
基于AI的无线网络感知技术研究综述*
2022-05-26 08:19章广梅
电讯技术 2022年5期
章广梅
(中国电子科技集团公司第七研究所,广州 510310)
0 引 言
随着5G逐渐步入商用阶段,无线网络面临着新兴业务应用需求快速增加、移动数据流量爆炸增长[1]、设备连接数海量等挑战。而未来网络终端类型变得多样化,业务类型愈加丰富,网络应用朝向多元化发展,网络性能更显差异化,用户需求也在不断提高。这些发展趋势促进了下一代移动通信新范式的研究。下一代移动通信的愿景可以概括为智慧连接、深度连接、全息连接、泛在连接[2]。
未来6G网络的发展趋势体现在:网络规模、终端设备、业务类型等更加复杂多样;网络管理更加智能化;通信场景范围扩大,信息交互需求的场景和类型也越来越复杂;网络连接对象活动范围扩展,需要更加深入的信息感知,对感知的实时反馈响应要求更高;通信接入地理空间扩展,更为广泛地随时随地连接。因此,在未来网络复杂化、多样化、广泛化的背景下,智能化管理需要对网络状态与业务需求等信息更加实时高效且准确地掌握。基于信息感知,有效收集处理与感知网络中产生的海量数据、获取网络管理需求信息(如终端种类、用户业务类型、信道状态、网络资源状态等)可以为后续网络配置以及资源调配与优化提供依据。
在此背景之下,传统的信息感知技术面临一些挑战:一是传统的信息感知技术往往针对具体的感知对象与网络设计相应的流程与算法,对专家的通信知识以及优化算法依赖度比较高;二是传统方法大多需要使用预先配置好的信息库,时效性差,且需要人工进行维护与扩展,成本比较高;三是未来多维度的网络资源与数据使得信息感知需要考虑的参数数量激增,传统方法将会需要巨大的通信和计算开销。
随着通信系统软硬件中的计算资源的增长,人工智能(Artificial Intelligence,AI)开始越来越多地被用于解决无线通信中的难题。其通过对数据进行收集、归纳、分析,从而获取目标信息,并利用这些信息为建立智能通信系统提供具有决策能力的模型。人工智能方法具有数据驱动性,能够从数据中学习隐藏的规律,并依据这些规律做出相应的预测或决策,可以在一定程度上打破专家通信知识的壁垒;具有自动控制能力,有效减少人工干预从而降低成本;具备强大的数据处理能力,有效缓解多维海量数据处理带来的计算压力。
信息感知的广义概念指通过获取客观事物的直接信息进行一些处理或分析,实现认知和理解的过程,主要目的是获取使用者需要却无法直接获取的信息[3]。在无线网络中,信息感知主要应用于终端、用户、业务、无线网络资源[4]与信道等方面。其中,终端感知主要目的为识别终端类型,用户感知则聚焦于用户位置与移动性、社会关系等,业务感知主要感知业务的种类和相关关键性能指标(Key Performance Indicator,KPI)等,无线网络资源感知主要感知网络吞吐量、能量消耗、频谱消耗、平均传输时延等,信道感知主要感知网络中信道实时状态与无线环境[5]。
传统的信息感知技术依据专家通信知识,根据感知对象与应用场景设计专用的流程与算法,例如业务感知中的端口识别方法、信道感知中的能量检测法等,对于通信过程中的直接数据使用特有的分析处理方法来实现目标信息的感知。基于人工智能的信息感知技术通过高效的算法挖掘数据中隐含的规律,总结出通用流程为数据收集、数据预处理、特征选择、样本划分、模型训练、感知测试、结果验证与评估。
1 基于AI的信息感知关键技术
信息感知关键技术往往与感知目标和感知对象密切相关,目前在无线通信中的感知研究多集中在终端感知、业务感知及信道感知,对终端类型、业务类型以及信道状态进行感知识别。在使用AI方法进行信息感知时,需要明确无线网络中感知对象具体类型的自身特性差异,分析感知对象的特征,针对具体的应用场景确定感知对象类型集合、采集参数种类、采集时刻选择、感知算法等。
1.1 终端感知
终端感知侧重于识别终端的类型、型号、身份等信息,对于终端感知的研究从终端的不同识别特征入手,提出不同的终端感知方法。终端的识别特征可以归类为设备特征、入网特征、通信特征、应用特征、行为特征[7]。
(1)设备特征为终端设备在生产制作后带有的全球唯一标识码,如国际移动设备身份码(International Mobile Equipment Identity,IMEI),与每台设备一一对应。
(2)入网特征是指获取入网许可的终端,在进入网络参与通信时携带的标识码,如国际移动用户识别码(International Mobile Subscriber Identity,IMSI)、接入点(Access Point Name,APN)等。其中,终端设备使用的SIM(Subscriber Identity Module)卡中存储着IMSI,而终端的SIM卡使用网络时需要标识网络数据的业务种类,会配置接入点名称,即参数APN,决定访问网络的方式。
(3)通信特征是终端在建立通信连接时使用的标识码,包括IP 地址/端口、域名等。
(4)应用特征是终端在使用业务应用的过程中产生的标识,如应用程序(Application,APP)、用户代理(User Agent,UA)[8]等。对于一些具有特殊性质终端,可以通过获取使用的APP名称识别终端,终端在使用浏览器业务时会向业务服务器提供UA,其中包括使用的浏览器类型及版本、操作系统及版本、浏览器内核等信息。使用UA识别终端需要预先建立UA库,通过解码UA进行匹配,获得相应终端信息。
(5)行为特征是指终端在网络中建立通信连接后各种行为体现的特征,包括终端运行时间、地理空间、网络流量等方面,不同的终端有其常用应用场景,因此行为特征呈现一定规律性,使用机器学习等方法挖掘行为特征的规律实现对终端类型的识别。
根据上述终端特征,常见的终端信息采集方式包括IMEI码、无线应用协议(Wireless Application Protocol,WAP)字段UA信息、内置客户端、机器学习等方法,各方法的优劣对比如表1所示,其中IMEI码和UA信息是常见的传统方法。IMEI码作为全球唯一的手机终端识别号,准确度高但需要获得厂商数据作为匹配依据,且存在易失效的问题[9]。根据移动通信中使用Internet的标准协议中的WAP标准,超文本传输协议(HyperText Transfer Protocol,HTTP)报文中的UA信息上的X-WAP-PROIMLE字段包含资源定位符(Uniform Resource Locator,URL)形式的字符串,可以唯一确定终端型号[8],但不同终端的报文常常存在不遵守标准格式的问题,甚至会出现UA残缺的情况。WURFL(Wireless Universal Resource File)是一个在网页服务器上实现终端识别的开源项目,通过预先建立包含终端信息的预定义配置文件,收集到的终端UA信息与之进行文本匹配,获取终端品牌和型号。文献[10]将机器学习方法应用于终端识别,结合终端IMEI,挖掘终端、用户与业务的行为信息,并利用这些特征生成终端唯一标示码。文献[11]提出了一种正样本反馈增强的正样本无标记(Positive-unlabeled,PU)学习方法,实现从海量设备中识别特定类型的物联网终端。
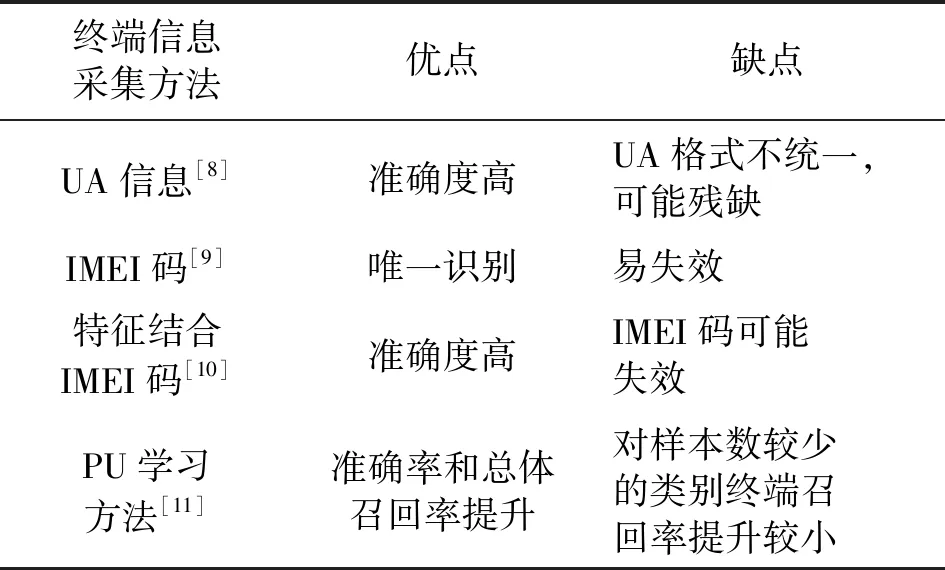
表1 现有终端信息采集方法对比表
随着移动通信的飞速发展,终端也进入了快速更新换代的阶段。而UA信息等传统感知方法对信息库依赖度高,更新速度慢,已经无法满足新兴终端的感知需求。为了突破上述限制,越来越多的研究通过采集终端网络流量,分析终端的行为特征(包括终端位置信息、业务信息等),使用机器学习分类算法实现对终端类型的识别。通用流程可以归纳为采集与存储目标网络流量、流量数据预处理、设备预分类、终端类型识别,如图1所示。
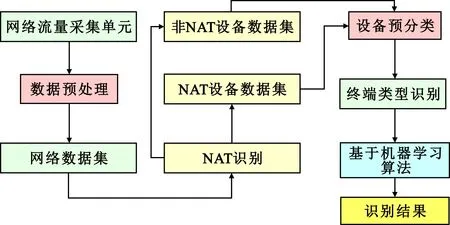
图1 基于人工智能的终端识别流程示意图
Step1 采集与存储目标网络流量[12]。在进行分析和挖掘之前,首先需要采集相关数据,并进行存储。网络流量的数据是以大量数据包的形式存在的。目前常用的网络流量采集工具有许多,如WireShark、Tcptrace、Tstat等。
Step2 流量数据预处理。由于网络流量采集的环境中往往包含非网络地址转换(Network Address Translation,NAT)设备与NAT设备,而两者在识别的过程中具有显著不同,具体体现在前者仅被识别为一个设备,而后者会被识别为一个或多个设备。因此,有必要预先将两者进行区分。
Step3 设备预分类。面对多种终端设备接入的网络环境,一些终端的网络流量表现出的特征可能大相径庭,因此可以进行初步的分析,对终端进行粗分类,为后期识别打下基础。
Step4 终端类型识别。基于机器学习算法,对网络数据集进行分析,获得终端类型识别结果。常见的算法包括支持向量机(Support Vector Machine,SVM)、朴素贝叶斯(Naive Bayes)、决策树(Decision Tree,DT)、随机森林(Random Forest,RF)等。对于有监督学习,需要做好明确标记的数据集,而在做标记前必须明确网络终端类型等所需属性,形成数据库。终端类型识别流程如图2所示。
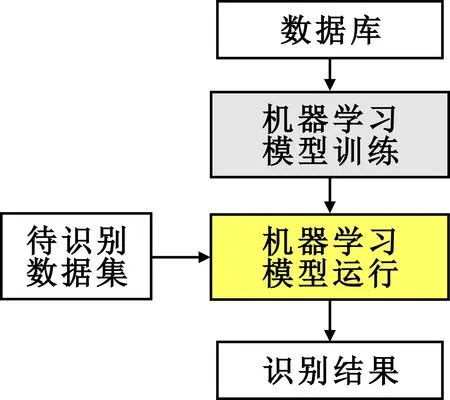
图2 终端类型识别流程示意图
文献[13]使用C4.5决策树算法进行终端识别。文献[14]提出基于多粒度的分词方法结合 TF-IDF(Term Frequency-Inverse Document Frequency)关键词获取算法形成过滤技术,之后引入Jaccard相似系数应用于终端识别,获取终端设备型号信息。文献[15]给出了随机森林算法进行网络终端识别分类的一般方法。文献[16]提出一种利用深度学习中的CNN算法对终端库进行自动化更新。基于人工智能的终端识别模型与传统终端识别方法的性能对比如表2所示。
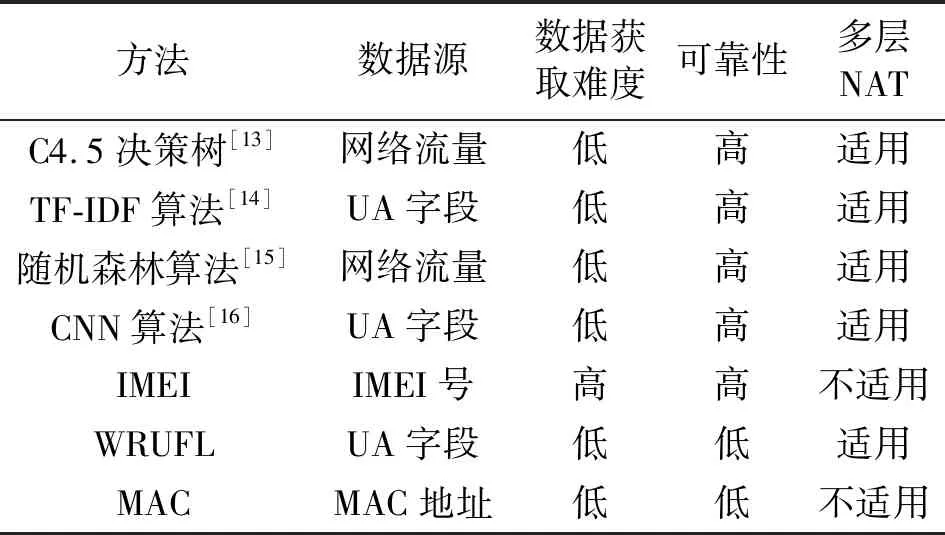
表2 终端感知算法性能对比表
几种基于人工智能的终端识别模型之间的性能对比如表3所示。
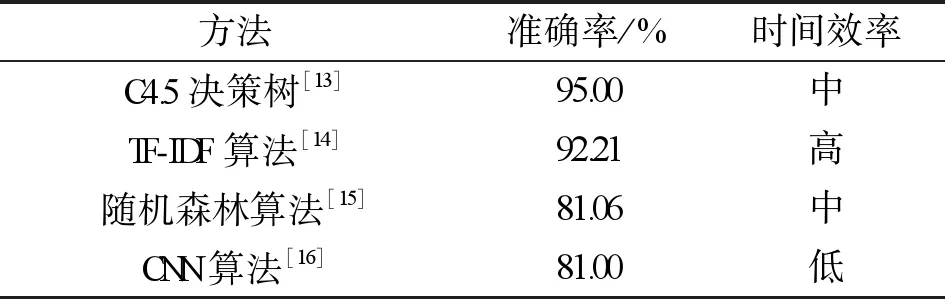
表3 人工智能终端识别模型性能对比表
由表3可知,C4.5决策树的准确率最高,TF-IDF 算法的准确率低于C4.5决策树,但高于其余两种模型。同时,TF-IDF算法的时间效率更高,可以更快地适应不断变化的操作系统。
相比于传统的终端识别方法,基于人工智能的终端识别模型可以提高可靠性,同时在保证高可靠性的前提下降低数据的获取难度,并且均适用多层NAT。然而,基于人工智能的终端识别模型过分依赖预先建立的特征库,终端的特征属性随时间会产生一定的变化,需要定期对模型进行训练与更新。如何高效地建立并更新特征库,是以后人工智能应用在终端识别领域时要考虑问题。
1.2 业务感知
业务感知方面主要是指对于业务类型的识别,一般通过分析网络流量实现业务种类的分类识别。根据TCP/IP协议,网络中的数据包会按照五元组[源 IP地址、源端口号、目的 IP 地址、目的端口号、协议类型]组成相应的有序排列,大量如此的数据包即组成了网络流量[17]。网络数据流反映网络应用的实际使用状态,包含空间、时间、技术指标三类重要的信息。
根据分析的层次深浅,可将网络流量特性分为微观特性与宏观特性。其中,宏观特性是指网络流量在一段较长时间内的直观变化趋势体现的特征,包括自相关性、周期性等;微观特性是指对网络流量进行深层次分析,可以提取到通信中使用的网络协议、源端发送与目的端口接收的数据包数目、上下行数据包数目等信息。分析网络流量的微观特性对业务感知的意义重大。目前对网络流量特征的统计达到了256种[18],其中数据包大小及其分布特性、包到达时间间隔相关特征、上下行字节数之比、下行字节速率等特征在网络流量统计特性中较为重要。
目前常见的基于网络流量的业务感知方法主要有端口识别方法、基于有效载荷的识别方法、基于机器学习的流统计特征识别方法三种。在网络中,每一类网络应用都有一个固定的端口号,是由因特网分配号码管理局为其分配的。使用某一网络应用时,网络流量会传输至相应端口,端口识别方法通过获取网络应用对应的协议类型识别应用类型[19]。随着网络应用的增多,不再使用固定的端口进行流量传输,端口识别法不再适用。为了应对业务种类繁多带来的挑战,业界提出了基于净荷特征的识别方法。首先建立网络应用的有效载荷的特殊签名数据库,利用深度包检测(Deep Packet Inspection,DPI)技术读取网络流量IP数据包中的载荷内容,进行深度解析与匹配,从而实现业务的识别[20]。该方法的准确性高,但实际应用中有效载荷的特殊签名数据库的建立需要使用大量人力根据经验和知识进行手动录入,而通信协议变化时需要对签名库进行及时更新。对于加密流量,没有固定的特殊字段,且不能侵犯用户隐私,有效载荷法与DPI技术皆不再适用。因此,越来越多的研究者从网络流量的流统计特征着手,使用机器学习算法进行分类,从而实现业务感知。网络业务流的统计特征包括数据包的最小、最大长度及均方差、数据包的上下行时间长度、某方向上的数据包的总长度等[21]。许多机器学习模型如决策树[22]、朴素贝叶斯[23]、支持向量机模型等都可以作为业务识别的基础分类器。
根据使用的机器学习方法有监督与半监督之分,其业务感知的流程分别如下所述。
(1)有监督学习
流程包括网络流量数据样本采集、特征过滤和特征选择、样本划分、分类模型训练、业务识别测试与结果验证,如图3所示。
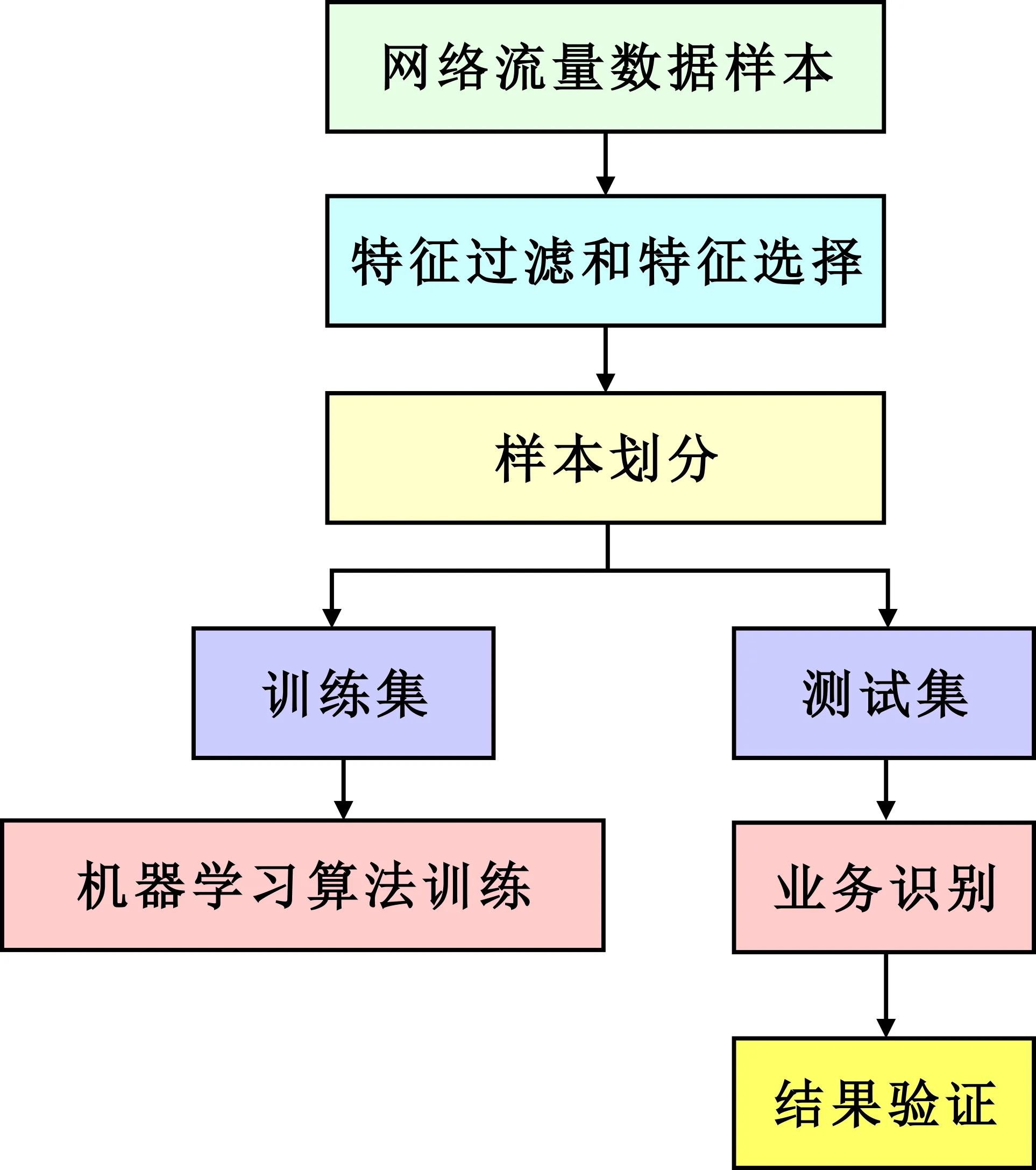
图3 有监督学习的业务感知流程示意图
(2)半监督学习
流程包括网络流量数据样本采集、通过五元组切分将数据分为有标签数据以及无标签数据、特征提取、通过半监督模型进行业务感知,如图4所示。
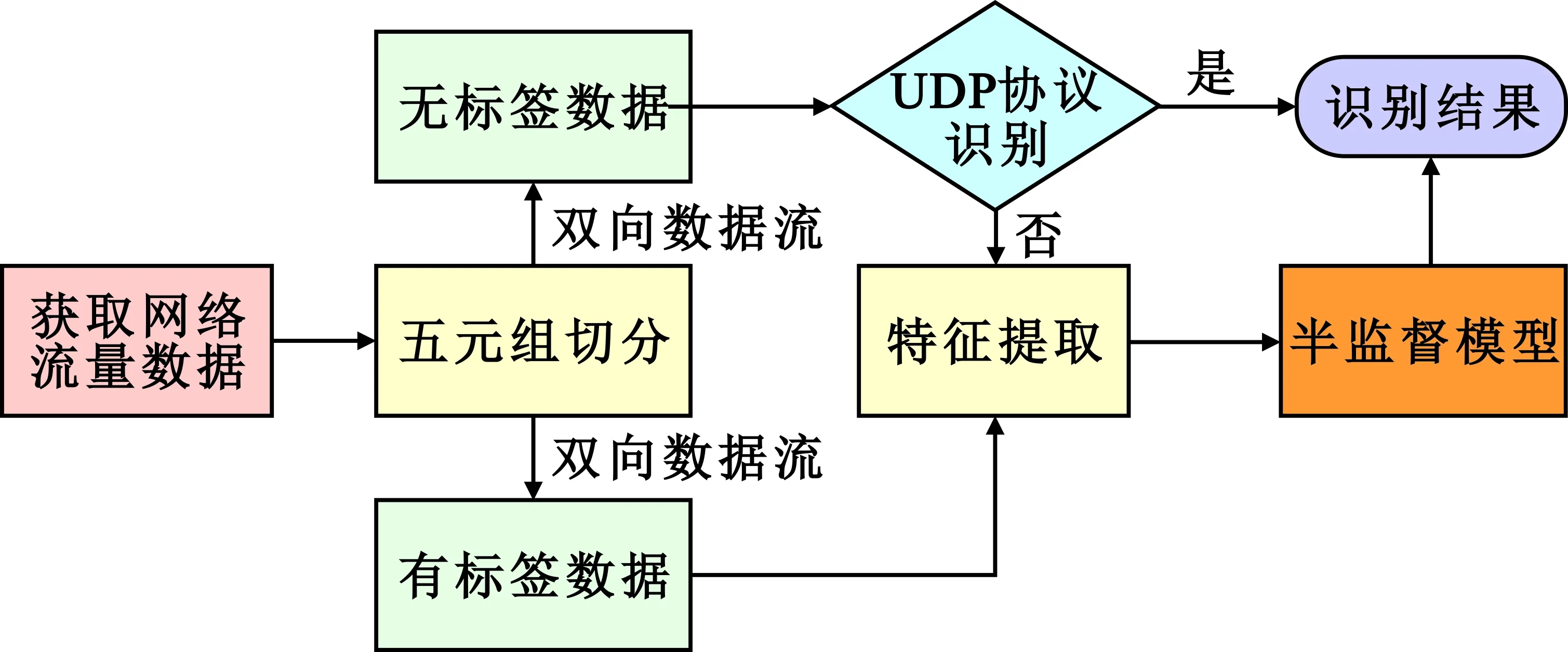
图4 半监督学习的业务感知流程
在对网络流量进行业务感知的过程中,采用单一的分类器进行识别容易产生错误的分类预测结果或者过度拟合。集成学习(Ensemble Learning)是通过结合若干个弱分类器来做出决策的一种思想,进而得到一个更加全面的强监督模型,以达到减小方差和偏差的效果。集成学习一般包括并行集成方法和序列集成方法。并行集成方法使用多个弱分类器独立预测,并为其分配权重,将预测结果进行并行集成,显著降低错误率,其流程如图5所示。序列集成方法则是将多个基础分类器串联迭代训练,增加误差小的基础分类器权重,决策准确性优于并行集成方法,但其复杂度较高,训练时间长。
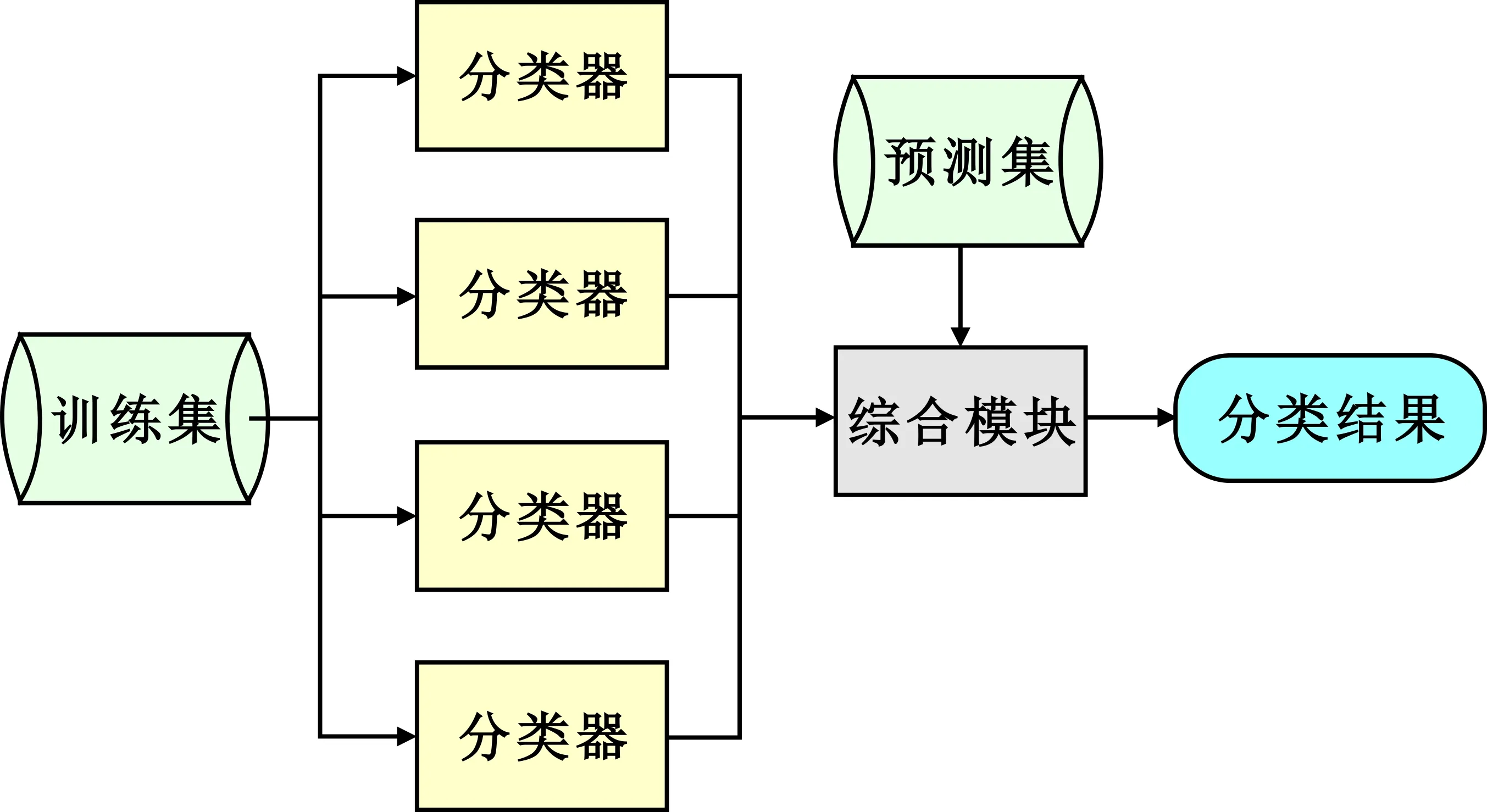
图5 并行集成学习流程示意图
基于序列集成决策树算法进行业务感知,能够有效提高单决策树分类性能。梯度提升树(Gradient Boosting Decision Tree,GBDT)以分类与回归树(Classification and Regression Trees,CART)作为基分类器,通过多决策树分类器串联来共同决策。每棵决策树通过学习前面决策树的训练结果和误差,在损失函数下降的方向生成新的决策树模型,进而进行下一步残差拟合,其模型如图6所示。
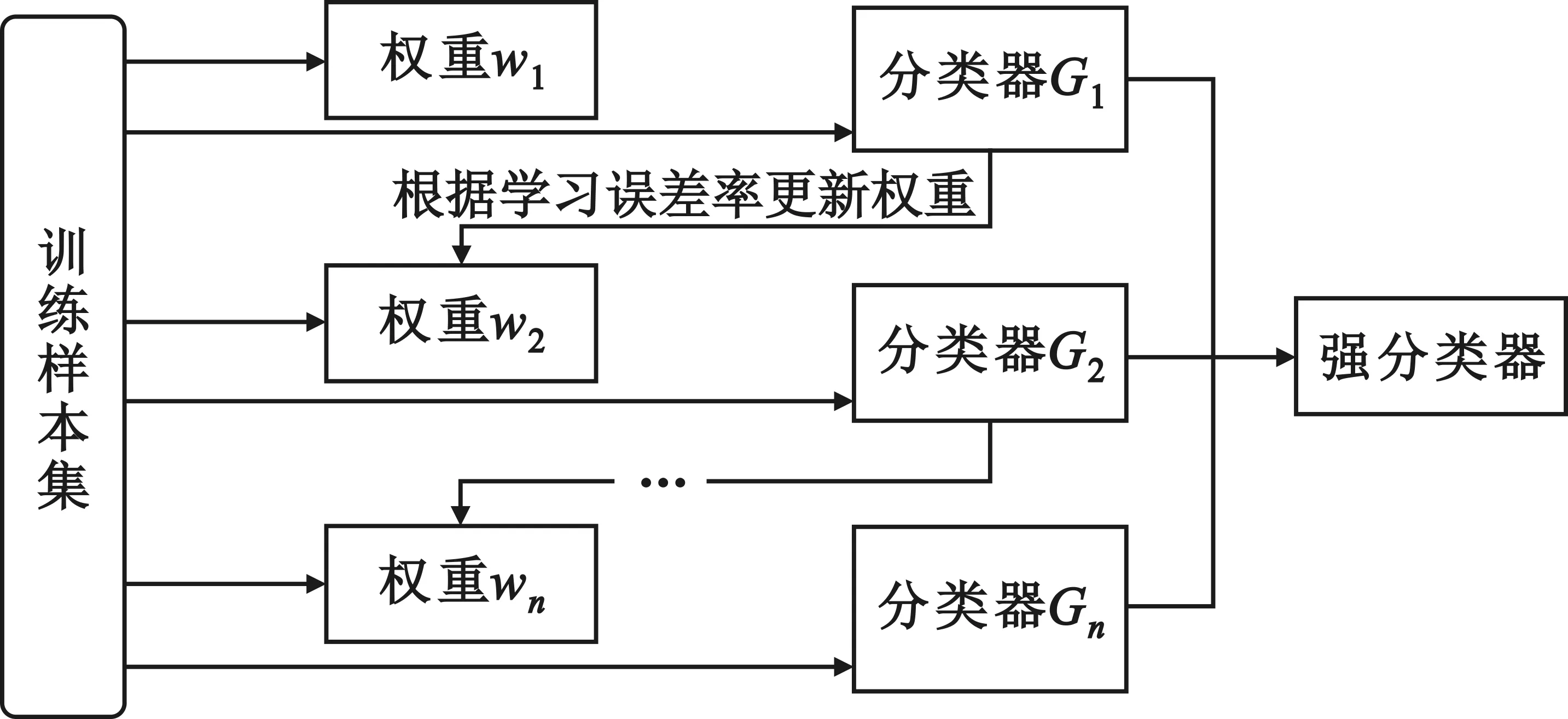
图6 GBDT模型
序列集成决策树算法的主要流程包括网络流量数据样本采集、特征过滤和特征选择、样本划分、XGboost算法训练、业务感知、结果验证等。
Step1 网络流量数据样本采集。实际应用中可能无法自行获取流量数据,可以采用目前已有的公开网络业务流量数据集,如剑桥大学的Moore数据集,其涵盖WWW、Mail、FTP、P2P、Multmedia、Attack等业务类型的数据,分为E1~E10 10个子数据集。
Step2 特征过滤与特征选择。从每个特征类簇中选择最具代表性的特征形成约简特征子集。采用混合式特征选择方法,首先对特征的重要性度量值进行降序排序,从序列的末尾向前依次删除重要性最低的几个特征,逐次迭代并计算分类精度,最终以分类精度最高的那次迭代所对应的特征集作为最优的特征选取结果。
Step3 样本划分。将获得的数据按比例划分,部分用于训练模型,部分用于测试模型和进行性能评估。
Step4 XGBoost算法训练。使用训练集数据对XGBoost模型进行训练。
Step5 业务感知。使用测试集对模型进行业务感知测试。
Step6 结果验证。根据测试结果,对比原数据集信息,对算法准确率和召回率进行计算。
随机森林算法是一种利用多棵树对样本进行训练并预测的一种分类器。文献[24]提出使用快速正交搜索(Fast Orthogonal Search,FOS)算法从来自数据的大量特征中选择具有判别能力的特征子集,然后使用K-最近邻(K-Nearest Neighbor,KNN)分类器利用 FOS 选择的特征对网络流量进行分类,即FOS-KNN算法。文献[25]提出了一种基于Keras深度学习框架的卷积神经网络(Keras Convolutional Neural Network,K-CNN)算法进行业务识别。XGBoost算法与上述三种算法的性能比较如表4所示。
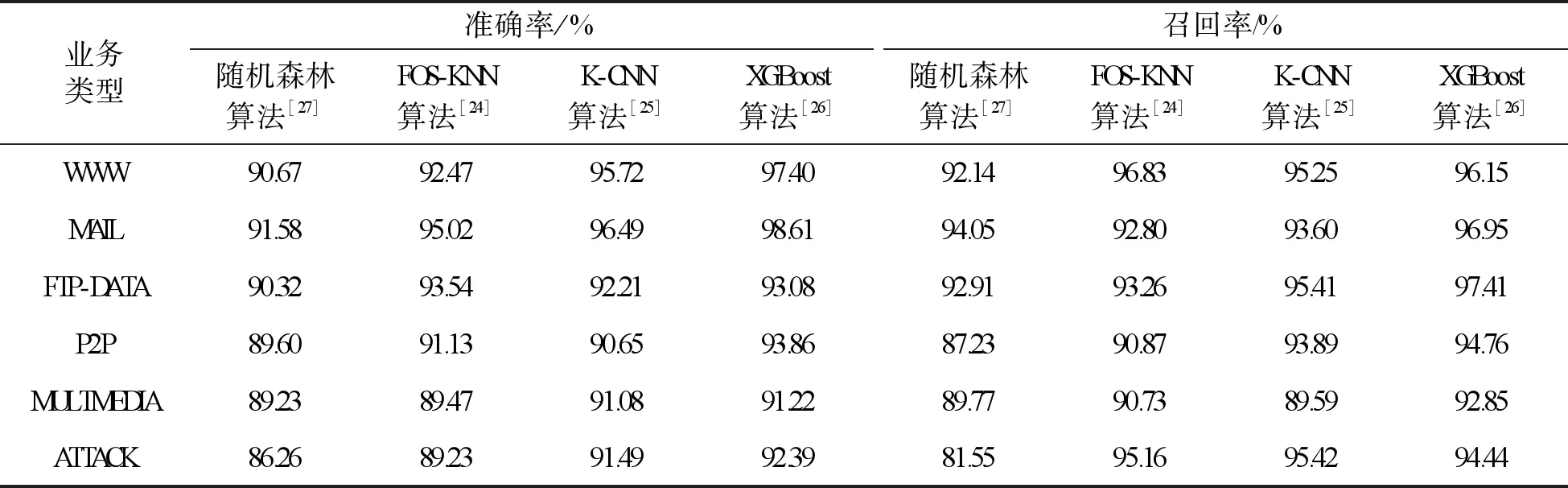
表4 不同算法的业务识别准确率和召回率对比表
从表4可以分析出,相较于其他算法,XGBoost算法在绝大部分业务类型下拥有最高的准确率与召回率,而随机森林算法的准确率与召回率低于其他算法。因此,使用XGBoost算法可以有效提高业务识别的准确率。
文献[27]比较了随机森林、线性判别分析和深度神经网络这三种不同的机器学习算法在网络业务分类时的性能,结果表明,在正常的网络场景下,线性判别分析的准确率最高,深度神经网络的准确率最低。文献[28]提出了一种基于卷积神经网络的深度学习模型,将业务分类问题转化为图像分类问题,通过对图像进行分类达到业务分类的目的。
上述方法属于有监督学习方法,实际使用中需要人工标注数据集,故需要较高的人力成本。考虑到基于少量数据标签的半监督学习可以减少数据集标注工作量,文献[29]提出了基于自步学习的协同训练模型,将有标签数据逐步通过标注伪标签的方式,扩大训练数据集并构建半监督模型。然而该方法由于在标注伪标签时仅考虑损失函数最小(即置信度)的原则,导致模型在迭代训练过程中两视角的差异性越来越小,无法保障多视角协同增益原则,即在保证置信度的前提下各视角提供了其他视角所不具备的信息。因此,该模型的识别性能在迭代过程中会因为差异性条件无法满足而受限。为了解决自步协同训练模型在训练过程中因视角差异性减小而导致的模型性能受限的问题,文献[30]提出了一种基于模糊度评估的自步协同训练模型,基于少量标注数据的半监督学习模型实现业务感知,在置信度选择框架下引入模糊度选择机制,每一轮训练中综合考虑置信度高和模糊度差异大的样本,以满足协同训练结构有效性的两个先决条件,在增加数据多样性的同时提升模型的容错性能。
协同训练是一种较为经典的半监督模型,首先通过将原始数据分成两个数据子集,称之为视角(View);其次针对两个视角下分别训练模型,并交叉地给另一视角的无标签数据打伪标签[31],利用两个视角的协同增益,即视角的一致性与差异性,提升模型性能。而自步协同训练则是在协同训练框架中进一步引入了自步学习方式来标注伪标签,如图7所示。自步学习的核心思想是对模型的迭代过程,每次倾向于选择所有样本中具有训练误差较小、置信度高的样本[29]。
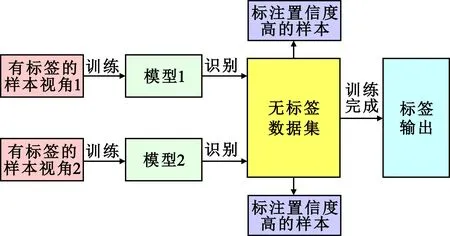
图7 自步协同训练模型
文献[30]首先把不同业务的数据过滤出来,将问题转化为半监督的分类问题。具体步骤如下:
Step1 数据预处理。使用数据抓取软件从代理服务器上抓取原始网络流量数据,使用五元组将数据切分成双向数据流,每一条流中包含的数据包属于同一类型业务。
Step2 协议识别。通过用户数据报协议(User Datagram Protocol,UDP),识别出无标签数据中的视频请求和语音请求两类,之后将无标签的数据与已经通过人工标注的包含四种类型(视频、图片、位置、其他)的有标签数据整合。
Step3 特征提取。对于整合的数据,提取其时间间隔、数据包的包长以及其组合作为特征,若数据有标签则用于训练,无标签数据用于测试。
Step4 构建半监督模型。训练基于模糊度的自步协同训练模型,为无标签的数据生成标签。
Step5 业务类型识别。使用训练好的半监督模型对测试集进行测试,获取识别结果。
综上,基于人工智能的业务感知主要解决的是加密应用的流量识别问题。由于加密流量没有固定的特殊字段,且不能侵犯用户隐私,传统的基于端口或有效载荷的识别方法不再适用。因此需要研究如何利用人工智能,根据网络流量特征来识别业务。从目前的研究结果可以看出,各人工智能算法的分类性能非常好,准确率均高于90%。然而,各人工智能算法都需对数据进行复杂的训练,并且无论是监督学习还是半监督学习都需要对样本进行标注,这增加了业务感知的时间成本与难度。因此,未来更需要研究的是如何降低训练成本并且使用无监督学习的方式进行智能业务感知。
1.3 信道感知
信道感知主要感知网络中信道实时状态与无线环境,常用在认知无线电研究中。从感知用户数量划分,信道感知可以划分为单用户感知与多用户协同感知。单用户感知中,物理层感知通过检测信号寻找频谱空穴,对媒体介入控制(Media Access Control,MAC)层感知的研究多集中在提升系统的感知效率以及感知周期和调度的优化。多用户协同感知可以有效解决单用户感知中阴影、多径等因素的影响,将多用户的数据融合在公共处理节点,再进行感知,可分为集中式和分布式。具体地,集中式协作感知系统中设立数据融合中心,接收各用户传输的数据进行相关处理并得到目标判决结果,再传输至各用户;分布式协作感知系统中,各用户自行进行本地感知,用户之间进行数据交换共享感知结果,再使用合适的分布式迭代算法来获取系统感知结果。
传统的物理层频谱感知算法包括能量检测、匹配滤波检测、循环平稳特征检测等。近年来对于频谱感知的研究逐渐与人工智能方法相结合:例如基于多层感知器神经网络的频谱感知,文献[32]提出了基于隐马尔科夫模型的频谱感知并进行了改进,文献[33]提出了基于强化学习的动态频谱感知与接入,文献[34]研究了大数据认知无线电系统,显著提高了感知性能。文献[35]提出了一种基于深度神经网络与卡尔曼滤波的信道感知算法,文献[36]分别介绍了基于深度卷积神经网络、基于深度循环神经网络、基于超分辨技术、基于压缩感知技术的信道估计。
不同的人工智能算法中,深度卷积神经网络的特点是多子网联合、稳健性强、计算复杂度高,更适用于毫米波大规模多输入多输出(Multiple-Input Multiple-Output,MIMO)系统。深度循环神经网络聚焦信道状态信息(Channel State Information,CSI)时间相关性、长短期记忆(Long-Short Term Memory,LSTM)网络,适用于时变信道及高速移动场景。超分辨技术依赖图像去噪算法,稳健性较差,适用于正交频分复用技术(Orthogonal Frequency Division Multiplexing,OFDM)通信系统。压缩感知技术拥有复杂的去噪器设计,适用于毫米波大规模 MIMO 系统。
多用户协作频谱感知分为本地感知和融合感知两大部分,通用流程如下:各个用户分别进行本地频谱感知,将感知结果发送给融合中心;融合中心收集各个用户的感知结果,采用一定的融合准则对接收到的感知结果进行综合处理,做出最终的判决,并将判决结果传输给各个用户[30]。
下面介绍一种基于神经网络实现的协作频谱感知方法,主要流程如图8所示。
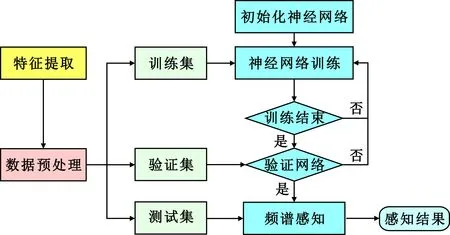
图8 基于神经网络的频谱感知流程
Step1 特征提取。根据融合中心接收到的信号样本,计算用于频谱感知的特征以及各接收信号的统计量,降低维度。
Step2 神经网络初始化。初始化权重参数w和各神经元阈值b,并且设定神经网络的终止条件,即训练误差的阈值及最大训练次数。
Step3 样本划分。将特征提取后获得的数据按比例随机划分为训练集、测试集和验证集。
Step4 神经网络训练。迭代训练直至满足设定的终止条件,即达到最大训练迭代次数或误差小于预设阈值。
Step5 模型验证。通过验证集的特征数据对神经网络性能进行验证,判断其是否存在过拟合,并根据网络的表现情况调整神经网络,选择泛化性能最好的神经网络,返回最佳的神经网络参数。
Step6 频谱感知。选择上一步得到的最佳的神经网络,使用测试集进行频谱感知性能测试。
2 未来挑战
未来无线网络在规模、复杂度、终端种类、应用种类各方面都将日益扩大,信息感知技术也需要向更加高效的方向发展,信息感知技术未来面临海量数据、系统能耗、复杂应用场景、隐私与安全四个方面的挑战。
(1)海量数据
未来网络密集分布的网元、节点等会产生海量的感知信息,在基于人工智能的信息感知过程中常使用有监督学习,虽然准确度较高,但是会依赖预先建立的识别库。随着网络规模的扩大,终端类型、业务类型等感知对象的种类必然经历不断发展与扩充的过程,因此该方法会受制于数据库的有限性和时效性。此外,面对海量的无标签数据,有监督学习的数据集标记工作需要投入一定的人力,带来了成本问题。
(2)系统能耗
面对网络中的海量数据,长期频繁的数据收集与处理会增加系统能耗,而有些节点或终端存在能量有限的情况。为了实现长期稳定的感知,减少感知过程的能耗,或者在感知能耗与感知效率之间取得平衡在未来也是挑战。
(3)复杂应用场景
6G将引入空天地海一体化网络和无线触觉网络,更加丰富的应用场景使得网络拓扑以及节点的移动性趋向复杂,因此信息感知时对节点的移动性需要动态把握,此时网络状态的不稳定、网络拓扑结构的动态变化都会对数据收集等带来挑战。
(4)隐私与安全
随着信息感知技术的普遍应用,需要获取的信息范围也逐渐变大,存在侵犯用户隐私的风险。信息感知技术还有可能应用于军事、金融等领域,从而引起信息安全问题。因此,数据加密、密钥管理、安全协议、隐私管理等都是信息感知技术未来可能面临的挑战。
3 结束语
本文讨论了无线网络中的人工智能感知技术,包括信息感知的基本原理与关键技术,并概述了未来信息感知技术面临的挑战。随着6G智慧连接、泛在连接的发展,网络规模、终端种类、业务类型等都在不断扩大,信息感知技术也不再局限于感知能力有限的传统专有方法,转而与蓬勃发展的人工智能方法结合,以实现从无线网络的海量数据中分析提取所需信息的目标。
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
淮阴师范学院学报(自然科学版)(2022年3期)2022-09-22
舰船科学技术(2022年10期)2022-06-17
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
北京航空航天大学学报(2021年9期)2021-11-02
现代装饰(2020年8期)2020-08-24
微型电脑应用(2019年8期)2019-08-22
当代陕西(2019年10期)2019-06-03
电子制作(2018年23期)2018-12-26
北京航空航天大学学报(2017年7期)2017-11-24
