
软件定义网络环境下的低速率拒绝服务攻击检测方法
2022-05-07 07:08刘向举路小宝方贤进尚林松
计算机应用 2022年4期
刘向举,路小宝,方贤进,尚林松
(安徽理工大学计算机科学与工程学院,安徽淮南 232001)
0 引言
拒绝服务(Denial of Service,DoS)攻击已经成为网络面临最重要的威胁之一。它通过控制僵尸网络,以洪泛方式向目标主机发送大量数据包,严重消耗网络资源,最终可使得网络瘫痪。为应对这种情况,很多网络设备都增加了检测模块,以快速识别攻击并制定网络安全防御措施。为了实现更隐蔽、更高效的攻击,产生了一种新型的网络攻击手段——低速率拒绝服务(Low-rate Denial of Service,LDoS)攻击。LDoS 攻击是对传统DoS 攻击的改进,它不同于传统通过洪泛方式的DoS 攻击,LDoS 攻击利用网络协议或应用服务中常见的自适应机制中存在的安全漏洞,通过周期性发送攻击短脉冲数据流,占用攻击目标的可用资源,从而降低攻击目标的服务性能。LDoS 攻击最大特点是平均攻击数据流速率相对较低,发出的脉冲是周期性的,其攻击脉冲可以用一个三元组(L
,R
,T
)来表示,如图1 所示。L
是脉冲宽度,它表示攻击脉冲的持续时间;R
是脉冲强度,它显示攻击流的最大值;T
是攻击周期,它表示连续攻击脉冲的时间间隔。这种攻击方式与正常数据流混合难以区别,可操控性强且攻击效率高。因此,现有的针对传统DoS 攻击检测方法运用到LDoS 攻击不能有效检测到攻击。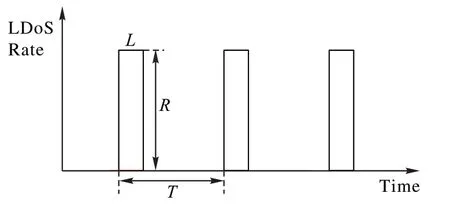
图1 LDoS攻击模型Fig.1 Model of LDoS attack
TCP 是现在网络中普遍使用的传输协议。目前研究的各类LDoS 攻击大部分是基于TCP 的自适应机制。LDoS 攻击正是利用了TCP 自适应机制中的两种拥塞控制机制。第一种是超时重传机制(Retransmission Time Out,RTO):当TCP 报文在网络传输过程中超时丢失,TCP 发送方将拥塞窗口减少到一个数据包,并重新传输丢失的TCP 报文;第二种是加增减乘机制(Additive Increase Multiplicative Decrease,AIMD):发送方收到三次重复的确认(ACKnowledgement,ACK)消息,TCP 发送方将拥塞窗口减半,以重传丢失的TCP报文。RFC2988建议最小超时重传时间为1 s。理论上,当LDoS 攻击周期为1 s 时,它可以连续触发超时重传,并周期性丢弃正常TCP 数据包,迫使发送方减小拥塞窗口以限制传输速率,从而降低网络服务质量。
软件定义网络(Software Defined Network,SDN)作为一种新型的网络创新体系架构,相较于传统网络设备实现了控制平面与数据平面的分离。这种新型网络的架构优势很明显,简化网络设备的管理和配置,形成统一高效的管理和维护,提高网络的运行效率,降低设备的维护成本。但由于通过控制器对网络集中控制和管理,更容易遭受LDoS 攻击,被攻击后造成的后果更加严重。因此,在SDN 环境下研究LDoS 攻击检测,对改善网络安全具有重要意义。
1 相关工作
目前针对传统网络架构,有大量针对LDoS 攻击检测的研究。岳猛等提出一种基于隐马尔可夫模型的LDoS 攻击检测方法,该方法将归一化累计功率谱密度(Normalized Cumulative Power Spectrum Density,NCPSD)方法作为LDoS攻击的初步检测,将其结果作为隐马尔可夫模型的观测值。该方法实时性强,检测率较高,但是检测LDoS 攻击阈值ζ
是在一定范围内选择的。何炎祥等提出了一种基于小波特征提取的LDoS 检测方法,该方法通过小波多尺度分析提取LDoS 攻击特征,采用反向传播(Back Propagation,BP)神经网络模型来检测攻击。吴志军等提出一种基于时间窗统计的LDoS 攻击检测方法,该方法利用LDoS 攻击在单位时间内产生正常流量下降同时攻击流量出现高脉冲的这种突变现象,用时间窗统计来进行LDoS 攻击检测。该方法网络环境简单,得到实验数据理想。苟峰等提出一种基于CUSUM算法的LDoS 攻击检测方法,该方法对流量利用基于累计和(CUmulative SUM,CUSUM)算法累积异常,累积值超过阈值即触发报警,实现异常检测。此方法在检测初期会有误报现象。吴志军等提出一种基于ACK 序号步长的LDoS 攻击检测方法,此方法通过LDoS 攻击的瞬间ACK 序号步长存在波动行为,运用排列熵算法设置阈值来检测攻击。以上方法都是利用LDoS 攻击流量的单个异常特征进行攻击检测,可能导致检测性能不稳定。Yue 等提出基于小波能量谱和组合神经网络的LDoS 攻击流量识别方法,根据网络流量多重分形特征,识别LDoS 攻击流量。吴志军等提出一种基于联合特征的LDoS 攻击检测方法,提取了可用带宽比、小分组比例和分组丢失率3 种LDoS 攻击流量的内在特征,通过BP 神经网络模型实现攻击检测;但是由于网络流量是动态变化的,攻击强度变弱时可用带宽比和分组丢失率并不会明显变化。Tang 等对LDoS 攻击检测有一定研究,提出基于多特征融合和CNN 的LDoS 攻击检测方法,该方法将网络流量多特征融合生成网络状态映射图,将其作为CNN 模型的输入来训练模型对网络流量进行分类,该方法检测率高且稳定性好。Tang 等提出一种用于LDoS 攻击检测的改进Mean-Shift聚类算法,根据不同属性重要程度不同对均值漂移聚类欧氏距离进行加权,通过对簇的预设阈值和判决特征比较来识别攻击流量,此方法有较好的检测性能。以上检测方法都是提取了网络流量多特征,通过机器学习算法来实现攻击检测。相较于单一特性,多特征联合检测方法的性能更优。与此同时,在SDN 新型网络架构下,陈兴蜀等提出云环境下SDNLDoS 攻击的研究,该方法提取了10 维特征,基于贝叶斯网络实现对LDoS 攻击的检测,此方法仅在数据平面得到验证。颜通等提出了一种SDN 环境下的LDoS 攻击检测与防御技术,该方法对每条OpenFlow 数据流的速率单独进行统计,并利用信号检测中的双滑动窗口法实现对攻击流量的检测。王文涛等提出一种SDN 环境下基于Renyi 熵的LDoS 攻击的检测,该方法通过收集packet_in 数据包,然后基于目的IP 来计算Renyi 熵,最后通过设定一定的阈值来检测异常流量。这种方法只考虑到packet_in 消息,可能因获取信息不足导致检测结果又有误差。
上述检测方法多集中在传统网络,目前针对SDN 环境下的LDoS 攻击检测的研究成果相对较少。基于在SDN 环境下检测LDoS攻击的特征单一性和过分依赖packet_in消息,本文提出一种在SDN 环境下的LDoS 攻击检测新方法,首先分析SDN 环境下LDoS攻击流量特征并提取出六元组特征,然后利用WMS-K
means算法进行聚类,以区分正常流量和异常流量。在软件定义网络的环境下,传统单一的K
-Means 算法并不适合LDoS攻击检测。K
-Means算法输入的初始聚类中心是随机的,必须给定生成簇的数量k
,最后的聚类结果往往受初始聚类中心的影响较大。Mean-Shift是基于密度的聚类算法,不需要预先知道簇个数,也不限定簇的形状,但聚类的最终结果不一定是最优的,Mean-Shift 算法对噪声的鲁棒性更强,因此将Mean-Shift算法聚类后的簇心,作为K
-Means 算法的初始聚类中心进行算法的融合。由此本文提出一种加权均值漂移-K
均值(Weighted Mean-ShiftK
-Means,WMS-K
means)算法。2 本文方法
2.1 流量分析以及LDoS 攻击流量特征选择
在全部的攻击类型中,资源消耗型攻击最为典型。SDN技术因其特殊的网络系统架构,攻击者可以限制控制器决策能力、消耗OpenFlow 交换机流表资源、消耗控制器与交换机通信的控制通道资源等。目前SDN 研究大部分是基于OpenFlow 协议的,因此本文所研究的主要是针对OpenFlow协议的SDN 资源消耗型攻击。在真实网络中,LDoS 攻击流量隐藏在正常网络流量之中,并没有完全消耗网络可用资源。但其攻击速率低且带有周期性,长时间发送攻击流量,依然可以给网络安全带来威胁。详细的网络流量分析如下:
1)在正常的网络流量时间尺度上,网络流量具有自相似性,因此短时间内不会出现网络流量明显的波动。在SDN架构下,当存在LDoS 攻击时,攻击端会周期性产生伪造虚假数据包,造成网络中packet_in 消息增加,所以packet_in 数据包变化可以作为检测依据。同时,在维持攻击速率稳定的情况下,LDoS 攻击流量分组越小,攻击效果越好。此时攻击流量数据包长度小于正常流量数据包长度,在攻击期间的表现为一段时间间隔Δt
内平均数据包长度被拉低。如图2 所示,可以看出在第14 秒攻击开始后,网络流量中packet_in 数据包个数增加以及攻击期间平均数据包长度低于正常流量平均数据包长度。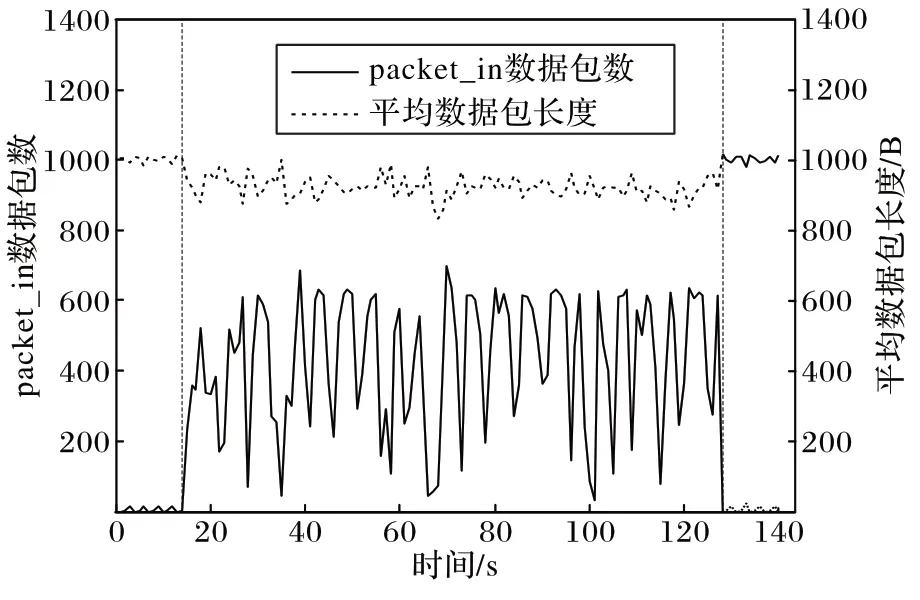
图2 packet_in数据包数和平均数据包长度的关系Fig.2 Relationship of packet_in packet number and average packet length
2)标准差反映的是数据集中数据分布的离散程度。在正常网络中,由于网络流量的自相似性,TCP 流量的标准差接近平均值。在SDN 架构下,当发生LDoS 攻击时,同样存在TCP 的拥塞控制机制,使得TCP 报文周期性持续丢失。在攻击期间表现为TCP 报文数下降且呈现周期性。如图3 所示,可以看出在14~126 s 攻击期间,TCP 标准差离散程度较大,相比于正常流量有明显变化。
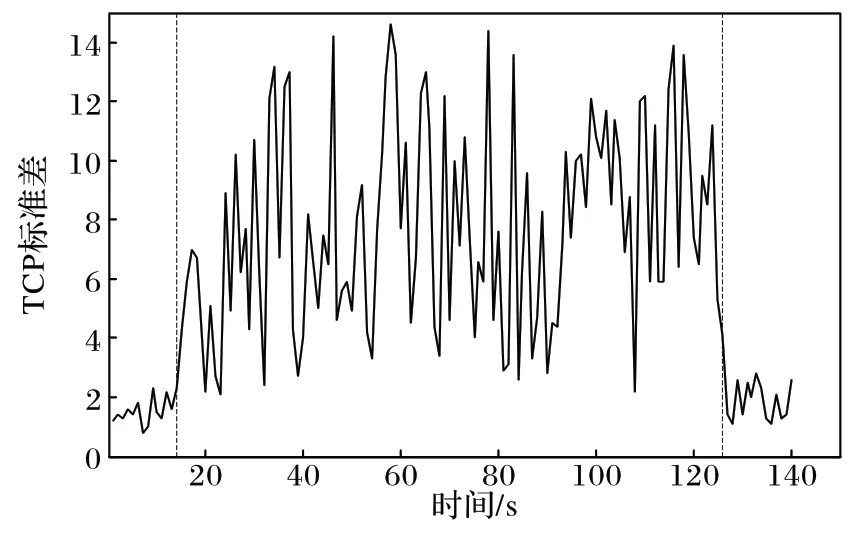
图3 TCP标准差变化Fig.3 TCP standard deviation change
3)在正常网络流量中,数据包中的源IP 地址绝大部分是已存在的网络地址,当遭受LDoS 攻击时,网络中会涌现大量伪造源IP 地址的数据包,此时控制器会收到大量packet_in 消息,并且攻击流量经过OpenFlow 协议封装产生TCP 的数据包,使得TCP 熵值偏低。如图4 所示,在14~126 s攻击期间,packet_in 源IP 地址熵值普遍接近于1,TCP 数据包熵值普遍靠近0.5,这是因为攻击源地址是伪造且随机产生增加了不确定性。
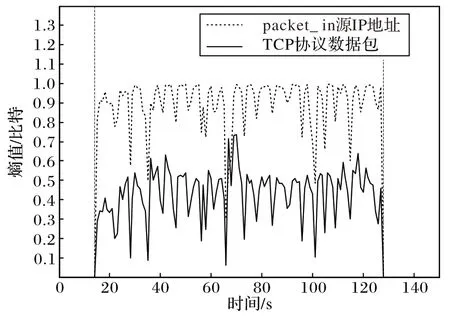
图4 熵值的变化Fig.4 Change of entropy
通过以上分析,LDoS 攻击流量特征选取的是packet_in数据包数、UDP 数据包个数、平均数据包长度、TCP 数据包标准差、packet_in 源IP 地址熵值和TCP 数据包熵值。在信息论中,信息熵是用来衡量随机变量不确定性和随机性的指标,对于时间序列,信息熵表示序列的无序程度。信息熵值越大,序列越无序;信息熵值越小,序列越稳定。信息熵的定义如下:

H
(X
)表示信息熵;x
表示出现的随机事件;n
表示随机事件的个数;p
(x
)表示随机事件发生的概率。具体流量特征表示如下:
1)packet_in 数据包个数:packet_in_sum
(Δt
),Δt
表示收集流表的时间间隔。2)UDP 数据包个数:udp_sum
(Δt
)。
3)平均数据包长度:
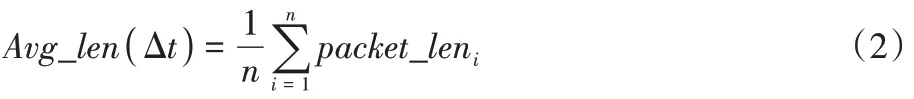
n
表示Δt
时间内的数据包总数;packet
_len
表示每个数据包的长度。4)TCP 数据包标准差:
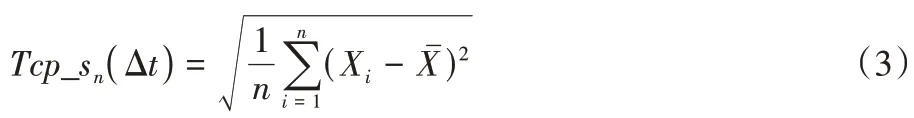
n
表示Δt
时间内TCP 数据包取的份数;X
ˉ表示Δt
时间内TCP 数据包平均值;X
表示Δt
时间内每份TCP 数据包个数。5)packet_in 数据包源IP 地址熵值:
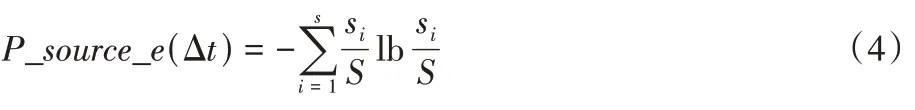
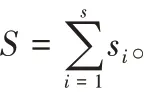
6)TCP 数据包熵值:
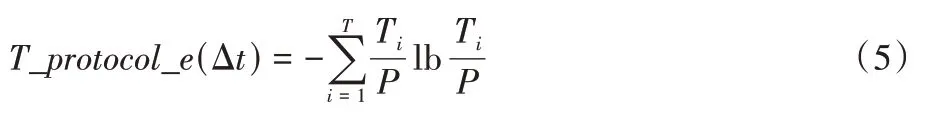

2.2 WMS-Kmeans算法
2.2.1 初始聚类中心生成过程
通常,聚类是根据数据集的样本点相似程度对其进行分类。因为数据点的属性有差别,相应的重要程度也会有所不同,所以数据点之间的距离不仅取决于相似程度,还取决于数据间的属性。Mean-Shift 算法一般采用欧几里得距离,同等对待数据的每个属性,不能反映不同属性间的重要性。针对这一问题,使用加权欧氏距离代替传统的欧氏距离。具体的改进方法如下:
在d
维欧氏空间上的n
个数据点x
(i
=1,2,…,n
)的核密度估计值如下:
h
为带宽;K
(x
)为径向对称函数,K
(x
)=C
k
(‖x
‖),C
是单位密度的归一化常数,k
为k
(x
)的简写。式(6)中的梯度如下:
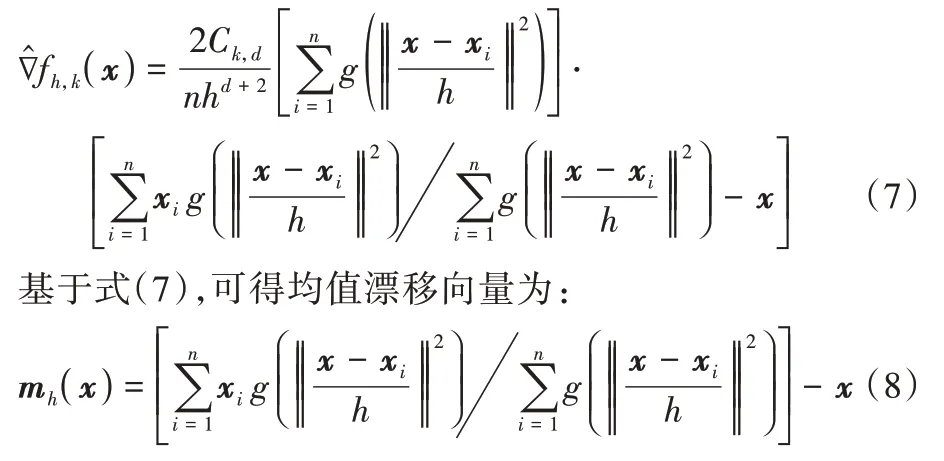
x
(i
=1,2,…,n
)在d
维欧氏距离下一个更新中心点为: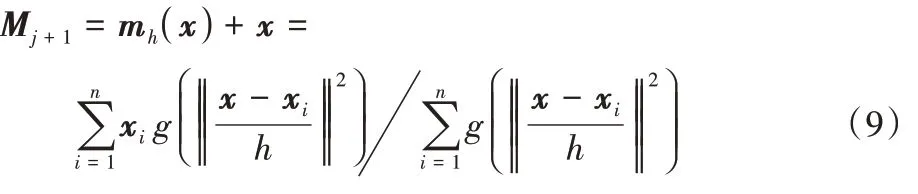
x=
(x
,x
,…,x
)和x=
(x
,x
,…,x
)间加权欧氏距离可表示为: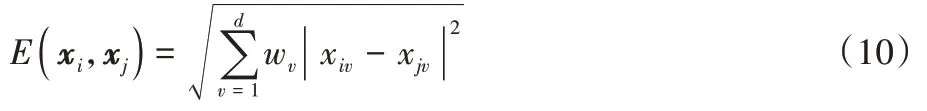
w
(v
=1,2,…,d
)表示第v
个属性权重。因此,Mean-Shift 算法在d
维欧氏距离下一个更新中心点由式(9)改为: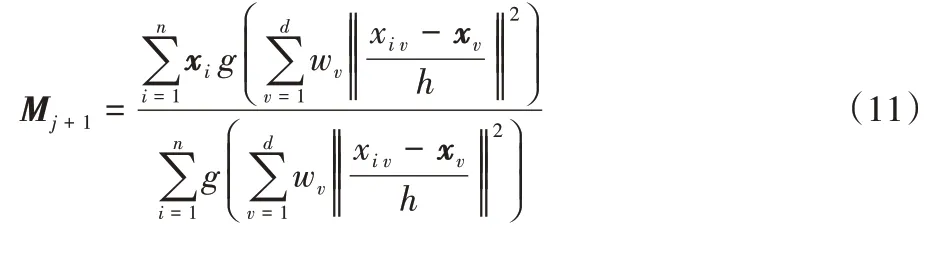
w
为第v
个属性的权重系数;g
(x
)为核函数。当发生LDoS 攻击时,网络流量的离散程度比正常网络流量离散程度更大,相应的加权系数的值越大,说明此属性有很强的重要性。本文选取平均绝对百分比误差作为欧氏距离加权系数,一定程度上反映网络数据流量的波动情况,具体表示为:
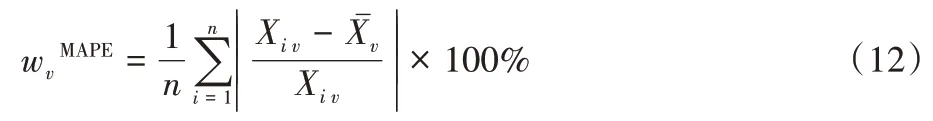
具体的初始聚类中心生成过程如下。
算法1 改进Mean-Shift 初始聚类中心选择过程。
输入 样本集Z
={z
,z
,…,z
},聚类带宽h
。输出 初始聚类中心{G
,G
,…,G
}。
K
means算法改进后的Mean-Shift 算法也是基于密度的算法,只是根据具体数据集使得均值偏移向量向概率密度最大的方向偏移得更加精准。通常情况下,好的聚类中心应该是数据分布密度最大的中心点,改进的Mean-Shift 算法生成的初始聚类中心更贴合实际数据的分布。算法具体过程如下:
选定初始聚类中心{G
,G
,…,G
}以及簇的个数k
,将数据集每个数据点根据欧氏距离划分到最近的簇,数据集样本点之间的欧氏距离越小,样本间相似程度越高。通过计算簇中所有数据点到中心点的均值重新选定簇心,WMS-K
means算法经过k
次迭代,直到簇心不再更新。最终得到k
个最佳聚类质心,使得簇内样本点相似度最高,簇间样本点相似度最低。具体算法描述如下。算法2 WMS-K
means 算法。输入 样本集Z
={z
,z
,…,z
};聚类个数k
。输出 簇划分C
={C
,C
,…,C
}。
2.3 基于WMS-Kmeans算法的LDoS攻击检测过程
本文的目的主要是在LDoS 攻击时WMS-K
means 算法通过聚类区分有无攻击。本文WMS-K
means 算法部署在SDN控制器中,SDN 控制器相当于人类大脑,具有足够的算力和储存空间。由于网络流量分析、特征选取和检测方法涉及流量都是SDN 控制器和OpenFlow 交换机之间的通信流量,所以检测方法和网络拓扑无关。具体的攻击检测过程如下:1)数据收集。此部分通过Wireshark 周期性地采集交换机中流表流量,保存完整的流表信息,将流表信息利用Python 导入数据库,为特征提取做准备。
2)特征提取。此部分通过2.1 节中的特征分析,提取出SDN 环境下LDoS 攻击流量六元组特征。使用Python 工具统计每秒内六元组特征值,并保存到数据库中。
3)攻击检测。此部分利用2.2 节中提出的WMS-K
means算法,对攻击流量六元组特征进行分类。具体检测过程如下: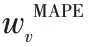

G
,G
,…,G
}。将中心点{G
,G
,G
…,G
}作为K
-Means 聚类初始聚类中心,计算所有样本点到初始聚类中心的距离:
d
,将每个样本点标记划分到最近的簇中。在每个簇中所有样本点重新计算新的聚类中心:

如果新计算出的簇心与原簇心距离变化较大,则重新迭代上述步骤,计算距离划分新的簇;如果重新计算出的簇心位置趋于稳定,可以认为聚类已达期望效果,输出本次分类结果。
3 实验与结果分析
3.1 实验环境
为了能充分展现LDoS 攻击检测的准确性,本文实验使用Mininet 和开源控制器ONOS 搭建仿真环境。虚拟交换机采用Switcher 2.9.2,OpenFlow 协议使用OpenFlow1.3 版本。虚拟机操作系统为Ubantu18.04 系统,内存为5 GB,处理器内核总数为2,在i5CPU 和8 GB RAM 的计算机上完成。实验拓扑如图5 所示,用Mininet 搭建由9 台主机和6 台OpenFlow交换机的网络并连接到Internet 上。主机h2~h9 为正常用户,h1 为攻击者。OpenFlow 交换机s1~s6 之间的链路带宽为10 Mb/s,各主机与交换机之间链路带宽为100 Mb/s,所有链路时延为10 ms。
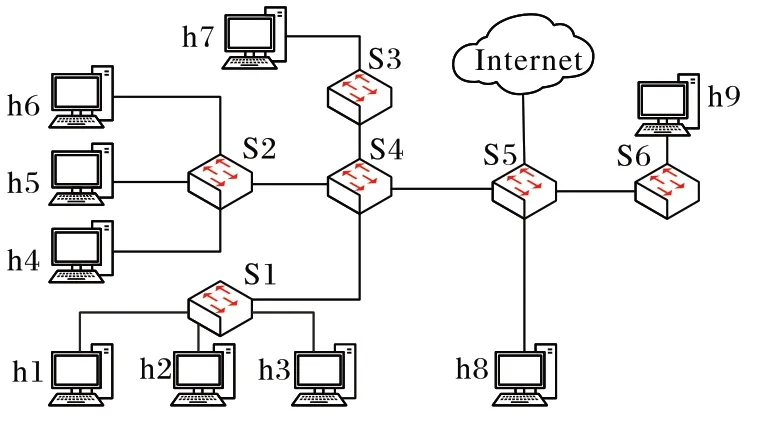
图5 实验拓扑Fig.5 Experimental topology
h1 向h9 发送UDP 攻击流量,攻击工具使用Hping3。h4、h7 分别向h8、h9 发送由D-ITG 产生的TCP 流量建立正常连接,使得在S4、S5 链路上汇集的正常流量速率接近于10 Mb/s,让UDP 流量产生更好的攻击效果。
实验分为三组,每组实验包含不同攻击参数的LDoS 攻击,具体参数如表1 所示。在搭建的网络拓扑中收集流表信息,每组实验攻击周期循环90 次,三组平均收集流表数983 202 个。
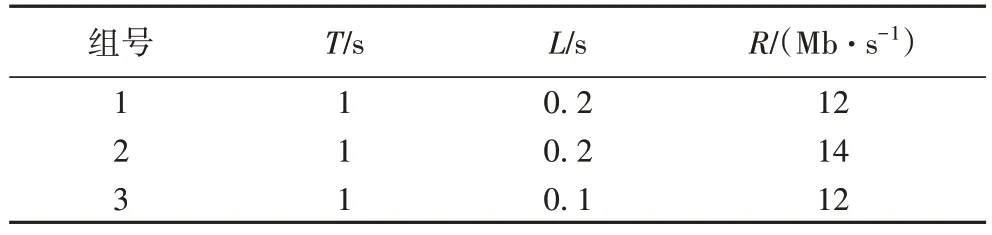
表1 LDoS攻击的参数Tab 1 Parameters of LDoS attack
3.2 实验结果分析
本文通过真正例(True Positive,TP)、真反例(True Negative,TN)、假正例(False Positive,FP)和假反例(False Negative,FN)计算检测率、误警率和漏警率来评价检测的性能。三个评价指标表示如下:
1)检测率I
(Detection Rate):表示正确预测攻击流量数量除以实际总的攻击流量数量的值。值越大说明检测LDoS攻击效果越好。
I
(False Alarm Rate):表示正常流量被预测为攻击流量数量除以实际总的正常流量数量的值。值越小说明正常流量成功预测率高。
I
(Missing Alarm Rate):表示未正确预测攻击流量数量除以实际总攻击流量数量的值。值越小说明检测LDoS 攻击效果越好。
K
means算法的LDoS攻击检测方法计算出I
、I
和I
三种攻击检测算法评定指标值。比较I
、I
和I
随着h
值的变化而产生的变化。由于h
值为核函数带宽,随着核函数带宽h
的减小,核函数值增加,数据集的概率密度增加,直接影响着最终聚类的检测结果。因此本文选取h
为0.2到0.7的值进行多次测试。实验测试结果如表2所示,计算六组不同h
值的平均检测率I
分别为99.29%、98.06%、97.01%、96.72%、94.30%、93.95%。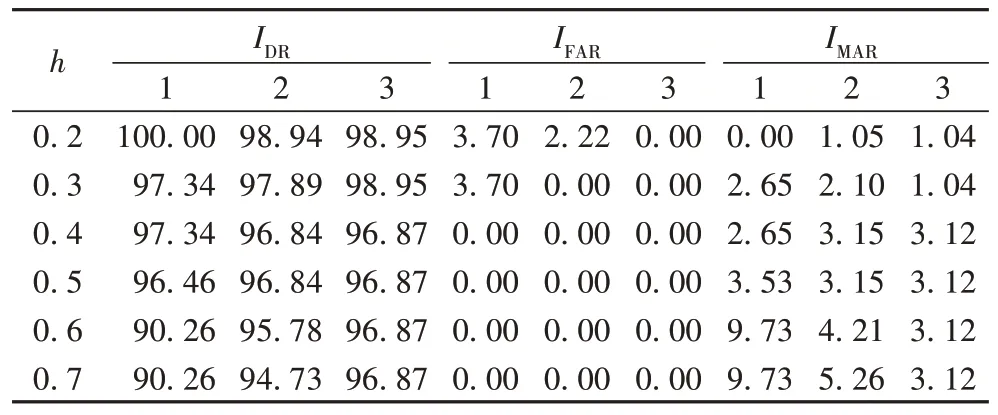
表2 三种评价指标随不同h值的变化 单位:%Tab 2 Changes of three evaluation indexes with different h values unit:%
从六组平均检测率中可以看出,平均检测率I
随着带宽h
值的增加不断减小。当带宽h
值大到一定程度,平均检测率会明显下降。当h
=0.2 时,此时平均检测率最高为99.29%,平均I
为1.97%,平均I
为0.69%。为了检验本文WMS-K
means 算法对LDoS 攻击检测的有效性,将本文方法与K
-Means 算法进行比较。用K
-Means 算法同样对上述三组LDoS 攻击数据进行检测,由于K
-Means 算法需要指定聚类个数,通过多次实验,取三组实验数据结果的最好检测值,即聚类个数k
为5 时的检测结果,记录如表3 所示。通过计算得出K
-Means 算法的平均检测率为97.71%,平均误警率为2.01%,平均漏警率FNR 为2.27%,如表4 所示,本文WMS-K
means 算法平均检测率为99.29%高于K
-Means 算法的97.71%,平均误警率和平均漏警率均低于K
-Means 算法,可以看出本文方法优于单一的K
-Means 算法。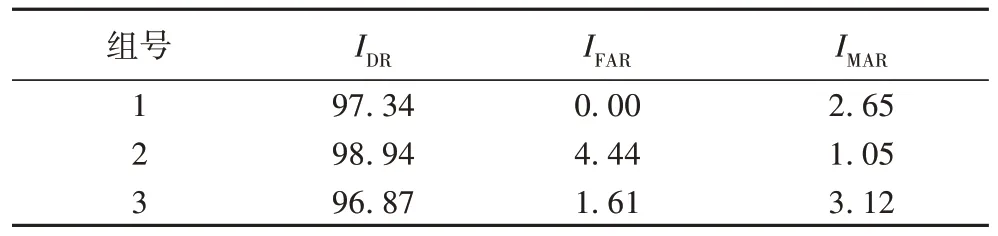
表3 K-Means算法评价指标(k=5) 单位:%Tab 3 K-Means algorithm evaluation index(k=5)unit:%

表4 本文方法与K-Means算法的对比 单位:%Tab 4 Comparative in proposed method and K-Means algorithm unit:%
表5 是本文方法与基于累加和(CUmulative SUM,CUSUM)算法、多特征自适应增强(Multiple Features-Adaptive boosting,MF-Adaboost)算法、HSMM(Hidden Semi-Markov Model)和双滑动窗口法的四种检测方法进行比较,并且使用I
、I
和I
三个指标评价算法性能。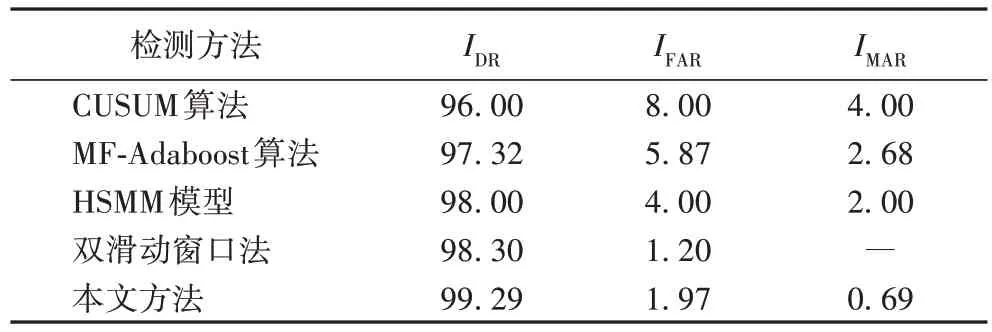
表5 不同检测方法的对比 单位:%Tab 5 Different detection methods comparison unit:%
表5 展示了五种检测方法的检测率,本文方法的检测率最优为99.29%,CUSUM 算法、MF-Adaboost 算法、HSMM 模型和双滑动窗口法四种检测方法的检测率分别为96%、97.32%、98%和98.3%。在误警率的比较中,本文所提方法的平均误警率I
为1.97%,CUSUM 算法、MF-Adaboost 算法和HSMM 模型检测方法的误警率I
分别为8%、5.87%和4%,均高于本文方法。与双滑动窗口法的1.2%相比,本文方法平均误警率略高于双滑动窗口法,但是本文方法的总体计算复杂度更低,检测率更高。在漏警率比较中,标记处双滑动窗口法无此参数,相较于其他方法,本文方法的平均漏警率I
同样最低为0.69%,CUSUM 算法、MF-Adaboost 算法和HSMM 模型检测方法的漏警率分别为4%、2.68%和2%。4 结语
LDoS 攻击因其平均速率低且具有周期性,消耗网络资源,降低网络服务质量,已经成为网络安全领域重要威胁之一。本文提出了一种SDN 环境中基于WMS-K
means 算法的LDoS 攻击检测方法,提取出LDoS 攻击流量六元组特征,用平均绝对百分比误差作为Mean-Shift 欧氏距离加权系数,将六元组特征作为改进Mean-Shift 算法的输入生成初始聚类中心,再利用K
-Means 算法进行分类,最后通过分组实验,得到本文方法评价指标值。本文方法的特色如下:1)在SDN 中利用控制器部署算法实现了LDoS 攻击的检测;2)在SDN 环境下分析LDoS 攻击流量特征,并提取出LDoS 攻击流量六个内在特性;3)根据LDoS 攻击流量特征,提出了WMS-K
means算法。最后在仿真环境下对本文方法进行验证,实验结果表明,本文方法与其他检测方法相比检测率有所提升,并且误警率和漏警率相对较低,有良好的检测性能;但是经过多次迭代执行时间相对较长。下一步的工作是优化算法,降低算法的时间复杂度。