
面向供应链数据安全共享的区块链共识算法设计
2022-06-02 10:22:44孔宪光刘洪杰张迎冰刘树全
信息安全研究 2022年6期
殷 磊 孔宪光 刘洪杰 张迎冰 刘树全
1(西安电子科技大学机电工程学院 西安 710071)2(睿蜂群(北京)科技有限公司 北京 100083)
传统供应链难以实现工业品生产制造企业内部信息系统之间、企业之间、企业和用户之间的信息汇聚及有效利用[1],致使工业品生产全过程数据追溯难,不能有效解决生产制造环节中的窜货、质量问题责任不明、全链条数据可追溯等问题[2].区块链技术具有不可篡改、强信任、在去中心化的条件下建立多方互信关系的特点[3],因此将区块链技术应用到供应链的数据共享中,通过将产品数据保存在区块链的分布式账本中,使得供应链各个参与方通过智能合约,达成多方共识,形成多方交叉验证机制,并形成具有公信力的防伪溯源机制,确保全过程数据可追溯.
因此,本文对供应链数据的安全共享问题进行探讨,构建了一种基于区块链的供应链数据安全共享模型,对传统的PBFT共识算法作了改进,提出一种新的共识算法CEBFT(credit election Byzantine fault tolerance),优化了PBFT算法的一致性协议,并引入节点信用机制,提高共识算法的稳定性.另外,在算法中加入管理节点协调共识网络的节点信息,控制节点加入和退出共识网络,解决了PBFT算法无法动态删除、添加节点的问题.最后通过实验对CEBFT算法在通信复杂度、吞吐量以及时延等方面进行了验证.
1 基于区块链的供应链数据安全共享模型
传统的数据共享平台基本都是基于第三方服务器进行数据的存储和交换,用户上传数据后无法看到平台内部的操作,只能被动地信赖第三方服务商,数据在共享过程中的完整性和机密性难以得到保障.因此本文参考文献[4]在传统数据共享模型的基础上,基于区块链设计了一种分布式的供应链数据安全共享模型,如图1所示:
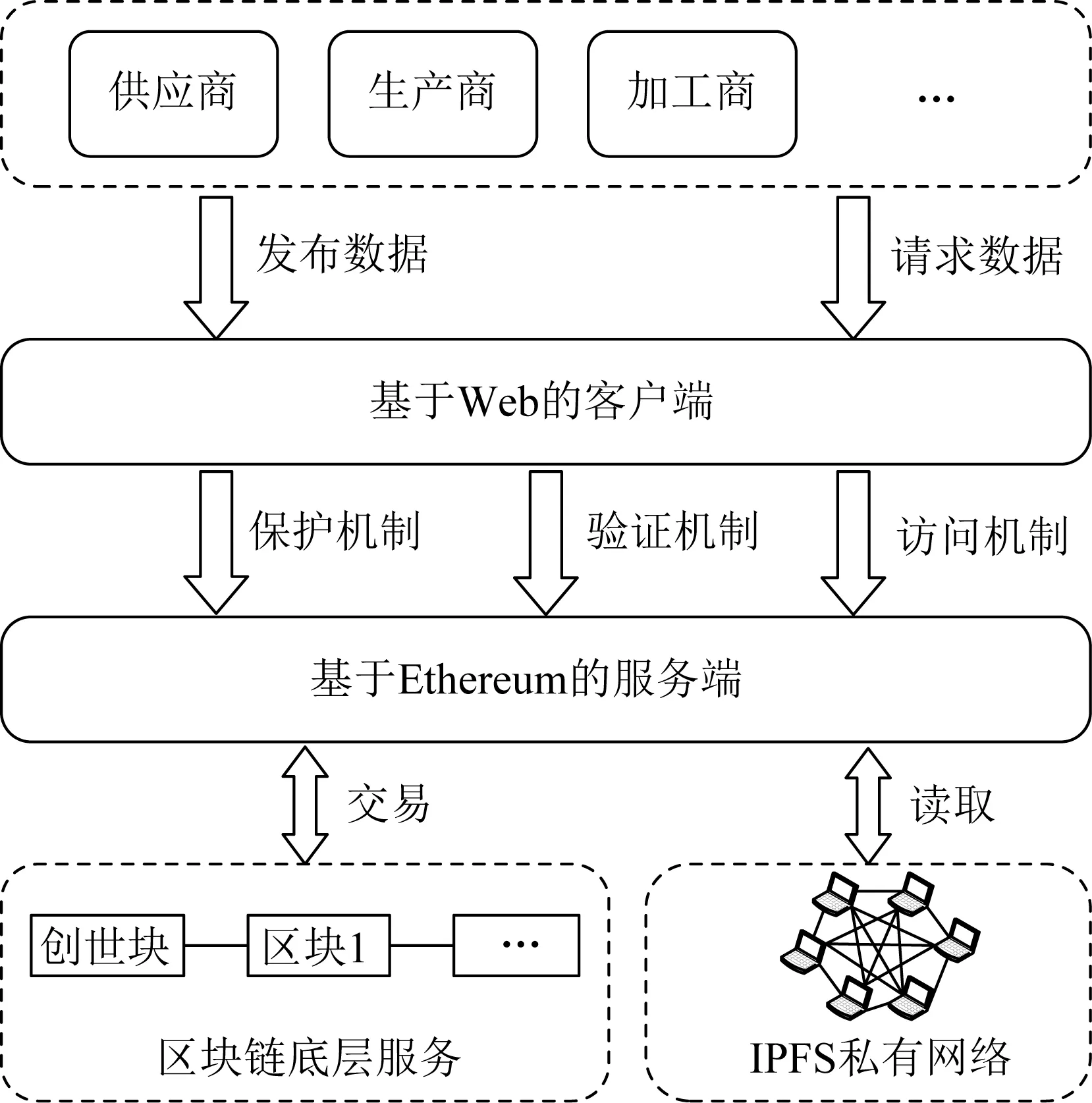
图1 基于区块链的供应链数据安全共享模型
该模型主要由供应链数据所有者、供应链数据消费者、客户端、区块链和IPFS分布式网络组成.数据所有者主要通过客户端对数据进行发布和加密.数据消费者通过客户端根据访问控制机制对需要的数据进行访问.客户端以可视化的方式为数据所有者和消费者提供面向不同终端的数据共享服务.区块链网络是基于以太坊搭建的联盟链网络,用于存储IPFS系统的文件信息访问地址和访问控制策略.IPFS分布式网络主要用来存储数据所有者的加密数据,可以很好地解决区块系统的存储瓶颈问题.
在本模型架构中,主要使用基于IPFS分布式系统的链下存储技术.将供应链质量数据存储在IPFS系统中,IPFS根据内容返回一个哈希值,不仅可以使用这个哈希值来索引原始数据,还可以通过哈希值判定原始数据是否被篡改.链上存储部分主要存储IPFS分布式系统根据质量数据返回的哈希值和数据所有者设置的访问控制策略.实现供应链数据共享分为以下3个阶段:
1)数据发布.数据所有者将供应链中的产品数据通过客户端的数据发布功能完成数据的加密和上传.供应链数据的元数据提取后放到区块链上,将数据加密后存储到IPFS分布式网络中,减轻区块链的存储负担.
2)数据请求.数据消费者可以通过客户端在系统中查找所需要的数据,并根据访问控制方式向数据所有者发起访问请求.
3)数据共享.如果数据消费者的自身属性满足数据所有者设置的访问要求,则消费者可以通过访问控制方式拿到所需要的数据.
2 供应链联盟链的PBFT共识算法
2.1 实用拜占庭容错算法
实用拜占庭容错算法[5]可以用于解决拜占庭将军问题.实用拜占庭容错算法中的一致性协议主要分为3个阶段[6]:Pre-Prepare(预准备阶段)、Prepare(准备阶段)、Commit(确认阶段).具体共识流程如图2所示:
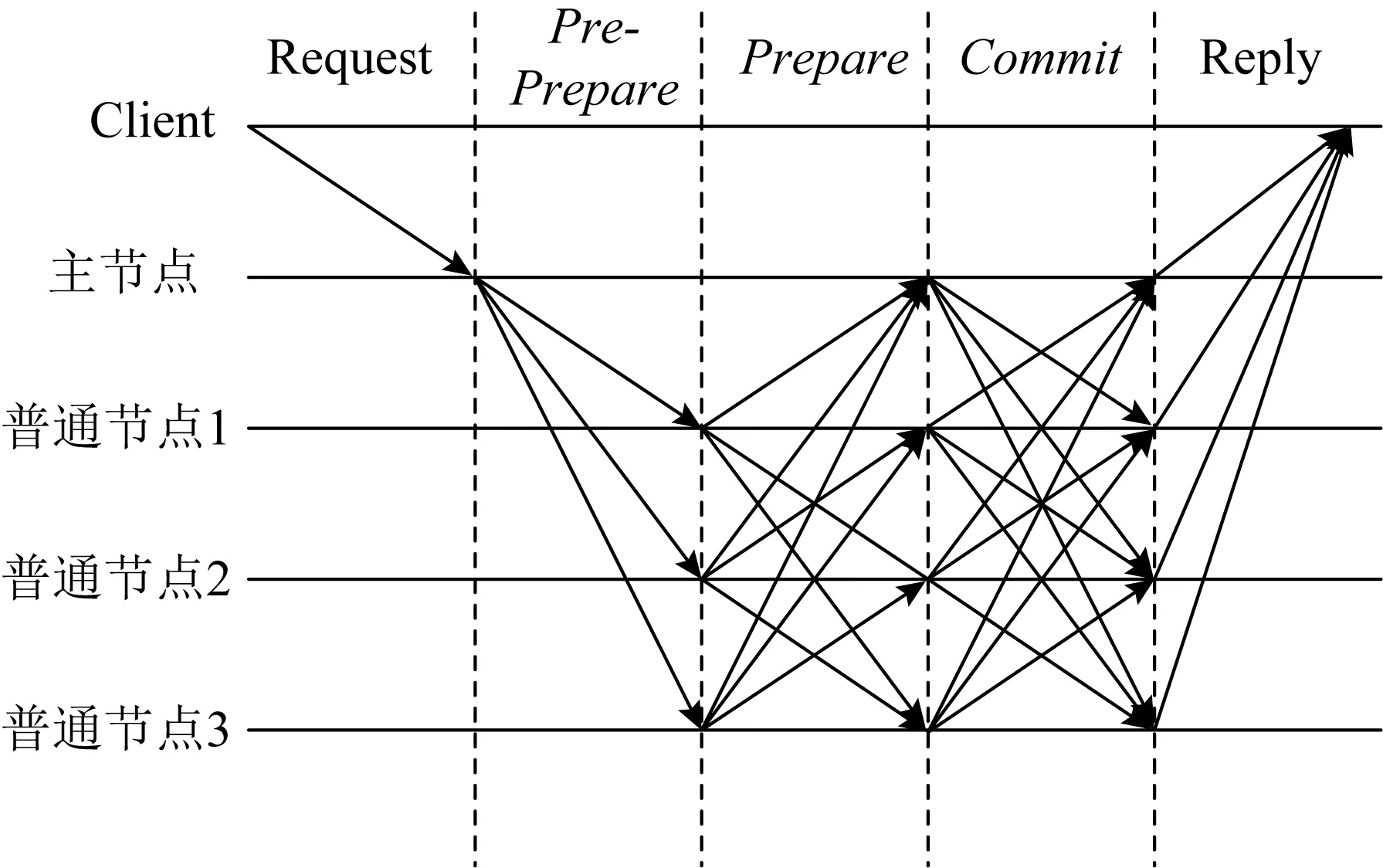
图2 PBFT算法流程图
1)预准备阶段.主节点收到客户端的交易请求后,为该请求分配编号,将请求封装成预准备消息并发送给所有从节点,发送的消息为〈〈〈Pre-Prepare,n,v,d〉signature,m〉〉,其中n为序列号,v是视图的编号,m为请求消息,d为m经过哈希运算后的摘要.
2)准备阶段.从节点收到预准备消息后,对消息进行验证并将消息添加到本地,然后构造Prepare消息并向其他从节点广播,消息格式为:〈Prepare,v,n,d,i〉.同时该节点会不断接收其他从节点的Prepare消息,并对其进行验证.
3)确认阶段.当从节点累计确认通过f+1个Prepare消息后,节点进入确认阶段,该节点会构造Commit消息并向网络中的其他节点发布.Commit消息格式为〈Commit,v,n,d,i〉,当从节点验证通过f个Commit消息后,确定大部分节点都已经进入确认阶段,完成了本次的共识过程.
2.2 CEBFT算法设计
针对联盟链中PBFT算法通信时间复杂度过高、共识效率低下、不支持动态管理节点等问题,文献[7]结合股份DPOS委托权益证明算法和PBFT算法,利用数字货币选出部分节点进行共识,有效降低了共识过程中的节点通信量;文献[8]提出了协调节点的概念,利用协调节点管理整个共识网络中的各个节点信息以及协调各个节点加入和退出共识网络等操作,但是该算法的时间复杂度仍为O(n2),通信复杂度过高;文献[9-10]设计了一种简化的PBFT算法,将算法的时间复杂度降为O(n),但该算法要求共识网络中不能存在拜占庭节点,算法的实用性不高;本文结合供应链数据共享场景和文献[8,11]提出了一种适用于供应链联盟链的CEBFT共识算法.
2.2.1 整体思想
在PBFT算法中,为了防止拜占庭节点对共识结果产生影响,共识过程中节点之间需要相互发送消息确认节点状态,在确认过程中会产生大量通信,严重影响算法的共识效率.而在供应链的数据共享场景中,联盟链中的所有节点都会经过认证审核,节点的可靠性更高.因此,本文对传统PBFT算法的共识流程进行改进,在所有共识节点都正常的情况下,优化了一致性协议,降低节点间的通信量.同时为了保障参与共识节点的可靠性,引入信用机制,将联盟网络中的节点划分为普通节点和候选节点,选择高可靠性的节点参与共识.普通节点没有生成和验证区块的权限,只负责结果存储,候选节点信誉值较高,可以竞选主节点参与共识流程.最后为了方便共识节点的加入和退出,在PBFT算法的基础上加入管理节点,管理节点并不参与节点共识,只负责管理联盟网络中节点的状态信息,控制节点加入和退出共识网络.与PBFT算法相比,CEBFT算法更加适用于供应链数据共享场景,如表1所示:

表1 CEBFT共识算法与PBFT共识算法对比
2.2.2 节点信誉值
为了保障系统安全性,提高参与共识节点的可靠性,在本文算法中引入节点信用机制,给每个节点设置信誉值用于评估节点的可靠性.如果联盟链中的节点在共识过程中无法正常出块,则会通过惩罚机制降低该节点的信誉值,使得该节点在下次选举时成为候选节点的概率下降.那些企图在共识过程中生产非法区块的节点很难累积信誉值,从而失去参与共识的机会,而可靠的生产节点能够更快地累积信誉值,在选举中更容易成为候选节点参与共识,使系统变得更加稳定可靠.
在每个共识过程结束后,根据节点的行为表现对节点信誉值重新进行评估计算,节点信誉值主要由以下因素决定:
1)节点当选为主节点,并正常完成了出块过程,则该节点的信誉值加0.5.如果该节点没有在系统规定时间内发起共识操作或者在确认提交阶段没有及时回馈,导致出块失败,则节点信誉值减0.5.
2)如果节点作为候选节点参与了本轮共识过程,在共识过程中能够正确签名验证消息,则节点信誉值加0.25,反之未能在规定时间内正确签名验证消息,节点信誉值减0.25.
3)如果节点在本轮共识过程中成功参与投票选举候选节点,则节点信誉值加0.25,反之节点信誉值减0.25.
2.2.3 主节点选取
为了提高算法的稳定性,在每轮共识过程中都会根据节点信誉值由高到低选取一半的节点作为候选节点参与本轮共识,然后在候选节点中选择主节点完成本轮共识.随着系统的运行,联盟网络中的节点会不断地累积信誉值,并且成功出块的主节点更容易累积信誉值,为了避免主节点被某高信誉值节点垄断,本文结合follow-the-sa-toshi算法[12],根据每个节点信誉度大小从候选节点中依概率随机确定主节点,如图3所示,使所有的候选节点都有概率当选主节点来累积信誉值,从而使系统在一定程度上实现去中心化.

图3 FTS树模型
候选节点选举完成后,将候选节点的信誉值作为权重构建Merkle树,叶子节点的权重为某个候选节点的信誉值,非叶子节点的权重为其左右子树的权重之和,然后节点根据一个数字随机选择Merkle树的左右子树,直到选出最终的叶子节点.
主节点选取流程:
1)候选节点选出后,统计全部候选节点的信誉值总值n,将候选节点的信誉值作为权重构建Merkle树;
2)通过1个随机数生成器生成1个(1,n)的随机数rand;
3)将随机数rand与Merkle树子树的权重进行比较,选择合适子树不断向下遍历,直到到达Merkle树任意1个叶子节点,则该叶子节点的权重所代表的候选节点作为本轮的主节点产出区块.
2.2.4 优化共识流程
PBFT共识算法的一致性协议在运行过程中需要完成2次复杂度为O(n2)的节点通信,这样设计是为了在网络中存在拜占庭节点的情况下,算法仍能够完成共识.CEBFT算法在不存在拜占庭节点的情况下,对一致性协议进行优化,使其在完成复杂度为O(n)的节点通信后,算法就能够完成共识.优化后的共识流程如图4所示.共识过程如下:

图4 优化共识流程
1)请求阶段.客户端节点发起交易请求,并将交易信息m发送给主节点,主节点对交易信息进行验证,验证通过则消息打包到区块中,否则直接删除消息.
2)预准备阶段.主节点收到客户端的交易请求后,为该请求分配编号,将请求封装成预准备消息,并发送给所有的候选节点,发送的预准备消息为〈〈〈Pre-Prepare,n,v,d〉signature,m〉〉,其中n为序列号,v为视图的编号,m为请求消息,d为m经过哈希运算后的摘要.
3)反馈阶段.其他候选节点收到主节点的预准备消息后,首先通过主节点的公钥去验证预准备消息的签名是否有效,然后判断消息的视图编号是否一致,最后对比本地的交易信息和预准备消息中的交易信息是否相同,全部验证通过后,候选节点将该共识请求写入日志,然后生成反馈消息发送给主节点.消息格式为〈Feedback,n,v,d〉signature,其中n为序列号,v为视图的编号,m为请求消息,d为m经过哈希运算后的摘要,signature为候选节点对反馈消息的签名.
4)确认阶段.当主节点验证通过所有反馈消息后,主节点构造确认消息发送给其他节点,节点收到主节点的Commit消息并对消息验证通过后,将交易信息存入本地.Commit消息格式为〈Commit,n,v,d,a〉signature.
2.3 动态节点管理
2.3.1 模型设计
为了方便共识节点的加入和退出,在PBFT算法的基础上加入管理节点.管理节点并不参与节点共识,只负责管理联盟网络中节点的状态信息.同时联盟链中每个节点中都维持1个信息表,表中包含当前联盟链中所有节点的信息,包括节点IP地址、ID信息、公钥、节点状态、信誉值等信息.节点的状态分为Active和Exited 2种状态,节点状态为Active表示节点仍在共识网络中参与共识;节点状态如果为Exited,则表示当前节点已经退出共识网络,不再参与共识.
2.3.2 节点加入流程
1)新的节点经过联盟链审批后,需要在联盟链CA服务器进行身份认证和注册,节点注册成功后,为新节点分配ID、公私钥等信息.
2)管理节点监测到有新节点加入后,首先给新节点同步节点信息表,然后向联盟网络中的所有节点发布消息更新节点信息表,如表2所示:
3)管理节点将新节点的信息封装成Join-Request消息,并向联盟网络中的所有节点进行广播,Join-Request消息格式为〈Join-Request,id,pk,timestamp〉signature,id为新节点在节点信息表中的ID,ip为新节点的IP地址,用于之后的网络通信,timestamp为新节点的加入时间,signature为管理节点对Join-Request消息的签名.
4)联盟网络中的其他节点收到管理节点的Join-Request消息,验证通过后,该节点将自己的节点编号j封装成1条Join-Reply消息反馈给管理节点,表示认可新节点的加入,Join-Reply消息的格式为〈〈Join-reply,i,id〉signature,j〉,是该节点对Join-Reply消息的签名.
5)管理节点收到2f+1个节点的Join-Reply消息后,通过signature对这些节点的签名进行验证,验证通过后利用聚合签名算法将这些节点的签名聚合成1个新的签名,然后向联盟网络中的所有节点发送Join-Commit消息,通知各节点更新本地节点信息表.Join-Commit消息的格式为〈Join-Commit,I,id,aggrsignature,node〉signature,aggresignature为将所有验证通过的节点签名聚合后生产的聚合签名,node为所有验证通过的节点ID列表,其他节点可以通过node集合验证aggresignature聚合签名的有效性.
6)联盟网络中的所有节点收到管理节点的Join-Commit消息后,通过node集合验证聚合签名有效后,更新本地节点信息表,此时新节点完成加入网络的共识过程.节点加入过程如图5所示:
3 实验与性能分析
3.1 通信开销对比
联盟链网络节点在共识过程中产生大量通信,严重消耗网络中的带宽资源,通信开销是衡量共识算法性能的重要指标.图6所示为CEBFT算法和PBFT算法完成1次共识所产生的通信量:

图6 2种算法交易通信量对比
PBFT算法的通信复杂度为O(n2),随着节点数量的增多,节点间的通信次数呈指数增加,导致通信量快速增长.而CEBFT算法因为采用优化后的共识流程,通信复杂度可以降为O(n),通信量呈线性增长趋势,增长缓慢.从图6可以看出,CEBFT算法可以有效降低共享过程中的通信开销,提高共识效率.
3.2 性能分析
1)时延测试.
交易时延是衡量一种共识算法性能好坏的重要指标[13],通常是指客户端发送交易请求到确认共识完成的时间间隔,交易时延越短区块在共识过程中确认的速度越快,可以有效防止区块分叉,提高系统的安全性.
本文实验中时延数据取100次共识的平均值,测试了不同节点数量下2种算法的交易时延.
从图7可以看出CEBFT算法的性能明显优于PBFT算法,随着节点数目的增多,CEBFT算法的交易时延增长缓慢,稳定性更高,优势较为明显.

图7 2种算法交易时延对比
2)吞吐量测试.
吞吐量一般是指系统在单位时间内能够完成的交易数量,是衡量共识算法性能的另一重要指标[14].本文在实验中设置客户端共发送1 000条数据,测试了CEBFT算法和PBFT算法在不同节点个数的情况下每秒完成的交易量.
从图8可以看出CEBFT算法和PBFT算法的吞吐量都随着网络中节点的数量增加而下降,但在相同节点条件下,CEBFT算法明显具有更高的吞吐量.

图8 2种算法吞吐量对比
本文实验对CEBFT算法和PBFT算法在不同节点数量下的时延和吞吐量进行了对比分析,通过时延以及吞吐量的测试可以看出,CEBFT算法在性能上较PBFT有较大的提升.
3.3 案 例
采用本文提出的数据安全共享模型和CEBFT共识算法开发了睿链库,由中心应用、区块链和分布式加密存储(IPFS)3大部分组成,总体架构如图9所示:
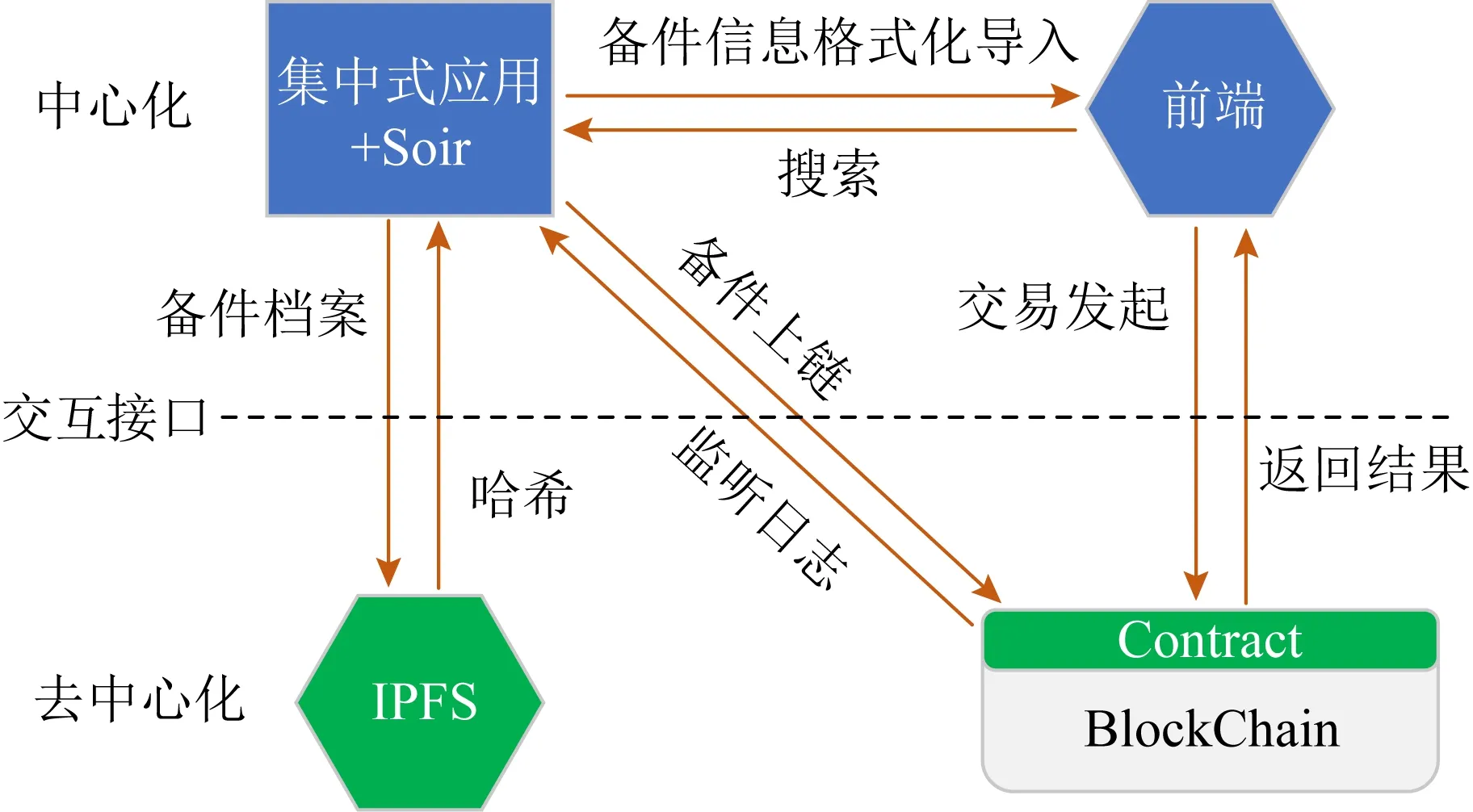
图9 睿链库平台架构
睿链库于2019年3月上线,至今已经接入风电、火电、水电等5个集团公司、11个省市的20多家电厂,接入装机量850万kW,协同备件金额9 933万元,协同交易量377万元,时延、吞吐量等性能指标完全满足应用要求,形成了发电企业多业务生态.
4 总结与展望
本文对供应链数据共享过程中的数据安全问题进行了研究和分析,提出了一种基于区块链的供应链数据安全共享模型,针对联盟链中PBFT算法共识效率低、不支持动态管理节点、无法直接应用到供应链数据共享场景中等问题,引入了简化的一致性协议和信用机制,根据信誉值投票选举高可靠性的节点参与共识,降低了节点间的通信复杂度.另外,通过管理节点实现动态增加新节点以及动态退出共识网络.最后通过实验对CEBFT算法进行了分析,证实CEBFT算法在通信复杂度、吞吐量以及时延等方面都有较大的提升.
猜你喜欢
公民与法治(2022年12期)2023-01-07 09:16:26
计算机应用文摘·触控(2022年8期)2022-05-25 13:27:53
小学生学习指导(当代教科研)(2021年6期)2021-05-23 13:24:38
马克思主义哲学研究(2020年1期)2020-11-26 07:25:48
华人时刊(2019年13期)2019-11-26 00:54:42
人大建设(2019年12期)2019-11-18 12:11:06
电子制作(2019年23期)2019-02-23 13:21:12
测控技术(2018年6期)2018-11-25 09:50:10
系统工程与电子技术(2016年7期)2016-08-21 13:59:18
电测与仪表(2016年17期)2016-04-11 12:38:28
