
基于正负效用划分的高效用模式挖掘方法综述
2022-05-07 07:07李小娟程浩东
计算机应用 2022年4期
张 妮,韩 萌,王 乐,李小娟,程浩东
(北方民族大学计算机科学与工程学院,银川 750021)
0 引言
传统的高效用模式挖掘(High Utility Pattern Mining,HUPM)算法假定数据集中的项效用值均为正,但在实际生活中,事务数据库可能会包含负项。例如,某些零售店为了提高某产品销售量,或者为了刺激其他商品的消费,可能会存在亏本销售现象,这时,项目的效用值就变成了负的。
当前,关于处理仅含正项的HUPM 算法,主要分为两阶段算法与一阶段算法。两阶段算法可以分为两类:基于Apriori和基于FP-Growth(Frequent Pattern Growth)演变而来的算法。基于Apriori 的两阶段算法采用层次搜索挖掘高效用项集(High Utility Itemsets,HUIs),在挖掘阶段需要对数据库进行多次扫描,同时产生大量的候选模式。而基于FPGrowth 的两阶段算法如UP-Growth(Utility Pattern Growth)、HUP-Growth(High UP-Growth)则采用模式增长的方式进行高效用模式挖掘。相较于两阶段算法,一阶段算法可以立即计算出搜索空间中每个模式的效用,因此,一阶段算法不需要生成候选项。尽管已设计出多种算法来挖掘高效用模式,但它们都假定事务数据库是静态的,但实际上数据会随时间变化。因此,有学者提出了增量挖掘方法及数据流上的模式挖掘方法。IHUP(Incremental High Utility Pattern)是一种基于FP-Growth 的算法,无需对数据库进行多次扫描即可生成高效用模式,将所有事务插入到IHUP-tree 数据结构中执行增量的挖掘操作。但是这种方法效率不高,因为它会由于高估而生成许多候选模式。HUPID(High Utility Patterns in Incremental Databases)是一种基于树的算法,它使用称为HUPID-Tree 和TIList(Tail-node Information List)的数据结构以分治法执行挖掘操作。HUI-LIST-INS(mining High Utility Itemsets based on the utility-LIST with transaction INSertion)是一种基于列表的算法,利用EUCS(Estimated Utility Cooccurrence Structure)结构缩减搜索空间,可快速从增量数据库中找到高效用模式。LIHUP(List-based Incremental High Utility Pattern mining)和IIHUM(Indexed list based Incremental High Utility pattern Mining)仅需扫描增量数据库一次,其中,LIHUP 使用列表结构,而IIHUM 使用索引列表结构来完善现有列表结构。MEFIM(Modified version of the EFficient high-utility Itemset Mining)是一种基于树的方法,用于从动态利润数据库中查找HUIs,iMEFIM(improved version of the MEFIM)使用P-set(Pex-set)结构提高MEFIM 性能的技术。
为了正确挖掘含负项的高效用模式而不丢失某些可能的结果集,Chu 等提出HUINIV(High Utility Itemsets with Negative Item Values)-Mine 算法,它可以挖掘包含负项的HUIs,是第一个考虑带有负效用的HUPM 算法。该算法在两阶段算法的基础上扩展而来,但同时也具有两阶段模型的所有限制。Lin 等提出FHN(Faster High-utility itemset miner with Negative unit profits)算法,利用效用列表和EUCS 结构来有效地挖掘HUIs,同时利用事务加权效用(Transaction-Weighted Utilization,TWU)和剩余效用来修剪搜索空间;但该算法可能会生成不在数据库中的模式集。
在现有的高效用模式挖掘综述中,Singh 等发表了带有负效用的高效用模式挖掘方法综述,介绍了与负项相关的概念和术语,给出了考虑负效用的挖掘算法。随后,Fournier-Viger 等发表了高效用模式挖掘综述,文中以算法的提出时间为顺序,介绍了常见高效用模式挖掘方法。目前为止,相关综述或者从正效用、或者从负效用角度来阐述高效用模式挖掘方法,且现有的关于正效用模式挖掘的综述都是从常规角度分类,例如基于先验、基于投影,或者基于阶段数等角度进行分类。
不同于以上综述,本文将从一个新颖的角度总结高效用模式挖掘算法,主要工作如下:
1)以正与负为角度对高效用模式挖掘方法进行划分,内容较为全面。
2)依据数据库的动与静对正效用模式挖掘进行分类,角度新颖;同时对负效用模式挖掘以各种关键技术进行划分,例如基于先验、基于树、基于效用列表和基于数组。
3)从算法的关键技术、数据结构以及算法的优缺点等角度对HUPM 算法进行了深入的分析和总结。
1 基本概念
设I
是项的有限集合,I
={i
,i
,…,i
},其中每个项目i
都有一个正的数量q
和与之相关的利润p
(i
)。事务数据库D
={T
,T
,…,T
}由一组事务组成,其中每条事务包含一组项i
∈I
,并与唯一的事务标识符T
相关联。表1 中列出了一个示例数据库,事务包含项及其数量,即内部效用。表2 列出了每一项的利润(又称为外部效用,可为负),一个项目的效用是数量和利润的乘积,即内部效用和外部效用的乘积。挖掘高效用模式的问题可以描述为找到效用值大于或等于用户定义的最小效用阈值(minimum utility,minutil)的所有项集。
表1 事务数据库Tab 1 Transaction database
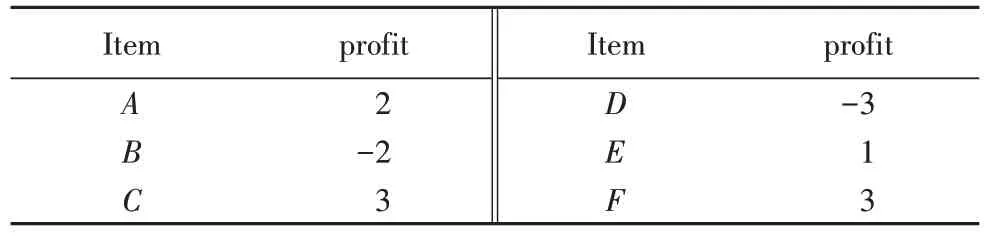
表2 项目效用值Tab 2 Item utility value
定义1
项目的效用。事务T
中项目z
的效用值如式(1)所示:
A
在事务T
中的效用为:U
(A
,T
)=p
(A
)*q
(A
,T
)=2 × 1=2;项目B
在事务T
中 的效用为:U
(B
,T
)=p
(B
)*q
(B
,T
)=-2 × 2=-4。定义2
项集在事务中的效用。如果项集X
∈T
,则项集X
在事务T
中的效用值为:
AB
}在T
中的效用为:U
(AB
,T
)=U
(A
,T
)+U
(B
,T
)=2×1+(-2)×2=2+(-4)=-2。定义3
项集的效用。项集X
的效用如式(3)所示,其中g
(X
)是包含X
的事务集:
AB
}出现在事务T
和T
中,则项集{AB
}的效用为:U
(AB
,T
)+U
(AB
,T
)=(-2) +(-2)=-4。同理,项集{AC
}的效用为:U
(AC
,T
)+U
(AC
,T
)=11+5=16。定义4
事务效用(Transaction Utility,TU)。事务T
的事务效用定义为:
T
的事务效用为TU
(T
)=U
(A
,T
)+U
(C
,T
)+U
(E
,T
)+U
(F
,T
)=2+3+2+9=16;事务T
的事务效用为TU
(T
)=U
(A
,T
)+U
(B
,T
)+U
(C
,T
)+U
(D
,T
)=2+(-4)+9+(-12)=-5。定义5
TWU。项集X
的TWU 定义为: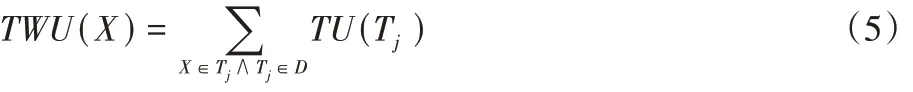
A
的事务加权效用为TWU
(A
)=TU
(T
)+TU
(T
)+TU
(T
)=(-5)+4+16=15,项目B
的事务加权效用为TWU
(B
)=TU
(T
)+TU
(T
)+TU
(T
)=(-5)+4+5=4。定义6
高效用项集。如果U
(X
) ≥minutil
,minutil
是用户设置的最小效用阈值,则项目集X
是高效用模式;否则,X
是低效用模式。在实际生活中,事务数据库中的项是可以带有负效用值的,含负项的高效用模式挖掘问题是要在数据库中发现外部效用值可能为正或为负的所有高效用项集。为了不丢失候选项集,用于挖掘正效用的挖掘算法不能直接应用于挖掘带有负效用的HUIs。为了解决该问题,重新定义了事务效用和事务加权效用,如下所述:
定义7
重新定义的事务效用(Redefined TU,RTU)。事务T
的重新定义的事务效用被定义为T
中具有正外部效用的项的效用值之和,即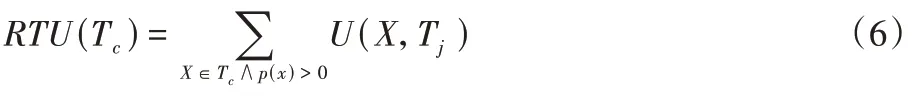
T
的重新定义的事务效用RTU
(T
)=U
(A
,T
)+U
(C
,T
)=2+9=11,其中不包括项目B
和D
的效用值,因为它们的外部效用值为负。定义8
重新定义的事务加权效用(Redefined TWU,RTWU)。项目集X
的重新定义的事务加权效用定义为: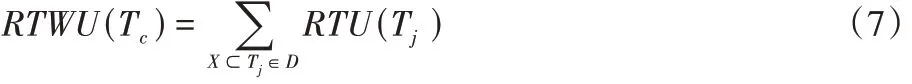
RTWU
(A
)=RTU
(T
)+RTU
(T
)+RTU
(T
)=11+10+16=37。2 带有正效用的模式挖掘方法
挖掘高效用模式,即找到效用值不小于用户定义的阈值的所有模式,是效用挖掘中一项至关重要的任务,目前已取得了大量的研究成果。本文将选取其中一些最新的、具有代表性的算法进行分析总结。
2.1 静态模式挖掘
静态高效用模式挖掘算法依据是否产生候选模式可将其分为两阶段算法和一阶段算法。它们的主要区别为:前者会生成大量候选模式,由于候选模式并不一定都是高效用模式,所以算法必须再次扫描数据集计算候选模式的效用值,才能断定其是否为HUIs;而一阶段算法则不会产生候选模式,在算法挖掘的过程中就可以得到全部模式的效用值。
2.1.1 两阶段算法
Two-Phase算法分两个阶段发现高效用模式,它首先找到候选HUIs,即TWU 值不小于minutil
的项集;然后再次扫描数据库以计算每个候选对象的确切效用,并选择效用值大于或等于minutil
的项目集。尽管Two-Phase 可以在事务数据库中找到完整的HUIs,但在挖掘过程中必须多次扫描数据库且产生大量候选项集,导致出现内存占用过多和时间运行过长等问题。为了解决上述问题,Tseng 等提出了UP-Growth 算法,算法将高效用项集的信息保存在名为UP-Tree(Utility Patterns Tree)的特殊数据结构中,仅需扫描数据库两次就可以从UP-Tree 生成潜在的高效用项集。算法还使用以下策略来减小搜索空间:丢弃全局无用项目;丢弃全局节点效用;丢弃局部无用项目和减少局部节点效用。随后,提出了一种名为IUPG(Improved UP-Growth)的算法,这是UP-Growth的改进版本,它采用了两种新颖的策略,即丢弃局部无用的项及其估计的节点效用和减少局部UP-Tree 的节点效用。
随 后PB(Projection-Based indexing approach for mining high utility itemsets)算法被提出,该算法利用索引机制来加速挖掘过程,同时降低挖掘过程中所需要的内存。索引机制是模仿传统的投影算法,达到投影以挖掘子数据库的目的,可以快速查找数据库中各项集的事务,不会为每个项集复制原始数据库来挖掘HUIs;相反,它们是直接通过索引结构提取信息的。因此,所消耗的内存比直接复制原始数据库来进行挖掘所需的内存要少得多。
2.1.2 一阶段算法
两阶段算法的性能良好,但它们都有一个局限:必须进行两次数据库扫描,才能判断候选模式是否为HUIs。为了解决这一局限性问题,有学者提出了一阶段算法,一阶段算法和两阶段算法的优越之处在于时间性能的大幅提升。
HUI-Miner(High Utility Itemsets Miner)算法通过使用一种名为效用列表(Utility-list)的新颖结构引入了一阶段算法的概念,此结构存储了项集的效用,以此来减小搜索空间所需的信息,而无需重复扫描数据库。HUI-Miner 算法首先扫描数据库为每个项目构造一个效用列表;然后,通过将子集的效用列表合并来递归地构建较大项集的效用列表,而无需再次扫描数据库。HUI-Miner 算法是一种完整的算法,因为它可以使用效用列表结构列举所有高效用项集及其效用值,但缺点为可能会生成不存在数据库中的项集。
随后,Fournier-Viger 等提出了FHM(Fast High-utility Miner)算法,引入了EUCS 结构以及相应的估计效用共现修剪技术,以减少需要执行的连接操作的数量,提高挖掘HUIs的速度。
Zida 等提出了EFIM(EFficient high-utility Itemset Mining)算法,算法依靠两个名为子树效用和局部效用的上限来有效地修剪搜索空间。此外,为了减少数据库扫描的成本,EFIM 还提出了高效数据库投影和高效事务合并技术。
基于效用列表的算法主要局限在于:创建和维护效用列表非常耗时,并且会占用大量内存,原因是建立了大量效用列表,并且列表相交/合并操作成本很高。为了解决此问题,ULB-Miner(Utility-List Buffer for high utility itemset Miner)算法被提出,通过应用一种称为效用列表缓冲区的改进的效用列表结构来减少内存消耗并加快联接操作,在缓冲区中记录了每个项目在数据中的索引位置,因此可以快速查找项目信息。
2.2 动态模式挖掘
高效用模式挖掘算法在静态数据库中表现优异,但是现实生活中大部分数据库都是处于动态增长的状态。在动态数据库中,数据库更新一次,都必须要重新进行一次高效用模式挖掘。但是,重新进行高效用模式挖掘并没有用到上次在数据库中挖掘出来的有效信息,更为致命的是,若一次插入少量数据就需要重新对整个数据库扫描,成本非常昂贵并且效率极低。为了克服这个问题,在动态数据库中的高效用模式挖掘算法IHUP 被提出,该算法可重用其先前挖掘的结果,从而在更新数据库时提高发现高效用项集的速度。
2.2.1 基于增量数据库的模式挖掘
为了解决在处理动态数据库时所面对的没有利用之前挖掘出的有效信息的问题,提出了增量高效用模式挖掘算法。
Ahmed 等提出了IHUP 算法,这是第一个在高效用模式挖掘中考虑增量数据集的算法,当更新数据库或更改最小效用阈值时,算法将重用先前的数据结构并开始在新增数据中挖掘HUIs。算法包括三种新颖的树结构来有效执行增量挖掘:1)IHUP 词典树,按照项目的词典序列排列,可以获得增量数据而不必重组;2)IHUP 事务频率树,依据项目的事务频率(降序)排列项目来得到紧凑的大小;3)IHUP 事务加权效用树,按项目的TWU 值降序排序。尽管IHUP 在查找高事务加权项集(High TWU Itemsets,HTWUI)时并未生成任何候选,并且比两阶段具有更好的性能,但它在第一阶段仍会产生过多的HTWUI。Lin 等提出了FUP-HUI(Fast-UPdate HUI mining)算法,使用FUP(Fast-UPdate)概念和两阶段模型来更新增量HUIs 集。但是,使用FUP-HUI 进行增量模式挖掘是一个很耗时的过程,因为算法使用了逐级挖掘方式。为了克服FUP-HUI 算法的局限性,Lin 等提出了一种改进的预大型概念和算法PRE-HUI(based on PRE-large concept HUI mining),基于预大型概念的属性保留预大型事务加权效用项目集以避免数据库重新扫描,直到所插入事务的累积总效用达到安全范围为止。由于FUP-HUI 和PRE-HUI 算法使用两阶段模型,因此仍需要执行多次数据库扫描,此外,它们还需要以基于模式增长的方法寻找HTWUI。Yun 等提出了HUPID 算法,该算法使用PID-Tree 扫描构建一个树结构,并使用一种名为TIList 的新型数据结构来重构方法,以处理增量数据。
采用两阶段的算法都面临两个问题:1)生成大量候选对象;2)重复数据库扫描,导致可伸缩性和效率瓶颈。
后来的增量算法采用一阶段,Lin 等提出了一种基于FHM 的增量算法HUI-LIST-INS 来维护和更新已建立的效用列表结构,通过事务插入来挖掘HUIs。基于效用列表结构,原始数据库中的相关信息可以被压缩,所提出的算法还应用EUCS,从而加快了计算速度。随后,Fournier-Viger 等设计了EIHI(Efficient Incremental High-utility Itemset miner)算法,EIHI 是一种高效的、基于列表的维护算法,它使用名为HUItrie 的结构来插入和维护关于HUIs 的信息,利用了HUILIST-INS 中没有用到的几个重要属性,在更新效用的过程中对搜索空间进行了修剪。EIHI 中集成的新的剪枝条件旨在减少执行时间,而不是减少内存使用。尽管这些方法更适合从动态环境中挖掘高效用模式,但它们在挖掘过程中会生成候选模式,并且需要特别的过程来识别是否为高效用模式,因为它们应用了高估概念。换句话说,即使已经提出了增量效用模式挖掘方法,无论采用树结构还是列表结构,以前的方法都需要至少两次扫描以进行增量高效用模式挖掘。但是,具有多次扫描的方法实际上不适用于流环境。为了解决这个问题,Yun 等提出了LIHUP 算法,该算法可应用基于列表的数据结构,在不生成候选对象的情况下,通过一次数据库扫描就可以从增量数据库中挖掘HUIs。该算法仅扫描一次新添加的事务,将其反映到先前构造的结构中,并通过重组过程优化更新的结构。EIHI、HUI-LIST-INS 和LIHUP 仍然存在效率瓶颈,其根本原因是它们都对效用列表使用了大量低效的联接操作结构。为了解决这个问题,通过改进dHUP(direct discovery of High Utility Patterns)算法提出了一种新的增量算法IdHUP(Improved dHUP),该算法通过改进基于相关性的修剪和基于上限的修剪来减小搜索空间,并使用哈希表来快速合并事务,从而适应了一阶段;提出了两种修剪策略:基于缺席的修剪和基于遗留的修剪,这些策略专门用于增量高效用模式挖掘。Yun 等提出了基于索引列表的增量高效用模式挖掘IIHUM 算法,通过防止候选模式的提取,提高了增量高效用模式挖掘的性能,此外,还提出了一种重组技术,以便在索引列表结构中更有效地处理增量数据。DHUPL(Damped High Utility Pattern mining based List)用于从增量非二进制数据库中发现高效用模式,通过扫描增量数据库一次并在基于列表的数据结构中管理它们来有效地执行挖掘操作,而无需生成候选模式。DHUPL还使用衰减因子根据每个数据的到达时间来处理数据的重要性,因此,通过增加最近输入数据的重要性和降低旧数据的重要性而获得了优异的结果。
2.2.2 基于数据流的模式挖掘
当今社会是信息技术快速发展的社会,数据规格也在急速增长,而目前所面临的主要挑战是如何在海量的数据中获得潜在的、有价值的信息。因此,在数据流上挖掘高效用模式已经成为了数据挖掘中的一个热点和难点问题。
数据流的特点决定了之前讨论的HUPM 算法无法直接用在数据流上。为了能够从数据流中获得数据,通常利用窗口技术处理数据流,窗口技术应用采样的方法,把数据流划分成若干部分,一般来说窗口技术有三种常见模型:界标窗口模型、时间衰减窗口模型和滑动窗口模型。第一种界标窗口模型不适用于数据流挖掘;时间衰减窗口模型是在界标窗口模型的基础上给数据流中的数据项设置了不同的权值,该模型比界标窗口模型更常用;滑动窗口模型不同于上述两种模型,它的窗口大小是固定的,是在数据流上挖掘高效用模式时使用最多的模型。
2008 年,Chu 等首次提出数据流上的高效用模式挖掘算法THUI(Temporal HUI)-Mine,该算法使用滑动窗口模型,进行挖掘时,先把窗口分成几个区,然后从各个分区中获得加权高效用项集,采用与先验算法相似的候选项产生策略,找到所有的候选项集,然后再进行一次滑动窗口数据的扫描,推算这些候选项集在窗口中的效用,以此来证实这些候选项集是否是高效用模式。Ahmed 等提出的算法HUPMS(HUPM over Stream data),是一种基于滑动窗口模型的算法,采用HUS-tree(High Utility Stream tree)来保存滑动窗口中的项集和高估效用值,并且采用模式增长的方式来剪枝。
以上所讨论的算法都是两阶段算法,两阶段算法最大缺点是在第一阶段会产生许多候选项集,还要在第二阶段重新校验候选项集的效用,时间性能较差。
王乐提出了一种一阶段算法HUM-UT(High Utility pattern Mining based on Utility Tree),算法采用滑动窗口模型,将数据项的TWU 视为估算效用值。窗口读入新批次数据后,为这批数据建造全局效用树,当窗口数据填充完成的时候,为窗口中的数据构建全局头表,最后利用全局头表和全局效用树进行高效用模式挖掘。当数据已经把窗口填满,并且到达了一批新的数据的时候,窗口可以自动“滑动”,也就是移除在这个窗口中停留时间最长的一批数据,然后把新到达的一批数据放到刚移除的一批数据的位置,同时要更新全局效用树。该算法的缺点为全局头表包含了和当前需要处理数据无关的冗余数据项;在算法挖掘的时候,对全局效用树中的低效用数据项执行了没有用的操作,这样做会大大降低算法的运行效率。随后,郭世明等在2018 年提出了HUISW(HUI mining over a Siding Window)算法,该算法将数据信息保存在树结构HUIL-Tree(HUI Tree which arranges items according to Lexicographic order)上,将数据的效用信息保存在全局效用数据库上,通过利用HUIL-Tree 的信息,再利用全局效用数据库就能够进行挖掘。该算法存在的问题是数据及其效用信息必须重复存储在全局效用数据库和条件效用数据库中。受静态数据库上的Top-k
高效用模式挖掘算法的启发,有学者把问题延伸到数据流上,提出了T-HUDS(Top-k
High Utility itemset mining over Data Streams)算法,该算法采用了滑动窗口模型,利用HUDS-Tree(High Utility Data Stream Tree)来维护事务和效用信息,利用上一窗口中的Top-k
高效用项集初始化新窗口的效用下限值,然后再进行Top-k
高效用模式挖掘。Tsai提出了一种基于加权滑动窗口模型的、单遍扫描算法HUI_W(HUI based on the weighted sliding Windows),该算法利用了重复使用存储信息的优势,可以有效地发现数据流中的所有高效用项集。Jaysawal 等提出了SOHUPDS(Single-pass One-phase algorithm for mining High Utility Patterns over a Data Stream),该算法利用投影技术,并且使用了滑动窗口模型,以此在数据流上挖掘高效用模式。此外,提出了一个数据结构IUDataListSW,它存储了当前滑动窗口中各项的效用和上限值,保存事务中每个项目的位置,这样可以快速地获得项目的原始数据库;还提出了一种更新策略,利用从先前滑动窗口中挖掘的HUIs 来更新当前滑动窗口中的高效用项集。2.2.3 其他
尽管已设计出多种算法来列举所有HUIs,但重要的问题是它们假定商品的效用(单位利润)是恒定的,但是这种假设在现实生活中是不合理的。例如,由于供应成本和促销活动的波动,零售商店中商品的单位利润通常会随时间变化,忽略这一重要特征使得当前的HUIs 挖掘算法无法应用于更多现实应用中。
为了解决当前HUPM 算法的这一关键限制,学者们研究了在具有动态单位利润的数据库中挖掘HUIs 的新问题,提出了一种新颖的MEFIM算法,算法依赖于一种新颖的紧凑型数据库格式来有效地发现所有模式;还提出了MEFIM算法的改进版本,称为iMEFIM,算法采用一种称为P-
set 的结构,以减少事务扫描的次数并加快挖掘过程。为了在动态利润数据库中挖掘HUIs,MEFIM 中对EFIM进行了两个重要修改:第一个修改是将事务数据库转换为紧凑格式;第二个修改是同时考虑项目的动态单位利润。2.3 小结
正效用模式挖掘算法中,因不同算法采用的数据结构和关键技术不同,算法的特征和性能也不同。例如基于两阶段模型的算法由于生成了过多的候选项并多次扫描数据库,导致算法效率较低;而一阶段算法因其不生成候选项的特点,解决了两阶段算法的局限性,算法性能大幅提升。在表3 中对正效用模式挖掘算法以多种角度进行了分析,并给出了算法的优缺点。

表3 正效用模式挖掘算法的对比Tab 3 Comparison of positive utility pattern mining algorithms
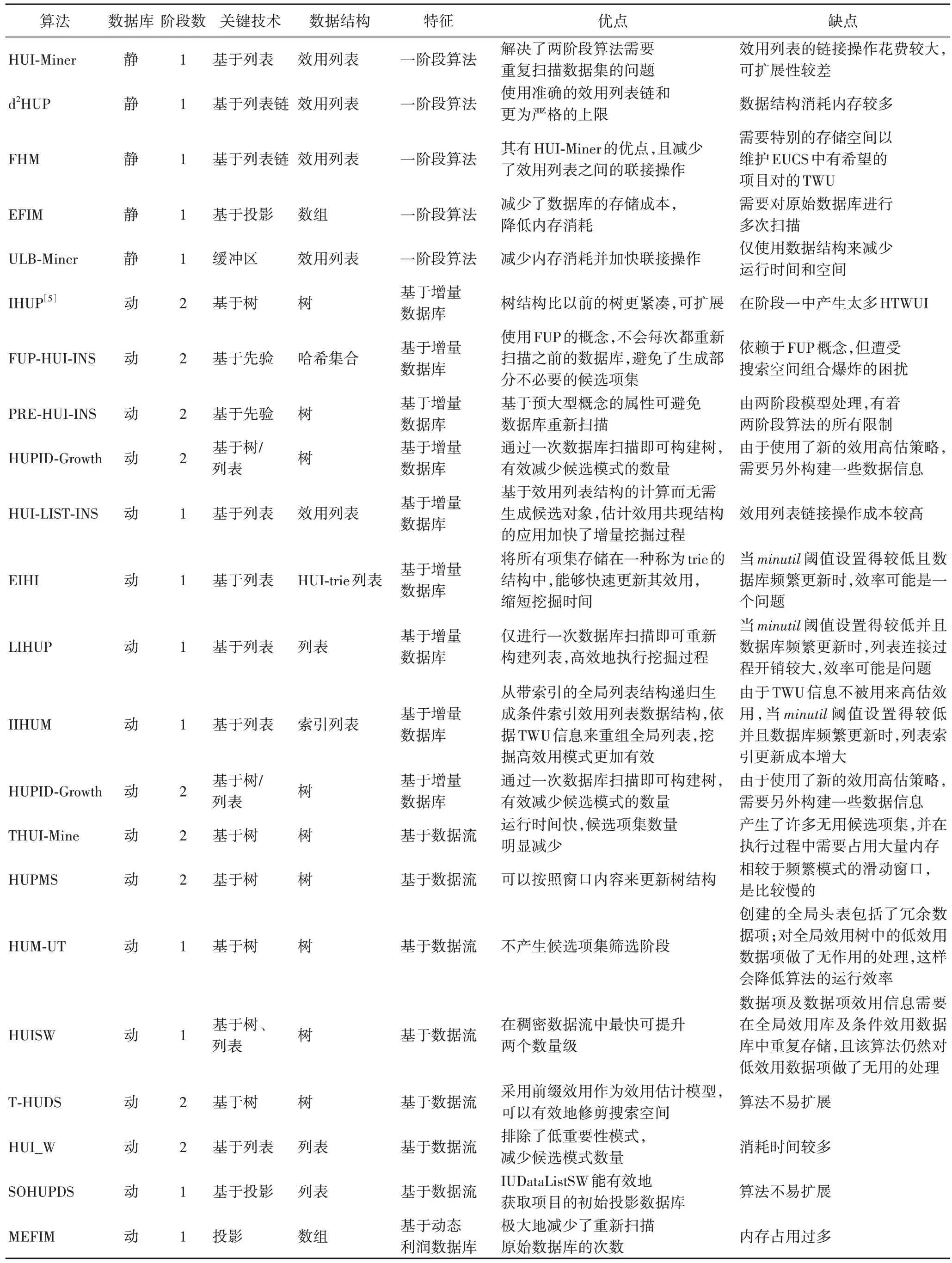
续表
静态HUPM 算法不能处理动态数据库,即当有事务插入时,静态HUPM 算法不能利用先前挖掘出的结果而导致效率低下,针对此缺陷学者们提出了动态数据库中的HUPM 算法。在动态HUPM 算法中,基于增量的模式挖掘算法可在插入增量数据时有效利用先前挖掘出的结果;数据流模式挖掘算法中的滑动窗口不仅考虑事务的增加,还同时考虑了事务删除的情况。图1 中列出了关于正效用模式挖掘算法下的各类方法总结,包括提出背景,解决问题和优缺点等方面。
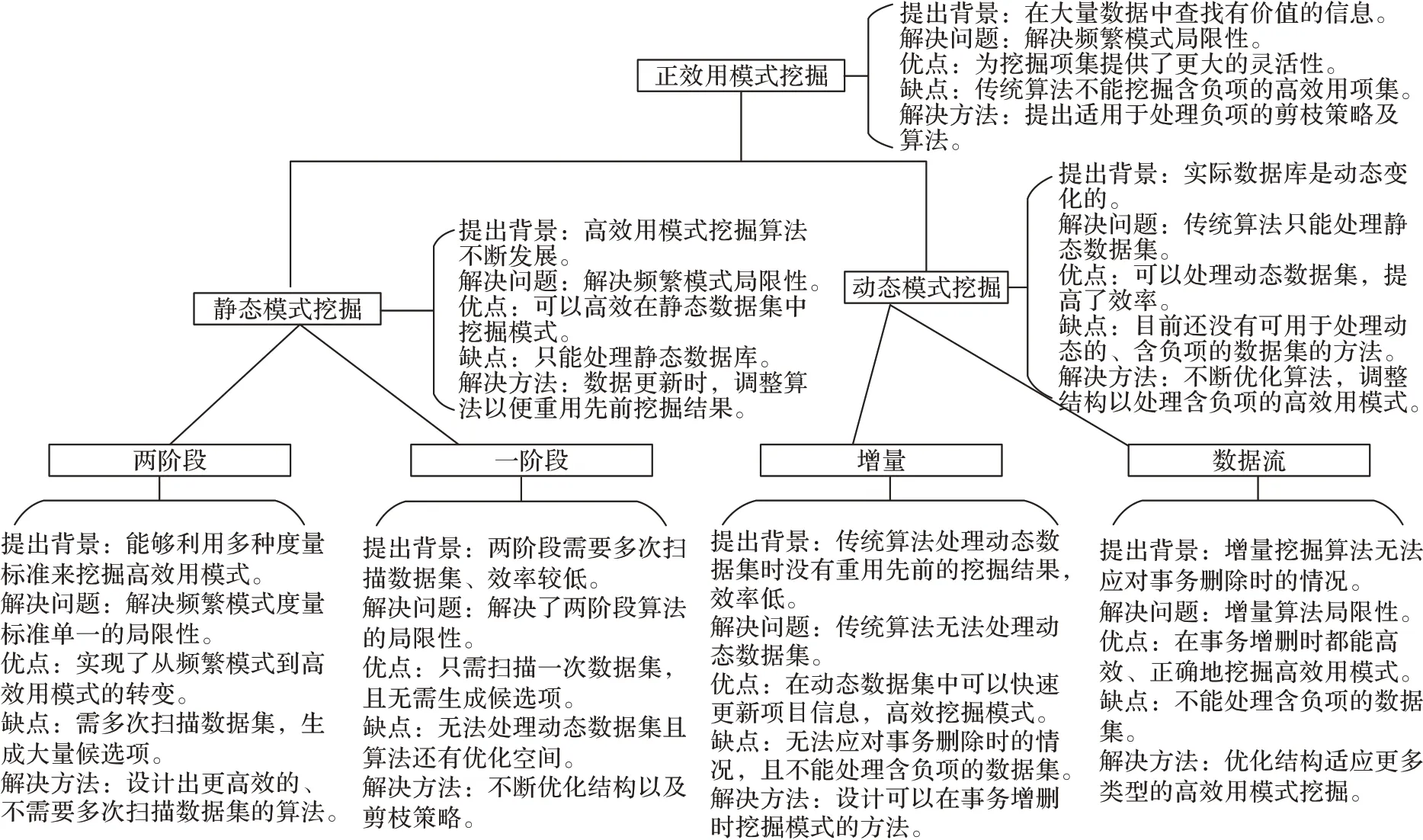
图1 正效用模式挖掘各类方法的优缺点Fig.1 Advantages and disadvantages of different methods with positive utility pattern mining
3 带有负效用的模式挖掘方法
传统高效用模式挖掘算法假定所有项的效用值均为正,但是在实际应用中,数据库通常包含带有负效用值的项。例如,在零售商店的交易数据库中,通常会发现单位利润为负的项目(即外部效用为负),原因是某些商品经常在交易中亏本出售以吸引顾客。经学者研究证明,如果数据库中出现带有负效用值的项,则传统的HUPM 算法会发现一组不完整的高效用项集,具体原因如下:当处理带有效用值的项目时,诸如TWU 之类的上限不再是项目效用的上限,因此,高效用项集可能会被错误地修剪。为了解决这一问题,含负项的HUPM 算法被提出。由于此类算法能处理更多贴近实际应用中的数据库,随后在各种高效用扩展模式中也提出了可以处理负项的挖掘方法。本章将以各种关键技术对含负项的高效用模式挖掘方法进行划分。
3.1 基于先验
第一个考虑负效用的HUPM算法为Chu等提出的HUINIV-Mine 算法,在算法中提出了基于RTWU 的高估和修剪策略。但是,它基于两阶段模型,需要进行多次数据集扫描才能找到HUIs,并生成过多的候选对象。
Lan 等提出了TS-HOUN(Three Scan-High On-shelf Utility itemsets with Negative profit values)算法,是第一个同时考虑负效用和货架时间段的HUPM 算法。使用货架时间段,可以准确地评估时间数据集中项集的实际效用值。大多数算法都认为商品具有相同的货架时间,即所有商品都在同一时间段内出售,但在现实生活中,某些商品仅在较短的时间段内(例如夏季)出售。TS-HOUN 扫描数据集三次,使用基于TWU 修剪策略来修剪搜索空间,是两阶段方法的扩展,因此,它需要大量的运行时间和内存空间才能完成挖掘任务并生成大量候选对象。算法在密集或大型数据集上表现不佳,因它在每个时间段分别挖掘项集,然后对挖掘出的项集执行昂贵的合并操作,可能必须在不同的时期内多次生成相同的项集,有着基于两阶段模型算法的所有限制。
3.2 基于树
Subramanian 等提出了一种不生成候选项的基于树的挖掘方法UP-GNIV(Utility Pattern-Growth approach for Negative Item Values)来挖掘含有负项的HUIs,它是UPGrowth 算法的负效用版本。算法提出了去除负项效用和PNI(Pruning Negative Itemsets)两种策略,并使用前者计算TU。
Xu 等提出了算法HUSP-NIV(High Utility Sequential Patterns with Negative Item Values),它是第一个挖掘包含负项的高效用序列模式的算法,使用了词典量化序列树,它的工作方式如下:1)使用词典顺序树(Lexicographic Quantitative Sequence tree,LQS-tree)提取完整的高效用序列集,并使用I-级联和S-级联机制生成新的级联序列;2)使用三种修剪方法来减小LQS-tree 中的搜索空间;3)遍历LQStree 并输出所有高效用序列模式。
Singh 等提出了一种利用模式生长树挖掘负效用HUIs的算法EHIN(Efficient High-utility Itemsets mining with Negative utility),通过合并相同的事务来降低数据集扫描成本,使用基于投影数据集的事务合并技术进一步降低数据集扫描成本,是第一项遵循基于模式增长的方法来挖掘含有负项HUIs 的工作。
3.3 基于效用列表
FHN算法引入了几种应对负项的策略,是FHM 算法的扩展,使用效用列表和EUCS 结构来有效地挖掘HUIs,利用TWU 和剩余效用来修剪搜索空间。FHN 在单个阶段中挖掘HUIs,虽然避免了候选项集的生成,但是可能会生成数据集中没有的候选项。
GHUM(Generalized High Utility Mining)提出了一种简化的、基于效用列表的数据结构来存储项集的信息,它不使用单独的效用列表来存储项目,按照项目的支持度升序对负项排序,从而有效地生成候选项。GHUM 采用并修改了现有的修剪策略U-Prune 和LA-Prune;同时,基于效用列表的算法需要执行连接操作来评估候选项集,因此,它提出了一种新的剪枝策略N-Prune(Novel Pruning strategy),由此显著减少了候选项总数;最后,提出了一种基于属性的反单调剪枝策略A-Prune(Anti-monotonic property based Pruning strategy)。
Fournier-Viger 等提出了FOSHU(Faster On-Shelf High Utility itemset mining)算法,用于从货架数据集中挖掘包含负项的HUIs,它是FHN 算法的扩展,利用效用列表结构来存储项目信息。FOSHU 在不生成候选对象的情况下在一个阶段中挖掘项集,并且同时挖掘所有时间段,而不是分别挖掘每个时间段;避免了对每个时间段中发现的项集进行昂贵的合并操作。
吕存伟等提出了含负项的高效用序列模式挖掘(Efficiently mining High Utility Sequential pattern with Negative unit profits,EHUSN)算法,采用效用列表快速构建非候选序列,进而提升算法的时间空间效率,存在的问题为算法的剪枝效果受阈值大小的影响。
陈丽娟等提出了EHINM(Efficient High utility Itemsets with Negative items values Mining)算法,在算法中介绍了一种改良的效用列表结构,并用来存储效用信息。所提出的效用列表结构是一种三元组结构,可以缩小存储空间,同时也可以依据结构中保存的信息来缩小搜索空间。
THN(Top-k
High utility itemsets with Negative items)是第一种在Top-k
模式挖掘中考虑负项的算法,算法提出了一种自动提升minutil
的策略,同时使用事务合并和数据集投影技术和减少扫描数据集成本,并使用重新定义的子树效用值和重新定义的本地效用值来修剪搜索空间。3.4 基于数组
先前讨论的HUINIV-Mine 和FHN 算法挖掘出的规则包括非常多的微小项集,EHNL(Efficient High utility itemsets mining with Negative utility and Length constraints)通过在包含负效用值的项集中结合长度约束的概念克服了这个缺陷。算法使用模式增长方法来挖掘包含负项的HUIs,仅考虑那些出现在数据集中的候选项集。算法引入了最小长度约束,以删除大量细小的项目集,还使用最大长度约束来限制太长的项目集。为了降低数据集扫描成本,还利用数据集投影和事务合并技术。为了提高效率,算法利用子树修剪策略来减小搜索空间,但是面临的主要问题是如何将子树修剪策略、长度约束与负效用项集挖掘结合在一起。为了解决这些问题,算法根据事务的效用值以非递增顺序对事务中的项目进行排序,并借助偏移指针将负项目保留在已排序项目的末尾;另一个问题是如何有效地计算项目集的效用,为了解决这个问题,算法使用基于数组的效用计数技术来计算线性时间和可忽略的存储空间中的效用值。
3.5 小结
将带有负效用的模式挖掘方法以各种关键技术为角度进行分类,包括基于先验、基于树、基于列表和基于数组。其中基于先验的HUPM 算法需要多次扫描数据集导致时空性能较低;基于树的HUPM 算法使用结构较为紧凑,但在处理树结构时会耗费较多的时间并占用更多内存;基于列表的HUPM 算法结构易为实现,缺点为列表合并时的昂贵操作依旧会导致算法效率变低;基于数组的HUPM 算法可以处理大量数据,但在插入、删除等情况下表现不佳,不适合动态存储。表4 对带有负效用的高效用模式挖掘算法进行了分析,其中各类方法的总结如图2 所示。
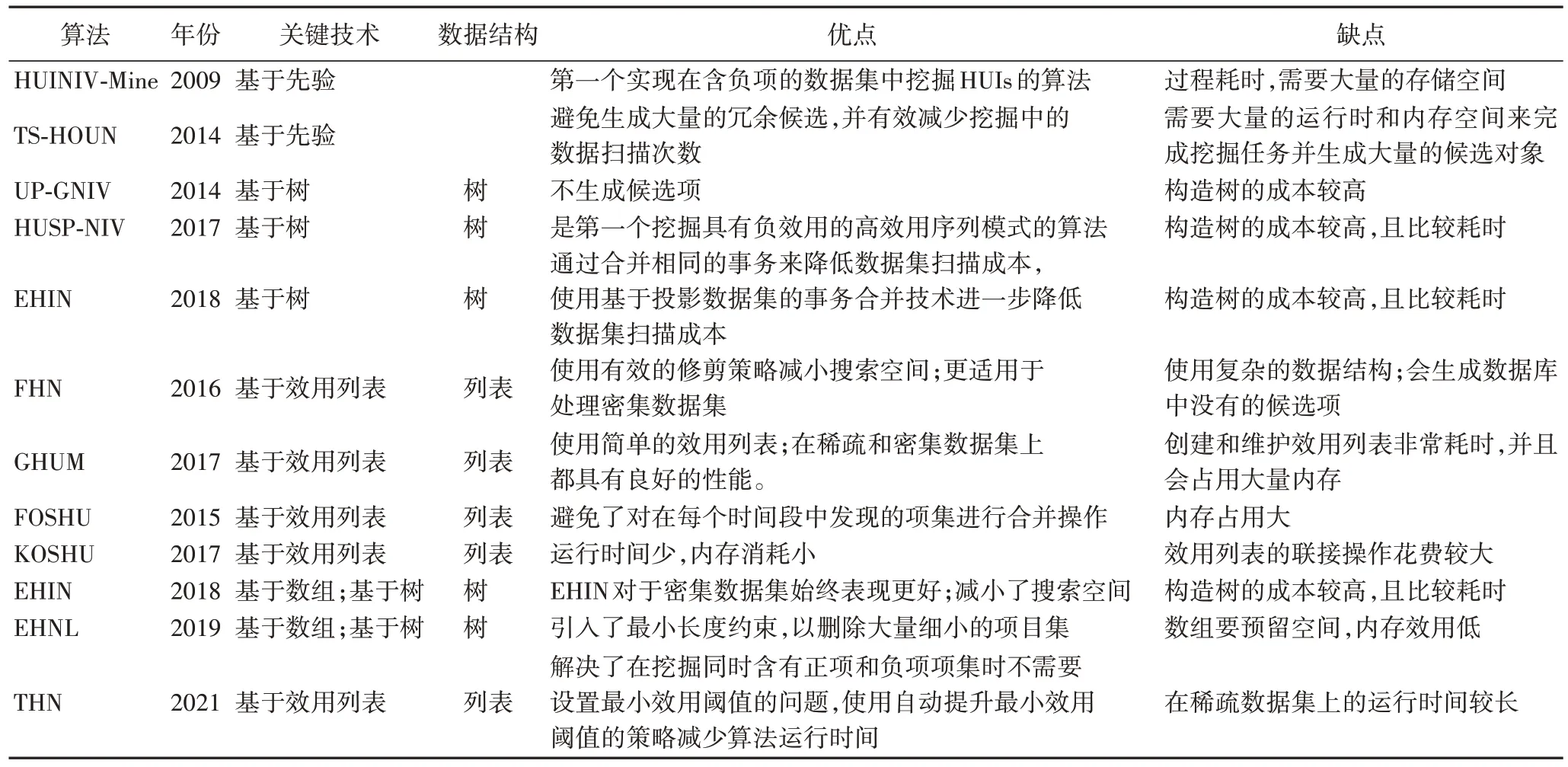
表4 含负项的模式挖掘算法对比Tab 4 Comparison of pattern mining algorithms with negative items
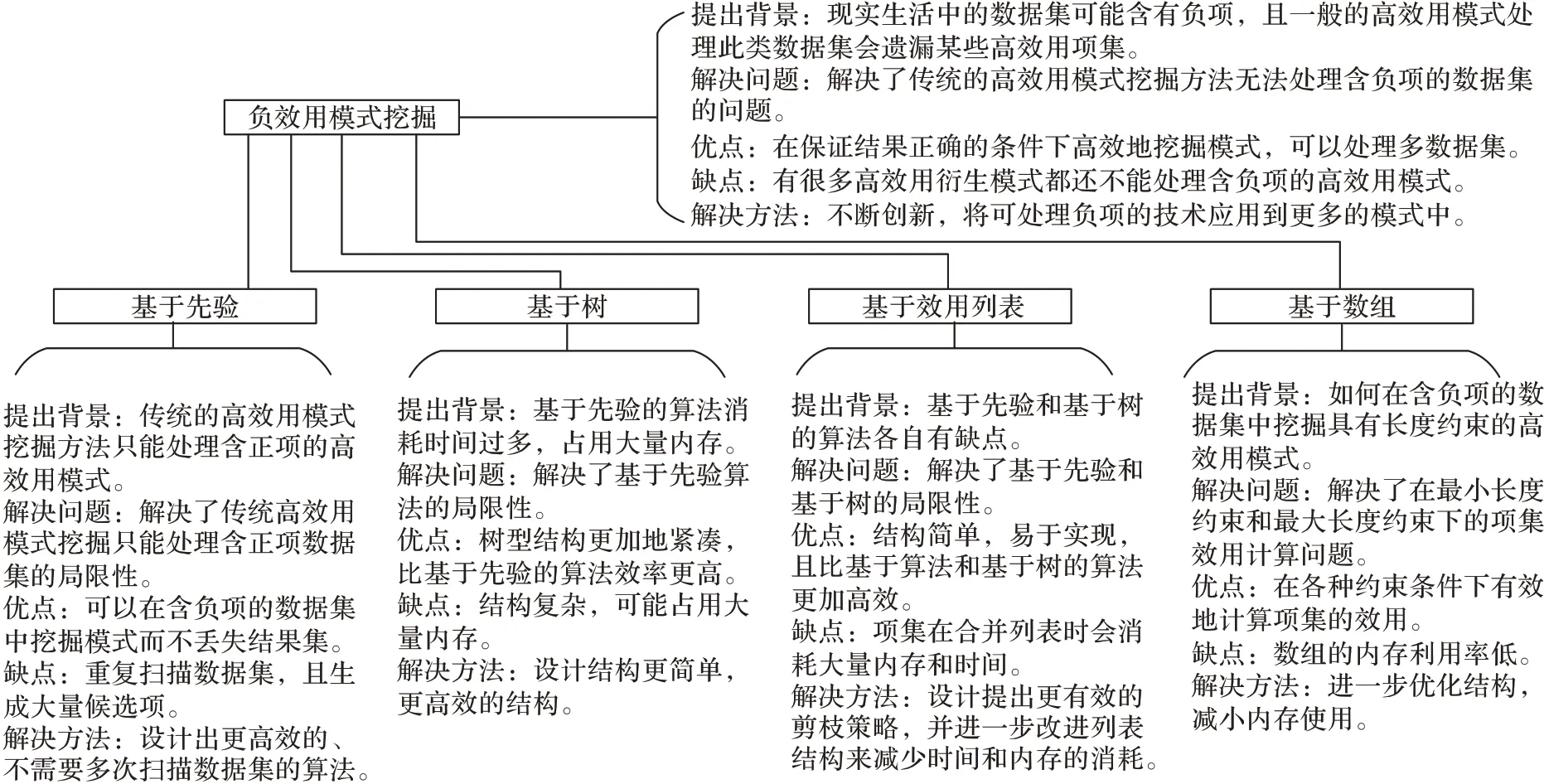
图2 含负项的模式挖掘算法下的各类方法优缺点Fig.2 Advantages and disadvantages of different methods with pattern mining algorithms with negative items
4 不同类型的高效用模式挖掘
4.1 Top-k高效用模式挖掘
传统HUPM 算法的另一个局限性在于如何设置minutil
,其值会极大地影响执行时间、内存使用率以及向用户显示的模式数量。一方面,如果用户将minutil
阈值设置得太低,则可能会发现大量模式,并且算法可能会变慢并消耗大量内存;另一方面,如果用户将minutil
阈值设置得太高,可能会发现很少或没有模式。为了解决这个问题,引入了Top-k
高效用项集(Top-k
HUI,THUI)挖掘问题。THUI 挖掘问题主要是HUIs 挖掘问题的一种变体,它允许决策者指定所需数量的HUIs,而不是最小效用阈值。TKU(Top-K
Utility itemsets mining)是从事务数据库中挖掘Top-k
高效用模式的最早算法之一。该算法分两个阶段挖掘HUIs,在第一阶段构建UP-Tree,并生成潜在的前K
个HUI;在第二阶段数据库扫描之后,从其中确定Top-k
HUIs。REPT(Raising threshold with Exact and Pre-calculated utilities for Top-k
high utility pattern mining)是挖掘THUI 的另一种两阶段方法,该算法的整体功能类似于前面所述的TKU 算法。在数据库的第一次扫描期间,REPT 算法将构造效用降序的预评估矩阵(Pre-evaluation Matrix with Utility Descending order,PMUD),PMUD 类似于TKU 算法中使用的PE(Pre-Evaluation)矩阵,关键区别在于矩阵中维护的二项集的性质。TKEH(Efficient algorithm for mining Top-K
High utility itemsets)算法降低数据集扫描成本的技术为:事务合并和数据集投影技术,当探索更大的项目时,这些技术会减少计算项目和上限的效用。PTM(Prefix-partitioning-based Top-k
high utility itemset Mining)算法能够在海量数据中挖掘Top-k
模式,PTM 将事务数据库维护为一组基于前缀的分区,项集的效用则通过一个特定分区中的事务来计算;使用了基于全后缀效用的子树剪枝规则,有效地减小了集合枚举树的探索空间。4.2 高平均模式挖掘
在传统的HUPM 算法中,项集的效用值定义为项集在所出现在事务中的效用值之和,此定义的一个重要问题是它没有考虑项集长度。由于较大项目集的效用通常大于较小项集的效用,因此传统的HUPM 算法倾向于查找一组大型项目集,证明了该定义不是效用的最合理的衡量。为了更好地评估每个项集的效用,提出了高平均效用项集挖掘(High Average Utility Itemset Mining,HAUIM)的任务,它同时考虑了项目集的长度及其效用,因此更适合实际情况,为此任务设计了几种算法。
Lin 等提出了一种平均效用列表结构AU(Average-Utility)-list,该结构只保留挖掘过程所需的信息,从而将非常大的数据库压缩。提出了一种有效的修剪策略,通过及早修剪没有希望的候选项来减小搜索空间,避免在枚举树中构建处理节点的扩展AU-list,以减少计算量。
Lin 等设计了一个高平均效用模式树结构(High Average Utility Pattern-tree,HAUP-tree)来更有效地挖掘HAUI。Lan 等开发了一种基于投影的平均效用挖掘(Projection-Based approach for mining high AU itemsets,PBAU)算法来挖掘HAUI。Lan 等还扩展了PBAU 算法,并设计了一种使用改进的策略来挖掘HAUI 的PAI(uses the Prefix concept to create tighter upper bounds of Average-utility values for Itemsets)方法。Lu 等开发了一种HAUI-tree 结构来挖掘没有候选生成的HAUI。
LMHAUP(List-based Mining of HAUP)采用了两个新的上限:事务最大平均效用上限和最大剩余平均效用上限,利用这两个上限可以极大地减小查找高平均效用模式的搜索空间,而无需多次扫描数据库。在算法中设计了一种基于列表的结构,称为TA-List,其中只存储提取高平均效用模式的必要信息,旨在最小化加入过程的成本,这是列表结构的缺点之一。因此,与使用列表结构的最先进的高平均效用模式挖掘算法相比,LMHAUP 花费更少的内存和运行时间。
4.3 高效用序列模式挖掘
高效用序列模式挖掘(High Utility Sequential Pattern Mining,HUSPM)的问题旨在在定量序列数据库中发现具有高效用的子序列,要考虑项目及其效用之间的顺序排序(根据购买数量和单位利润等标准)。高效用序列挖掘已被应用于多种应用中,由于序列的效用度量不满足向下闭包属性,因此比一般高效用模式挖掘更具挑战性。
已经设计了许多算法来发现序列数据库中的序列模式。最受欢迎的是GSP(discovers these Generalized Sequential Patterns)、PSP(Projection-based,Sequential Pattern-growth approach)、SPAM(Sequential PAttern Mining)。所有这些序列模式挖掘算法都将序列数据库和最小支持阈值作为输入,并输出高效的序列模式集。对于序列模式挖掘任务,始终只有一个正确答案,因此,如果所有序列模式挖掘算法在相同的数据库上以相同的参数运行,则它们将返回相同的序列模式集。所以各种算法之间的差异不是它们的输出,而是每种算法如何发现序列模式,各种算法利用不同的策略和数据结构来有效地搜索顺序模式。
4.4 其他高效用模式挖掘
传统的高效用项集挖掘算法不认为项集的效用值可能随时间变化,因此无法找到只在特定时间段内为高效用项集的模式,发现这样的项集很有用,因为某种产品在特定时间段可能会卖得特别好,但是在一年中的其余时间则不会。通过定义挖掘局部高效用项集(Local HUI,LHUI)的问题和挖掘高峰高效用项集(Peak HUI,PHUI)的问题来解决HUPM的这一局限。
Fournier-Viger 等提出了名为LHUI-Miner(Local HUI Miner)和PHUIMiner(Peak HUI Miner)的算法来挖掘这些模式,它依赖于名为LU-list(Local Utility-list)的新型数据结构,并扩展了HUI-Miner 算法的基本搜索过程和效用列表数据结构。算法将挖掘LHUI 的问题扩展到挖掘PHUI 问题,它包括查找项集具有高效用的时间段。由于PHUI 的集合可能很大,并且PHUI 中出现的某些项目对其峰值的贡献不大,因此提出了第三个问题,即挖掘一个较小的模式集,称为非冗余峰值高效用项集(Non redundant Peak HUI,NPHUI),针对此问题设计了一种名为NPHUI-Miner(Non redundant Peak HUI Miner)的算法。与传统的HUPM 算法相比,该算法为用户提供了更多的信息,因为该算法可以识别模式具有较高效用的时间间隔,而不仅仅是在整个数据库中检查模式是否具有较高的效用。实际上,此问题证明了传统的HUIs 挖掘问题是LHUI 挖掘问题的特例。
4.5 小结
考虑到传统HUPM 算法的一些局限性,学者们提出了多种高效用衍生模式。因传统HUPM 算法无法设置合适的minutil,
所以提出了Top-k
高效用模式挖掘算法,解决了传统HUPM 方法对minutil
设置比较敏感的问题,在算法中只需设置k
值,避免了阈值对模式数量的影响。高平均效用模式挖掘算法则考虑了项集的长度及其效用,解决了传统HUPM 算法没有考虑项集长度的问题,因此更适合实际情况。实际生活中的数据库中大多项目是有顺序性的,高效用序列模式的提出考虑到了项目及其效用之间的顺序排序,更加适用于处理现实生活中的数据集。而局部高效用模式可以挖掘出只在特定时间段为高效用的模式,在此基础上扩展而来的峰值高效用模式挖掘方法可以查找项集具有高效用的时间段。5 下一步工作
尽管高效用模式挖掘的问题已经研究了十多年,并且已经发表了许多有关该主题的算法和概述,但是仍然有许多研究机会:
1)含负项的HUPM 方法在现阶段主要应用于静态模式挖掘中,但在大数据环境下已不能满足现实要求。对此,下一步将研究在动态数据库中挖掘含负项HUIs 的算法,将FHN 算法中处理负项时用到的属性、剪枝条件等应用在性能优异的增量模式挖掘算法中,以此来解决现有动态模式挖掘算法只能处理正项的局限性。
2)尽管已经设计了一些算法来从增量数据库中挖掘高效用模式,但在挖掘过程中它们仍然有性能限制。IIHUM 算法可以在不生成任何候选对象的情况下提取高效用模式,今后将其中的增量数据处理技术应用于不同类型的流模式挖掘领域,如基于滑动窗口和阻尼窗口模型的数据挖掘环境。
3)滑动窗口中最重要的参数之一为窗口大小,其大小直接影响着模式挖掘时的性能。今后将设计定义一种方法来自动设置窗口大小参数;但是动态地调整窗口大小是很有挑战性的,因为它需要定义新的上界,这些上界对于不同的窗口长度都是有效的,同时又不会过于宽松,以致无法有效地减小搜索空间和挖掘模式。
6 结语
近年来,高效用模式挖掘已经引起了人们的广泛关注和研究,并已取得大量研究成果。本文对高效用模式挖掘进行了系统综述,首先以效用值的正负为角度对高效用模式进行了划分;之后进一步对带有正效用的HUPM 方法以数据库的动静为标准进行划分,而带有负效用的模式挖掘算法则以各种关键技术进行了分类,同时从多种角度对HUPM 算法进行了分析和总结;随后,介绍了几种经典的高效用衍生模式,包括模式的提出背景及解决问题;最后,提出高效用模式挖掘算法的下一步研究方向,包括在大数据环境下用于处理负项的关键技术与动态模式挖掘算法的结合,增量挖掘技术与数据流环境的结合,数据流中窗口参数的动态调整等问题,动态模式挖掘将会是以后的工作之重。
