
基于BERT-BILSTM的医疗文本关系提取方法
2022-05-09 13:53龚汝鑫余肖生
计算机技术与发展 2022年4期
龚汝鑫,余肖生
(三峡大学 计算机与信息学院,湖北 宜昌 443002)
0 引 言
健康医疗大数据是国家重要的基础性战略资源,其应用发展将带来健康医疗模式的深刻变化,有利于提升健康医疗服务效率和质量[1]。其中,健康医疗文本数据是健康医疗大数据的重要组成部分之一,多为包含患者病史、现状、诊断、检查、治疗信息的非结构化长文本,并且上下文结构联系紧密、内容专业性强,容易出现医疗信息抽取难度大、利用率低的情况[2]。
2010年之前多采用机器学习方法来处理文本中的信息,但时间成本投入大,且未利用语言之间的相关性,无法充分学习、利用所包含的信息[3-4]。而后利用神经网络紧密联系上下文的特点,让CNN、RNN及变体LSTM、GRU在文本提取和分类研究中取得不错表现[5-7]。为减少重要信息的流失,张志昌等人将BIGRU与注意力机制相结合,重点处理影响力较强的文本信息[8-9]。
现有的关系提取方法没有针对性地考虑如何获取和充分利用医疗领域文本包含的信息,该文提出一种BERT和双向长短期记忆神经网络(bidirectional long short-term memory,BILSTM)融合的关系提取方法,来获取健康医疗文本中实体间隐含的价值信息。在预处理阶段,针对医疗词语进行关键词提取,减小医疗实体提取难度;再使用BERT模型进行词嵌入,将词向量、位置向量、句子级特征输入到BILSTM中进行处理,最后结合注意力机制来优化特征向量,从而充分理解和利用文本中的重要信息,提高准确率。
1 相关工作
关系提取的实质是关系分类,即确定两实体间的关系类别。2010年之前多采用人工标注特征结合浅层分类模型来进行分类,Kambhatla等人采用模式匹配方法,利用基于文本特征的统计模型进行关系提取,取得一定成果[3]。2010年之后,文本分类方法逐渐向深层模型过渡,Liu等人使用CNN模型处理特征时,结合实体语义信息,将多个同义词使用同一向量作为模型输入值[4,10]。Mikolov等人利用RNN将词语与上下文信息联系起来,实验结果表明,RNN模型比CNN模型更适合用于文本分类研究[11]。LSTM-RNN[12]、LSTM-CNN[13]、LSTM-GRU[14-15]等混合神经网络模型在关系提取、情感分类等任务中的准确率进一步提高。在单向神经网络结构取得一定成果后,研究目光转向BILSTM和BIGRU,关举鹏等人使用BILSTM模型提取文本特征,减少了人工制定特征带来的麻烦,还进一步提升了关系抽取效果[7]。双向循环神经网络可充分学习词语和上下文语义信息,为减少噪声带来的影响,可集成其他研究方法,发扬和弥补各自优缺点。
2015年Bahdanau等人使用注意力机制进行机器翻译,让注意力机制在自然语言处理领域得到认可[16]。朱星嘉等人将注意力机制与LSTM相结合,重点处理对于关系分类影响力强的词语,减少重要信息的流失[17-20]。为进一步完善模型架构,在预训练阶段进行优化,Shi等人使用BERT模型进行词嵌入,缓解了Word2Vec语言模型存在的一词多义问题,还加入位置向量、句子特征向量拼接成新向量作为模型输入,丰富了语义表征[21-24]。
健康医疗文本有内容上下文联系紧密、名词专业化等特点,相较于情感分析、人物关系等文本,更加难以处理。Ozlem等人在医疗文本中定义了6大常见医疗实体关系,通过确定实体间关系类别来获取隐含信息[25]。Frunza等人使用朴素贝叶斯和SVM模型对疾病治疗、预防、副作用三者之间的语义关系进行分类,结合生物医学文献和临床医疗知识,得到了更加准确的结果[26]。Sahu等人首次使用CNN结合多种向量表征方式进行中医医学关系提取,减小了对专家定义特征质量的依赖[5]。Zhang等人利用CNN和RNN优势,构成CNN-RNN模型对生物医学文本中实体进行关系分类[6]。Chikka等人使用BILSTM模型来提取治疗和医疗问题之间的关系,结合基于规则的方法,可对小样本数据进行关系分类[27]。张志昌等人使用BIGRU模型结合注意力机制,增强特征识别的性能,减少误差带来的影响[8-9]。武小平等人将把BERT作为语言训练模型,相较于常见语言模型,新加入位置向量、句子特征向量,来丰富词性[28]。在文本处理领域,可采用神经网络模型作为基础架构,与注意力机制相结合,充分学习、利用文本信息,但准确率还有提升空间。
2 基于BERT与BILSTM融合的关系提取方法
在医疗领域,存在大量非结构化文本数据,采用CNN、RNN进行处理,会出现文本利用率低,重要信息大量流失的情况。因此,提出了一种基于BERT和BILSTM-ATT融合的关系提取模型(如图1所示),来充分学习和利用健康医疗文本中的重要信息。利用BERT语言模型生成词向量嵌入到BILSTM层,不仅能让词语紧密联系上下文,还能缓解中文词语存在的一词多义问题;在BILSTM层,获取正反两方向的隐含特征,让词语紧密联系上下文;再结合注意力机制考虑输入文本中部分词语重要性,合理分配权重;最后使用Softmax分类器得到关系概率。
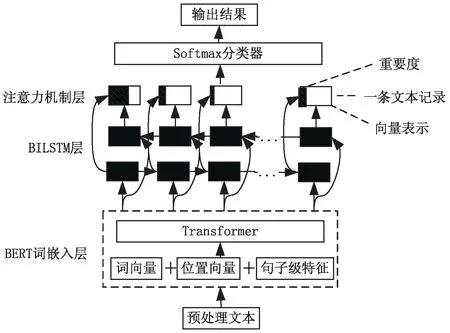
图1 基于BERT与BILSTM融合的 关系提取模型架构
2.1 BERT词嵌入层
基于已有的Word2Vec、GPT等语言模型,2018年Google团队提出BERT语言模型,由多层Transformer语言架构组合而成,凭借庞大语料库和超强算力,在文本处理任务中取得优异表现[29]。BERT模型嵌入值由词向量、位置向量和句子特征向量组成,能保证文本中词语正确排序,并获得句子级表征能力,从而丰富向量表征信息,有利于后续任务的进行[16]。健康医疗文本的上下文联系较为紧密,实体需要结合上下文进行处理才能获取精确的信息,且中文词语可在不同句子中表示不同意思,存在一词多义的情况,使用BERT模型代替常用的Word2Vec模型进行词嵌入,能很好地缓解这些问题。
该文采用的是BERT中文预训练模型(BERTBASE),Transformer层数为12,隐藏层维度为768,多头注意力机制个数为12,总参数为110 M。以句子“患者出现胸闷、气短,诊断为高血压,口服速效救心丸后缓解”为例,展示BERT模型处理后的文本向量。
2.2 BILSTM层
1997年Hochreiter提出RNN变体─LSTM,由门控记忆单元组成,包括输入门、遗忘门、输出门。计算过程见式(1)~式(6):
ft=σ(Wfht-1+Ufxt+bf)
(1)
it=σ(Wiht-1+Uixt+bi)
(2)
at=tanh(Waht-1+Uaxt+ba)
(3)
ct=ct-1·ft+it·at
(4)
ot=σ(Woht-1+Uoxt+bo)
(5)
ht=ot·tanh(ct)
(6)
其中,ht-1表示上一单元的隐藏状态,xt表示本单元输入信息,ft表示对上一单元隐藏状态的遗忘概率,决定保留多少过去状态信息;ht-1和xt使用不同激活函数构成本单元输入值,由上一单元部分记忆和本单元输入值共同组成本单元记忆ct,ct和之前未处理的隐藏状态信息ot共同构成本单元隐藏状态信息ht,决定向后传递多少信息。利用LSTM的链式结构选择记忆信息,缓解了RNN存在的长距离依赖问题,避免信息快速流失[30]。
BILSTM由正向和反向LSTM组成,同时从两个方向开始训练,能有效获取过去和未来信息,从而缓解了单向LSTM只能序列化处理文本的情况。BILSTM模型处理过程如图2所示,以句子“患者出现胸闷、气短,诊断为高血压,口服速效救心丸后缓解”为例,获取LSTM处理后的向量;{hi1,hi2,hi3,hi4,hi5,hi6,hi7,hi8,hi9}和{hj1,hj2,hj3,hj4,hj5,hj6,hj7,hj8,hj9}分别代表“患者”“出现”“胸闷”“气短”“诊断”“高血压”“口服”“速效救心丸”“缓解”在正向LSTM和反向LSTM中的向量,对正向和反向的隐藏向量进行叠加,得到向量{h1,h2,h3,h4,h5,h6,h7,h8,h9},从而做到基于上下文进行处理,使BILSTM中每个字词包含整句的信息。由于健康医疗文本数据存在多模态、碎片化、记录时间不规律等特点,仅使用LSTM模型效果有限,故与其他方法结合进行集成分析,扩展其在医疗领域应用范围。
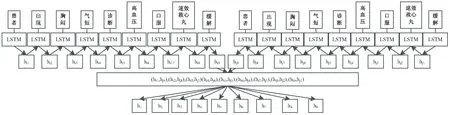
图2 BILSTM模型示例图
2.3 注意力机制层
在健康医疗文本中,每个词语对于实验目的的贡献不相上下,若统一分配权重,会遗漏部分重要信息,降低准确率,故结合注意力机制对权重进行调整,快速筛选并重点处理高价值信息。计算过程见式(7)~式(9):
ut=tanh(Wuht+bu)
(7)
(8)
(9)
其中,ut为随机初始化矩阵,以键值对的形式计算当前词语与句子中其他词语的相似度,得到占比权重at,权重at和BILSTM层输出向量ht乘积的累加和得到新的表示向量st[16]。
注意力机制模型见图3,以句子“患者出现胸闷、气短,诊断为高血压,口服速效救心丸后缓解”为例,根据BILSTM层输出向量{h1,h2,h3,h4,h5,h6,h7,h8,h9},得到对应权重{a1,a2,a3,a4,a5,a6,a7,a8,a9},乘积累加得到新的隐藏状态向量st,最后使用Softmax函数进行分类,得到预测标签。
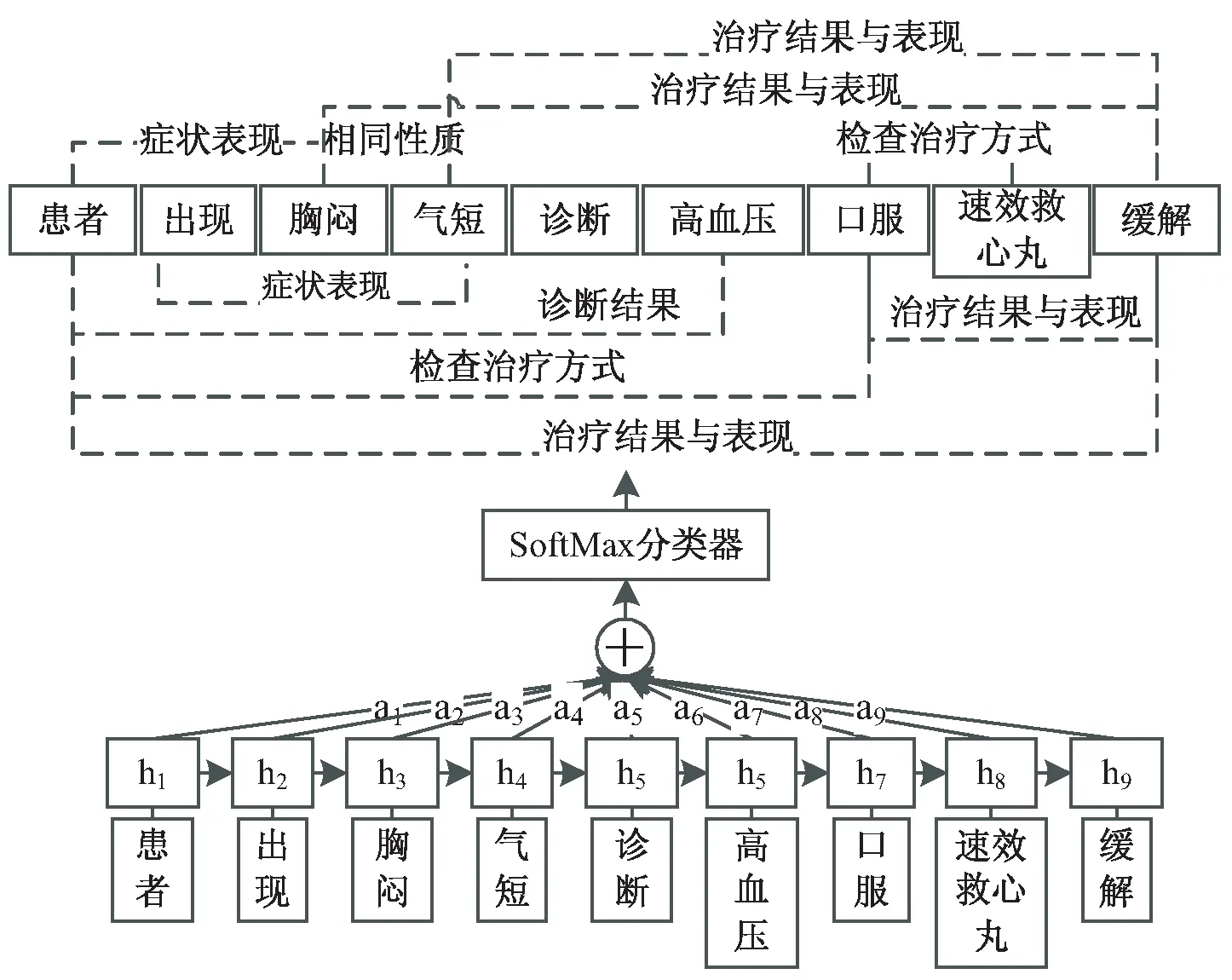
图3 注意力机制模型示例图
2.4 模型训练方法
BERT-BILSTM-ATT模型以健康医疗文本数据集、实验参数作为输入,利用BERT模型把文本处理成向量形式,再使用BILSTM结合注意力机制获取关系类别,算法如下:
输入:健康医疗文本数据集、实验参数;
输出:健康医疗文本中实体间关系类别。
Step1:使用BERT模型进行词嵌入,词语对应向量为xt。
Step2:使用BILSTM和注意力机制对数据集中每条健康医疗文本记录进行处理,其中文本中单词数量为n。
for hop=1 ton:
ut=tanh(Wuht+bu)
end for
Step3:根据最终的表示向量st,使用Softmax函数计算各关系概率,确定关系类别。
3 实验与结果分析
3.1 实验数据与预处理
健康医疗文本除了包含医学专业词语外,还包含大量常用词语。若未提前对健康医疗文本中词语进行筛选,直接使用jieba工具提取关键词,会出现关键词中常用词语较多、医疗相关词语较少的情况,妨碍获取文本中医疗实体。为减少高频无意义词语(如:的、不能、月末等)对医疗信息获取的影响,在预处理阶段先过滤掉部分无意义词语,再进行医疗关键词提取,降低医疗信息获取的困难程度,使模型重点针对医疗相关实体进行处理。
3.1.1 实验数据
通过查阅国内公开电子健康病历、咨询专家后,将医疗相关实体分为12类(例如:身体部位、疾病名称、药品名称等),实体间关系分为10类(例如:检查治疗方式、诊断结果等),具体内容如图4所示。
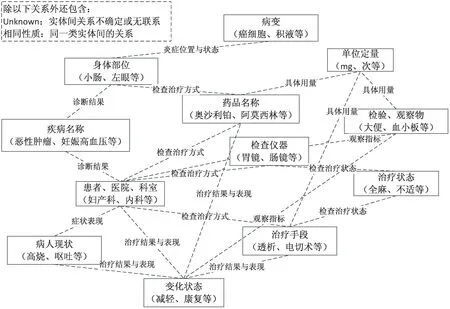
图4 医疗实体关系表
选取2个健康医疗文本数据集进行实验研究。Yidu-S4K数据集:由“医渡云”医学数据智能平台根据真实病历的分布情况人工编辑而成,共包含8 000条数据,80%为肿瘤疾病文本,每条记录包含现状、诊断内容、治疗项目、恢复情况等;本地数据集:由2017-2018年间某市疾控中心的高血压患者数据组成,数据集已经过脱敏处理,包含记录5 830条,每条记录包含患者现状、诊断内容、治疗项目等。
3.1.2 对健康医疗文本的预处理过程
将寻医问药网(https://www.xywy.com/)词库作为文中的疾病词库,其中词库包含疾病、检查方式、科室、症状、治疗项目、身体部位等12类实体,共计19 832条数据,用于判断是否为医疗相关实体,有利于提取医疗关键词。
健康医疗文本处理步骤如图5所示,输入健康医疗文本,去除无用符号(如逗号、引号等),保留句号、分号作为句子隔断,再使用jieba工具进行分词处理。为减少无意义词语(如:年前、出现、不会等)对医疗领域文本处理的影响,以疾病词库为基础过滤掉部分词语,即存在于疾病词库则判断为关键词并保存,否则删除;使用jieba工具统计排名靠前的关键词作为研究实体,专家对实体间关系类别进行标注,最后将处理后的数据输入到文中模型中。

图5 健康医疗文本预处理步骤
3.2 实验参数及评价指标
实验使用精确率(precision)、召回率(recall)、F1值(f1-score)3个标准作为评价指标,它们的计算公式如下:
(10)
(11)
(12)
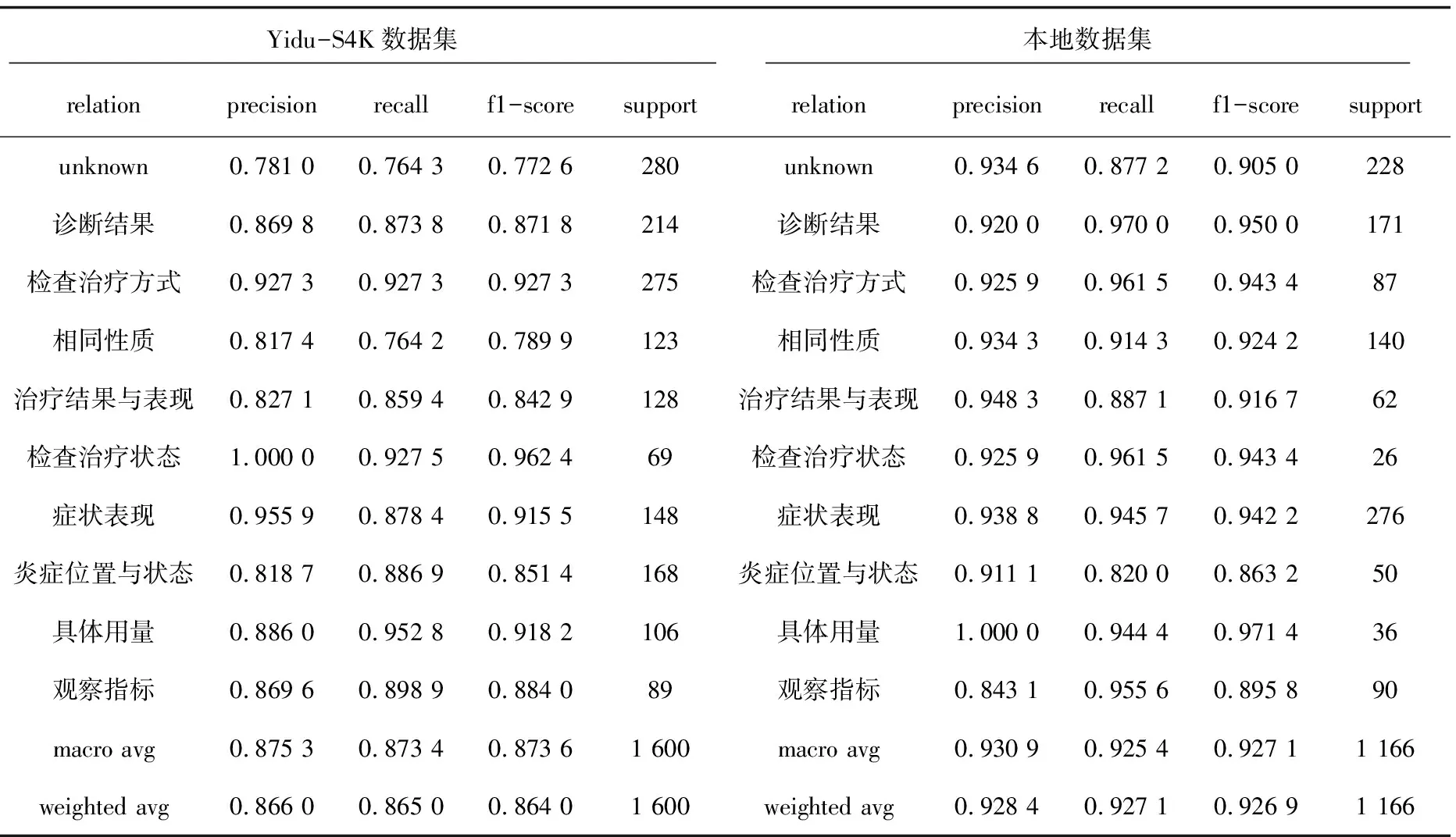
表1 数据集实验结果
3.3 实验结果分析
对BERT-BILSTM-ATT模型进行迭代,得到各类别实验结果和总体平均值,见表1。由于LSTM模型参数量大,存在过拟合的风险,联合观察精确率和损失值动态变化来判断模型拟合状态,并做出参数调整;如图6,迭代过程无异常波动,模型良好拟合。
各模型训练得到的结果如表2所示,其中BERT-BILSTM-ATT模型效果最佳。对比未提取关键词的BERT-BILSTM-ATT模型,BERT-BILSTM-ATT模型精确率提升12.18%~12.85%,证明突出医疗词语有助于进行后续健康医疗文本关系提取实验。对比Word2Vec-BILSTM-ATT模型,BERT-BI LSTM-ATT模型精确率提升3.36%~3.76%,证明在词嵌入过程中,BERT语言模型优于Word2Vec语言模型。与CNN模型、BILSTM-CNN模型进行对比,精确率大幅度提升,说明本模型效果优于其他CNN、RNN神经网络模型,能充分学习、利用健康医疗文本包含的信息,提高准确率;与BERT-LSTM-ATT模型进行对比,精确率提高3.35%~4.8%,说明双向LSTM模型结构优于单向结构,可获取更加准确的语义信息;与BERT-BIGRU-ATT模型对比,精确率提高4.07%~4.45%,说明虽然LSTM结构比GRU结构复杂,但灵活性强,更加适合提取内容复杂的文本信息。总体来看,本模型对健康医疗文本关系提取效果较优。
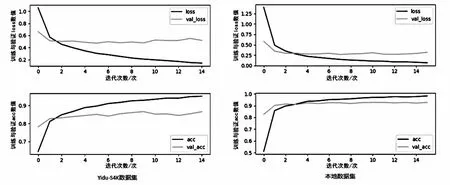
图6 loss和acc变化过程 表2 各类模型实验结果
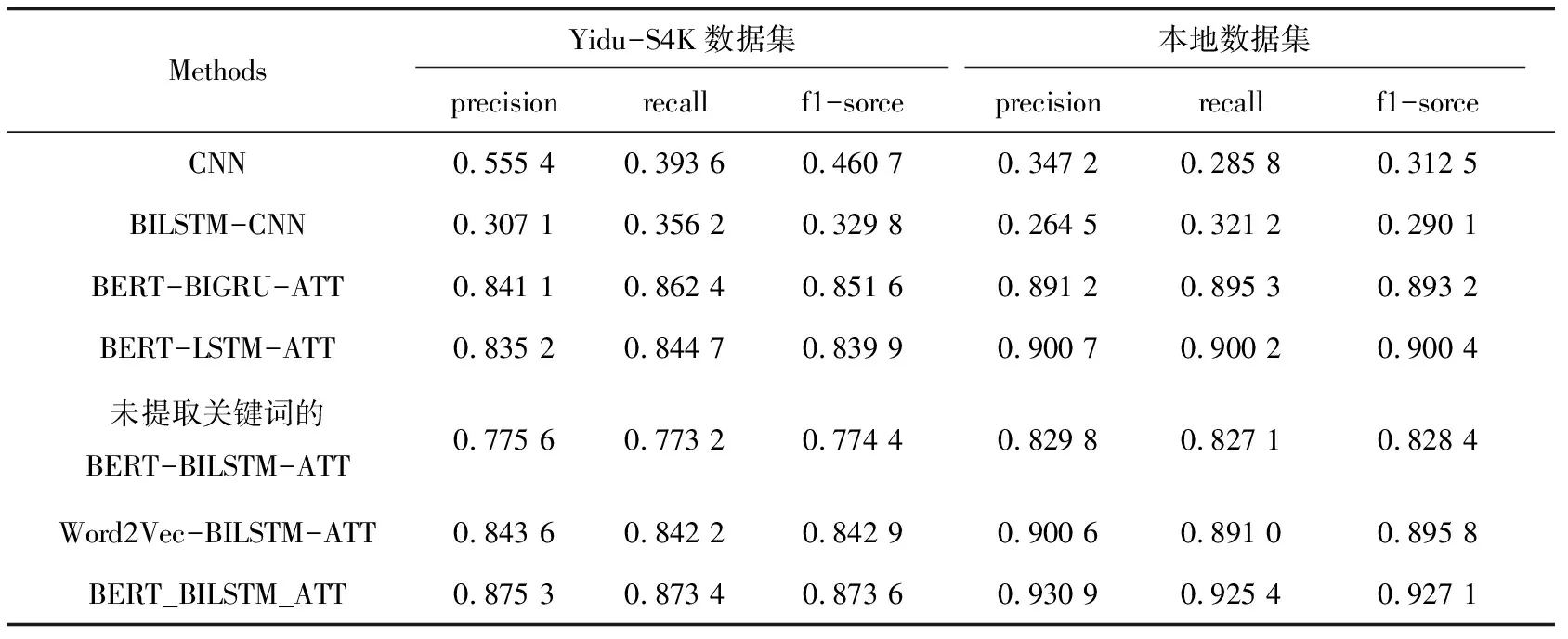
Methods Yidu-S4K数据集 本地数据集 precisionrecallf1-sorceprecisionrecallf1-sorceCNN0.555 40.393 60.460 70.347 20.285 80.312 5BILSTM-CNN0.307 10.356 20.329 80.264 50.321 20.290 1BERT-BIGRU-ATT0.841 10.862 40.851 60.891 20.895 30.893 2BERT-LSTM-ATT0.835 20.844 70.839 90.900 70.900 20.900 4未提取关键词的BERT-BILSTM-ATT0.775 60.773 20.774 40.829 80.827 10.828 4Word2Vec-BILSTM-ATT0.843 60.842 20.842 90.900 60.891 00.895 8BERT_BILSTM_ATT0.875 30.873 40.873 60.930 90.925 40.927 1
4 结束语
针对健康医疗文本处理面临着利用不充分、信息获取难度大、准确率较低等问题,提出一种基于BERT和BILSTM融合的健康医疗文本关系提取方法,来对此类问题进行处理。与单向LSTM、CNN、BIGRU等模型进行对比,该模型分类性能表现最好,精确率提高3.35%以上,验证了基于BERT和BILSTM的融合模型能很好地获取实体间关系,满足医疗领域实际应用需要。但还存在一些问题,需进一步思考,如:不同病种数据对于健康医疗文本关系提取模型的影响;在健康医疗文本预处理阶段需专家进行标注,存在部分主观因素。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
计算机系统应用(2021年11期)2022-01-06
当代陕西(2019年5期)2019-03-21
21世纪商业评论(2018年3期)2018-03-02
第二课堂(课外活动版)(2016年2期)2016-10-21
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
现代出版(2014年6期)2014-03-20
中学英语之友·高一版(2008年10期)2008-12-11
