
基于PSO-SRU 深度神经网络的煤自燃温度预测模型
2022-05-13 02:12:40贾澎涛林开义郭风景
工矿自动化 2022年4期
贾澎涛,林开义,郭风景
(1.西安科技大学 计算机科学与技术学院,陕西 西安 710054;2.陕西建新煤化有限责任公司,陕西 黄陵 727300)
0 引言
我国对煤炭的需求短期内不会发生根本性变化,煤炭在能源结构中仍将长期处于主体地位[1-2]。长期大量开采导致采空区遗煤增多,煤自燃灾害频发[3-4]。煤自燃是一个复杂的动态氧化过程,一旦发生会造成巨大资源浪费和环境污染[5-6]。因此,开展煤自燃的温度预测研究对防控煤自燃灾害发生具有重要意义[7]。
近年来,学者们围绕煤自燃温度预测相关问题提出了多种方法,主要有测温法、自燃实验预测法和气体分析法等[8-10]。其中气体分析法根据煤体氧化升温时不同温度状态会释放不同浓度的气体产物这一规律,通过监测煤自燃过程中气体指标浓度预测煤自燃温度[11-13]。气体分析法因规律性强、灵敏度高而被广泛应用[14-15]。邓军等[16]建立了支持向量回归(Support Vector Regression,SVR)的煤自燃预测模型,并采用粒子群(Particle Swarm Optimization,PSO)选取最佳的核函数和惩罚因子,提高了预测精度,但该模型对参数选取敏感,易陷入局部最优。刘宝等[17]提出了基于相关向量机(Relevance Vector Machine,RVM)的煤自燃预测方法,简化了模型参数选取,泛化性较好,但预测精度有待提高。昝军才等[18]采用反向传播(Back Propagation,BP)神经网络学习煤温与气体指标的非线性映射关系,实现煤自燃温度预测,但该方法易出现过拟合现象,泛化能力较差。郑学召等[19]建立了基于随机森林(Random Forest,RF)的煤自燃温度预测模型,优化了决策树深度和数量,参数优化简单,泛化性好,但预测精度和模型鲁棒性有待提高。
综上可知,现有的煤自燃温度预测方法存在预测模型泛化性不强、鲁棒性较差的问题。针对上述问题,本文考虑真实煤自燃监测数据前后具有强关联性,提出了基于PSO 算法优化简单循环单元(Simple Recurrent Units,SRU)的煤自燃温度预测模型-PSO-SRU 模型。将煤自燃多特征数据输入SRU 预测模型,利用SRU 神经单元挖掘特征数据间的非线性关系,根据挖掘到的规律和当前煤自燃特征的输入预测煤自燃温度;通过改进的PSO 算法优化SRU 预测模型参数,提高了模型的预测精度和鲁棒性。该模型可为利用深度神经网络预测煤自燃温度提供解决思路。
1 理论基础
1.1 SRU
SRU 是循环神经网络(Recurrent Neural Network,RNN)的优秀变体[20],与长短期记忆网络(Long Short Term Memory,LSTM)和门循环单元(Gate Recurrent Unit,GRU)等循环神经单元的结构一样,都是基于“门控”结构构建。SRU 简化了单元结构,使RNN更加轻便,其内部结构和网络结构如图1 所示。

图1 SRU 内部结构和网络结构Fig.1 Simple recurrent units(SRU) interior structure and network structure
SRU 结构计算过程如下:
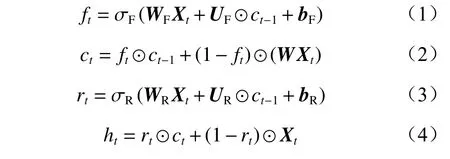
式中:ft为遗忘门,用来决定单元状态需要丢弃过去哪些信息,t为时刻;σF为遗忘门激活函数;WF为遗忘门细胞状态的参数矩阵;Xt为输入数据;UF,bF,UR,bR为需要在训练过程中学习的参数向量;⊙为点乘运算符号;ct-1,ct为神经单元状态;W为细胞状态参数矩阵;rt为重置门,控制前一单元状态有多少信息被写入到当前细胞ht中;σR为重置门激活函数;WR为重置门细胞状态的参数矩阵。
SRU 网络结构由轻量循环(式(1)和式(2))和高速网络(式(3)和式(4))2 个重要部分组成。轻量循环采用UF⊙ct-1的计算方式,降低单元与单元间的依赖程度,提高运算速度。高速网络采用(1-rt)⊙Xt跳跃连接的方式,使梯度能够直接向前传播,缓解梯度消失和梯度爆炸问题。
1.2 PSO 算法
PSO 算法从拟态生物学的角度出发,将鸟群在空间内的觅食过程、状态及行为抽象为无质量粒子在多维空间内搜索满足最优适应度值的过程、状态和行为。其核心思想是信息共享,通过粒子群中记录的全局最优适应度和个体最优适应度更新粒子的速度和位置,计算自身的适应度,将信息分享给群体,各粒子调整自身的速度和位置,朝最优适应度粒子周围聚集,达到搜索终止条件的最优适应度粒子的每个维度值即为全局最优解[21]。
在D维搜索空间下,PSO 算法的更新公式为
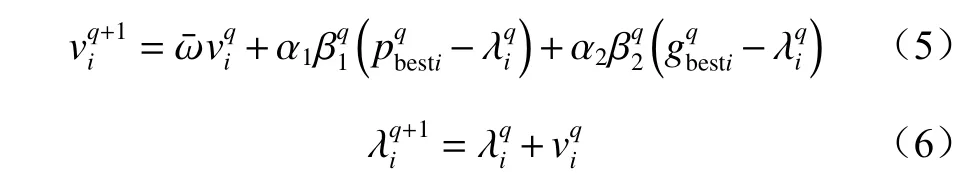
式中:νi,λi分别为第i个粒子的速度和位置,i=1,2,…,s,s为粒子数,通常取40;为惯性权重,通常取0.9;q为当前迭代次数;α1,α2为学习因子,控制着第q-1 次迭代的经验对第q次迭代的影响程度,通常α1=α2=0.5;β1,β2为[0,1]内的随机数;pbesti为个体粒子历史最优位置;gbesti为全局最优个体粒子位置。
2 基于PSO-SRU 的煤自燃温度预测模型
2.1 PSO-SRU 模型构建
PSO-SRU 模型架构如图2 所示。通过煤自燃程序升温实验采集到n个时刻煤自燃数据样本,令数据集合X={X1,X2,…,Xn},Xt为第t个时刻样本,Xt=[xt1,xt2,…,xtm],xtj为第t个时刻第j个预警指标气体浓度,t=1,2,…,n,j=1,2,…,m,m为预警气体指标个数。PSO-SRU 模型构建过程如下:
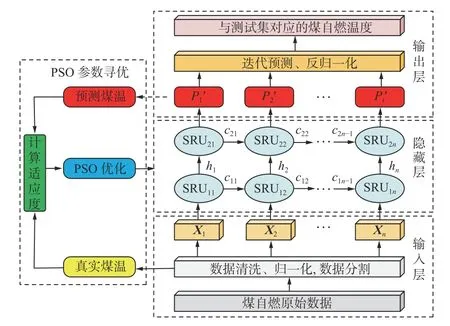
图2 PSO-SRU 模型架构Fig.2 Temperature prediction model framework for coal spontaneous combustion based on particle swarm optimization and simple recurrent unit(PSO-SRU)
(1)通过实验采集煤自燃预警指标气体浓度,对数据进行清洗、归一化处理,计算气体与煤温相关性,筛选相关性气体指标并将数据集划分为训练集和测试集。
(2)建立SRU 煤自燃温度预测模型,将Xt输入SRU 进行矩阵计算,通过式(1)-式(4)计算得到下一时刻煤自燃温度。
(3)提升SRU 预测模型性能,将隐藏层神经元数L1,L2,学习率ɛ及模型训练次数e作为PSO 算法寻优对象,改进PSO 算法,提升寻优算法性能。
(4)用最优超参数建立SRU 预测模型,将测试集输入参数最优的SRU 预测模型,得到煤温预测结果。
2.1.1 数据采集及处理
实验选取某矿采集的气煤煤样进行程序升温实验。装煤总质量为1 kg,装煤高度为17.5 cm,混合煤样平均粒径为 4.18 mm,空隙率为0.48%,平均升温速率为0.3 ℃/min,供风量为120 mL/min。利用程序升温装置对煤样进行加热,并向程序升温装置送入预热空气,测定气体产物,当温度升高到400 ℃预定温度时停止加热。共得到625 组样本数据,记录气煤煤样氧化升温过程中产生的多种气体(如CO,CO2,CH4,C2H4,O2)浓度和温度等。625 组原始数据中包含缺失值和异常值的数据,会使建模过程陷入混乱,导致输出结果不可靠,通过剔除异常值并对缺失值进行插补,得到601 组数据,采用MinMaxScaler方法将数值映射到[0,1]之间。
2.1.2 预警气体指标分析
不同气体指标与煤温随时间变化关系如图3 所示。从图3(a)可看出,因为煤氧复合反应的发生,实验环境中的O2体积分数呈现随煤温升高而逐渐减小的规律。从图3(b)、图3(c)可看出,从煤温开始发生变化时,CO 和CH4体积分数呈现随煤温升高而不断增大的趋势,并且与煤自燃温度变化有明显的强相关性关系,具有很好的规律性,可以用于煤自燃预测预警的整个周期。从图3(b)、图3(d)可看出,CO2和C2H4体积分数在煤温为100 ℃以前没有明显变化,而在煤温达到100 ℃以后,能够反映煤温的剧烈变化,因此,可以作为煤自燃发生后期的预警气体。
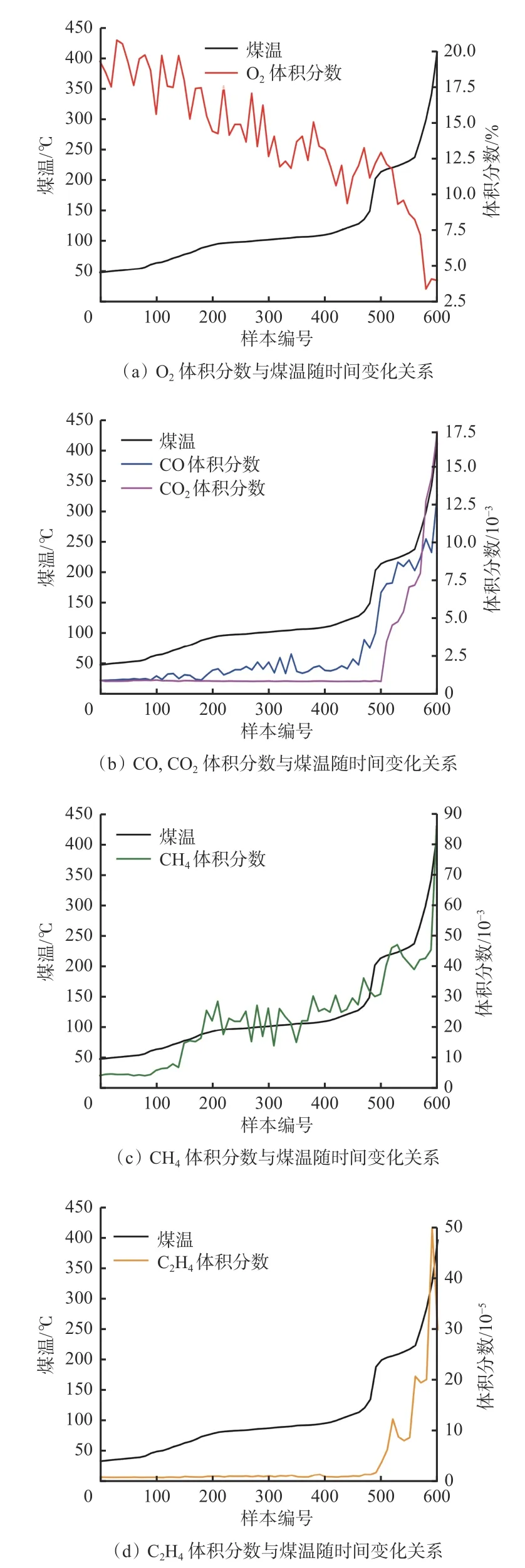
图3 不同气体指标与煤温随时间变化关系Fig.3 Gas indicators and coal temperature as time changes
2.2 SRU 预测模型参数寻优
2.2.1 改进PSO 算法
为了平衡全局搜索和局部搜索,提高PSO 算法寻优的性能,根据[-4,4]之间双曲正切曲线变化规律对标准PSO 算法权重进行改进,使惯性权重随粒子搜索迭代次数动态改变。改进后的PSO 算法权重更新公式为

改进后的权重随迭代次数变化趋势如图4 所示。

图4 动态的惯性权重Fig.4 Dynamic inertia weight
为了进一步避免算法陷入局部最小值,提高种群多样性和跳出局部极值的能力,从拟态物理学角度出发,将粒子调整自身朝个体最优位置和全局最优位置飞行的过程看作是受到二者的引力作用。与此同时,所有粒子都避免自己成为全局最差粒子,纷纷远离当前全局最差粒子,将粒子远离全局最差粒子构造为一股排斥力,使粒子陷入局部极值时迅速跳出[24-25]。在前人研究的基础上,综合考虑粒子在飞行过程中受到的引力和排斥力,即粒子更新将同时受到2 个引力和1 个排斥力的影响,对粒子速度更新进行改进,改进后的粒子速度更新公式为
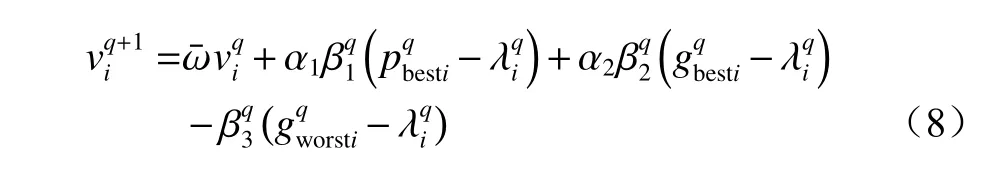
式中:gworsti为全局最差个体粒子位置;β3为[0,1]内的随机数。
第q+1 次迭代时,粒子λi受到的个体最优粒子对其的引力为pbesti-λi,受到全局最优粒子对其的引力为gbesti-λi,受到全局最差粒子对其的排斥力为gworsti-λi,加入排斥力后,能使粒子更快地向全局范围内适应度小的位置聚集,提高算法的收敛速度。
2.2.2 改进PSO 优化SRU 预测模型
(1)将获取的煤自燃温度和气体指标原始数据进行数据预处理,将数据划分为训练集和测试集。
(2)确定参数寻优范围,初始化粒子群参数。最大迭代次数设为1 000;寻优范围设置如下:2 个隐藏层神经元数的取值范围均为[1,200],学习率边界范围为[0.000 1,0.01],训练次数寻优范围为[1,500]。
(3)利用当前粒子群中各粒子的参数取值建立SRU 煤自燃温度预测模型,学习训练集中气体指标与煤自燃温度之间的非线性规律,再对测试集样本进行预测。
(4)计算各粒子适应度,更新共享信息。记录当前取得最小适应度的粒子,更新粒子群的全局最优位置gbesti;更新每个粒子从搜索开始后各自的历史最优位置pbesti;记录当前取得最大适应度的粒子,更新粒子群的全局最差位置gworsti。适应度计算公式:
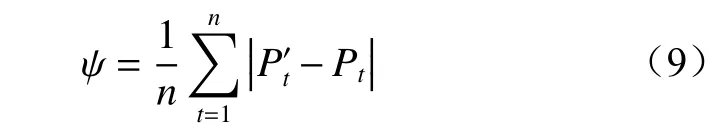
(5)判断是否达到终止条件。若未达到终止条件,根据迭代次数更新,并依据式(8)、式(6)更新每个粒子的速度和位置,然后转步骤(2)继续执行;否则执行步骤(6)。
(6)输出全局最小适应度及全局最小适应度对应粒子的位置参数,该位置参数即为全局最优解。
3 实验与结果分析
实验环境配置如下:CPU 型号为i7-3612QM;GPU型号为RTX1080Ti;内存容量为12 GB;编程语言为Python-3.6;编程平台为PyCharm-2019.2.5(Professional Edition);集成环境管理为Anaconda Navigator-1.3.1;深度学习框架为PyTorch-1.6;机器学习框架为Scikitlearn-0.23.2。
3.1 预警指标择优
煤氧复合作用下,煤体氧化升温过程中会释放不同浓度的气体产物,需要分析各气体指标与温度在数据上的紧密程度,筛选出与煤自燃温度相关性尽可能大的气体指标。对插补过的指标气体数据与煤样温度数据进行相关性分析,对数据的每一列均采用Kolmogorov-Smirnov 检验,其P-value 均小于0.001,采用Pearson 相关系数法分析相关性。
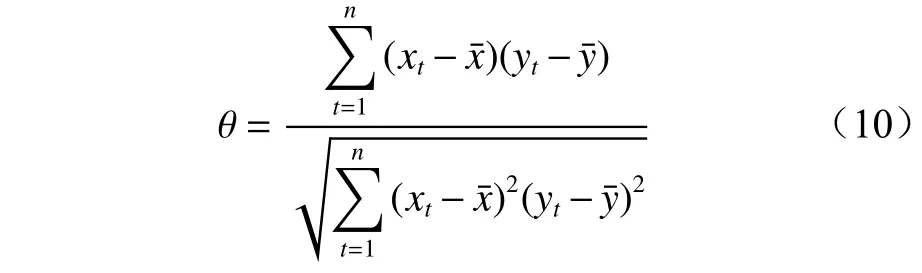
式中:θ为线性相关的程度;xt,yt为任意2 个特征指标的样本值;为对应特征指标的均值。
选取与温度相关系数大于0.7 的气体指标O2,CO,CO2,CH4,C2H4作为预测模型输入数据,煤温作为预测模型目标输出,将这些数据样本按照70%训练集、30%测试集进行划分。各指标间相关性系数见表1。
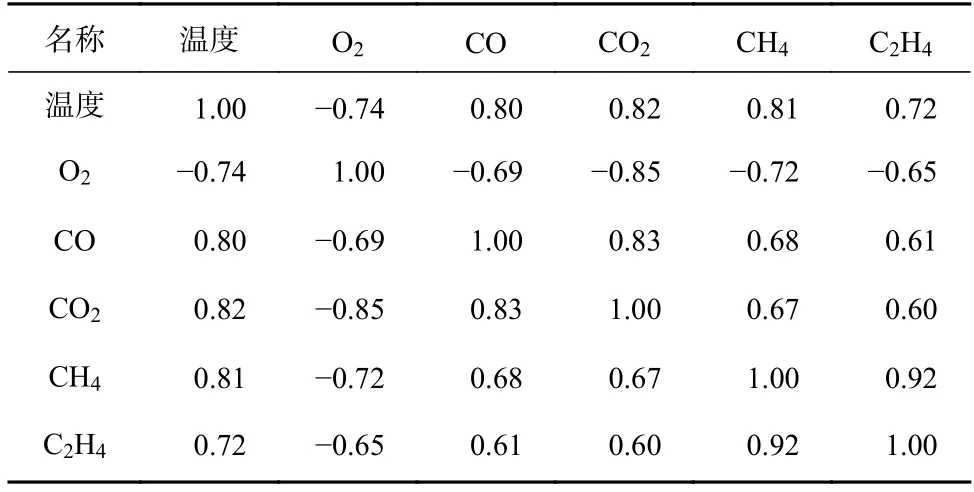
表1 温度与气体指标间的相关性Table 1 Correlation between temperature and gas indexes
3.2 评价指标计算
为了评估PSO-SRU 模型性能,对模型的预测结果作出统一客观的评价,选取平均绝对误差(Mean Absolute Error,MAE)、均方根误差(Root Mean Square Error,RMSE)、决定系数R2作为评价指标。
(1)MAE 计算公式为
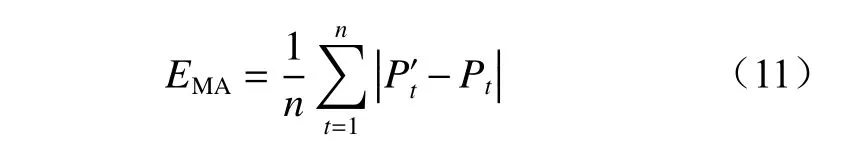
MAE 是预测值与真实值之间绝对误差的平均值,能避免误差相互抵消。MAE 越小,说明预测越精准。
(2)RMSE 计算公式为
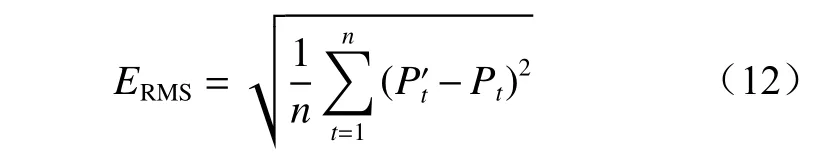
RMSE 能体现出预测值的离散程度,RMSE 越大,说明有较多或较大的偏差值出现,RMSE 越小,说明模型性能越好。
(3)R2计算公式为
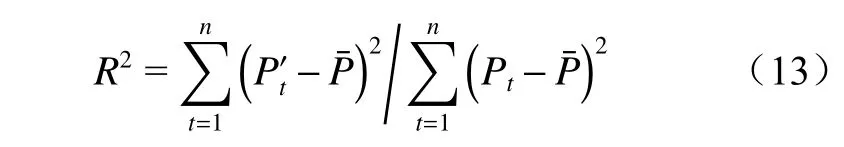
R2可以判别模型拟合非线性关系的程度,取值范围为[0,1],数值越接近1,表示模型预测性能越好。
3.3 实验结果分析
3.3.1 模型结构确定
为了选择合适的隐藏层数,本文利用改进的PSO 算法分别优化隐藏层的SRU 预测模型,改变不同隐藏层数模型的训练次数,进行MAE 和运行时间对比,结果如图5 所示。
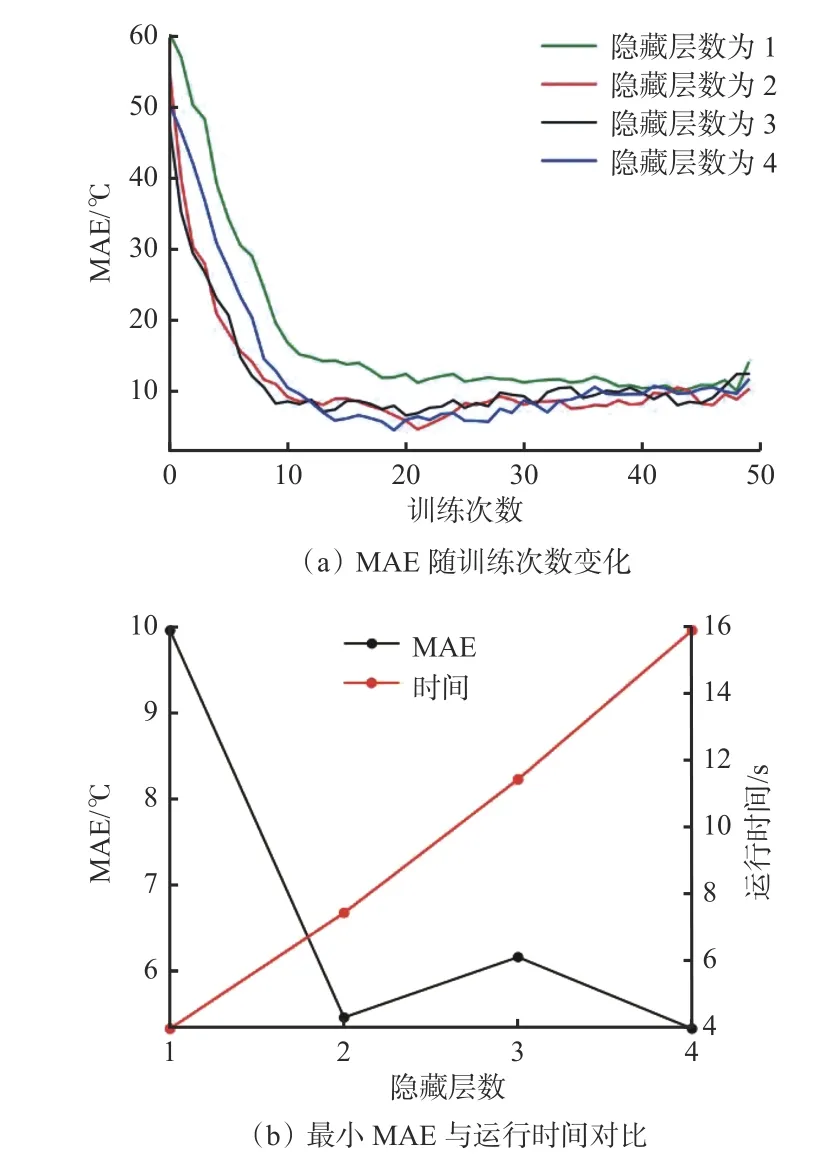
图5 不同隐藏层数SRU 预测模型MAE 与时间对比Fig.5 Comparison of mean absolute errors(MAE) and running time under various hidden layer of simple recurrent units(SRU) perdiction model
从图5 可看出,不同隐藏层SRU 预测模型的MAE 随训练次数增加逐渐减小,运行时间随隐藏层数增加几乎为线性增长。1 层隐藏层模型的最小MAE 始终大于2,3,4 层模型;3 层隐藏层模型的最小MAE 略高于2,4 层模型;4 层隐藏层模型的MAE 最小,虽然比2 层模型的MAE 略小,但运行时间是2 层模型的2.1 倍。因此,在综合考虑预测精度和时效性的前提下,本文采用含有2 层隐藏层的SRU 构建PSO-SRU 模型。
3.3.2 模型参数优化
SRU 预测模型由输入层、2 层隐藏层和1 层输出层构成。为了验证改进的PSO 算法性能,分别采用改进的PSO 算法和PSO 算法对含有2 层SRU 隐藏层的模型进行优化对比。寻优过程中二者的适应度变化曲线如图6 所示。从图6 可看出,改进的PSO 算法明显比PSO 算法可更快求得全局最优解,并最终求解到全局最小适应度,说明改进的PSO 算法全局寻优能力更强,算法收敛速度更快。基于改进的PSO 算法最终寻找到的最优SRU 预测模型参数如下:L1=18,L2=18,ɛ=0.001,e=21。
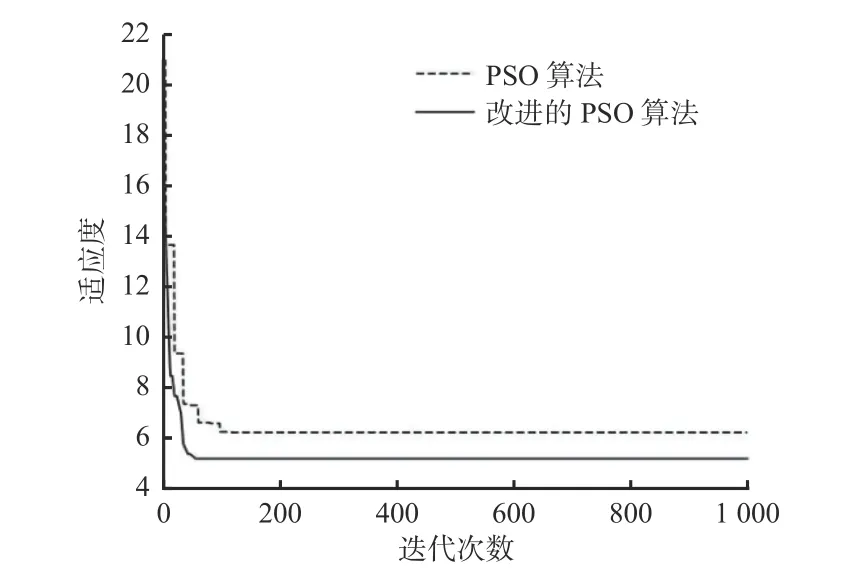
图6 PSO 算法改进前后适应度变化曲线Fig.6 Fitness value change curves before and after improving particle swarm optimization(PSO)algorithm
3.3.3 性能对比
为了验证PSO-SRU 模型的性能,在使用相同训练集和测试集数据前提下,利用改进的PSO 算法对各对比模型参数进行优化。基于SVR 算法的预测模型[16]惩罚因子为9.16,核参数为12.47;基于BP 算法的预测模型[18]2 层隐藏层神经元数分别为12 和8;基于RF 算法的预测模型[19]决策树数量为115,最大树深为5。采用MAE、RMSE 和R2指标对不同预测模型的性能进行评价,结果见表2。
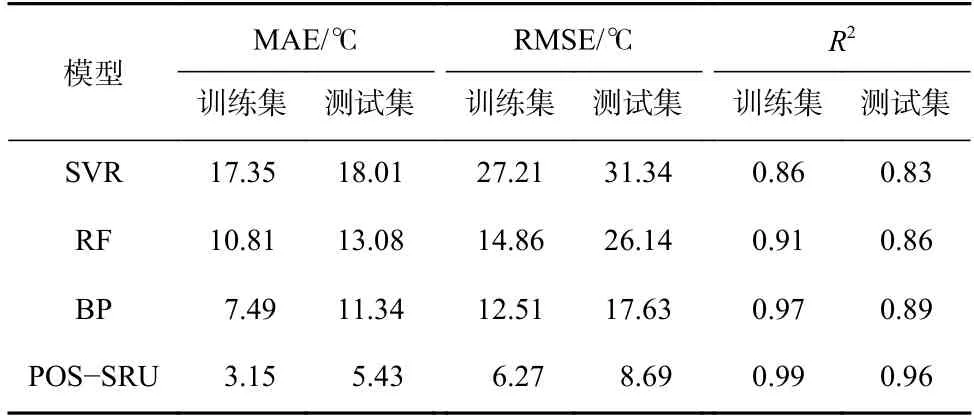
表2 不同预测模型的性能预测结果对比Table 2 Comparison of predictions using various models
由表2 分析可知,PSO-SRU 模型在测试集上的决定系数R2比基于SVR,RF 和BP 算法的预测模型分别提高了15.67%,11.63%和7.87%,且PSO-SRU模型的R2为0.96,说明其预测效果及性能最好,预测结果最接近真实值。在训练集和测试集上的预测结果表明:基于BP 算法的预测模型容易出现过拟合;基于SVR 和RF 算法的预测模型在训练样本和测试样本上预测误差差距较小、泛化性较好,但预测精度不足;PSO-SRU 模型在训练集和测试集上的R2差值为0.03,说明PSO-SRU 模型具有良好的泛化性。相较于基于SVR,RF 和BP 算法的预测模型,PSO-SRU模型在测试集上的MAE 分别降低了12.58,7.65,5.91 ℃,说明PSO-SRU 模型在测试样本上的预测精度优于其他3 个模型;同时,RMSE 分别降低了22.65,17.45,8.94 ℃,说明PSO-SRU模型预测的煤自燃温度离散化程度低,具有良好的鲁棒性。
不同模型测试样本真实煤温与预测煤温对比如图7 所示。

图7 不同模型测试样本真实煤温与预测煤温对比Fig.7 Comparison of real and predicted temperatures of testing samples using different models
从图7 可看出,基于SVR 算法的预测模型预测值偏离真实值程度最大,基于RF 算法的预测模型预测值离散化程度较大,模型鲁棒性较差,基于BP 算法的预测模型预测值曲线虽然比基于SVR,RF 算法的预测模型更贴近真实值,但预测精度仍然低于PSO-SRU 模型。PSO-SRU 模型预测的煤温曲线平滑,验证了其用于提高煤自燃温度预测精度、鲁棒性和泛化能力的有效性。
4 结论
(1)PSO-SRU 模型利用SRU 挖掘煤自燃温度与气体指标特征之间的非线性关系,根据历史监测数据预测出煤自燃温度,并利用改进的PSO 算法对模型参数进行优化。相较于标准PSO算法,改进的PSO 算法在优化SRU 煤自燃温度预测模型超参数的过程中,降低了预测模型选取参数的难度和模型结构复杂程度,提高了参数寻优效率。
(2)实验结果表明:与基于SVR,RF,BP 算法的煤自燃温度预测模型相比,PSO-SRU 模型在测试集上决定系数R2分别提高了15.67%,11.63%,7.87%,且R2为0.96,预测结果最接近真实值;MAE 分别降低了12.58,7.65,5.91 ℃,预测精度得到了提升;RMSE分别降低了22.65,17.45,8.94 ℃,预测曲线在拐点处更平滑,说明PSO-SRU 模型具有良好的鲁棒性。
猜你喜欢
计算机仿真(2022年8期)2022-09-28 09:53:02
数学物理学报(2022年4期)2022-08-22 04:07:12
数学物理学报(2022年2期)2022-04-26 14:08:04
测控技术(2018年10期)2018-11-25 09:35:54
金桥(2018年4期)2018-09-26 02:24:54
浙江工业大学学报(2017年5期)2018-01-22 02:03:46
中国塑料(2016年11期)2016-04-16 05:26:02
中国卫生(2014年5期)2014-11-10 02:11:26
物理与工程(2014年4期)2014-02-27 11:23:08
山西大同大学学报(自然科学版)(2014年3期)2014-01-23 01:56:42
