
多任务学习在中国方言分类中的应用研究
2022-05-09 13:53万苗,任杰*,马苗,曹瑞
计算机技术与发展 2022年4期
万 苗,任 杰*,马 苗,曹 瑞
(1.陕西师范大学 计算机科学学院,陕西 西安 710119;2.西北大学 信息科学与技术学院,陕西 西安 710127)
0 引 言
语音识别是人机交互的重要组成部分,现如今,基于深度神经学习的语音识别系统日趋成熟,并在导航、翻译、智能家居、车载系统、教学等诸多领域得到广泛应用[1]。但目前由于用户输入语音可能存在口音、方言等特征,导致智能语音系统常常出现无法准确识别的问题[2],进而需要用户矫正口音、重复输入语音指令,严重影响用户使用体验。由此,预先自动判定输入音频语种是提升语音识别系统后端效能的关键步骤。
此外中国历史悠久,地域跨度大,民族繁多,方言种类多样且差异性较大,由于普通话的推广及普及,方言使用频率日趋减少。由此,中共中央办公厅、国务院办公厅印发《关于实施中华优秀传统文化传承发展工程的意见》,提出要“大力推广和规范使用国家通用语言文字,保护传承方言文化”,各地政府也积极建立方言语料库及方言博物馆。进一步,对方言的准确识别及翻译可以有效提升方言使用范围及频率,对方言文化的保护至关重要。
具体的说,方言语种识别是对输入音频源数据的语种种属进行分析判定,进一步根据语种分类结果将音频数据输入到对应的自然语言处理模型进行推理。该文针对方言语种分类进行研究,基于深度学习模型构建方言语种分类模型,面向西北、华北、西南、华中地区的十地方言进行语种分类实验验证。具体来说,主要贡献如下:
(1)抽取MFCC特征,构建基于MFCC的LSTM单任务深度学习模型,进一步,考虑到同一地理区域内不同方言语种间的相似性及不同区域方言语种的相关性,首次基于MFCC特征,以方言区域为辅助任务,构建基于参数硬共享方言语种识别模型;
(2)发现基于参数硬共享的模型仅在任务相关性强时具有良好性能,而方言分类任务的相关性不能被明确界定。由此,首次提出基于参数稀疏共享的多任务方言分类模型,该模型通过联合训练,自主确定任务间的相关性,并对子任务部分网络进行自适应共享。
1 相关研究
1.1 语音语种识别
语音语种识别是模式识别的一个重要分支。其首要任务是从输入声音中提取特征作为多维向量。特征提取是通过将语音波形以相对最小的数据速率转换为参数表示形式进行后续处理和分析来实现。梅尔频率倒谱系数(MFCC)[3]、线性预测倒谱系数(linear prediction cepstral coefficients,LPCC)[4]、离散小波变换(discrete wavelet transformation,DWT)[5]和感知线性预测(perceptual linear predictive,PLP)[6]是常见的语音特征参数。这些方法已经在广泛的应用中进行了测试,具有很高的可靠性和可接受性。方言研究通常将语音预处理为上述特征参数。
语音语种识别其主流起先是人工神经网络,继而高斯混合模型、HMM、MVC等模型也被广泛应用。随后发展到基于神经网络的应用。2011年Ge等人提出基于情景依赖的预训练DNN方法[7],蒋兵在2015年提出基于深层神经网络提取音素相关深瓶颈特征(deep bottleneck feature,DBF)的语种识别方法[8]。CNN在语音识别领域有广泛的应用,Koller等提出了混合CNN-HMM模型,关注到语音输入的连续性[9]。2017年,微软在新的对话语音识别系统中加入了CNN-BLSTM声学模型。这些均取得了不错的成果。近几年,循环神经网络(recurrent neural network,RNN)也广泛应用到了语音识别领域[10]。LSTM和GRU网络也被相继提出,由于其改善了RNN所存在的长期依赖问题,对序列化的语音特征的识别有良好性能。如使用CNN与GRU融合深度神经网络对语音语种进行分类。相关研究还在此基础上对原有LSTM及GRU模型进行改进,以达到性能优化的目的[11]。
近年来,方言识别多采用端到端的识别模型,通常使用卷积层和循环层结合的网络[12]。文献[2]利用卷积神经网络对江苏省县级市方言进行分类识别,文献[13]将多任务学习运用到解决方言语种识别的问题上,但其使用语音音频时段较长。
1.2 基于多任务学习的语音识别研究
多任务学习(multitask learning,MTL)假设不同任务数据分布之间存在一定的相似性,在此基础上通过共同训练和优化建立任务之间的联系。充分促进任务之间的信息交换并达到了相互学习的目标。各个子任务可以从其他任务获得一定的启发,并间接利用其他任务的数据,达到了提升各自任务学习性能的目的[14]。
S Ruder提出了深度学习中MTL的两种最常用的方法。阐明了MTL原理,为自然语言处理和语音识别提供指南。
近年来,多任务学习及LSTM循环网络的提出为方言语种识别提供了研究的空间。该文应用LSTM网络构建单任务学习模型,对其参数进行优化。进一步利用不同地域方言的相关性,提出基于参数软共享的多任务模型,共享隐藏层信息提高准确率。考虑到同一方言区域的方言语种的相似性,以方言区域为辅助任务提出基于参数硬共享的多任务学习模型,提升模型的泛化性。继而为确定任务相关性,提出基于参数稀疏共享机制的多任务学习模型。在方言语种的选取上,很多研究多选取印地方言[15],某一单一区域方言如湖南方言等[16],部分语音识别相关研究选取少数民族语言如维吾尔语、藏语等。该文选取涵盖6大方言区域的10种中国方言语种。
2 语音特征
音频中包含丰富的语音特征信息,不同的特征向量往往可以表征不同的声学意义,由此抽取语音特征,挖掘语音特征关联信息,对语种识别至关重要。语音特征提取是指从一段语音中选择有效的音频表征。原始语音信号是典型的非平稳信号,而语音特征提取的分析手段是针对平稳信号的。由此通常假定10 ms~30 ms的短时内信号为平稳信号,并基于此进行成分分析。该文对原始音频的长语音信号进行加窗、分帧处理,进而获得多个平稳的短时信号。在此基础上,进行语音特征的分析提取。该文抽取MFCC特征。
图1展示了MFCC特征的抽取方法及其与常见语音特征Fbank、语谱图的对比。
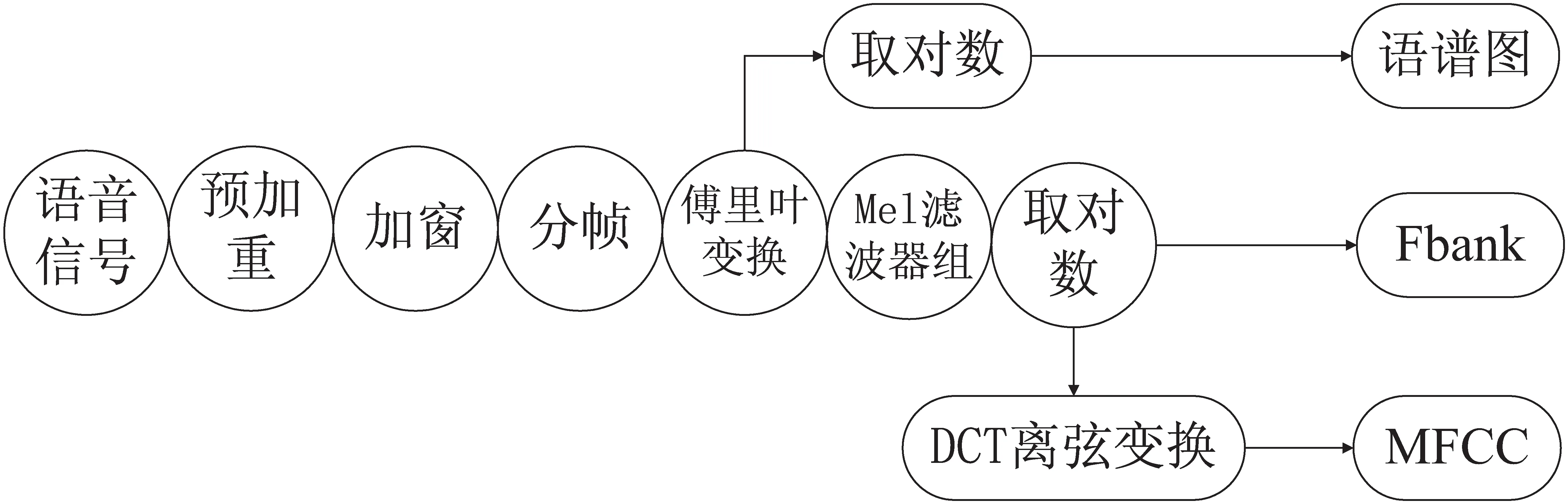
图1 MFCC抽取方法及其与Fbank、语谱图的对比
语谱图通过将语音信号进行傅里叶变换后取对数而得,保存了更多的原始语音信号信息但噪音较多。Fbank特征是在对语音信号进行傅里叶变换后,进一步使用梅尔滤波器组进行处理,并对结果取对数而得。MFCC和Fbank参考人类对声音高低的敏感度,利用梅尔刻度对这种敏感度进行量化表示。其获取流程与人耳处理声音的流程类似。MFCC特征是在Fbank基础上进行DCT离弦变换后获得的倒谱参数,因此数据维度小。
3 基于单任务学习的方言分类模型
本节基于MFCC特征构建单任务神经网络模型。模型构建包含数据采集、特征提取及模型训练三个过程,训练过程如算法1所示。训练及测试数据集来自于科大讯飞AI挑战大赛所提供的方言数据集。
3.1 特征提取
通过Python wave库提取语音信号MFCC(mel-frequency cepstral cofficients),并将10种方言数据处理成[data,label](数据及其对应标签,其中闽南、客家、上海、合肥、陕西、宁夏、长沙、河北、南昌、四川依次对应标签0~9)。
3.2 基于单任务神经网络的方言语种分类
该模型由CNN和LSTM两部分组成,网络结构如表1所示,其中C1、C2为卷积层,D1、D2为全连接层。以C1参数为例,(3×3,1)中,3×3表示卷积核大小,1表示步长,8表示卷积核个数。上述三种单任务神经网络模型实验结果及性能分析见5.3节。模型训练过程见算法1。

表1 基于MFCC的单任务模型架构
算法1:单任务语种分类模型训练算法。
输入:训练集数据及标签(Train_Data,Train_Label)、测试集数据及标签(Dev_Data,Dev Label)、训练轮数(Epoch)
#初始化
Epoch=N;
Best_acc=0;
For i=1 to N
#将数据输入网络进行训练
Train_Pre= Net(Train_Data);
#对网络输出执行softmax运算
Train_Pre=Softmax(Train_Pre);
#计算训练集准确率及Loss函数值
Train_acc=Acc(Train_Pre, Train_Label)
Loss=Loss (Train_Data, Train_Label)
#反向传播更新权重
Loss.backward()
Dev_Pre=Net(Data);
Dev_Pre=Softmax(Dev_Pre);
Dev_acc=Acc(Dev_Pre, Dev_Label)
Best_acc=Dev_acc
输出(Train_acc,Dev_acc)
IF Dev_acc> Best_acc:
Best_acc=Dev_acc
保存模型
EDN IF
输出模型;
输出:训练集准确率(Train_acc) 测试集准确率(Dev_acc)
4 基于多任务学习的方言分类模型
多任务学习(Multi-task learning,MTL)在自然语言处理和计算机图像[17]等领域取得了一定的成功。其核心是通过同时训练多个相关任务并共享不同任务间的参数以提升模型整体的泛化能力,多任务学习包含参数软共享和参数硬共享两种参数共享方式。本节基于MFCC特征构建基于参数软共享的多语种任务方言分类模型以及基于参数硬共享的以方言区域分类为辅助任务的方言分类模型。
4.1 以方言区域识别为辅助任务的方言分类模型
本节介绍以方言语种分类为主任务、以方言区域识别为辅助任务构建的基于参数硬共享的多任务学习模型。中国方言可划分为十大方言,分别是:官话方言、客家方言、晋方言、徽方言、湘方言、吴方言、粤方言、闽方言、赣方言、平话土话。不同方言区域有其各自特点,与此同时不同方言区域特征也有一定的交叉性,如赣方言长期受地理位置邻近的客家方言的影响,导致其特征与客家方言相似。本节以方言区域分类做辅助任务,为主任务提供不同方言区域特征信息和方言区域的交叉信息,由此构建基于参数硬共享的多任务学习模型。参数硬共享机制共享任务间的隐藏层,并保留各自输出层,适合任务相关性较高的情况。以方言区域识别为辅助任务的方言语种分类模型,主任务方言语种分类和辅助任务区域识别任务共享同一网络架构,共享各个方言区域的隐藏信息,保留主任务和辅助任务的输出,网络联合训练所有任务损失值,通过输出评估结果。方言区域与标签对应关系如表2所示,实验结果见5.4.1节。
该模型网络结构同单任务模型相同,模型结构如图2所示。该模型通过在共享层实现参数硬共享,计算主任务和辅助任务的损失loss1,loss2并进行加权求和,权重均为0.5,如公式(5)。对losssum进行反向传播和更新,训练并保存模型。

图2 基于参数硬共享的模型架构图 表2 方言区域标签对应表

方言方言区域标签闽南闽方言0客家客家方言1上海,合肥吴方言2陕西,宁夏,河北,四川官话方言3南昌赣方言4长沙湘方言5
4.2 基于稀疏参数共享的方言分类模型
本节介绍基于稀疏参数共享[18]的方言分类模型,稀疏共享通过自主发现子任务间的共性,裁剪不重要的网络参数,完成子任务间部分参数的共享,在提高共享机制灵活性的同时减少模型参数量,提升模型执行效率。
训练流程包含3步,首先,构建一个超参数模型,称为基础网络(base network)。然后,子任务基于base network开始训练,训练过程中子任务根据需求动态裁剪冗余参数。最后,从基础网络中抽取出各个任务需要的子网络。由于是自动训练,往往任务相关性高的子网络会共享部分网络权重,而任务相关性不高的子网络独自为一体。与硬共享不同,稀疏共享因为子任务间部分网络的重叠,实现了参数共享的目的。图2所示为所用的稀疏共享机制。首先,选用第四节构建的单任务模型作为稀疏共享机制的基础网络,并定义方言语种分类和方言区域分类两个子任务,其中Task1为方言语种分类任务、Task2为方言区域分类任务。进一步,使用二进制掩码矩阵M∈{0,1}为各个任务选择子网,图中Mask1、Mask2为各个任务子网络,将各个任务子网络合并在一起构成了稀疏共享结构。然后,分别使用两个子任务数据进行联合训练,联合训练时抽取各个任务的数据对相应子网络进行训练,基础网络中子任务重合的参数被多次训练。参数的稀疏共享机制既能够体现出两种分类任务之间的差异性,又注重语种与其所属语言区域特征的交叉性与相关性。
4.2.1 子任务网络
子任务网络通过对base network进行迭代幅度裁剪(iterative magnitude pruning,IMP)[19]而得,训练过程如算法2所示。网络结构和参数由二进制掩码Mask矩阵和基础网络决定。设基础网络的参数为θ,子任务t的Mask矩阵为Mt,则子任务t的网参数为Mt·θ。α为每轮训练过程中子网参数权重保留率(percent of weights remaining),即子网中α的参数的权重被保留,将权重由小到大排列,前1-α的参数权重被裁剪,若权重被保留则其对应的Mt值为1,反之为0。
算法2:稀疏共享模型子网络训练算法。
输入:基本网络,最低保留率Minα;
输出:最高准确率对应的子网络Mt。
模型参数初始化
Fort=1…t
Do
初始化Mt
初始化保留率α=100%
初始化网络参数总数total_params
Do
Train()
Dev()
计算保留参数个数total_m
#更新保留率
α=1-round (100%*total_m/self.total_params,2)
#裁剪并保存网络θ,mask,acc
Whileα>Min(α) or pruning epoch>10
4.2.2 并行训练子任务网络
每个任务训练时都只用到了对应的子网络,但各个子任务的网络会共享网络参数,因此这部分参数会被多个任务的数据进行更新,训练过程如算法3所示。实验结果详见5.4.2节。
算法3:并行训练子网的算法。
输入:基本网络,子任务数据集,子网络Mask;
输出:测试集准确率。
Epoch=N;
Fori=1 toN
选择任务t
M=Mt
#为任务t随机选择一个Batch的数据
Train()
Dev() #更新子网络参数
Acc() #计算相应任务准确率
5 实验分析
5.1 实验平台
硬件平台:使用高性能服务器进行模型训练,该平台配置了Intel(R) Core(TM) CPU,64 GB内存,2块GeForce RTX 2080 Ti GPU。
软件平台:服务器运行Ubuntu系统,搭载Pytorch(1.6.1)、CUDNN(1.6.0)、CUDA(10.0)。模型均基于Pytorch框架进行实现。
5.2 数据集
实验数据集为科大讯飞AI开发者大赛提供的方言数据。数据集共包括十种方言,每种方言包含 40个本地人的朗读风格语音数据,数据以采样率16 000 Hz,16比特量化的PCM格式存储。数据集包含训练集和测试集两个部分。训练集每种方言有5 000句语音,包含15位男性和15位女性,共30位说话人,每个说话人200句语音;测试集每种方言包含5个说话人,其中3名女性和2名男性。训练集、测试集的说话人均没有重复,训练集方言音频条数为6 000条,测试集方言音频条数为500条,同时,对所使用的数据集进行了统一时长及去噪处理。
统一时长:由于数据音频时长不统一,且部分音频中存在大量的空白时段,通过音频裁剪或填充方法,将所有音频数据处理为2秒。
去噪:实验使用谱减法对数据进行去噪。
5.3 单任务方言分类模型结果分析
分别抽取数据集的MFCC的语音特征,并分别输入单任务模型进行训练。代价函数为交叉熵损失函数,epoch为25。
采用少量数据对单任务模型进行参数调整。参数调整结果见表3。
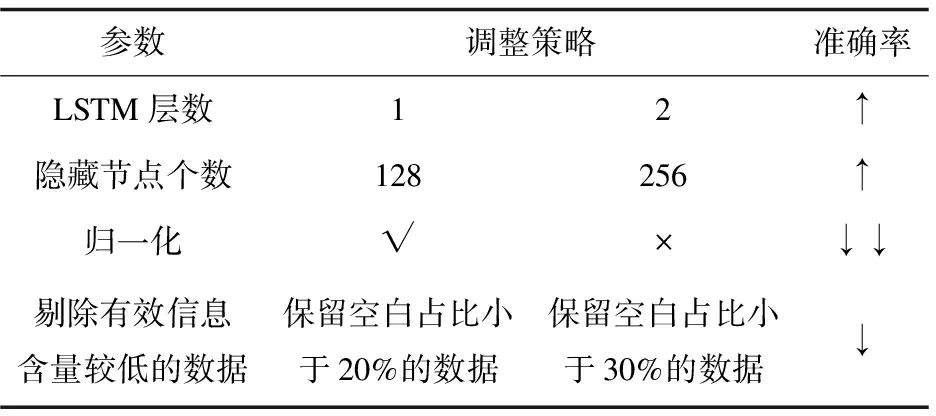
表3 参数调整对准确率影响变化趋势
在表3准确率变化栏中,准确率的变化趋势由符号‘=’,‘↑’,‘↓’表示,符号数量表示程度,‘=’表示调整参数后准确率变化不大,‘↑↑’表示调整参数后准确率提高幅度大,‘↓↓’反之。分别将原始数据和去噪数据输入优化后的网络模型,记录测试集准确率。如图3(a)所示,使用原始数据训练的模型准确率可达79.04%,去噪数据准确率达到76%。其召回率、精确率、F1_score值如图3(b)所示。

图3 面向MFCC的单任务模型识别准确率 及召回率、精确率、F1_score
综上可知,三种单任务模型在去噪数据集上的准确率低于原始数据训练模型。这是由于降噪过程中需要对原始音频数据进行平滑处理,该处理方式有利于改善用户听感,但另一方面,平滑处理使频谱信息变得模糊,导致部分原始音频信息丢失,从而无法获得较高准确率。后续实验模型均基于原始数据进行构建。
5.4 多任务语种识别模型结果分析
5.4.1 以方言区域识别为辅助任务的硬共享方言分类模型
首先,为数据集中每条音频信息进行区域标记。形式为[data,label1,label2],其中label1表示数据方言语种标签,label2表示数据的方言区域标签,然后,将MFCC特征原始数据输入模型(模型结构见表2),实验结果如图3所示。相比于单任务模型,主任务和辅助任务联合训练的参数硬共享模型准确率平均提升1%。其在测试集上的准确率达79.9%。模型召回率为79.1%,精确率为77.4%,F1_score为76.7%。
5.4.2 基于稀疏共享的方言分类模型
本节选择单任务模型作为base network。分别选取最优的子任务模型,Task0为方言语种分类任务,Task1为方言区域分类任务。图4(a)为不同参数权重保留率下子任务的准确率,实验选择准确率最高的子任务模型。子任务模型选择情况为任务Task0选取参数保留率为25.12%的模型,Task1选取参数保留率为39.81%的模型,
对不同任务分别进行联合训练,其准确率如图4(b)所示。召回率为77%,精确率为76%,F1_score为65%。模型准确率可达83.59%,较基于参数硬共享的方言识别模型准确率提高3%。
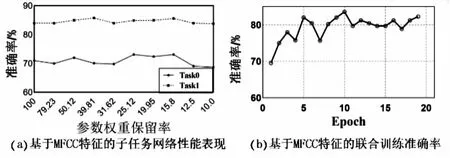
图4 基于MFCC特征的子任务网络性能 表现及联合训练准确率
5.4.3 基于不同语音特征的多任务模型结果分析
为进一步验证稀疏共享分类模型的有效性和优越性,在原始数据集上提取语谱图,Fbank两个常见的语音特征,并针对两种特征建立基于LSTM的单任务模型,进一步构建基于参数硬共享和基于参数系数共享的多任务模型,其准确率如图5(a)、5(b)所示。语谱图、Fbank特征在参数稀疏共享模型上的准确率分别提升3%、1%,召回率、精确率、F1-score如表4所示。
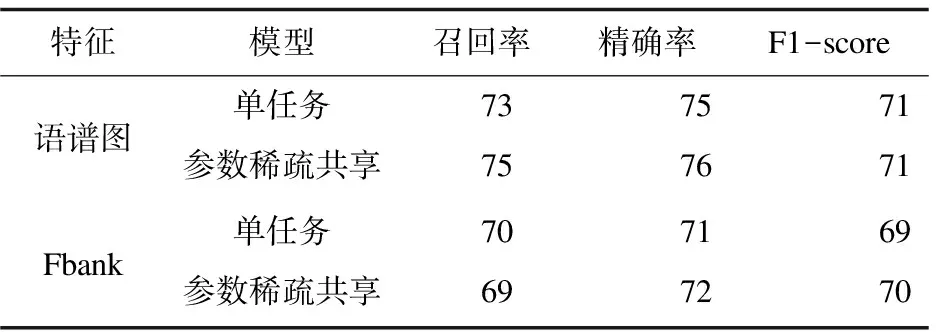
表4 模型召回率、精确率、F1_score对比表
语谱图与Fbank特征在多任务模型上的表现均优于单任务模型。基于在稀疏共享的多任务的模型上获取最高准确率。
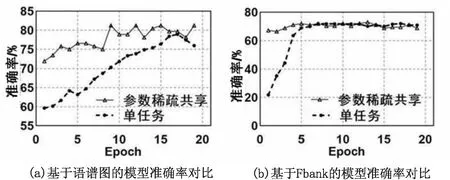
图5 基于语谱图、Fbank的模型准确率对比
5.5 实验对比
将基于稀疏共享的方言分类模型(sparse-sharing network,SSNet)同文献[14]提出的ATLNet方言分类模型进行比较。为了保证数据的统一性,用同样的2秒数据集训练ATLNet网络。由于ATLNet(准确率仅为78.3%)模型无法充分挖掘方言任务间相关性,由此在2秒数据集中,提出的基于稀疏共享的方言分类模型性能更优,准确率达83.59%。
5.6 实验结果总结
针对中国方言的复杂性、相似性的特征,结合语音数据特征特性,首先应用LSTM搭建面向MFCC的方言语种识别系统,并对模型进行调参优化。进一步提出基于参数硬共享、稀疏共享的两种多任务模型。并以Fbank、语谱图为输入进行有效性验证,获得表现最优(准确率达83.59%)的基于稀疏参数共享的方言分类模型。
6 结束语
中国地域辽阔,方言种类繁多,汉语方言识别一直是语音识别中的难点,提升方言分类准确率对于下一步的方言识别至关重要。首先抽取典型的语音特征MFCC进行对比研究,并基于该语音特征分别构建LSTM方言分类模型,准确率可达79.04%。进一步挖掘中国十种方言的地域特征,建立以方言区域为辅助任务的参数硬共享多任务方言分类模型,由于多个子任务之间存在一定相关性,相比单任务模型,联合训练多任务模型可以挖掘到更多的数据特性,由此也获得了更好的性能,准确率可达79.9%。最后,为了进一步提升多任务模型规模,删除冗余的网络节点对结果的影响,提出基于参数稀疏共享的多任务方言分类模型,联合训练多个子任务的过程中,对base network进行自动裁剪,并共享相关度高的网络权重,在降低网络复杂度的同时,提升识别性能,准确率可达83.59%。
综上,MFCC语音特征,利用三种不同的网络结构对方言分类进行建模研究,其中基于参数稀疏共享多任务方言分类模型性能最优。下一步,作者将从以下三个方面进行进一步研究:(1)针对多任务模型中不同子任务loss值对模型性能的影响进行研究;(2)研究Attenion机制对方言分类的影响;(3)利用迁移学习降低模型训练开销。
猜你喜欢
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
意林·全彩Color(2019年6期)2019-07-24
福建基础教育研究(2019年8期)2019-05-28
卷宗(2018年24期)2018-11-07
未来英才(2017年24期)2018-01-23
中学生博览(2017年23期)2017-12-16
高中生·天天向上(2009年11期)2009-12-17
