
正式性的测量方法和描写路径*
2022-05-31 03:22:12黄劲怡彭宣维
外语研究 2022年2期
黄劲怡 彭宣维
(1.云南师范大学外国语学院,云南 昆明 650500;2.深圳大学外国语学院,广东 深圳 518060)
0.引言
语言的“正式性”(formality)指社交情景的正式程度在语言使用中的体现。(Irvine 1979:773-776;Matthews 1997:133)正式语境(如学术论文、新闻报道等)中的高频词属于谨慎体(careful style);非正式语境(如日常会话等)下的高频词则划归到随意体(casual style);(Richards&Schmidt 2002:209,503,522)两者之间是一条从(超)正式到(超)非正式的连续统(Joos 1961;Labov 2006;侯维瑞1988)。然而,正式性层次(level of formality)与语言形式(如词汇选择)的对应关系具有模糊性(Irvine 1979:786;彭宣维2021:24-25),如何用理性、实证的方法把词项(lexical item)归入各正式性层次(Rickford&McNair-Knox 1995:265),进而指导语篇正式性的功能描写成为一个难题(Heylighen&Dewaele 1999;Li et al.2016)。
第一,如何用客观数据和主观直觉相平衡的方法(Halliday 2004:23-24;Sinclair 2004),把词项归入各正式性层次,进而评测语篇正式度?从研究现状看,直觉和数据两种取向各自为政。前者多从研究者的语感出发来确定词项的正式性(如Joos 1961;程雨民2004等),结果使语篇标注缺乏可验证性;后者主要采用F-Score(Heylighen&Dewaele 1999)和ADFScore(Fang&Cao 2009)等测量公式,但它们仅以词类的数据多寡为标准来判断语篇的正式性,这在多大程度上符合母语者的使用习惯有待明确(Li et al.2016)。
第二,如何把用词正式程度和语篇功能描写结合起来?先前客观数据和主观直觉之间的失衡可能导致语篇描写走向两种极端:过于强调研究者的主观直觉,会导致分析模型的确立缺乏数据支持和可验证性,(Tognini-Bonelli 2001:63-68;McEnery&Hardie 2012:147-162)以此标注并导出的结果有沦为“直觉式数据(intuitive data)”(Sinclair 2004:39-41)的可能;反之,单纯倚重现成的语料库数据,又容易弱化功能语篇描写中“理论驱动式(theory-driven)”理念(Matthiessen&Nesbitt 1996)的优势,难以充分发挥理论范畴对语篇的解释力。
为此,本文从“词汇选择体现语篇特征”的角度(Halliday&Hasan 1976:274-292,318-329;Leckie-Tarry 1995:107-131),尝试构拟一套语料库数据驱动的词项正式度测量方法,说明设计步骤,对正式、中性和非正式性三个典型范畴予以数据支持。这样的方法能让大规模数据更多地替代人的语感来为理论范畴提供证据。(施春宏2017:55)此外,基于小型语料的定性描写又是理论走向实践的必经之路(Martin 2004:341-342),所以我们进一步在两个语篇案例中演示标注和描写程序,并在系统功能语言学(SFL)“权势↘语体”(POWER↘STYLE)模型的指导下考察语篇中的词项正式性如何体现交际者之间的权势关系。
1.测量方法
一套实证性的词项正式度测量方法必须具备详尽的设计步骤及解说。(Heylighen&Dewaele 1999)回顾学界对词项正式性的测量研究,其判断依据已从早期的主观识别发展到现今的词项跨语域分布数据(彭宣维2011:145;Liu 2010:77-78)。数据驱动(data-driven)的词项正式性识别具有实证意义,其内核是:词项之间的正式性差异一直较为模糊,但语域之间的正式性相对容易察觉,所以查看词项是哪个/些语域的高频词可以为其正式度的判断提供数据支持。不过,该方法也有待完善:首先,既然是用语料库数据判定词项正式性,那么怎样的语料库可以保障判定的效度?其次,怎样的证据能证明库中语域之间存在正式度差异?第三,以什么标准检验词项在跨语域分布中的数据显著性,从而使各语域正式度和它的高频词汇相联系?最后,用何种规则把数据分布规律转化为抽象范畴,以顺应理论驱动下的语料标注原则?为回答以上疑问,本文吸收Liu(2010)和Davies&Gardner(2010)的有关经验,探索一套数据驱动的词项正式性测量方法,把相关词项分别归入正式、中性和非正式范畴下。下文将按该方法的实施步骤逐步给出具体解说。
1.1 步骤一:选取大规模的多语域、平衡语料库为数据库
数据库的选取需符合如下要求:语域多,则便于提取词项的语域分布数据;语域库的容量和时效平衡,可保障语域分布数据之间的可比性;规模大,才能保证正式性判定结果的有效性。经考察,Corpus of Contemporary American English(COCA)(Davies2008a)能同时满足以上要求,因此我们选择它最大库容的本地词表作为数据来源,即The COCA 100,000 Word List(简称“词表”)(Davies 2008b)。它对应大约4.5亿词的语料,包括10万个常用词项在6个不同正式度的语域库中的标准化频率(normalized frequency):台词对白(SOAP)①、口头访谈(Spoken_COCA)、虚构文学(Fiction_COCA)、流行杂志(Magazine_COCA)、新闻报道(News_COCA)和学术论文(Academic_COCA)。
1.2 步骤二:用F-Score对各语域进行正式度测评
用跨语域数据分布判定词项正式性的前提是语域之间的正式性梯度,即6个语域库的正式度。为此,我们用F-Score进行计算:
F-Score=(名词词频+形容词词频+介词词频+冠词词频-代词词频-动词词频-副词词频-感叹词词频+100)÷2
下面按具体步骤,说明测算流程。
首先,在6个语域库中检索所需词类的标准化频率。如前文所述,F-Score以各词类的出现频率来测定语料的正式性,因此我们分别去COCA和SOAP的在线数据库中获取所需数据信息(见表1)。
然后,我们把各词类的标准化频率代入公式,从而获得6个语域的正式性分值及其间的梯度特征:学术论文(90.94)>新闻报道(81.46)>流行杂志(79.52)>虚构文学(60.54)>口头访谈(55.25)>台词对白(22.27)。这一结果不仅印证了我们的主观直觉,也符合学界对语域之间正式性差异的一般认识(侯维瑞1988;Davies 2020等)。
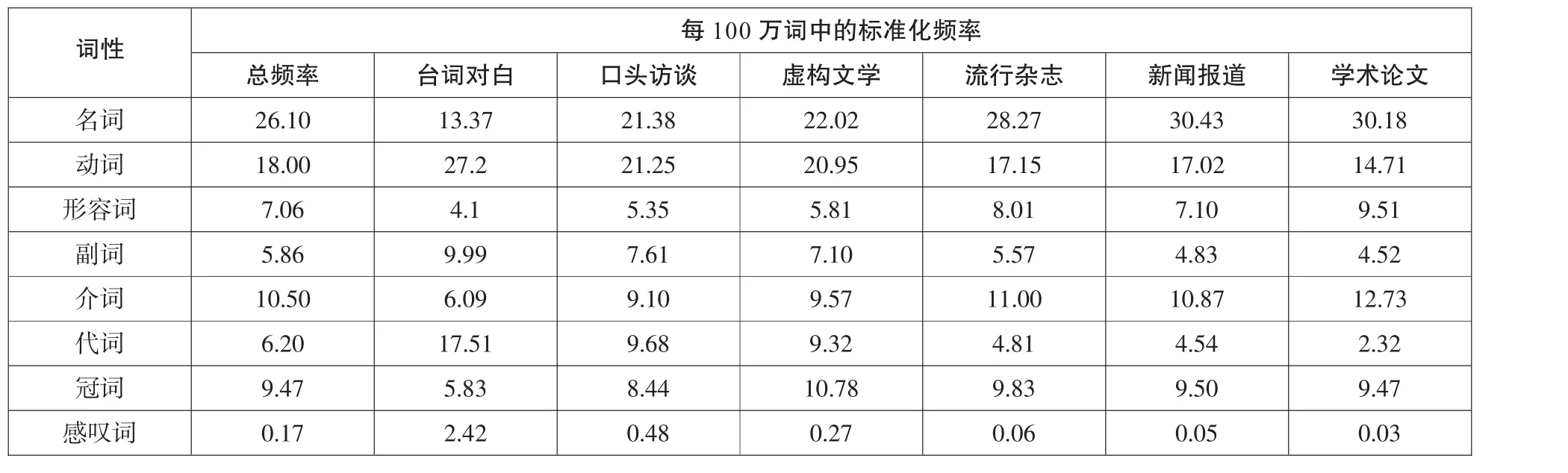
表1:各词类在6个语域中的标准化频率
1.3 步骤三:按照正式性梯度为语域赋值
获得语域正式性的梯度后,我们需要把它转化为抽象数值,以便后续词项正式性的判断。根据程雨民(2004:61-67),中性内容对应零值,正式对应正值,非正式对应负值;其中正/负值的大小表示正式/非正式程度。我们把65—70的F-Score分值区间设置为程雨民(同上:47-48)所说的“语域中性区”,即每个语域之间的共同范围,它们对词汇正式性的划分无显著影响②;高于该区间即为正式区:学术论文(90.94)、新闻报道(81.46)和流行杂志(79.52)赋码为正数;低于这个区间则为非正式区:虚构文学(60.54)、口头访谈(55.25)和台词对白(22.27)。根据F-Score的分值梯度,我们可以为它们逐一赋值③:学术论文(+4)>新闻报道(+3)>流行杂志(+2)>虚构文学(-2)>口头访谈(-3)>台词对白(-4)。
1.4 步骤四:按既定规则查看词项在各语域中的分布情况
当语域之间存在正式性梯度时,各语域中的高频词会带上相应的正式性梯级特征。这符合SFL实例化渐变阶(instantiation cline)中概率的实例化原则(Matthiessen 1993)。前文所述的语域正式性赋值,相当于语域/语篇类型的累积概率,为词项的正式性提供相对频率。两者相辅相成:前者是后者的整体引导,后者是前者的具体体现。因此,明确了词项在某个/些语域中的数据显著性,就可以判定该词带有这个/些语域的正式性特征。那么,如何为“数据显著性”提供证据?这里,我们参照Davies&Gardner(2010:3-7)的做法:如果一个词项在某语域中的标准化频率大于或等于它在其他所有语域中频率之和的两倍,且有显著性差异(p<0.05),则可以为该词赋上该语域的正式性分值。不过,词项的跨语域分布情况复杂,所以需要细化赋码规则,以保证它能把所有情况转化为相应的范畴化数值。
1.5 步骤五:根据词项的跨语域分布数据确立其正式度分值
首先,要判定词项是正式、非正式还是中性,就要对比词项在正式性和非正式性区域的频率。当正式区域的频率之和大于或等于非正式区域频率的两倍时,词项就是正式性的,标为“+”,如:

即:theory这一词项的跨语域分布状况为(学术论文+新闻报道+流行杂志)>(虚构文学+口头访谈+台词对白)×2。
反之,当非正式区域的频率之和大于或等于正式区域的两倍时,词项就是非正式性的,标为‘-’,如:

即:kiddo这一词项的跨语域分布状况为(虚构文学+头口访谈+台词对白)>(学术论文+新闻报道+流行杂志)×2。
如果以上两种情况都不满足,则判定为中性,赋码为0,如:

即:beautifully这一词项的跨语域分布状况为(学术论文+新闻报道+流行杂志)≯(虚构文学+口头访谈+台词对白)×2,且(虚构文学+头口访谈+台词对白)≯(学术论文+新闻报道+流行杂志)×2。
然后,要为正式和非正式词项确定刻度。在非正式词项的数据组里,我们对比三组非正式库的数据差异及其显著性。当词项在台词对白(-4)中的频次最高且大于等于它在其他非正式库中总频率的两倍时,计为-4,如:

即:kiddo这一词项在三个非正式库中的分布状况为台词对白>(口头访谈+虚构文学)×2。
如果词项在口头访谈(-3)中的频次最高,且大于或等于它在其他非正式库中总频次的两倍,则计为-3,如:

即:cop-killer在三个非正式库中的分布状况为口头访谈>(台词对白+虚构文学)×2。
当词项在虚构文学(-2)中的频次最高且大于或等于它在其他非正式库中总频次的两倍时,计为-2,如:
即:fifity-cent在三个非正式库中的分布状况为虚构文学>(台词对白+口头访谈)×2。
如果不属于以上三种情况,则计为-1,如:

即:pushy在三个非正式库中的分布状况为台词对白≯(口头访谈+虚构文学)×2。
同理,在正式词项数据组里,也对比三组正式语域的数据差异:
如果三组数据中没有出现最大值大于或等于其他两组数据之和的两倍,则计为+1,如:

即:proximity在三个正式库中的分布状况为学术论文≯(流行杂志+新闻报道)×2。
如果词项在流行杂志(+2)中频次最高、且大于或等于它在其他正式语域中总频次的两倍,计为+2,如:

即:rewarm在三个正式库中的分布状况为流行杂志>(新闻报道+学术论文)×2。
当词项在新闻报道(+3)中频次最高,且大于或等于该词在其他正式语域中总频次的两倍时,则计为+3,如:

即:bullishness在三个正式库中的分布状况为新闻报道>(流行杂志+学术论文)×2。
如果词项在学术论文(+4)中高频出现,且大于或等于它在其他正式库中总频次的两倍,计为+4,如:

即:theory在三个正式库中的分布状况为学术论文>(流行杂志+新闻报道)×2。
以上述标准,可以从词项的跨语域分布数据推出词项的正式性,并确立词汇正式性的连续统。
1.6 步骤六:实现词项正式性的自动测算及其在语料中的半自动标注
上述方法是在大型语料库的事实标准(de facto standard)(Leech 2017:1-4)中找到理论范畴的存在依据(Matthiessen&Nesbitt 1996:46-49,72-80),但范畴的应用还涉及语篇标注的操作细则。为此,我们需要对语料标注的准备工作做一些必要说明。
首先,利用Visual Basic语言,对前文所述的判定规则进行编程,批量测算“词表”中所有词项的正式度。就语篇中词项正式性的标注而言,获取带有正式性赋码的“词表”相当于获得了一套语料赋码集(tagset)。
其次,把语料中的词项与“词表”中的词项进行匹配,并把后者的正式性赋予前者。编程会帮助我们把已经完成正式性测算的“词表”导入已完成词性标注④的语料,进而把语料中的词项放入“词表”中进行自动检索。当语料中某词项的形符及其词类匹配到“词表”中的某一词条时,该词项即被赋上“词表”词条所属的正式性。经过试验,以上路径能标注出语篇中大多数词项的正式度。
第三,限定语篇标注的范围,必要时进行人工手动测算和标注。由于我们的方法是通过把新语料放在“词表”中进行检索来实现的,所以“词表”的容量关乎语料标注的范围。目前“词表”只有词汇级,不涉及搭配带来的词组/短语、小句级的正式性,所以标注对象暂时停留在Matthiessen(1991:265-271;1995:110-119)所说的“词项选择正式性”上。对于那些语料中包含但不在“词表”中的词项,我们在COCA和SOAP在线数据库中手动检索,并把它们的跨语域数据分布情况输入程序,或做手动计算,保证“词表”容量覆盖分析者的所需范围。
第四,我们需要标明语篇中词项标注的范围及其理据。根据Tucker(1998:7-8)和Biber et al.(1999:62)等人的观点,语篇中实词的选取是语义驱动的,而虚词主要是语法要求的。因此,我们只选择语篇中的实词词项:名词、动词、实义形容词和实义副词。相应地,本文的探讨对象锁定在语篇中的词项上,in addition、in turn、right now、go on等固定搭配则暂不予考虑。
按照以上规程,我们接下来对两个语篇中的词项正式度进行标注,并从相应的理论视角对标注结果进行人际功能描写。
2.描写路径
词项正式性具有人际范畴的韵律特征(Halliday 1979/2002:205-206),因此以它为对象的语篇描写需要在一定理论框架和操作规程的引导下,识别不同正式度的词项在语篇中所凸显的形式特征,从中提取规律并探求其语义体现(Halliday 1971/2002:89-107),最终建构语言事实(施春宏2010:3-5;2017:30-43)。
2.1 理论框架
“权势↘语体”系统(彭宣维2000:154-192;2003:97-100;2011:144-176)是本文赖以提取语篇特征的分析工具。它是SFL人际相度中语言正式性的理论范畴化:语体系统关注正式性的词汇语法,权势系统关注相应的语义范畴,语体体现权势。权势语义包括三个并行的方面:(1)等级性(HIERARCHY),即说话人在话语社团里等级序列上的位置,包括高位(正式)、中位(中性)和低位(非正式)连续统,以及与受话人之间的相互关系,包括:平等、不平等的“上对下”和“下对上”关系;(2)庄重性(SOLEMNITY),即说话人的话语在公共(正式)到私下(非正式)、专业(正式)到俗常(非正式)阶列中的位置;(3)亲疏性(INTIMACY),即交际者之间的社交心理距离,由疏远(正式)到亲近(非正式),以及这两极之间的中间范围,包括对立、中和非对立和投合非对立(同上;黄劲怡2021:88-134)。
2.2 标注结果
词项的正式性标注能让我们了解语篇中正式度成分的量化特征;为此,我们以语场相同而语旨、语式相异的两个语篇⑤为个案进行标注,从中获取原始数据。语篇一总共3,185词,其中标注词项为1,769词;语篇二共4,176词,标注词项有1,670词。文内的词项正式性识别情况见表2。

表2:两个语篇中词项正式性的识别情况:原始数据⑥
为避免两个语篇的词数差异对数据可比性可能造成的影响,下面分别从三个方面对原始数据加以处理:分布模式(distribution pattern)、语体丰满度(stylistic fullness)和语体密度(stylistic density)。我们将对比以上三个指标的数据结果,进而总结它们的共同特征。
2.2.1 分布模式
“分布模式”是基于每100词中各正式度词项的出现频率,对不同语篇中的语体词项分布状况所做的调查(见表3)。
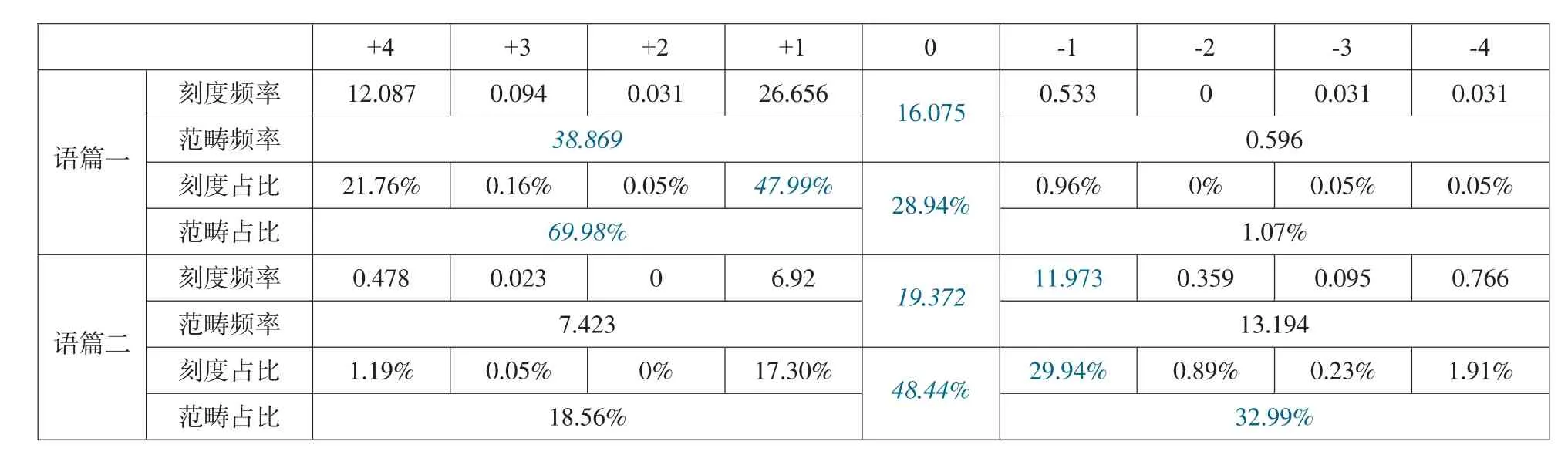
表3:两个语篇中词项选择正式性的分布模式对比⑦
表3所示,在正式词项的选择上,语篇一大于语篇二;就非正式资源看,语篇一小于语篇二;从中性角度说,语篇一小于语篇二。
2.2.2 语体丰满度
“语体丰满度”是基于语篇中正式性和非正式性词项选择的原始数据,对语体变异的幅度范围进行测算,从而凸显语篇之间的语体差异。(程雨民2004)我们这里按先前构拟的测算公式(彭宣维2003:244-245)进行:语体正/负丰满度=(正式/非正式词项的分值×出现次数)÷语篇总词数×100。通过把有关数据代入公式,其语体丰满度的异同见表4:
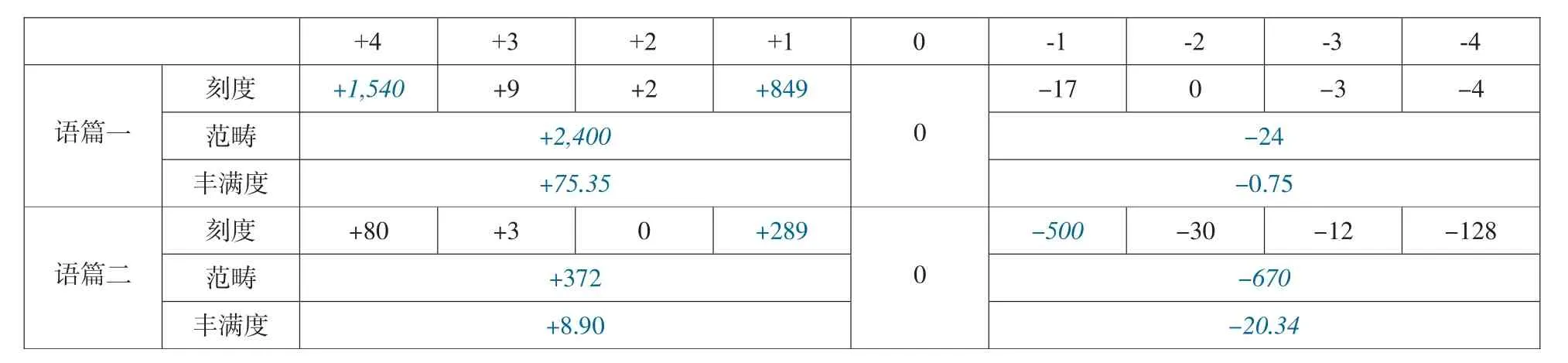
表4:两个语篇中词项正式性的语体丰满度对比
可见,语篇一的语体幅度是(+75.35,-0.75),而语篇二是(+8.90,-20.34)。前者正式词项偏高,后者非正式词项偏高。
2.2.3 语体密度
“语体密度”的计算跟“词项密度”(lexical density)有关。词项密度是通过查看实词在整个句子总词数中的占比来测算语篇中每个句子的信息“打包”程度,(Halliday 1985:63-67)而语体密度是进一步考察正式、中性和非正式词项在词项密度中的占比,从而说明语体成分在词项密度中的角色权重。在获得两个语篇词项密度的前提下⑧,我们从标注结果中获取正式、中性和非正式的实词数量,然后将上述数据代入测算公式:语体密度=(正式/中性/非正式词项的频次)÷语篇中句子的数量÷每句的词项密度,并导出结果(见表5)。

表5:两个语篇中词项的语体密度对比
可见,语篇一的正式、中性和非正式词项分别占了词项密度的61.43%、25.40%和0.94%;语篇二中的占比则为18.02%、47.03%和32.03%。
综合以上三种计量指标,我们归纳出它们的共同特征:语篇一侧重正式词项的选用,语篇二更关注非正式词项;语篇二比语篇一更注重中性词项的使用。
2.3 人际描写
根据统计结果,高正式性是语篇一最突出的词汇特征,权势语义就存在于作者与“潜在读者”(putative reader)(巴赫金2009:439-452)的人际关系之中。
第一,从等级性看,作者不断占据话语权而读者无法即刻反馈,以科学研究者的口吻行文,对非专业背景的受众设置门槛⑨,从而在语篇中与潜在读者地位有别,形成不平等的人际关系。作者谋求居高临下的权势效应(Halliday 1978:154-163)。面对这样的语体风格,非专业或教育背景局限的读者可能无法准确理解专业语境下的语篇语义(Halliday 1988/2004:158;1989/2004:159-180),从而在作者—读者关系中被放在下对上的弱势地位。
第二,从庄重性看,语篇涉及了技术性话题、探索性活动及高分类性语场⑩,所以潜在读者识读专业性语体的能力高低决定了语篇权势效用的强弱。作者不断利用正式性话语向潜在读者强调自己的体制性和专业性,把语篇内容建构为严肃和庄重的议题。对读者来说,不熟悉该研究领域的人难以理解高正式性措辞背后的相应语义,降低了读者与作者有效互动的可能性。
第三,从亲疏性看,语篇一属于技术性语域、读者反馈空间不足及话轮转换的缺失都会对潜在读者造成疏远的社交心理距离。正式词项的高频使用反映了科学语式的典型特征:写作者自我意识明确,组织计划性强,话轮由作者一方掌控,不与读者发生直接的视听接触,总是延迟回复(Martin 1992:528-532;Leckie-Tarry 1995:44-51)。正式语体很容易给读者带来疏离感(Halliday 1989/2004):交际双方的共鸣度弱,从而拉远了人际距离。
与此相对,语篇二是选择非正式词项更突出的一方,彰显了口头对话的固有特性。它涉及四位参与者:一位主持人和三位嘉宾。嘉宾3在每100词里使用非正式词项的概率为16.38,占所用实词的40.6%;嘉宾1的频率为12.31,占32.4%;嘉宾2为11.56,占28.11%;主持人为9.89,占25.41%。可见,四人都使用了一定量的非正式词项,由此确立的权势语义也有趋同:
第一,从等级性看,会话人之间是平等的同盟关系。他们首先通过选用非正式词项放低自己的角色地位,然后与交际者进行相同语体的交换,实现多方(主持人和嘉宾、说话人和观/听众)的低位结盟。
第二,从庄重性看,会话人彼此弱化交际的体制性和专业性。大量非正式词项的使用,向受众传达了私下和俗常的非庄重性交际意图,尽可能把议题内容表述得让所有在场者或观/听众易于接受,使所有人能轻松理解语篇语义。
第三,从亲疏性看,会话人彼此结盟,营造非对立的融洽性。语篇二的语式是说话人视听接触频繁、反馈直接且话轮均分(Martin 1992:508-523),那么非正式词项的相互交换能拉近人际距离,建立亲和的同盟关系,同时使会话人有效排除语义理解障碍,规避曲解。
3.结语
本文从正式性层级和词项之间的模糊性难题入手,一方面提出大型语料库数据驱动的词项正式性测量方法,用实证的手段把词汇资源归入各正式度范畴,弥补了先前研究中直觉和数据失衡所产生的强主观性和非可验证性;另一方面把此方法运用到语篇中词项正式性的标注和计量,并在“权势↘语体”模型的指导下描写语篇的人际意义,显示了词项正式性的测量和语篇描写之间的互补性。在某种意义上,这一尝试也回应了对SFL的某些诟病,如:理论范畴是直觉属性的,而非来自数据证据(Tognini-Bonelli 2001:63-66,74);理论范畴的可验证性有待加强(Butler 1985:92-93)等。大型语料库数据驱动的测量方法和SFL理论驱动式描写路径之间的界面研究,符合数据时代下语言“特征化”刻画的需求(陆俭明2021)。新方法和经典路径的有机结合,将更加有益于“语言事实”的挖掘及“语言学事实”的建构。
注释:
①SOAP的语料为美国肥皂剧中的台词对白转写而成,语料产生时间为2001到2012年间,库容为100,783,900词,是“极端非正式语言的重要材料”(Davies 2008c)。它为COCA自带的五个语域库补足了超非正式端。
②程雨民(2004:47-48)把各语域的集合看作连续统,而“中性区”指这个连续统的中间阶段。根据我们的F-Score测算结果,它的区间应小于正数区的最小值(79.52)而大于负数区的最大值(60.54)。
③这里,语域正式性的赋值梯度是为后续的词项正式度赋值做准备。笔者经过多次试验,证明这样的赋值既符合语域正式性的差异,也便于以此测算词汇正式度。
④我们的数据来源COCA和SOAP都采用由兰卡斯特大学开发研制的UCREL Claws 7 Tagset进行词性标注,所以“词表”也沿用了这一词性赋码集。为了使语料中的词项和“词表”中的词项更易于匹配,我们用同样的赋码集对语料进行词性赋码。
⑤两个语篇的语场都是抗议美国说唱音乐中的厌女观(misogyny)。其中,语篇一是“Theinfluenceof rap/hip-hop music:amixed-method analysis on audience perceptions of misogynistic lyrics and the issue of domestic violence”,属于学术论文语域,其语旨在科研领域内的相关人士之间,语式是书面媒介;语篇二为美国Fox5NY频道旗下电台节目Street Soldiers的其中一期,主题为“Hip-hop and women:has the disrespect gone too far?”,其语域属于电台访谈,语旨在主持人和三位受访者(一位说唱歌手、一位唱片打碟师、一位青少年心理疏导从业者)之间,语式是口头媒介。综上,两个语篇的语场相同而语旨、语式相异。
⑥在第二节的所有数据表中,斜体加粗的数值为所在数据组中的最大值;加粗的为数据组中的次大值。
⑦在第二节的所有数据表中,“刻度”指正式性连续统中的九个层次,即+4、+3、+2、+1、0、-1、-2、-3、-4;“范畴”指该连续统中的三个典型范畴,即正式(+4、+3、+2和+1四个刻度的数据总和)、中性(0值的数据)和非正式(-1、-2、-3和-4四个刻度的数据总和)。
⑧把待考察的两个语篇导入UAMCorpus Tool 3.3(O’Donnell 2013),提取文本基础信息:语篇一的句子数为155,词项密度为13.0;语篇二有273句,词项密度为6.3。
⑨这三个特征依次表明了语篇一在情景语境层语旨(tenor)三变量中的取向(Halliday&Matthiessen 2014:37-38),即:接触角色(contact role)、机构角色(institutional role)和地位角色(status role)。
⑩三个特征依次表明了语篇一在情景语境层语场(field)三变量中的取向(Martin 1992:537-539;Halliday&Matthiessen 2014:35-37),即:活动序列(activity sequence)、活动场(field of activity)和语场可分性(field taxonomy)。
猜你喜欢
科普童话·学霸日记(2022年1期)2022-05-30 10:48:04
科普童话·学霸日记(2022年1期)2022-05-30 10:48:04
哲学评论(2018年1期)2018-09-14 02:34:18
物流技术与应用(2017年3期)2017-05-17 05:29:04
首都外语论坛(2014年1期)2014-03-20 15:21:23
河南科技(2014年10期)2014-02-27 14:09:02
科技视界(2013年23期)2013-08-15 00:54:11
上海理工大学学报(社会科学版)(2011年4期)2011-09-26 11:01:32
大家(2011年9期)2011-08-15 00:45:37
职业教育研究(2011年6期)2011-03-25 10:36:23
