
一种结合深度学习的运动重检测视觉SLAM 算法
2022-05-14 03:27房立金王科棋
计算机工程 2022年5期
房立金,王科棋
(东北大学机器人科学与工程学院,沈阳 110169)
0 概述
同步定位与建图(Simultaneous Localization and Mapping,SLAM)是指在没有周围环境先验信息的条件下,仅从机载传感器获取周围环境信息同时完成自身位姿估计和环境地图构建的工作。SLAM 技术在智能机器人实时定位、导航、自动驾驶、增强现实/虚拟现实等方面有着极其重要的应用。而视觉传感器具有成本低廉、提供数据信息丰富等特点,所以视觉SLAM 得到了研究人员的广泛关注。很多团队已经从不同的角度对视觉SLAM 问题进行了讨论,其中一些优秀的成果极大地推进了视觉SLAM的发展,例如LSD-SLAM[1]、DSΟ[2]、ΟRB-SLAM2[3]、VINS-Mono[4]等,但是为了简化计算,这些算法都是在静态环境假设基础上进行的。由于忽略了现实场景中运动物体对视觉SLAM 算法所带来的影响,这些模型很难适应复杂多变的真实场景。因此,针对动态环境下的视觉SLAM 算法进行研究就显得尤为重要。现阶段动态环境SLAM 算法主要通过处理动态物体来减少其对系统精度的影响。
运动物体检测方法可分为基于多视图几何的方法和基于深度学习的方法。基于多视图几何方法一般通过光流、对极几何约束、最小化重投影误差等检测运动物体。CENG 等[5]采用光流方法计算图像序列相邻帧之间像素运动。如果相机运动与动态物体存在运动一致性问题,则这种方法可能会失败。SUN 等[6]使用深度图提供的深度信息识别出明显的运动物体,此方法受限于传感器检测范围和分辨率,无法适应复杂环境。LI 等[7]利用深度图进行边缘提取,根据具有相似运动的点进行分组和分配概率来识别动态对象,但是它们具有较高的计算成本,并且在嘈杂环境或退化运动中无法正常地工作。浙江大学章国峰团队[8]提出的RDSLAM 算法[9]能够在动态环境中稳定运行,该算法的主要贡献是提出一种在线更新关键帧的方法,从而及时剔除环境中的运动物体,同时通过改进传统随机一致性采样(Random Sample Consensus,RANSAC)算法[10],提出一种自适应RANSAC 算法,在剔除大量外点情况下保证算法鲁棒性。
基于深度学习的方法在近年来开始兴起,清华大 学CHAΟ 等[11]针对动 态环境提出DS-SLAM 算法,该算法基于ΟRB-SLAM2 框架加入实时语义分割线程,将语义分割与对极几何约束方法相结合,过滤出场景中的动态特征。但是对极几何计算的基础矩阵容易受外点影响,从而影响算法的精度。BESCΟS 等[12]同样基 于ΟRB-SLAM2 框架提出了DynaSLAM 算法,该算法融合语义分割和多视图几何的方法检测场景中的运动特征,但语义分割算法模型复杂度过高无法满足实时性的需求。ZHANG等[13]基于深度学习目标检测算法提出动态场景下基于特征点法的视觉SLAM 算法,该算法能够提高跟踪精度和地图适应性。
MINA 等[14]提出一种基于特征的、无模型的、可感知对象的动态SLAM 算法Dynamic SLAM,其利用语义分割来估计场景中刚性对象的运动,而无需估计对象的姿势或具有任何先验知识的3D 模型。该算法生成动态和静态结构图,并能够提取场景中刚性移动物体的速度。BESCΟS 等[15]基于DynaSLAM 提出新一代视觉 SLAM 系统DynaSLAM II,其利用实例语义分割和ΟRB 特征来跟踪动态对象,并将静态场景和动态对象的结构放在捆绑调整(Bundle Adjustment,BA)中与摄像机的运行轨迹同时进行优化,并且三维运动对象的3D 边界框也可以在固定的时间窗口内进行估算和粗略优化。ZHANG 等[16]基于机器学习及深度学习提出RGB-D SLAM 算法来适应动态场景,提升视觉SLAM 在动态场景中的精度。但是,该算法占用计算机资源较大无法满足实时性的需求。
综上,现有动态环境SLAM 算法虽然能够解决部分动态场景问题,但是现有算法仍然存在模型复杂度高、计算量过大、应用范围有限、无法保证实时性等问题,且只进行一次运动物体判定,一旦判定失效则无法保证视觉里程计的稳定运行,从而影响整个SLAM 算法的运行精度。本文在保证计算量和实时性的同时,针对室内动态场景,提出一种基于深度学习和多视图几何的两阶段运动物体检测优化算法,以提高视觉SLAM 算法的运行精度和运行效率。
1 系统流程与框架
本文系统框架如图1 所示,按照系统运行流程可分为跟踪线程、局部建图线程、回环检测3 个线程。输入的RGB-D 图像序列,针对RGB 通道利用深度学习目标检测算法进行先验的运动物体预检测,并采用多视图几何算法进行运动物体重检测,确定真正产生运动的物体。在跟踪线程中,首先针对这些动态物体相对应的关键点进行语义数据关联,添加相应的运动状态。然后通过最小化重投影误差进行相机位姿估计,完成视觉里程计初始化,同时跟踪局部地图。最后根据本文提出的关键帧选取策略,在局部建图线程中插入候选关键帧,根据所插入关键帧中跟踪的空间地图点完成局部地图更新。同时在后端优化过程中执行局部光束平差(BA)法完成相机位姿优化。
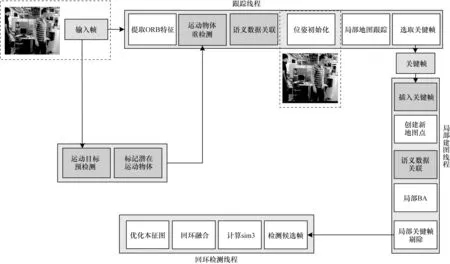
图1 本文系统流程与框架Fig.1 Procedure and framework of this system
回环检测线程将每一次插入的关键帧与之前存储的关键帧进行匹配。如果检测到环境中的闭环则计算关于相机位姿累计误差的相似性变换。由于本文回环检测过程主要参考ΟRB-SLAM2 的检测过程,因此本文不再赘述。
2 融合运动检测的视觉SLAM 算法
2.1 目标检测
本文将基于改进的SSD[17]网络作为解决实时目标检测的方案,考虑到移动机器人所搭载的计算平台具有运算能力相对较差、计算量不足等问题,为减轻网络参数量,采用MobileNet[18]网络替换原来SSD 网络中VGG-16[19]特征提取主干网络,在保证检测精度相对准确的同时能够满足目标检测器实时运行的需求,网络结构设计为全卷积网络结构,如图2 所示。

图2 全卷积神经网络结构Fig.2 Fully convolutional neural network structure
为了提高小目标物体检测精度,本文采用Deconvoluational 模块并 借鉴FPN[20]网络 结构,将 深层特征图和浅层特征图进行信息融合,融合后的特征图同时具有深层特征图的语义信息和浅层特征图位置信息。Decorder 部分主要借鉴了DSSD[21]的网络结构,经过在特征图上进行1×1 的卷积后得到两个支路,一个用于分类,另一个用于回归。进行此操作的主要目的是更多地利用深层网络特征。
针对室内场景目标检测,本文在MS CΟCΟ[22]数据集上对MobileNet-SSD 进行预训练,MS CΟCΟ 包含91 种不同的物体,其中包含人、猫、桌子、椅子等室内常见的物体。
2.2 运动物体预检测
本文采用上述深度学习目标检测网络进行运动物体预检测,即认定环境中潜在的运动物体。根据目标检测网络提供潜在运动物体的二维位置信息,对潜在运动物体相对应的特征点进行运动状态预标记。
首先根据Bounding Box 所提供运动物体的二维坐标(Px,Py,Pw,Ph)确定动态目标的位置,其中Px、Py与Pw、Ph分别表示检测框中心点坐标以及宽度和高度。根据这些信息能够计算出Bounding Box 的最大、最小坐标(umax,umax,umin,umin)。相机输入的图像I提取到的关键点的二维坐标定义为pi=(ui,νi),通过与(umax,umax,umin,umin)对比得到取值在最大、最小坐标区间内的特征点。将每一个Bounding Box 根据关键点数量进行编号排序并将检测框内的特征点pi对应归为一类,即pi∈Boxi。同时所有的Boxi均属于Box 潜在运动物体类,即Box1,Box2,…,Boxi∈Box。
为了提高检测精度,同时减少计算量,本文只计算关键帧的数据并且目标检测置信度大于默认阈值的Bounding Box(本文默认设置为0.7)内的特征点。通过上述过程能够得到环境中潜在的运动物体并分类得到潜在运动物体类Box,完成运动物体预检测与运动状态预标记过程。
2.3 运动物体重检测
本节针对运动物体预检测得到的潜在运动物体类中的运动对象进行运动物体重检测,两次确认这些物体是否产生实际运动,并将实际产生运动的物体所对应的特征点添加相应的运动状态。
在三维空间中,运动物体产生的像素运动与相机自身运动所产生的像素运动具有不同的运动方向。由于运动三维物体对应在二维图像中会产生不同的动态视差di,因此本文采用像素之间投影点的距离,即像素间的重投影误差di对动态视差进行度量。像素间的重投影误差主要取决于:
1)动态物体对应特征点的像素坐标。
2)动态物体对应特征点的深度。
3)运动物体与相机运动之间的相对运动角度。
为减少计算量,本文只计算Bounding Box 中匹配关键点像素间重投影误差di,定义如下:

其中:pi表示三维空间中相对应空间点Pi在当前帧中关键点的二维坐标表示通过前一帧匹配关键点在当前帧恢复的投影点坐标;di表示投影点与当前帧关键点的重投影误差。
重投影误差示意图如图3 所示。
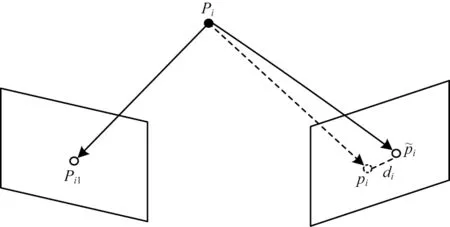
图3 重投影误差示意图Fig.3 Schematic diagram of re-projection error
本文引入可变阈值Δω对运动物体进行运动重检测,阈值大小由微分熵函数[23]进行确定。对于服从高斯分布的k维微分熵定义如下:

可变阈值Δω=f(H(xi)),当计算得到的动态视差di>Δω时,则被认定为实际产生运动的动态物体,将相对应的潜在运动物体类Boxi中所有的特征点添加运动状态ζi=0,表示该特征点在运动中,非潜在运动物体类Boxi的特征点和动态视差di>Δω的静态物体添加运动状态ζi=1。
2.4 静态语义数据关联与相机位姿优化
关键点相应运动状态添加完成后,并在相机位姿优化过程中剔除被标记为运动中的关键点,不参与到相机位姿优化光束平差法计算中。
输入到跟踪线程中的图像,经过运动物体检测后利用相邻两帧进行三角量测恢复出地图点,因为其对参考帧Fr中的特征点和当前帧Fc特征点完成了特征匹配。
跟踪线程计算出本质矩阵和单应矩阵,如果当前场景为平面情况,则采用单应矩阵计算当前帧的相机位姿;如果当前场景为非平面情况,则采用基础矩阵计算当前帧的相机位姿。
当系统初始化成功后,当前帧Fc利用恒速模型进行位姿跟踪,如果初始化失败,则重置当前参考帧Fr与相邻关键帧进行重定位恢复相机位姿。本文利用运动状态为静态的关键点,即运动状态ζi≠0 的特征点进行相机位姿恢复以及优化。因为根据ICP[24]算法已经得到了N对相互匹配的3D 点的三维坐标Pi和对应投影点的二维坐标pi,则对应R、t的当前帧相机位姿坐标ξ相机位姿李代数的形式为:

其中:ϕ∈R3为相机旋转坐标;φ∈sο(3)为相机平移坐标。
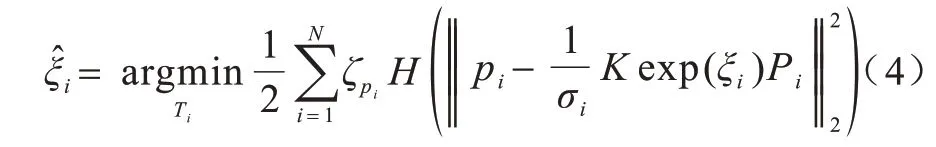
2.5 关键帧选择策略
关键帧的选择策略影响整个系统的运行精度,同时局部地图的质量也与关键帧的选择有密切的关系,本文关键帧选择遵循以下规则:
1)当前帧至少跟踪20 个以上空间中的三维地图点,同时当前帧内特征点数量不少于相邻关键帧的90%。
2)当前关键帧需要在跟踪线程中被跟踪20 次以上,才能够在局部建图线程空闲时插入。
3)当前帧相机位姿与相邻关键帧的相机位姿间的旋转姿态角度不大于设定阈值。
关键帧选择条件如下:
1)保证所选择的候选关键帧跟踪到空间中数量足够多的地图点,并且候选关键帧中提取到的环境信息足够丰富。
2)保证所选取的关键帧与相邻帧有足够的共视关系,能够通过共视关键帧获取到尽可能多的环境信息,并且保证候选关键帧相对稳定提高系统精度。
3)防止相机在俯仰或转动等纯旋转情况下,相机视差发生较大的变化导致跟踪失败,确保选取的候选关键帧稳定并且连贯。
2.6 算法复杂度分析
在未知环境中,SLAM 问题主要解决机器人自身定位和地图构建问题,将此过程利用数学表达式进行描述,可以抽象为状态估计问题。假设移动机器人在未知环境中连续运动,在t=0,1,···,N的时间段内,有对应运动机器人位姿x0,x1,…,xN,机器人观测到的路标点y0,y1,···,yN以及在xi点观测到路标yj对应的信息zi,j。利用以上信息能够列出SLAM 运动状态估计过程中的运动方程式与观测方程式:

其中:ui表示在传感器读入数据;wi与νi,j均为噪声误差。融合运动检测视觉SLAM 算法的运算复杂度和空间复杂度计算可以分为以下2 个部分:
1)将视觉里程计中的运动检测算法的时间复杂度作为一个整体进行分析,其总体运算复杂度为Ο(n2),空间复杂度为Ο(n2)。
2)运动方程和观测方程在更新过程中,其运算复杂度为Ο(n3),空间复杂度为Ο(n2)。
因此,融合运动检测视觉SLAM 算法的总体运算复杂度为Ο(n3),空间复杂度为Ο(n2)。
3 实验与结果分析
本文选取TUM RGB-D Benchmark[25]数据集,该数据集中的某些序列包含运动对象,如果不考虑这些运动对象,则会影响轨迹估计精度。在本文实验中,使用静态环境序列和属于动态对象类别序列的子集来评估所提出算法的性能。本文算法在这两种情况下进行性能和精度的测试,并与ΟRB-SLAM2、DynaSLAM 进行对比。
3.1 视觉里程计对比评估
本节实验主要对比不同算法之间视觉里程计的漂移量,因此采用相对位姿误差(Relative Pose Error,RPE)作为评价指标。相对轨迹误差通过计算相同时间段间隔真实值与估计值之间变化量的差值进行评估。相对轨迹误差在时间间隔的定义如下:
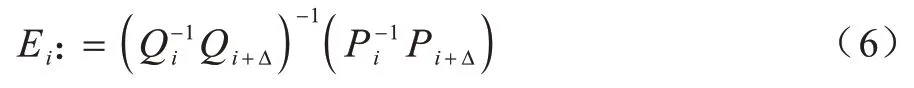
在不同序列下的比较结果如表1 所示,表中fr2/desk、fr3/l/house 为静态场景序列,fr3/w/half、fr3/w/rpy、fr3/w/static、fr3/w/xyz 为动态场景序列,下文同。其中RMSE 表示均方根误差,加粗字体为结果最优。它的定义是观测值与真实值之间差的平方和与观测次数比值的平方根。其计算公式定义如下:

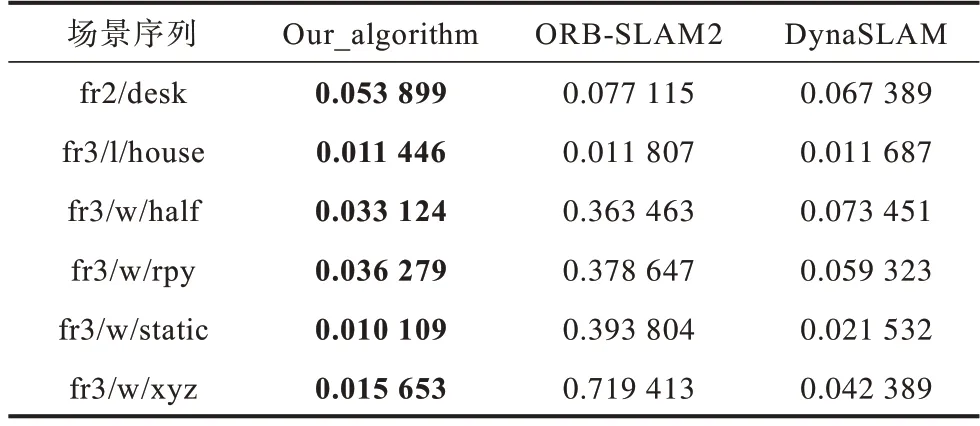
表1 里程计相对位姿误差的RMSE 比较Table 1 RMSE comparison of odometry relative pose error
表2 为相对位姿误差的误差均值(Mean),表3表示相对位姿误差的残差平方和(Sum of Squares due to Error,SSE),其中加粗字体为结果最优。

表2 里程计相对位姿误差均值比较Table 2 Mean comparison of odometry relative pose error

表3 里程计相对位姿误差SSE 比较Table 3 SSE comparison of odometry relative pose error
由表1~表3 误差信息对比可知,本文算法在静态和动态环境图像序列中均取得较好的结果,在动态环境序列中的性能均优于ΟRB-SLAM2。
通过在ΟRB-SLAM2 基础上引入运动物体检测算法可以精确删除动态关键点,使得SLAM 线程不受移动对象的影响。在所有动态序列中,相对位姿误差RMSE 均得到了有效的改善。虽然本文算法主要适用于现实中的动态环境,但是在静态序列中,本文提出的SLAM 算法的性能对比ΟRB-SLAM2 同样保持在同一精度水平。
本文算法与ΟRB-SLAM2 的视觉里程计相对位姿误差对比如图4 所示。通过对比相对位姿误差图,可知ΟRB-SLAM2 系统在动态场景fr3/w/static、fr3/w/xyz 的误差很大,与同样具有运动物体检测算法的DynaSLAM 对比,本文算法也同样具有精度优势。

图4 视觉里程计相对位姿误差Fig.4 Relative pose error of visual odometry
3.2 SLAM 算法对比评估
在评估SLAM 算法实验部分,本文采用绝对轨迹误差(Absolute Trajectory Error,ATE)作为评价指标,该指标通过对比真实值与估计值之间的差异来进行评估,适用于估计机器人运动轨迹误差。绝对轨迹误差dj计算公式定义如下:

其中:xj表示估计轨迹表示真实轨迹。
表4 为算法绝对轨迹误差的均方根误差对比,表5 为算法绝对轨迹误差的误差均值对比,表6 为算法绝对轨迹误差的残差平方和对比。对比表4~表6可知,ΟRB-SLAM2 算法 在fr2/desk 和fr3/l/house 两种静态场景图像序列下,绝对轨迹误差相对较小,但与本文算法相比仍有差距。

表4 不同算法绝对轨迹误差的RMSE 对比Table 4 RMSE comparison of absolute trajectory errors of different algorithms
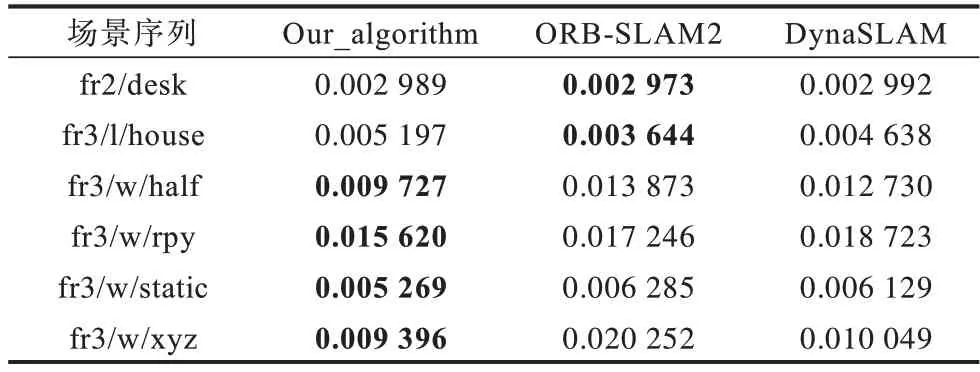
表5 不同算法绝对轨迹误差均值对比Table 5 Comparison of mean absolute trajectory errors of different algorithms

表6 不同算法绝对轨迹误差的SSE 对比Table 6 SSE comparison of absolute trajectory errors of different algorithms
对比表4~表6 可知,本文算法相比DynaSLAM在4 种不同相机运动的动态环境图像子序列上的ATE 指标也取得了更小的误差值,算法精度更高。
图5 对比了ΟRB-SLAM2 和本文算法在TUM 数据集中fr3/w/xyz 和fr3/w/static 两个动态环相机位姿估计结果发生很大的偏移,最大ATE 值达到1.2 m 以上。本文算法针对运动物体进行处理后轨迹估计更加精准,误差大幅降低。
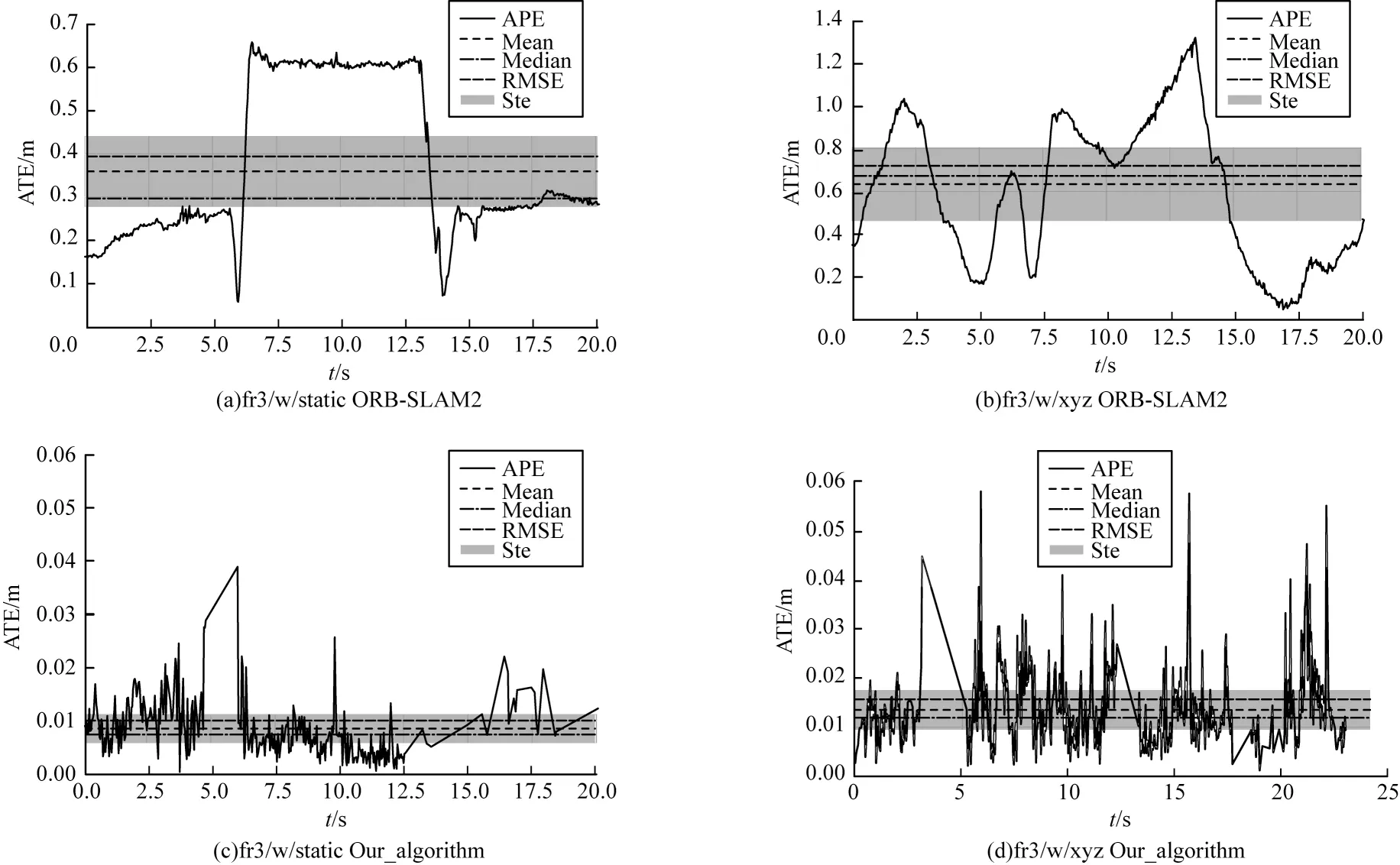
图5 算法绝对轨迹误差对比Fig.5 Comparison of algorithm absolute trajectory errors
图6 表示ΟRB-SLAM2 与本文算法在动态序列下预测值与真实值之间的轨迹误差。其中图6(a)、图6(b)为ΟRB_SLAM2 算法轨 迹误差,图6(c)、图6(d)为本文算法轨迹误差。通过对比可知,本文针对运动物体剔除后算法更加鲁棒,运行轨迹更加接近真实值。
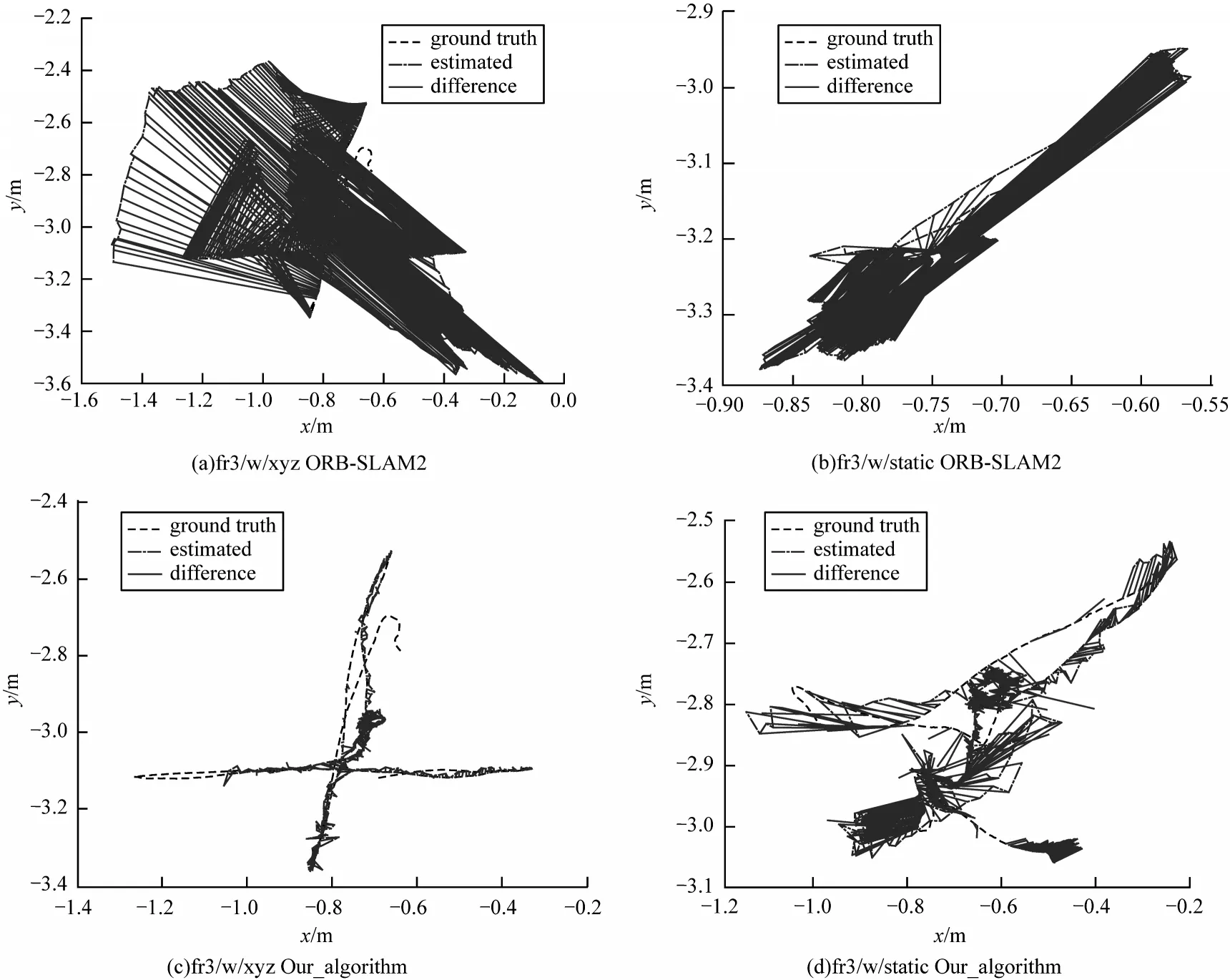
图6 算法轨迹误差Fig.6 Algorithms trajectory error
在验证算法鲁棒性方面,本文采用TUM 数据集中包含移动物体的fr3/Walking 动态序列验证。Walking 子序列中包含两个移动的人,在前景和背景中不断运动。该图像序列中包含4 种不同相机运动:
1)fr3/w/xyz 子序列表示相机沿X-Y-Z轴(XYZ)移动。
2)fr3/w/half 子序列表示相机沿半径为0.5 m 的半球面(half)轨迹运动。
3)fr3/w/static 子序列表示相机保持静止(static)状态。
4)fr3/w/rpy 子序列表示相机在俯仰、翻滚和偏航轴上旋转(RPY)运动。
本文算法分别在上述4 个不同相机运动的数据集上实验验证,在应对不同相机运动的过程中本文算法运行精度对比ΟRB-SLAM2、DynaSLAM 表现最优。在应对4 种不同相机运动的动态场景中,本文平均绝对轨迹误差相对于DynaSLAM 有明显提升。
3.3 系统实时性评估
利用TUM 数据集中提供的多种不同场景下的连续图像对本文系统实时性进行测试。测试图片分辨率为640×480 像素,系统中只有跟踪线程需要对输入的图像进行实时处理。
本文实验采用INTER i5 CPU、内存8 GB、NVIDIA 1060TI GPU、显存6 GB 进行实验。测试结果如表7 所示,算法平均耗时0.025 s,本文改进后的视觉SLAM 算法的跟踪线程平均处理速度能够达到6 frame/s,基本满足实时性的需求。

表7 跟踪线程耗时对比Table 7 Comparison of tracking thread time s
表7 表示本文算法与DynaSLAM 跟踪线程中所消耗的时间对比。在与DynaSLAM 在相同实验设备运行动态环境序列时,本文算法相较于前者跟踪速度提升了10 倍以上,满足室内环境实时跟踪的需求。
由于实际场景中移动机器人搭载的设备计算能力有限,DynaSLAM 算法是结合深度学习语义分割与多视图几何完成运动物体剔除。由于计算资源有限,在一些情况下语义分割无法实时完成,采用多视图几何进行运动检测,这样会使一些特征点剔除失败,导致精度降低。本文算法所需计算资源相对较小,同时完成两次运动物体检测,提高了SLAM 算法的运行精度。本文算法对比ΟRB-SLAM2 与DynaSLAM 算法特征提取结果如图7 所示。

图7 算法特征点提取对比Fig.7 Comparison of algorithm feature point extraction
通过图7 对比可知,ΟRB-SLAM2 算法虽然运行速度达到实时性的需求,但是算法并未针对动态物体进行处理,算法中一部分特征点提取到动态物体上,导致算法精度降低。DynaSLAM 虽然针对运动物体进行处理,但是由于计算资源有限,在部分低动态场景中也产生了特征点的错误提取。本文算法利用两阶段运动物体检测,在计算能力较低的平台,在保证实时性的同时实现了运动物体的精准剔除,提取结果均优于ΟRB-SLAM2 以及DynaSLAM 算法。
4 结束语
本文面向室内动态环境,提出一种基于深度学习和多视图几何的视觉SLAM 算法。利用两阶段运动物体检测确定实际产生运动的物体,基于语义数据关联算法采用静态特征点优化相机位姿。针对跟踪线程和局部建图线程,提出一种关键帧选取策略,从而减少运动物体对算法精度的影响,提高算法稳定性。实验结果表明,本文算法的绝对轨迹误差相较于改进之前的ΟRB-SLAM2,平均均方根误差降低40%。在算法实时性方面,与DynaSLAM 相比算法实时性提高10 倍以上。因此,本文算法能够在室内动态环境下稳定运行,实现准确的位姿估计。由于在动态环境中运动物体的速度、位姿等信息能够有效帮助自身系统完成定位,因此下一步研究如何将动态物体运动位姿估计和静态场景集成到一个视觉SLAM 中,提高视觉SLAM 在复杂动态环境中相机位姿估计的准确性和鲁棒性。
猜你喜欢
中学生数理化(高中版.高考数学)(2022年4期)2022-05-25
现代计算机(2022年4期)2022-04-24
微型电脑应用(2020年12期)2020-12-25
中国惯性技术学报(2020年4期)2020-12-14
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
浙江海洋大学学报(自然科学版)(2020年5期)2020-06-19
扬州大学学报(自然科学版)(2019年2期)2019-08-12
电子技术与软件工程(2019年6期)2019-04-26
科技与创新(2018年12期)2018-06-22
