
基于布谷鸟搜索的地震属性聚类方法及其在塔中地区碳酸盐岩礁滩储层的应用
2022-05-22 11:05:30曹成寅
大庆石油地质与开发 2022年1期
曹成寅 高 赞
(1. 核工业北京地质研究院,北京 100029;2. 石油工业出版社有限公司,北京 100011)
0 引 言
目前可以从地震数据中提取几十甚至上百种地震属性,每种属性都可以从不同的方面来反映地下储层的岩性、物性和含油气性等相关的地质特征,它们与储层特征之间的关系是非常复杂的。在地震解释时通常需要从中优选出对地质和储层特征比较敏感的属性或者属性组合来研究地下地质特征,这就是常说的地震属性分析,其中地震属性聚类是比较重要的一种地震属性分析方法。目前聚类技术可以分为5 类方法:划分的方法、层次的方法、基于密度的方法、基于网格的方法和基于模型的方法。J.Dumay 等[1]首先提出将K均值(K‐means)聚类方法应用于地震相分析;陈遵德等[2]将自组织特征映射(SOM)方法应用于地震波形聚类识别油气;1997 年Paradigm 公司采用神经网络方法对地震波形进行分类,推出的Strati‐magic 软件,是目前业界进行地震沉积相划分应用最为广泛的软件;杨培杰等[3]将模糊C均值(FCM)聚类方法应用于地震多属性聚类中;F.Liu等[4]和刘杏芳[5]将粒子群优化算法应用于地震属性聚类,在碳酸盐岩储层地震相划分中取得了比较好的效果;印兴耀等[6]提出了一种基于核子空间的模糊聚类方法,在储层预测中较好地刻画了碳酸盐岩含气储层的边界。
K均值是地震储层预测中最常用的聚类方法之一,具有很高的计算效率,但是该方法的不足之处是易陷入局部最优,计算结果依赖于初值,计算不稳定。群体智能是自然界生物群体通过合作表现出的智能现象,个体行为准则简单,但是群体合作表现出极强的全局搜索能力,是一类用于解决复杂问题的优化方法。本文将群体智能方法中的布谷鸟算法引入到基于K均值的地震属性聚类中,克服了传统的K均值聚类方法的不足,在实际应用中取得了一定的效果。
1 基于布谷鸟搜索的聚类算法
聚类分析是一种重要的数据挖掘技术,是在划分的类未知的情况下,根据“类内尽可能相似,类间尽可能相异”的原则将数据对象分组成多个类或者簇,K均值方法为其中最常见的方法。
1.1 K均值算法
K均值算法以k为参数,把n个样本分为k个簇,以使簇内具有较高的相似度,而簇间具有较低的相似度。相似度的计算根据样本与所属簇中样本的平均值(被看作簇的中心)的距离来进行。
K均值算法的处理流程:首先,随机选择k个样本,每个样本代表了一个簇的平均值或中心,对剩余的每个样本,根据其与各个簇中心的距离,将它赋给最近的簇,然后重新计算每个簇的平均值。这个过程不断重复,直到准则函数收敛。通常采用平方误差准则,其定义为
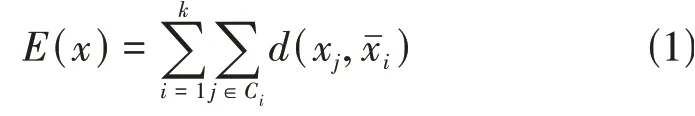
式中:E(x)——所有样本平方误差的总和;xj——样本空间中的点;—— 簇Ci的 平 均 值,d(xj,)——样本点xj到中心点xˉi的距离。
这个准则试图使生成的结果簇内尽可能地紧凑和簇间尽可能的独立。当簇是密集的,并且簇与簇之间的区别明显时,它的效果较好。对处理大数据集,该算法是相对可伸缩的和高效的。但是这个算法经常收敛于局部最优,另外该算法初始中心点的选择是随机的,其结果依赖于初始值的选择,每次聚类的结果不一定相同,计算不稳定。
1.2 布谷鸟搜索算法
布谷鸟搜索是一种全局寻优算法,它是由剑桥大学X.S.Yang 等[7]根据一些布谷鸟品种如Guria和ani 的“寄生生育”习性提出来的,该算法用Levy‐Flight 过程取代传统群体智能优化算法中的随机过程,具有更高的搜索效率。与常规的优化算法相比,布谷鸟搜索不要求矩阵求逆或者目标函数可导,因此具有更广泛的应用前景。
布谷鸟中Guria 和ani 是一种很独特的鸟类,它们具有一种独特的生育方式——寄生生育后代的方式。布谷鸟通常在它生育后代的时候将卵产在食性、卵的颜色、孵化时间与它相差不大的鸟(称之为宿主鸟)的巢中,为了防止宿主鸟发现布谷鸟的卵,增加布谷鸟卵孵化的成功率,布谷鸟同时会移走一些宿主鸟的卵。另外在布谷鸟产完卵后,宿主鸟也有可能发现外来布谷鸟的卵,发现后它会将布谷鸟的卵给找出来丢掉,或直接将巢废弃,重新筑巢产卵[7]。X.S.Yang 通过分析布谷鸟寻巢产卵的过程,总结出3 条规则[8‐9]:
(1)假定布谷鸟每次只产一个卵,并随机寻找巢孵化它;
(2)在每次搜索过程中布谷鸟只会保留它认为最优的那个巢;
(3)每个巢的宿主鸟发现巢中布谷鸟卵的概率是pa。
如果发生这种状况,那么宿主鸟就会将布谷鸟的卵扔掉或者直接废弃巢,重新筑巢产卵。简单的来说,该条规则可以被近似为赋予每个巢一个被发现的概率εi,如果εi>pa,则认为产在该巢的卵被发现,需要重新寻巢,否则保留该巢。
根据以上3 个规则,布谷鸟寻巢产卵的过程可以通过公式表示为
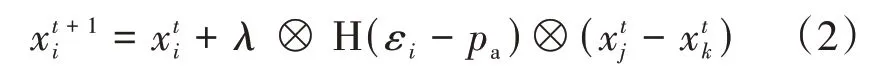
式中:xi,xj,xk——3 个不同的巢;t——迭代次数;λ——步长,它满足正态分布的随机过程;⊗——哈达玛的积算子;H(u)——Heaviside 函数;εi——随机赋予每个巢的被发现的概率,服从正态分布。
式中Heaviside 函数H(u)是δ函数从负无穷到u的积分,其具体表达式为
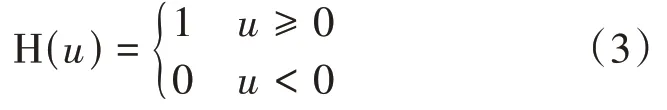
利用式(2)可以对实际问题进行优化。然而在实际应用中,往往采用Levy‐Flight 过程来取代服从正态分布随机过程,使得算法具有更高的收敛速度。
在智能优化算法中采用Levy‐Flight 能扩大搜索范围,增加种群的多样性,更容易跳出局部最优[10‐14]。因此,在实际计算中常常引入Levy‐Flight随机过程。Levy‐Flight 是一种步长满足重尾概率分布的随机搜索,在行走过程中短距离的搜索和长距离的跳跃相间,能扩大搜索范围、增加种群多样性,更容易跳出局部最优点。其分布满足积分的表达式为
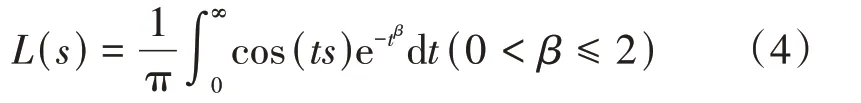
式中:s——改进后的步长;β——尺度因子。
除了特殊的例子外,该分布不具有解析式。当β= 1 时该积分就成为柯西分布,当β= 2 就变为正态分布。在搜索未知的大尺度的空间时,Levy‐Flight 往往比满足正态分布的布朗运动更加高效。那么用Levy‐Fight 表示的布谷鸟寻巢产卵过程可以通过公式表示为
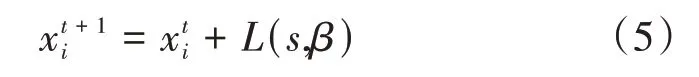
式中L(s,β)——Levy‐Flight 随机过程。
当s比较大时,其表达式为

式中 Γ(x)——伽马函数。
Γ(x)的表达式为
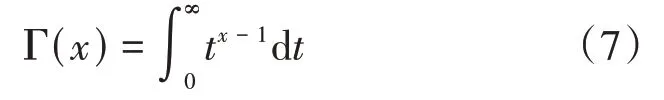
在大多数情况下,步长通常取0~1。
P.Civicioglu 等[15]证明,在目前的群体智能优化算法中,布谷鸟搜索算法具有较高的精度和稳定性。因此本文将布谷鸟搜索算法引入到地震属性聚类中,用以解决K均值算法对初值敏感和易陷入局部收敛的问题。
1.3 基于布谷鸟搜索的地震属性聚类方法
K均值算法对初始值敏感,并且易收敛于局部最优,为了避免这些问题,本文就将全局寻优的布谷鸟搜索算法和K均值方法结合起来,进行地震属性聚类。其中,每个巢代表一个聚类方案,巢位置代表各类别的中心点位置,适应值可以用K均值的目标函数的倒数来表示,即
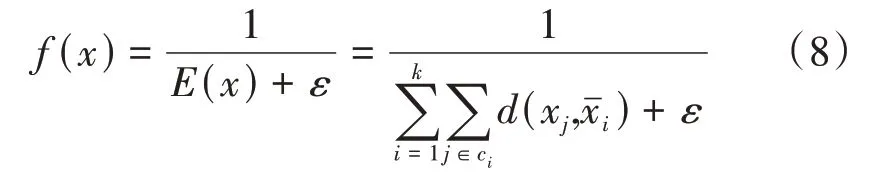
式中ε——为了保证系统的稳定性人为赋予的一个非常小的常量。
基于布谷鸟搜索建立地震属性聚类方法步骤(图1)。
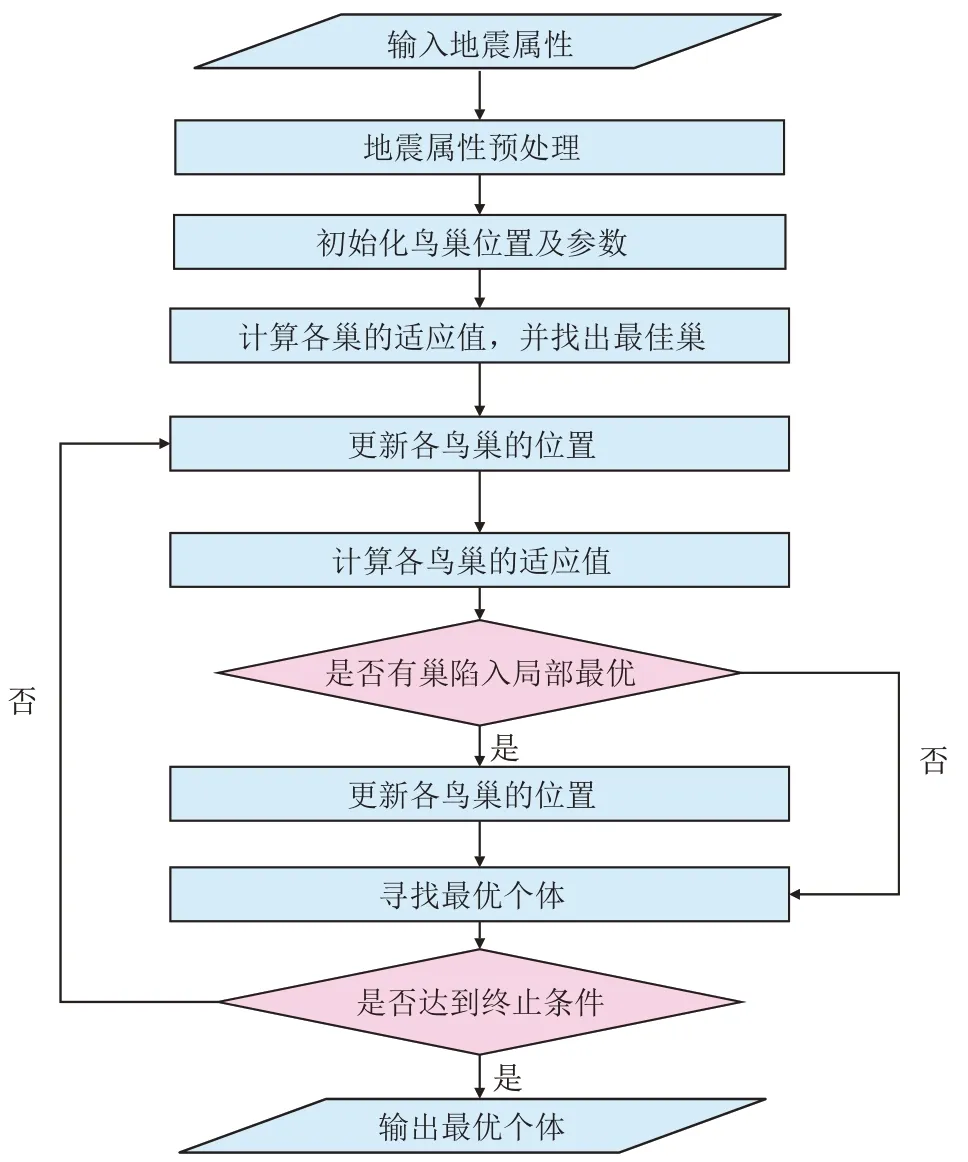
图1 基于布谷鸟搜索的地震属性聚类方法流程Fig.1 Workflow of seismic attribute clustering method based on Cuckoo Search
(1)从地震数据中提取多种属性,并对各属性进行预处理;
(2)初始化聚类所需的各种参数,例如,初始的类别数、巢的个数(聚类方案的个数)和巢位置(聚类的中心点),然后计算每个巢的适应值,寻找出当前适应值最大的巢作为最佳巢;
(3)更新每个巢的位置,并计算每个巢新的适应值;
(4)随机赋予每个巢1 个概率,比较每个巢的概率和预设的被发现的概率,如果有1 个巢概率大于被发现的概率(该聚类方案陷入了局部最优),则更新该巢位置;
(5)计算新巢的适应值,选择适应值最大的巢作为当前最优的巢;
(6)判断是否达到终止条件(最佳巢的适应值不变或是迭代次数达到预设值),如果是,则终止计算,当前的最佳巢位置即为最优聚类方案中各类的中心点,否则转至第3 步继续下次迭代计算。
最终输出的巢位置即为最佳聚类的中心点所在的位置,最终的分类方案就是地震属性聚类结果。
2 模型试验
在研究中采用了加州大学提出的UCI 机器学习数据库中的Iris 和Wine 数据集对聚类算法的精度进行测试。Iris 数据集以鸢尾花的特征作为数据来源,数据库中共150 个样本,4 种特征分别对应着花瓣和花萼的长度和宽度,图2 为其中的前3 个特征。这些样本被分为3 个品种,分别为Setosa(第1 种)、Versicolour (第2 种) 和Virginica (第3种),每种含50 个样本。在3 个品种中,第1 种与其他两种能比较容易地分开,而第2 种和第3 种比较难区分。
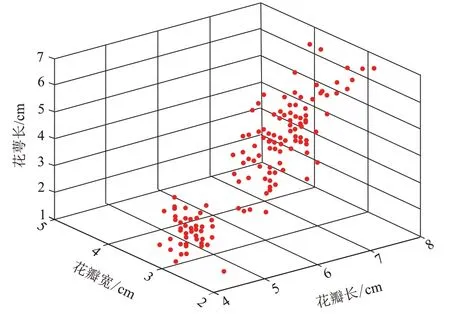
图2 Iris数据前3个特征Fig.2 Top 3 characteristics of Iris data
本文中分别用K均值方法和基于布谷鸟搜索算法的方法进行聚类,聚类结果统计见表1。聚类精度的计算公式为
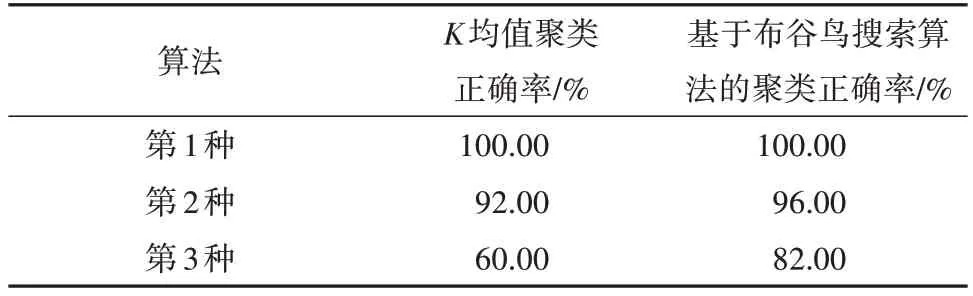
表1 Iris数据集的聚类正确率Table 1 Clustering accuracy rates of Iris data set

式中:r——聚类精度;N——样本数;er——错分的样本数。
由表1 可见,对于易分的第1 种花,2 种聚类算法都能正确的划分,没有分错的样本。对于比较难区分的第2 种花和第3 种花,基于布谷鸟搜索算法的聚类方法正确率明显高于K均值聚类方法。对于整个Iris 数据集来说,基于布谷鸟搜索算法的聚类方法对所有样本的分类正确率可以达到92.67%,要明显高于K均值聚类的84.00%。
Wine 数据集源自意大利所产的3 种葡萄酒的178 个样本,有酒精含量、苹果酸、灰分等13 种特征,图3 为前3 个特征。全部样本被分为3 类,每类分别有59、71 和48 个样本,分别用K均值方法和基于布谷鸟搜索算法的聚类方法对该数据集进行聚类,统计结果见表2。
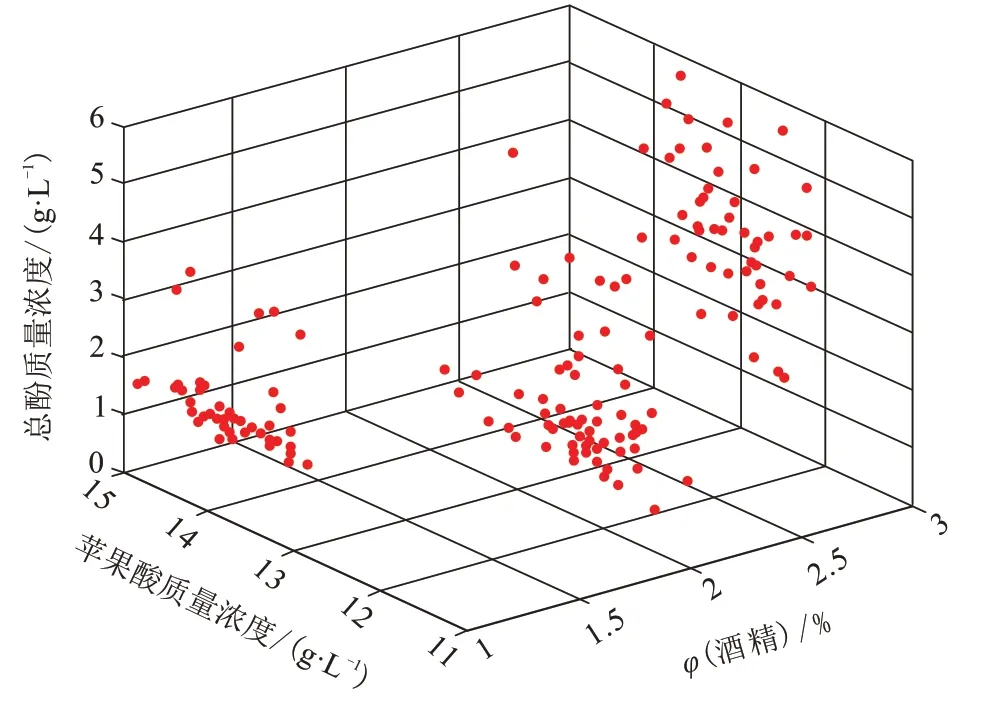
图3 Wine数据前3个特征Fig.3 Top 3 characteristics of Wine data
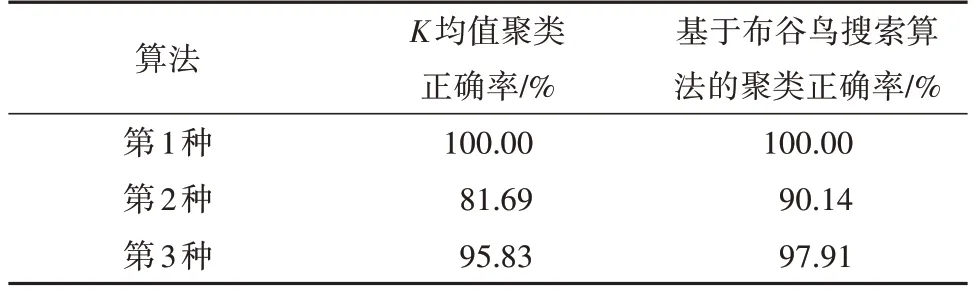
表2 Wine数据集的聚类正确率Table 2 Clustering accuracy rates of Wine data set
其中,基于布谷鸟搜索算法的聚类方法和K均值聚类方法都能正确地划分出第1 类,对于第2类,基于布谷鸟搜索算法的聚类方法的正确率要明显高于K均值聚类的结果,对于第3 类两者的正确率相差不大。总体来说,基于布谷鸟搜索算法的聚类方法对所有样本的分类正确率均能达到95.51%,明显高于K均值聚类的91.57%。
3 应用实例
研究区位于中国西部塔里木盆地的塔中Ⅰ号坡折带上,是一个长期继承性的古隆起,目的层为晚奥陶世在台地边缘发育的一套纵向上多旋回叠置、横向上多期次加积的较大规模的礁滩相沉积体系,岩性主要是泥质条带灰岩和颗粒灰岩,储层类型为裂缝性和孔洞性储层,非均质性强,埋深普遍超过5 000 m。图4 为研究区过井B8 的一条地震剖面,解释的红色与绿色地层界面中间部分为该研究区的目的层,该研究区地震数据分辨率比较低,地震资料主频约为20 Hz,储层识别和预测的难度比较大。研究区内共有8 口完钻井,其中4 口井钻遇油层(井B5、井B7 和井B8 为高产油流井,井B2 为低产油流井),其余4 口为干井(井B1、井B3、井B4 和井B6)。
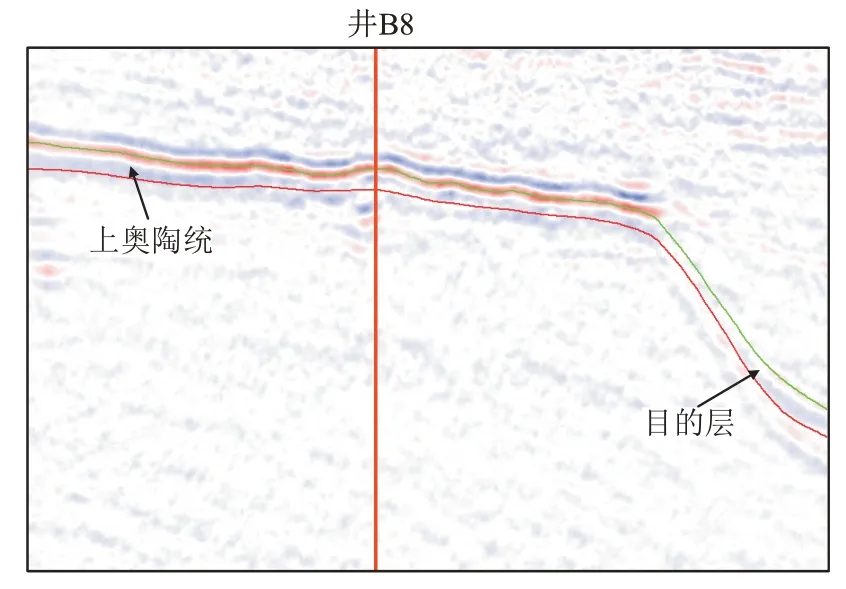
图4 研究区过井B8的地震剖面Fig.4 Seismic section crossing Well B8 in studied area
碳酸盐岩沉积相带的分布与沉积前的古地貌有很大的关联性,目的层残余厚度可以在一定程度上反映目的层沉积前的古地貌,用于分析有利储层的发育部位。图5 为目的层的残余时间厚度,其中绿色到蓝色区域代表残余厚度比较大,为古地貌的低洼地,为台内洼地部位;而红色反映的是残余厚度比较小,是古地貌的高部位,是礁滩沉积体系中储层发育的有利相带。
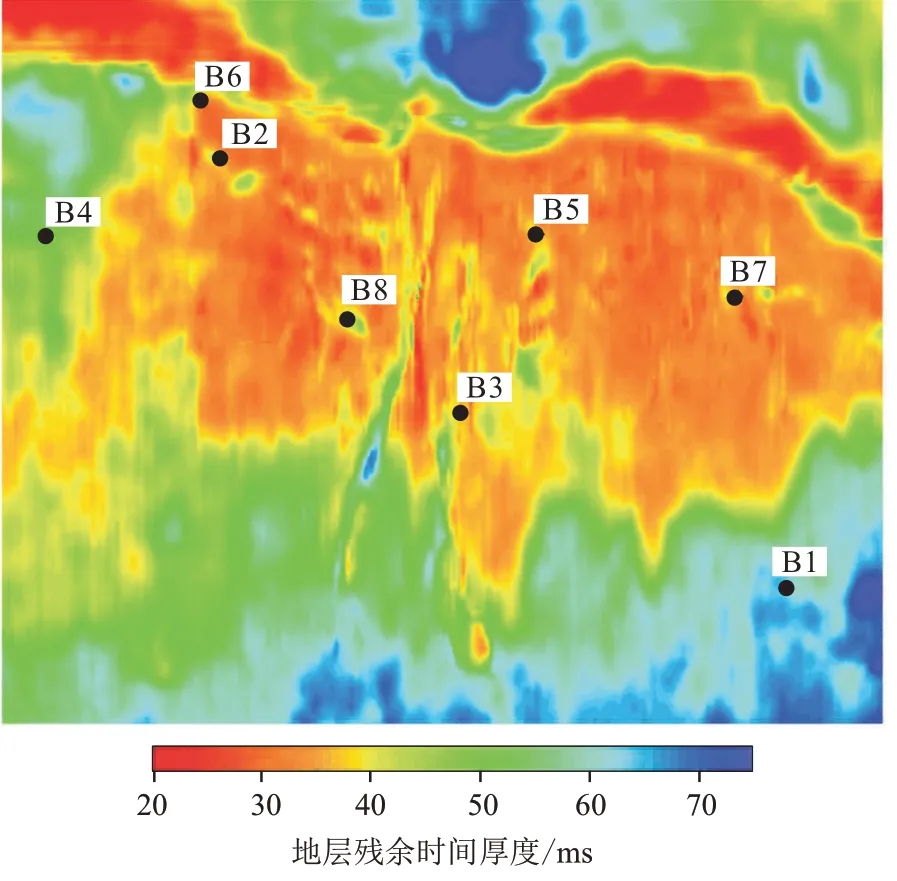
图5 研究区目的层的残余时间厚度Fig.5 Residual time thickness of target layer in studied area
利用该工区的三维地震数据提取了目的层瞬时相对振幅、瞬时频率、瞬时相位、相干体4 种属性(图6)。其中瞬时相对振幅属性能刻画礁滩体的发育区域,但是边界刻画得不是很清楚,而瞬时频率属性能比较清楚地刻画出工区内的油气分布信息,与钻井已知的油气分布信息基本一致,瞬时相位与古地貌特征比较相近,较好地刻画出了礁滩体分布,相干体以及波形差主要描述了工区内断裂的分布。通过多次试验,将该研究区聚类中的类别数设置为7 时比较合理。随后分别采用K均值方法、商业软件中的SOM 方法和基于布谷鸟搜索算法对这些地震属性进行聚类,结果如图7―图9 所示,图中不同颜色反映了不同的地质特征。
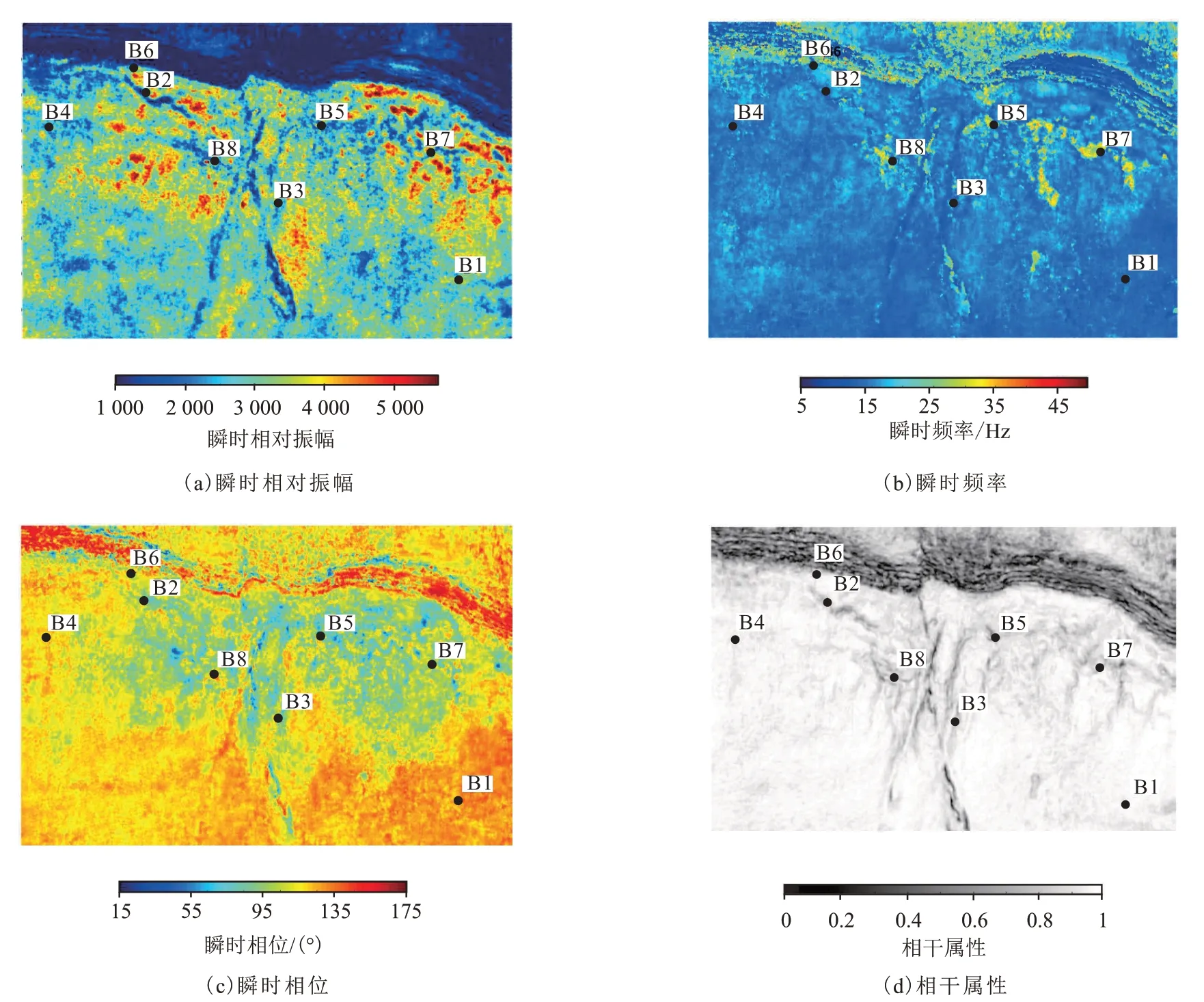
图6 研究区相关地震属性Fig.6 Seismic attributes from studied area
图7 为2 次K均值聚类结果,这2 次K均值聚类结果都不太一样。其中在图7(a)中,类别数5代表台内洼地,类别数1、2 和6 代表礁滩体地层发育位置。但是该结果刻画的礁滩体的边界不是很清楚,无法较好地刻画油气分布。在图7(b)中,类别数2 代表台内洼地,类别数4 和6 表示礁滩体地层发育的位置,其分布与古地貌图有较好的匹配,能较好地描述礁滩体的分布,但是由于将断层和油气聚集区划分为同一类别(类别数5),因而无法较好地区分断裂与油气分布。图8 是用某商业软件中SOM 方法聚类的结果,图中类别数6为台内洼地,类别数7 为礁滩体的发育区域,但是该方法刻画的礁滩体的轮廓,与古地貌的特征不相匹配,并且将油气分布与断层划分为一类(类别数2),高产油井和低产油井的分布区域划分在同一类别中,无法进行有效区分。
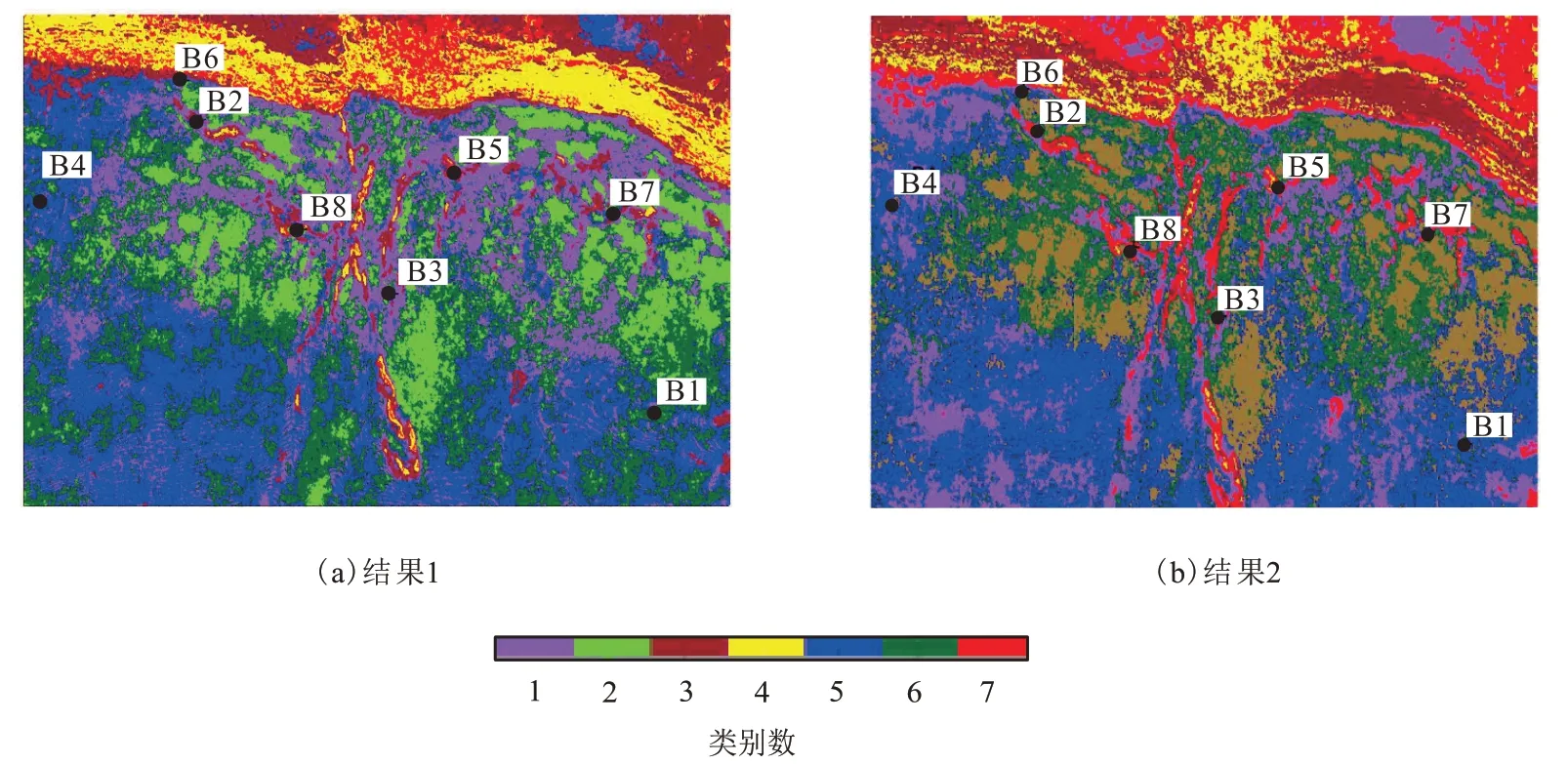
图7 K均值聚类结果Fig.7 K-means clustering results
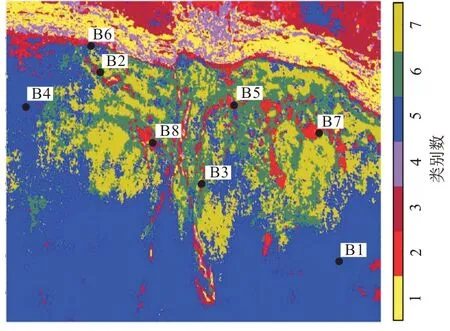
图8 某商业软件SOM聚类Fig.8 SOM clustering of a business software
图9 是基于布谷鸟搜索地震属性聚类结果,其中类别数5 代表台内洼地,类别数6 和7 为礁滩体的发育位置,与研究区古地貌特征非常匹配,类别数3 所代表的区域应是断裂分布的位置,类别数2 应为油气聚集区,高产油井B5、B7 和B8 都是分布在这一区域中,低产油井B2 分布在类别数3 所在的区域中,4口不产油井则是分布在其他类别数代表的区域中,说明该结果能较好地刻画礁滩相储层的发育部位,并且能较好地区分断层与油气分布。
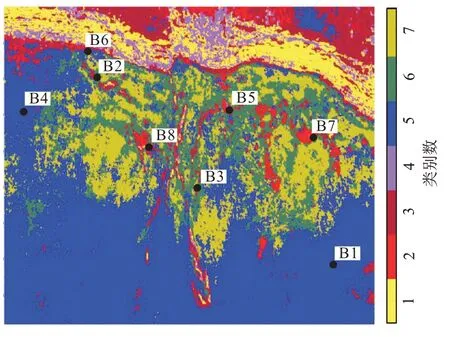
图9 基于布谷鸟搜索的地震属性聚类Fig.9 Seismic attribute clustering based on Cuckoo Search(CS)
4 结 论
(1)将群体智能算法中的布谷鸟搜索算法引入到地震属性聚类中可以较好地解决K均值聚类局部收敛、计算结果依赖于初值和不稳定的问题。
(2)通过理论数据集试验证明,基于布谷鸟搜索的聚类方法聚类精度要明显优于K均值的计算精度。
(3)通过应用实例表明,基于布谷鸟搜索的地震属性聚类方法能够更好地刻画礁滩复合体、储层、流体和断裂的分布。
猜你喜欢
红蜻蜓·低年级(2021年12期)2022-01-19 05:18:26
红蜻蜓·低年级(2021年12期)2021-12-19 15:06:23
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19 08:38:42
大灰狼(2019年4期)2019-05-14 16:38:38
剑南文学(2016年14期)2016-08-22 03:37:18
新校长(2016年8期)2016-01-10 06:43:59
电测与仪表(2015年15期)2015-04-12 00:43:48
河北科技大学学报(2015年5期)2015-03-11 16:16:37
商事法论集(2014年1期)2014-06-27 01:20:42
中央民族大学学报(自然科学版)(2014年1期)2014-06-11 01:28:38
