
改进的YOLOv4在飞机蒙皮损伤检测中的应用
2022-05-15 11:07农昌瑞杨智勇
海军航空大学学报 2022年2期
农昌瑞,张 静,杨智勇
(1.海军航空大学,山东烟台 264001;2.烟台理工学院,山东烟台, 264001)
0 引言
飞机蒙皮作为飞机的重要组成部分,是保持飞机良好的空气动力特性的重要支撑。飞机蒙皮大部分时间直接暴露在自然环境中,同时,在飞行过程中承受复杂的压力,非常容易产生裂纹、缺损等损伤。因此,飞机蒙皮损伤检测是飞机日常维护过程中的一项重要工作,是保障飞行人员人身安全、保护国家财产安全的重要环节。
目前,在飞行外场中,飞机蒙皮的检测仍以机务人员目视检查为主要方法,这种方法的检测效率低,对机务人员的专业素养要求较高。随着人工智能的发展,智能检测设备在工业中得到广泛的应用。因此,飞机蒙皮损伤检测急需1种智能化的检测方法,以提高飞机蒙皮损伤检测的效率,促进部队的智能化发展。
深度学习是人工智能领域的1 个研究热点,它凭借自身强大的自学习能力,在目标检测等任务中具有突出表现。卷积神经网络作为深度学习的1 个分支,广泛应用在桥梁损伤检测、道路裂缝检测、钢轨裂纹检测中。而在飞机蒙皮损伤检测中:文献[7-8]利用深度学习与元学习结合的思路,提高蒙皮罕见损伤类别的检测效果;文献[9-10]利用Mask R-CNN目标检测算法,将图像中的凹痕进行掩码分割,实现了对飞机凹痕的自动化检测;文献[11]搭建了基于YOLOv3 算法的飞机蒙皮检测网络,获取损伤类型和位置,并利用小孔成像原理对损伤部位的真实尺寸进行测量;文献[12]同样利用YOLOv3 目标检测模型对蒙皮的掉漆、裂纹、锈蚀、变形和撕裂等多种损伤类型进行检测,准确率达到了76%;文献[13]将树形结构引入到Faster R-CNN的分类网络中,提升了对飞机蒙皮紧固件的腐蚀损伤检测的腐蚀程度分级和定位精度。
深度学习方法在飞机蒙皮损伤检测中的应用较少,上述文献中采用的方法,检测速度与精度仍有待提高,同时,对于小目标的检测效果也欠佳。为此,本文提出了1种基于增强特征融合和自适应训练样本选择策略(Adaptive Training Sample Selection,ATSS)的YOLOv4 飞机蒙皮损伤检测方法,通过增强特征融合网络,将深层和浅层特征信息充分融合,丰富多尺度特征信息,提高小目标检测性能,同时改进正负样本的选择策略,进一步提高模型的检测性能。
1 YOLOv4算法原理
YOLOv4是YOLO(You Only Look Once)系列算法中性能十分强悍的版本,具有检测速度快、精度高的优点。YOLOv4由CSPDarkNet-53主干特征提取网络、SPPNets 空间金字塔池化网络、PANet 特征融合网络和检测头网络组成,如图1所示。
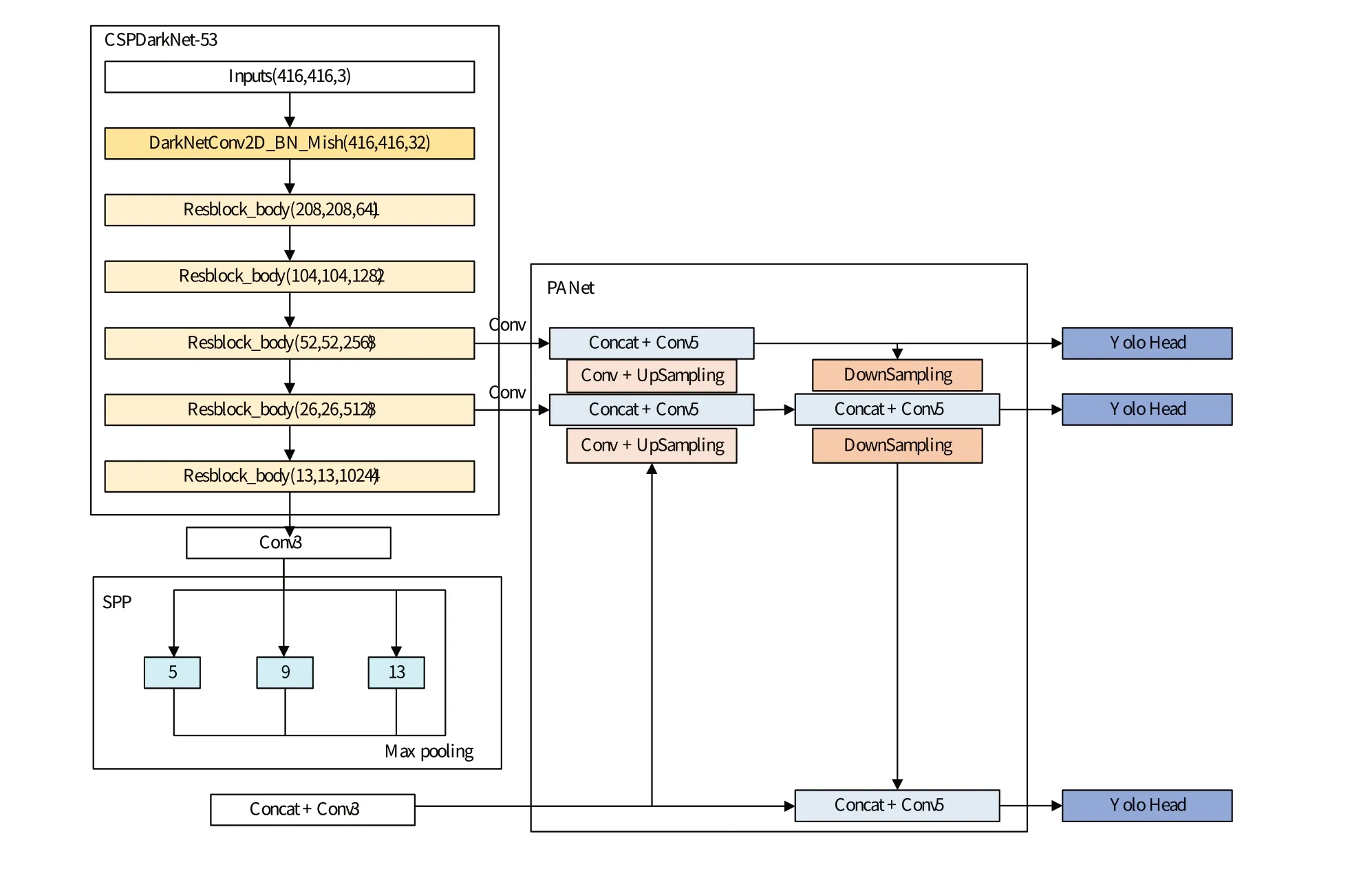
图1 YOLOv4结构Fig.1 Structure of YOLOv4
CSPDarkNet-53 在DarkNet-53 的基础上加入了CSPNet(Cross Stage Partial Network)模块的跨阶段特征融合思想,不仅提高了网络的特征提取能力,还减少了网络的计算量。CSPDarkNet-53 网络作为“特征提取器”,经过一系列的卷积操作后,分别输出52×52、26×26、13×13共3种不同尺度的特征层。
在CSPDarkNet-53 后,增加了SPPNet 模块。SPPNet模块的作用是固定图像尺寸,使得网络可以输入任意尺寸的图像。SPPNet 通过多个不同尺寸的池化核提取输入的特征图的特征信息,得到多尺度的池化特征图,同时还增加了1条桥接路径,将输入的特征图直接与多尺度的池化特征图进行融合,增加了融合图像的鲁棒性。
PANet 作为YOLOv4 的颈部网络,融合了FPN 和PAN 的结构思想。FPN采用自上而下的网络路径,利用上采样的方式,将高层图像的特征信息向下传递与低层特征信息融合,获得多尺度的融合特征图,PANet 在FPN 的基础上,增加了1 条从底层到顶层的自下而上的横向连接路径,在缩短信息传递的同时,提升了特征金字塔的特征融合性能。
检测头网络则是在多尺度融合特征图进行目标检测,输出目标的类别和位置边界框。
2 改进的YOLOv4算法
2.1 增强特征融合的结构优化
利用YOLOv4进行飞机蒙皮损伤检测过程中,发现YOLOv4 对于小目标(小裂纹)的检测效果并不理想,存在一定的漏检情况。为此,我们对YOLOv4 的结构进行分析,YOLOv4 利用特征网络中的3 个特征层进行特征融合,获得3个尺度的特征图,随后使用3个尺度的融合特征图进行预测,这3 个尺度的特征图能够检测大部分物体目标,但是对于小目标的检测能力仍有待提高。由于飞机蒙皮中的裂纹与背景的相似度较高,在特征提取的过程中,随着特征提取层数的不断加深,特征层中裂纹的特征信息越来越少,因此,多尺度特征图中的特征信息不够丰富,这就容易导致漏检的情况出现。
为此,本文增加了浅层的104×104 特征图用于预测,以提高对小裂纹目标的检测效果。浅层的特征图包含大量的边缘纹理信息,更有利于裂纹目标的检测。此外,为提升多尺度特征图的信息融合能力,丰富多尺度特征图的特征信息,本文通过增加特征融合层,将浅层的104×104 特征层与其他3 个尺度的特征层进行特征融合,进一步网络的特征提取能力。改进前后的特征融合网络结构,如图2、3所示。

图2 PANet结构Fig.2 Structure of PANet
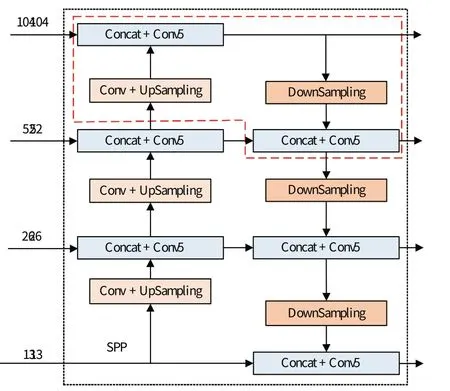
图3 改进的PANet结构Fig.3 Structure of improved PANet
2.2 基于K-means++的锚框聚类算法优化
锚框是一系列固定尺寸的先验框,其尺寸的设计关系着模型的收敛效果以及检测精度的优劣。YOLOv4 采用K-means 聚类算法来获取先验框的尺寸。K-means聚类算法通过随机方法选取初始的聚类中心,导致聚类结果对初始聚类中心的选取依赖性较大,容易产生局部最优解。如果聚类得到的先验框的尺寸不够准确,则无法较好地与目标的真实框匹配,导致定位不准确,甚至出现漏检的情况。
为了避免上述的问题,本文采用K-means++算法进行先验框的聚类。K-means++对K-means 的中心点初始化过程进行了改进,避免了局部最优解的产生,使得聚类的结果能够更准确地反映真实框的尺寸类型,获得更优的先验框尺寸。
为兼顾模型的计算量和模型的多尺度结构设计,本文选择先验框的数量为=12 。利用改进的Kmeans++算法获得的先验框聚类结果,如表1所示,先验框是输入416×416时的飞机蒙皮损伤图像数据集所采用的先验框尺寸。

表1 K-means++的聚类结果Tab.1 Clustering results of K-means++
2.3 正负样本选择策略优化
YOLOv4的样本选择策略是人工对IoU阈值进行预设,然后将每个样本的IoU与设定的阈值进行比较,以此来选取正样本,样本的IoU大于IoU阈值,则记为正样本,反之则为负样本。这种方法对人的依赖性较大,且阈值设置不恰当会导致正负样本不均衡,造成某一类别的目标训练效果下降,从而对模型的整体训练效果产生重要的影响。为此,我们引入了ATSS 方法,该方法可以根据样本的整体情况自动获取IoU阈值,在不带超参数的情况下,实现正样本和负样本的自动划分。ATSS的运算流程,如图4所示。
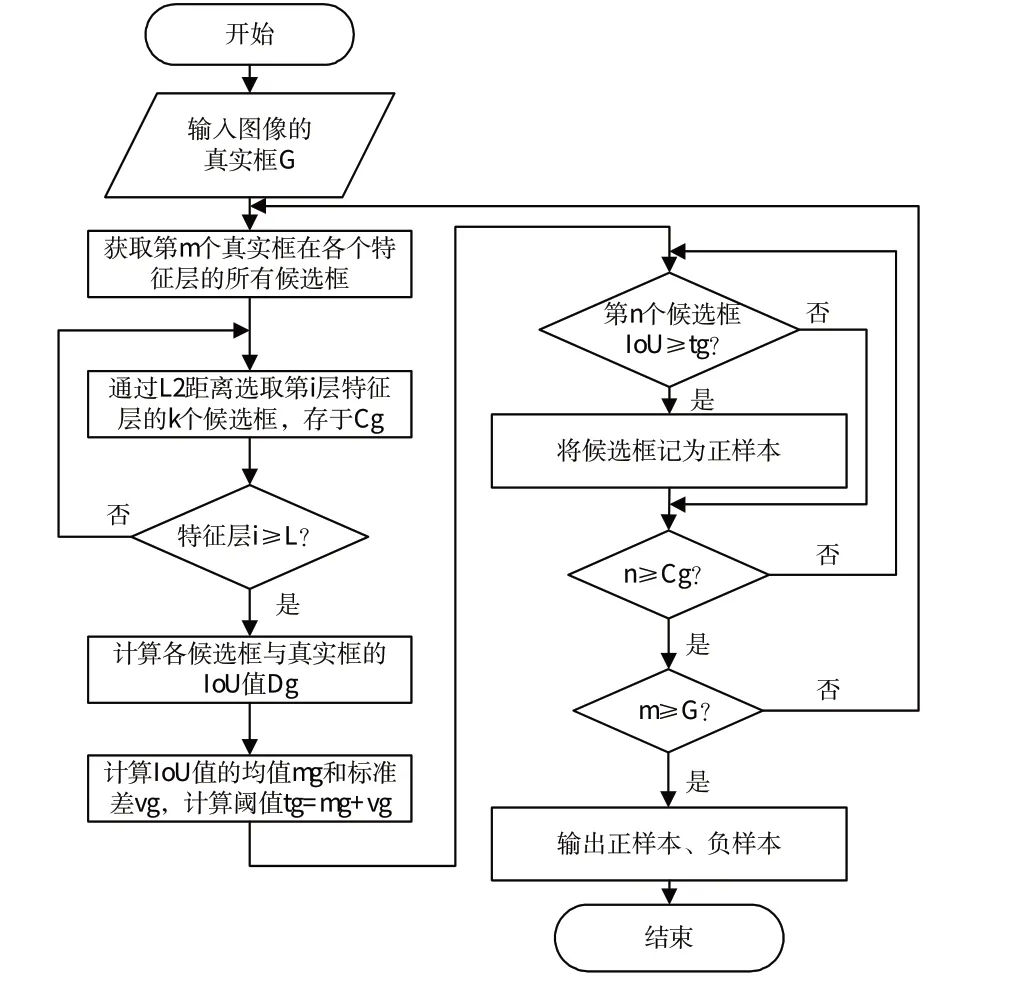
图4 ATSS流程图Fig.4 Flow chart of ATSS
训练过程中,当输入1 张包含个真实目标的蒙皮损伤图像时:首先,获得第个目标在所有特征层的先验框,在每一特征层上利用2 距离选择个距离最近的先验框作为候选正样本;其次,计算这些候选正样本与真实框的IoU 值,将这些候选正样本的IoU的均值与方差进行求和,获得最终的IoU 阈值;再次,将候选正样本的IoU 值与阈值进行比较,选择IoU 值大于阈值的候选正样本作为正样本,否则为负样本;重复上述步骤,直到找到所有真实目标的正负样本,最后,输出正负样本进行网络的回归训练。
自适应样本选择策略能够根据输入样本自适应获取阈值,相比人工设定阈值,使用这种方法得到的正负样本更加合理均衡,更有助于提升模型的训练效果,提高模型的检测精度。
3 训练过程与结果分析
3.1 实验环境配置
本文采用的实验环境配置,如表2所示。

表2 实验环境组成Tab.2 Components of the experimental environment
本文采用的是单GPU的计算机,算法的网络结构都是基于Windows 系统下的Tensorflow-1.13.0 以及Keras-2.1.5神经网络架构进行搭建,Keras具有大量封装好的各个神经网络层,直接调用便可进行目标检测模型的搭建,且其后端为Tensorflow 平台。所有的程序都是在Python3.6平台的第三方库调用,所有的第三方库都集成在集成平台Anaconda 环境中,其中,主要利用Opencv 库实现图像处理部分,利用Numpy 库实现数值计算,利用Matplotlib库实现图表处理。
3.2 实验数据集
本文采用某型飞机的蒙皮损伤图像1 300 张,将原图像按照80%、10%和10%的比例划分成训练集、验证集和测试集,如表3 所示。训练集和验证集主要用于网络训练过程中的训练和网络性能验证;测试集则用于网络训练结束后对网络泛化能力的测试。

表3 数据集的划分情况Tab.3 Partitioning of data sets
3.3 训练过程
在模型训练前,需要根据训练集的特点对超参数进行设置与优化,训练过程中,还需要根据训练损失对学习率进行调整优化,以提高模型的训练水平。在训练过程中,采用了以下几种训练技巧。
1)优化算法的选择。本文选取了适应性矩阵估计优化方法(Adaptive Moment Estimation,Adam)作为网络的优化算法,加快模型训练的收敛速度,强化模型的训练效果。
2)模型迁移训练方法。在公开数据集训练好的权重基础上,再用飞机蒙皮图像进行训练,有助于加快模型的训练速度,提升模型的检测精度。
3)标签平滑。为训练标签加上1 个较小系数的惩罚值,使模型的分类不会太准确,从而避免模型出现过拟合。
训练过程中:输入的图像尺寸统一调整为416×416,训练的迭代次数设置为epoch=800。冻结训练100次,解冻后训练700次。冻结训练的初始学习率为1×10,最小值为1×10;解冻后训练的初始学习率为1×10,最小值为1×10。当学习率衰减到最小值或到达迭代次数的最大值后会停止训练。
图5、6分别展示了网络训练过程中模型的损失变化曲线以及验证损失变化曲线。
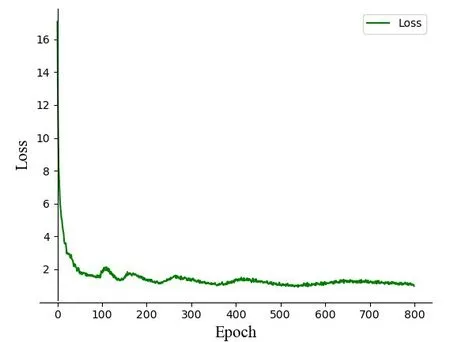
图5 训练过程中的损失曲线图Fig.5 Loss curve during training

图6 训练过程中的验证损失曲线图Fig.6 Verification loss curve during training
由训练的损失变化曲线可以看到,当网络训练epoch 为100 时,网络的冰冻训练阶段结束,训练损失值已经下降至小于2,随后进行解冻后的训练,损失值会有短时间的上升,后续开始下降,并进行小幅度的波动下降,直至训练结束,此时的损失值已经下降到小于1 的范围内。再看训练的验证损失变化曲线图,与损失曲线的变化趋势相似。2 张曲线图可以说明,模型训练的epoch 为100 时,已经开始收敛了,后续的训练使得模型的收敛效果更好。
3.4 实验结果与分析
在测试阶段,随机选取了部分测试图像进行拼接,这样获得的拼接图像能够包含多个类型的损伤目标,检测背景更复杂,检测难度更大,更有利于对模型的检测性能和泛化能力进行测试。图7展示了部分检测结果,其中,左侧代表YOLOv4的检测结果,右侧代表改进后YOLOv4的检测结果。

图7 检测结果图Fig.7 Detection results
由图7可以看到,除了左侧第2幅图像中YOLOv4没有检测到缺损目标,其他图像中的损伤目标基本上都能够检测出来。再从2组结果中各个类别的预测框对模型的定位能力进行分析,可以看到YOLOv4算法的预测框尺寸较紧凑,个别预测框没有完整框出目标区域,而是紧贴目标区域的边缘,而改进后的YOLOv4对于目标区域的定位能力则更优,目标区域能够完整地包含在预测框内。再对检测结果的置信度进行分析,YOLOv4的检测置信度在某些类别并不高,甚至没有达到0.6,而改进后检测的置信度均达到了0.8 以上。通过检测的结果来看,改进后的YOLOv4检测能力确实获得了一定的提升。
为了对改进后的模型检测性能的提升程度进行充分的分析说明,本文还与其他的算法模型进行对比分析。将训练集在Faster R-CNN、SSD 和YOLOv3 模型上分别进行训练,并采用测试集分别对各模型的检测性能进行测试,最后的检测结果,如表4所示。

表4 不同算法的检测性能对比Tab.4 Detection performance comparison of different algorithms
从表中可以看到,本文改进的算法由于增加了特征融合层与预测层,所以模型的检测速度有所下降,但是mAP值、精确率和召回率相比原来的YOLOv4算法均有小幅度的提升,其中mAP 提升了6.65%,精确率提升了3.85%,召回率提升了3.16%,说明本文的改进方法在一定程度上提升了模型的检测性能。
4 结论
文章针对基于深度学习的飞机蒙皮损伤检测算法开展研究,主要的工作总结如下:
1)借鉴了多尺度预测思想对YOLOv4 结构进行优化,增加了特征融合层与小目标预测层,使得网络能够充分利用浅层特征信息,提升了网络的小目标检测性能;
2)引入了K-means++的候选框聚类算法,通过聚类的方法对训练样本的真实框尺寸进行聚类,得到与训练样本的目标类别较符合的候选框尺寸,提高了预测框的定位能力;
3)引入了ATSS对网络训练的样本选择策略进行优化,通过自适应的方法获得更合理的阈值,提高了正负样本的分类效果,提升了模型的检测性能。
通过实验验证表明,模型的检测精度更高,检测结果更准确,算法性能得到了有效提升。
猜你喜欢
兵器装备工程学报(2022年10期)2022-11-01
教练机(2022年1期)2022-08-18
教练机(2022年1期)2022-08-18
汽车实用技术(2022年4期)2022-03-07
河南科技(2021年28期)2021-03-10
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
中学生数理化·高一版(2017年2期)2017-04-25
数学学习与研究(2017年3期)2017-03-09
电子技术与软件工程(2016年23期)2017-03-06
计算技术与自动化(2014年1期)2014-12-12
