
改进Bi-LSTM的文本相似度计算方法
2022-05-23 07:25冯月春陈惠娟
计算机工程与设计 2022年5期
冯月春,陈惠娟
(1.宁夏理工学院 计算机学院,宁夏 石嘴山 753000; 2.西安工程大学 计算机学院,陕西 西安 710000)
0 引 言
文本语义相似度对各种语言处理任务来说至关重要[1]。由于语言表达的多样性,语义文本相似度(semantic textual similarity,STS)的检测具有挑战性,并且该相似度检测需要从多个层次(如单词、短语、句子)进行。近年来,在自然语言处理中,大量学习模型将词的语义特征编码成低维向量嵌入文本[2]。文献[3]在释义数据集PPDB上训练单词嵌入模型,然后将单词表示应用于单词和二元语法相似性任务。
现有的文本相似度建模研究大多依赖于特征,如机器翻译度量的特征、基于依赖关系的特征等[4,5]。文献[6]利用依赖树提出了一种单语对齐器,并成功地将其应用于STS任务,该方法在语义文本相似度、多文档摘要冗余消除方面取得了很好的效果。文献[7]提出了一些基于维基百科结构特征的语义计算方法,其具有更好的文本相关性。目前,深度学习模型成为了单词/句子连续向量的有效表示方法。文献[8]提出一种结合HowNet语义相似度和隐含狄利克雷分配模型的主题聚类方法,该方法在一定程度上提高了文本分类的准确性,然而忽视了上下文信息。
此外,对于句子的建模,构图方法取得了广泛的应用。文献[9]提出了用于句子建模的层次化卷积神经网络-长短期记忆(convolutional neural network-long short term memory,CNN-LSTM)架构,其中CNN被用作编码器编码句子编码,而LSTM被用作解码器[10]。文献[11]提出了一种基于卷积滤波器的N-gram单词嵌入方法,以增强用于捕获上下文信息的传统单词嵌入表示,该方法在多语言情感分析中取得了良好的性能。
由于不同的单词嵌入模型捕获语言属性的不同方面,并且在不同的数据集上,嵌入模型的性能也会有所差异[12,13]。为此,提出了一种改进Bi-LSTM的文本相似度计算方法。其创新点总结如下:
(1)现有方法在编码文本时需要维度一致,而所提方法将输入的句子转换成含有多个嵌入向量的多个单词向量,简单而有效地组合不同维度的各种预训练单词嵌入。
(2)为了能够结合上下文信息处理长文本相似度问题,采用了Bi-LSTM方法,并且引入注意力机制,用来为关键的影响因素配置更多的计算资源,提高方法计算的效率。
1 提出的文本相似度计算方法
所提模型主要由3部分组成,如图1所示。首先将输入的句子转换成多个单词向量,其中每个单词向量里包含多个嵌入向量[14]。然后通过Bi-LSTM提取出每个单词向量中的最佳词特征,用于表示句子。最后,对两个句子分别从词与词、句子与句子、词与句子这3个层面进行多级比较,并加权计算得到其最终的相似度。
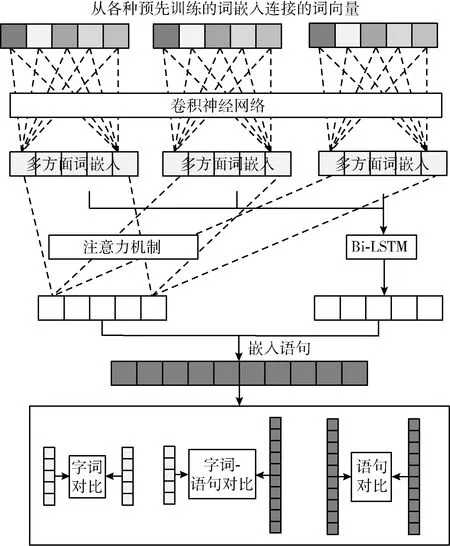
图1 所提方法的模型
1.1 多方面文字嵌入向量
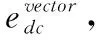
(1)
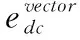
(2)
(3)
式中:σ为logistic sigmoid函数。
1.2 利用改进Bi-LSTM提取词特征
长短时记忆(long-short term memory,LSTM)神经网络是一种时间递归神经网络,其包含了输入门it、 输出门ot、 忘记门ft和记忆单元ct, 将门和记忆单元组合可极大地提升LSTM处理长序列数据的能力[16]。LSTM的函数表示为

(4)
式中:ht为t时刻隐藏状态,Wf、Wi、Wo、Wc为LSTM的权重矩阵,bf、bi、bo、bc为LSTM的偏置量,δ(·) 为激活函数。

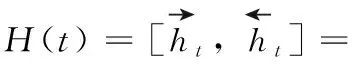
(5)
为了合理分配计算资源,减小非关键因素的影响,在Bi-LSTM中引入注意力模型。
Attention机制模拟人脑注意力的特点,核心思想是:对重要的内容分配较多的注意力,对其它部分分配较少的注意力。根据关注的区域产生下一个输出。基于注意力模型的LSTM模型结构如图2所示。
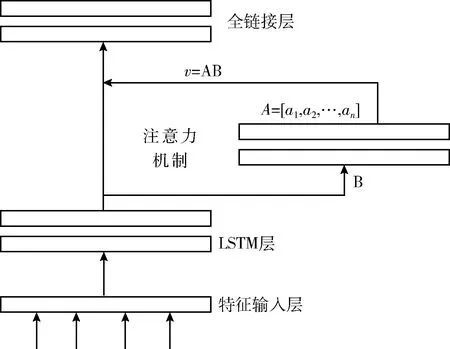
图2 基于注意力模型的LSTM模型结构
在该模型中,Bi-LSTM层的输出H(t) 经过隐藏层B,隐藏层状态值为ut,A=[a1,a2,…,an] 为历史输入的隐藏状态对当前输入的注意力权重,最后的特征输出v为不同注意力权重的隐藏状态的总和
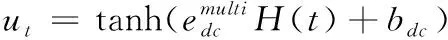
(6)
式中:uw为上下文向量;在训练过程中随机初始化并不断学习;at为注意力向量。
1.3 利用多层相似加权计算文本相似度
利用改进Bi-LSTM获得词特征后,从词与词、句子与句子、词与句子这3个层面进行多层比较,并加权计算获得其最终的相似度。
(1)字词比较
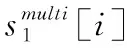
(7)
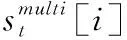
(2)句子比较
给定两个输入句子s1和s2, 将其编码为两个句子嵌入vs1和vs2, 为了计算两个嵌入量之间的相似性,引入了3个比较指标:
余弦相似性εcos
(8)
乘法矢量εmul和绝对差εabs
εmul=vs1⊙vs2,εabs=|vs1-vs2|
(9)
神经差异
εnd=Wnd(vs1⊕vs2)+bnd
(10)
式中:Wnd和bnd分别为权重矩阵和偏差参数。
因此,句子相似度向量simsent计算如下
simsent=σ(Wsent(εcos⊕εmul⊕εabs⊕εnd)+bsent)
(11)
式中:Wsent和bsent分别为权重矩阵和偏差参数。
(3)词句比较
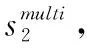
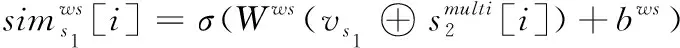
(12)
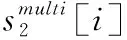
(4)文本相似度
句子对的目标分数计算如下
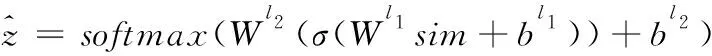
(13)
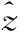
由于采用皮尔逊相关r评估所提模型,因此 [1,K] 范围内句子对的相似度计算替换为
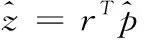
(14)
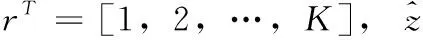
满足z=rTp的稀疏目标分布p计算如下
(15)
对于i∈[1,K],z为相似性得分。
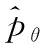
(16)
式中:m为训练句子对的数目,θ为模型参数。采用梯度下降优化学习模型参数,并在训练阶段保持预训练单词嵌入的固定。
2 实验结果与分析
所提方法采用SMTeuroparl、MSRvid和MSRpar这3种数据集用于评测文本的相似度。其中SMTeuroparl和MSRpar文本长度长,但SMTeuroparl不符合语法,而MSRpar结构复杂,符合语法。MSRvid长度最短且结构简单。实验中,由3个预先训练的单词嵌入组成的单词嵌入维度,并作为Bi-LSTM尺寸;bdc、bsent、bws和bws′的维数分别为50、5、5和100。
采用3种数据集和fastText、Glove、SL999以及Baroni这4种预训练的单词嵌入模型评估所提方法的效率,并将所提方法与其它方法进行比较分析。
2.1 多个预训练单词嵌入的效率
将使用多个预训练单词嵌入方法与使用1个、2个和3个预训练单词嵌入方法的效率进行比较,结果见表1。其中采用的两个评估指标为:z为相似性得分, |V|avai为预先训练的单词嵌入中可用词汇的比例。所有方法采用相同的目标函数和多层次比较,将Bi-LSTM的维数和卷积滤波器的数目设置为相应字嵌入的长度。
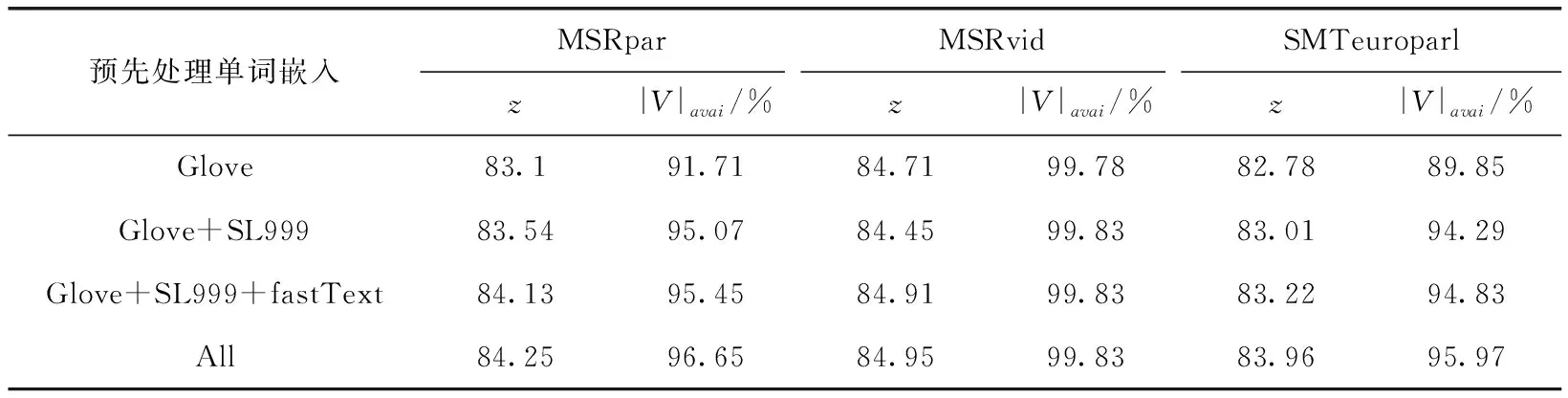
表1 不同数据集上不同数量预训练单词嵌入方法的评估结果
从表1中可看出,使用4个预训练单词嵌入的方法优于使用其它数量单词嵌入的方法。其中 |V|avai是预先训练的单词嵌入中可用词汇的比例,MSRvid数据集忽略了惯用的多词表达式和命名实体,因此MSRvid的 |V|avai相当高。由于SL999的嵌入经过了释义数据库的训练,且具有较高的 |V|avai, 因此加入SL999单词嵌入,其可用词汇增多且相似度会提高。
在MSRpar和SMTeuroparl中,由于SMTeuroparl不符合语法,而MSRpar结构复杂,且符合语法,因此对于不符合语法的文本语法分析树和依存关系树可能是错误的,从而导致实验结果偏低。当采用4种预先训练的单词嵌入方式时,其 |V|avai明显提高,因此文本相似度的度量性能也随之提升。
2.2 所提方法的性能分析
为了全面论证所提方法的性能,选择MSRvid和MSRpar两个数据集分别从词、句等多层相似性进行论证。
(1)MSRvid
采用生活中的一些相似文本对所提方法的性能进行评估,结果见表2。

表2 用于文本相似度分析的典型文本
从表2的样本#1中可看出,在样本#1的上下文中,people和spectators不能交换,词的相似度必须考虑上下文信息。而所提方法采用Bi-LSTM能够很好的基于上下文信息计算文本相似度,从而判定#1中语句相似度不高。所提方法中引入注意力机制,能注重比较整个上下文的意义而不是每个词的强表现力。在样本#3中,可看出这两个句子对共享一些短语(如a good idea)。虽然这对词有相同的短语,但为其分配的相似度很低,这与所提方法相矛盾,因此#3相似度仅为0.9。而样本#2的相似度较高,其值为8.8。在这些样本中,每个单词或短语对句子的贡献程度不同,如 “just”通常对其句子意义贡献不大,但在样本#3中,其改变了整个句子的含义。因此,在评价句子的相似性或语法蕴涵时,应考虑每个词在句子中的作用。由此可知,所提方法能够较为准确地辨识文本相似度。
(2)MSRpar
本文采用的改进Bi-LSTM方法有效结合了文本词语的上下文,考虑了局部语境。为了理解局部语境对句子相似度的相关性,研究了不带局部语境的Bi-LSTM,并将其与所提方法进行了比较,使用不同长度的局部语境:3、5、7和9,结果见表3。
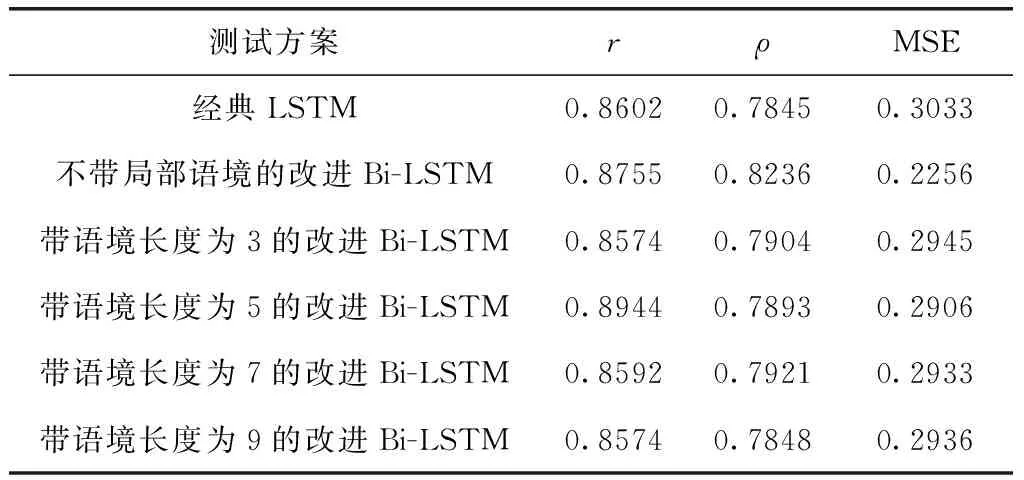
表3 测试集的皮尔逊r和斯皮尔曼ρ相关系数和均方误差
最初的Bi-LSTM只考虑单词的一般上下文来分析句子,正如预期的那样,根据皮尔逊相关系数和均方误差(mean square error,MSE)对单词的一般和局部上下文进行句子分析。短或长的局部上下文没有产生最好的结果,这表明短的局部上下文(3个词)没有得到足够的关于词邻域的信息,长的局部上下文(7个词)包含了不相关的信息。因此,在设置局部上下文词汇数为5时,算法性能最佳。
为了论证语境对文本相似度的影响,表4和表5在词汇层面上展示了一对释义的相似性:“她的一生跨越了女性不可思议的变化。”和“玛丽经历了一个解放女性改革的时代。” 对于两个句子中的每一对词,由余弦距离度量一般词嵌入的相似度,结果见表4,长度为5的局部上下文相似度见表5。其中需要注意的是,因为各自代表不同的维度空间,这两个表具有不同的值范围。

表4 余弦距离度量一般词嵌入的相似度结果
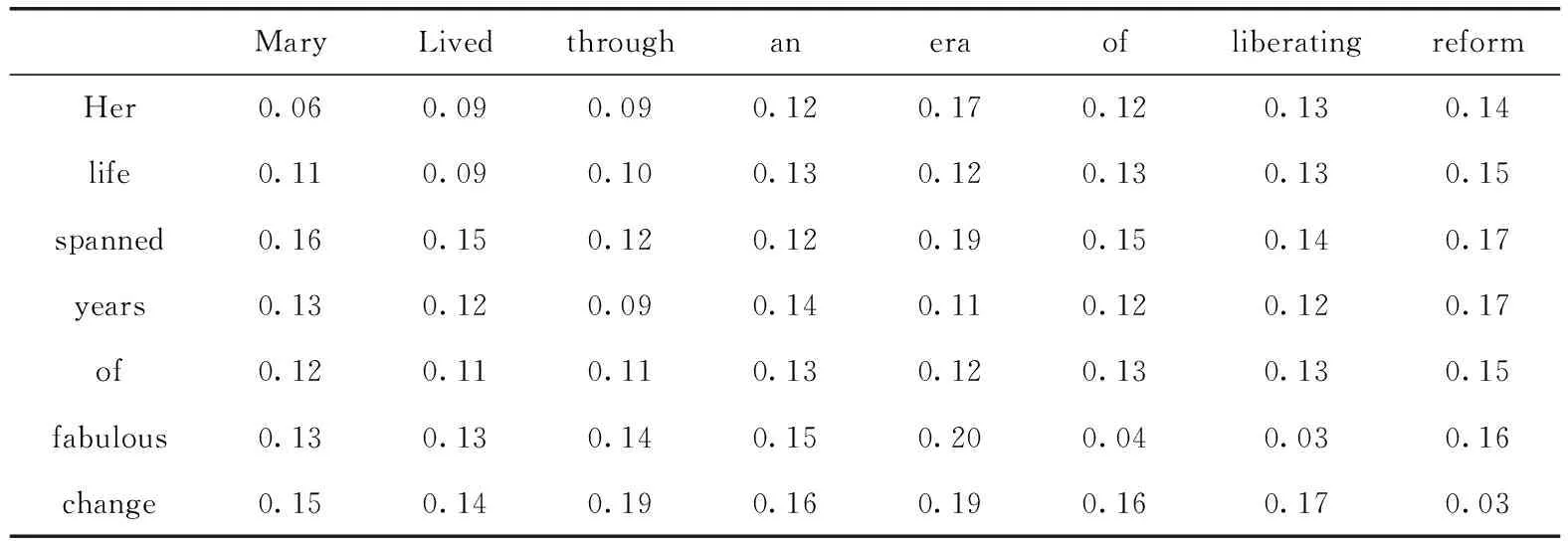
表5 长度为5的局部上下文相似度结果
从表4中可以看出,单词嵌入保留了单词的一般语义和句法关系。在本例中,这些词与具有类似语义(1-“Her”和2-“Mary”、1-“life”和2-“lived”、1-“reform”和2-“change”)或具有类似句法角色(1-“of”和2-“for”)的词更为相似。表5强调了单词的局部上下文有基于其窗口中单词的语义和句法特征;例如,最接近1-“life”的上下文是2-“Mary”,2-“lived”,2-“through”,因为这些局部上下文有直接(2-“lived”)和间接(2-“Mary”)相似的语义。这一分析类似于语境的句法特征,例如最近的当地语境1-“for”是2-“lived”,2-“of”。当所提方法分析短语动词或词义强烈依赖于其前一个词和后一个词的多个词的表达时,当地语境的关联性得到加强。
所提方法对于MSRpar数据集中多层次相似的文本相似度见表6。
表6中的#1句子对描述了一个主动语态和被动语态,意思相同,因此相似度为8.8。#2句子对是肯定句和否定句,相似度较低。而对于#3句子对,所提方法能够确定短语动词“wipe off”和动词“clean”的语义关系,因此相似度较高,为7.6。在MSRpar数据集中的相似度测试结果与实际值相近,由此论证了所提方法的准确性。局部语境不仅有助于更好地识别相似的句子,而且有助于更好地识别否定句和不同意义的句子。这些局部信息为改进Bi-LSTM提供了一个更平滑的单词分析,以及它们在句子中的连接方式。
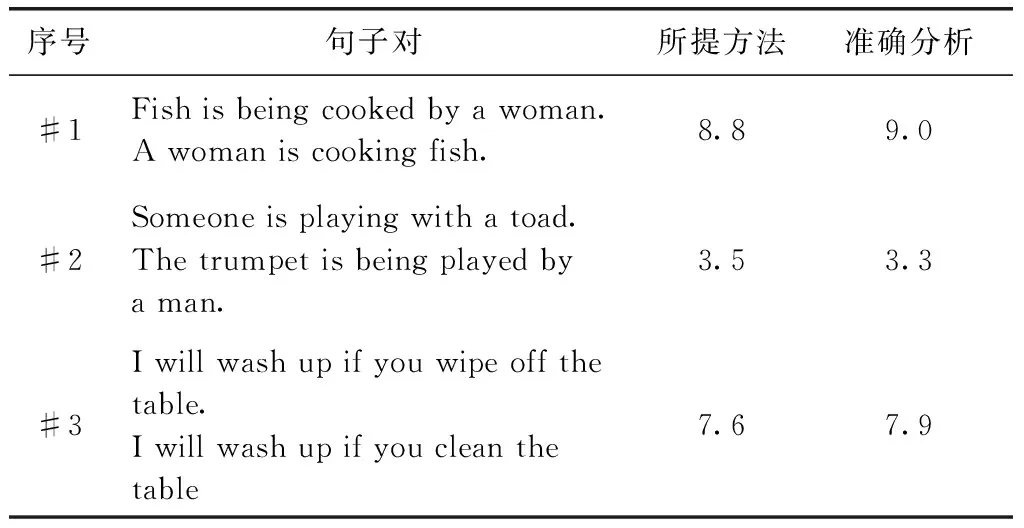
表6 MSRpar数据集中用于文本相似度分析的典型文本
2.3 与其它方法的对比分析
本章将MSRvid、MSRpar和SMTeuroparl这3个数据集中的所有文本按长度分类,分别统计相似度计算性能。将所提方法与文献[6]、文献[7]和文献[9]所提方法在文本长度从10-70之间的MSRvid上进行相似度对比计算,结果如图3所示。当句长大于70或者小于10时文本长度稀疏化,不具代表性。
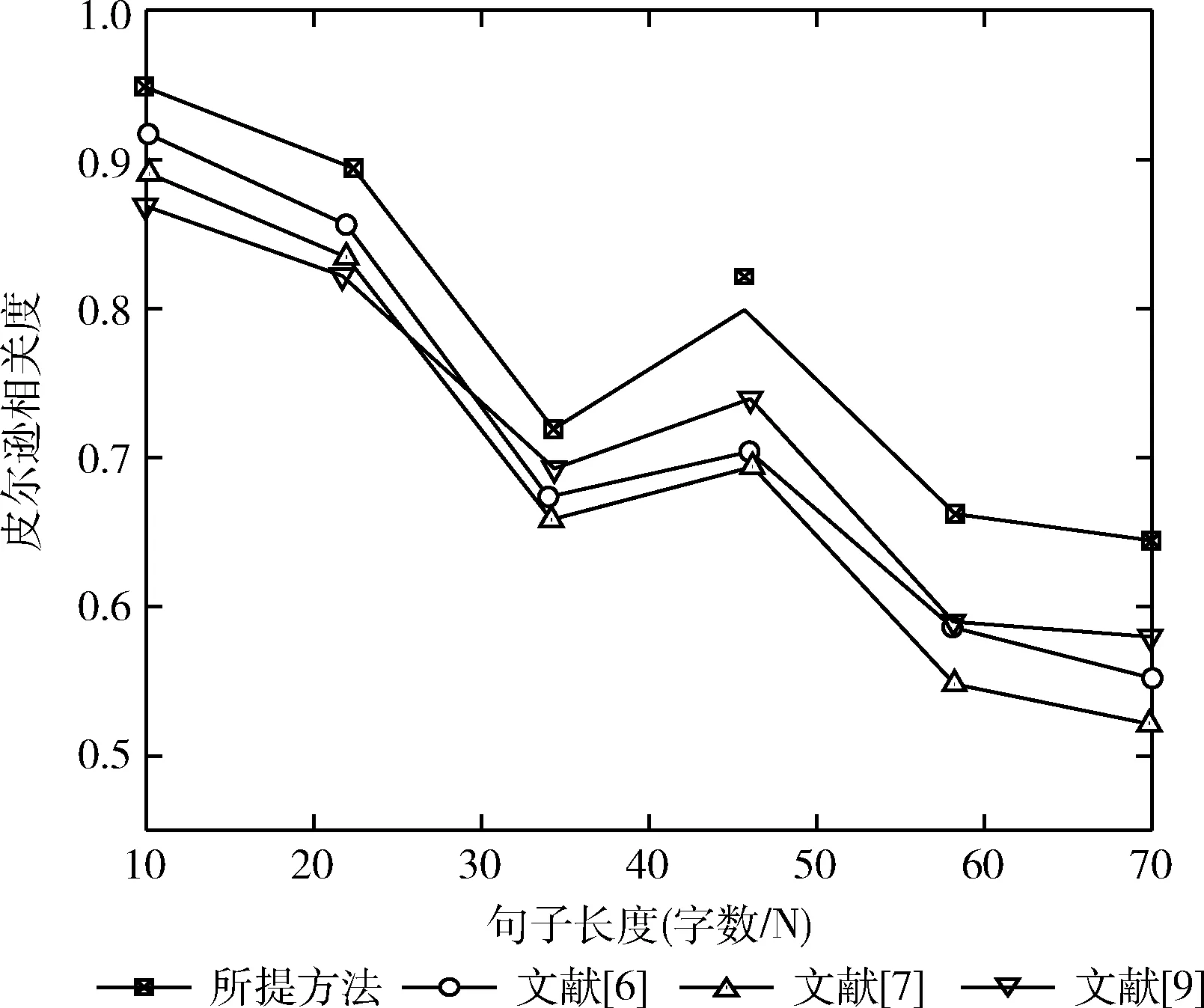
图3 不同句长下的相似度计算结果
从图3中可以看出,随着文本长度变长,4种算法相关度计算性能略有下降。尤其在句长为20-35字时下降较为明显,但所提方法性能仍较优于其它文献所提方法。当句长大于35时,4种方法的相关度计算性能均有所上升,且在45字句长后再次出现下降。文献[6]与文献[9]所提方法相关度计算性能大体相似,文献[7]所提方法在长句长条件下相关度计算性能下降最为明显。由图可知,所提方法相关度计算性能整体优于文献[6]、文献[7]和文献[9]所提方法。
将所提方法与文献[6]、文献[7]和文献[9]所提方法在MSRvid、MSRpar和SMTeuroparl这3个数据集上进行对比分析,结果如图4所示。
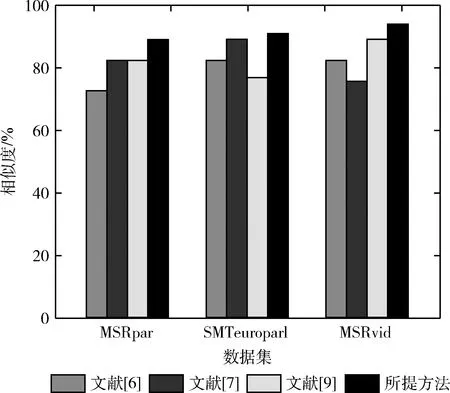
图4 不同数据集上不同方法的计算结果
从图4中可看出,所提方法在不同数据集的文本相似度计算上都具有较大的改善。特别是在STS任务中,所提方法在MSRpar和SMTeuroparl两个数据集上相较于其它文献所提方法都具有明显优势。由于MSRpar包含了复杂的样本,因此4种方法的相似度计算性能均较低。文献[9]所提算法在MSRvid数据集中表现较好的相似度计算性能,略优于所提方法,但所提方法性能仍略优于文献[6]和文献[7]所提方法。在SMTeuroparl数据集中不使用词嵌入,尽管文献[9]所提方法在句子分类上很强,需要提取显著特征来预测目标,但由于该方法忽略了词序的属性,在捕捉需要两个句子整体意义的句子间的关系效果不佳。而所提方法通过改进Bi-LSTM捕捉这一特性,并应用了多层相似加权,因此相比于其它方法,其获得的相似度最高。
此外,MSRvid长度最短且结构简单,因此不同方法在该数据集上表现的性能均较为理想。
3 结束语
所提方法使用多个预训练单词嵌入和多层次比较以测量语义文本相似关系。其中Bi-LSTM能在处理长本文的同时结合上下文提取特征,并且引入注意力机制减小非关键因素的影响,提高了方法的效率,而采用多层相似加权能得到更为准确的计算结果。在MSRvid、MSRpar和SMTeuroparl这3个数据集上对所提方法进行了对比论证,结果表明了多个预训练单词嵌入的高效性,通过提高可用词汇的比例提高文本相似度计算效率,并且允许使用多个不同维度的预训练单词嵌入。此外,相比于其它方法,所提算法的对于文本相似度的计算性能更佳。
但所提方法未考虑一些非规范化的口语化的表达方式,由于句法、语义分析系统的局限性,其对文本内容的影响不能准确反映在相似度计算结果中。如何提高对于非规范化文本的句法、语义分析,是以后研究工作中需要关注的问题。另外,可将所提方法应用到迁移学习任务中,拓展其使用范围。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
开放教育研究(2020年2期)2020-03-31
阅读(快乐英语高年级)(2020年8期)2020-01-08
智慧少年·故事叮当(2018年11期)2018-05-14
高中生学习·高三版(2016年9期)2016-05-14
长江学术(2016年4期)2016-03-11
新高考·高二数学(2015年11期)2015-12-23
长江学术(2015年1期)2015-02-27
