
二进制代码相似性搜索研究进展
2022-05-07 07:07庞建民
计算机应用 2022年4期
夏 冰,庞建民,周 鑫,单 征
(1.数学工程与先进计算国家重点实验室,郑州 450001;2.中原工学院前沿信息技术研究院,郑州 450007)
0 引言
随着物联网和工业互联网的快速发展,无论是智能手机还是嵌入式设备,绝大多数软件都是以二进制代码形式发布。为了快速开发产品,厂商使用开源软件或通过代码重用加速产品迭代,为不同操作系统和不同CPU 架构,产生众多可定制化且满足客户需求的固件镜像文件。这种通过开源部署生成的二进制固件程序在满足客户便利的同时,一旦固件镜像文件引用的开源组件或底层系统被发现存在安全风险,会带来巨大安全隐患。如现在仍未消除的OpenSSL(Open-source Secure Sockets Layer)漏洞因破坏性之大、影响范围之广,堪称网络安全里程碑事件。出于商业保护或其他技术原因,厂家通常并不对外提供源代码。因此,在源代码无法获取或者获取不便这一事实下,二进制代码分析成为工业界和学术界研究其安全问题的最佳方法,其研究话题和分析技术持续高涨。
由于代码复用,同样的代码会出现在多个程序中,甚至出现在同一个程序的多个部分。一旦发现某个二进制代码存在bug,从众多代码中找到被使用的bug 代码、相同的bug代码或相似的bug 代码,从而可大规模、快速且及时地发现bug 风险。这样一来,采用相似性搜索技术发现网络安全脆弱性为二进制代码安全分析提供一种新思路,其研究成果广泛应用在bug 搜索、恶意软件分析检测、补丁生成分析和软件窃取检测等方面。
本文首先介绍二进制代码相似性搜索体系架构,给出二进制代码涉及的基本概念,详细介绍二进制代码相似性搜索流程;其次,从二进制代码的语法、语义和语用相似性搜索角度,总结对比分析现有技术研究现状;最后,给出二进制代码相似性搜索领域未来发展方向。
1 二进制代码相似性搜索体系架构
1.1 二进制代码
二进制代码是指源代码经过编译链接后,可被CPU 直接执行的机器代码。从源代码到目标程序大致需要经历编译过程和链接过程。编译过程主要是将程序源代码作为输入,选择某种编译器如GCC(GNU Compiler Collection)和优化级别如-O0、-O1、-O2 后,编译生成目标文件。链接过程是将多个目标文件链接在一起,生成被CPU 如x86、ARM(Advanced RISC Machine)等识别执行的目标程序、独立可执行程序或库文件。如图1 所示为源代码编译过程。
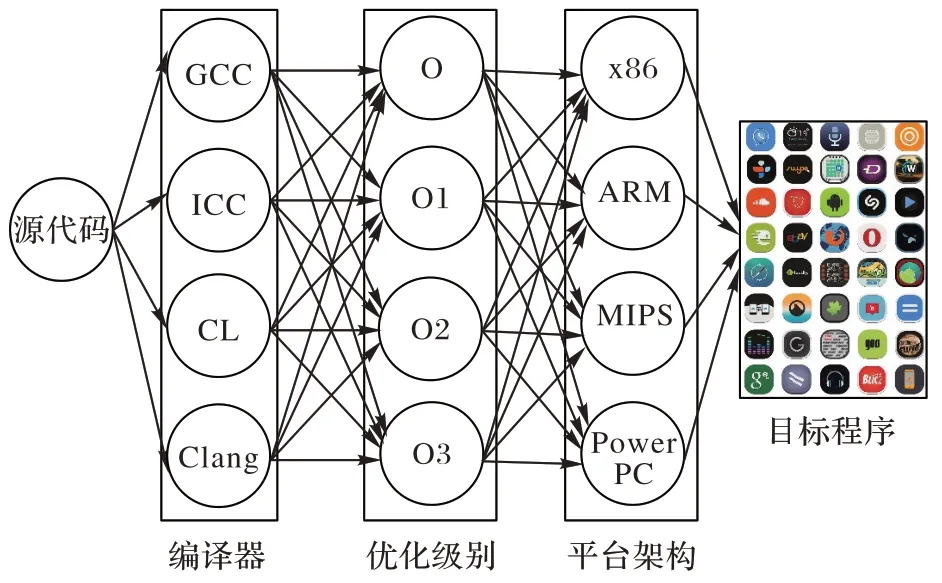
图1 源代码编译过程Fig.1 Compilation process of program source code
二进制代码可以有不同表现形式,如:用十六进制字符串形式表示原始字节,用IDA Pro(Interactive Disassembler Professional)工具将二进制代码反汇编后得到汇编指令序列,用LLVM(Low Level Virtual Machine)工具将其转化为等价的中间语言IR(Intermediate Representation),用控制流图(Control Flow Graph,CFG)表示功能调用关系等。本文将以x86 汇编指令为例,不包含文献[42-43]中讨论的类似Java 字节码的操作,讨论和二进制代码相似性搜索有关的指令、基本块、程序流程图等基本概念。
通常一条汇编指令由一个助记符或操作码最多3 个操作数组成。操作码表示指令的机器行为语义。每个操作数可以是一个参数(如寄存器、偏移量)或用于寻址的一组参数。如汇编指令MOV EAX,[ESP+8],其中MOV 为操作码,EAX 和[ESP+8]为操作数,EAX 和ESP 为寄存器,[ESP+8]为寄存器ESP 和偏移量8 共同组成的用于寻址的一组参数。
二进制目标文件通过反汇编后会生成多个二进制函数。二进制函数通常有若干个基本块(Basic Block,BB)组成并在CFG 的作用下完成函数功能。一个二进制函数的CFG 可以用一个二元组(N
,E
)描述,其中:N
是有穷节点集合,每个节点表示函数内一个基本块;E
是边,表示基本块之间的连接调用关系。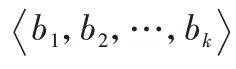
1.2 二进制代码相似性搜索流程
二进制代码相似性搜索通常以携带片段属性(如代码片段具有高危漏洞风险或恶意代码调用风险)的代码片段作为查询条件,利用相似性技术从资源池中返回满足查询条件的代码片段作为输出。二进制代码相似性搜索是项系统工程,是多种技术的融合结果。具体来讲二进制代码相似性搜索主要由代码片段提取、代码片段比较、资源池组成,如图2所示。
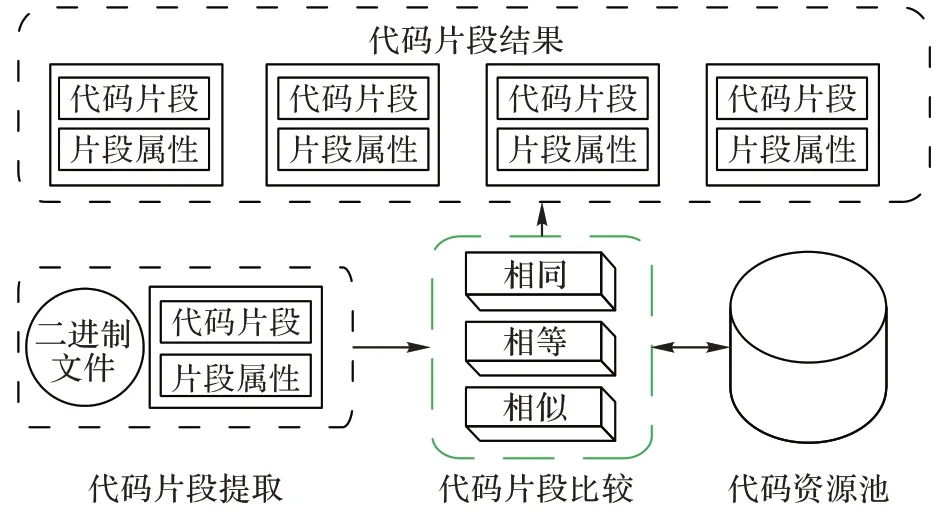
图2 二进制代码相似性搜索框架Fig.2 Framework of binary code similarity search
1.2.1 二进制代码片段提取
代码片段大小和特定应用场景有关,如要搜索的是文件、函数或者基本块。这些片段具有某种特征或属性,属性可以是已知也可以是未知。片段可以来自同版本程序,如某个二进制可执行程序的两个函数,也可以来自同程序的两个版本,或者也可以来自两个不同程序。
按照代码片段提取的粗细粒度,从细到粗可以划分为指令、一组相关的指令、基本块、一组相关的基本块、函数、一组相关的函数,路径轨迹和整个程序。如文献[44]采用一组相关的指令K
-Gram 方案,文献[8]采用共享某个属性的指令Strand 方案。通过设置切片规则,提取的指令可以属于不同的基本块,甚至不同的函数。一组相关的基本块由共享结构属性(如数据依赖关系、调用关系)的多个基本块组成。这组基本块可以隶属相同的函数,也可以属于不同的函数。相关函数是一个二进制程序的组件,如一个库组件、一个类组件或者一个模块组件。路径轨迹是指一条处理二进制程序某个变量或参数的执行路径。代码片段提取后,通常有两种方式得到代码片段比较结果。一是,用细粒度比较后的统计结果来推导粗粒度比较结果,如文献[8]的Strand 用细粒度的指令去分析粗粒度的基本块或函数;二是,用细粒度特征累加推导粗粒度结果,如文献[15]提出的Gemini 方案在基本块上累加指令的特征,从而在函数粒度上产生特征向量实现函数间比较。
1.2.2 二进制代码片段比较
通常将比较结果分为相同(Identical)比较、等价(Equivalent)比较和相似性(Similar)比较。二进制代码相似性搜索关键在于代码片段比较。
两个二进制代码片段相同是指它们具有相同的语法表示。判断二进制片段是否相同最简单的方式是采用哈希散列技术,如采用SHA(Secure Hash Algorithm)技术和MD5(Message Digest algorithm 5)技术来计算哈希值,就能够实现每个片段内容是否相同的判断。然而,这种简单粗暴的方式对代码片段要求特别苛刻,一旦某个细微变化都会产生巨大差异结果,甚至在原本相同的代码上产生意想不到的后果。即使源代码没有改变,采用相同编译器对同一源代码进行前后两次编译,产生的二进制代码也会发生变化。这是因为这些执行文件加入了类似当前编译时间等实现自动计算的动态变化信息。
两个二进制代码片段等价是指它们具有相同的语义,即它们具有相同功能或影响。两个二进制片段语义相等并不关心二进制代码的语法。尽管两个相同的二进制代码片段具有相同的语义,但两个不同的二进制代码片段也可能具有相同的语义。如“MOV EAX,0”和“XOR EAX,EAX”是语义相等的两条x86 指令,功能都是设置寄存器EAX 的值为0。由于证明两个程序是否功能相等是一个不可判定问题,因此判断代码相等需要付出高额代价。一种比较实际的方式是通过比较细粒度的二进制代码片段来实现等价判断。如文献[12]提出的XMATCH 方案,通过抽取基本块中的条件表达式来判断两个基本块的语义是否等价。
两个二进制代码片段相似是指它们的语法、结构或功能语义是相似的。语法相似性比较的是代码字面表示。结构相似性是指代码片段用图表示后,两个图结构间是相似的,如代码的CFG 或函数间调用图。由于CFG 的点和边可以携带更多语义信息,因此在某种程度上能捕获代码的语法表示和语义表示。语义相似性比较的是代码功能。一种简单的语义相似性比较方法是比较程序的交互行为是否相似,或者比较操作系统API(Application Programming Interface)调用或系统调用后程序环境是否相似。但是,两个具有相同系统调用的程序却可以实现截然不同的结果。因此,本文不考虑通过系统调用或利用操作系统API 和环境进行交互的行为相似性比较这种动态分析方法,而是关注静态分析比较。
小结一下,二进制代码相同能够推导出等价和相似,但是二进制代码相似不能推导出等价或相同。语义相似性比较对代码语法转变和代码结构变化不敏感,不足之处是如果比较的是较大代码片段,则会带来计算代价高的问题。
1.2.3 二进制代码资源池
软件开发者依据客户需求可以编译生成符合任何目标平台架构需要的二进制程序,从而得到多个不同架构的程序版本。这种情况下产生的二进制程序因使用了不同的指令集,语法前后产生巨大变化。软件开发者也可以利用混淆转变技术,为一份相同源代码产生多样化的二进制程序变种,然而变种后的语义功能却没有变化。因此,二进制代码相似性搜索要具有一定的鲁棒性,要能够处理资源池中不同平台架构的二进制程序。
鲁棒性是指代码搜索方案在面临代码转换场景时,如选择不同编译器和优化选项、不同平台架构和混淆等,仍然能够找到相似性的代码。因此,依据代码搜索的鲁棒性来建设资源池,可将资源池中的二进制代码分为单平台代码如x86和跨平台代码如x86、ARM、MIPS(Million Instructions Per Second)。
由于跨平台代码语法差异很大,因此在比较上通常是计算语义相似性。当前跨平台解决方案采用两种技术来实现。一是语法分析,先利用中间语言表示技术,把二进制代码提升到和平台无关的中间语言表示上,然后在中间语言表示上完成相同的语法分析,这样就实现了和原来平台架构无关,如文献[10]提出的BinGo 方案和文献[2]提出的FirmUp 方案。二是特征分析,为每一个平台架构设计单独的模块获取特征向量,捕获二进制代码的语义信息,利用监督学习机制在跨平台间打上标签,如来自同一份源代码则表示相似标记为1,否则标记为0,然后将数据喂入模型训练从而得到分析模型,BinDNN 方案、INNEREYE 方案和SAFE 方案。
1.3 代码转换与相似性搜索
二进制代码相似性搜索本质上仍然属于程序逆向分析和应用技术,因此需要解决高级语义丢失、编译转换和代码混淆带来的技术难题。源代码经过编译处理后,使其原本丰富的程序语义信息丢失,如函数名、变量名、备注和数据结构,从而为分析带来挑战性。
编译转换带来的代码变化主要是由于编译过程使用了不同的编译器,选择了不同优化选项,为不同操作系统和底层不同CPU 指令集平台架构生成的二进制程序,这些都会导致二进制代码发生巨大变化。此外,为保护知识产权或增加程序逆向分析难度,代码混淆转变既可以发生在源代码,也可以发生在二进制代码中,尽管语义保持不变,但是二进制代码的结构或语法发生了变化,也给代码相似性搜索提出挑战。综上所述,二进制代码相似性搜索主要面临源代码转换和二进制代码转换的挑战,这二种转换都不改变代码语义。如图3 所示为代码转换过程。
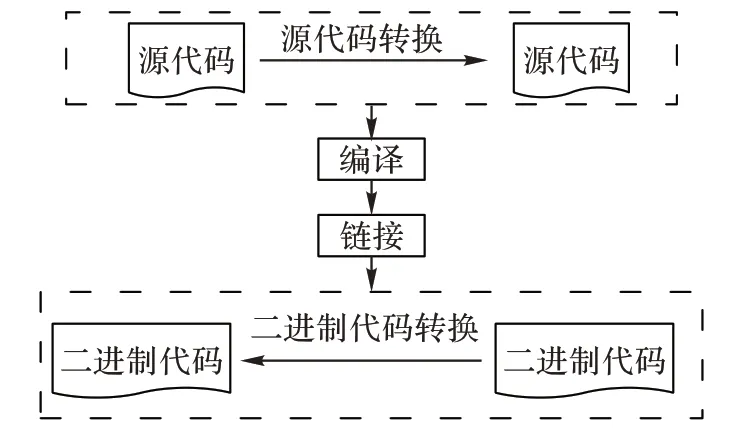
图3 代码转换过程Fig.3 Process of code transform
源代码转换发生在编译前,转换前后的输入和输出都是源代码,如将相同的软件功能分别采用不同高级语言来实现。因此,源代码转换通常不考虑目标平台,只需要特定的程序语言编写程序即可。
二进制代码转换发生在编译后,转换前后的输入和输出都是二进制。二进制代码转换与采用的开发语言无关,严重依赖目标平台。二进制代码转换后,代码前后在语法上差异巨大,对相似性搜索提出严峻挑战。
1.4 讨论与小结
二进制代码相似性搜索需要比较两个或多个二进制代码片段。对两个以上片段的比较方法,通常是采取一个片段和剩余片段的比较,或片段之间彼此比较来实现。这样一来,基于比较数目,二进制代码相似性搜索结果可分成一对一类型、一对多类型、多对多类型。多数一对一类型实现二进制代码差异进化问题,如区分同一程序的两个连续版本,识别目标版本中增加、删除、修改的内容。多数一对多类型实现的是二进制代码相似性搜索问题。例如搜索一个查询片段是否和目标片段中相似,然后返回TopK
个最相似的目标片段。多对多类型典型应用场景是二进制代码片段集群识别,如恶意代码聚类分析中,将两两比较相似的识别为同类。由于语义相似性聚焦在相似的行为影响或功能等价上,因此可有效应对源代码转换和二进制代码转换的挑战。为了系统描述研究现状,本文将从二进制代码语法、二进制代码语义和二进制代码语用三个角度介绍。
2 基于语法的二进制代码相似性搜索
基于语法的代码搜索是指在代码片段比较的时候,比较的是代码字面表示。主要包括基于哈希、指令序列和CFG 的代码搜索技术。
2.1 基于哈希的搜索技术
将哈希技术应用到原始字节的比较上,可以提高搜索效率,快速区分是否在细粒度上发生代码复用。哈希实现的是相同,而不是相似的输入。哈希值压缩后便于存储和计算,比较效率高,从而多用于检索。基于哈希的搜索技术主要包括局部敏感哈希、模糊哈希和可执行文件哈希。
2.1.1 局部敏感哈希
局部敏感哈希(Locality-Sensitive Hashing,LSH)思想是相似的输入产生相似的哈希值。具体来讲,将待比较的两个代码原始字节集合分成了多个较小子集合,对每个子集合中的数据施加哈希计算,最后统计相同哈希值的数量。相同数量越多,相似性越高。
文献[50]抽取二进制文件数据段中的ASCII(American Standard Code for Information Interchange)格式字符串、代码段中的ASCII 格式字符串和数据段中的Unicode 字符串,组合得到可读字符串序列,借助深度学习编码可读字符串,随后对编码向量施加LSH 计算从而实现快速检索。
Gemini 方案引入属性控制流程图(Attributed CFG,ACFG),借助Structure2vec 技术生成图嵌入向量,然后利用LSH 计算每个嵌入向量的哈希值,并存入到数据库。为了从数据库中搜索识别一组与查询函数相似的二进制代码函数,只需要哈希计算查询函数嵌入向量,从而实现函数的快速搜索。
文献[51]将SimHASH 哈希技术应用到函数相似性检测中,依据函数中代码块的SimHASH 值快速发现相似代码块。文献[52]提出的BinHASH 方案将函数表示为一组行为特征集合,利用输入输出分析获得基本块内的行为,如内存操作行为、寄存器操作行为,然后将这些行为特征施加最小哈希MinHASH 运算,从而在大规模函数中实现聚类分析。
文献[53]提出的Kam1n0 方案认为现有哈希技术不能很好地处理分布不均匀的数据,认为:基本块越小,相似性越高;基本块越大,向量空间呈稀疏分布,相似性越低。因此,在LSH 的基础上,提出了一种新的自适应局部敏感哈希(Adaptive LSH,ALSH)算法,该算法对于稠密区域可以得到较少的点,对于稀疏区域可以得到较多的点,并证明性能等效近邻搜索。
2.1.2 模糊哈希
模糊哈希主要原理是依据分片条件对文件进行分片,使用一个弱哈希计算文件局部内容,使用一个强哈希对文件分片计算哈希值,并与分片条件一起构成一个模糊哈希结果,最后使用一个字符串相似性对比算法来判断两个模糊哈希值的相似度是多少,从而判断两个文件的相似程度。模糊哈希算法多用于文件级别的相似性比较。
文献[54]提出的Ssdeep 方案认为同源文件以相同的顺序共享相同的位集(sets of bits),因此,通过使用滚动方式获得数据的边界,提出一种上下文触发的分段散列(Context-Triggered Piecewise Hashing,CTPH)算法。这种散列可以用来识别未知输入和已知文件之间的有序同源序列,当文件的部分变化发生时,如修改、增加、删除等操作,使用Ssdeep 均能发现与源文件的相似关系。这是因为模糊哈希不仅捕捉二进制代码相似性,也捕捉了可执行文件中数据的相似性。文献[55]的结果证实,模糊哈希能够识别具有共同代码或库程序之间的相似性。他们发现即使相同的源代码在编译的时候采用不同编译优化选项,可执行文件的数据部分仍然相同,这对数据相似性分析引入到二进制代码相似性搜索中具有指导意义。类似的实现方案还有TLSH(Trend LSH)方案、nextGen-hash 方案和BitShred 方案。
2.1.3 可执行文件哈希
可执行文件哈希把一个可执行文件作为输入,在进行哈希计算时使用的输入仅仅是可执行文件部分内容,如导入表或者文件头,这在恶意软件变种相似性比较非常有用。变异的恶意文件如果采用简单的二次加壳,或者混淆变化小,那么文件内容很少会发生变化,这样一来,将可执行文件哈希用于比较分析恶意文件的多个变种时,能产生多个相同的哈希值。
文献[59]提出的peHash方案对一个PE(Portable Executable)可执行文件,选择在编译和加壳过程中很少发生变化的区域上进行哈希计算,如初始化栈大小、堆大小。文献[60]提出的ImpHash 方案认为加壳变种后功能是一样的,则认为导入表同样也是一样,因此在计算的时候仅仅对导入表进行哈希计算。由于恶意代码在加壳过程中加入一些不相关可执行文件,并重构导入表,从而造成错误率很高。
2.1.4 讨论与小结
哈希技术能够感知代码细微变化,检索匹配效率高,不足之处在于错误率高。从方案名称、实现、优点、不足四个角度总结基于哈希的搜索技术如表1 所示。

表1 基于哈希的二进制代码相似性搜索方案间比较Tab 1 Comparison of binary code similarity search schemes based on hash
2.2 基于指令序列的搜索技术
指令序列通常是指函数中的指令在空间上是按照线性连续地排列。指令序列在比较时需要指令归一化,归一化主要包括操作码归一化和操作数归一化。文献[61]提出的BinClone 方案采用操作数归一化,将常量用VAL 符号代替,内存地址用MEM 符号代替、寄存器用REG 符号代替。与BinClone 不同的是,文献[11]提出的BinSequence 方案将常量分为内存偏离量和立即数。文献[45]采用操作码符归一化,将操作码区分为逻辑计算、数据传输、栈操作、数学运算、函数调用、地址操作等类别。由于指令是代码搜索最基本的组成单位,因此通常将指令比较的结果作为相似性搜索的前提。典型的指令比较主要包括N
-Gram、N
-Perm、指令哈希和指令对齐方式。2.2.1N
-Gram指令序列可定长也可变长。定长指令序列通过运用滑动窗口大小或步长来实现。滑动窗口大小也就是指令序列中指令的数量,步长是指从窗口开始处开始滑动的指令个数。当步长小于滑动窗口大小时,连续序列重叠。当步长为n
时,产生的序列称之为N
-Gram。例如,给定一个指令助记符序列{MOV,SUB,ADD},当N
=2 时,指令助记符序列会得到{MOV,SUB}和{SUB,ADD}两个指令序列。Rendezvous 方案、Kam1n0 方案以及ILINE 方案在各自的系统中都采用了N
-Gram 作为相似性比较的方法。2.2.2N
-PermN
-Perm 是指不考虑顺序的N
-Gram 方案,这种方法能够捕获序列中的指令重新排序状况。由于不考虑指令顺序,因此一个N
-Perm 指令序列会产生多个N
-Gram。如2-Perm 的{MOV,PUSH}会产生2-Gram 的{MOV,PUSH}和{PUSH,MOV}。文献[45]表明将N
-Germ 用于软件指纹比较时,N
取值为4 或5 的时候,相似性比较的可信度较高。2.2.3 指令哈希
指令哈希是指从一个变长的指令序列中得到固定长度个数的指令序列后,运用哈希计算,如果两者之间哈希值一样,则认为序列相似,如SMIT(Symantec Malware Indexing Tree)方案、BinClone方案以 及SPAIN(Security Patch Analysis for bINary)方案。
2.2.4 指令对齐
TRACY 方案采用指令对齐方式,从CFG 上抽取连续的固定个数的基本块形成Trace,对齐基本块后对基本块内部采用指令序列对齐方式,这样就可以在两个序列之间产生一个映射。指令对齐时候定义一个相似度分值,指令和空对齐的时候定义一个空分值。如果Trace 间相似度超过阈值a
,认为两个Trace 相似,并计入Trace 相似总数。接着,计算所有相似性Trace 匹配结果的覆盖率,从而得到一个覆盖值。设置阈值b
,如果覆盖值超过阈值b
,则认定两个函数相似。2.2.5 讨论与小结
指令作为代码分析最重要的组成部分,在实现代码搜索方案中通常是将其作为方案预处理部分。如指令预处理后喂入词向量训练模型从而进行后期基本块或者图的比较搜索。由于指令优化和体系架构的差异,指令数量庞大且变化多通常超出字典范畴,因此需要进行归一化处理。指令归一化后会造成指令精确语义的缺失,进而会影响语义比较。如何识别指令语义细微差异,并对其指令序列进行精确表示学习是代码分析的一项基础工作。基于指令序列的二进制代码相似性搜索方案间的比较结果如表2 所示。

表2 基于指令序列的二进制代码相似性搜索方案间比较Tab 2 Comparison of binary code similarity search schemes based on instruction sequence
2.3 基于图结构的搜索技术
代码片段的控制结构可以抽象成图来表示,二进制代码用图表示后,代码相似性计算问题就转换为图相似性比较问题。图结构的稳定性,以及图中节点和边都可以携带更多的语义信息,使其在搜索效果上具有更强的鲁棒性。
二进制代码有三种有向图表示方式:函数内部CFG、函数间CFG(Inter-Procedural CFG,ICFG)和程序调用图(Call Graph,CG)。由上面分析可知,每个函数都有自己的CFG。CFG 和ICFG 节点是基本块,边表示控制流转移如分支或跳转,不同之处在于CFG 节点位于于同一函数内,ICFG 节点属于程序内任一函数。CG 的节点不是基本块,而是函数,边表示函数间的调用者与被调用者关系。
三种有向图的输入是不同的。CG 或ICFG 以整个二进制程序或文件作为输入,基于CFG 的方法是以二进制函数作为输入。多数方案不在图上进行二次加工。如文献[62]采用CG 方式,文献[63]采用CFG 方式,文献[64]采用ICFG方式。
有些方案赋予图更多的语义信息。Genius 方案和Gemini 方案融入基本块的统计属性,文献[23]融入边的属性,把CFG 中的边标记为控制流转移类型。SIGMA(Semantic Integrated Graph Matching Approach)方案融入图的属性,提出一种包含CFG、CG 和寄存器流程图的语义集成图。文献[66]融合CFG 调用的内联函数和库函数,提出执行依赖图(Execution Dependence Graph,EDG)。文献[67]使用指令依赖关系图(Reductive Instruction Dependent Graph,RIDG),认为虽然指令的顺序发生了变化,但指令之间的依赖关系图却保持不变。这意味着指令依赖关系图具有天然抗指令重排序的特性,因此引入RIDG 实现一种通用且抗混淆的二进制程序相似性分析。
当前基于图结构的搜索技术主要包括图相似性比较、路径相似性比较和图嵌入向量相似性比较。
2.3.1 图相似性比较
由于图同构要求图中所有节点要相同,比较代价较高,因此当前二进制代码比较通常是采用子最大公共子图同构,即找到两个图中的最大同构子图。为了减少图比较对的数目以及图大小,文献[62]对相同签名的CFG 和差异较大CFG不进行比较,iBinHunt 方案只比较具有相同污点标签的节点。SMIT 方案和BinSlayer 方案把图相似度模型归结为图优化问题。SMIT 利用制高点树(Vantage Point Tree,VPT)技术将搜索问题转换为近邻搜索,BinSlayer 利用匈牙利算法(Hungarian Algorithm,HA)加快搜索速度。文献[22]采用子图匹配的方案,其基本思想是把函数CFG 图分割成多个子图,为每个子图产生一个指纹,通过统计子图指纹匹配数量来确定两个图之间的相似度。
2.3.2 路径相似性比较
CoP 方案和BinSequence 方案把函数相似性转换为路径相似性比较。CoP 利用符号执行和证明理论,计算基本块中的语义等价最长公共序列,作为路径上的基本比较元素。BinSequence 为提高搜索速度,采用两个过滤器,过滤掉基本块数量和函数指纹差距大的函数,借助近邻搜索技术得到CFG 上的最长执行路径,接着在两个函数之间建立基本块映射关系并计算两两之间的相似性度量值。路径相似性比较优势在于路径全覆盖,通过统计的方式来获得度量值。最大的不足在于:如果函数CFG 顶点过少,则在小片段比较上不具有优势;如果函数CFG 过大,在计算效率上会受到影响。
2.3.3 图嵌入向量相似性比较
文献[15]提出一种基于图嵌入的相似性解决方案。利用统计方法得到基本块的向量表示,将二进制函数的CFG 表示为具有向量值的属性CFG(ACFG),然后利用Structure2vec实现图嵌入,接着将两个图嵌入向量送入孪生神经网络,从而实现相似性比较。
VulSeeker方案首先构建标签语义流图(Labeled Semantic Flow Graph,LSFG);然后提取每个基本块的特征向量,利用DNN(Deep Neural Network)模型生成函数图嵌入;最后计算余弦距离得到相似度。文献[70]认为CFG 节点的顺序对于图相似度检测很重要,因此融入语义感知、结构感知、顺序感知等信息,使用BERT(Bidirectional Encoder Representations from Transformers)预训练模型提取语义信息,并使用卷积神经网络(Convolutional Neural Network,CNN)模型提取节点顺序信息。
2.3.4 讨论与小结
由于搜索的二进制代码片段可以用图来表示,因此在二进制相似性搜索中通过成熟的图比较技术来实现不失为一种解决方案。基于图结构的二进制代码相似性搜索方案间的比较如表3 所示。

表3 基于图结构的二进制代码相似性搜索方案间比较Tab 3 Comparison of binary code similarity search schemes based on graph structure
2.4 小结
基于语法的二进制代码相似性搜索是指在代码片段比较的时候,比较的是代码字面表示,主要包括基于哈希、指令序列和CFG 的代码搜索技术。哈希技术能够感知代码细微变化,检索匹配效率高;不足之处在于错误率高。指令作为代码分析最重要的组成部分,在实现代码搜索方案中通常是将其作为方案预处理部分。图结构的搜索技术比较的是代码片段图表示后的相似度,由于图中节点和边都可以携带更多的语义信息,从而使得相似的代码结构变化较小,在搜索效果上具有更强鲁棒性。表4 总结了基于语法的二进制代码相似性搜索方案异同。

表4 基于语法的二进制代码相似性搜索方案间比较Tab 4 Comparison of binary code similarity search schemes based on grammar
3 基于语义的二进制代码相似性搜索
由前面分析可知,更精确的语义相似性比较应该聚焦在和语法无关的代码行为语义比较上,当前主要包括基本块语义比较和特征语义比较。
3.1 基于基本块语义的搜索技术
由于基本块中指令是线序表示,不包含任何控制流,便于数据流分析,因此多数方案都是从基本块粒度实现语义比较。核心基本思想是如果两个基本块具有相似的影响如更新某个寄存器或内存中的内容,则认为两代码片段之间语义相似。基本块语义可通过输入输出行为和符号公式两种方式获取。
3.1.1 输入输出行为
给定相同的输入如果能够产生相同的输出,则认为二进制代码片段在功能上是相等的。语义信息抽取出来后,统计相等的结果占比,依据占比结果是否达到阈值进而判定函数相等或者不相等。
文献[52]认为二进制代码片段相似当且仅当代码在机器状态上具有相同的影响,因此从寄存器、内存、函数调用参数、跳转条件4 个角度构建基本块的输入输出行为模型。文献[10]将机器状态定义成由内存、通用寄存器和条件标志组成的三元组,然后在执行路径上获得执行前后符号表达式,利用文献[6]提出的输入输出随机产生样本和约束求解技术,进而比较执行前后符号表达式产生的语义是否等价。
文献[72]遍历CFG,识别函数执行过程用到的参数,通过函数的多路交换语句识别出所有的间接调转地址,然后选择一个随机值作为输入来产生语义签名,最后比较签名值来进行相似性度量。文献[34-35,73]提出的方案均将相同的输入送入到基本块中并执行,然后比较代码执行后的输出是否相等。相同输入的比较优势在于处理流程可能需要多次,依据测试多种可能的输入输出结果进而判定两个片段是否相等。如果任一个输入产生的输出不同,则两个片段不相等。这对一些不重要的二进制片段来讲是不切合实际的。
综上可知,这种输入输出比较方法,比较的是代码执行后的最终状态,由于忽略了代码中间状态,因此该方法得到的语义相等和代码表示无关。输入输出行为实现方案最大的优势是能够证明语义相等,但是不足之处也很明显,即需要满足所有输入这一约束条件,一旦一个输入产生的输出结果不同,则认为基本块不相等。
3.1.2 符号公式
符号公式是一个赋值语句,等号左边是输出变量,等号右边是输入变量和实现输出变量的逻辑表达式。如指令ADD EAX,EBX,用符号公式可表示为EAX2=EAX1+EBX,其中EAX2 和EAX1 分别表示指令执行前后EAX 寄存器的值。为了便于符号公式化,该方案需要对各类指令操作规范化,如使用通用寄存器类型表示任意类型的寄存器。符号公式抽取出来后,可采用定理证明器、哈希和图距离三种方法进行符号执行后的结果比较。
iBinHunt为基本块中的每个寄存器和内存变量都产生一个符号表达式,然后基于定理证明器来检查两个符号公式是否相等。方案假设输入变量共享相同的值,符号公式执行后如果输出变量具有相同的值,则两个符号公式相等。通常一个基本块有多个寄存器和内存变量组成,这样会生成多个输出,由于每一个输出都需要单独的符号公式,因此iBinHunt 须实现多对输入输出结果间的比较。XMATCH 方案、Expose 方案和BinSim 方案则采用从系统调用参数的执行路径轨迹上抽取符号公式,然后利用定理证明器方案进行相等验证。基于定理证明器方法能够实现代码片段的相等比较,不足在于计算代价高,符号公式越长搜索比较时间越长,受到定理证明器的约束。
语义哈希是检查两个符号表达式是否具有相同的哈希。如果两个符号公式具有相同的哈希值则认为它们是相等的。BinHASH 方案将内存操作行为、寄存器操作行为用符号公式表示后,利用最小哈希技术计算符号公式的哈希值。GitZ 方案将不同平台的指令转换到中间语言后,抽取基本块中数据依赖的相关指令并符号化为公式,利用MD5 技术生成语义哈希。语义哈希尽管效率高,仍存在两个本来相等的公式在归一化和简化后会具有不同哈希值,如指令重新排序会引起符号公式中的符号项发生变化,从而产生不同的哈希值。
XMATCH方案和TEDEM(Tree Edit Distance based Equational Matching)方案把一个基本块的符号公式表示为一个树,通过树/图编辑距离计算相似性。图编辑距离的计算代价要比语义哈希高,但是却能处理符号重新排序带来的问题。
3.1.3 讨论与小结
由于基本块不包含控制信息且计算代价较小,因此在二进制相似性搜索通常从基本块提取语义信息进行比较。基于基本块语义的二进制代码相似性搜索技术间比较结果如表5 所示。

表5 基于基本块语义的二进制代码相似性搜索技术间比较Tab 5 Comparison of binary code similarity search schemes based on basic block semantics
3.2 基于特征语义的搜索技术
由于二进制代码的语法、语义或结构属性都可以表示为特征,这样二进制代码片段间的比较就转变为特征向量的比较。
3.2.1 嵌入比较
Genius 方案首次使用图嵌入实现二进制代码相似性分析,将基本块中的统计属性和结构属性编码为向量。Gemini 沿用Genius 思路,增加Structure2vec 模型得到图嵌入向量。借助自然语言处理技术如Word2vec、Doc2vec实现语义相似度比较,不少方案从图和基本块的研究转移到指令上和原始字节上。文献[78]的方案和INNEREYE 方案把指令看作单词,基本块看作句子,CFG 看作有多个基本块组成的段落;SAFE 方案使用Word2vec 方法生成函数嵌入;ASM2VEC则采用Doc2vec 形成路径嵌入,综合函数中的不同路径嵌入成一个向量;αDiff 方案认为文献[8,10,15]方案提取的特征存在偏见,因此直接对函数上的原始字节序列进行编码从而生成函数嵌入,该方案仅仅解决了不同版本之间的原始字节粒度的检测,并没有实现函数粒度的检测。
3.2.2 机器学习比较
通过比较机器学习得到的分类结果或预测结果,也可以实现二进制代码相似性比较。BinDNN将相似性比较定义为一个二分类任务,采用神经网络分类器去判定两个来自相同源代码的不同编译函数是否相似。ZeeK 方案将二进制函数中的每个基本块分割成多个串(strand),使用文献[13]中的方法将每一个串进行归一化和标准化,之后采用MD5哈希这些标准化表示转换成一个类似one-hot 的稀疏向量。这样,每个函数转换成向量之后,利用全连接网络判定两个函数是否属于同一类。Zeek 没有考虑函数之间的调用信息,串的分割损失串内部的信息以及串之间的控制流程信息。文献[73]在汇编指令级上捕获trace 内的程序行为集合并编码为向量后,采用基于树的机器学习模型来预测两个函数相似概率值。
有学者将基于神经网络技术应用到跨平台二进制代码相似性搜索上。VDNS(Vulnerability Detection based on Neural network and Structures matching)方案以函数为最小关联单元,对函数间调用图ICFG、函数内CFG、函数基本信息进行特征选择和特征编码,然后利用反向传播神经网络计算函数相似度。文献[50]认为不同编译配置下编译而生成的多个同源二进制文件中,可读字符串的内容和顺序基本保持一致,基于这种可读字符串的编译不变性,提出一种基于双层双向门控循环单元(Gated Recurrent Unit,GRU)模型的字符串序列编码方法。MIRROR 方案将基本块中的操作码和操作数看作一个符号序列,利用NMT(Neural Machine Translation)在x86 和ARM 之间实现翻译,从而实现跨平台的相似性搜索。
3.2.3 讨论与小结
基于特征语义的二进制代码相似性搜索方案间比较结果如表6 所示。

表6 基于特征语义的二进制代码相似性搜索方案间比较Tab 6 Comparison of binary code similarity search schemes based on features semantics
4 基于语用的二进制代码相似性搜索
本文中的二进制代码语用信息是指从二进制代码中恢复出高级语义用于代码分析的信息,主要包括调试变量恢复和函数语义识别两种。
4.1 调试信息恢复
为节省储存空间,多数商用二进制程序的调试信息通常被剥离。更严重的是,携带安全漏洞和恶意行为的二进制程序经常有意剥离掉,从而对抗安全分析。如果能够尝试恢复已剥离二进制程序的数据类型或变量名称,生成恢复二进制程序中的调试信息,从高级语义角度开展相似性比较和搜索,可解释性和鲁棒性更强。
Debin 方案将变量识别为一个二分类问题,然后利用概率推导来预测变量值。该方案采用极端随机树(Extremely randomized Tree,ET)分类模型,用于程序变量的恢复和抽取。如果模型将寄存器或内存偏移识别为变量,则在寄存器和变量、内存偏离和变量之间打上变量标签。在变量值预测方面,Debin 给每一个未知节点分配一个属性值,在概率图模型上进行最大后验概率推导,根据图的结构信息来预测所有未知节点的全局最优值。
Debin 概率图中的节点是函数、寄存器变量、内存偏离变量、数据类型、标志、指令、常量、位置和一元操作共计9 种类型,节点之间通过函数关系、变量关系、类型关系和因子关系建立连接,这些关系的引入更加接近高级语义,因此有助于代码搜索。调试信息恢复方案不同于以往的函数相似性搜索,而是从数据相似性角度搜索代码片段中是否包含感兴趣的变量或关系。但是,Debin 方案预测准确率低至68.8%,在代码混淆处理上准确率更低。类似的工作还有Dire 方案。
4.2 函数语义识别
如果顺着函数的执行流程,利用内部调用关系,建立一个全局视图来表达函数内部意图或用法的高级语义信息,那么二进制代码相似性搜索结果就符合人类理解和认知,可解释性更强。
Nero 方案通过建立神经网络翻译模型,对给定的一个剥离二进制函数,能够预测产生API 调用序列高级语义名称。具体实现为,提取函数的形成API 调用序列后,借助切片技术获得API 参数的具体值或最大概率抽象值,从而形成增强Call 调用序列,然后将这些Call 调用序列喂入Encoder-Decoder 算法模型中从而实现预测。由于Nero 方案是利用API 调用序列来描述高级语义,能处理代码混淆问题,却无法处理调用的用户自定义内部函数。如果函数不包含API,是无法得到高级语义的。
Karonte 方案认为设备通常使用多个二进制文件实现其功能,因此建模和跟踪多个二进制文件的函数交互来分析嵌入式设备固件。该方案最大的优势在于不仅仅利用了多个文件,同时还利用了多个函数,因此能在多文件多函数之间传播污染信息,进而检测出不安全的交互并识别漏洞。
识别函数语义方案最大优势在于给定一个代码片段,可以理解代码片段的高级语义,相较于基本块语义方案,方案语义整体感强烈,便于人类认知。
4.3 小结
不同于语法的寄存器等低级语言表述,也不同于语义在基本块和嵌入向量上的语义描述,语用方案是从函数甚至整个程序上给出高级自然语言语义信息。从语用角度来搜索相似性的二进制代码片段,不仅可解释性强,而且更符合人类语义。二进制代码相似性搜索方案间比较结果如表7所示。

表7 二进制代码相似性搜索方案间比较Tab 7 Comparison of binary code similarity search schemes
5 展望与挑战
当前二进制代码相似性搜索面临可解释性、语义识别和进化性的挑战。
5.1 可解释性问题
可解释性最大的挑战就是方案间可比性差,在数据集、比较粒度、比较类型和向量表示上都会造成可解释性差。
可解释性差的第一个原因在于方案都是各自采用定制的数据集。即使有些方案在同样的数据集进行比较,但由于代码不开源,在解释性方面有点牵强。第二个原因是各种方案之间在输入比较和输入粒度上都不一样,如有的比较是指令、有的比较是基本块,有的比较是基于CFG,从而方案之间很难进行比较。第三个原因是代码比较类型不一样。代码比较类型分成代码相似性比较、代码等价比较和代码相同比较。代码相同比较的结果,代码一定相似性;代码相似比较的结果,代码不一定相同。同时,指令归一化后的比较方案和基于图的相似性解决方案之间也无法比较。第四个原因是通过嵌入学习的向量,无法描述相似性决策过程,定位不了哪些片段区域相似。
近些年知识图谱在很多任务中展现巨大应用潜力。知识图谱是以图的形式表现客观世界中的实体(概念)及其之间关系的知识库。知识表示学习是面向知识库中实体和关系的表示学习。通过将实体或关系投影到低维向量空间,能够实现对实体和关系的语义信息的表示,高效地计算实体、关系及其之间的复杂语义关联,进而理解搜索的语义,提供更精准的搜索答案。以Word2vec、Doc2vec 和BERT 为代表的预训练语言模型,能从文本抽取出丰富的语言信息,但是很少考虑将知识图谱的结构化信息融入其中,从而提高语言的理解。ERNIE(Enhanced language Representation with Informative Entities)方案通过训练一个增强的语言表示模型,能够同时利用词汇、语义和知识信息,使得实体能够增强语言表示。因此,从n
个目标中找到k
个最相似的代码搜索问题,可以尝试利用TransE(Translating Embeddings for modeling multi-relational data)代表的知识表示学习二进制代码语义信息,从多个维度实现异质信息融合。将二进制代码片段看作是一个知识图谱,通过知识图谱推理结果来比较代码片段,在准确性和可解释性上可能会效果更好。深度学习的不透明特性为找到网络安全解决方案带来挑战。深度神经网络利用数以万计的神经元在大量的数据集上进行训练而成。训练本身带来的高度复杂性和黑盒操作,使得研究人员很难理解神经网络的某些决策,从而导致无法信任神经网络给出的安全结果,对于错误的结果也无法有效判断神经网络的错误出现在哪里。LEMNA(Local Explanation Method using Nonlinear Approximation)方 案开启了二进制代码逆向和恶意软件聚类的可解释性问题的研究,重点关注寻找函数边界,确定函数类型,以及定位相似代码,实验阐释了为什么聚类操作会作出正确或者错误的决定。
5.2 语义识别问题
准确定义语义关系并识别代码语义是解决代码搜索的核心技术。语义比较能够容忍源代码转换和二进制代码转变。在评估两个文件相似性的时候,基于语义的方案既能够容忍跨编译、跨优化和跨平台带来的鲁棒性搜索问题,更能够处理代码混淆转换后的相似性问题。
由于动态分析发生在运行时,代码运行时的内存地址、操作值和控制流去向都非常明确,因此可以处理部分代码混淆从而应用于语义相等比较。但是动态分析在混淆代码的处理上也存在困难,主要是因为一次只能执行一个路径,并且只能在这个路径执行中比较相似性。二进制代码仍会面临代码混淆带来的挑战。研究表明由于函数边界识别问题,当前脱壳技术会造成20%~60%的原始代码丢失,如对采用虚拟化加壳器技术带来的混淆并没有较好的解决方案。
从漏洞发现角度出发,融入数据语义相似性和数据流分析技术可能会产生比较好的语义相等结果,从而有助于漏洞进化研究。因此,结合二进制代码类型恢复,定位代码使用中的变量并对变量相关的操作进行分类,生成携带调试信息的参数,进一步挖掘二进制的高级语义信息是二进制代码逆向分析的趋势,其研究结果更有助于搜索等下游任务的实现。
5.3 进化性问题
当前二进制代码相似性比较方案,并没有考虑比较片段是否进化如代码的新增、更新或者删除。这些进化可能会带来语义的巨大差异,如深度学习模型中某个参数的修订或者加解密算法中某个API 的更换。总之,相似性比较方案仅仅能够鉴别相似性,但是却无法鉴别语义进化。
安全漏洞分析和bug 搜索中也会面临这样的需求,如很多程序在更新补丁信息后并不会透露更新细节。安全补丁大多是微小变化,92%的安全补丁是在一个文件中,30%的补丁修复仅仅包含一行条件。这样一来,基于相似性的方法在识别细微变化上会更难,从而无法有效地区分补丁版本和未补丁版本,从而在bug 搜索或者漏洞发现时会产生很高的误报率或漏报率。研究高级语义的描述,识别不同应用场景的进化模式,可能是进化性搜索的解决之道。
有学者从演化网络入手,研究恶意代码之间的多继承关系。文献[98]提出了利用分割图的恶意代码家族世袭网络构建算法,能够自动构建包含多继承关系的演化网络。该方案虽然能够自动地进行分析,但面对海量待分析恶意代码时,计算时间将急剧增加。有学者从基因视角来描述恶意代码之间的演化关系,通过计算基因之间的相似性来判断恶意代码之间的相似性。为识别相似的恶意代码之间是否发生进化,文献引入时间特征来反映恶意代码出现的先后顺序,从而指导恶意代码演化网络的建立。
6 结语
本文讨论了二进制代码相似性搜索当前的研究现状,分别从语法、语义和语用角度对比分析各种方案。未来的二进制代码分析需要从低级语义分析变更到高级语义或语用的分析上来,需要能够处理进化性、可解释性带来的问题挑战。尽管逆向分析话题很老,但是技术难度大,并伴随着闭源和安全对抗的需要会永远持续活跃下去,并会在网络安全漏洞发现和恶意代码分析等真实应用场景大放异彩。
