
基于随机森林算法的无线传感网络攻击流量阻断模型构建*
2022-05-27 02:05徐礼金贺艳芳
计算机工程与科学 2022年5期
徐礼金,贺艳芳
(1.广东理工学院信息技术学院,广东 肇庆 526000;2.河南大学民生学院,河南 开封 475000)
1 引言
高度移动环境下,传统无线网络通过最大化带宽利用率实现资源管理策略的同时优化路由,以此保证用户的高质量服务体验[1]。无线传感网络内的大部分节点都保持静止不动状态,只有少部分需要移动,这部分移动节点主要运行在危险的远程环境或者无法操控的恶劣网络环境中,具有无法替代性。目前研究无线传感网络的核心问题是探寻一种有效的网络策略以延长网络的生命周期[2 -4]。在最初对无线传感网络进行研究时,研究者认为Ad-hoc路由机制和成熟的因特网技术能够充分满足无线传感网络的基本需求[5],但是随着学术研究的不断深入,研究人员发现,与传统无线网络相比,无线传感网络的核心技术要求差异巨大。传统的无线网络的核心目的是实现数据的传输,为了满足各种应用程序数据传输的需求,边缘论思想“端到端”是传统无线传感网络的主要设计思路,具体内容为:在网络端系统上,对数据进行处理,并主要利用中间节点对数据的分组转发进行控制[6,7]。从长远来看,这种方法不利于无线传感网络的发展。无线传感网络的拓扑结构存在多变性,其中的传感器节点可以人为控制随时减少或增加,随意聚合或分开[8]。无线传感网络传递信息的方式为无线传递,信息在传感节点中传递时由于各网络节点都暴露在外,导致很容易受到外部攻击和入侵,以至于无线传感网络的损坏和网络信息的泄露,探寻一种优异的无线传感网络攻击流量阻断模型是目前研究的主要内容[9]。
目前已有针对无线传感网络攻击流量阻断的相关研究,包括重定向流量、丢弃数据包和限制流速等多种方法。重定向流量是把无线传感网络发出攻击的流量转发到其它设备进行处理,但是这种方法并不能降低整个无线传感网络遭受攻击后的负载压力[10];丢弃数据包判断攻击流量的方式是通过端口号和IP地址实现数据包丢弃,这种方法无法判断数据的合法性,会把合法数据一起丢弃[11];限制流速不会丢弃数据,仅限制攻击流量速率以阻断攻击,虽然不会丢弃合法数据,但是依然没有实现阻断流量攻击的目的[12]。
基于此,本文基于字符(单词)的词频矩阵,利用词频-逆向文件频率TF-IDF(Term Frequency-Inverse Document Frequency)算法提取有效载荷的特征,使用随机森林算法,根据特征结果进行网络流量分类,基于分类结果实现流量攻击溯源,完成异常无线传感网络检测,利用流表的报文过滤实现无线传感攻击流量的阻断,为无线传感网络的安全运行打下基础。
2 无线传感网络攻击流量阻断模型
2.1 无线传感网络攻击流量检测方法
2.1.1 特征提取
词频-逆向文件频率TF-IDF是20世纪80年代末期提出的用于挖掘文本和检索信息的一种加权技术[13]。该技术中TF表示某个样本内某字符或者某单词出现的频率,主要由某个字符数量oi与样本中总字符数量U相除而得,某个样本内字符di出现的频率如式(1)所示:
(1)
IDF的中心思想是指在有效载荷特定的样本中出现某个字符,而这个字符在其他正常流量或者样本中较少出现,说明该字符具有极强的区分此类样本的能力,与选择攻击特征的样本相契合,这就要求IDF具有更大的值[14]。样本中字符IDF值的计算方式如式(2)所示:
(2)
其中,|C|与|{di∈cj}|分别表示样本总数与包含字符di的样本数量。为了防止包含字符di的样本数量失去数学意义,将分母设置为1+|{di∈cj}|。
特征提取的计算方法如式(3)所示:
TFIDF=TFi*IDFi
(3)
在实际测试中发现,TF-IDF技术区分标点和字符时不够智能,这就需要对复杂的字符与标点实行人工分词,对无线传感网络攻击流量和正常流量字符进一步分析差别,使用独热(One-hot)编码标记2种流量样本,进行快速傅里叶变换,获取具有步长序列的频谱图[15]。经对比频谱图,正常流量比攻击流量的字符幅值更高。
本文对相同数据进行2次分析,第1次将字符作为特征提取词频矩阵训练的依据,第2次将单词作为特征提取词频矩阵训练的依据,得到2个训练结果。在此基础上,将随机森林算法的输入向量视作特征提取结果的词频矩阵对训练结果进行验证,至此完成对无线传感网络攻击流量和正常流量的识别,最终得到需要提取的特征。
2.1.2 基于随机森林算法的流量分类
在得到无线传感网络攻击流量的特征后,本文以此为依据,采用随机森林算法对流量进行分类。在引导聚集算法的基础上改进得到随机森林算法,以下为随机森林算法的具体过程:
(1)经TF-IDF提取特征得到词频矩阵:
CP*Q={C1,C2}
(4)
其中,C1表示将单词作为依据生成的词频矩阵,C2表示将字符作为依据生成的词频矩阵,P与Q分别表示训练样本总数与TF-IDF算法提取出的无线传感网络攻击流量特征总数。将词频矩阵作为输入得到词频矩阵特征集:LC={l1,l2,…,ln},通过Bootstrap完成取样。为构成M个样本集:R={R1,R2,…,RM},M≥1,需要随机在输入数据集内抽取M个样本集,再利用剩余数据构成袋外数据OOB(Out Of Bag)样本集。无线传感网络流量的分类过程如图1所示。

Figure 1 Process of traffic classification 图1 流量分类过程
(2)依据随机森林算法的要求,由步骤(1)中抽取的样本集R需要在各待分裂节点中选择p个特征,此处p取值为2,避免出现过度拟合,由基尼系数决定节点分裂标准:
(5)
其中,vi代表全部样本与训练集内特征值样本个数的比值。最优分裂点是通过式(5)计算得到的最低基尼系数。
(3)重复执行步骤(2),直至达到已设定好的阈值或者不能分裂为止,此时建立第1棵决策树。
(4)重复执行以上3个步骤,一直到得到所需数量的决策树,构成随机森林,最后以投票方式确定无线传感网络流量是否为攻击流量。
完成无线传感网络流量分类后需要对攻击流量实现溯源。溯源攻击流量实际上就是利用随机森林算法获得的流量分类结果,对存在异常的无线传感网络加以识别。无线传感网络环境下,各主机都有自身的行为特征[16]。为了更详细地分析主机特征,通常把主机行为分为2种,一种是主机负责接收报文,另一种是主机负责发送报文。对某个IP地址特征进行提取时,需要同时分析此IP地址作为源地址和目的地址的全部数据包,取得对流量进行分类的相关信息。使用随机森林算法获得一个训练完成的分类器,识别出异常主机行为。在流量攻击IP地址得到确定的基础上,对连接攻击流量的交换机和端口进行深入挖掘。在无线传感网络的拓扑图中找到相对应的节点信息,依据这些节点信息查询链路信息,获得邻近攻击终端的交换机节点信息,完成流量分类,并将交换机的ID和端口作为攻击流量阻断的阻断点。
2.2 基于拓扑结构的阻断攻击流量
在实现流量分类的基础上,本文基于拓扑结构阻断攻击流量。攻击阻断主要是过滤属于攻击者IP的报文,把出现异常的网络恢复到正常运行的状态,主要采取的技术手段是经软件定义网络SDN(Software Defined Network)实现集中控制,下发控制流表至连接攻击流量IP的交换机,实现攻击报文的实时过滤。
经过以上攻击流量溯源,无线传感网络流量攻击的主机IP地址与连接该地址的交换机被控制器发现,此后实时过滤掉攻击流量报文,完成攻击流量阻断。过滤报文的具体过程如图2所示。
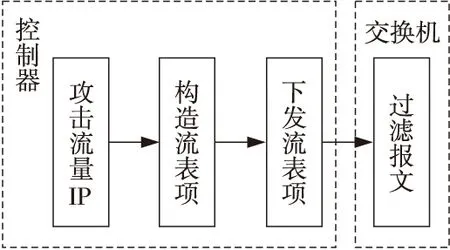
Figure 2 Process of packet filtering 图2 过滤报文过程
在无线传感网络出现攻击流量时,与攻击流量连接的交换机接收到OpenFlow网络通信协议作为基础控制器下发的控制流表,流表内包含主要针对攻击流量终端的相关流表项,交换机先接受流表项,然后过滤具有攻击性的报文。再接入攻击终端的端口位置,丢弃攻击流量终端I/O数据报文,完成无线传感网络攻击流量阻断。
3 实验与结果分析
为了验证本文模型的阻断效果,本节使用某市电力公司的无线传感网络作为研究对象。从开放式分类目录DMOZ(Directory MOZilla)中采集无线传感网络正常流量数据集,从CSIC 2010 HTTP Dataset中采集无线传感网络攻击流量,对采集出的数据集进行清洗,分别保存6万条正常流量数据和攻击流量数据,攻击流量分为代码执行、跨网站脚本XSS(Cross Site Scripting)攻击、结构化查询语言SQL(Structured Query Language)注入攻击和回车换行CRLF(Carriage Return Line Feed)注入攻击等。构建的模拟实验场景主要包括目标靶机、实验机、攻击机和交换机各一台。目标靶机模拟Web服务器,系统为Windows 2010;经过交换机端口镜像实现实验机对无线传感网络的监听,同时使用本文模型对HTTP数据包进行流量检测。攻击机利用BurpSuite向靶机模拟攻击。通过真阳性TQ、假阳性FQ、真阴性TM和假阴性FM4个参数,计算准确率、精确率、召回率和调和平均数,评判本文模型的应用效果。各参数的具体含义如表1所示。

Table 1 Meaning of each parameter表1 各参数具体含义
评价指标计算方法分别如式(6)~式(9)所示:
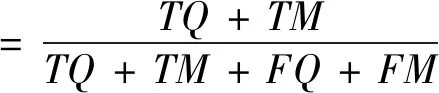
(6)

(7)

(8)

(9)
实验从2个方面检验模型的性能,分别为攻击流量检测效果和攻击流量阻断效果。本文使用基于OpenFlow的攻击流量阻断模型(文献[11]模型)和面向节点影响力的攻击流量阻断模型(文献[12]模型)与本文模型进行对比。3种方法采用相同数据集进行仿真实验,分别在不同数据比例节点进行对比统计。
3.1 攻击流量检测效果
3种模型的攻击流量检测的准确率结果如图3所示。从图3能够看出,随着数据集的增加,2种对比模型的准确率都出现下降趋势,而本文模型准确率出现平稳上升趋势,说明本文模型对于无线传感网络流量攻击具有较高的准确率。这主要是因为本文根据特征结果使用随机森林算法对网络流量进行分类,提高了检测范围和效率,进而提高了检测准确率。
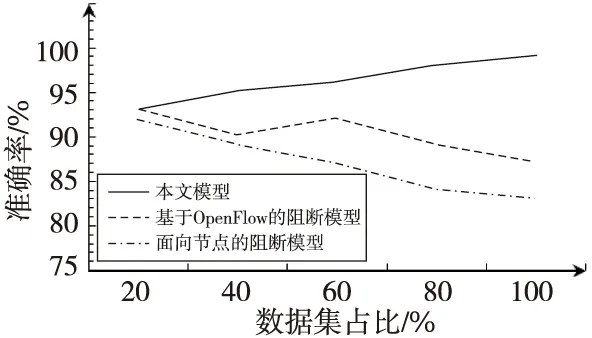
Figure 3 Comparison of detection accuracy图3 检测准确率对比
3种模型检测攻击流量的假阳性(FQ)率如图4所示。从图4中能够看出,伴随数据集的增加,基于OpenFlow的阻断模型呈现出不稳定的状态,而面向节点的阻断模型虽然整体趋势较平稳,但是假阳性率依旧较高。本文模型的假阳性率较低,证明本文模型具有良好的攻击流量检测效果。这主要是因为本文以特征为基础对攻击流量进行检测,提高了检测准确率,降低了假阳性率。
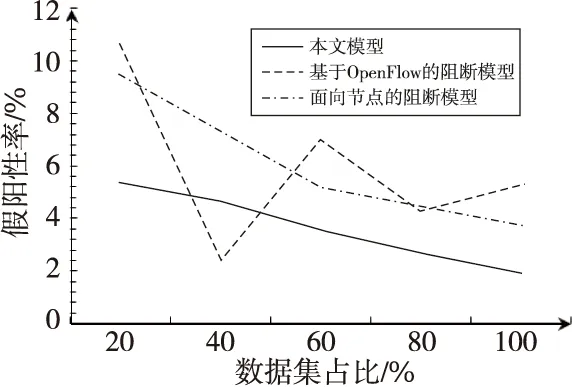
Figure 4 Comparison of false positive rates图4 假阳性率对比
3种模型检测攻击流量的检测召回率如图5所示。从图5中能够看出,随着数据集的逐渐增加,基于OpenFlow的阻断模型的检测召回率呈现逐渐升高的状态,且涨幅较大,而面向节点的阻断模型整体检测召回率的涨幅更大。本文模型的检测召回率则降低,尽管随着数据集的增加也有升高的趋势,但涨幅明显低于其他2种阻断模型。这主要是因为本文模型通过过滤报文来实现无线传感网络攻击流量的阻断,有效降低了检测召回率。
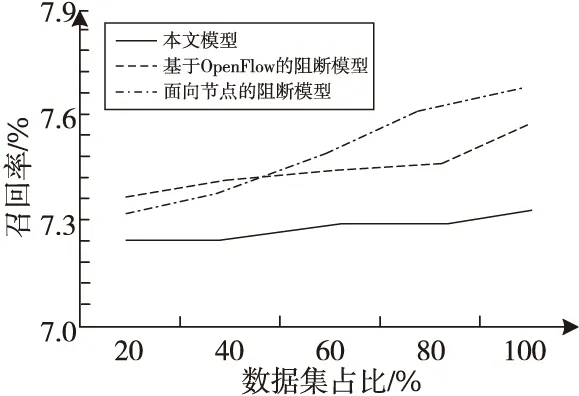
Figure 5 Comparison of detection recall rate图5 召回率对比
本文模型所使用的随机森林算法,森林内树的数量和特征数量都会对整个算法造成影响,不同数量的树对整个模型检测结果影响如表2所示。从表2可以看出,随着森林中树的数量增加,检测的准确率和调和平均数等不断增高,而假阳性率在树数量为20时最低,证明随机森林算法中树的数量为20时,检测无线传感网络流量攻击的效果最好。
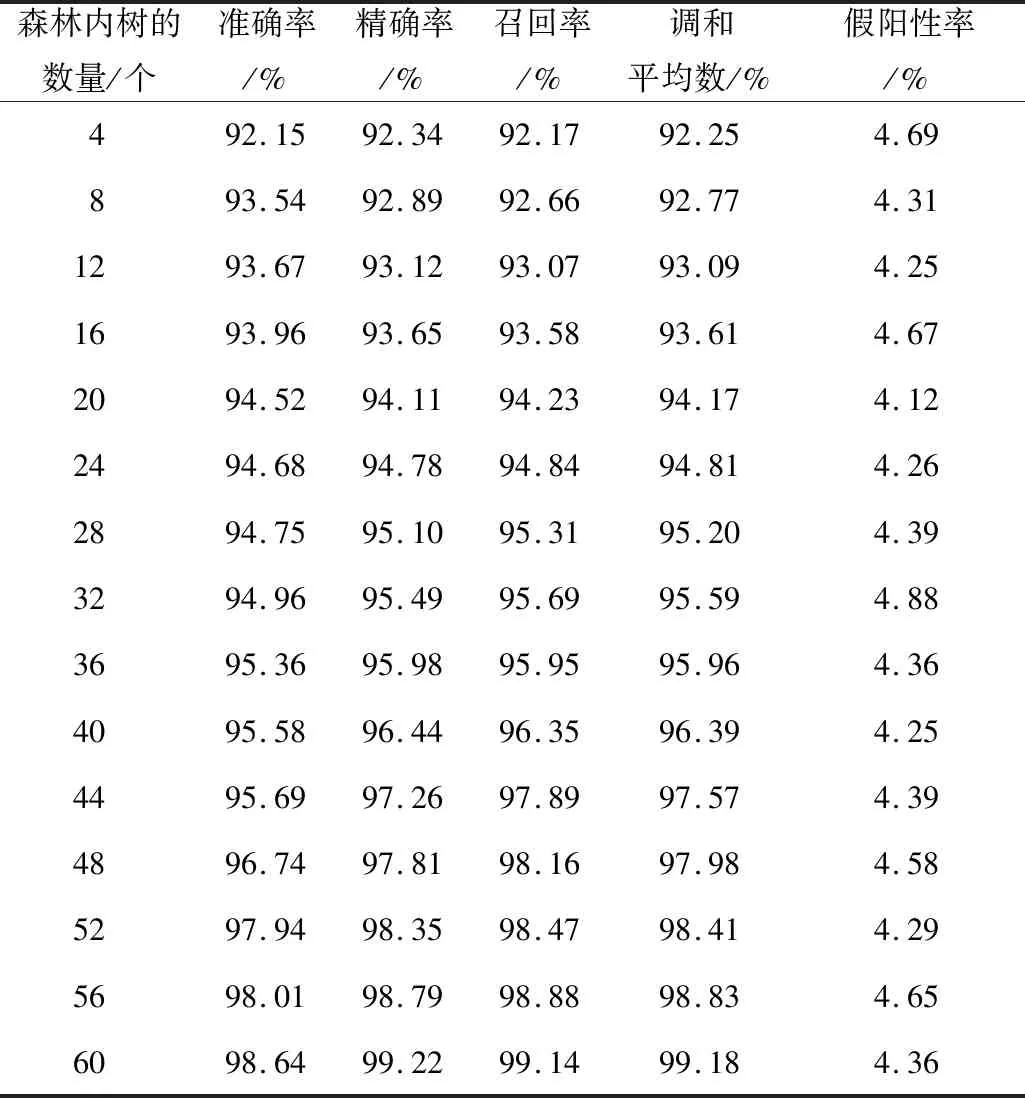
Table 2 Effect of tree numbers in forest on attack flow detection 表2 森林中树的数量对攻击流量检测的影响
通过式(6)~式(9)计算评价3种模型的各项指标性能,对比结果如表3所示。

Table 3 Performance comparison表3 性能对比 %
由表3可知,基于OpenFlow的阻断模型准确率与精确率较低,其检测无线传感网络攻击流量的性能较差;而面向节点的阻断模型虽然准确率与精确率较高,但是召回率较低,说明该模型只能检测正常流量,对攻击流量的检测能力较差;本文模型各项指标均较高,在检测正常流量和攻击流量时具有良好的性能。
3.2 攻击流量阻断效果
选取2个具有代表性的特征分析网络受到攻击前后网络流量状态典型特征变化情况,分别为总数据包数和目的地址的熵(H(dstIP)),采用3种模型对遭受到的攻击进行阻断,阻断对比结果如表4和表5所示。从表4和表5中所示的总数据包数和目的地址的熵变化情况可以看出,该无线传感网络在40 s后遭受到攻击,相比于另外2种对比模型,使用本文模型能够有效阻断网络攻击流量,可在较短时间内将网络恢复至正常。

Table 4 changes in the total number of packets表4 总数据包数变化情况
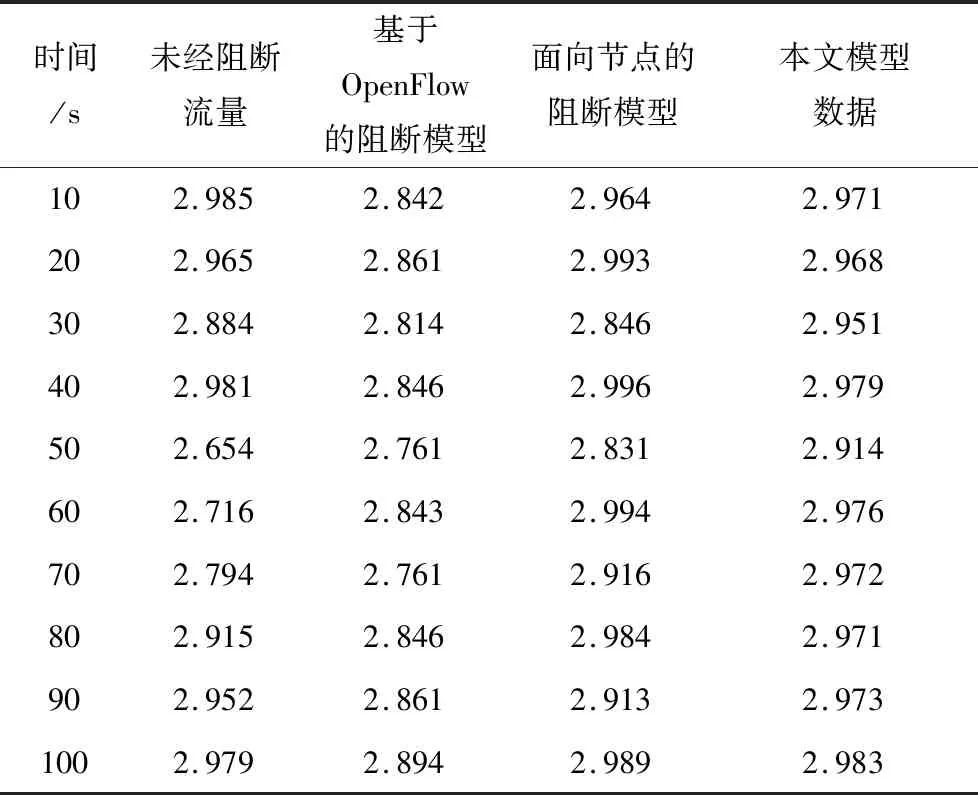
Table 5 Changes in entropy of destination address表5 目的地址的熵变化情况
4 结束语
本文针对无线传感网络攻击流量构建阻断模型,使用TF-IDF和随机森林算法对无线传感网络流量进行分类,识别正常流量和攻击流量,再使用溯源方法确定交换机的ID和端口作为攻击流量阻断的阻断点,通过过滤报文实现无线传感网络攻击流量的阻断。实验结果表明,本文模型在检测攻击流量时具有较高的准确率、精确率和召回率,调和平均数均在98.1%以上,检测率达到了100%,误检测准确率在7.56%以内,识别攻击流量的能力较强;在攻击流量阻断方面,本文模型能实现各类攻击流量的阻断,与同类型的模型相比具有良好的阻断效果,提升了无线传感网络的性能。
今后的研究可从多个角度展开:探索性能良好的控制器,进一步提高攻击流量监测的精确率;将无线传感网络节点微型化,实际应用于微无线通讯和微机电等领域;寻求节能策略,降低能耗,改进电源技术,提出一种低能耗的无线传感网络;节省节点,降低无线传感网络的成本,推动无线传感网络的发展。
猜你喜欢
传感技术学报(2022年7期)2022-10-19
今日农业(2022年15期)2022-09-20
内江科技(2021年8期)2021-09-13
无线互联科技(2021年4期)2021-04-21
小猕猴智力画刊(2019年3期)2019-04-19
电子制作(2018年23期)2018-12-26
电子制作(2018年23期)2018-12-26
亚太教育(2018年5期)2018-12-01
电子制作(2018年19期)2018-11-14
读者·校园版(2015年7期)2015-05-14
