
基于全融合网络的三维点云语义分割*
2022-05-27 02:05刘李漫谭龙雨
计算机工程与科学 2022年5期
刘李漫,谭龙雨,彭 源,刘 佳
(中南民族大学生物医学工程学院,湖北 武汉 430074)
1 引言
点云是一种基本的三维数据结构,由三维物体表面的点构成,表征物体的形状及其它特征(如颜色、法向量等)。近年来,由于机器人导航和无人驾驶[1]研究的兴起,点云数据因其易得性受到了科研人员越来越多的关注。同时,点云在遥感测绘[2]、增强现实和虚拟现实[3]等领域也有重要应用,具有较高的科研和应用价值。三维点云语义分割任务,就是对点云中的每个点进行标签预测,使得同类物体具有相同标签,不同类物体具有不同标签。
点云分割的传统方法主要有3种:基于区域增长的方法[4]、基于模型拟合的方法[5 -7]和基于聚类的方法[8]。传统方法虽然可以用于三维点云语义分割任务,但是效果并不理想。

Figure 1 AFN network model 图1 AFN网络模型
文献[9]首次提出直接将三维点云数据作为深度学习网络的输入,实现端到端的学习。PointNet直接输入原始三维点云数据,通过逐点共享多层感知机的方式提取点云的特征。这种方法虽然避免了数据处理所产生的损耗问题,但是由于PointNet网络中每个点的特征提取是互不关联的,网络无法捕捉到点与点之间的关系,导致网络缺乏对目标局部细节的理解,从而无法准确预测每个点的语义信息。文献[10]提出了PointNet++网络,使用采样分组的策略,解决了PointNet无法捕捉局部特征的问题,但对局部细粒度特征的提取能力仍旧有限。文献[11]提出的三维点云卷积模型PointConv,通过逆密度加权卷积操作建立每个点与周围点之间的联系,极大增强了网络对目标局部特征的学习能力,在室内场景的语义分割上取得了很好的结果,但可视化结果显示,网络对目标轮廓的预测结果较差。
网络对目标细粒度特征提取能力的强弱,是影响语义分割性能的决定性因素。细粒度特征提取能力差会导致小尺度目标分割精度偏低。受二维图像目标识别[12]启发,本文提出全融合网络AFN(All Fusion Network),将多尺度特征融合扩展到三维点云特征提取网络。通过逐级的多尺度特征提取融合,加强网络的特征表达能力。同时,将提出的全融合网络用于三维点云的语义分割任务。本文在ScanNet数据集[13]和S3DIS数据集[14]上进行了实验与测试,并在相同实验条件下与同类三维点云语义分割网络进行比较。实验结果表明,全融合网络(AFN)大幅提升了三维点云小尺度目标的分割精度,在室内场景语义分割中取得了较好的结果。
2 基于全融合网络的三维点云语义分割框架
全融合网络AFN主要包括5个模块:多尺度特征编码模块、渐进式特征解码模块、多尺度特征解码模块、特征融合模块和语义分割头部。如图1所示,多尺度特征编码模块通过逐级下采样不断扩大网络的感受野,得到点云不同尺度的特征。渐进式特征解码模块通过残差连接对高层语义特征进行渐进式逐层解码。多尺度特征解码模块对特征编码模块提取的多尺度特征分别进行特征解码,得到多层次解码特征图。特征融合模块将渐进式解码特征图与多层次解码特征图进行特征全融合。语义分割头部利用融合特征,对每个点进行语义类别预测,实现语义分割。
2.1 多尺度特征编码模块
多尺度特征编码模块采用PointConv网络的特征编码器,利用邻域点的相对坐标学习权重并对点特征加权,同时将局部区域点的特征与密度倒数相乘,降低点云不同部位稀疏程度的不同对网络的影响。多尺度特征编码器输入点云坐标及其特征,经过特征编码,输出加权后的点云特征,即网络提取的特征。本文将5层编码器堆叠,构成一个多尺度特征编码模块。
本文使用采样分组策略[10]采样点云,在将点云输入每一层编码器之前,首先使用最远点采样FPS(Farthest Point Sampling)选取一定数量的质心点,再以质心点为中心构建点云邻域空间,将输入点云分成若干个局部区域。对每个局部区域使用共享的编码器提取特征,最终完成对整个点云的特征提取。
每一层编码器的输入为上一层编码器的输出,点云每经过一层编码器数量都会减少,网络的感受野增大,最终通过5层特征编码器,得到了L0、L1、L2、L3和L45个语义特征,不同层的感受野不同,能够提取到点云不同尺度的特征。底层尺度拥有更多空间结构信息,有利于对物体的定位;高层尺度拥有更多的语义特征,有利于对物体整体的分类。显然,将不同层的特征进行融合,能够更好地实现语义分割的效果。
2.2 渐进式特征解码模块
渐进式特征解码模块由PointConv反卷积层构成,通过反距离插值法和跨层跳跃逐层上采样,最终将点云数量恢复到原始点云的数量,获得每个点的语义判别特征。
首先将多尺度特征编码模块生成的语义特征L4使用反距离加权插值法进行数据扩充,再使用跨层跳跃连接将特征L3层与插值特征拼接,进行特征融合,将融合后的点云输入到特征解码层提取特征,得到解码特征D3,这样就完成了一次反卷积操作。本文将4个这样的反卷积层堆叠,进行渐进式特征解码,依次得到解码特征D3、D2、D1和D0。
2.3 多尺度特征解码模块
对L4的渐进式特征解码虽然连接了L3→L0每一层的特征,但解码过程中不可避免地会有部分信息丢失。为了弥补这一损失,本文设计了多尺度特征解码模块,直接对特征编码模块得到的每一个尺度特征进行特征解码,即使用每一个尺度的特征单独进行语义类别预测。
多尺度特征解码首先将逆密度加权模块下采样得到的多尺度特征L1~L4分别进行反距离加权插值,直接将点云数量恢复到原始点云数量,插值特征与输入层语义特征L0使用跨层跳跃连接,经过特征编码层,最终得到4层特征UpL1、UpL2、UpL3和UpL4,融合4层特征即为多尺度解码特征图。
多尺度特征解码特征图直接从各编码特征层解码后与输入层跳跃联结而来,这样的做法很大程度上避免了点云细节特征的丢失。各层分别对某些物体有着最好的特征表达效果,对这些物体来说,多层次特征解码使得各类物体最终的语义分割精度有了很大的保障。
2.4 特征融合模块
为了解决渐进式特征解码过程中局部细节信息的丢失,以及多尺度特征解码特征尺度单一、缺少全局特征的问题,本文设计了多尺度特征融合模块,即将渐进式解码特征与多尺度解码特征拼接在一起,利用多尺度解码特征对每个尺度的细节特征编码,以弥补渐进式解码特征细粒度特征不足的缺陷,充分发挥各自的优势,实现缺陷互补。
由于最终融合的特征既包含有跨越全局特征的渐进式解码特征图,又极大程度地保留了点云细节特征的多尺度解码特征图,最终形成具有判别性的融合特征,使网络在小尺度目标的分割精度上有了很大的提升。
2.5 语义分割头部
为了实现点云的语义分割,本文将融合后的点云多尺度特征输入到全融合网络的语义分割头部,为点云中的每个点分配标签。语义分割头部由权值共享的多层感知机组成,输入每个点的融合特征,输出网络预测的每个点属于各个类别的概率。
3 全特征融合网络的实现
点云在特征编码模块中进行特征提取时,每经过一次下采样,网络感受野就会变大,聚合的邻域特征范围随之增大,点云逐渐学习到接近全局区域的特征。然而,随着每个点承载的信息越来越多,边界轮廓类与小物体的信息可能会逐渐丢失。本文提出的特征全融合网络的构想,融合多个尺度特征与全局特征,以得到更好的分割效果。
接下来,本文将详述全融合网络实现的细节。
首先,输入点云通过特征编码模块实现特征的多尺度提取,多尺度特征编码模块由多个编码层堆叠而成,每个编码层编码一个尺度的特征。编码层的核心是逆密度加权卷积,卷积过程如下所示:
(1)采样分组:输入点云通过最远点采样法寻找局部区域质心点p,然后使用K近邻算法以质心点p构建点云邻域。每个点云邻域中包含K个邻域点,为减少空间变换对邻域特征的影响,将这K个点的坐标与局部区域质心p的坐标相减,得到三维点云的局部区域相对坐标,记为Plocal。
(2)逆密度评估:使用核密度估计算法[15]估计局部区域中每个点的密度,将局部区域点的密度输入到多层感知器中进行一维非线性变换,得到逆密度向量s=(s1,…,sK|sl∈R1,l∈{1,2,…,K})。为了实现对特征的逆密度加权,首先要进行维度对齐,将s复制扩展得到逆密度张量S=(S1,…,SK|Sl∈RCin),Cin为点云输入特征的维度。
(3)逆密度加权:用逆密度张量S加权局部区域特征Fin,Fin∈RK×Cin,如式(1)所示:
(1)
(4)卷积权重计算:将局部点云的相对坐标Plocal输入多层感知机中,多层感知机的最后一层为线性层,多层感知机中线性层输入为M∈RK×Cmid,线性层的权重为H∈RCmid×(Cin×Cout),其中Cin、Cmid和Cout分别是点云邻域在输入层、中间层和输出层的特征维度,cin,cmid和cout分别是输入层、中间层和输出层特征维度的索引。Conv则是卷积核为1×1的卷积神经网络,用于计算权重,从而权重的计算公式如式(2)所示:
W(k,cin)=Conv(H,M)=
(2)

(3)
对所有以质心点为中心构建的点云邻域使用一个共享的特征编码器进行编码,编码器将学习到每个邻域空间的全局特征(整个点云的局部特征),所有邻域空间特征即构建一个完整点云的特征。经过共5次逐级下采样后,可获得5个包含不同尺度的点云特征L0~L4。由于L0基本不包含高级的语义特征,本文只对后4个特征进行多尺度特征解码。
为了将特征信息逐层传递回原始点云数据,全融合网络采用基于逆密度加权卷积的渐进式特征解码模块,逐层地将高层的语义特征传递到原始点云中的每个点。
渐进式特征解码模块首先由反距离加权插值法进行点云数量扩充,然后由跨层连接将特征串联叠加,最后由逆密度加权卷积层提取特征。反距离加权插值法选取插值点周围3个最近点,用它们与插值点距离的倒数加权特征,求和作为插值点的特征,其计算公式如式(4)所示:
(4)
fi的权重wi(x)的计算公式如式(5)所示:
wi(x)=d(x,xi)-p
(5)
式(4)和式(5)中,fi是xi的特征,d为x与xi的欧氏距离,p=2。

渐进式逐层解码能够通过特征插值的方法将高层的语义特征传递到底层,同时通过跳跃连接来融合编码部分具有相同点云数量的点特征,以弥补在下采样编码过程中损失的结构信息,高层特征与底层特征融合,使最终输出的每个点既包含了点云局部特征,又蕴含点云全局特征,网络将会对点云整体的上下文信息有更深刻的学习,对每个点的预测更加准确。对物体边界以及小物体等容易产生归属误判的情况,这种底层细粒度信息的传递更是尤为重要。
为了增强网络对不同尺度物体语义分割的鲁棒性,本文在特征空间中通过多尺度特征解码模块将特征编码模块提取的多尺度特征图分别解码。特征编码模块输出的L1、L2、L3和L4尺度特征与L0特征拼接,使用反距离插值法直接将点云数量恢复至原始点云数量,得到多尺度解码特征UpL1、UpL2、UpL3和UpL4,每个解码特征图大小相同。将特征通道使用串联方式相加,聚合不同尺度的特征信息。全融合语义分割网络学习的点云多尺度特征和全局特征,拥有更强的特征表达能力,兼顾局部细节特征与全局抽象特征,能够有效地提高点云语义分割效果。
4 实验与结果分析
4.1 实验参数
为了确保实验结果的可对比性,本节在公开数据集ScanNetv1和斯坦福三维室内分割数据集S3DIS(Stanford large-scale 3D Indoor Spaces)上进行了实验,这是三维点云语义分割网络最为通用的三维点云室内场景数据集。
ScanNetv1数据集由1 513个具有标注的室内场景组成,场景类型丰富,物体种类众多。每一个室内场景中包含桌子、门和窗户等20类已知物体,和一个未知类别。本文把1 513个室内场景中的1 201个用于训练,312个用于测试。
S3DIS数据集由3个不同建筑物中6个大型室内区域组成,包含桌子、椅子、沙发、书柜和地板等13种物体类别。数据集中每个点云都标注了坐标XYZ及其所属的物体类别信息。本文将数据集中的Area1~Area5作为训练集,Area6作为测试集。
本文实验环境配置如表1所示,网络参数设置信息如下:在进行数据处理时使用非均匀采样。模型使用Adam优化器,初始学习率learning_rate=0.001,每次输入点云数num_point=4 096,训练批量batch_size=4。延迟率decay_rate=0.7。延迟步长decay_step=200 000,最大迭代次数max_epoch=501。实验结果使用以下3种指标进行判断:
(1)点云预测准确度PA(Point Accuracy)。在三维点云数据集中,室内场景有K个物体种类,1个背景类别,PA的计算公式如式(6)所示:
(6)
其中,Puu表示将点云中的语义标签为u预测为u的点云数量;puv表示将点云中的语义标签为u预测为v的点云数量。
(2)平均类别准确度MPA(Mean Point Accuracy)。MPA是PA的平均加权。首先计算每个类别预测准确度,即每类预测正确的点占该类点总数的比值,然后再计算所有类别的预测准确度的平均值,计算公式如式(7)所示:
(7)
(3)平均交并比MIoU。IoU是2个集合交集与并集的比值,在语义分割中IoU即每个类别预测结果和实际结果的交集,与每个类别预测结果和实际结果的并集,这2个集合的比值。对所有类别的IoU求均值,即为平均交并比,其计算公式如式(8)所示:
(8)
其中,TPu表示被模型预测为第u类的第u类样本的数量,FPu表示被模型预测为第u类但非第u类样本的数量,FNu表示被模型预测为非第u类的第u类样本的数量。

Table 1 The hardware/software configuration表1 硬/软件配置
4.2 实验结果分析
本文首先在ScanNetv1数据集上对全融合网络AFN进行训练和测试,并与PointNet++和PointConv的语义分割结果进行对比。由于AFN网络参数量较大,为了保证能在NVIDIA Tesla V100-SXM2-16上正常训练,将输入的初始点云数设置为4 096。PointNet++与PointConv输入的原始点云数量为8 192,输入的原始点云数量越多,目标的细节特征就保留得越多,毫无疑问网络能够学习的特征就越多。所以,为了比较的公平性,本文在同样的设备上以同样的网络参数配置,用同样的数据预处理方法,重新对PointNet++与PointConv进行训练与测试,训练结果如表2所示。表2显示,全融合网络在点云预测准确度(PA)上,相比PointNet++网络提升了3.3%,稍逊于PointConv网络;而在平均类别准确度(MPA)对比中,全融合网络则具有显著的优势,比PointNet++的平均类别准确度高出19.57%,比PointConv的平均类别准确度也提高了6.93%。在ScanNetv1数据集中,每个点云场景中大尺寸目标的数量远超小目标的数量,小物体预测正确与否对PA的影响较小,所以PA并不能准确地反映网络的分割结果,不能有效体现网络对小尺寸目标语义分割的精度。而平均类别准确度MPA通过对每一类物体的PA求平均值,每一类物体分割精度对最终结果是有相同的影响力,能更加准确地反映网络对整体场景的预测准确度。本文的全融合网络在MPA上有很大的提升,说明该网络在三维点云语义分割过程中对小物体目标分割具有一定的优势,验证了设计的多尺度特征全融合网络的有效性。
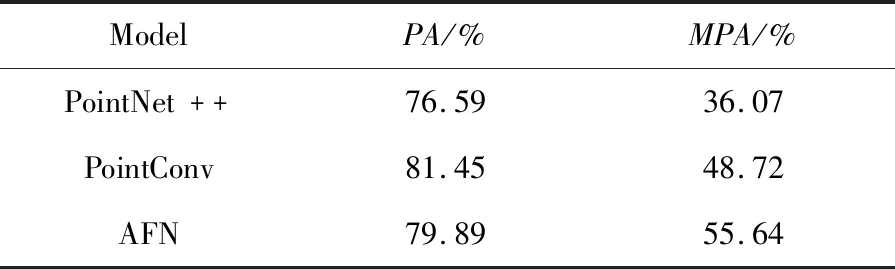
Table 2 Comparison of semantic segmentation results on ScanNetv1 with non-uniform sampling表2 ScanNetv1数据集上非均匀采样语义分割结果对比
表3详细对比了AFN、PointNet++和PointConv在ScanNetv1数据集的每个类上的语义分割结果。相较于PointNet++网络,AFN网络共有13类物体预测准确度有所提高,并且在11类物体预测准确度上高于PointConv。其中,AFN在“水槽”“冰箱”和“门”这3类物体的预测成功率有了极大的提高,分别至少提高了59.81%,29.02%和24.27%,这3类物体虽然在房间不同位置,但它们拥有一个共同的特点,即它们在每个场景中的数量占比都很小,同时它们的轮廓更加容易与背景融为一体,AFN网络远超其它网络的表现表明了全融合网络对细粒度特征提取的有效性,从而对小目标分割更加准确;同时,AFN对“椅子”“浴帘”“橱柜”和“图片”这4类物体的预测准确度也提高了5%~20%。
文献[9]并未给出PointNet网络在ScanNetv1数据集上的实验结果,因此本文在S3DIS数据集上对PointNet和AFN网络的语义分割结果进行了对比。使用K折交叉验证将数据集划分为训练集和测试集,使用训练好的模型在数据集的Area6区域进行实验,结果对比如表4所示。可以看出,全融合网络无论在MIoU,还是在PA上的结果都优于PointNet网络,其中,MIoU提高了11.61%,PA提高了6.29%。

Table 3 Comparison of semantic segmentation accuracy of each type of target on ScanNetv1表3 ScanNetv1数据集上每类目标语义分割准确度对比

Table 4 Semantic segmentation results on S3DIS Area6 test set表4 在S3DIS Area6测试集上的语义分割结果
本文还将AFN与PointNet在S3DIS数据集上13个类别的MIoU评分进行了对比,结果如表5所示。
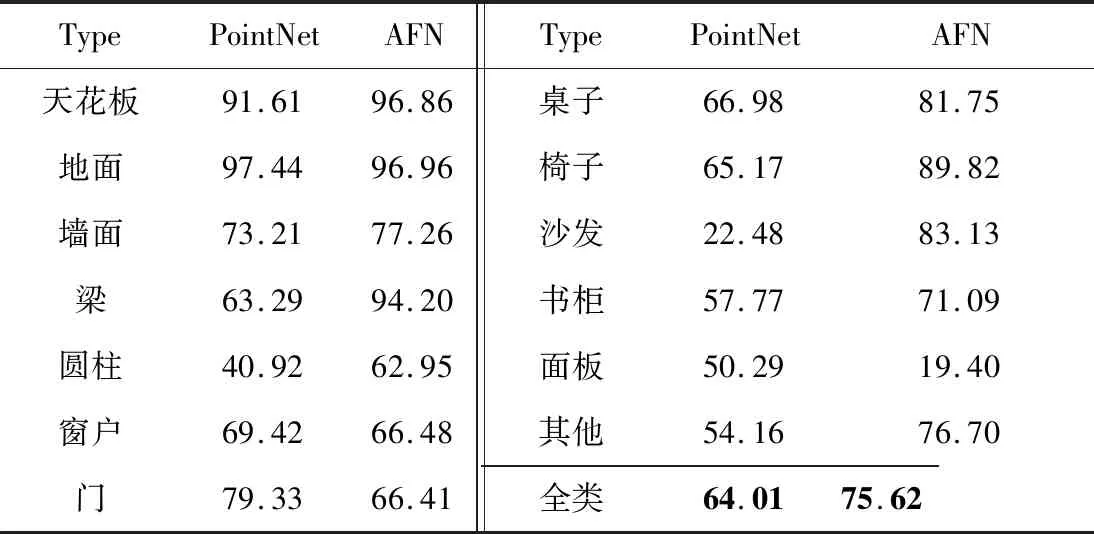
Table 5 MIoU comparison of semantic segmentation accuracy of each type of target on S3DIS Area6表5 S3DIS Area6测试集每类目标语义分割结果MIoU对比 %
从表5中可以看出,全融合网络在除“地面”“窗户”“门”和“面板”之外的所有类上语义分割能力都有提升,最高提升达60.65%,尤其对于场景中小物体及大目标的轮廓分割能力具有明显的提升,说明了全融合网络融合多尺度特征对细粒度特征提取的有效性。
本文采用MeshLab软件将PointNet网络和全融合网络在S3DIS数据集上的语义分割结果可视化,如图2所示,不同灰度代表不同物体类别。为了更清晰地观察室内场景,将天花板去除。在图像标注的方框1中,对于梁和墙壁物体轮廓连接在一起的地方,可能由于物体不太明显,PointNet模型直接将梁全部错误分割为其他物体,而全融合网络精准地分割了梁。从图像标注的方框2中可以看出,对于沙发与椅子这些长相类似,且在场景中点云数量占比较少的类别,PointNet网络由于缺乏点云局部特征的提取能力,往往会出现语义混淆的情况,将沙发分割为椅子,将门分割为墙等。而全融合网络由于融合特征的鲁棒性,对小物体拥有更加准确的分割能力。

Figure 2 Visual comparison of S3DIS semantic segmentation results图2 S3DIS数据集语义分割结果可视化对比
对ScanNetv1数据集语义分割结果的可视化结果如图3所示,图3b~图3d中的黑点均为桌面摆放物体,由于体积小且桌面摆放物体不固定,所以标记为其他类。

Figure 3 Visual comparison semantic segmentation results on ScanNetv1 图3 ScanNetv1数据集语义分割结果可视化对比
从图3可以看出,全融合模型对场景整体语义分割结果的视觉表现强于PointNet++和PointConv网络,可以更加精准地分割场景中的小物体,目标轮廓也更加清晰。PointNet++和PointConv网络由于局部特征提取能力不如AFN,在分割时无法准确分割目标轮廓。
总结来说,面对各式各样的室内场景、位置不定且大小不一的各类物体,全融合网络的表现更加优秀。评价指标和可视化结果都表明了AFN网络融合特征对于语义分割强大的提升能力,这种能力主要体现在小物体目标与物体轮廓边缘的分割。实验结果有力地证明了全融合网络对提高语义分割准确率的有效性,以及针对物品、场景多样化的通用性。
相较于良好的深度学习机制,良好实验效果的获得更多是AFN网络框架的设计占了更大的主导地位。受U-Net[16]网络的启发,较多的语义分割网络使用先下采样后上采样的策略对目标进行特征提取、分割。AFN网络同样如此,多尺度加权特征编码模块和渐进式特征解码模块便可组成一个有效的U型语义分割网络。但是,本文的创新之处在于,AFN网络对各特征层进行了更为充分的利用。多尺度特征解码使得网络有更多的机会接触到各特征层的信息,使得网络特征提取与学习的效率更高。最终的实验结果也表明了AFN网络的优异性。
5 结束语
受二维目标检测模型中多尺度特征融合思想的启发,本文提出了全融合网络结构,将多尺度特征融合思想扩展到三维点云数据处理中。全融合网络通过多尺度特征的编码、解码,最后融合不同尺度的特征,提升了网络特征提取能力的鲁棒性。本文将提出的全融合网络用于点云语义分割任务,并在ScanNetv1与S3DIS数据集上进行实验。实验结果表明,三维点云中的小尺度物体语义分割结果易受大尺度物体影响,导致语义类别错误,或部分边界被大尺度物体侵蚀,本文提出的全融合网络能够捕获不同尺度物体的特征,对三维场景中的小物体和物体边界拥有更加优秀的分割能力。
猜你喜欢
中国石油石化(2022年12期)2022-07-16
陶瓷学报(2021年4期)2021-10-14
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
少儿画王(3-6岁)(2020年4期)2020-09-13
中国外汇(2019年19期)2019-11-26
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
太空探索(2016年5期)2016-07-12
时代英语·高三(2014年5期)2014-08-26
微型计算机(2009年4期)2009-12-23
