
基于特征融合的商标检索方法
2022-05-23 07:24余松森陈晓升张智辉
计算机工程与设计 2022年5期
余松森,陈晓升,苏 海+,钟 莉,张智辉
(1.华南师范大学 软件学院,广东 佛山 528000;2.华南师范大学 计算机学院,广东 广州 510000)
0 引 言
商标Logo是区分商品和服务来源的一种标记。目前存在的有效商标注册量超过2274万。平均每5.2个市场主体就拥有一件有效商标。商标的注册需要规避已注册的相同相似商标;商标量的增加导致商标审查员目不暇接,容易错判误判。商标申请人在进行商标注册前会通过专业的商标代理机构进行商标检索,国家商标局同意商标注册之前会排查该商标是否与已注册商标存在过高的相似度,若相似则无法注册[1]。
商标图像与普通图像存在较大的差异,其中最常用的商标由文字和图案组成,换句话说,该类型的商标在市场上的申请量是最普遍的,也是商标代理企业处理最多的一种类型的商标图像。在商标图像数据库中检索到一组相似度最高的商标图像,该过程虽然可以用传统意义的图像检索算法来实现,但是检索的效果却不尽人意,究其原因是商标图像存在以下特点:①图案单一,像素点之间没有太大的联系;②包含相同文字的商标图像,其字体形状在不同商标图像中呈现较大差异,但属于相似商标;③不同商标图像中包含的不同文字可能为同音字,但属于相似商标。
综上所述,商标图像检索与传统图像检索的最大差异在于,与查询目标图像相似的一组商标图像在视觉上并不一定特别相似。因此,本文主要研究基于内容的图像检索技术(CBIR)[2]在提高商标检索系统效率中的应用,提出一种特征融合的商标检索方法。CBIR的关键技术在于特征提取和特征匹配,提取图像的关键信息作为特征描述符,并以此作为检索的匹配依据。
1 相关工作
早期的商标检索系统,大多方法利用基于形状特征的方法来实现,因为当时的商标图像通常是二进制图像,由简单的图形单元组成,采用形状描述符就能很好地表示商标图像。Wu等[3]提出了一种基于形状区域特征和边界特征融合的商标图像检索方法。Rusinol等[4]通过计算图像的颜色直方图结合形状特征作为检索的综合特征。雷蕾等[5]提出使用Zernike矩作为全局特征,并使用边缘梯度共现矩阵作为局部特征,将特征进行融合检索从而提高检索精度与鲁棒性。胡明娣等[6]提出了一种新的颜色特征量化算法与HU不变矩的形状特征进行融合进一步提高检索效率。Yan Y等[7]提出了颜色和空间描述符的自适应融合,用于彩色商标图像检索。将颜色量化和k均值相结合以进行有效的主色提取,通过分析图像直方图,实现这两个功能的自适应融合,从而实现更有效准确的商标图像检索。Qing等[8]提取图像的LBP特征来作为图像检索的描述符。还有一些其它流行的基于SIFT的方法,比如将SIFT与MSER相结合进行图像匹配和PCA-sift等。Chen[9]提出了一种基于SIFT的商标图像搜索算法。通过计算邻近区域的梯度直方图来检测和描述特征点。再通过欧几里得距离得到从两个对应图像中提取的SIFT特征之间的相似性。汪慧兰等[10]提出一种将小波变换与SIFT特征相结合的方法,用小波变换提取到的图像轮廓与SIFT特征进行融合。商标图像规模的增多使得哈希技术也应用到商标图像检索技术中,哈希检索可以将图片的高维内容特征转为低维的哈希序列,降低了图像检索对计算机内存的要求,加快了检索速度。Yannis等[11]将CNN最后一个卷积层提取出的特征进行加权,改变特征平面权重的同时也对每个通道进行加权,取得了不错的效果。Noh H等[12]提出了一种大规模商标图像检索技术,利用采用全卷积神经网络模型ResNet50提取局部密集特征,提取的特征具有语义局部特征,还引入了一个对关键点进行选取的注意力机制,使特征匹配更加精确。Perez等[13]提出使用两个经过预训练的VGG卷积神经网络在商标图像的数据库中分别对商标图像的视觉相似性和概念相似性进行了微调训练,结果表明这两种方法融合在METU数据库上取得了不错的效果。以上的方法能提取到商标图像很好的视觉特征,而绝大部分常用的商标包含文字,由于字体千变万化,相同文字在视觉感知上却不尽相同。然而,这部分文字信息对检索算法确是非常关键的,对于商标而言,包含相同或形近字就是近似商标的充分非必要条件。但也由于这部分关键信息在视觉感知上差异较大,导致该文字信息不仅没有提取到,反而使得特征的差异更大了。
基于以上的研究,本文提出一种融合卷积特征和文字特征的方法来作为商标图像的描述,主要有以下两点贡献:①针对文字特征匹配改进编辑距离算法,提高形近字的匹配度。②提出一种基于结果融合的重排序方法,将卷积特征检索结果与文字特征匹配结果进行融合重排序,得到最终的结果。
2 本文方法
本节介绍详细的商标检索方法,如图1所示,本文检索的方法在基于深度学习的基础上融合文字检索的结果,特征提取过程需要对商标图像进行文字识别和卷积特征提取,检索过程分为基于深度学习商标检索和基于文字商标检索。最后将两者检索的结果进行融合重排序得到最终的检索结果。
2.1 基于深度学习的商标检索
本节介绍卷积神经网络的检索方法,本文收集200组不同的商标,每组共20张相似商标(如图2所示)。利用商标库的200类商标对深度网络模型NetVLAD进行分类训练。将训练好的模型保存之后,用来提取商标数据库图像的卷积特征,经过加权和局部聚合成一维向量之后,以此作为检索的索引向量。
2.1.1 特征处理
本节介绍详细的特征处理方法,本文利用商标数据集训练NetVLAD进行特征提取。对于输入的图像首先做一个预处理,使得图像输入卷积神经网络的尺寸为224*224*3,X∈RN×W×H为卷积层提取到的三维矩阵,其中N为通道(Channel)数,W和H分别为每一层特征平面(Feature Map)的长和宽。即利用提取到的卷积层特征进一步对每一个特征平面的元素进行一个权重的赋予,并且每个通道也赋予不同的权重。按照这样的方式。假设xkij∈X,s为三维的权重矩阵,x′kij表示加权后的特征,那么
(1)
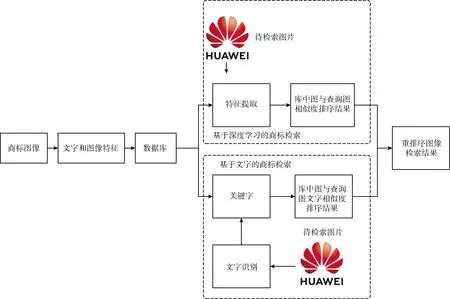
图1 本文方法框架

图2 商标分类数据集
bk表示每个通道的权重大小,aij表示特征平面上每个元素赋予的权重,因此skij=bkaij。 由于图像感兴趣区域经过卷积滤波之后会有较强的响应,本文利用卷积特征平面的特征值作为加权的依据
(2)
(3)
其中,对平面 (i,j) 点处的权重参数为该点的通道权重与平面权重的乘积。
2.1.2 特征聚合
局部聚合的思想来源于局部特征拥有更好的匹配效果,全局的CNN特征缺少几何不变性,限制了对可变场景的分类和匹配,因为全局的CNN特征包含了太多的空间信息。以往对局部特征的描述也有很多方法,比如SIFT(尺度不变特征变换)描述子,它的思想是在图像感兴趣区域提取到稳定的特征点,比如边缘或目标物体的区域,该特征点不随图像的缩放或者旋转等操作而改变。对于商标图像而言,感兴趣区域比较集中。通过对CNN特征加权,实际上也是为了突出感兴趣区域。这样在进行局部特征聚合的时候,可以使得商标有Logo的区域得到更大的权重。
通过对卷积层加权后输出的特征为X′∈RN×W×H, 我们将该三维的向量视为共 (W×H) 个长度为D一维的向量。聚合的思想与Bag of Features[14]和文献[15]类似,也是将已提取到的描述子进行聚类最终得到一维的向量特征。本文采用NetVLAD池化方法,将长度为D的一维向量看作一个个的描述子,NetVLAD可以理解成一种Pooling的方式,即将多个维度不同的特征聚合,生成一个能够描述这些特征集的向量。
2.1.3 特征匹配
利用余弦距离来度量向量之间的相似度,通过计算两个相同长度的向量之间的夹角余弦值来衡量它们之间的相似度。向量夹角余弦值的范围在[-1,1]之间,向量之间夹角越小则余弦值越大,代表两个向量越相似,反之亦然。余弦距离对向量的绝对值数值大小不敏感,因为它反映的是两个向量在方向上的相似度。上一步将图像聚合成一维向量特征后,本节将采用L2归一化和PCA-Whitening对特征进一步处理,由于本文采用的是余弦距离,所以向量绝对值的大小不影响最后的距离计算。计算特征向量X与Y的余弦距离公式如下
(4)
2.2 基于文字特征的商标检索
本文采用CRNN算法进行商标文字识别,CRNN网络是端到端可训练的网络模型,只需要图像和文字标注即可进行训练。百度中文识别大赛的数据集都采集自中国街景,并由街景图片中的文字行区域(例如店铺商标、地标等)截取出来而形成,所有图像的文字区域利用仿射变换,等比映射为一张大小为100*32像素的图片。该数据集部分图像如图3和图4所示。

图3 七星豹电动车

图4 魅派集成吊顶
通过CRNN文字识别将商标库中的文字商标图像的识别结果作为数据库中商标图像的文字特征关键字。
2.2.1 文字匹配
基于文字特征关键字来进行检索相当于给定一个字符串集合和待查询字符串,从字符串集合中找出相似的字符串,通过该方法找到对应的相似商标图像。返回相似结果采用基于top-k的字符串匹配,给定数据库中商标文字的字符串集合P,从图片识别的文字结果作为待查询的字符串q,从字符串集合中P中查找与待查询字符串q比较相似的前k个字符串。比如从字符串集合P={“阿里巴巴”, “阿里”, “阿里爸爸”, “啊里巴”}, 对于待匹配字符串q=“阿里巴巴”,使用top-1查询得到的结果为 {“阿里巴巴”}。 字符串近似匹配一般有海明距离,J-W距离、编辑距离[16,17]等。商标图像中文字的音、形相似也可以判断为相似图像的特点,本文提出一种基于融合音形的编辑距离算法,利用汉子的拼音编码和笔形编码,通过比较汉字的编码得到单个汉字的相似度,结合单个汉字的相似度的和以及编辑距离的值得出两个字符串的相似度。
编辑距离算法是根据计算一个字符串转换到另一个字符串所需要最少操作(对字符串进行插入、删除或替换)来度量两个字符串的相似度[17]。如果编辑距离越小,两个字符串就越相似,比如计算a,b两个字符串的相似度,编辑距离为ED(a,b), 标准化编辑距离为NED(a,b), 公式如式(5)所示
(5)
标准化编辑距离NED的取值范围是[0,1],标准化编辑距离越大说明两个字符串越相似。两个字符串a,b的编辑距离可以通过动态规划的算法进行计算,首先构造一个以 |a|+1为行, |b|+1为列的矩阵D[|a|+1,|b|+1], 先给矩阵D[|a|+1,|b|+1] 的第一行和第一列赋值从0开始递增,D[i][0]=i, 0≤i≤|a|,D[0][j]=j, 0≤j≤|b|。 编辑距离计算公式如式(6)所示
D[a][b]=min(D[i-1][j]+1,D[i][j-1]+1,D[i-1][j-1]+cost)
(6)
其中,D[i-1][j]+1为删除一个字符的操作,D[i][j-1]+1为增加一个字符串的操作,D[i-1][j-1]+cost为替换字符操作,如果a[i]=b[j],cost的值为1,否则cost的值为0。以此迭代计算出最后D[a][b] 的值为编辑距离ED(a,b) 的值。
2.2.2 改进编辑距离算法
由于传统的编辑距离算法并没有考虑到中文字符的音和形,在替换、删除和增加操作的权重都是1,而商标图像中文字的音和形相似对于判断近似商标图像都比较重要,为了增加商标图像中汉字的音和形的影响,本文提出一种改进的编辑距离算法,融合汉字的音和形,也就是拼音和五笔,表1为一些汉字的五笔编码和拼音。将基本字符集中使用五笔编码方式的常用的6757个汉字,按照编码规则,表示成代表其字形信息的五笔编码,并组建常用汉字的字形数据库。每个汉字都可以使用至多4个字母表示其五笔编码,部分汉字的拼音和五笔编码见表1。
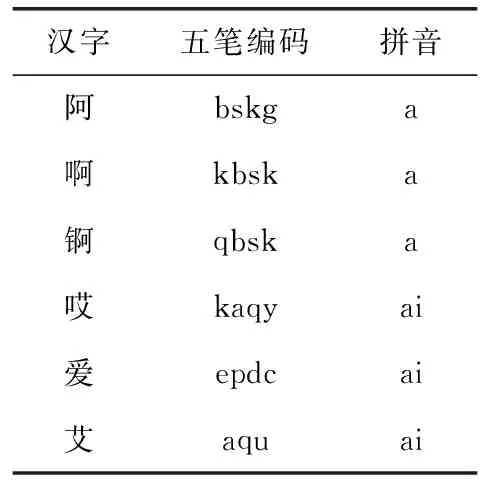
表1 汉字编码
提出一种融合音和形的编辑距离算法如式(7)~式(9)所示
(7)
(8)
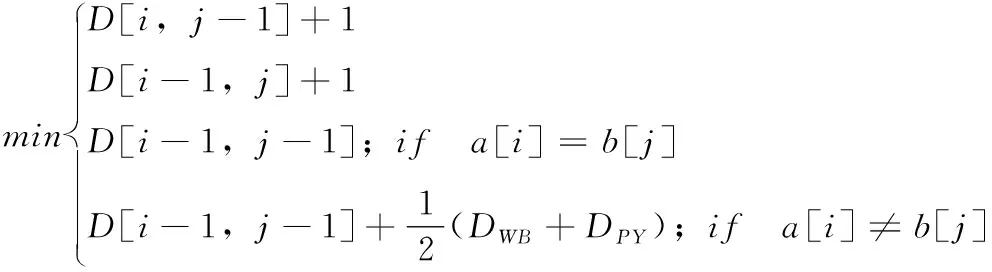
(9)
其中,式(7)中的DWB为两个字符的五笔差异,式(8)中的DPY为两个字符的拼音差异,EDWB(a[i],b[j]) 为两个字符的五笔编辑距离,EDPY(a[i],b[j]) 为两个字符拼音的编辑距离,MAX(|a[i]WB|,|b[j]WB|) 为两个字符五笔长度取较长的值,MAX(|a[i]PY|,|b[j]PY|) 为两个字符拼音长度取较长的值。一般来说汉字的五笔编码不超过4个字母,所以两个字符五笔编码的编辑距离不会超过4,汉字的拼音编码最长为6个字母,两个字符拼音的编辑距离最大为6。在汉字中存在着多音字的情况,在3500个常用汉字中,就有250多个多音字,一个汉字的读音有可能有5个之多。如“重”字就有“chong”和“zhong”两种读音,在计算两个字符的拼音的编辑距离时,如果一个汉字存在多音字,选取两个字符的拼音编辑距离较小的读音。该算法的伪代码如算法1所示。
算法1:改进的编辑距离算法
开始
输入:a:待匹配的字符串
b:目标匹配的字符串
输出:a,b两个字符串的编辑距离d[i,j]
字符串a的长度为n,字符串b的长度为m
构造一个矩阵d[m+1,n+1], 初始化矩阵第一行为0到n,初始化第一列为0到m
for(i ← 1 tom) do
for(j ← 1 to n) do
ifa[i]==b[j] then
cost=0
else
cost=d[i-1,j-1] +1/2(DWB +DPY) //DWB和DPY为拼音和五笔的编辑距离的均值
d[i,j]=min{d[i-1,j]+1,d[i,j-1]+1,d[i-1,j-1]+cost}
returnd[m,n]
结束
2.3 检索与重排
检索结果融合与重排序,本节详细介绍如何将2.1与2.2的检索结果进行融合重排序进而得到最终的检索结果,单纯利用2.1或2.2得到的检索结果并不算特别好,都有各自的局限性。本文针对大量商标图像中含有文字和图形组成的混合图像,提出一种基于排序列表相似度分数融合的图像相似度方法,在计算图像相似度时,将基于深度学习和文字识别的检索结果的排序表融合在一起得到最后的检索排序结果。现有的根据多个排序列表进行相似度融合的方法主要有:IRP(inverse rank positon)算法、BC(borda count)算法等。
本文提出的相似度排名列表融合算法首先在基于深度学习的相似度排名表中依次判断是否出现在文字检索相似度排名列表中,如果该图像在两种排名列表中均出现,则将该图片排在最终相似度排名列表的前面,然后将两种排名列表剩下的图片依次循环插入到最终相似度排名列表中。该算法的如算法2所示。
算法2:排名融合
开始
输入:Q:基于深度学习的检索结果排名图像,{Q[q]:1≤q≤N}
T:基于文字的检索结果排名图像, {T[t]:1≤t≤N}
输出:S:Q、T两者排名结果进行融合的相似度排名图像, {S[s]:1≤s≤N}
for(q←1 toN) do
for(t←1 toN) do
ifQ[q]==T[t] then
S[s]←Q[q]
Break;
for(循环次数←1 toN-s) do
S←将T[t]∉S图像插入最终相似度排序列表中
S←将Q[q]∉S图像插入最终相似度排序列表中
returnS
结束
图5是利用排名融合算法对基于深度学习检索和文字检索的相似度排名列表进行融合的前5个检索图像的排序,基于深度学习检索的前5个检索图像的排序结果为 {a,b,c,d,e}, 文字检索的前5个检索图像的排序结果为 {f,a,g,c,b}, 根据算法2,首先依次遍历基于深度学习检索的前5个检索图像的排序a,图片a也出现在文字检索结果排名列表中,将图片a排在最终检索列表的第一位,后面依照此规则得到检索结果排名为{a,b,c}, 再依次将两种排名剩下的图片插入到最终检索结果排名列表中,得到最终的检索结果排名为 {a,b,c,f,d}。
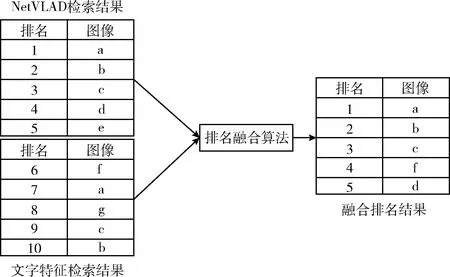
图5 融合排序算法
3 实 验
3.1 数据集
本文收集1000组商标进行检索实验,每一组包含15张相似商标图像,一共15 000张商标图像作为测试集(以下称为Logos)。每一组商标图像从Logo1-Logo15进行编号,每一组的Logo1作为检索的查询图像,按照与Logo1的相似度从大到小排序的原则从Logo2到Logo15对该组的商标进行编号。图6为两组相似商标。

图6 相似商标图像
3.2 实验结果分析
本文首先在包含形近字或同音字的商标上面进行实验,利用本文提出的改进编辑距离算法1计算包含形近字或同音字的部分词语的距离,并与改进前的算法作比较,表2为改进后和改进前的编辑距离一些字符串相似度的比较结果。
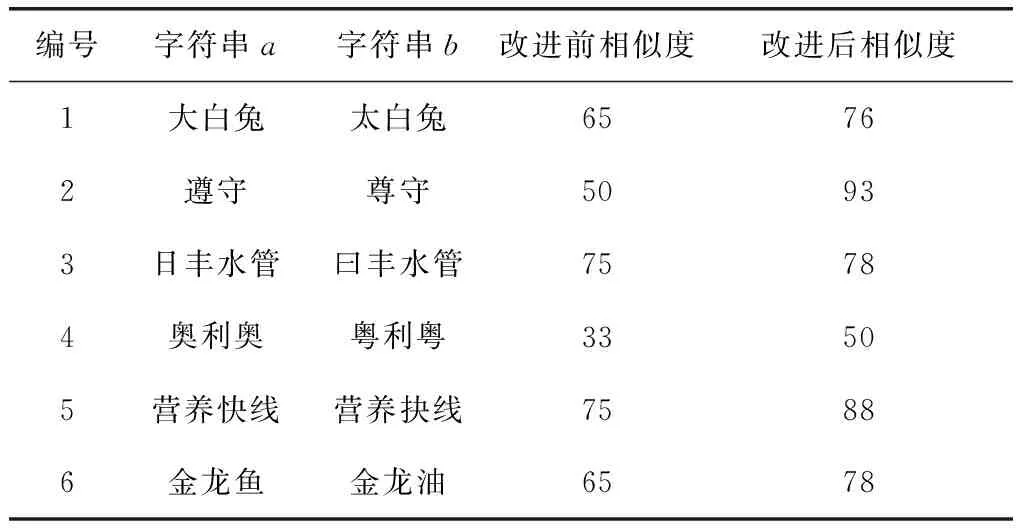
表2 比较结果/%
上面的字符串列表中,列举了一些易混淆的商标名称,这些商标名称中包含了形近字和同音字的情况。从改进后算法的相似度结果来看,针对易混淆的商标名称,改进后的结果比传统的编辑距离计算相似度效果更好。因此,利用改进的编辑距离算法就可以更好找出含有相似度比较高的文字的商标图像。
本文的检索方法在Logos上进行评估,对Logos分别进行文字检索和卷积特征检索,最终将结果进行融合重排序。检索精度相比于深度学习检索方法得到的结果要高出将近3个百分点。评估结果如图7所示。
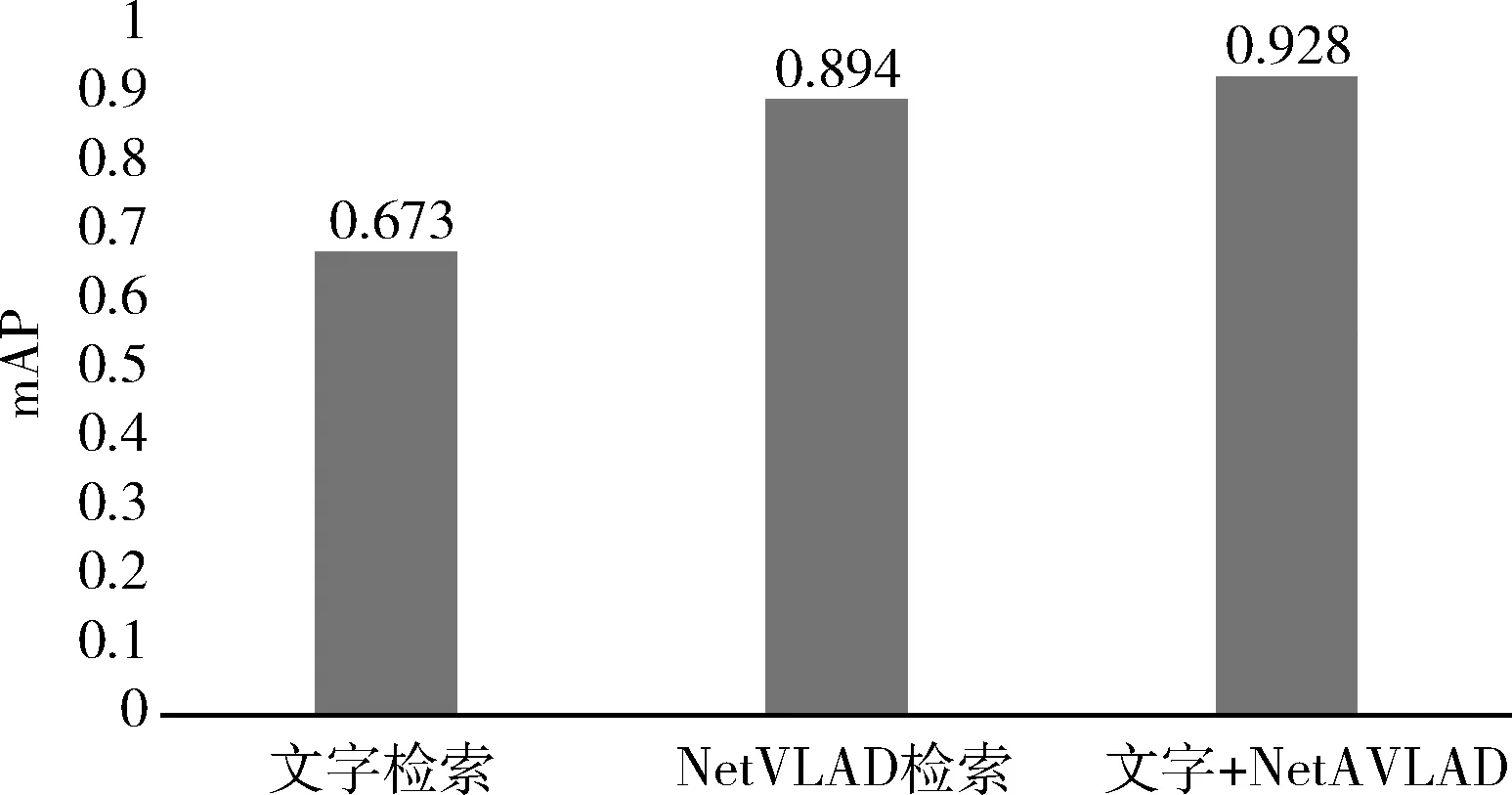
图7 评估结果
本文对文中提到的部分方法进行实验评估,本文选取3个比较有代表性的算法在商标数据集上评估,包括深度学习算法经典模型VGG16、HU矩特征和SIFT这3种图像检索算法。由于Logos数据集的商标图像都包含文字部分,为了使得结果更加公平,所有算法都在Logos上进行实验评估,图8展示了不同算法在返回图像数量10张到50张的查全率的变化。
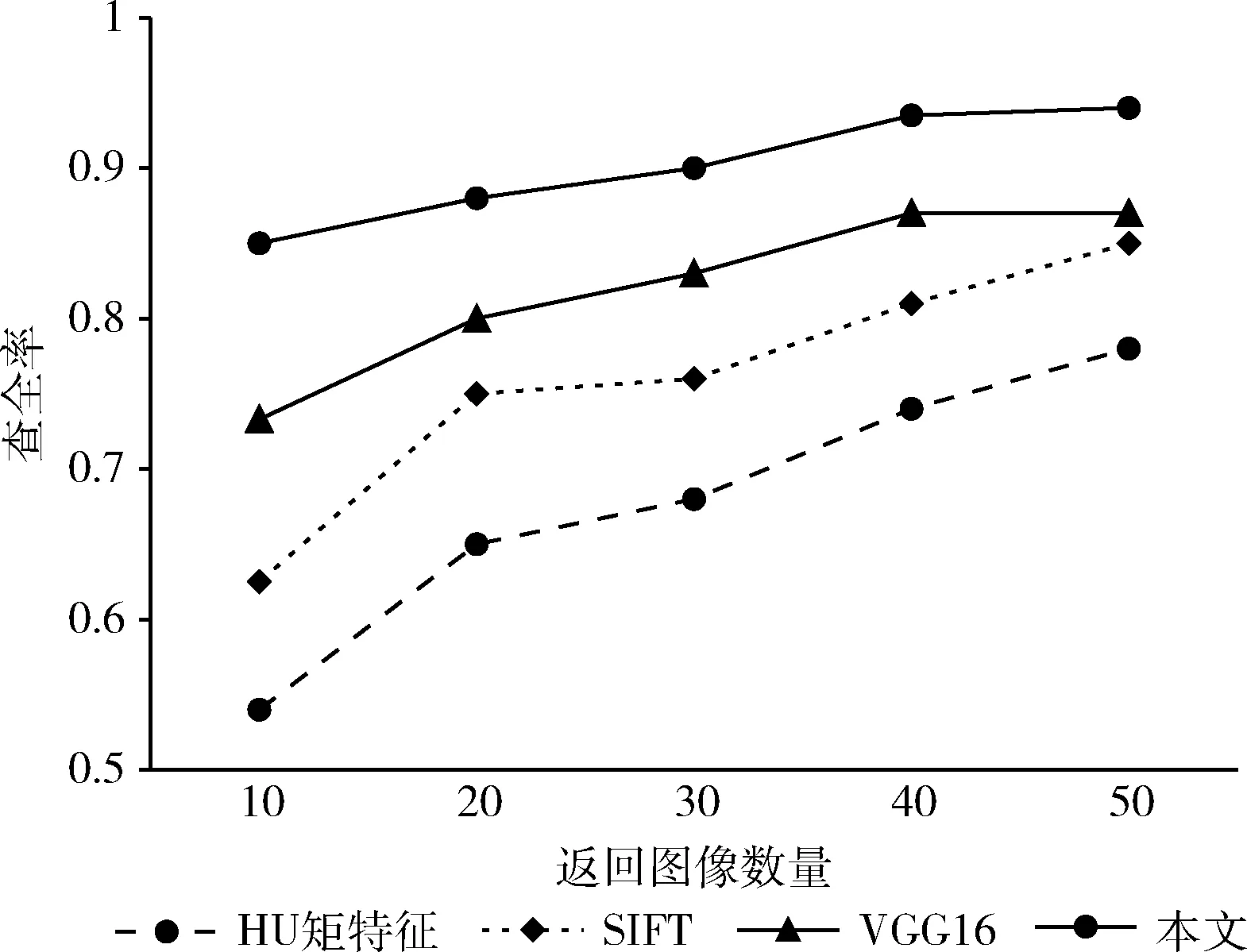
图8 实验评估结果
本文分别对不同算法之间的查准率和查全率进行实验比对。在实验过程中,设置返回的前top-k=50。表3是实验对比结果。
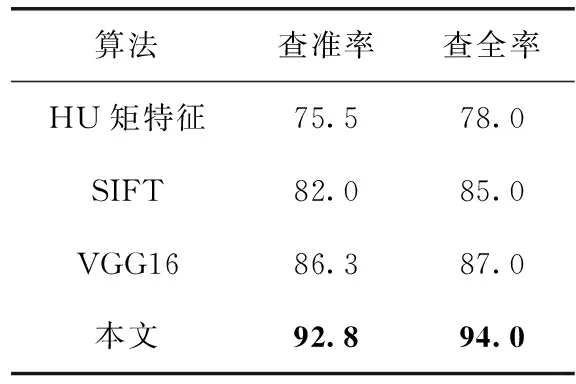
表3 不同方法实验对比结果/%
4 结束语
本文提出一种商标Logo的检索方法,利用商标图像的包含文字的特性,将文字匹配的结果与卷积特征检索的结果进行融合。另外,本文提出一种改进的编辑距离算法,能大大提高形近字的匹配率。随着我国的商标注册量直线飙升,在数据库中更加精准找到相似商标可以降低企业申请商标的成本。为了提高卷积特征的匹配率,针对商标图像的特性重新训练了网络模型,利用训练后的网络模型来提取特征,并对特征进一步加权和局部聚合,使得最后得到的特征描述符能更好地表示商标Logo图像。在融合文字特征搜索结果之后结果提高了3个百分点。实验结果表明,本文方法对商标检索方面具有良好的表现,更加适用于商标Logo图像的检索。
猜你喜欢
无线互联科技(2020年11期)2020-12-01
科学与财富(2019年27期)2019-10-25
数码世界(2019年9期)2019-09-07
电子制作(2019年14期)2019-08-20
小学生导刊(2018年34期)2018-12-18
科教导刊·电子版(2016年30期)2016-12-26
中国新通信(2016年17期)2016-11-17
山东青年(2016年3期)2016-02-28
中国信息技术教育(2015年21期)2015-09-10
母子健康(2015年1期)2015-02-28
