
基于深度霍夫优化投票的三维时敏单目标跟踪
2022-05-18 10:47:01杨玺雷航钱伟中曾一芳王旭鹏
航空兵器 2022年2期
杨玺 雷航 钱伟中 曾一芳 王旭鹏





摘 要: 针对三维点云时敏单目标跟踪问题,提出了一种基于深度霍夫优化投票的深度学习算法。首先, 采用PointNet++网络分别从模板点云和搜索点云中计算种子点、提取几何特征,并通过面向目标的特征提取方法将目标模板信息编码到搜索区域中。其次,通过种子点投票计算并筛选出具有高置信度的潜在目标中心。最后,通过目标中心点的采样、聚集产生多个提议,选取具有最高得分的提议生成三维目标框。该算法能够有效避免耗时的三维全局搜索,且对点云的无序性、不规则性和稀疏性保持鲁棒。为了验证该网络的有效性,在公共数据集KITTI上进行测试。实验结果表明,该网络相较于当前最好的基于三维点云的方法,准确度提高了约10%,并可以在单个NVIDIA2080S图形处理器上以43.5 FPS运行。
关键词: 时敏目标; 单目标; 目标跟踪; 点云数据; 霍夫投票; 深度学习; 人工智能
中图分类号: TJ760; TN911.73
文献标识码: A
文章编号: 1673-5048(2022)02-0045-07
DOI: 10.12132/ISSN.1673-5048.2020.0238
0 引 言
基于点云数据的三维时敏单目标跟踪是自动驾驶和机器人视觉等相关领域应用的基础[1-3]。现有的三维目标跟踪算法[4-8]大都继承二维目标跟踪的经验,对于RGB信息有很强的依赖性。但当环境因素变化导致RGB信息退化时,这些算法的性能会变得很差甚至失效。三维点云数据描述场景的几何信息,其采集过程不受光照变化的影响,相较于RGB信息更适用于目标跟踪任务。然而,三维点云数据的不规则性、无序性和稀疏性,导致传统二维目标跟踪算法(如基于孪生神经网络的算法[9])无法直接应用,给三维时敏单目标跟踪带来巨大的挑战。
为了解决上述问题,本文提出了一种基于深度霍夫优化投票[10]的端到端时敏单目标跟踪算法。首先,从模板点云和搜索点云中提取种子点,采用面向目标的特征提取方法编码目标信息; 然后,通过投票和筛选生成高置信度的潜在目标中心; 最后,执行联合提议和验证生成预测结果。通过在KITTI跟踪数据集[11]上进行实验验证,本文提出的算法在成功率和精准度上都显著优于当前最先进的算法[12],且可在单个NVIDIA2080S图形处理器上以43.5 FPS运行。
1 基础理论
1.1 三维目标跟踪
目前常用的目标跟踪算法[4-8,13]有RGB或RGB-D信息,对基于点云的三维目标跟踪算法的研究相对较少[10]。主要存在以下问题: (1)过于依赖RGB信息,在光照变化剧烈或极端天气情况下,RGB视觉信息的质量变差甚至无法获取,会极大地限制算法的性能。(2)除此之外,一些算法[6-8]专注于生成二维目标框,相较于三维目标框,由于缺少一个维度的信息无法精确地表示目标在空间中的位置信息。基于形状补全的三维孪生跟踪[12]是目前唯一仅使用点云数据的三维目标跟踪算法,该算法通过在点云和三维目标提议上进行深度学习,取得了三维目标跟踪的最好结果,但因为其在三维全局进行搜索,存在计算复杂度过高的问题。
1.2 二维目标跟踪
许多先进的二维目标跟踪算法[14-25]大都基于孪生神经网络。如图1所示,孪生神经网络通常包含两个分支,分别用于处理模板区域和搜索区域。其通过结构相同且权重共享的两个子网络, 输出映射到高维度空间的
特征表示,用于比较两个区域的相似程度。在此基础上,
结合区域候选网络可以实现高性能的二维目标跟踪[23]。后续许多研究[17,19-22]都建立在这套框架之上并取得了不错的性能。但是,上述算法均以二维卷积神经网络为基础,而点云的不规则性导致传统二维的卷积操作无法直接应用到点云数据。所以,本文的工作是以二维孪生跟踪框架为基础,将其扩展用于解决三维目标跟踪。
1.3 点云深度学习
目前,点云深度学习越来越受到大家的关注[26-27]。但由于点云的无序性、稀疏性和不规则性,许多在二维视觉中成熟的算法无法应用到点云上。为此,许多学者在三维目标识别[28-29]、三维目标检测[10,30-32]、三维目标姿态估计[33-35]和三维目标跟踪[12]方向都进行了相关研究,以解决在三维点云场景下的各类问题。
基于形状补全的三維孪生跟踪算法[12]虽然取得了不错的结果,但该算法不能执行端到端的训练,且在三维全局空间进行搜索计算,复杂度较高。为解决这一问题,本文提出了一种端到端的三维目标跟踪算法。
1.4 霍夫投票
霍夫投票[36]是基于广义的霍夫变换[37],提出的一种学习物体形状表示的方法,可以有效地将不同训练样本上观察到的信息结合在一起。基于这一思想,霍夫投票与深度学习相结合,提出了一个可训练的端到端深度网络[10],用于解决点云中的三维目标检测问题。该网络通过聚合目标的局部上下文信息进行联合提议和验证,取得了很好的结果。如何有效地结合霍夫投票和深度学习网络来实现三维目标跟踪,同时进一步优化投票的选择,是本文专注解决的问题。
2 时敏单目标跟踪算法
给定目标模板点云Ptemp={pi=(xi, yi, zi)}N1i=1和搜索空间点云Psea={si=(xi, yi, zi)}N2i=1,目标跟踪算法预测目标在搜索空间中的位置信息Φ。其中: N1为模板点云中点的数量; N2为搜索点云中点的数量; Φ由目标中心的坐标以及X-Y平面的旋转角度构成。
本文提出的基于深度霍夫优化投票[10]的时敏单目标跟踪算法以模板点云和搜索点云作为输入,由面向目标的特征提取、潜在目标中心的生成、联合提议和验证以及模板点云的更新四部分组成,如图2所示。
面向目标的特征提取(图2(a))使用PointNet++网络[27]提取模板点云Ptemp和搜索点云Psea的几何特征并生成模板种子点集Q和搜索种子点集R,通过计算Q和R的相似度矩阵T将目标信息编码到搜索空间中,生成编码了目标信息的搜索种子点集D; 潜在目标中心的生成阶段(图2(b)),每个编码后的搜索种子点dj通过投票产生对应的潜在目标中心点cj,并基于置信度得分B从潜在目标中心C中筛选出具有高置信度的潜在目标中心E; 联合的提议和验证阶段(图2(c)),采样和聚集高可信度的潜在目标中心E,产生K个提议,具有最高得分的提议作为最终的预测结果Φ; 模板点云的更新阶段(图2(d))采用模板点云更新策略γ,基于前一帧目标的预测结果更新模板点云Ptemp。该算法充分挖掘模板和搜索空间中目标的相似性,有效应对点云的无序性和不规则性以及目标外观变化,能够高效稳定地对场景中的时敏单目标进行持续跟踪。
单个目标表面的点可以直接生成目标提议,但是由于单个目标表面的点只捕获了目标的局部信息,无法有效地描述目标的全局信息,所以无法得到目标在三维空间中的精确位置。而本文提出的基于优化的深度霍夫投票算法,先把目标表面的每一个点回归到物体中心,再聚集目标的候选中心点生成提议,可以获取目标更多的全局信息,从而得到更加准确的检测结果。
3 实 验
为了验证本文提出的基于深度霍夫优化投票的三维时敏单目标跟踪算法,在KITTI跟踪数据集[11](使用激光雷达扫描空间获取点云)上进行了一系列的实验。采用一次通过评估(OPE)[39]来评估不同方法的成功率和精准率。成功率是目标预测框和目标真实框之间的IOU。精准率是在0~2 m(目标预测框中心和目标真实框中心的距离)内误差的AUC。
3.1 实验配置
3.1.1 数据集
因为KITTI测试集[11]的真实值无法获得,本文仅使用训练集来训练和测试本文提出的算法。该数据集包含21个室外场景和8种类型的目标。由于KITTI数据集中汽车数据具有最高的质量和多样性,本文主要考虑汽车为目标的跟踪,并进行了消融实验、定量实验以及定性实验。除此之外,为了进一步验证算法的性能,还对其他3种目标(如行人、货车和自行车)进行了实验。
本文为所有视频中的目标实例逐帧生成了轨迹,并将数据集分割如下: 场景0~16用于训练,场景17~18用于验证,场景19~20用于测试。
3.1.2 实施细节
对于模板点云和搜索点云,本文通过随机放弃或复制的方式,把模板点云中的点的数量归一化到N1=512,搜索点云中的点的数量归一化到N2=512。本文采用PointNet++网络[27]提取点云的几何特征,网络由3个下采样层组成,每层的感知球半径依次为0.3, 0.5, 0.7, 即每层都从当前点集中采样一半的点,产生了M1=64个模板种子点和M2=128个搜索种子点,输出特征的维度为d1=256。本文的多层感知机包含3层,每层的大小均为256,即d2=256。对于采样和聚集生成提议,采样K=32个潜在目标中心点并聚集在其R=0.3 m内领域的点生成提议。
使用Adam优化器[40]优化模型参数,batch大小为12,学习率最初为0.001,在训练集迭代10次后变为之前的0.2。
在测试阶段,使用训练后的网络逐帧预测目标位置信息生成三维目标框,前一帧的预测结果放大2 m,作为后续搜索区域点云。
3.2 消融實验
3.2.1 特征提取方式
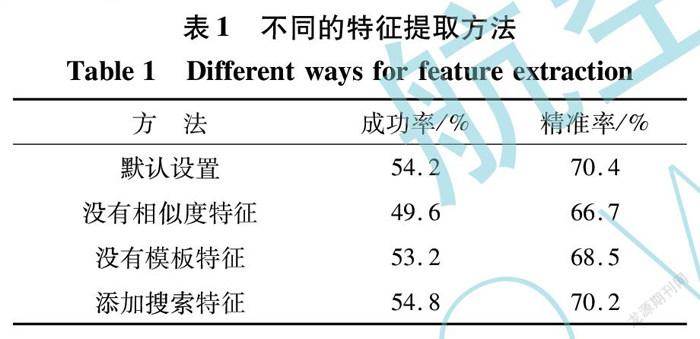
为了验证本文提出的面向目标特征提取方式的有效性,将提出的算法和其他4种算法进行对比,包括: 在合并相似度矩阵和模板种子点时,分别移除模板种子点和搜索种子点的相似度特征、移除模板种子点的特征、移除模板种子的坐标以及添加搜索种子点的特征。实验结果如表1所示。
从表1可看出,在移除相似度特征后,模型的成功率下降了4.6%,精准率下降了3.7%; 在移除模板特征后,成功率下降了1.0%,精准率下降了1.9%。这验证了这些部分在默认设置中的作用。而在添加了搜索种子点的特征后并没有对性能有太大的提升,甚至降低了精准率。这表明,搜索种子点的特征只是捕获了场景中的上下文信息而非目标的信息,对于目标跟踪任务没有帮助。而本文采用的方法编码了模板中丰富的目标信息,能够产生更加可靠的提议,用于后续目标的精准定位。
3.2.2 对潜在目标进行筛选的有效性
根据潜在目标中心的置信度得分,进一步筛选出具有高置信度的潜在目标中心,能够产生更好的提议。本文通过删除对潜在目标进行筛选,以验证该算法的有效性。实验结果如表2所示。
从表2中可以看出,对潜在目标的筛选将模型的准确率提升了2.2%,成功率增加了3.0%。这表明,对潜在目标进行筛选以提高提议的质量,能够显著地提高时敏单目标跟踪的精确度
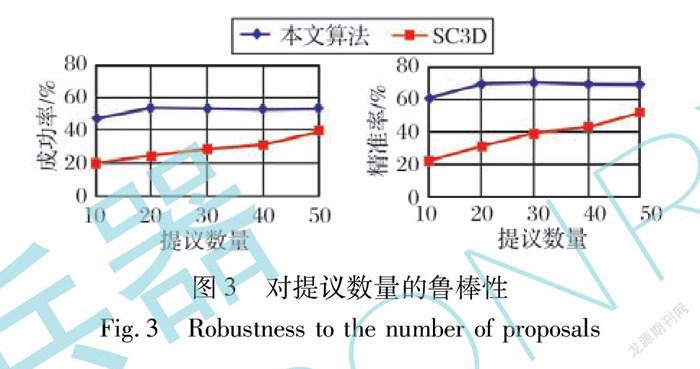
3.2.3 对不同提议数量的鲁棒性
本文测试提出的算法和基于形状补全的三维孪生跟踪算法(SC3D)[12]在不同数量的提议下的成功率和精准率如图3所示。可以看出,即使在只生成10个提议的情况下,本文提出的算法也获得了令人满意的表现,但是SC3D[12]的性能随着提议数量的减少急剧下降。这说明本文提出的算法可以高效地生成高质量的提议,使得在提议数量减少时仍然可以保持稳定。
3.3 定量分析
SC3D[12]是当前唯一一个基于点云的三维目标跟踪算法,将本文提出的算法与SC3D[12]在跟踪汽车、行人、货车和自行车上的表现进行对比,实验结果如表3所示。
从表3中可以看出,本文提出的算法与SC3D[12]相比,在成功率及精准率上均高出了约10%,在数据丰富的汽车和行人数据集上具有十分明显的优势。但是,在数据量较少的货车和自行车上性能有所下降。这可能是因为该网络依赖于丰富的数据来学习更好的网络,特别是在生成潜在目标中心时。相比之下,SC3D[12]只需要较少的数据就可以满足两个区域间的相似度测量。为了进一步验证这种想法,使用在汽车数据上训练好的模型来测试货车,因为汽车和货车具有较高的相似性。如预期的一样,模型的性能从原来的成功率/精准率: 40.6%/48.1%变成了成功率/精准率: 52.4%/62.8%,而SC3D从成功率/精准率: 40.4%/47.0%变成了成功率/精准率: 37.2%/45.9%。
3.4 定性分析
图4展示了本文提出的算法在KITTI数据集上对单目标即汽车的跟踪过程,同时,与当前性能最好的SC3D算法进行了对比。
从图4中可以看出,本文提出的算法可以很好地对目标进行跟踪,在连续多帧中都可以准确地捕获到目标中心。同时,可以看到,即使在第120幀目标点云已经十分稀疏时,该算法仍然能够得到满意的结果。
3.5 复杂度分析
本文在KITTI测试集上跟踪汽车目标来验证提出算法的复杂度。具体而言,通过计算测试集所有帧汽车跟踪的平均时间,来计算模型的运行速度。
在NVIDIA2080S图形处理器上,本文提出的模型以43.5 FPS运行(包括处理点云的7.2 ms、模型计算14.7 ms以及后处理1.1 ms),相较而言SC3D以1.6 FPS运行,本文提出的算法具有更低的计算复杂度。
4 结 论
本文提出了一种基于深度霍夫投票的三维时敏单目标跟踪算法。主要贡献如下:
(1) 提出了一个基于三维点云的端到端时敏单目标跟踪算法,该算法可以高效稳定地对场景中的时敏单目标进行持续跟踪,得到单目标连续的运动轨迹。
(2) 提出了一种面向目标的特征提取方法,该方法充分挖掘模板和搜索空间中目标的相似性,将目标模板中的信息有效地编码到搜索空间中,为目标跟踪提供高鉴别力的特征信息,同时该方法对点云的无序性和不规则性保持鲁棒。
(3) 提出了一个基于深度霍夫优化投票的时敏单目标跟踪算法,该算法能够筛选并编码目标局部信息,有效应对点云的稀疏性和目标运动过程中外观变化。
(4) 提出的三维目标跟踪算法在KITTI数据集上取得当前最好的性能,同时具有较低的计算复杂度。
后续工作考虑优化霍夫投票算法,更加有效地提取目标的局部信息,进一步提高模型的性能,以应对更加具有挑战性的场景。
参考文献:
[1] Luo W J, Yang B, Urtasun R. Fast and Furious: Real Time End-to-End 3D Detection, Tracking and Motion Forecasting with a Single Convolutional Net[C]∥IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 3569-3577.
[2] Machida E, Cao M F, Murao T, et al. Human Motion Tracking of Mobile Robot with Kinect 3D Sensor[C]∥SICE Annual Conference (SICE), 2012: 2207-2211.
[3] Comport A I, Marchand E, Chaumette F. Robust Model-Based Tracking for Robot Vision[C]∥IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2004: 692-697.
[4] Asvadi A, Giro P, Peixoto P, et al. 3D Object Tracking Using RGB and LIDAR Data[C]∥IEEE 19th International Conference on Intelligent Transportation Systems, 2016: 1255-1260.
[5] Bibi A, Zhang T Z, Ghanem B. 3D Part-Based Sparse Tracker with Automatic Synchronization and Registration[C]∥IEEE Conference on Computer Vision and Pattern Recognition, 2016: 1439-1448.
[6] Liu Y, Jing X Y, Nie J H, et al. Context-Aware Three-Dimensional Mean-Shift with Occlusion Handling for Robust Object Tracking in RGB-D Videos[J]. IEEE Transactions on Multimedia, 2019, 21(3): 664-677.
[7] Kart U, Kmrinen J K,Matas J. How to Make an RGBD Tracker?[C]∥European Conference on Computer Vision (ECCV),2018.
[8] Kart U, Lukeicˇ A, Kristan M, et al. Object Tracking by Reconstruction with View-Specific Discriminative Correlation Filters[C]∥IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019: 1339-1348.
[9] Bertinetto L, Valmadre J, Henriques J F, et al. Fully-Convolutional Siamese Networks for Object Tracking[C]∥European Conference on Computer Vision (ECCV), 2016.
[10] Qi C R, Litany O, He K M, et al. Deep Hough Voting for 3D Object Detection in Point Clouds[C]∥IEEE/CVF International Conference on Computer Vision (ICCV), 2019: 9276-9285.
[11] Geiger A, Lenz P, Urtasun R. Are We Ready for Autonomous Driving? The KITTI Vision Benchmark Suite[C]∥IEEE Conference on Computer Vision and Pattern Recognition, 2012: 3354-3361.
[12] Giancola S, Zarzar J, Ghanem B. Leveraging Shape Completion for 3D Siamese Tracking[C]∥IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019: 1359-1368.
[13] Pieropan A, Bergstrm N, Ishikawa M, et al. Robust 3D Tracking of Unknown Objects[C]∥IEEE International Conference on Robotics and Automation, 2015: 2410-2417.
[14] Tao R, Gavves E, Smeulders A W M. Siamese Instance Search for Tracking[C]∥IEEE Conference on Computer Vision and Pattern Recognition, 2016: 1420-1429.
[15] Wang Q,Gao J,Xing J L,et al. DCFNet: Discriminant Correlation Filters Network for Visual Tracking[J].Computer Science,2017.
[16] Held D, Thrun S, Savarese S. Learning to Track at 100 FPS with Deep Regression Networks[C]∥European Conference on Computer Vision (ECCV), 2016.
[17] Zhu Z, Wang Q, Li B, et al. Distractor-Aware Siamese Networks for Visual Object Tracking[C]∥European Conference on Computer Vision (ECCV),2018.
[18] Wang Q, Teng Z, Xing J L, et al. Learning Attentions: Residual Attentional Siamese Network for High Performance Online Visual Tracking[C]∥IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 4854-4863.
[19] Li B, Wu W, Wang Q, et al. SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks[C]∥IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019: 4277-4286.
[20] Fan H, Ling H B. Siamese Cascaded Region Proposal Networks for Real-Time Visual Tracking[C]∥IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019: 7944-7953.
[21] Zhang Z P, Peng H W. Deeper and Wider Siamese Networks for Real-Time Visual Tracking[C]∥IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019: 4586-4595.
[22] Wang Q, Zhang L, Bertinetto L, et al. Fast Online Object Tracking and Segmentation: A Unifying Approach[C]∥IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019: 1328-1338.
[23] Li B, Yan J J, Wu W, et al. High Performance Visual Tracking with Siamese Region Proposal Network[C]∥IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 8971-8980.
[24] 王玲, 王家沛, 王鵬, 等. 融合注意力机制的孪生网络目标跟踪算法研究[J]. 计算机工程与应用, 2021, 57(8): 169-174.
Wang Ling, Wang Jiapei, Wang Peng, et al. Siamese Network Tracking Algorithms for Hierarchical Fusion of Attention Mechanism[J]. Computer Engineering and Applications, 2021, 57(8): 169-174.(in Chinese)
[25] 申亚丽. 基于特征融合的RGBT双模态孪生跟踪网络[J]. 红外与激光工程, 2021, 50(3): 236-242.
Shen Yali. RGBT Dual-Modal Siamese Tracking Network with Feature Fusion[J]. Infrared and Laser Engineering, 2021, 50(3): 236-242.(in Chinese)
[26] Charles R Q, Hao S, Mo K C, et al. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation[C]∥IEEE Conference on Computer Vision and Pattern Recognition, 2017: 77-85.
[27] Qi C R,Yi L,Su H,et al. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space[C]∥Advances in Neural Information Processing Systems (NIPS), 2017.
[28] Klokov R, Lempitsky V. Escape from Cells: Deep Kd-Networks for the Recognition of 3D Point Cloud Models[C]∥IEEE International Conference on Computer Vision, 2017: 863-872.
[29] Li Y Y,Bu R,Sun M C,et al. PointCNN: Convolution on X-Transformed Points[C]∥Advances in Neural Information Processing Systems (NIPS), 2018.
[30] Qi C R, Liu W, Wu C X, et al. Frustum PointNets for 3D Object Detection from RGB-D Data[C]∥IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 918-927.
[31] Shi S S, Wang X G, Li H S. PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud[C]∥IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019: 770-779.
[32] Yang Z T, Sun Y N, Liu S, et al. STD: Sparse-to-Dense 3D Object Detector for Point Cloud[C]∥IEEE/CVF International Conference on Computer Vision(ICCV), 2019.
[33] Li S L, Lee D. Point-to-Pose Voting Based Hand Pose Estimation Using Residual Permutation Equivariant Layer[C]∥IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019: 11919-11928.
[34] Ge L H, Cai Y J, Weng J W, et al. Hand PointNet: 3D Hand Pose Estimation Using Point Sets[C]∥IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 8417-8426.
[35] Chen X H, Wang G J, Zhang C R, et al. SHPR-Net: Deep Semantic Hand Pose Regression from Point Clouds[J].IEEE Access, 2018, 6: 43425-43439.
[36] Leibe B, Leonardis A, Schiele B. Robust Object Detection with Interleaved Categorization and Segmentation[J].International Journal of Computer Vision, 2008, 77(1/2/3): 259-289.
[37] Ballard D H. Generalizing the Hough Transform to Detect Arbitrary Shapes[J].Pattern Recognition, 1981, 13(2): 111-122.
[38] Ren S Q, He K M, Girshick R, et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks[C]∥IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015: 1137-1149.
[39] Wu Y, Lim J, Yang M H. Online Object Tracking: A Benchmark[C]∥IEEE Conference on Computer Vision and Pattern Recognition, 2013: 2411-2418.
[40] Kingma D P, Ba J. Adam: A Method for Stochastic Optimization[C]∥International Conference on Learning Representations (ICLR), 2015.
Time-Sensitive 3D Single Target Tracking
Based on Deep Hough Optimized Voting
Yang Xi,Lei Hang,Qian Weizhong*,Zeng Yifang,Wang Xupeng
(University of Electronic Science and Technology of China,Chengdu 610054,China)
Abstract: Aiming at the problem of time-sensitive single target tracking in 3D point cloud,a deep learning algorithm based on deep Hough optimized voting is proposed. Firstly, the algorithm uses PointNet++ network to calculate seed points and extract geometric features from template point cloud and search point cloud. A target-oriented feature extraction method is then used to encode the target information from the template into the search area. Secondly, potential target centers with high confidence are calculated and screened by seed point voting. Finally,multiple proposals are generated through sampling and aggregation of the target center points,and the proposal with the highest score is selected to generate a 3D target box. The algorithm can effectively avoid the time-consuming 3D global search, and is robust to the disorder, irregularity and sparsity of point cloud. In order to verify the effectiveness of the network, experiments are conducted on the public KITTI dataset. Experimental results show that the accuracy of the proposed network is improved by around 10%,compared to the current method based on 3D point clouds. At the same time, the method can run at 43.5 FPS on a single NVIDIA2080S graphics processor.
Key words: time-sensitive target; single target; target tracking; point cloud; Hough voting; deep learning; artificial intelligence
猜你喜欢
软件导刊(2017年1期)2017-03-06 00:28:18
科技创新与应用(2016年36期)2017-02-21 18:48:01
科技创新与应用(2017年3期)2017-02-18 15:23:09
无线互联科技(2016年13期)2017-01-10 02:28:42
电脑知识与技术(2016年27期)2016-12-15 19:37:37
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
法制与社会(2016年32期)2016-12-01 15:25:53
软件导刊(2016年9期)2016-11-07 22:20:49
软件工程(2016年8期)2016-10-25 15:47:34
科技视界(2016年5期)2016-02-22 12:25:31
