
复杂背景茶树病害图像识别
2022-05-21 04:51余文森
武夷学院学报 2022年3期
余文森
(武夷学院 数学与计算机学院,福建 武夷山 354300)
1 相关工作
茶树是我国重要的经济作物,广泛分布于我国江南、江北、华南、西南等四大茶区。近年来,随着我国社会经济的发展,人民生活水平的逐步提高,对茶叶需求量日益增加,同时对茶叶产品质量也日益关注。然而,茶叶种植过程中病虫害问题极大影响了茶叶的品质和产量,也损失茶农的经济效益。传统茶树病虫害识别主要依靠人工感观识别,需要有丰富的经验,且容易发生误诊,出错率比较高。随着计算机技术的不断发展,基于图像识别的方法是当前茶树病虫害识别的发展方向。从上个世纪八十年代开始,国内外学者就开始经致力于农作物病害图像自动识别技术研究,如Sarkar等研发了基于计算机视觉的番茄分选系统,通过对番茄茎和花端视图的分析,以确定番茄新鲜市场质量的特征[1]。到目前为止,基于计算机视觉的农作物病害图像识别研究主要集中在传统机器学习方法[2-8]和深度学习方法[9-19]两大类上。传统机器学习方法分为图像预处理、病害图像特征提取、病害识别等阶段。虽然传统机器学习方法在一些特定作物病害自动识别上取得一定成效,但是该类方法需要人为设计病害图像特征。由于作物病害特征多样、获取病害图像的场景复杂等原因,人为设计的病害图像特征往往仅对特定病害有效,很难推广应用。2006年开始,深度学习方法逐渐应用到图像识别领域,并取得显著成效。深度卷积神经网络具有强大的自主学习能力,可以自动提取图像特征,克服了人工设计图像特征的缺陷,成为农作物病害图像识别的主流方法。
虽然基于深度学习的农作物病害图像识别方法受到国内外学者广泛关注,也取得较大进展。但是茶树病害图像识别方面的研究文献较少,主要原因是没有足够的茶树病害图像数据集。因此,一些学者开始研究基于小样本的茶树病害图像识别算法[20-21],并取得一定成效。但是这些研究的数据集主要是简单背景的病害图像,实际应用往往是自然环境复杂背景下的茶树病害图像识别。为能够满足茶园自然环境复杂背景下茶树病害图像识别,以茶树叶部病害为研究对象,选择茶白星病、茶炭疽病等常见的病害,基于非常小的样本数据集,研究复杂背景下茶树病害图像自动识别方法。
2 实验数据
研究的目标是能够在茶园自然环境等复杂背景下,通过微信小程序、手机APP等终端应用程序自动识别茶树病害。为与应用场景相一致,采用网上搜索和现场拍摄两种途径收集任意分辨率以及任意背景下的茶树病害图像。因收集到的不同病害图片数量相差比较大,为保证训练集相对均衡,也为更容易推广到其它茶树病害图像识别,构建每种病害30幅左右的小样本茶树病害图像数据集(以下简称Tea_disease),其中茶白星病图像26幅、茶炭疽病图像30幅、健康茶树叶部图像32幅,部分图像如图1、2、3所示。

图1 茶树白星病图像Fig.1 Tea white star disease image

图2 茶树炭疽病图像Fig.2 Tea anthracnose disease image

图3 健康茶树图像Fig.3 Healthy tea tree image
此外,利用多种植物有同一病害的特性构建一个374幅病害图像的茶树病害图像增广数据集(以下简称Tea_disease_augment),其中白星病害图像119幅、炭疽病图像135幅、健康茶树叶部图像120幅。在研究二次迁移学习方法时,使用网上公开的植物病害图像数据集[22](以下简称Plant_disease),该数据集是由在线平台PlantVillage收集构建,包含14种作物54309幅图像,总共有38个类别。另外,分割Plant_disease数据集,建立Plant_rest_disease数据集和Apple_disease小样本数据集。Plant_rest_disease数据集由Plant_disease数据集除去apple的4类数据后,剩余的数据组成,共34个类别51134幅图像。Apple_disease小样本数据集是从apple的4类数据中分别随机抽取30幅图像组成,共4个类别120幅图像。
3 茶树病害图像识别模型
深度学习是当前机器学习领域最受欢迎的研究课题。近十几年,研究者已经开发出许多深度学习模型,并在图像识别领域取得显著成效。然而,深度学习的成功依赖于规模庞大的训练数据集,如ImageNet图像数据集(以下简称ImageNet),收集超过1 500万幅的图像,涵盖的图像类别约22 000种。然而许多实际应用场景很难构建大规模的训练数据集或者构建成本太高,深度学习无法满足这些应用场景需求。但是人类有一项非凡的智慧,就是能够从少数几个例子中学习识别新事物、新概念。即使是一个五六岁的小孩,都能够通过一两张图片的学习,认识新事物。受人类这种学习能力启发,小样本学习概念被提出,并迅速成为研究的热点。
3.1 基础网络模型选择
目前,主流的小样本学习方法是基于深度学习网络,通过迁移学习、数据增广、模型微调等技巧来克服训练数据量少的缺陷。研究者已提出LeNet、AlexNet、ZF-net、GoogleNet、VGG N et、ResNet等深度学习网络,本文选择迁移性能较好的VGGNet。VGGNet是Visual Geometry Group(牛津大学计算机视觉组)和Google DeepMind公司合作研发的深度卷积神经网络,共有6种不同的网络结构,其中VGG-16和VGG-19比较出名[23]。基于VGG-16网络结构,分别研究数据增广、迁移学习、模型微调、学习速率微调等常见的小样本学习方法在复杂背景下的茶树叶部病害图像识别的成效。
VGGNet的网络配置如图4所示。每种结构都分成5个卷积层组,每组由多个采用卷积核的卷积层串联一起,后接一个最大池化层。最后是3个全连接层和1个softmax层。其中,红线方框部分是VGG-16的卷积层组配置,输入是一个的RGB图像,第一组由两个采用64个卷积核的卷积层串联组成,第二组由两个采用128个卷积核的卷积层串联组成,第三组由三个采用256个卷积核的卷积层串联组成,第四、第五组由三个采用512个卷积核的卷积层串联组成。
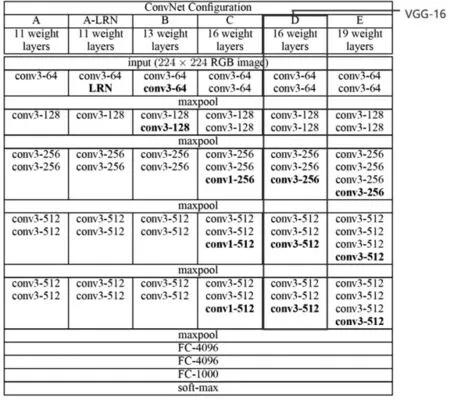
图4 VGGNet网络配置Fig.4 VGGnet network configuration
3.2 数据增广
数据增广是小样本学习中常用且直观的一种方法。它是指对原有的小样本数据进行数据扩充或特征增强,用于增加训练数据集,提升训练模型的泛化能力。常见的图像数据增广方法有平移、旋转、缩放、水平/垂直翻转、裁剪、亮度增强、对比度增强、色彩抖动、噪声等。近年来,研究者还提出利用无标签数据或合成带标签数据扩充数据集、样本特征空间增强等数据增广方法[24]。
在收集茶树叶部病害图片过程中发现,茶树的许多病害如白星病、炭疽病等,其它相似植物也有同类病害,而且病害图像特征很相似。因此,提出利用其它相类似植物的同种病害图像扩充茶树病害图像数据集的新思路,构建一个茶树病害增广数据集,并通过实验验证了该方法的有效性。
3.3 迁移学习
迁移学习是近年来受研究者广泛关注的一个新兴的学习框架,其目标是把源域中学习到的知识迁移到不同但相关的目标域中。类似于人类“举一反三”的学习过程,迁移学习是指利用数据、任务或模型之间的相似性,将源域中学习到的知识应用于目标域的学习过程。在小样本学习中,可以利用相关源域中已有的大规模训练数据,通过迁移学习解决目标域的小样本问题。Mohanty等在Plant_disease数据集上,对比直接训练和迁移学习两种方法,发现迁移学习模型的识别率明显更高[25]。谢军等利用ImageNet、Plant_disease以及自已构建的茶树病害数据集,采用二次迁移学习方法,研究小样本茶树病害图像识别问题,取得较好识别率[20]。然而无论是Plant_disease还是谢军等人构建的茶树病害数据集,样本图像的背景都比较简单的,病害图像识别相对容易。
将上述迁移学习方法以及小样本学习常用的数据增广、模型微调、学习速率微调等方法引入复杂背景下茶树病害图像识别问题。通过实验对比分析这些方法对所研究问题的有效性。首先是数据增广方法。构建Tea_disease(未增广)和Tea_disease_augment(增广)两个茶树病害数据集。在此基础上,采用迁移学习的框架,将ImageNet预训练模型VGG-16分别迁移到两个数据集进行训练和测试,比较两者的识别准确率,讨论本文提出方法的有效性。
其次是迁移学习方法。设计在Tea_disease数据集上采用一次迁移、经过Plant_disease二次迁移、经过Tea_disease_augment二次迁移以及在Apple_disease数据集采用一次迁移、经过Plant_rest_disease二次迁移等多个实验,分析讨论迁移方法对所研究问题的影响。
第三是模型微调方法。一般小样本学习中常见的微调方法是先在大规模数据集中预训练一个网络,然后迁移到小样本数据集中训练。在小样本数据集中训练时,一般会冻结前面网络层的参数,只微调后面几层的参数。本文实验比较了微调网络的全连接层和微调整个网络两种方法。
最后是学习速率微调方法。Howard等在研究通用微调语言模型时,提出斜三角学习速率[26]。该方法在训练过程中,根据迭代次数动态调整学习速率,当从0开始增长时,学习速率逐渐变大,增长到某个固定值时,学习速率开始逐步下降。将这个学习速率微调方法引入所研究问题,实验比较了固定学习速率和斜三角学习速率两种方法训练的模型,讨论学习速率微调方法对所研究问题的影响。公式(1)、(2)、(3)为斜三角学习速率计算公式。

其中,T是迭代训练总次数,cut为学习速率从递增转变为递减的迭代次数,cut_frac为学习速率递增的迭代次数比例分数,ratio指定了最小学习速率比最大学习速率小多少,ηmax为最大学习速率,ηt为第次迭代的学习速率。
4 实验结果及分析
4.1 实验环境
实验平台为联想DeepNex深度学习平台,配置为3节点软硬件一体化大数据深度学习平台。每个节点硬件配置2颗Intel Xeon Gold 20C 125W 2.1GHz处理器、256GB 2933MHZ DDR4内存、2*480GB SSD、4*4TB SATA热插拔硬盘、Raid 730-8i 12Gb/s RAID卡、1GB缓存、1块NVIDIA Tesla V100 32GBGPU。
4.2 实验比较及分析
实验公共的配置如下:采用VGG-16为基础网络模型,该模型的输入数据尺寸为224×224×3,因此,实验中所有样本图像调整成这一尺寸;VGG-16模型迁移时,丢弃原模型的全连接层,添加一个激活函数为relu的256个卷积核的全连接层,后面紧跟一个丢弃率为0.5的Dropout层,最后是一个labels个卷积核的softmax全连接层,其中,labels是类别数。除模型微调对比实验外,其它实验统一采用如下微调策略:微调最后三层参数而冻结前面网络层的参数。除学习速率微调对比实验外,其它实验的学习速率统一采用固定值0.001。实验迭代轮数统一设置为200。
4.2.1 数据增广对比实验
从网上下载ImageNet预训练的VGG-16模型,分别迁移到Tea_disease和Tea_disease_augment两个数据集上进行训练,训练得到的两个模型的平均识别准确率以及模型损失图如表1及图5所示,在增广数据集上的平均识别准确率要明显高于未增广的,且模型损失变化更平滑,从而验证了本文提出利用相似植物同一种病害图像来增广数据集的方法是有效的。

表1 数据增广对比实验Tab.1 Comparative experiment of data augmentation

图5 数据增广对比实验的模型损失图Fig.5 Model loss diagram of comparative experiment of data augmentation
4.2.2 迁移学习方法对比实验
首先设计如下两个实验来对比分析一次迁移和二次迁移方法对所研究问题的影响:①将ImageNet预训练的VGG-16模型一次迁移到Tea_disease(用ImageNet_Tea_T表示)。②将ImageNet预训练的VGG-16模型迁移到Plant_disease中训练,然后再次迁移到Tea_disease中训练(用ImageNet_Plant_Tea_T表示)。实验结果如表2所示,发现二次迁移实验②的平均识别准确率要比一次迁移实验①的低,与谢军等文中结论相反[20]。通过分析二次迁移的数据集我们发现,谢军等的二次迁移实验的数据集都是简单背景的图像组成,而本文的二次迁移实验中Plant_disease数据集是简单背景的图像组成,但是Tea_disease数据集是复杂背景的图像组成。初步分析产生前面实验结果的原因可能跟二次迁移实验②从背景简单的数据集迁移到背景复杂的数据集有关。因此,设计第三个迁移学习的实验:③将ImageNet预训练的VGG-16模型迁移到Tea_disease_augment中训练,然后再迁移到Tea_disease中训练(用ImageNet_Augment_Tea_T表示)。Tea_disease_augment和Tea_disease两个数据集都是复杂背景的图像组成,即二次迁移是从复杂背景的数据集迁移到复杂背景的数据集上。实验结果如表2所示,二次迁移实验③的平均识别准确率要比一次迁移实验①的高,这个实验表明上述初步分析是正确,中间数据集与最终数据集的背景复杂情况相似度会影响二次迁移方法的效果。

表2 Tea_disease数据集上的迁移学习方法对比实验Tab.2 Comparative experiment of transfer learning methods on Tea_disease dataset
为了进一步证明上述结论,再次设计两个迁移学习的实验:④将ImageNet预训练的VGG-16模型一次迁移到Apple_disease(用ImageNet_Apple_T表示)。⑤将 ImageNet预训练的 VGG-16模型迁移到Plant_rest_disease中训练,然后再次迁移到Apple_disease中训练(用ImageNet_Plant_rest_Apple_T表示)。实验结果如表3所示,二次迁移实验⑤的平均识别准确率要高于一次迁移实验④。实验⑤的中间数据集Plant_rest_disease和最终数据Apple_disease都是简单背景的图像组成。因此可以得出结论,二次迁移学习方法对所研究问题还是有效的,但是中间数据集与最终数据集的复杂背景情况要一致,即同为简单背景或同为复杂背景。

表3 Apple_disease数据集上的迁移学习方法对比实验Tab.3 Comparative experiment of transfer learning methodson on Apple_disease dataset
4.2.3 模型微调对比实验
实验采用目前常用的微调全连接层、微调整个网络参数两种方法,并选择Tea_disease和Tea_disease_augment两个数据集进行实验对比研究模型微调对所研究问题的影响。实验结果如表4以及图6所示,表4显示对于样本数非常少的小数据集(如Tea_disease),微调整个网络方法的识别准确率要比微调全连接层低,主要原因在于样本数太少,过拟合问题较严重。但是随着样本数增加,微调整个网络方法的有效性会逐步提升,比如在Tea_disease_augment数据集中,其样本数比Tea_disease大,微调整个网络方法的模型识别准确率接近微调全连层。此外,分析比较图6也可以发现,采用微调整个网络方法在Tea_disease_augment上训练的模型损失图(d)的纵坐标范围比同样方法在Tea_disease上训练的图(c)小。如果考虑比例尺因素,从整体上看图(d)的损失曲线比图(c)更平滑。说明随着样本数的增加,采用微调整个网络方法训练的模型损失波动逐渐变小,且变化曲线逐渐趋于平滑,有利于加快训练的收敛速度。因此,当数据集样本数非常小时,应该采用微调全连接层策略;样本数相对比较大时,可以采用微调整个网络参数来提高识别正确率。

图6 模型微调实验的模型损失图Fig.6 Model loss diagram of comparative experiment of model fine-tuning

表4 模型微调对比实验Tab.4 Comparative experiment of model fine-tuning
4.2.4 学习速率微调对比实验
实验选择固定学习速率和斜三角学习速率两种策略,分别在Tea_disease、Tea_disease_augment数据集上进行实验对比分析学习速率微调对所研究问题的影响。实验相关参数配置如下:固定速率设置为0.001,斜三角速率公式中相关参数配置为T=200,cut_frac=0.1,ratio=32,ηmax=0.01。实验结果如表5及图7所示,表5显示在两个数据集上采用固定学习速率训练的模型平均识别准确率都高于斜三角学习速率。但是从图7来看,采用斜三角学习速率训练的模型损失图(b)和(d)的纵坐标范围比固定学习速率的图(a)和图(c)的小,且损失变化曲线也相对更平滑,说明斜三角学习速率训练策略的损失变化范围更小且曲线更平滑,更有利于加快训练的收敛速度。


图7 学习速率微调对比实验Fig.7 Model loss diagram of comparative experiment of learning rate fine-tuning

表5 学习速率微调对比实验Tab.5 Comparative experiment of learning rate fine-tuning
5 结论
构建茶树病害小样本图像数据集和增广数据集以及利用网上公开的植物病害图像数据集,通过实验比较分析研究迁移学习、数据增广、模型微调、学习速率微调等方法对复杂背景下的茶树病害图像识别问题的有效性。得到以下结论:
(1)利用相似植物同一种病害图像来增广数据集的方法对所研究问题是有效的。
(2)二次迁移学习方法可以提高复杂背景下茶树病害图像识别的准确率,但是中间数据集也需要复杂背景的样本图像。
(3)在进行迁移学习时,如果数据集样本数非常小时,应该采用微调全连接层策略;样本数相对比较大时,可以采用微调整个网络参数来提高识别正确率。
(4)在样本数量非常小的情况下,斜三角学习速率策略虽然不能提高识别准确率,但是有利于加快训练的收敛速度。
猜你喜欢
茶道(2022年3期)2022-04-27
乐器(2021年1期)2021-09-10
福建茶叶(2020年5期)2020-12-23
福建茶叶(2020年10期)2020-12-22
农技服务(2020年1期)2020-12-17
广西民族研究(2014年6期)2015-05-05
食品工业科技(2014年23期)2014-03-11
