攻击种类.而反过来新加坡水厂的攻击种类少,反迁移时未能学习到数据集中不包含的攻击模式,因此普遍正确率偏低.
不论是从油料储运数据集到密西西比数据集的迁移结果还是从密西西比数据集的迁移结果来看,除了TrAdaBoost以外,正确率都比较低,这是因为这2个数据集的工控流程完全不同,难以完成直接的迁移.
考虑到密西西比数据集工控流程以及攻击分类的较大差异,所以将油料储运数据集与密西西比数据集调整为仅区分正负样本的二分类模式进行迁移,同时选择27列特征与20列特征分为2组进行预测,20列特征的筛选仍然依据前文中的选择方式,额外的7列特征选择了与密西西比主要工艺流程较为接近的公共管道特征数据,实验结果数据如表5所示.
从表5可知,将分类模式变为二分类后迁移正确率得到了极大提升,多分类问题变成二分类问题时复杂性降低,可以得到更高的正确率;同时在使用20列特征进行迁移预测时正确率普遍低于向新加坡水厂数据集迁移的预测正确率.从工艺流程的角度看,油料储运数据集与密西西比数据集的原始工艺流程差异性更大,在相同的分类与特征前提下,低于新加坡水厂数据的迁移正确率具有一定的合理性;同时,选27列特征的密西西比数据集与油料储运数据集的迁移学习与选20列特征相比,预测结果正确率更高,多出的7列特征包含管道信息,油料储运特征中也包含管道相关数据,由此分析,增加部分相似的系统环节特征可能有助于提高迁移学习的正确率.
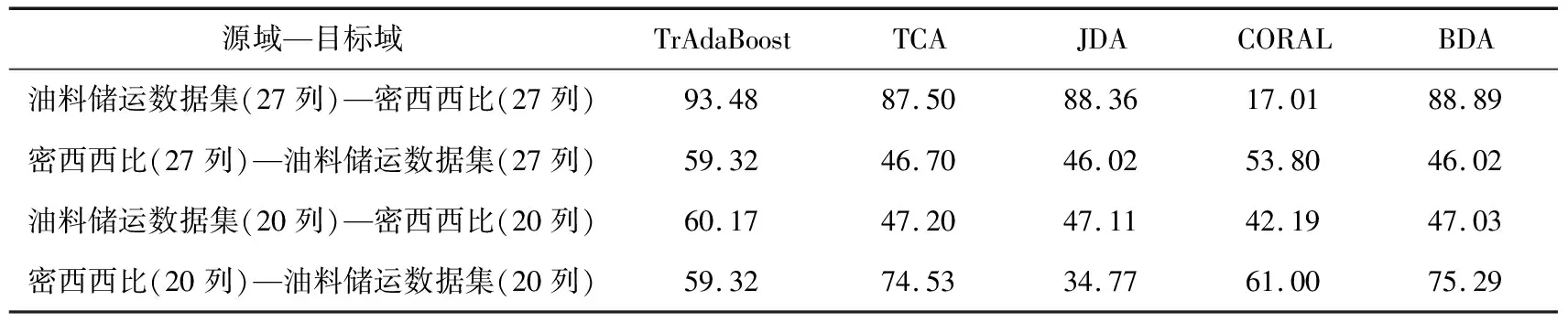
表5 油料储运数据集与密西西比数据集二分类迁移实验的正确率 %
上述2表中,TrAdaBoost正确率相对较高;算法原理是更注重错分样本的训练,因此迁移结果较好,这是算法训练时的技巧,实际应用中会存在过拟合的问题;从油料储运数据集与密西西比数据集的迁移结果来看,降低问题复杂度可以提高预测结果准确率;针对差异性强的系统可以选择类似的特征列以提高预测结果的正确率.实验证明油料储运数据集对于其他相似或存在相似流程部分的数据集展现出更强的迁移能力,具有更鲜明的工艺特征.
5 总结与展望
为了提高油料储运工控系统的底层异常检测算法能力,本文研究了基于实际油料储运工控系统业务的半实物仿真系统.针对该仿真系统进行了多种底层攻击,采集了攻击情况下的异常数据,与正样本一起构建了一个用于研究油料储运工控系统底层安全防护算法的数据集.通过仿真平台采集传感器数据,以实际的业务攻击为手段,探索出了一套构建业务安全数据集的方法;建设了一个可持续研究应用的仿真平台;形成了一套优于国际、填补国内空白的数据集.
该数据集与国际上2个代表性的公开数据集进行了比较,在数据规模、负例样本种类、数据集的平衡性和数据集对迁移算法的支持能力方面都占有一定的优势;此外,数据特征对于业务流程的覆盖更加全面,攻击类型更有针对性.
本研究团队将持续改进仿真系统,进行数据采集和数据扩充,力求反映实际现场业务情况.不断提高系统的传感器精度,扩大点位数据规模,增加攻击方式及负例样本种类.同时,利用模型从仿真平台采集到的大量数据进行样本扩充,研究样本的特征,丰富样本数据,进一步开展迁移学习研究.
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
科学与信息化(2022年12期)2022-07-20
网络安全与数据管理(2022年3期)2022-05-23
网络安全与数据管理(2022年2期)2022-05-23
科技信息·学术版(2021年3期)2021-12-24
科学与财富(2021年35期)2021-05-10
军事运筹与系统工程(2020年2期)2020-11-16
军事运筹与系统工程(2020年1期)2020-09-11
中国化工贸易·上旬刊(2019年8期)2019-09-10
农家顾问(2016年12期)2017-01-06
