
基于卷积自编码生成式对抗网络的高分辨率破损图像修复
2022-05-23 03:55侯向丹刘昊然刘洪普
中国图象图形学报 2022年5期
侯向丹,刘昊然,刘洪普
河北工业大学人工智能与数据科学学院,天津 300401
0 引 言
图像是生活中常见的信息载体形式,只有图像完好才可以保证信息传输的完整性,但经常会有所需图像文件破损或遮掩现象,例如照片破损、监控图像中所需内容遮掩等。为了保证图像信息传递的完整性,提出了一系列图像修复方法。然而,传统的修复方法,例如基于纹理合成技术进行图像修复的方法(Efros和Freeman,2001;Criminisi等,2003;Komodakis,2006;Barnes等,2009),虽然可以在纹理上进行修复,但是缺乏对破损图像全局结构和图像语义的把握。
随着深度学习的发展,提出了两类基于深度学习的图像修复方法,即基于卷积自编码网络的图像修复方法和基于对抗生成网络的图像修复方法,二者各有优劣。基于卷积自编码网络的图像修复方法较多。Pathak等人(2016)提出的CE(context-encoders)方法通过周围图像信息推断缺失内容。Iizuka等人(2017)和Li等人(2017)在CE网络基础上加入global和local两个判别器,提高了细节修复能力。Yu等人(2018)、Song等人(2018)、Nazeri等人(2019)和Xiong等人(2019)将修复分为初步修复精细修复两个步骤,降低修复难度的同时提升了修复效果。这些方法虽然可以对破损图像在色彩和内容上进行较好的修复,但是细节纹理的修复效果并不理想,修复区域会出现模糊现象,在破损区域较大时,由于可利用信息不足,导致修复效果欠佳。基于对抗生成网络的图像修复方法也得到广泛应用。Yeh等人(2017)提出一种基于DCGAN(deep convolutional generative adversarial network)的破损图像修复方法,思路是从图像数据库中搜索与待修复图像完好部分最相似的图像,将破损区域用搜索出的图像进行覆盖,从而实现图像修复。通过输入不同的高斯噪声,DCGAN网络可以产生各样的图像,这些生成的图像组成为用于搜索的数据库,解决了Hays和Efros(2007)方法中数据库容量有限的缺点。该方法与基于卷积自编码网络的图像修复方法相比,对图像的纹理修复效果有所提升,对破损区域周围信息的依赖度降低,更适合用于破损区域较大图像的修复工作。但是该方法的缺点也很明显,由于从高斯噪声到高维空间图像映射关系的复杂性,使得DCGAN训练很困难,随着生成图像分辨率的提高,训练难度逐渐增大,容易出现模式崩塌现象(Goodfellow,2017),产生缺乏真实性且单一的图像。因此DCGAN网络适用于低分辨率图像修复工作,对64×64×3大小的破损图像修复效果较好,但对高分辨率图像无法完成修复工作。
受AEGAN(auto-encoder generative adversarial network)网络(Wang等,2018)启发,本文将卷积自编码网络(convolutional auto-encoder,CAE)(Masci等,2011)与生成式对抗网络(generative adversarial network,GAN)(Goodfellow等,2014)相结合,提出一种新的网络模型:卷积自编码生成式对抗网络(convolutional auto-encoder generative adversarial network,CAE-GAN)。如图1所示,网络训练不再是直接由高斯噪声空间Pz到图像高维空间Px,而是从高斯噪声空间到编码器提取的低维特征空间Pk的映射,生成的低维向量经过训练好的解码器解码成为高维度空间的高分辨率图像。通过降低映射关系的学习难度,使网络更容易训练,降低了发生模式崩塌的可能性,生成的图像也更加逼真。随后,经过搜索找到与破损图像完好部分最相似的生成图像,将破损部分用生成图像覆盖,完成高分辨率图像的修复。本文方法相较于其他方法主要解决了两个问题:1)可实现连续大面积破损图像修复。本文方法对待修复破损图像已知信息的依赖性较小,在修复连续大面积破损图像时有优势。2)可实现高分辨率图像修复。本文方法通过降低映射学习难度,提升了网络训练效果,可以由高斯噪声生成高分辨率图像,进而实现高分辨率图像修复。
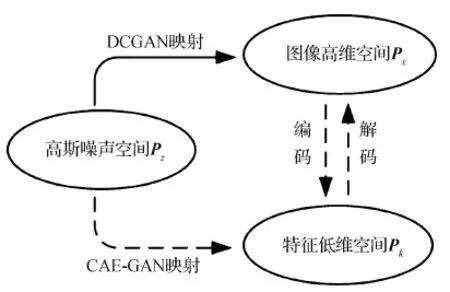
图1 DCGAN映射与CAE-GAN映射
1 相关工作
1.1 卷积自编码网络
自编码网络由Rumelhart等人(1986)提出,并应用于高维复杂的数据处理,通过将数据先下采样再上采样,实现了不同映射关系的学习。卷积神经网络(convolutional neural network, CNN)(Lecun等,1998)出现后,Masci等人(2011)提出一种基于卷积层的自编码网络—卷积自编码网络(CAE),具有出色的特征提取功能,在数字识别,例如在MNIST(mixed national institute of standards and technology database)数据集上进行数字识别,在CIFAR10(canadian institute for advanced research 10)数据集上进行对象识别,都有出色的表现。

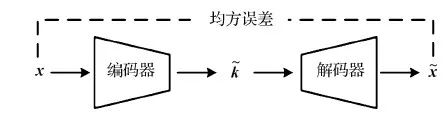
图2 CAE网络结构
1.2 生成式对抗网络
生成式对抗网络(GAN)是Goodfellow等人(2014)提出的一种非监督学习的网络框架,生成对抗网络中有生成器和判别器两个网络模型。生成器尽可能使生成图像以假乱真,迷惑判别器使其难辨真伪,判别器判断输入是数据集图像还是生成器合成的图像。二者相互对抗训练,不断更改自己的网络参数,直到判别器无法分辨合成图像与数据集图像。GAN的优化公式为


(1)
式中,V(D,G)表示函数值,E表示期望,z表示输入生成器的噪声,G(z)表示生成器生成的图像,D(x)表示判别器判断是真实图像的概率,x为真实数据。
随着对GAN的研究,相继提出了许多GAN的变体。深度卷积生成对抗网络(DCGAN)(Yeh等,2017)将卷积神经网络引入GAN中,弥补了用于监督学习的卷积神经网络与用于无监督学习的GAN之间的差距,使传统GAN网络的训练更稳定,多项研究已经验证该网络可以用于生成高质量的图像(Denton等,2015;Radford等,2015)。
2 基于CAE-GAN的高分辨率图像修复
2.1 网络介绍
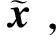
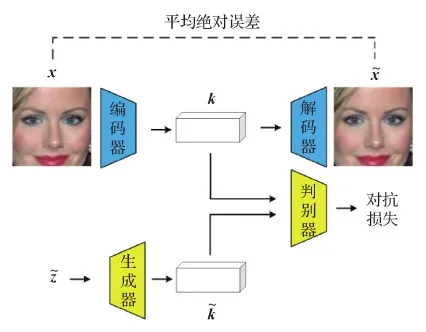
图3 CAE-GAN网络结构
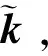
2.2 训练与修复
(2)
式中,n表示mini-batch大小,Enc表示被编码器处理,Dec表示被解码器处理。
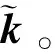
(3)
式中,D表示判别器,D(x)表示判别器对图像x的评价值;G表示生成器,G(z)表示生成器根据高斯噪音生成的图像。最终,生成器能够生成以假乱真的特征矩阵,即G(z)=Enc(x)。模型训练完成后,可将生成器根据随机一组高斯噪声z生成的特征矩阵,通过解码器解码为高分辨率图像,从而实现了从高斯噪声空间到高分辨率图像空间的映射。
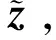

图4 搜索相似图像流程

(4)
式中,M为掩码,是与图像相同大小的矩阵,该矩阵中每一个元素只有0或1两种值。通过与图像进行哈达玛积(⊙)运算,结果仅保留掩码中值为1对应部分内容,舍弃值为0对应部分;Dec表示被解码器处理。搜索目标是使破损图像y未破损部分与生成图像对应部分的像素值相同。衡量生成图像的真实性差距的计算式为
(5)
当判别器判断生成的图像越真实时,Ld越小。将式(4)与式(5)结合,得到总损失函数,即
(6)
式中,γ是一个控制Ls与Ld权重的参数。通过训练不断改变NetNoise的参数值,使损失值不断变小,生成图像与待修复图像完好部分逐渐接近。最终将搜索到的图像的对应部分粘贴到破损图像上,实现高分辨率图像的修复。
3 实 验
实验分为两个阶段。第1阶段训练CAE-GAN网络,使其具备根据高斯噪声生成逼真高分辨率图像的能力。第2阶段通过搜索合适的高斯噪声值,使生成网络据其生成的图像与待修复图像完好部分相似,然后将待修复图像破损区域用生成图像覆盖,达到高分辨率图像修复的目的。训练CAE-GAN及搜索合适生成图像流程具体步骤如下:
1)编码器和解码器未收敛时进行:
ki←Enc(xi);

结束循环;
固定编码器和解码器的网络参数θEnc和θDec。
2)生成器和判别器未收敛时进行:
ki←Enc(xi);
结束循环;
固定CAE-GAN网络参数θD和θG。
3)NetNoise未收敛时进行:


结束循环;
覆盖损坏位置。
3.1 数据集与网络结构
在人脸数据集CelebA(Liu等,2015)、街景门牌号码数据集SVHN(street view house number)(Netzer等,2011)、Oxford 102 flowers数据集和Stanford cars数据集(Krause等,2013)上分别进行高分辨率图像修复实验。CelebA人脸数据集包含202 599幅人脸图像,以人脸为中心,将其裁剪为90×90×3的方形图像。SVHN街景门牌号数据集包含99 289幅门牌号图像,以号码为中心将其裁剪为70×70×3的方形图像。Oxford 102 flowers数据集包含102种英国常见的花卉图像,共8 189幅图像,裁剪为450×450×3的方形图像。Stanford cars数据集包含16 185幅汽车图像,以汽车为中心裁剪为480×480×3的方形图像。由于GAN网络训练要求数据集较大,而满足要求的公开数据集较少,高分辨率图像数据集更是匮乏。因此,对4个数据集裁剪后的方形图像,利用PIL(python image library)模块扩大为512×512×3的图像,作为高分辨率图像进行实验。本文实验虽然没有直接使用高分辨率图像,但是在数据层面上这样处理后的图像数据量与高分辨率图像相同,均由512×512×3组成,因此可以看做是高分辨率图像进行的实验。在每个数据集中抽取500幅图像作为测试集,其余作为训练集。
实验包含5个网络,分别为编码器、解码器、生成器、判别器以及修复阶段用于搜索合适高斯噪声的NetNoise。各网络结构如表1所示,其中,LeakyReLU、ReLU、Tanh和Sigmoid为激活函数。需要注意的是,NetNoise网络的输出层×3,因为最后一层的Tanh激活函数将数据限制在[-1,1],不能很好地映射出高斯分布,×3使输出为[-3,3],使输出值符合高斯分布的概率达到99.87%。

表1 编码器、解码器、生成器、判别器和NetNoise的结构数据
3.2 网络训练与图像修复
3.2.1 网络训练
在训练阶段,首先训练编码器和解码器两个网络,使高分辨率图像先编码再解码。然后训练生成器和判别器两个网络,使生成器可以根据随机高斯噪声生成不同的编码,进而训练好的解码器解码为高分辨率图像。在修复阶段,训练NetNoise网络生成合适的噪声,通过训练完成的生成器和解码器上采样后,输出与待修复图像相似的生成图像。训练阶段设置batch大小为4,使用Adam(Kingma和Ba,2017)优化器,学习率设置均为0.000 2,其余参数使用默认值。
训练编码器和解码器时,发现损失值不再下降要停止训练,这是为了防止模型过拟合,保持模型的泛化能力,否则下一阶段训练时会出现解码后图像多样性低的情况。训练生成器和判别器时,加载并固定训练好的编码器和解码器两个网络的参数。在CelebA数据集上的训练损失曲线如图5和图6所示。

图5 CAE-GAN与DCGAN的判别器损失值对比

图6 CAE-GAN与DCGAN的生成器损失值对比
从图5和图6可以看出,CAE-GAN从第7回合开始,生成器与判别器的损失值保持平稳,网络学习处于平衡状态。DCGAN在第20回合时,判别器损失值陡降,生成器的损失值陡升,这一时刻发生了模式崩塌。印证了前文所述生成对抗网络在映射难度较大时容易发生模式坍塌,通过降低映射难度,可以使生成器与判别器保持平稳地进化。
图7展示了CAE-GAN与DCGAN在CelebA数据集上随机生成的512×512×3图像。可以看出,与DCGAN方法相比,本文方法生成的图像更加逼真,人脸五官线条明朗,轮廓清晰,图像的多样性更好,可以生成不同肤色不同发色的面部图像。

图7 生成图像对比
为了评估生成图像的质量,使用FID(Fréchet inception distance)值(Heusel等,2017)作为评价指标。FID值计算的是两个多维变量分布之间的距离,能够表示生成图像的多样性和质量,FID越小,图像多样性越好,质量也越好。本文分别计算了两种网络生成图像的FID值,如表2所示。可以看出,本文方法生成图像的FID值为47.87,远小于DCGAN网络生成图像的FID值84.52,说明本文方法生成的图像空间分布与CelebA数据集更加接近,生成的图像质量更高,多样性更好。

表2 生成图像FID值对比
在修复阶段,训练的回合数为100,输入为1×100、元素全为1的向量[1,1,…,1],输出为100×1×1的高斯噪声,训练NetNoise网络使其输出的向量不断优化,使生成器和解码器根据该高斯噪声生成的图像逐渐接近待修复图像。
3.2.2 图像修复
制作破损图像。1)制作规则破损中的中心破损图像和半侧破损图像、不规则破损中的噪声破损图像时,先制作512×512×1的矩阵蒙版,将需要制作成破损的地方置0,其余置1,与完好图像矩阵进行哈达玛积运算,得到待修复的破损图像。2)制作高斯噪声破损时,将小于0.7的值置0,其余置1,这样制作的破损图像破损率为75.8%。3)制作不规则破损图像中的随机破损时,先使用画图工具在512×512×1的白板上随意描绘,保存后将绘画区域置0,其余区域置1,如图8所示。然后与完好的图像进行哈达玛积运算,得到待修复的随机破损图像,如图9所示。

图8 随机破损蒙版示例

图9 破损图像制作过程
衡量生成图像与待修复图像相似度时同样使用该蒙版,将生成图像与蒙版进行哈达玛积运算,结合训练完成的判别器,计算出用于NetNoise训练的损失函数,γ取值为0.002。经过100回合迭代训练,找到与待修复图像完好部分相似度最高的生成图像。然后将待修复图像破损部分用生成图像覆盖,完成高分辨图像的修复。
3.3 结果对比
为了验证本文方法的性能,本文与CE(Pathak等,2016)和DCGAN(Yeh等,2017)方法进行对比。与CE方法对比的目的是为了展示基于对抗生成网络的方法(如本文方法与DCGAN)更适用于大面积破损图像的修复。与DCGAN方法对比是为了展示本文方法更适用于高分辨率图像的修复。
结果对比包含定性和定量对比两方面。定性对比主要是观察修复图像的颜色是否相似、纹路是否吻合、修复信息是否合理以及修复痕迹是否明显。定量对比选用峰值信噪比(peak signal to noise ratio,PSNR)(Huynh-Thu和Ghanbari,2008)和结构相似性(structural similarity,SSIM)(Wang等,2004)两个评价指标进行比较。PSNR基于对应像素点间的误差,是使用广泛的一种图像客观评价指标,值越大表示图像越相似。SSIM是一种衡量两幅图像相似度的指标,取值范围为[0,1],值越大表示图像越相似。实验计算了3种方法在CelebA、SVHN、Oxford 102 flowers和Stanford cars测试集中各500幅图像的修复数据PSNR和SSIM的平均值,统计结果如表3所示。

表3 CE、DCGAN及本文方法在CelebA测试集上的PSNR和SSIM
3.3.1 本文方法与CE对比
CE是一种自编码模型,与本文方法和DCGAN方法不同,该方法通过周围信息推断缺失内容。基于该方法又衍生了类似方法,然而这类方法在修复连续大面积破损图像时,无法从附近像素中获得提示,修复效果不佳,这是这类方法无法避免的缺陷。
在小范围破损及高斯破损图像修复时,由于破损图像周围像素可提供信息较多,CE网络修复效果与本文方法接近,甚至在一些数据集上优于本文方法。在中心破损图像修复中,CE方法修复效果与本文方法接近,如图10(a)前4行所示,但在细节纹理上略逊色于本文方法,例如第4行对红色汽车的修复,CE方法仅能还原相应颜色,而本文方法能够还原车灯等细节。在高斯破损图像修复中,CE网络和本文方法恢复的内容都较为合理,如图10(a)第5—8行所示,但本文方法修复的细节更好,例如第5行对人脸的修复,CE方法还原的肤色接近原图,但是人脸边缘比较模糊,而本文方法修复的人脸边缘更加清晰。从客观数据上看,如表3所示,在中心破损及高斯破损图像修复中,CE方法在各数据集上的PSNR值与本文方法接近,甚至超过本文方法,SSIM值虽然比本文方法低,但很接近。
随着破损面积的增加,CE网络可利用的信息量变少,修复的图像缺乏合理性,在细节纹理方面修复得也不好。本文方法对破损周围信息依赖较小,可以通过“想象”生成符合缺失部分的图像。如图10(b)(c)所示,本文方法相较于CE方法更能预测出相应内容,例如,图10(b)第1行对人脸的修复,CE方法未能修复出黑色眼镜,而本文方法修复出眼镜细节。图10(c)第3行对花朵的修复,CE方法仅能对色彩进行修复,内部花蕊未能修复出来,而本文方法修复出了内部黑色的花蕊条纹。从客观数据上看,如表3所示,在较大连续破损的破损图像修复中,本文方法修复的PSNR与SSIM均高于CE方法,尤其在car数据集上对随机破损图像的修复中,PSNR值较CE方法提升31.64%,在SVHN大面积中心破损图像修复中,SSIM值较CE方法提升18.05%。
3.3.2 本文方法与DCGAN对比
由于DCGAN训练生成512×512×3的图像难度较大,训练阶段容易产生模式崩塌,训练效果不佳,修复图像效果略差,实验采用DCGAN网络模式崩塌前最后一轮网络参数进行破损图像修复工作。
如图10所示,在修复内容匹配度上,本文方法优于DCGAN方法。例如图10(b)第6行对紫色花朵修复,由于DCGAN训练效果不佳,可生成图像多样性较低,无法修复紫色花朵的另一半,而本文方法由于训练效果好,可生成图像多样性高,可以生成与待修复破损图像内容相近图像,能够很好地完成修复工作。同时,本文方法修复纹路吻合度更高。例如图10(b)第2行对花朵修复,DCGAN修复了花蕊,但边缘连接不流畅,在破损右下角出现黄色区域。而本文方法不仅修复了花蕊,而且边缘清晰明显,修复区域与完好区域的连接顺畅,整体花蕊接近圆形,修复痕迹较少。在修复图像清晰度上,本文方法填充区域清晰度高于DCGAN方法。例如图10(b)第5行对人脸的修复,DCGAN方法基本修复出人脸另一半,且肤色也接近,但是修复的皮肤不光滑,嘴唇部分分界不明显。而本文方法修复的另一半肤色接近原图,皮肤光滑,五官清晰且分界明显。在定量比较上,如表3所示,本文方法在各数据集上对不同程度破损图像的修复数据均优于DCGAN方法,尤其在flowers数据集上修复高斯破损图像时,PSNR和SSIM值分别提升了24.4%和50.0%。

图10 破损图像修复
通过对修复结果的定性与定量分析,可以看出,本文方法相较于CE方法及DCGAN方法,对连续大面积破损图像和高分辨率破损图像的修复效果更好,更适合于连续大面积破损图像及高分辨率图像的修复工作。
4 结 论
提出CAE-GAN修复模型,能够解决大面积破损图像修复与高分辨率破损图像修复问题。将高斯噪声到图像的直接映射关系改为先从高斯噪声映射到特征矩阵,再由特征矩阵映射到图像。这种分阶段的处理方式降低了对抗生成网络的训练难度,使网络可以根据高斯噪声生成以假乱真的高分辨率图像。然后,利用NetNoise网络搜索出相似图像,将待修复图像的破损区域使用搜索出的图像覆盖,完成大面积破损的高分辨率图像的修复工作。实验对比了CE方法与DCGAN方法。与CE方法相比,本文方法对待修复图像已知信息依赖度小,仅需搜索与待修复图像已知部分相似的图像,对应位置进行覆盖即可,对比实验表明本文方法在修复大面积破损时效果有所提升。与DCGAN方法相比,本文方法修复细节更好,内容匹配度更高,对高分辨率破损图像修复效果有所提升。但是本文方法也存在不足之处,由于在高分辨率图像映射到低维特征矩阵时会有信息损失,因此最终生成的图像会有模糊现象。为了解决这一问题,在下一阶段将研究用于图像特征提取的网络模型,更加科学合理地提取有价值的特征信息。
参考文献(References)
Badrinarayanan V,Kendall A and Cipolla R.2017.SegNet: a deep convolutional encoder-decoder architecture for image segmentation.IEEE Transactions on Pattern Analysis and Machine Intelligence,39(12): 2481-2495[DOI: 10.1109/TPAMI.2016.2644615]
Barnes C,Shechtman E,Finkelstein A and Goldman D B.2009.PatchMatch: a randomized correspondence algorithm for structural image editing.ACM Transactions on Graphics,28(3): #24[DOI: 10.1145/1531326.1531330]
Criminisi A,Perez P and Toyama K.2003.Object removal by exemplar-based inpainting//Proceedings of 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Madison, USA: IEEE: #1211538[DOI: 10.1109/CVPR.2003.1211538]
Denton E,Chintala S,Szlam A and Fergus R.2015.Deep generative image models using a Laplacian pyramid of adversarial networks//Proceedings of the 28th International Conference on Neural Information Processing Systems.Montreal, Canada: MIT Press: 1486-1494
Efros A A and Freeman W T.2001.Image quilting for texture synthesis and transfer//Proceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques.New York, USA: ACM: 341-346[DOI: 10.1145/383259.383296]
Goodfellow I.2017.NIPS 2016 tutorial: generative adversarial networks[EB/OL].[2020-09-21].https://arxiv.org/pdf/1701.00160.pdf
Goodfellow I J,Pouget-Abadie J,Mirza M,Xu B,Warde-Farley D,Ozair S,Courville A and Bengio Y.2014.Generative adversarial nets//Proceedings of the 27th International Conference on Neural Information Processing Systems.Montreal, Canada: MIT Press: 2672-2680
Hays J and Efros A A.2007.Scene completion using millions of photographs.ACM Transactions on Graphics,26(3): #1276377-1276382[DOI: 10.1145/1276377.1276382]
Heusel M,Ramsauer H,Unterthiner T,Nessler B and Hochreiter S.2017.GANs trained by a two time-scale update rule converge to a local nash equilibrium//Proceedings of the 31st International Conference on Neural Information Processing Systems.Long Beach, USA: Curran Associates Inc.: 6629-6640
Huynh-Thu Q and Ghanbari M.2008.Scope of validity of PSNR in image/video quality assessment.Electronics Letters,44(13): 800-801[DOI: 10.1049/el:20080522]
Iizuka S,Simo-Serra E and Ishikawa H.2017.Globally and locally consistent image completion.ACM Transactions on Graphics,36(4): #107[DOI: 10.1145/3072959.3073659]
Johnson J,Alahi A and Li F F.2016.Perceptual losses for real-time style transfer and super-resolution//Proceedings of the 14th European Conference on Computer Vision.Amsterdam,the Netherlands: Springer: 694-711[DOI: 10.1007/978-3-319-46475-6_43]
Kingma D P and Ba J.2017.Adam: a method for stochastic optimization[EB/OL].[2020-09-21].https://arxiv.org/pdf/1412.6980.pdf
Komodakis N.2006.Image completion using global optimization//Proceedings of 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition.New York, USA: IEEE: 442-452[DOI: 10.1109/CVPR.2006.141]
Krause J,Stark M,Deng J and Li F F.2013.3D object representations for fine-grained categorization//Proceedings of 2013 IEEE International Conference on Computer Vision Workshops.Sydney,Australia: IEEE: 554-561[DOI: 10.1109/ICCVW.2013.77]
Lecun Y,Bottou L,Bengio Y and Haffner P.1998.Gradient-based learning applied to document recognition.Proceedings of the IEEE,86(11): 2278-2324[DOI: 10.1109/5.726791]
Li Y J,Liu S F,Yang J M and Yang M H.2017.Generative face completion//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition.Honolulu, USA: IEEE: 3911-3919[DOI: 10.1109/CVPR.2017.624]
Liu Z W,Luo P,Wang X G and Tang X O.2015.Deep learning face attributes in the wild//Proceedings of 2015 IEEE International Conference on Computer Vision.Santiago,Chile: IEEE: 3730-3738[DOI: 10.1109/ICCV.2015.425]
Nazeri K,Ng E,Joseph T,Qureshi F and Ebrahimi M.2019.EdgeConnect: generative image inpainting with adversarial edge learning[EB/OL].[2020-09-21].https://arxiv.org/pdf/1901.00212.pdf
Netzer Y,Wang T,Coates A,Bissacco A,Wu B and Ng A Y.2011.Reading digits in natural images with unsupervised feature learning//Proceedings of NIPS Workshop on Deep Learning and Unsupervised Feature Learning.Granada, Spain: NIPS: 12-17
Pathak D,Krähenbühl P,Donahue J,Darrell T and Efros A A.2016.Context encoders: feature learning by inpainting//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas, USA: IEEE: 2536-2544[DOI: 10.1109/CVPR.2016.278]
Radford A,Metz L and Chintala S.2015.Unsupervised representation learning with deep convolutional generative adversarial networks[EB/OL].[2020-09-21].https://arxiv.org/pdf/1511.06434v1.pdf
Rumelhart D E,Hinton G E and Williams R J.1986.Learning representations by back-propagating errors.Nature,323(6088): 533-536[DOI: 10.1038/323533a0]
Song Y H,Yang C,Lin Z,Liu X F,Huang Q,Li H and Kuo C C J.2018.Contextual-based image inpainting: infer,match,and translate//Proceedings of the 15th European Conference on Computer Vision.Munich,Germany: Springer: 3-18[DOI: 10.1007/978-3-030-01216-8_1]
Wang J Y,Zhou W G,Tang J H,Fu Z Q,Tian Q and Li H Q.2018.Unregularized auto-encoder with generative adversarial networks for image generation//Proceedings of the 26th ACM International Conference on Multimedia.Seoul, Korea(South): ACM: 709-717[DOI: 10.1145/3240508.3240569]
Wang Z,Bovik A C,Sheikh H R and Simoncelli E P.2004.Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Processing,13(4): 600-612[DOI: 10.1109/TIP.2003.819861]
Xiong W,Yu J H,Lin Z,Yang J M,Lu X,Barnes C and Luo J B.2019.Foreground-aware image inpainting//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Long Beach, USA: IEEE: 5840-5848[DOI: 10.1109/CVPR.2019.00599]
Yeh R A,Chen C,Lim T Y,Schwing A G,Hasegawa-Johnson M and Do M N.2017.Semantic image inpainting with deep generative models//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition.Honolulu, USA: IEEE: 6882-6890[DOI: 10.1109/CVPR.2017.728]
Yoo D,Kim N,Park S,PaekIn A S and Kweon I S.2016.Pixel-level domain transfer//Proceedings of the 14th European Conference on Computer Vision.Amsterdam,the Netherlands: Springer: 517-532[DOI: 10.1007/978-3-319-46484-8_31]
Yu J H,Lin Z,Yang J M,Shen X H,Lu X and Huang T S.2018.Generative image inpainting with contextual attention//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City, USA: IEEE: 5505-5514[DOI: 10.1109/CVPR.2018.00577]
Zhang R,Isola P and Efros A A.2016.Colorful image colorization//Proceedings of the 14th European Conference on Computer Vision.Amsterdam,the Netherlands: Springer: 649-666[DOI: 10.1007/978-3-319-46487-9_40]
猜你喜欢
作物学报(2022年9期)2022-07-18
中国典型病例大全(2022年12期)2022-05-13
健康体检与管理(2021年10期)2021-01-03
小天使·二年级语数英综合(2019年4期)2019-10-06
现代信息科技(2019年18期)2019-09-10
科技创新与应用(2017年26期)2017-09-12
计算机应用(2016年10期)2017-05-12
中国信息技术教育(2016年13期)2016-09-10
电脑爱好者(2015年24期)2015-09-10
电影故事(2015年16期)2015-07-14
