
基于改进YOLO V4 的桥梁缆索表面损伤识别方法
2022-05-24 11:44:18邹易清苏建功夏晓华李玉强蒋立军韦耀淋
电子设计工程 2022年10期
邹易清,苏建功,夏晓华,李玉强,蒋立军,韦耀淋
(1.柳州欧维姆机械股份有限公司,广西 柳州 545006;2.长安大学道路施工技术与装备教育部重点实验室,陕西 西安 710064)
桥梁中的缆索是关键受力构件,在悬索桥、拱形桥和斜拉桥等大跨度桥梁建设中应用广泛。一旦缆索表面出现损伤,在缆索拉应力及长期风吹日晒的作用下,损伤日趋严重,致使雨水渗入缆索内部,引发缆索内部钢丝锈蚀和锈断,严重威胁桥梁安全。因此,及时、准确的缆索表面损伤识别,对有效预防桥梁事故的发生具有重要意义[1]。
当前,国内外对桥梁缆索表面损伤的识别主要通过人工检测[2]完成,检测过程存在一定的主观性且效率低。激光扫描法[3]能实现自动检测,但成本高,难以推广应用;文献[4-5]利用机器视觉技术进行检测,然而当图像存在色差等问题时检测结果不佳。随着计算机视觉与深度学习的发展,深度卷积神经网络在诸如板裂纹[6]、桥梁与路面病害[7-8]等表面缺陷[9]检测中体现出巨大的优越性。文献[10]利用Faster R-CNN 卷积神经网络实现了缆索表面损伤类型及区域的识别,但目前这方面的文献较少,基于深度学习的缆索表面损伤识别方法仍需进一步研究。
鉴于YOLO V4(You Only Look Once V4) 模型[11]在目标识别中具有良好的性能,文中在其基础上开展桥梁缆索表面损伤自动识别与定位研究。为提升网络的特征提取能力,在YOLO V4 模型结构中嵌入注意力机制模块,从而提高缆索表面损伤的识别精度,实验验证了该方法的有效性。
1 桥梁缆索表面识别方法
基于深度学习的目标检测模型能对图像中的物体进行快速准确的识别和定位,相较于Mask RCNN[12]、Faster R-CNN[13]等两阶段(two-stage)目标检测模型,YOLO V4 作为典型的单阶段(one-stage)目标检测模型,经过单次检测即可直接得到目标的类别概率和位置坐标值,具有良好的检测速度和精度。文中提出的桥梁缆索表面损伤识别方法基于改进的YOLO V4 目标检测模型,其流程如图1 所示,主要包括4 个步骤。
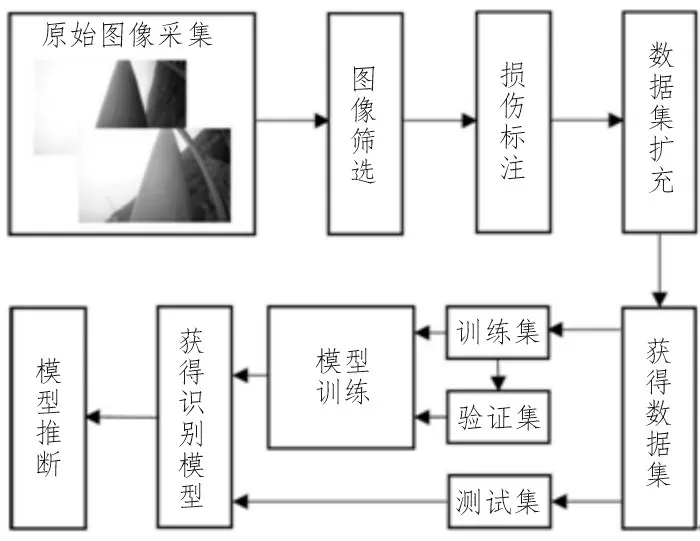
图1 桥梁缆索表面损伤识别方法流程图
1)原始图像采集:通过缆索爬行机器人拍摄桥梁缆索表面图像。
2)数据集制作:包括图像筛选、损伤标注、数据集扩充及获得数据集。筛选图像,通过数据增强方法扩充样本数量。
3)模型训练:改进YOLO V4 模型,调整模型参数,使用数据集进行模型训练,获得识别模型。
4)模型推断:利用识别模型作出预测,输出识别结果。
2 数据集制作
桥梁缆索图像的采集地点为江西省某大桥,使用缆索爬行机器人完成图像采集,挑选缆索表面出现损伤的图像共201 张,图像分辨率为1 920×1 080像素。
对深度学习而言,准备的数据越充足、越全面,训练得到的深度学习网络模型识别效果越好。当数据量不足时,可采用数据增强的方法扩充数据集。数据增强不仅可以增加训练的数据量,提高模型的泛化能力,也能通过增加噪声数据,提升模型的鲁棒性。通过旋转、镜像、亮度改变、添加高斯噪声等单一方法或多种方法结合的物理变换对图像进行数据增强[14-15],最后获得2 995 张图像作为数据集,并使用图形图像注释工具LabelImg 对每张图像中的桥梁缆索表面损伤进行标注。随机选取数据集中的90%(2 695 张)作为训练集,10%(300 张)作为测试集,在训练集中任意选取10%(270 张)作为验证集。
3 改进YOLO V4模型
YOLO V4 目标检测模型在YOLO V3 目标检测模型的基础上,对主干特征提取网络(Backbone network)、加强特征提取的颈部网络(Neck network)和预测输出的头部网络(Head network)进行改进。在主干特征提取网络中,利用CSPNet 结构(Cross Stage Partical Network)构造了CSPDarknet53,可以在降低计算量的情况下保持甚至提高网络的性能。此外,CSPNet 结构中引入了Mish 激活函数,Mish 激活函数是光滑函数,具备较好的泛化能力,对结果也有优化作用。在颈部网络中,使用了SPP(Spatial Pyramid Pooling)结构和PANet(Path Aggregation Network)结构。在对CSPDarknet53 网络输出的最后一个特征层完成3 次卷积操作后,利用SPP 结构中4 个不同尺度的最大池化层进行处理,可以极大地增加感受野,分离出最显著的上下文特征,且几乎不会降低网络的处理速度。PANet 结构的使用能够准确地保留空间信息,有助于正确定位像素点,形成mask。
在深度卷积神经网络处理图像时,使网络自适应地注意重要、有用的目标信息,可以提高最终模型的识别准确率。SENet[16](Squeeze-and-Excitation Networks)是一种通道卷积注意力机制模块,通过学习的方式自动获取每个特征通道的重要程度,以此来提升有用的特征并抑制无效特征,进而加快特征处理的速度。SENet模块结构如图2 所示。
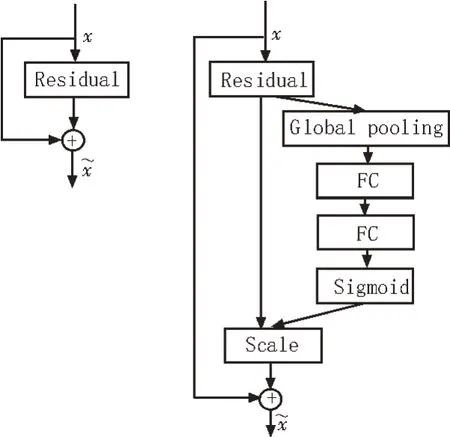
图2 SENet模块结构
SENet 模块首先对输入进来的特征层进行全局平均池化(Global pooling),然后利用两个全连接层(FC)先降低特征层维度而后升高至原来维度,最后经过Sigmoid 激活函数处理后便获得了输入特征层各个通道的权值,通过将权值与原输入特征层相乘的方式对每个特征层进行加权,以此处理不同重要程度的特征层[18-19]。
SENet 模块并不是一个完整的网络,可以灵活嵌入到分类或目标检测网络中。如图3 所示,将SENet模块嵌入到YOLO V4 模型主干特征提取网络层的3 个有效特征层中,同时在PANet 结构中将两个上采样后的结果添加到SENet 模块,增强网络的特征提取能力。图3 中Conv 表示卷积(Convolution),BN 表示批量正则化(Batch Norm),Concat 表示特征融合(Concatenation),UpSam 表示上采样(UpSampling),DownSam 表示下采样(DownSampling)。

图3 嵌入SENet模块的YOLO V4模型结构
4 模型的训练与测试
实验在台式计算机上完成,利用Tensorflow 以及Keras 框架来改进YOLO V4 模型。实验环境如表1所示。

表1 实验环境
为减少模型的训练时间以及使模型更好地收敛,采用迁移学习的方法训练模型。在模型训练过 程中,先冻结主干特征提取网络层,将更多的资源用
4.1 实验环境与网络训练
于训练后半部分网络,训练一定代数后,解冻主干特征提取网络层,并采用预训练好的COCO 分类网络模型的参数作为主干特征提取网络层的初始权重值,继续对全部网络进行训练,直至得到最终的模型,利用这种训练方式可有效保证权值。
设置合适的训练参数是提升识别模型性能的重要手段。训练图像尺寸设为800×800 像素,在使用预训练参数时,设置模型的迭代次数(Epoch)为50次,批处理的数据集样本数量(Batch size)为8,基础学习率(Base learning rate)为0.001;不使用预训练参数时,设置模型的迭代次数为70 次,批处理的数据集样本数量为2,基础学习率为0.000 1,总迭代次数为120次。学习率采用余弦退火策略进行调节,每5轮重置基础学习率,基础学习率最小值设置为0.000 01。在训练集上每完成一个Epoch,保存一次权值参数,模型训练结束后共得到120 个模型权值参数,以此评价训练模型的性能。训练集损失值曲线如图4所示。
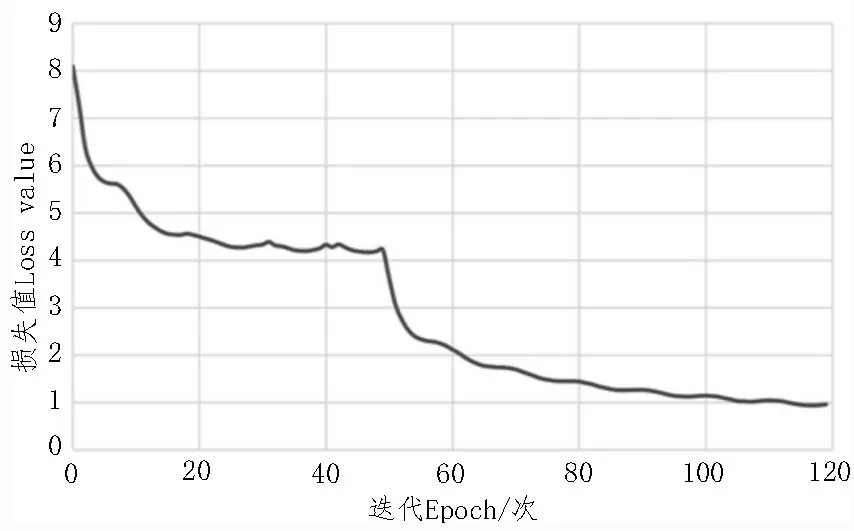
图4 损失值随迭代次数变化曲线
训练模型时,选用Adam 梯度优化器,其超参数beta_1 设置为0.9,beta_2 设置为0.999,利用Keras 框架中的提前终止法(Early stopping)来防止过拟合,在每一个Epoch 结束时,计算模型在验证集上的损失值,若损失值不再下降,则停止训练。
在前50 代训练中,训练集损失值虽有一定震荡,但整体呈现持续下降趋势;第50 代训练时,由于解冻训练致使训练集损失值突然下降,在后续的训练过程中,损失值缓慢变小直至几乎不发生变化,模型收敛。
4.2 模型测试结果与分析
采用SSD[17]模型、Faster R-CNN 模型、原始YOLO V4 模型和在颈部网络融入注意力机制的YOLO V4模型对测试集图像进行识别,识别效果如图5 所示,图中白色矩形框为模型检测出的表面损伤,椭圆形框和平行四边形框为漏检的表面损伤,虚线矩形框为误检的表面损伤,黑色矩形框为局部放大区域。由图5 可知,SSD 模型对桥梁缆索表面损伤的检测效果较差,易出现漏检的情况(图中椭圆形框)。在图5(a)、5(b)中,Faster R-CNN 模型虽能正确识别出损伤,但存在误检问题(图中虚线矩形框)。在图5(b)中,YOLO V4 模型对小目标存在漏检问题(图中椭圆形框)。在图5(c)中,YOLO V4 模型对其中的一处损伤识别正确但仅识别出某一小部分,图中平行四边形框中的损伤未能识别出来。融入注意力机制的YOLO V4 模型则能准确识别出桥梁缆索表面损伤,具有较高的识别准确率和良好的泛化能力。

图5 不同模型的识别结果对比图
为客观评价训练所得模型对缆索表面损伤的识别效果,通过计算预测图像的平均精度和平均检测时间来评价训练后的模型,其中,平均精度是以召回率(R)为横坐标、精确率(P)为纵坐标建立的PR 曲线的线下面积,平均检测时间为检测一张图像所需的平均时间,平均精度的计算公式为:

式中,r为积分变量,P(r)为P-R 曲线函数表达式。利用SSD 模型、Faster R-CNN 模型、原始YOLO V4 模型和融入注意力机制的YOLO V4 模型对缆索表面损伤进行识别的客观评价结果如表2 所示。为保证实验结果的公平性,每个模型的训练图像尺寸均为800×800像素,迭代次数一致。原始YOLO V4模型和融入注意力机制的YOLO V4 模型使用上节给出的超参数,并分别对SSD 和Faster R-CNN 模型设置合适的超参数,在相同的实验环境下采用相同的训练方式进行训练,如迁移学习、优化器等。
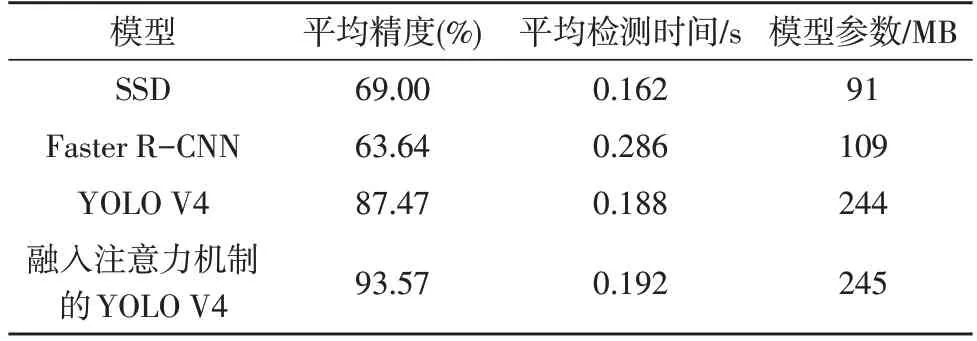
表2 不同模型对桥梁缆索表面损伤的识别结果
从表2 中可以发现,融入注意力机制的YOLO V4 模型相较于原始的YOLO V4 模型,缆索表面损伤识别的平均精度高出6.10%,平均检测时间仅增加了0.004 s;与SSD 模型相比,虽然平均检测时间有所增加(增加了0.030 s),但平均精度高出24.57%,识别效果显著提升;与Faster R-CNN 模型相比,在平均检测时间减少(减少了0.094 s)的同时,平均精度高出29.93%,表明改进的YOLO V4 模型在缆索表面损伤识别中明显优于现有文献使用的Faster R-CNN模型。因此,在颈部网络部分嵌入注意力机制的YOLO V4 模型能有效提升桥梁缆索表面损伤的识别精度,其识别精度明显高于SSD 模型和Faster R-CNN模型。虽然改进的YOLO V4 模型在平均检测时间上略高于原始YOLO V4 模型和SSD 模型,但其0.192 s的单幅图像平均检测时间仍可保证在缆索表面损伤识别过程中具有较好的实时性。上述平均精度和平均检测时间的实验验证了文中方法的有效性。
5 结论
识别桥梁缆索表面损伤是修复缆索损伤的前提,能有效预防桥梁缆索向严重病害发展,对提高桥梁的经济性和安全性具有重要意义。为实现准确、快速的桥梁缆索表面损伤识别,文中将注意力机制嵌入YOLO V4 目标检测模型中,提出了基于改进YOLO V4 模型的桥梁缆索表面损伤图像识别方法。
融入注意力机制的YOLO V4 模型能有效识别桥梁缆索表面损伤,平均精度为93.57%,相较于SSD模型、Faster R-CNN 模型和原始YOLO V4 模型,平均精度高出24.57%、29.93%和6.10%,其0.192 s 的单幅图像平均检测时间能保证在缆索表面损伤识别过程中具有较好的实时性。
猜你喜欢
交通科学与工程(2021年3期)2021-11-04 09:27:22
中外女性健康研究(2020年10期)2020-08-02 11:03:18
水道港口(2019年5期)2019-11-19 06:07:58
中国医学创新(2019年9期)2019-08-19 01:35:26
石油工程建设(2019年2期)2019-05-11 07:36:26
电子制作(2018年19期)2018-11-14 02:37:08
医学信息(2017年16期)2017-09-05 15:34:20
自动化学报(2017年11期)2017-04-04 02:52:58
建筑建材装饰(2016年13期)2017-01-04 22:55:47
舰船科学技术(2015年8期)2015-02-27 15:38:44
