
基于NMF与CNN联合优化的声学场景分类
2022-05-07 09:20杨皇卫宁方立
系统工程与电子技术 2022年5期
韦 娟, 杨皇卫, 宁方立
(1. 西安电子科技大学通信工程学院, 陕西 西安 710071; 2. 西北工业大学机电学院, 陕西 西安 710072)
0 引 言
声学场景分类(acoustic scene classification, ASC)旨在从不同音频片段中识别出各自包含的场景信息并加以分类。相比利用图像或视频信息实现场景分类,ASC技术具有全向性,且不会受遮挡和光线条件的影响,在智能穿戴设备、物联网音频监控、巡检机器人等领域有着广泛的应用前景[1-2]。
实际声学场景通常由多个声学事件组成,但只有少数声学事件能对场景分析起到关键作用,因此需要提取足够有效的声学特征。ASC任务中常用的对数梅尔谱(log Mel-spectrogram,LM)[3-4]和常数Q变换(constant Q transform,CQT)[5]可以对频带相对固定的音频信号进行有效的时频分析,但对于结构性较差的声学场景信号表现不佳[6]。于是,基于自动特征学习的非负矩阵分解(non-negative matrix factorization,NMF)[7-8]被应用于ASC任务。作为一种基于部分表达整体的方法,NMF能够有效解决由各类声学事件组成的场景分类问题。姚琨等人[9]将NMF与LM进行特征融合以提高识别率,但未考虑样本标签对特征提取的辅助作用。Lee等人[10]提出一种利用标签信息对各类声学场景独立学习基矩阵的方法,但不同场景可能存在相似的声学事件,易造成基向量的冗余和混淆。Bisot等人[11]提出基于逻辑回归的任务驱动型NMF(task-driven NMF,TNMF)算法,通过分类器修正特征学习的方式有效提升场景分类效果,但因逻辑回归分类器性能有限而难以得到更有判别性的特征。
如何利用声学特征训练出有效的分类模型是ASC任务的另一个难点。随着深度学习的快速发展,卷积神经网络(convolutional neural network,CNN)[12]因为可以识别缩放、移位等空间失真不变性[13],在ASC任务中得到广泛应用。Boddapati等人[14]通过叠加声谱图、梅尔倒谱系数以及相干复原图组成三通道特征,结合图像识别中两种常用的CNN模型进行环境声音分类。Doan等人[15]提出一种应用于耳蜗谱图的深度CNN模型,通过加深卷积层个数学习更丰富的场景信息。曹毅等人[16]将马尔可夫模型的思想应用于CNN,提出一种更适合音频分类的N阶密集CNN模型。虽然上述模型尝试从不同角度获取特征图中的分类信息并取得一定的效果,但均基于一次性提取的无监督特征图,没有考虑在后续模型训练过程中对特征图本身所包含的信息进行优化。
针对以上问题,提出一种NMF与CNN联合优化的有监督特征学习算法。该算法利用基于NMF的特征表示训练CNN模型,根据标签信息和实际训练效果不断反向优化NMF的过程,自适应地调整特征提取方向以获得更利于分类的判别性特征。
1 特征提取
NMF在对原始时频图降维的同时能够提取出声学场景的更好表示[17]。一方面,对非负声谱图矩阵V进行NMF,可理解为联合学习非负的基矩阵W与权值矩阵H,使得V≈WH[18-19]。其中,W的列向量代表特定的声学事件,H的列向量对应当前时刻各声学事件所占的比重。由于声学场景是由不同声学事件组成的复杂多源环境,因此判断特定事件是否发生将有助于分辨不同的场景。另一方面,NMF算法可以与标签信息结合,不断修正特征提取过程,促使基矩阵W对环境中声学事件的刻画更加准确,从而增强NMF特征的表达能力。
(1)
式中:‖·‖F表示矩阵Frobenius范数;λ表示L2正则化系数,目的是防止基矩阵出现过拟合。
通过NMF算法得到基矩阵W,再对每个样本的声谱图v在W上利用带有正约束的最小角回归算法[20]进行投影,得到的权值矩阵h即为该样本的NMF特征。
进一步,令∂f(W,h)/∂h=0,有:
h=(WTW+λI)-1WTv
(2)
对式(2)求微分,有:
dh=-(WTW+λI)-1WTdWh+ (WTW+λI)-1(dW)T(v-Wh)
(3)
式(3)表达了权值矩阵h与基矩阵W的微分关系,利用该式以及样本的标签信息即可根据联合优化算法实现NMF特征的修正。
2 联合优化算法
NMF作为一种自动特征学习方法,能够根据不同任务和数据集自动学习到有效特征。在加入标签信息后,NMF可进一步调整特征提取方向,提高对特定任务的适应性。于是,在文献[11]的基础上提出一种联合优化算法,通过引入CNN模型实现NMF与神经网络的联合训练,提取同时包含生成信息和判别信息[21]的有监督NMF(supervised NMF,SNMF)特征。
令神经网络的损失函数为ls,有:
(4)
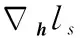
(5)
利用梯度下降法实现基矩阵的修正:
(6)
式中:ΠW表示对基矩阵W进行L2范数标准化;ρ代表基矩阵的学习率。
在修正后的基矩阵上进行投影,得到新的权值矩阵h即为SNMF特征。
算法具体步骤如下。
步骤 1将训练集样本的声谱图扩展后进行NMF,得到基矩阵W。
步骤 2将训练集样本的声谱图在基矩阵W上进行投影,获得的权值矩阵输入已搭建的CNN模型中进行训练。
步骤 3从训练集中随机不重复选取一组样本的声谱图,在基矩阵W上投影得到权值矩阵h,输入已训练CNN模型中获取对应的一组损失值。
步骤 4利用式(6)实现网络损失值对基矩阵W的修正。
步骤 5在修正后的基矩阵W基础上重复步骤3~步骤4,完成整个训练集样本对基矩阵的修正。
步骤 6在修正完毕的基矩阵W基础上重复步骤2~步骤5,直到满足预设条件后退出循环。
联合优化算法的整体流程如图1所示。
3 网络模型
目前ASC任务主要采用CNN型深度神经网络对二维时频特征进行分类[22-23]。通过NMF得到的二维特征同样包含丰富的分类信息,可使用相似的网络结构[10]。在模型的搭建上,一方面,由于各时间片段里包含的声学事件有所不同,为使模型充分学习到这些声学事件的有效特征,应适当减少在时间轴上的池化。另一方面,网络中的卷积层数目对识别效果也有一定影响[24]。数目过少可能导致网络的拟合程度不高;数目过多则可能因梯度消失问题降低SNMF特征的修正效果。为得到适合SNMF特征的模型,并验证网络层数对分类效果的影响,在视觉几何组网络(visual geometry groupnet work, VGGNet)[25]和文献[3]的基础上分别搭建卷积层数目为8、10、12的CNN8、CNN10和CNN12模型进行实验。
模型结构与参数如表1所示,其中@符号表示Conv2D卷积层。优化器使用随机梯度下降算法,批大小为16,模型的训练与SNMF特征的修正交替进行。为避免因网络收敛过快而导致修正幅度较小,选择每训练10轮模型修正1次SNMF特征。每10轮间模型的学习率按热重启学习率策略[3,26]从5×10-3以余弦下降方式衰减到5×10-5,使用交叉熵损失函数共训练70轮[11]。

表1 CNN模型结构
4 实验与分析
4.1 实验数据与配置
实验所采用的数据集为TUT Acoustic Scenes 2017开发数据集[27]。该数据集的录音时长总计13 h,包括沙滩、公交、咖啡馆/饭馆、汽车、市中心、林荫道、杂货店、家、图书馆、地铁站、办公室、公园、居民区、火车、电车在内的15种声学环境,每类音频包含312个样本,总共4 680个样本。样本均为采样率44.1 kHz,精度24位,时长10 s的双声道音频。将所有样本降采样到22.05 kHz,平均左右声道数据以供后续使用。根据官方提供的四折交叉验证方式进行数据集的划分与实验,使用准确率作为最终的评价指标。实验硬件配置为Intel(R) Core(TM) i5-10400F CPU、16 GB内存、Nvidia GeForce RTX 2060 GPU,软件环境为Ubuntu18.04系统,Python3.6.11、Tensorflow1.15.0、Keras2.3.1。
4.2 参数设置
NMF特征设置:帧长和帧移分别为1 024和512个采样点,通过短时傅里叶变换得到512×431的对数声谱图。按文献[11]的方法进行池化操作得到512×108的对数声谱图。扩展所有训练样本的声谱图后进行NMF得到512×K的基矩阵W,K为基向量数及特征维数,该基矩阵同时用作SNMF特征的初始基矩阵。最后在W上重新投影得到K×108的NMF特征。
SNMF特征设置:正则化系数λ设为2×10-2,学习率ρ取5×10-4。参数的选择来源于组合实验的结果。
其他特征设置:为了对比分析,提取由声谱图通过256组梅尔滤波器后获得的LM特征,尺寸为256×431;每8度取24个频带得到的CQT特征,尺寸为255×431。通过池化操作后得到256×108的LM特征与255×108的CQT特征。
4.3 结果分析
4.3.1 特征维数和模型层数对准确率的影响
为说明不同特征维数对分类准确率的影响,令分类器为已搭建的CNN10模型,并分别令NMF中基向量的数目为64、128、256和512以提取4种不同维数的SNMF特征。如表2所示,为SNMF特征在四折交叉验证下取不同特征维数时的准确率变化情况。

表2 不同特征维数下的准确率
由表2可知,K值取64、128和256时,四折数据划分下的识别准确率均随着特征维数的增加而提高。说明随着基向量的增多,基矩阵对声学场景中各声学事件的学习更加充分,能够从声谱图中学习到更细分的基事件,使提取的SNMF特征中包含更多的区分信息。但当K值大于256时,识别准确率发生一定下降,说明K值并非越大越好。因为,此时多余的基向量学习到的是噪声和冗余信息,将对识别效果产生一定干扰。
表3为K=256时SNMF特征在模型取不同层数时对识别准确率的影响。
分析表3可知,模型的层数会对识别准确率产生较大影响。层数较低时,因为网络欠拟合而导致分类效果不佳;而层数较高时则容易因网络过深而产生梯度消失问题。由于联合优化算法的效果依赖于网络损失值的梯度反向传播,若出现梯度消失将会使SNMF特征的修正程度不高,从而降低联合优化算法的效果。
4.3.2 不同特征之间的对比
为验证联合优化算法的实际效果,将SNMF特征与TUT2017数据集的官方基线系统[27]、无监督NMF特征、以对数声谱图为基础提取的TNMF特征[11]、CQT特征与LM特征进行对比。其中,NMF特征和SNMF特征的特征维数K=256。为保证所有特征能够拥有适合其自身特点的分类器,令NMF与SNMF特征的分类器为CNN10模型,TNMF特征的分类器同文献[11],而LM和CQT特征则选取在2020年声学场景和事件的检测与分类挑战赛(Detection and Classification of Acoustic Scenes and Events,DCASE)中表现优异的类VGGNet模型[28]。获得的分类结果如表4所示。
分析表4可知,与CNN结合的无监督NMF特征和SNMF特征的识别准确率分别高出基线系统4.9%和8.8%,说明NMF与CNN结合是一种有效的识别方法。同时,即使未使用联合优化算法的NMF特征也要优于使用逻辑回归分类器的TNMF特征,说明分类器的性能对识别结果有着较大影响。另外,通过联合优化算法获取的SNMF特征识别准确率达到83.6%,分别高出NMF特征3.9%、CQT特征3.1%和LM特征2.3%,说明联合优化算法有助于提取更优的特征。原因是与CNN分类器相结合的有监督特征学习方式能够利用标签信息和实际分类效果不断调整NMF中基矩阵内的参数,提高基向量的表征能力,从而获取更有判别性的特征。
由表4还可知,在不同类别场景下的分类效果方面,SNMF特征在所有类别中准确率的最大值与最小值之间的差值最小,说明SNMF特征有更好的稳定性。另外,无论哪一种特征,在汽车、市中心、办公室、电车等类别的分类上均表现良好,而在某些类别的分类上性能却不高,如饭馆、图书馆、公园和居民区。这主要是因为噪声影响使其具有的特定声学事件变得模糊不清,或是该类声学场景中具有易与其他声学场景造成混淆的相似声学事件[29-30]。而在测试集样本的总预测时间方面,几种特征没有明显的区别,都能够满足一般场景下的实时性要求。
5 结 论
为解决ASC任务中特征提取与模型训练的联合优化问题,首先对声谱图进行NMF,得到基矩阵和权值矩阵,然后搭建并训练CNN模型,根据训练结果反向更新基矩阵以获得修正的SNMF特征,实现一种NMF与CNN联合优化的有监督特征学习方法。得出结论如下:
(1) 提高特征维数有利于学习更细分的基事件,但维数过高则会因噪声和冗余信息降低识别效果;
(2) 由于联合优化算法依赖于梯度反向传播,过高的网络层数会引起梯度消失从而影响算法的优化效果;
(3) 相较于直接使用NMF特征,联合优化后的SNMF特征能够使分类准确率得到明显提升;
(4) 所提方法实现了特征提取与网络训练的联合优化,是一种有效的声学场景分类方法。
猜你喜欢
电子产品世界(2022年4期)2022-04-21
煤气与热力(2021年5期)2021-07-22
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
计算机系统应用(2021年2期)2021-02-23
健康体检与管理(2021年10期)2021-01-03
家庭影院技术(2020年11期)2020-12-28
家庭影院技术(2020年5期)2020-08-24
家庭影院技术(2020年6期)2020-07-27
