
基于RGB-D的龙眼实时检测与定位方法
2022-05-24 03:21:20孙宝霞郑镇辉胡文馨郭文韬熊俊涛
林业工程学报 2022年3期
孙宝霞,郑镇辉,胡文馨,郭文韬,熊俊涛*
(1. 广东机电职业技术学院电气技术学院,广州 510515; 2. 华南农业大学数学与信息学院,广州 510642)
龙眼是我国华南地区重要的热带亚热带果树之一,已成为我国华南地区农村经济的支柱产业,在推进农业产业结构的调整、增加农民收入方面发挥着重要的作用[1]。近些年来,我国龙眼产量呈波动上升态势,但依然存在龙眼管理成本高、机械化程度低等问题。目前龙眼的采摘依赖人工操作来实现。随着农业机械化的发展,将农业机器人应用到龙眼采摘过程中,能够大幅降低劳动成本,提高龙眼经济效益。
果实的检测与定位是采摘机器人的关键技术之一,其精确度和准确度是机器人成功采摘的关键。目前,水果检测与定位已有众多研究,但以龙眼为研究对象的成果则较少,如Pathaveerat等[2]提出利用HSB (hue、saturation、brightness,色相、饱和度、亮度)颜色模型和霍夫圆检测来分割出龙眼果实。Wang等[3]利用小波变换和K均值聚类对荔枝进行识别,实验表明该识别方法能够很好地对抗光照变化,对无遮挡和部分遮挡的荔枝平均识别率分别为98.8%和97.5%。Liu等[4]提出一种在Cr-Cb(色调-饱和度)坐标中构建多椭圆边界模型的方法来获取柑橘的轮廓信息,正确率达90.8%。以上方法基于果实的颜色和纹理特征进行检测,其环境适应性低,鲁棒性较弱,不适合用于与枝条颜色和纹理相近的龙眼果实。
近年来,深度学习算法已成功应用到农业视觉领域中,并取得较好的效果。Bargoti等[5]利用Faster-RCNN检测苹果、芒果和杏仁,且苹果和芒果检测网络的F1得分大于0.9。但RCNN(regions with CNN features)系列算法检测速率较低,相对而言,YOLO(you only look once)系列算法则能弥补这一缺陷。熊俊涛等[6]提出利用YOLOv2对航拍绿色芒果图像进行检测,测试集识别正确率为90.64%,平均检测时间为每幅图0.08 s。Tian等[7]提出一种改进的YOLOv3模型用于检测不同生长阶段的苹果,测试结果表明,该模型优于Faster-RCNN和VGG16(visual geometry group),平均检测时间为每张图0.304 s。
随着RGB-D设备的成熟,许多研究者将水果的深度信息应用到水果检测与定位中。Barnea等[8]结合三维表面特征和反射效果来检测感兴趣区域,再通过SVM来检测甜椒,其运行时间为197 s,检测精度为55%。Nguyen等[9]提出对苹果点云数据进行聚类的方法,同时实现苹果检测和定位。范永祥等[10]基于RGB-D SLAM手机构建了森林样地调查系统,在18块半径为7.5 m的圆形样地中进行了测试,坡向估计具有较大的RMSE,是由于当坡度较小时,即使SLAM系统估计位姿有较小漂移,仍会导致该值产生较大偏差,但整体而言坡向仍是无偏的。
本研究的龙眼果实体积较小,与枝条颜色同是浅棕色,在检测和定位上有一定难度,但其形状呈规则圆形,利用深度学习算法能够较好地学习该特征。因此,本研究提出一种自然环境下龙眼的检测和定位算法,通过RGB-D相机采集龙眼的彩色和深度图像,利用YOLOv5对彩色图像进行识别,并结合深度图像进行定位。结果表明,该方法有较高检测率,能为龙眼的自动采摘机器人提供技术支持。
1 材料与方法
1.1 图像采集
本研究所用视觉传感器为kinect v2,将一台微软kinect v2传感器与一台Win10笔记本电脑相连,使用Microsoft Visual C++2017、OpenCV3.4.1图像处理库实现图像采集功能。kinect v2搭载了红外光源、红外摄像头和彩色摄像头。红外摄像头拍摄的图像分辨率为512×424 px,视场角为70.6°×60.0°,有效拍摄距离为500~4 500 mm。彩色摄像机分辨率为1 920 pixel×1 080 pixel,视场角为84.1°×53.8°。本研究利用这两个摄像头分别获取深度图像和彩色图像。
高世科等[11]在进行光照强度对碟状体生长的影响试验时,设置2个组: NL1为自然光组(1 405 lx),WL2为弱光组(黑色塑料布罩住光源,光照度为605 lx)。因此,试验设置强烈光组(2 005 lx)、中等光组(1 405 lx)和暗淡光组(605 lx)进行图像采集。
参照《龙眼种质资源描述规范和数据标准》[12]和NY/T 1305—2007《农作物种质资源鉴定技术规程 龙眼》进行果实数量类别划分,将果实数量分为较少(穗粒数50以下)、中等(穗粒数50~200)、较多(穗粒数200以上)3组。
试验图像于2020年7月拍摄于广州市天河区果树研究所。拍摄距离为500~1 200 mm,并从不同的光照度下进行拍摄,共拍摄920幅龙眼图像作为本研究的数据集。根据果树数量和光照强度的不同进行了图像分类,不同情况下的龙眼图像统计见表1。对表1中所有图像打上人工标签,并对每种龙眼图像分别随机抽取80%的数据,共736副图像作为本研究模型的训练集,剩余的184副图像作为测试集。

表1 各类龙眼图像统计Table 1 Statistical table of various longan images
1.2 总体技术实现流程
总体研究技术流程图如图1所示。
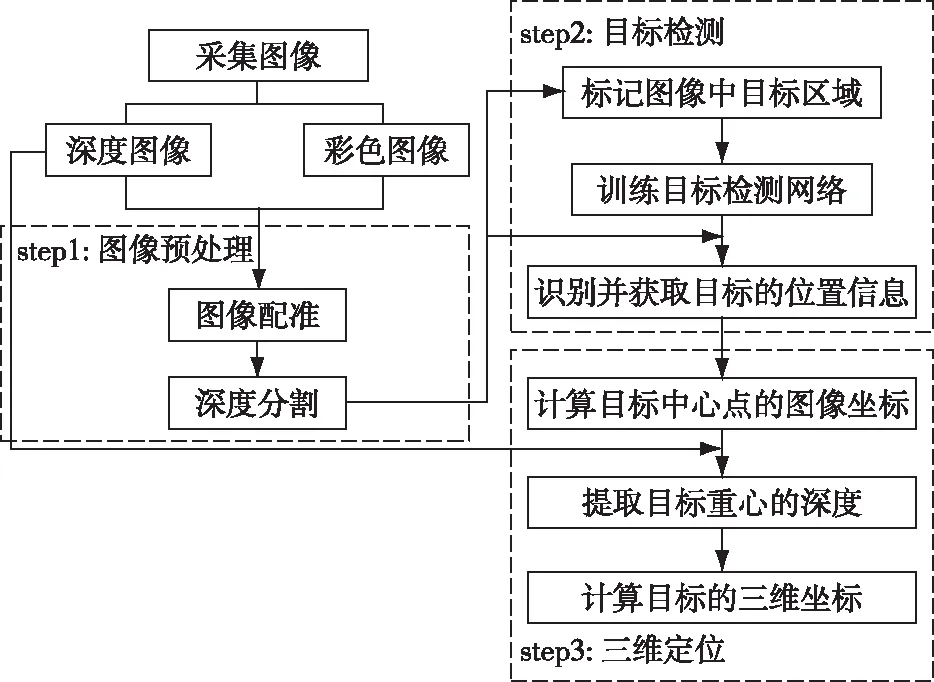
图1 检测与定位算法流程图Fig. 1 Flow chart of detection and location algorithm
首先利用视觉传感系统采集大量花果图片,并对图片进行图像配准和深度分割预处理。然后对预处理后的图片进行打标,并输入目标检测神经网络中训练。网络训练完成后能够识别并获取图像中目标的位置信息,然后根据位置信息计算出目标的图像坐标,再结合深度图像中的信息最终计算出目标的三维坐标。
1.3 图像预处理
本研究图像预处理流程包含图像配准和深度分割两个步骤。由于深度图像和彩色图像用不同分辨率和视场角的摄像头拍摄所得,因此在对图像进行目标检测前需要先进行图像配准,在深度图像和彩色图像两者坐标之间建立对应关系,使坐标对齐。本研究利用kinect v2软件开发工具包里提供的“MapDepthFrameToColorSpace”函数调整彩色图像以匹配深度图像。由于图像的背景会干扰目标检测的效果,并且考虑到机械臂的活动范围和kinect的有效拍摄范围,本研究对配准后的图像进行了深度分割。对不同深度的图片进行多次预试验,对比不同的图像效果,最终选择图片的有效深度在500~1 200 mm。
1.4 YOLOv5识别模型
YOLO算法最早由Redmon等[13]提出,后来经过改进发展成YOLOv4[14]和YOLOv5[15]。YOLOv5能够在保证时效性的同时有着较高的检测准确率。对于Faster-RCNN,其检测过程分成两步,首先提取出候选框,然后对候选框进行分类和回归。而YOLOv5网络将检测问题转换为回归问题。它不需要提议区域,直接通过回归生成每个类的边界框坐标和概率。因此在检测速度上,基于回归的YOLOv5比基于候选区的Faster-RCNN要快很多。
YOLOv5由名为Darknet-53的基础网络和检测网络构成。其中Darknet-53包含了52个卷积层和1个全连接层,其结构如图2所示,该网络以416×416分辨率的图像作为输入,输出3种不同尺度的特征(13×13,26×26,52×52),然后送到检测网络中进行回归,得到多个预测框,最后运行非极大抑制算法,保留置信度最高的预测框作为目标最终的检测框。
YOLOv5模型检测过程为:首先将整个图像缩放到416×416分辨率,并用S×S个网格划分图像,图中的检测目标由目标中心点所在的单元格负责检测,每个单元格预测多个边界框的坐标信息和置信度信息。
在检测过程中,同一个目标会得到多个候选边框和相应的置信得分,因此YOLOv5使用非极大值抑制(non-max suppression,NMS)[16]算法来消除冗余边框,选出最佳的候选框作为目标的检测框。
YOLOv5通过计算单元格预测值和真实值的误差平方和作为模型的损失。损失函数由边界框位置误差、置信度误差和分类误差三部分组成,用公式表示为:

图2 龙眼检测网络结构Fig. 2 Structure diagram of longan detection network
(1)
3个误差用公式分别表示为:
(2)
(3)
(4)
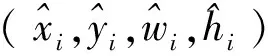
1.5 三维定位方法
YOLOv5模型能够获取并输出多个目标的大小和位置信息。本研究定位方法如图3所示。
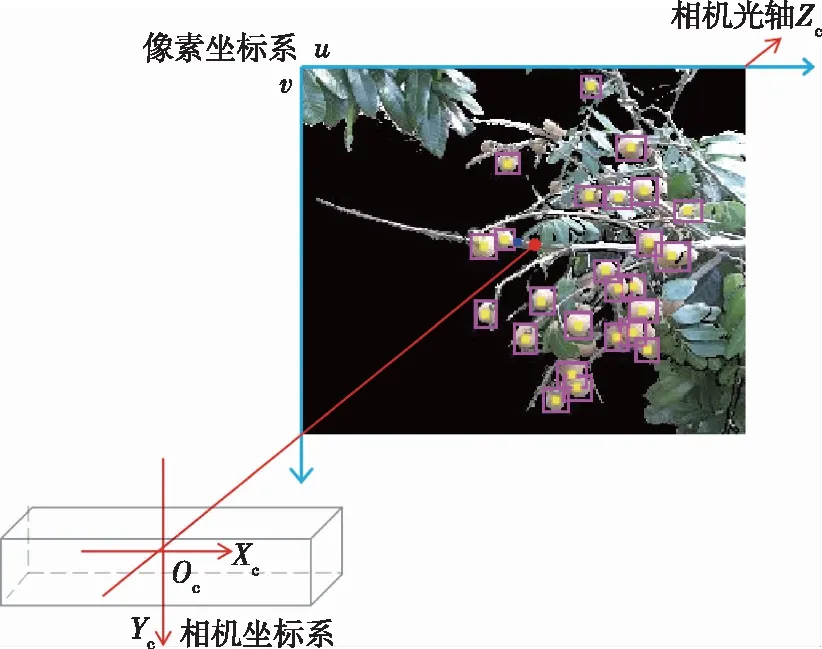
图3 龙眼定位方法Fig. 3 Method of longan location
图3中红色框为YOLOv5模型的输出框,黄点为输出框的中心点。为了提高算法的实时性,简化计算过程,将输出框的中心点作为龙眼的质心,通过以图像最左上角像素点为原点建立像素坐标系,获取中心点的像素坐标并映射到深度图的像素坐标系中,则该点在深度图的像素值即为龙眼到相机平面的距离。以kinect的红外摄像头为原点建立相机坐标系XcYcZc(图3中红色箭头方向),其中Zc为相机的光轴,则龙眼的三维坐标(xd,i,yd,i,zd,i)用公式表示为:
(5)
式中:Idep为深度图像;(ui,vi)为图像像素坐标;(Cx,Cy,fx,fy)为红外摄像头的内参矩阵,本研究通过张正友相机标定法计算所得。
2 结果与分析
2.1 龙眼检测试验
本试验的软硬件平台配置如下:操作系统为Ubuntu16.04;深度学习框架为Pytorch;CPU i7-8700,3.2 GHz主频,六核十二线程;内存32 GB;显卡为GeForce GTX3090。本研究在YOLOv5模型的预训练权重YOLOv5-l的基础上训练龙眼识别网络,设置的学习率为0.001,迭代次数为5 000次。
在实际的龙眼拍摄环境中,每张图像包含的果实个数和受到光照的强度往往不同,针对该现象,对龙眼数量差异较大的图像进行分类,并在不同的光照条件下进行测试,部分图像测试结果经局部放大2.5倍后如图4所示,分别为图像果实个数较少、中等、较多时的测试结果。在串果稀少的图像中,目标对象较为完整,大部分果实都能被正确检测。而串果较多的图像中,存在部分果实过小、粘连和相互遮挡的情况,精确率有所降低。此外,模型在光照度强烈和中等环境下能取得较好的检测效果;而光照暗淡环境下由于存在较多阴影,影响了龙眼的检测效果。
对图4中龙眼和输出框的个数进行人工统计,其统计结果如表2所示。

图4 检测结果Fig. 4 Testing results
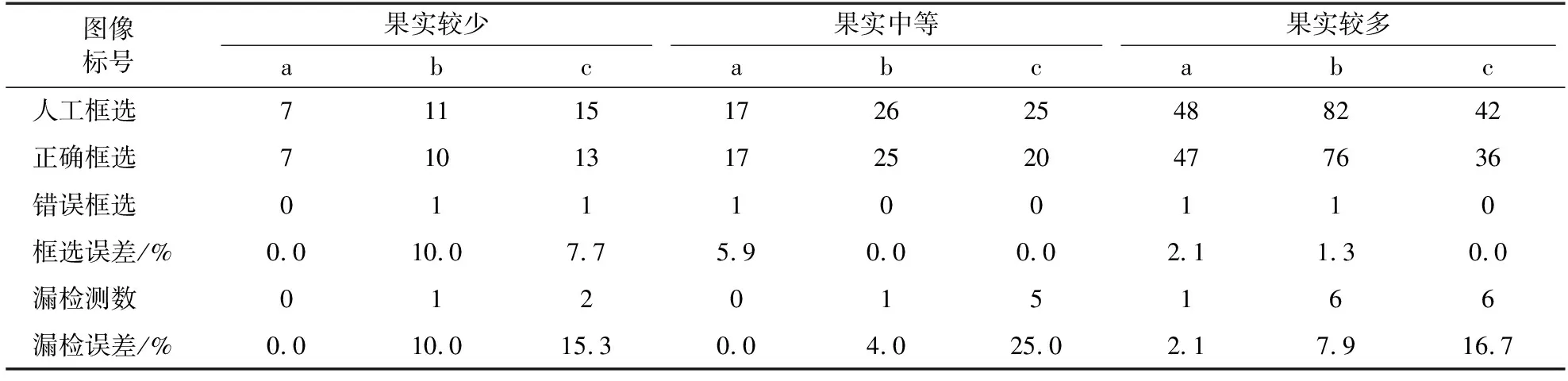
表2 人工统计结果与本研究算法检测结果的对比Table 2 Comparison of results of manual statistics with calculation results
选取精确率(precision,P)和召回率(recall,R)来评价图像整体的检测效果,并用精确率和召回率的调和平均值,即F1分数(F1-score,F1)来衡量模型的性能。
精确率、召回率、F1值、mAP(mean average precision)作为评估指标,经常用到分类效果的评测上,且只考虑正样本的指标。精确率是以预测结果为判断依据,预测为正例的样本中预测正确的比例,即相对正例的预测结果而言,正例预测的准确度;召回率是以实际样本为判断依据,实际为正例的样本中,被预测正确的正例占总实际正例样本的比例,实际为正例的样本中,即评估所有实际正例是否被预测出来的覆盖率占比多少;由于单独用精确率或召回率不能全面评估模型好坏,所以结合F1分数来评估模型的性能;mAP是各类别AP的平均值。以上评估指标皆为越大越好。
精确率、召回率和F1分数用公式表示为:
(6)
(7)
(8)
式中:TP表示正确检测的龙眼框选数目;FP表示错误检测的框选数目;FN表示漏检测的龙眼数目。
不同图像的YOLOv5测试结果如表3所示。最终模型的平均精确率为96.55%,平均召回率为92.02%,F1(F1-score)为0.942。

表3 不同图像的YOLOv5测试结果Table 3 Test results of different images using YOLOv5

图6 不同条件下的框选结果对比Fig. 6 Comparison of box selection under different conditions
本研究所用方法对于部分粘连龙眼未能有效检测,如图5所示,图中蓝圈里面的粘连龙眼能正确检测,而黄圈里面的则未能正确检测。明显看出,图5a中黄圈的龙眼比蓝圈的龙眼体积更小,因而导致黄圈内一整串果实未能有效检测,即使是黄圈内仅有的一个红色输出框,也是错误地框着两个互相粘连的龙眼;而图5b中,整体光照暗淡,且黄圈内的龙眼由于受到背光的影响,比起蓝圈内的更模糊,且目标颜色普遍泛白,颜色信息失真,相比蓝圈内的更加难以检测。综上,对于粘连龙眼,在检测龙眼体积较小和环境光照不良情况下,会更容易导致龙眼漏检。

图5 粘连龙眼检测结果Fig. 5 Test results of overlapping longans
为了更直观体现本研究检测算法的优越性,笔者设计了对比试验,在与YOLOv5同样的试验硬件配置下搭建Tensorflow框架和Darknet框架,并在不同复杂场景下扩充龙眼数据集来训练YOLOv5、YOLOv4和Faster-RCNN 3个不同果实检测模型。重新构造后的数据集一共包含2 219张龙眼图像,按照70%,15%,15%的比例随机拆分为训练集、验证集、测试集。试验结果以对比的形式显示,分别使用YOLOv5、YOLOv4和Faster-RCNN 3个算法测试随机抽取的两张测试图像,效果如图6所示。
由图6可知,在多果远距离检测的情况下,3种算法都能有效检测图像中大多数的龙眼,但Faster-RCNN算法存在将重叠果实识别成单个果实的缺陷(图6a);同时YOLOv4则出现将背景树叶误识别为龙眼的情况(图6b);而YOLOv5则可以很好地克服其他两种算法存在的问题(图6c)。此外,在多果背光遮挡检测的情况下,YOLOv4和Faster-RCNN算法存在漏识别龙眼的不足,而YOLOv5则可以成功将图像中被遮挡的龙眼识别出来。
最终Faster-RCNN、YOLOv4与YOLOv5 3种检测模型的测试结果如表4所示,在龙眼果实的检测上,YOLOv4和YOLOv5的检测时间明显较Faster-RCNN短,且检测速率明显比Faster-RCNN快,此外YOLOv5的精确度远比Faster-RCNN和YOLOv4高,可以满足果园复杂环境下龙眼精准检测的需求。
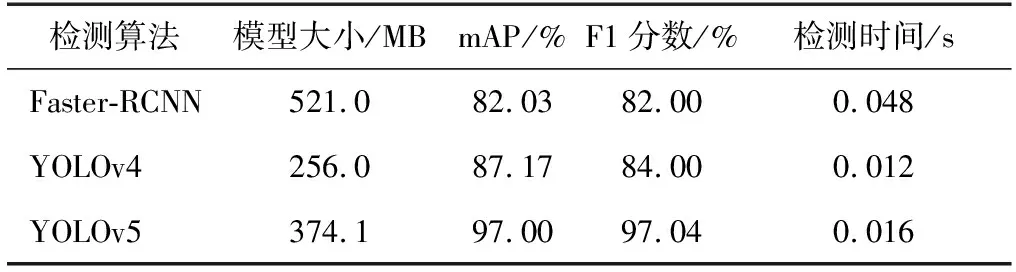
表4 模型测试结果对比Table 4 Comparison of three model test results
2.2 定位精度分析试验
由于平均误差和标准偏差可能受到大误差的影响,本研究将定位精度量化为由检测算法估计的坐标(xd,i,yd,i,zd,i)与真实位置坐标 (xg,i,yg,i,zg,i) 之间的中值误差(median error, MEDE)和中值绝对偏差(median absolute deviation, MEDAD),以x轴方向为例用公式表示如下:
MEDE=median{|xd,i-xg,i|}
(9)
MEDAD=median{||xd,i-xg,i|-MEDE|}
(10)
式中:median()为取集合中元素的中值,同理可得y轴和z轴方向上的中值误差和中值绝对偏差。
试验过程主要是在500~1 200 mm范围内设定kinect相机和龙眼果实的不同距离,每隔50 mm利用kinect相机对多个方位的龙眼果实进行三维定位,计算用kinect所得的龙眼三维坐标与激光测距仪测量的实际龙眼三维坐标之间的中值误差,并绘制出误差曲线。龙眼真实位置的测量场景见图7,分别用激光测距仪和游标卡尺测出龙眼的z轴和x、y轴的坐标。误差曲线见图8,可以看出3个坐标的误差都随着深度变化不同程度地上升,其中z轴坐标的误差上升得最快,在深度值较大时明显高于x轴和y轴的误差。

图7 坐标测量场景Fig. 7 Coordinate measurement scene
随机挑选多个果实的中值误差和中值绝对偏差的计算结果见表5,在x、y和z轴方向上的中值误差分别为5,6和10 mm,深度方向上的误差略大,但3个方向上的中值误差都不超过10 mm,能够被采摘机器人接受。
此外,本研究在处理器为Inter(R) Core(TM)i5-6500 @ 3.20 GHz、内存为8 GB的计算机平台上对60张龙眼图像进行定位,最终算法的平均运行时间为0.071 s。
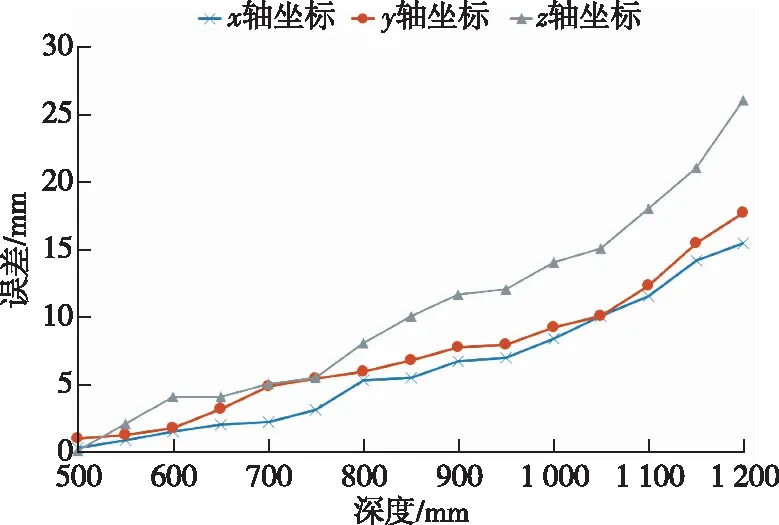
图8 不同坐标的深度误差曲线Fig. 8 Curves of depth error for different coordinates

表5 误差计算结果Table 5 Error calculation results
3 结 论
检测与定位是采摘机器人的关键技术之一。针对目前对龙眼果实进行检测与定位的研究较少,本研究通过RGB-D相机获取龙眼彩色和深度图像,随后在图像配准和深度分割后,利用YOLOv5检测模型对龙眼果实进行检测,并结合深度图像获取果实的三维坐标。试验验证了该方法的有效性与可行性。
1)相比Faster-RCNN,YOLOv5能够更加有效地检测龙眼果实,平均检测时间、精确率、召回率、F1分数分别为0.024 s、96.55%、92.02%、0.942。在果实数稀少、中等和较多的情况下精确率分别为98.37%,97.86%和95.57%,召回率分别为93.92%,92.15%,91.57%。而在光照强烈、中等和暗淡的环境下精确率分别为98.06%,96.34%和95.27%,召回率分别为93.03%,93.37%和89.68%,能够适应不同果实数量和中高强度光照的情况,具有一定的鲁棒性。
2)构建了深度误差曲线,且测量了龙眼果实在x、y和z轴方向上定位的中值误差分别为5,6和10 mm,中值绝对偏差分别为3.7,3.3和5.1 mm,最终定位算法平均运行时间为0.071 s,满足采摘机器人的采摘需求。
3)验证了YOLOv5模型对龙眼果实识别的精确性和实时性,但仍存在识别效果不理想的情况,主要原因是龙眼在光照暗淡的环境下果实轮廓不明显。后续的研究将考虑利用低光照图像增强技术来提升识别效果。
4)本研究设计了对比试验,在与YOLOv5同样的试验硬件配置下搭建Tensorflow框架和Darknet框架,并在不同复杂场景下扩充龙眼数据集来训练YOLOv5、YOLOv4和Faster-RCNN 3个不同果实检测模型,可以满足果园复杂环境下龙眼精准检测的需求。
猜你喜欢
中学生数理化·七年级数学人教版(2020年11期)2020-12-14 06:59:52
导航定位与授时(2020年5期)2020-09-23 03:05:00
铁道通信信号(2020年9期)2020-02-06 09:16:06
作文大王·低年级(2019年4期)2019-05-13 01:44:10
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14 01:14:28
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08 02:44:26
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26 06:03:48
知识经济·中国直销(2018年3期)2018-04-12 06:43:37
岭南音乐(2016年5期)2017-01-17 07:44:58
学苑创造·A版(2016年9期)2016-10-10 11:36:01
