
基于集成学习的相似数据表推荐*
2022-05-10 07:28:24王成泽彭艳兵
计算机与数字工程 2022年4期
王成泽 汪 洋 彭艳兵
(1.武汉邮电科学研究院 武汉 430070)(2.南京烽火天地通信科技有限公司 南京 210019)
1 引言
日常工作中我们所处理的数据表数量众多,且数据表名及数据项标准并不统一,导致在寻找相似数据表时并不能简单的以表名去判别两张表的内容是否相似,这就对我们筛选出相似表造成了极大的困难。同时,相似表的筛选也是有意义的:一是对于相似的数据表我们可以合并,使数据表总量减少,并扩充已有的数据表内容;二是便于我们对于赘余的数据表进行废弃,提高工作效率;三是推荐出相似表的同时,进行表中相似字段的推荐,便于数据对标使用。因此,本文希望可以引入表识别、字段推荐等模型实现半自动化处理,为相似数据表识别及推荐提供一些帮助。
集成学习[1](Ensemble Learning)是一种优化算法,将多个学习器用某种策略结合起来,使得整体的泛化性能得到大大提升。其潜在思想是即便一个弱分类器得到了错误的结果,其他弱分类器也可将错误纠正。总体来说,集成的泛化能力是远好于单个学习器的泛化能力。
目前国内外关于集成学习算法的应用研究已有很多。扈晓君[2]等用基于选择性集成学习完成支持向量机的分类;刘擎超[3]等基于集成学习研究交通状态预报的方法;张有强[4]等基于选择性集成学习研究离群点的检测;乔桢[5]等对集成学习的多样性进行系统研究;林坚鑫[6]等基于AdaBoost算法对雷达剩余杂波抑制进行研究。
本文针对数据表的特点,将其类比成文本进行分析,提出了利用多种文本相似度算法进行集成学习,对数据表中的表名和字段项分别进行相似度计算,最终加权得出算法置信度并推荐出相似的数据表。基于互联网爬取的原始业务表与核心表数据进行试验,验证所提算法的有效性。
2 数据表推荐算法
2.1 数据表推荐算法思路
数据表分为表名和字段名,其重要程度也不尽相同,且都有中英文两种形式,所以相似度计算分为四个部分:中文表名,中文字段名,英文表名,英文字段名。
本文提供以下几种思路:可以训练表格领域的词向量,通过大量数据表数据的词向量训练,最终构建出一套较为完整的词向量词表,然后利用词向量之间的余弦距离计算相似性,这样可以包含文本中的语义信息,而不是仅仅考虑字符层面的相似;从神经网络的角度入手,可使用孪生神经网络衡量两个输入的相似度,以一对样本及标签作为输入输出来训练模型,通过表的上下文解析出语义信息;将表格数据映射成文本,且表格数据中的表名和字段项均为短文本,可以从短文本相似度的角度去进行表格之间的相似度比较。
整体步骤如图1所示。
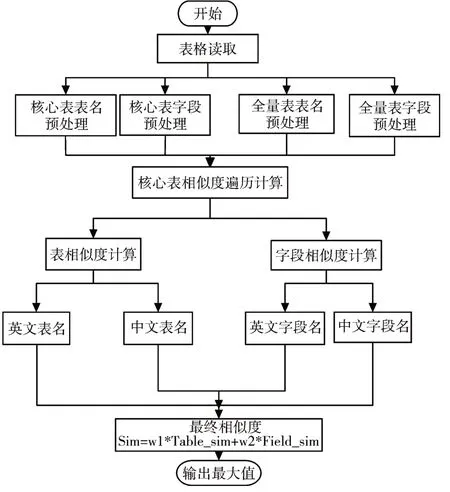
图1 数据表推荐流程图
2.2 相似度推荐算法
数据表同文本数据类似,每个表字段项可以看成是文本的一部分,但表不同于文本的地方在于其每个字段及表名的字符长度较短,属于短文本范畴。下面简要介绍本文所尝试的相似度算法[7~11]及选择标准。
文本相似度算法包括三类算法:一是基于关键词匹配的传统算法,如N-gram[12]相似度,Jaccard[13]系数,Simhash[14],Bm25等;二是将文本映射到向量空间,再利用余弦相似度等方法进行计算,如LDA[15],WMD[16]等;三是基于深度学习的方法进行训练,如孪生神经网络[17]等方法。
神经网络虽性能强大,算法效果显著,但是比传统算法计算代价高昂,通常神经网络模型参数极大,而且存在非线性操作,因此需要大量样本且保持样本的独立性。然而本文所用数据并不复杂且互相之间存在关联,样本的数据量也不符合神经网络的要求,难以得到良好的泛化性;利用词向量进行比较,可以融入语义信息,效果好于直接利用短文本相似度方法比较,但数据量层面来看,无法满足词向量的训练要求,所以在使用词向量训练时,在词表中加入了之前涉及的其他地市的数据表以达到扩充数据量的要求。最终主要采用基于关键词匹配的相关算法应用于实际的表识别场景,同时加入基于词向量的WMD(词搬移)方法进行词向量层面的尝试。
基于关键词匹配的算法较多,但侧重点却并不相同,jaro,jaro-winkler[18]以及edit distance(编辑距离)都是度量字符间距离的算法,jaro强调字符间的距离限制,而jaro-winkler则强调字符的公共前缀更为重要;simhash强调的是大规模数据的相似度比较,其核心思想是降维;Lcs(最大公共子序列)强调字符串中公共字符的个数;N-garm则强调字符的切分粒度。基于向量模型的LDA(文档主题生成模型)强调语义与主题层面的相似,假设每份文档都使用多个主题混合生成,同样每个主题也是由多个单词混合生成,即根据文档得到主题分布,再根据分布选出对应单词;WMD基于word2vec得到embedding向量,在此向量空间中,语义相似的词间的距离相对较小,通过欧式距离用距离来表示文档间的相似度,这与上文所说的度量字符间距离的算法不尽相同。
上文介绍了多种短文本相似度算法,对于实际情况来说,准确率也有所差异。本文相似度算法的选择主要基于两方面去考虑:一是算法应用于数据时的准确度;二是算法运行速度。所以对于不同算法分别应用于数据表表名和数据项字段进行这两方面的考量,选出较为理想的几种算法,再进行加权集成,达到更高的准确度。
2.3 相似度计算
本文从两个角度进行数据表的相似度计算,一是对表名的相似度计算,基于算法选择的标准,选出合适算法,加权集成,同时由于表名的特殊性以及防止过大数据量造成内存的损耗,人为规定两张数据表表名必须至少有一个相同文字才进行相似度的比较,通过一次筛选,减少比较的数据量;二是对表字段项进行计算,对于两张表的字段项分别进行遍历计算,找出两张表中最相似的字段对应,并推荐出最为相似的两张表。
算法的侧重点不同,置信度并不统一,首先需要进行归一化,再进行算法的调参。算法归一化采取的Z-score标准化,使结果落到[0,1]区间,公式如下:

其中μ为样本数据中算法置信度的均值,σ为其方差。
得到表名相似度和字段项相似度之后,加权后的数据表相似度计算公式如下:
其中Table_sim为表名的相似度算法置信度,Field_sim为表字短信的算法置信度,w1,w2分别为其权重。
3 实验验证
3.1 实验数据集和实验环境
本文验证数据来自互联网爬取的地市对标采集的全量表数据和根据标准制定的业务核心表。该数据包含中英文表名、中英文表字段名、相似字段对照等信息。通过采集并筛选出对标结果为核心表的全量表数据作为本次实验的数据集。本文算法采用的是语言Python 3.6,在Windos系统下运行,计算机CPU为Intel Core i5-7500@3.4GHz,内存大小为8G。
3.2 实验过程
3.2.1 数据预处理
本文数据选取的是互联网爬取的各地市对标采集的共1600张业务数据全量表,以及150张业务应用广泛的核心表,其中446张原始全量表经专家进行筛选后可对应在业务上应用广泛的核心表;409张原始数据表有中英文表名,37张原始数据表仅有英文表名。
原始数据表的表名和字段名是包含通用字段的,例如旅馆信息记录表,我们所关注的是旅馆,而信息记录表这些字段对判断相似没有帮助,在进行表名的推荐时应去掉这些通用字段,通过我们对1600张原始数据表及核心表的人工预研,去掉字段如表1所示。
同时,对于数据表中的字段项我们也需要进行预处理,去掉其中无意义的字段,以提高之后算法推荐的准确度。同时由于字段项不同于数据表的表名,每张数据表的字段项较多,其形式也会更加多样,还可能会出现一些符号,例如人员_数量,类似这种带有特殊符号的字段项,预处理时需要考虑全面,首先去掉特殊符号,再进行通用字段的删除。预研之后去掉的数据表通用字段项如表2所示。

表2 数据项通用字段删除
这些字段与数据表的主体内容并不相关,可能会导致推荐时的偏差,这里我们的选取原则是对1600张数据表中的字段进行统计,选取出现次数Top20的字段进行人工判研,最后筛选出15个频次出现较高的通用字段项进行删除,以提高相似表的推荐精度。
3.2.2 确定最优参数与算法
上述介绍的算法各自侧重点不同,本文在选择合适算法时,先分别对数据表名和字段项相似度采用上述算法,对比专家预设结果,选出准确率较高且运行时间相对较短的算法作为集成学习的单个学习器。各算法在表名相似的准确率如表3、表4所示。
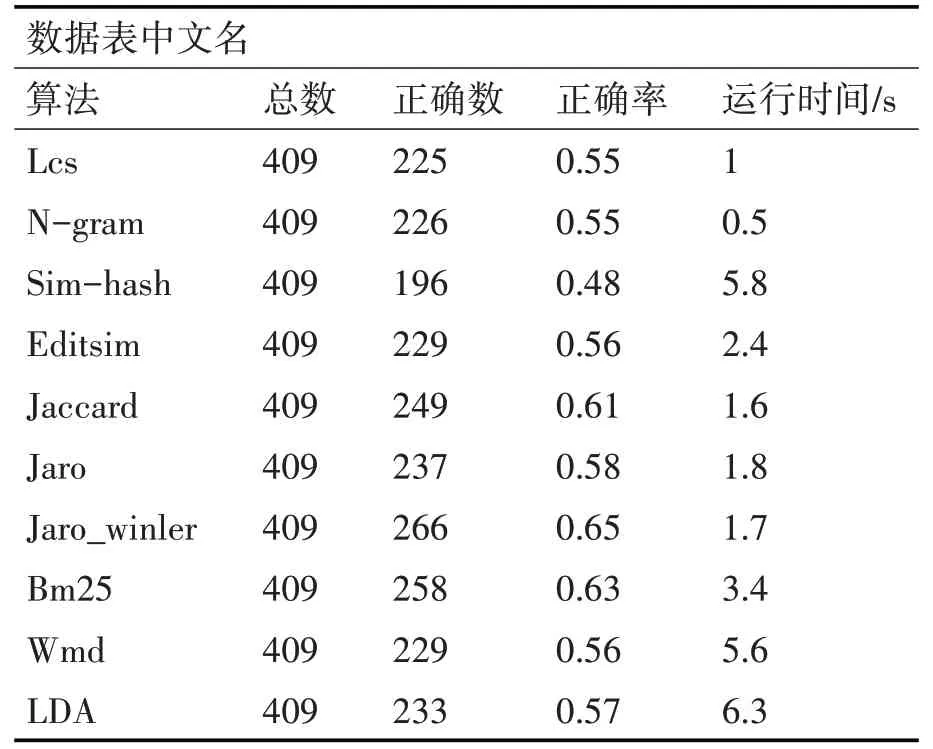
表3 数据表中文表名算法准确率
英文表名的比较效果准确度相对较低,原因在于各地市对标数据与核心表所提供的英文表名方式不一致。各地市的英文表名存在多种情况,如对应的中文表名首字母,拼音与英文混搭,甚至存在多张表英文名相同,仅通过编号区分的情况,而核心表统一为英文简写,所以算法的结果准确性偏低,本文不再考虑此维度。
算法在数据表字段项相似方面准确率如表4所示。
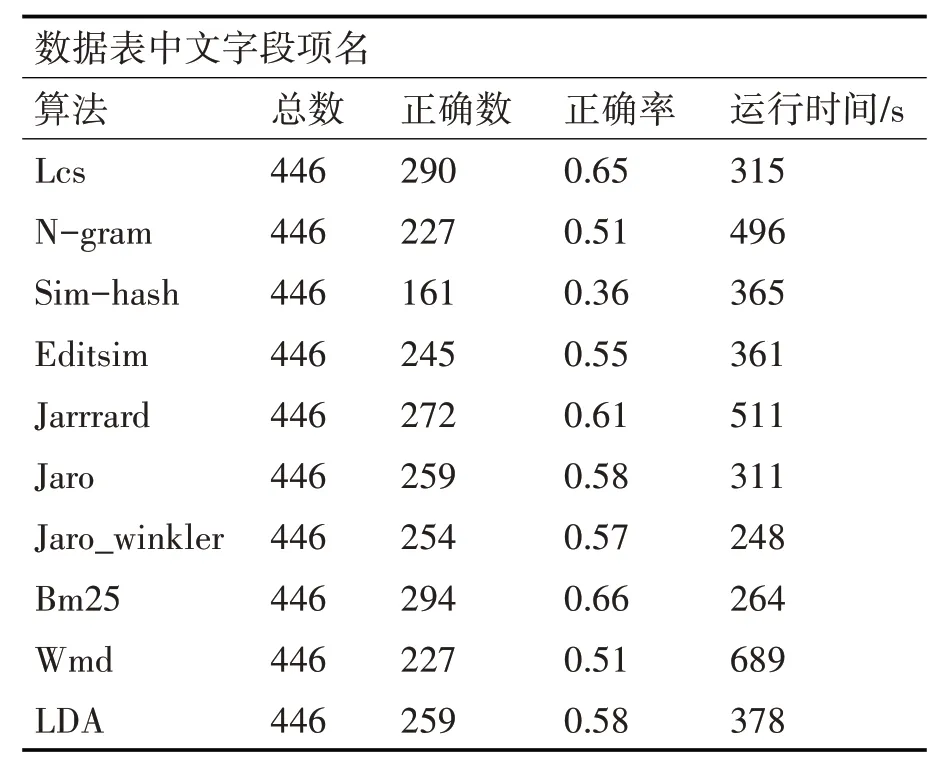
表4 数据表中文字段项名算法准确率
在英文字段项上的对比与表名类似,由于各字段英文表达方式的不同,表示同一字段的英文相去甚远,导致算法的准确率并不理想,因此本文不对此方面进行过多考虑。
单个算法的数据表推荐效果一般,所以本文对于中文表名和字段项均采用效果较好的三个算法进行集成学习,若选择算法过多反而会导致计算量庞大且效果并不明显。参数优化采取了随机搜索优化参数,即通过固定次数的迭代,采用随机采样分布的方式搜索合适的参数。其为每个参数定义了分布函数,并在该空间中进行采样,本文次数设置为500,经500次迭代后,最终各算法的权重如表5所示。
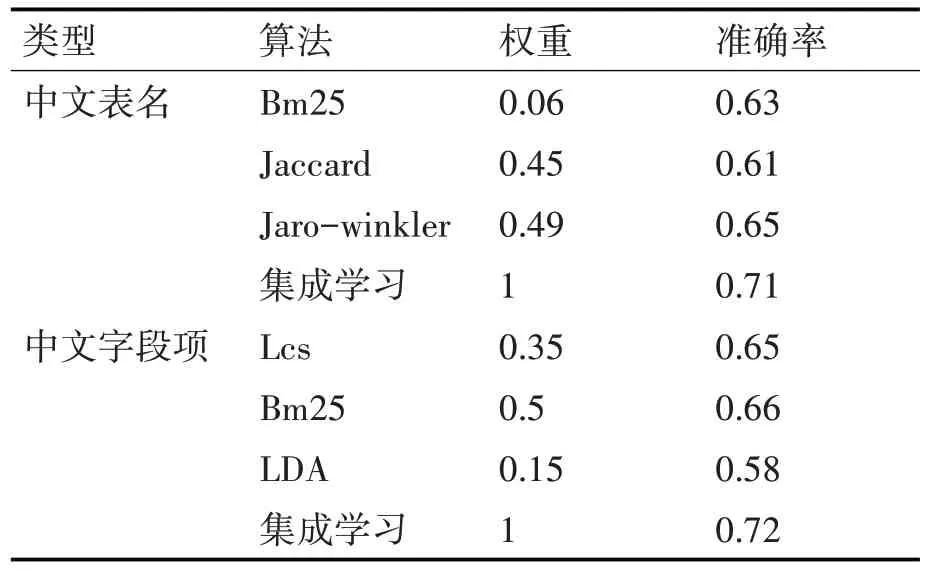
表5 各算法权重分布
3.3 实验结果分析
中文表名和字段项分别经过集成学习后准确率均提高了6%左右,中文表名比较时总数为409张,因为提供的数据中有部分没有中文表名,为了除去此影响,不将其纳入中文表名的比较中。分别计算完表名和字段名的相似度,最后将两个部分调参后的结果加权求和得到最终的表识别相似度,经过随机采样分布多次调试后,表识别准确率结果如表6所示。
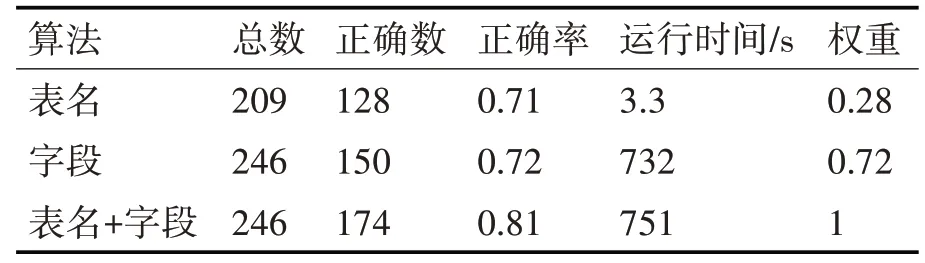
表6 集成学习算法权重分布
表名和字段名的权重设为0.28和0.72,其中对于无中文表名的数据表,仅利用字段进行判别。加权求和后,准确率上升了10%。
同时考虑到在进行数据表字段项识别时,我们已经通过相似度算法简介推荐了核心表每个字段的最相似字段,按照此思路,优化表识别的功能,请相关人员标注了部分核心表中字段项的核心字段,通过核心字段,可以推荐出全量表与其相似的字段,便于我们分析该张全量表是否是业务需要的。
4 结语
本文提出了一种基于集成学习的相似数据表推荐算法。以采集的地市对标数据作为实验数据来源,运用集成学习将多种短文本分类算法运用到相似度比较中,从表名和字段项两方面对不同方法实验后,选择准确度较高且运行时间较短的方式,选取合适的权重,最终得到推荐的相似结果。对比有经验的专家人工给定的对标结果,算法成功率达到81%。实际上,在相似度比较过程中,会遇到英文字段的表达方式不统一,数据表中部分字段缺失以及没有中文表名等问题,给本文算法的判断带来了困难。
猜你喜欢
江苏科技信息(2022年16期)2022-07-17 09:07:36
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
党员生活(2020年2期)2020-04-17 09:56:30
铁道通信信号(2018年10期)2018-12-06 09:34:56
中国交通信息化(2018年5期)2018-08-21 03:37:40
图书馆建设(2015年10期)2015-02-13 03:48:27
中国石油企业(2014年4期)2014-11-30 06:13:06
新世纪图书馆(2014年7期)2014-09-19 12:20:40
